The third example uses the logical regression of Spark ML to predict music tags
- This is a multivariate classification problem, that is, there are many predicted results.
- For the introduction and knowledge points of Spark ML, please refer to: Spark ML learning notes - Spark MLlib and Spark ML.
3.1 data preparation
3.1.1 data set file preparation
-
(1) The project does not use the database as the data source, but directly puts the data file in the project directory, which is a structured simplified data set.
-
(2) The data set used in this project is the famous MNIST data set, which contains 780 features. Dataset address: Million song dataset.

2.1.2 dataset field interpretation
- Because there are too many fields, no specific field explanation is given here.
2.2 implementation code using Spark ML
2.2.1 importing project dependencies
Most of the dependent packages used come from Spark ML, not Spark MLlib.
import org.apache.spark.SparkConf import org.apache.spark.mllib.classification.LogisticRegressionWithLBFGS import org.apache.spark.mllib.evaluation.MulticlassMetrics import org.apache.spark.mllib.util.MLUtils import org.apache.spark.sql.SparkSession
2.2.2 load and parse MNIST dataset in libsvm format
val data = MLUtils.loadLibSVMFile(spark.sparkContext, "datas3/mnist.bz2")
2.2.3 preparation of training and test sets
val splits = data.randomSplit(Array(0.75, 0.25), 12345L) val training = splits(0).cache() val test = splits(1)
2.2.4 run the training algorithm to create the model
val model = new LogisticRegressionWithLBFGS()
.setNumClasses(10)
.setIntercept(true)
.setValidateData(true)
.run(training)
- At this step, the prediction model has been created successfully. In the future, you only need to predict according to this model.
2.2.5 calculate the original score on the test
val scoreAndLabels = test.map{
point => {
val score = model.predict(point.features)
(score, point.label)
}
}
- At this stage, the prediction results have been obtained several times. You only need to cycle through the output. The prediction results are shown in the following figure:
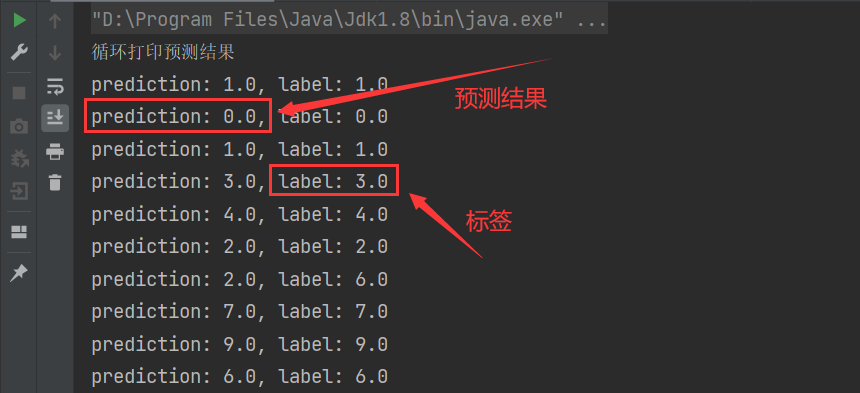
- It can be seen from the above figure that the prediction predicted is completely consistent with the label, indicating that the prediction accuracy is very high.
- So far, the prediction work has been completed, and there are still some operations to observe the training process and model evaluation.
