1. Experimental Purpose
To crawl the State Drug Administration( Service Platform for Cosmetics Production License Information Management System (nmpa.gov.cn) (Details of cosmetics production (specific information about each enterprise), when we entered the first page of this website, we found that it was structured with 15 pieces of json-type data per page. See below for short the first page:
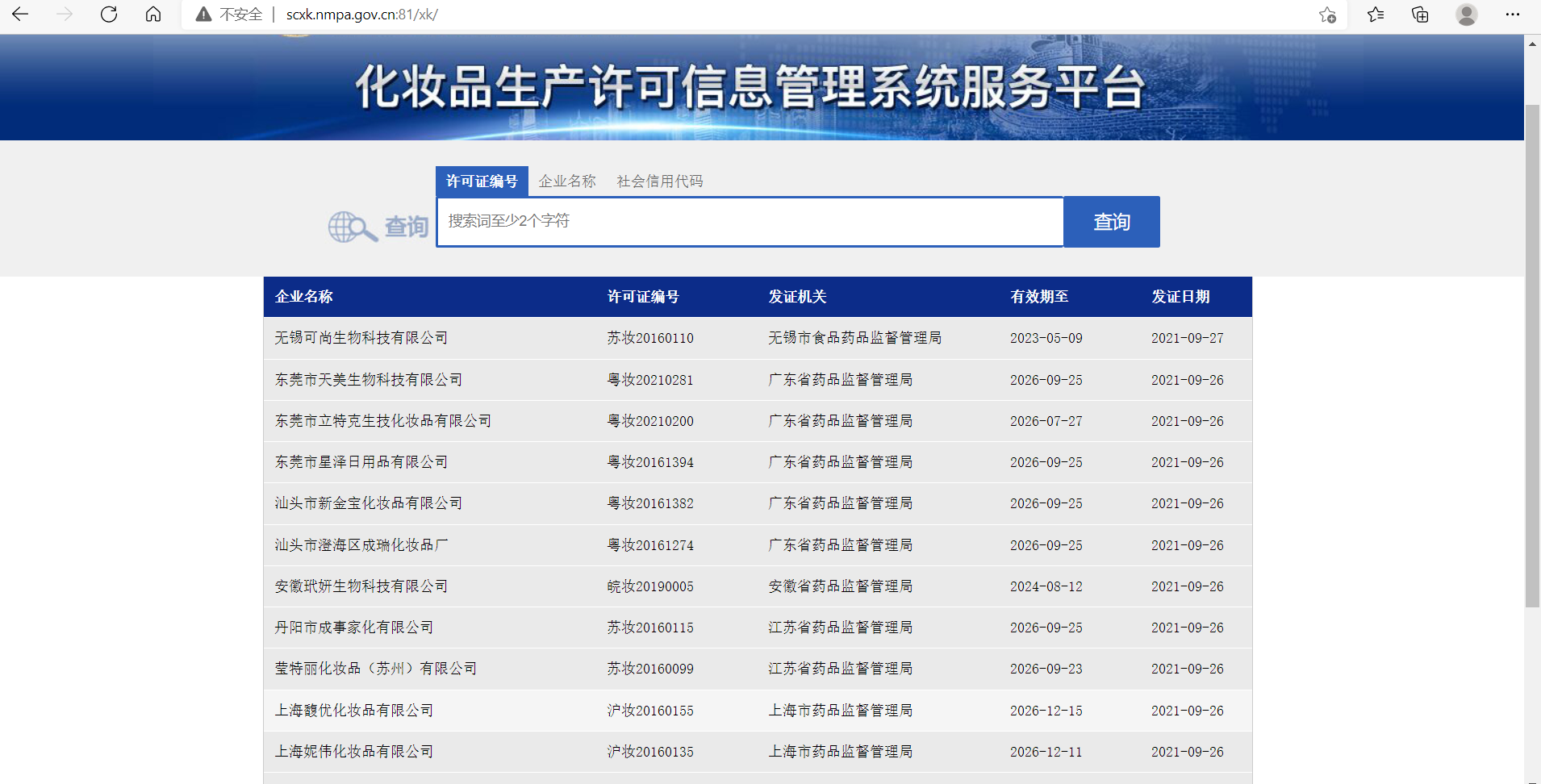
Click on the hyperlink corresponding to the business name to jump to the page we need to crawl, hereinafter referred to as the details page:

* We need to crawl all the information on the details page and save it locally in json format.
