Original source: The fifth part of the series "explanation of the principles of Chrome V8" explains the source code of V8 Parser - Security guest. The security information platform V8 is the core component of chrome, so it's not necessary to say how important it is. This series of articles explain the V8 source code, strive to fully cover the knowledge points, have a theoretical height, explain the code in detail and have a practical basis. https://www.anquanke.com/post/id/253652
https://www.anquanke.com/post/id/253652
1. Summary
This is the fifth chapter, which analyzes the source code and workflow of V8 parser, and explains the core source code, main workflow and important data structures of V8 parser. This article will follow the "test sample code" of the fourth article.
2. Overview of syntax analysis
Syntax analysis is the next stage of lexical analysis (scanner). The token word output (out) of lexical analysis is the input (in) of syntax analysis. Syntax analysis will frequently use lexical analyzer to generate tokens during work. In this paper, the lexical analyzer is used as a black box function to directly give the token word results of lexical analysis. See the fourth article for the principle of lexical analyzer.
3. Source code analysis
Taking function and JsPrint as examples, this paper analyzes the implementation principle of V8 parser in detail, starts with the entry function DoParseProgram() of parser, explains the syntax analysis process of user self-defined function JsPrint, and then explains the parse lazily technology.
3.1 syntax analysis
The following code is the entry function of syntax analysis.
FunctionLiteral* Parser::DoParseProgram(Isolate* isolate, ParseInfo* info) {
DCHECK_EQ(parsing_on_main_thread_, isolate != nullptr);
DCHECK_NULL(scope_);
ParsingModeScope mode(this, allow_lazy_ ? PARSE_LAZILY : PARSE_EAGERLY);
ResetFunctionLiteralId();
FunctionLiteral* result = nullptr;
{
Scope* outer = original_scope_;
DCHECK_NOT_NULL(outer);
if (flags().is_eval()) {
outer = NewEvalScope(outer);
} else if (flags().is_module()) {
DCHECK_EQ(outer, info->script_scope());
outer = NewModuleScope(info->script_scope());
}
DeclarationScope* scope = outer->AsDeclarationScope();
scope->set_start_position(0);
FunctionState function_state(&function_state_, &scope_, scope);
ScopedPtrList<Statement> body(pointer_buffer());
int beg_pos = scanner()->location().beg_pos;
if (flags().is_module()) {
DCHECK(flags().is_module());
PrepareGeneratorVariables();
Expression* initial_yield =
BuildInitialYield(kNoSourcePosition, kGeneratorFunction);
body.Add(
factory()->NewExpressionStatement(initial_yield, kNoSourcePosition));
if (flags().allow_harmony_top_level_await()) {
BlockT block = impl()->NullBlock();
{
StatementListT statements(pointer_buffer());
ParseModuleItemList(&statements);
if (function_state.suspend_count() > 1) {
scope->set_is_async_module();
block = factory()->NewBlock(true, statements);
} else {
statements.MergeInto(&body);
}
}
if (IsAsyncModule(scope->function_kind())) {
impl()->RewriteAsyncFunctionBody(
&body, block, factory()->NewUndefinedLiteral(kNoSourcePosition));
}
} else {
ParseModuleItemList(&body);
}
if (!has_error() &&
!module()->Validate(this->scope()->AsModuleScope(),
pending_error_handler(), zone())) {
scanner()->set_parser_error();
}
} else if (info->is_wrapped_as_function()) {
DCHECK(parsing_on_main_thread_);
ParseWrapped(isolate, info, &body, scope, zone());
} else if (flags().is_repl_mode()) {
ParseREPLProgram(info, &body, scope);
} else {
this->scope()->SetLanguageMode(info->language_mode());
ParseStatementList(&body, Token::EOS);
}
scope->set_end_position(peek_position());
if (is_strict(language_mode())) {
CheckStrictOctalLiteral(beg_pos, end_position());
}
if (is_sloppy(language_mode())) {
InsertSloppyBlockFunctionVarBindings(scope);
}
if (flags().is_eval()) {
DCHECK(parsing_on_main_thread_);
info->ast_value_factory()->Internalize(isolate);
}
CheckConflictingVarDeclarations(scope);
if (flags().parse_restriction() == ONLY_SINGLE_FUNCTION_LITERAL) {
if (body.length() != 1 || !body.at(0)->IsExpressionStatement() ||
!body.at(0)
->AsExpressionStatement()
->expression()
->IsFunctionLiteral()) {
ReportMessage(MessageTemplate::kSingleFunctionLiteral);
}
}
int parameter_count = 0;
result = factory()->NewScriptOrEvalFunctionLiteral(
scope, body, function_state.expected_property_count(), parameter_count);
result->set_suspend_count(function_state.suspend_count());
}
info->set_max_function_literal_id(GetLastFunctionLiteralId());
if (has_error()) return nullptr;
RecordFunctionLiteralSourceRange(result);
return result;
}
DoParseProgram() is the beginning of parsing. FunctionLiteral* result = nullptr; This statement defines a result, which is the abstract syntax tree (AST) generated at the end of syntax analysis. The result is currently null. After DoParseProgram() is executed, the ast will be generated. Debug the sample code and enter the following method.