2.2.6 initialize a multi class measure for model evaluation
// Initialize a multi class metric for model evaluation (metrics contains various metric information of the model) val metrics = new MulticlassMetrics(scoreAndLabels)
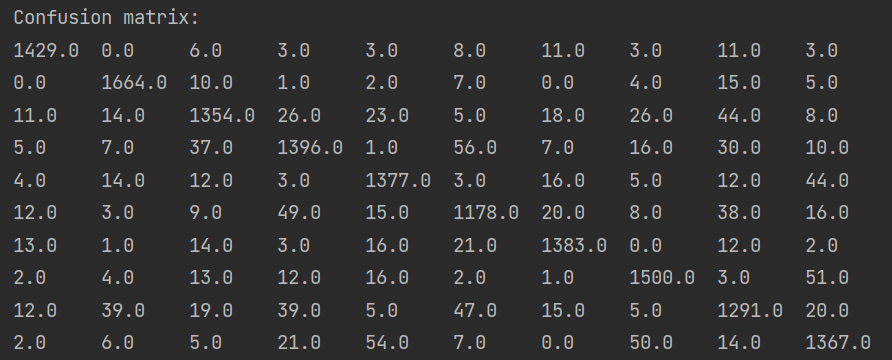
2.2.7 constructing confusion matrix
println("Confusion matrix: ")
println(metrics.confusionMatrix)
The confusion matrix is shown in the figure below:
2.2.8 overall statistical information
val accuracy = metrics.accuracy
println("Summary Statistics")
println(s"Accuracy = $accuracy")
// Precision by label
val labels = metrics.labels
labels.foreach(
l => println(s"Precision($l) = " + metrics.precision(l))
)
// Recall by label
labels.foreach(
l => println(s"Recall($l) = " + metrics.recall(l))
)
// False positive rate by label
labels.foreach(
l => println(s"FPR($l) = " + metrics.falsePositiveRate(l))
)
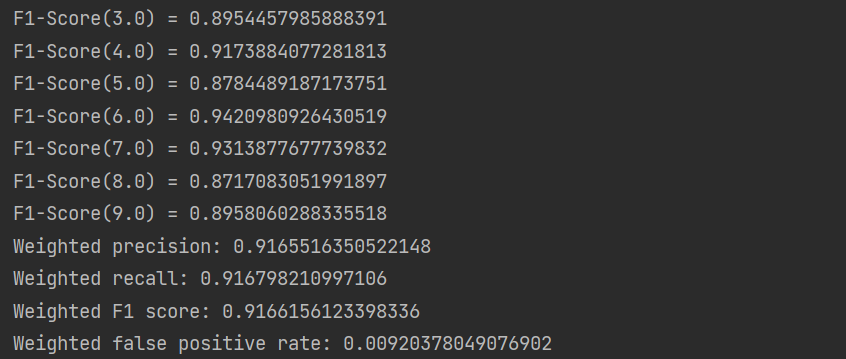
// F-measure by label (F1 score)
labels.foreach(
l => println(s"F1-Score($l) = " + metrics.fMeasure(l))
)
// Calculate overall statistics
println(s"Weighted precision: ${metrics.weightedPrecision}")
println(s"Weighted recall: ${metrics.weightedRecall}")
println(s"Weighted F1 score: ${metrics.weightedFMeasure}")
println(s"Weighted false positive rate: ${metrics.weightedFalsePositiveRate}")
The output information of the above code is shown in the figure below:
2.2.9 complete project code
import org.apache.spark.SparkConf
import org.apache.spark.mllib.classification.LogisticRegressionWithLBFGS
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.sql.SparkSession
/**
* description: Multivariate classification using logistic regression: Original
*/
object SparkML_0105_test5 {
def main(args: Array[String]): Unit = {
// TODO creates the running environment of Spark SQL
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkML")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// step 1: load and parse MNIST dataset in libsvm format
val data = MLUtils.loadLibSVMFile(spark.sparkContext, "datas3/mnist.bz2")
// step 2: prepare training and test sets (split the data into training set (75%) and test set (25%))
val splits = data.randomSplit(Array(0.75, 0.25), 12345L)
val training = splits(0).cache()
val test = splits(1)
// step 3: run the training algorithm to create the model
val model = new LogisticRegressionWithLBFGS()
.setNumClasses(10)
.setIntercept(true)
.setValidateData(true)
.run(training)
// step 4: clear default threshold
model.clearThreshold()
// step 5: calculate the original score on the test
val scoreAndLabels = test.map{
point => {
val score = model.predict(point.features)
(score, point.label)
}
}
// step 6: initialize a multi class measurement for model evaluation (metrics contains various measurement information of the model)
val metrics = new MulticlassMetrics(scoreAndLabels)
// step 7: construct confusion matrix
println("Confusion matrix: ")
println(metrics.confusionMatrix)
// step 8: overall statistics
val accuracy = metrics.accuracy
println("Summary Statistics")
println(s"Accuracy = $accuracy")
// Precision by label
val labels = metrics.labels
labels.foreach(
l => println(s"Precision($l) = " + metrics.precision(l))
)
// Recall by label
labels.foreach(
l => println(s"Recall($l) = " + metrics.recall(l))
)
// False positive rate by label
labels.foreach(
l => println(s"FPR($l) = " + metrics.falsePositiveRate(l))
)
// F-measure by label (F1 score)
labels.foreach(
l => println(s"F1-Score($l) = " + metrics.fMeasure(l))
)
// Calculate overall statistics
println(s"Weighted precision: ${metrics.weightedPrecision}")
println(s"Weighted recall: ${metrics.weightedRecall}")
println(s"Weighted F1 score: ${metrics.weightedFMeasure}")
println(s"Weighted false positive rate: ${metrics.weightedFalsePositiveRate}")
spark.close()
}
}