2. URL to obtain dynamically loaded data
First, we verify whether we can crawl hyperlinks for each enterprise data by crawling the homepage information, then request access to the hyperlink data for experimental purposes, open the developer mode, and find the page corresponding to the homepage url:
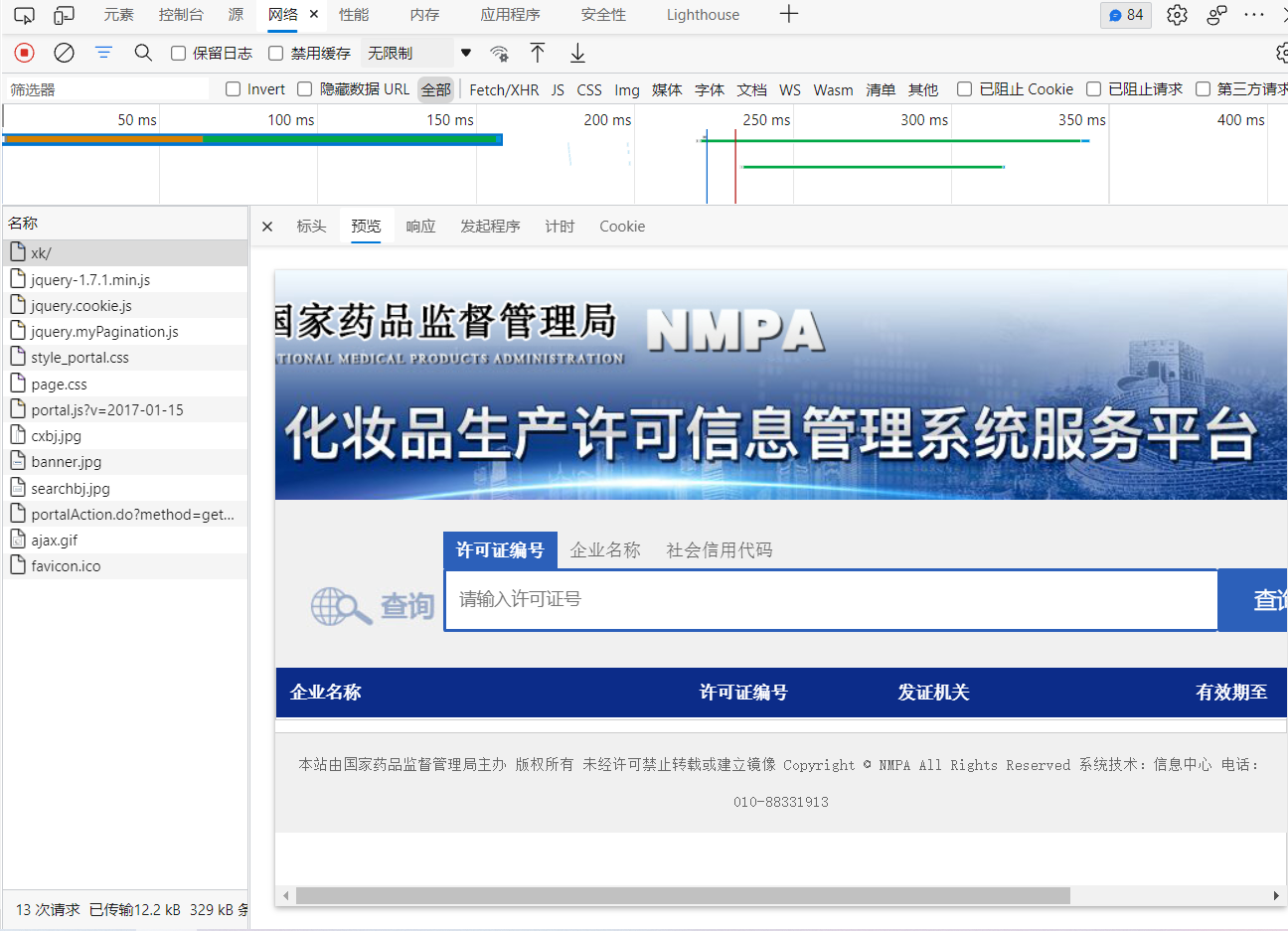
It is found that there is no enterprise hyperlink on this page, indicating that the information on this page belongs to dynamic loading data, that is, the url of the first page is different from the url of dynamic loading link, and the url corresponding to dynamic loading data needs to be found.
