This is an exercise in the little turtle video. The general requirement is
subject
#Task: divide the data in the file (talk.txt) and save it according to the following rules:
#– A author's dialogue is saved separately as A_ * Txt file (remove "A author:")
#– B author's conversations are saved separately as b_ * Txt file (remove "B Author:")
#– there are three conversations in the file, which are saved as A_1.txt, B_1.txt,A_2.txt, B_2.txt, A_3.txt, B_3.txt there are 6 files in total (prompt: different conversations in the file have been split with "=======================================================
You can see the content of talk.txt created by myself as follows

effect
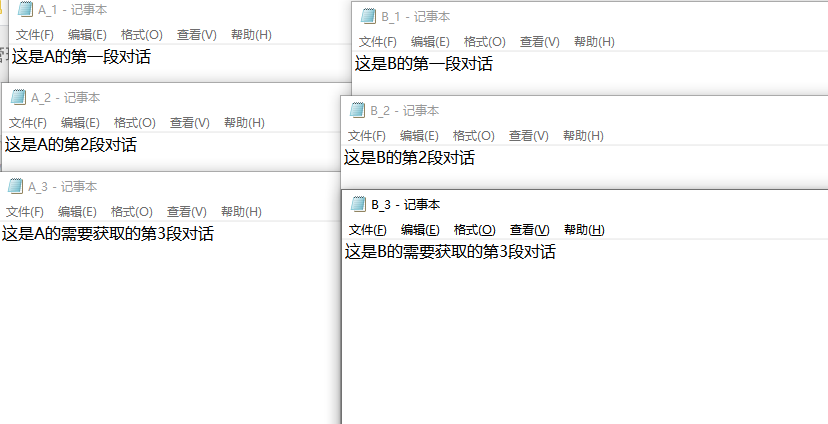
Let's take a look at the effect after completion

The original txt is divided into six files, and each file saves the corresponding words separately
Unoptimized code
Most of the notes and instructions are written in the notes
#Task: divide the data in the file (talk.txt) and save it according to the following rules:
#– the conversation of author A is saved separately as A *. TXT file (remove "author A:")
#– B author's dialogue is saved as a separate file of B_*.txt (remove "B Author:")
#– there are three conversations in the file, which are saved as A_1.txt, B_1.txt, a_2.txt, b_2.txt, a_3.txt and b_3.txt (Note: different conversations in the file have been divided by "=============================================================
f = open('talk.txt','r', encoding='UTF-8')
listA = []
listB = []
count = 1
for each_line in f:
if each_line[:6] != '======': # Just a few equal signs before cutting
(role,line_spoken) = each_line.split(': ',1) # split: cut the character once. Note whether the symbol in txt is Chinese or English
# Store the cut two parts in role and line_spoke in turn
if role == 'A author':
listA.append(line_spoken) # Add the author's content to list A
if role == 'B author':
listB.append(line_spoken) # B the author's content is added to list B
else:
# If an equal sign is encountered, save the file
file_name_A = 'A_' + str(count) + '.txt'
file_name_B = 'B_' + str(count) + '.txt'
A_file = open(file_name_A,'w') # Create a new txt file named file_name_A in w mode
B_file = open(file_name_B,'w') # And label the B_file
A_file.writelines(listA) # Write the contents of list A to the A_file
B_file.writelines(listB)
A_file.close() # Close A_file
B_file.close()
listA = [] # clear list
listB = []
count += 1
# The loop takes the equal sign as the judgment condition. In this way, if there is no equal sign at the end of the last paragraph of text, the last paragraph of text needs to be processed separately (the processing method directly calls the above else part repeatedly)
file_name_A = 'A_' + str(count) + '.txt'
file_name_B = 'B_' + str(count) + '.txt'
A_file = open(file_name_A,'w') # Create a new txt file named file_name_boy in w mode
B_file = open(file_name_B,'w') # And label the B_file
A_file.writelines(listA) # Write the contents of list A to the A_file
B_file.writelines(listB)
A_file.close() # Close A_file
B_file.close()
f.close()
The main idea here is
1. Open the txt file we have created, save the speech contents of author A and author B with listA and listB respectively, and count for counting.
2. Traverse each line in the file. When there is no paragraph segmentation symbol '= = =', divide each line with a colon and divide it into two parts: author name and speaking content. The speaking content part is pushed into the list
3. When the equal sign part of the paragraph separator is encountered, a new txt file is created, named after the count count
4. Use the writelines() method to write a sequence of strings (previously saved listA, listB) to the file.
5. Close the file.
6. The loop takes the equal sign as the judgment condition. In this way, if there is no equal sign at the end of the last paragraph of text, the last paragraph of text needs to be processed separately (the processing method directly calls the above else part repeatedly)
7. Close file
ps
Here is a record of the small problems encountered
1. Prompt when python reads a file resolvent:
resolvent:
f = open('talk.txt','r', encoding='UTF-8')
Later, it was found that there was another solution
f = open('talk.txt','rb')
2. Symbol problem in split segmentation

This is because I use Chinese symbols in txt, but the English symbols used in the program are segmented, resulting in an error
Optimized code
Update after writing in the afternoon