void ParserBase<Impl>::ParseStatementList(StatementListT* body,
Token::Value end_token) {
DCHECK_NOT_NULL(body);
while (peek() == Token::STRING) {
bool use_strict = false;
#if V8_ENABLE_WEBASSEMBLY
bool use_asm = false;
#endif // V8_ENABLE_WEBASSEMBLY
Scanner::Location token_loc = scanner()->peek_location();
if (scanner()->NextLiteralExactlyEquals("use strict")) {
use_strict = true;
#if V8_ENABLE_WEBASSEMBLY
} else if (scanner()->NextLiteralExactlyEquals("use asm")) {
use_asm = true;
#endif // V8_ENABLE_WEBASSEMBLY
}
StatementT stat = ParseStatementListItem();
if (impl()->IsNull(stat)) return;
body->Add(stat);
if (!impl()->IsStringLiteral(stat)) break;
if (use_strict) {
RaiseLanguageMode(LanguageMode::kStrict);
if (!scope()->HasSimpleParameters()) {
impl()->ReportMessageAt(token_loc,
MessageTemplate::kIllegalLanguageModeDirective,
"use strict");
return;
}
#if V8_ENABLE_WEBASSEMBLY
} else if (use_asm) {
impl()->SetAsmModule();
#endif // V8_ENABLE_WEBASSEMBLY
} else {
RaiseLanguageMode(LanguageMode::kSloppy);
}
}
while (peek() != end_token) {
StatementT stat = ParseStatementListItem();
if (impl()->IsNull(stat)) return;
if (stat->IsEmptyStatement()) continue;
body->Add(stat);
}
}
The previous method is the entry point for parsing, and ParseStatementList() is the starting point for parsing program statements. In the while (peek() == Token::STRING) statement, peek is the type of token obtained. The token obtained here is Token::FUNCTION, so the value is false. Enter the while (peek()! = end_token) loop, execute the ParseStatementListItem() method, and enter the analysis function corresponding to Token::FUNCTION in this method. The code is as follows:
ParserBase<Impl>::ParseHoistableDeclaration(
ZonePtrList<const AstRawString>* names, bool default_export) {
Consume(Token::FUNCTION);//cache mechanism
int pos = position();
ParseFunctionFlags flags = ParseFunctionFlag::kIsNormal;
if (Check(Token::MUL)) {
flags |= ParseFunctionFlag::kIsGenerator;
}
return ParseHoistableDeclaration(pos, flags, names, default_export);
}
Consumption () is the specific implementation of the "token word cache" mechanism mentioned in the third article. Take a token from the cache and start analysis. If the cache is missing, drive the lexical analyzer (Scanner) to work. The principle of obtaining token from consumption is to make the current member in Scanner class point to the next member, and then use next_next judge whether to scan the next token word. Please refer to the code by yourself.
Take out the token word function and type function (Token::FUNCTION), and then judge which type the function belongs to (FunctionKind). The specific code of FunctionKind is as follows:
enum FunctionKind : uint8_t {
// BEGIN constructable functions
kNormalFunction,
kModule,
kAsyncModule,
//.................................
//A lot of code is omitted
//.................................
// END concise methods 1
kAsyncGeneratorFunction,
// END async functions
kGeneratorFunction,
// BEGIN concise methods 2
kConciseGeneratorMethod,
kStaticConciseGeneratorMethod,
// END generators
kConciseMethod,
kStaticConciseMethod,
kClassMembersInitializerFunction,
kClassStaticInitializerFunction,
// END concise methods 2
kInvalid,
kLastFunctionKind = kClassStaticInitializerFunction,
};
Do not confuse the concepts of FunctionKind and Token::FUNCTION. They belong to different technical fields. Token belongs to compilation technology and FunctionKind belongs to ECMA specification. In the sample code, the FunctionKind of token function is KnormalFunction, so the next step is to analyze the name of this function (Token::IDENTIFIER). The code is as follows:
const AstRawString* Scanner::CurrentSymbol(
AstValueFactory* ast_value_factory) const {
if (is_literal_one_byte()) {
return ast_value_factory->GetOneByteString(literal_one_byte_string());
}
return ast_value_factory->GetTwoByteString(literal_two_byte_string());
}
In the CurrentSymbol() method, do one_byte judgment, JsPrint is one_byte type, if statement is true, return identifier. Figure 1 shows the function call stack of the currentsymbol () method to facilitate the reader to reproduce the code execution process.
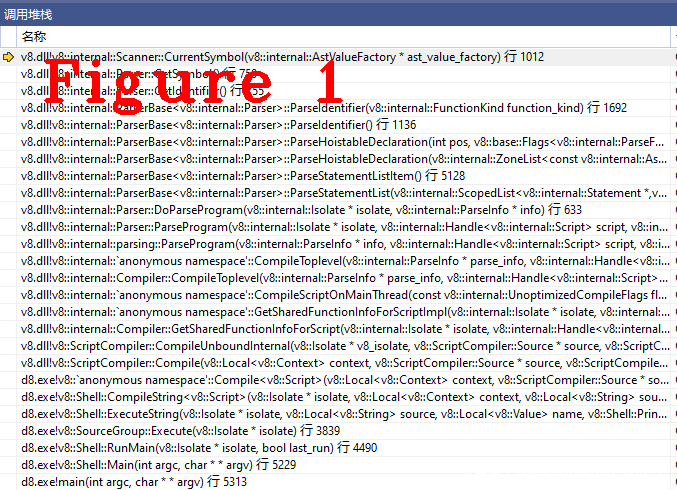
So far, the syntax analysis of the two Token words function and JsPrint has been completed. The workflow of the above code is as follows:
(1): In the Javascript source code, when you see the character 'function', it should be followed by a function;
(2): Judge whether the function type is asynchronous or other, and the sample code is kNormalFunction;
(3): It is kNormalFunction to get the name of the function.
3.2 delay analysis
What is delay analysis? Delay analysis is a performance optimization technology in V8, that is, code that is not executed immediately is not analyzed first, and then analyzed during execution. As we all know, in a program, code execution is sequential, and not all codes will be executed. Based on this, V8 implements delay analysis and delay compilation technology to improve efficiency. The following explains why the sample code triggers delay analysis.
JsPrint is a conventional (kNormalFunction) method. After obtaining the function name, start analyzing the function content. The code is as follows:
FunctionLiteral* Parser::ParseFunctionLiteral(
const AstRawString* function_name, Scanner::Location function_name_location,
FunctionNameValidity function_name_validity, FunctionKind kind,
int function_token_pos, FunctionSyntaxKind function_syntax_kind,
LanguageMode language_mode,
ZonePtrList<const AstRawString>* arguments_for_wrapped_function) {
bool is_wrapped = function_syntax_kind == FunctionSyntaxKind::kWrapped;
DCHECK_EQ(is_wrapped, arguments_for_wrapped_function != nullptr);
int pos = function_token_pos == kNoSourcePosition ? peek_position()
: function_token_pos;
DCHECK_NE(kNoSourcePosition, pos);
bool should_infer_name = function_name == nullptr;
if (should_infer_name) {
function_name = ast_value_factory()->empty_string();
}
FunctionLiteral::EagerCompileHint eager_compile_hint =
function_state_->next_function_is_likely_called() || is_wrapped
? FunctionLiteral::kShouldEagerCompile
: default_eager_compile_hint();
DCHECK_IMPLIES(parse_lazily(), info()->flags().allow_lazy_compile());
DCHECK_IMPLIES(parse_lazily(), has_error() || allow_lazy_);
DCHECK_IMPLIES(parse_lazily(), extension() == nullptr);
const bool is_lazy =
eager_compile_hint == FunctionLiteral::kShouldLazyCompile;
const bool is_top_level = AllowsLazyParsingWithoutUnresolvedVariables();
const bool is_eager_top_level_function = !is_lazy && is_top_level;
const bool is_lazy_top_level_function = is_lazy && is_top_level;
const bool is_lazy_inner_function = is_lazy && !is_top_level;
RCS_SCOPE(runtime_call_stats_, RuntimeCallCounterId::kParseFunctionLiteral,
RuntimeCallStats::kThreadSpecific);
base::ElapsedTimer timer;
if (V8_UNLIKELY(FLAG_log_function_events)) timer.Start();
const bool should_preparse_inner = parse_lazily() && is_lazy_inner_function;
bool should_post_parallel_task =
parse_lazily() && is_eager_top_level_function &&
FLAG_parallel_compile_tasks && info()->parallel_tasks() &&
scanner()->stream()->can_be_cloned_for_parallel_access();
// This may be modified later to reflect preparsing decision taken
bool should_preparse = (parse_lazily() && is_lazy_top_level_function) ||
should_preparse_inner || should_post_parallel_task;
ScopedPtrList<Statement> body(pointer_buffer());
int expected_property_count = 0;
int suspend_count = -1;
int num_parameters = -1;
int function_length = -1;
bool has_duplicate_parameters = false;
int function_literal_id = GetNextFunctionLiteralId();
ProducedPreparseData* produced_preparse_data = nullptr;
Zone* parse_zone = should_preparse ? &preparser_zone_ : zone();
DeclarationScope* scope = NewFunctionScope(kind, parse_zone);
SetLanguageMode(scope, language_mode);
#ifdef DEBUG
scope->SetScopeName(function_name);
#endif
if (!is_wrapped && V8_UNLIKELY(!Check(Token::LPAREN))) {
ReportUnexpectedToken(Next());
return nullptr;
}
scope->set_start_position(position());
bool did_preparse_successfully =
should_preparse &&
SkipFunction(function_name, kind, function_syntax_kind, scope,
&num_parameters, &function_length, &produced_preparse_data);
if (!did_preparse_successfully) {
if (should_preparse) Consume(Token::LPAREN);
should_post_parallel_task = false;
ParseFunction(&body, function_name, pos, kind, function_syntax_kind, scope,
&num_parameters, &function_length, &has_duplicate_parameters,
&expected_property_count, &suspend_count,
arguments_for_wrapped_function);
}
if (V8_UNLIKELY(FLAG_log_function_events)) {
double ms = timer.Elapsed().InMillisecondsF();
const char* event_name =
should_preparse
? (is_top_level ? "preparse-no-resolution" : "preparse-resolution")
: "full-parse";
logger_->FunctionEvent(
event_name, flags().script_id(), ms, scope->start_position(),
scope->end_position(),
reinterpret_cast<const char*>(function_name->raw_data()),
function_name->byte_length(), function_name->is_one_byte());
}
#ifdef V8_RUNTIME_CALL_STATS
if (did_preparse_successfully && runtime_call_stats_ &&
V8_UNLIKELY(TracingFlags::is_runtime_stats_enabled())) {
runtime_call_stats_->CorrectCurrentCounterId(
RuntimeCallCounterId::kPreParseWithVariableResolution,
RuntimeCallStats::kThreadSpecific);
}
#endif // V8_RUNTIME_CALL_STATS
language_mode = scope->language_mode();
CheckFunctionName(language_mode, function_name, function_name_validity,
function_name_location);
if (is_strict(language_mode)) {
CheckStrictOctalLiteral(scope->start_position(), scope->end_position());
}
FunctionLiteral::ParameterFlag duplicate_parameters =
has_duplicate_parameters ? FunctionLiteral::kHasDuplicateParameters
: FunctionLiteral::kNoDuplicateParameters;
FunctionLiteral* function_literal = factory()->NewFunctionLiteral(
function_name, scope, body, expected_property_count, num_parameters,
function_length, duplicate_parameters, function_syntax_kind,
eager_compile_hint, pos, true, function_literal_id,
produced_preparse_data);
function_literal->set_function_token_position(function_token_pos);
function_literal->set_suspend_count(suspend_count);
RecordFunctionLiteralSourceRange(function_literal);
if (should_post_parallel_task) {
// Start a parallel parse / compile task on the compiler dispatcher.
info()->parallel_tasks()->Enqueue(info(), function_name, function_literal);
}
if (should_infer_name) {
fni_.AddFunction(function_literal);
}
return function_literal;
}
ParseFunctionLiteral(), the name of this method indicates that its main function is to analyze the function content. After the name JsPrint analysis is completed, enter this method to analyze the contents of the JsPrint function. First judge whether this method meets the delay analysis conditions.
Figure 2 is the sample code. It can be seen that JsPrint will not be executed immediately, and it is the most external top-level method, which meets the delay analysis conditions. The same conclusion can be drawn from the execution sequence of Javascript: JsPrint function is defined, but console.log() is the first to execute when code is executed. When console.log() is executed, parameters need to be calculated and stacked first, so JsPrint is not executed immediately, but JsPrint is called when console.log() is executed, so it meets the delay analysis condition.
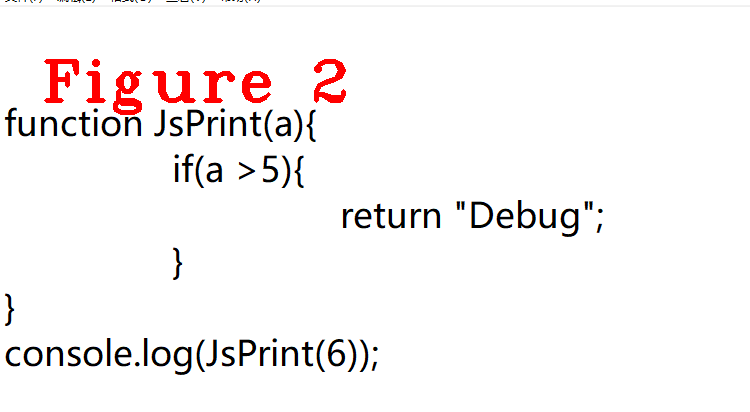
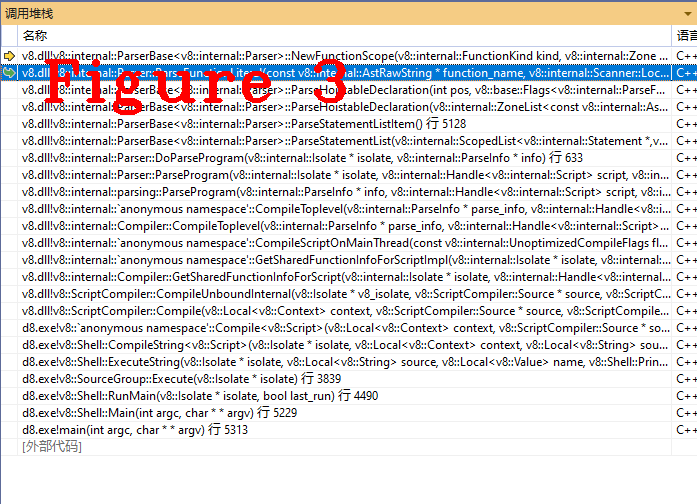
Debugging program is the most effective verification method. Verify whether the above conclusion is correct from the perspective of code. Please track ParseFunctionLiteral() method and check is_lazy and is_ top_ The value of the level member. If you see that the values of these two members are true, the above conclusion is correct. Figure 3 shows the call stack of ParseFunctionLiteral(), which is convenient for readers to reproduce the code execution process.
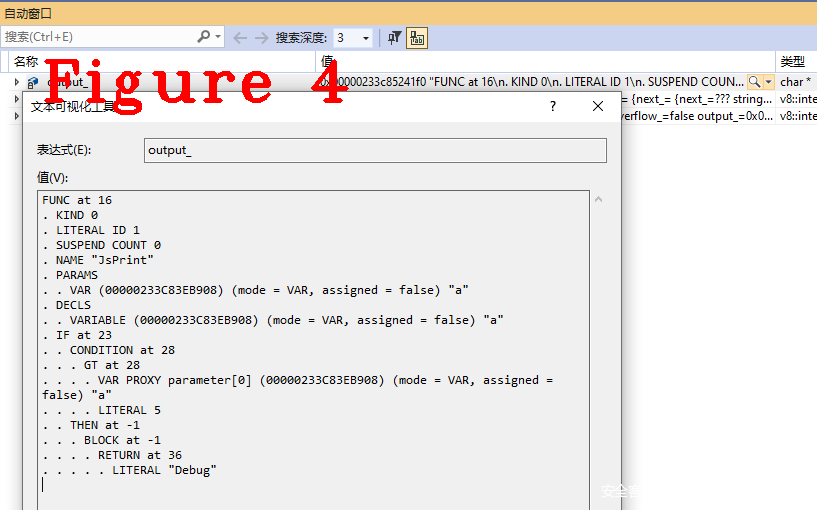
The abstract syntax diagram of JsPrint() is given below for readers to analyze and learn, as shown in Figure 4.
In conclusion, the code logic of the parser is very complex. Making stack records when analyzing the code is helpful to quickly help you find the nearest correct location and improve learning efficiency in case of "error tracking and loss" problems in the tracking code.
Well, that's all for today. See you next time.
Wechat: qq9123013 remarks: v8 communication email: v8blink@outlook.com