Open the details of the dynamically loaded data through the package capture tool:
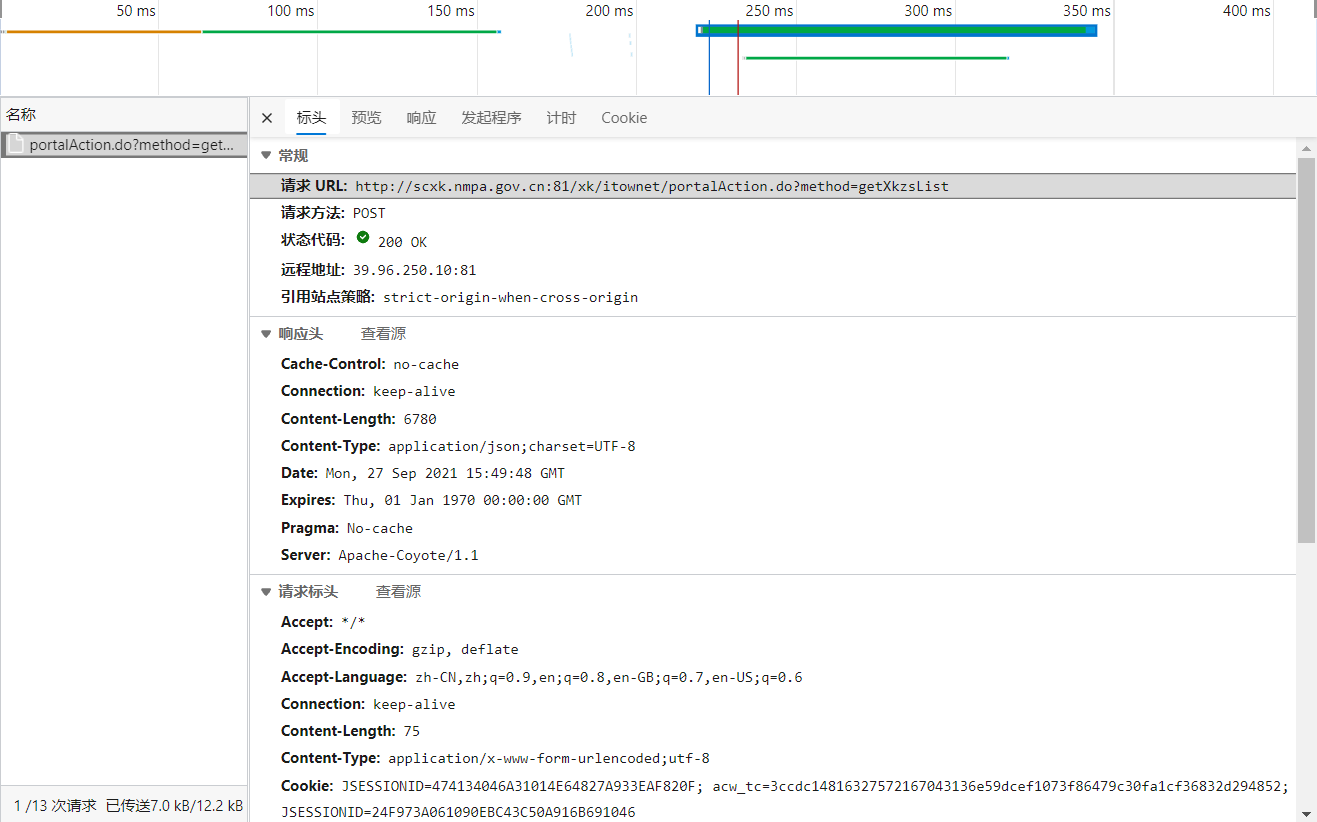
The corresponding dynamic url is found to be: http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList
The data format is: json
Request method is:post
The structure of its dynamic data is: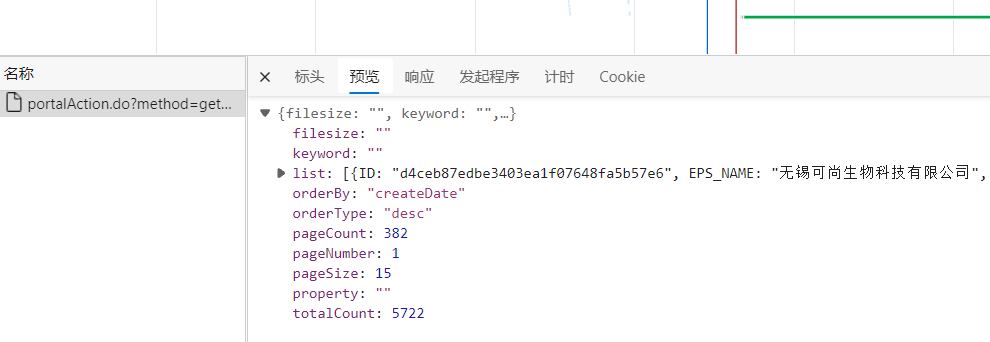
A page is a big dictionary, its value is a list, which contains 15 small dictionaries, each of which corresponds to 15 pieces of enterprise information on each page. When we open the details page and use the previous verification methods, we find that the information in the details page is also dynamically loaded data, and can not be crawled directly, so we use the package capture tool to find out the dynamic load letter of its first enterprise.The url corresponding to the message:
Cosmetics Production License of the People's Republic of China (nmpa.gov.cn) It is structured as a dynamic URL plus a unique identifier for each enterprise enterprise enterprise enterprise id, so our experimental idea is to crawl the enterprise ID of the first page, then stitch it onto the dynamic URL of the details page, and then traverse to request the specific information of the new url, which is nested in the dictionary of the first page structure:

3. Code implementation
After clarifying the crawl ideas, we begin code practice with comments:
#Project Objectives Crawl Data on Cosmetics Production Licenses from the State Drug Administration
#The relevant data of this web page include: enterprise name, license number, validity period, etc.#Ultimately, you need to crawl the details of each business (detail pages) - data that is dynamically loaded (not directly resolved by the url of the current page)
#Crawl ideas: crawl the homepage data before locating the hyperlink corresponding to each enterprise name on the homepage (crawl the hyperlink url corresponding to each enterprise through the homepage) and then send a request for each detail page hyperlink
# Validation: Use XHR to capture dynamic data packets to view the data structure and type of dynamic data
import requests
import json
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
} #Anti-crawl mechanism: disguise user login via browser
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
#Encapsulation of parameters
for page in range(1,6):
page = str(page)
data = {
'on': 'true',
'page': page, #Which page of the hour
'pageSize': '15', #The page has 15 pieces of data
'productName':'',
'conditionType': '1',
'applyname':'',
'applysn':'',
}
# Combining request and response data to get json data with a dictionary type of enterprise id
json_ids = requests.post(url=url,headers=headers,data=data).json()#Make an access request to the url; use the post() method to get the request page information in the form of.json data.
print(json_ids)
id_list = [] # Storage enterprise id
all_data_list = [] # Store all enterprise detail data (in 15 dictionaries)
# Get ID values for different enterprises in batch (enterprise detail page url=original url+enterprise id) Unified url+different parameters
#The value of the dictionary is a list (each small dictionary in the list corresponds to one enterprise)
for dic in json_ids['list']: #Walk through each dictionary in the list and fetch the id data
id_list.append(dic['ID'])
#Get Enterprise Detail Data
post_url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_list:
data = {
'id':id
}
detail_json = requests.post(url=post_url,headers=headers,data=data).json()
all_data_list.append(detail_json)
#print(detail_json)
#Persistent storage all_data_list
fp = open('./Outcome.json','w',encoding='utf-8') #Write and save data
json.dump(all_data_list,fp=fp,ensure_ascii=False)
print('Save Successfully')The crawled JSON data is now stored in Outcome.json under the current path, and the output is viewed:
