2021SC@SDUSC
Catalogue of series articles
(1) Division of labor within the group
(2) Task 1 code analysis of crawler part (Part I)
(3) Task 1: code analysis of crawler part (Part 2)
catalogue
preface
Following the above, continue to analyze the crawler code
1, Core code analysis
After entering the search interface, we need to grab the title of the article, turn pages and crawl multiple pages at the same time. We use the following function.
(2) def page_url_list(soup, page=0):
The main function of this function is to get all the URLs that need to be crawled and save them to the list urls_list as the return result
The home page is as follows
fir_page = "http://xueshu.baidu.com" + soup.find_all("a", class_="n")[0]["href"]
urls_list = []How to turn the page? Let's open multiple pages to observe the web page URL:
first page:
https://xueshu.baidu.com/s?wd=%E4%B8%93%E5%88%A9&pn=0&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D%7BfirstSimpleSearch%7D&sc_hit=1
Page 2:
https://xueshu.baidu.com/s?wd=%E4%B8%93%E5%88%A9&pn=10&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D%7BfirstSimpleSearch%7D&sc_hit=1
Page 3:
https://xueshu.baidu.com/s?wd=%E4%B8%93%E5%88%A9&pn=20&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D%7BfirstSimpleSearch%7D&sc_hit=1
It can be found that only one of the three page URL s has changed, that is, the value of "pn", starting from 0 and then increasing by 10 each time. Therefore, we can turn the page well through this.
next_page = fir_page.replace("pn=10", "pn={:d}".format(i * 10))Then use find_all method to get the title
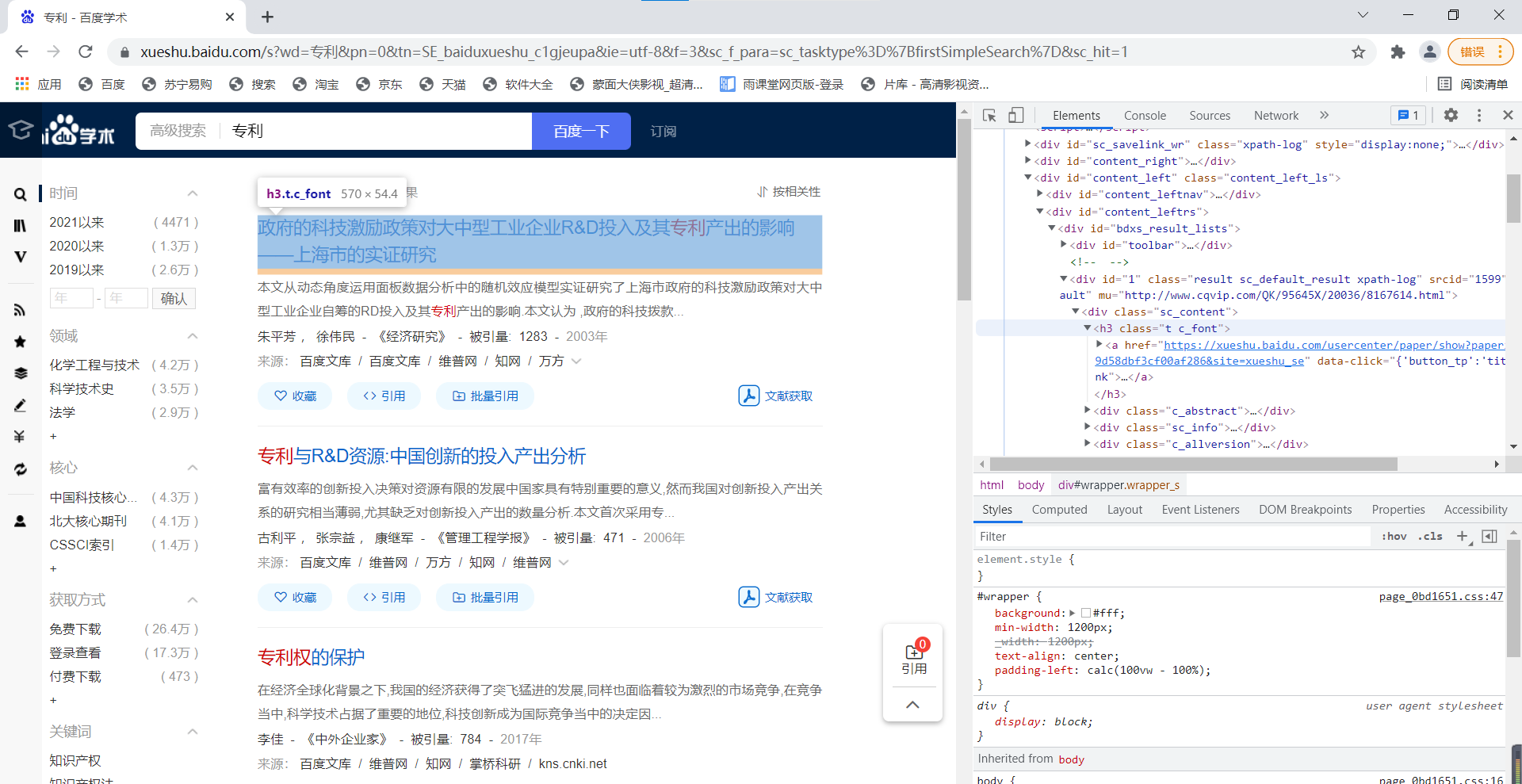
c_fonts = soup_new.find_all("h3", class_="t c_font")Then cycle at C_ Use C in fonts_ Font. Find ("a"). Attrs ["href"] can obtain all required URLs
So far, the analysis of the second function is completed
The next step is to grab the places of interest. When we enter the details page, we need to capture the following things: title, summary and keywords. Or according to the old method, check the source code of these things that need to be crawled one by one, and handle them with CSS select method.
(3) def get_item_info(url):
First, requests is used to convert links into html language, while beautiful soup is used to find the required content.
content_details = requests.get(url) soup = BeautifulSoup(content_details.text, "lxml")
Then, you can get the required content by using the soup.select() method.
The prototype of soup.select() in the source code is: select(self, selector, namespaces=None, limit=None, **kwargs)
Function: find what we need in html
The main parameter we use is selector, which is defined as "string containing CSS selector". For CCS, we also need to understand some concepts. Refer to CCS syntax, CSS Id and Class.
When we write CSS, we do not add any modification to the tag name, add dots before the class name and add #, here we can also use similar methods to filter elements
# Extract article title
try:
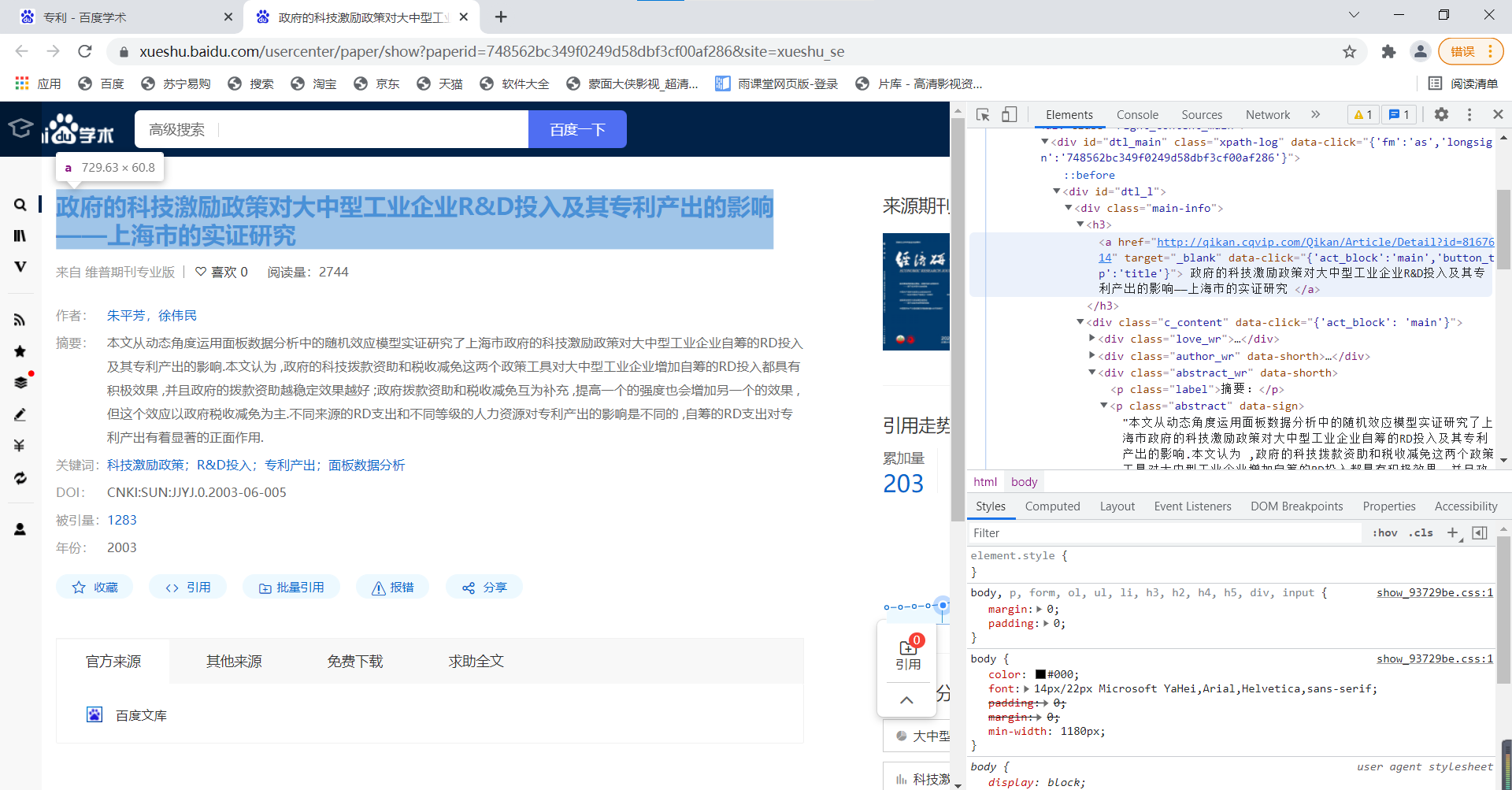
title = ''.join(list(soup.select('#dtl_l > div > h3 > a')[0].stripped_strings))
except(IndexError):
title = ''
# Extract summary
try:
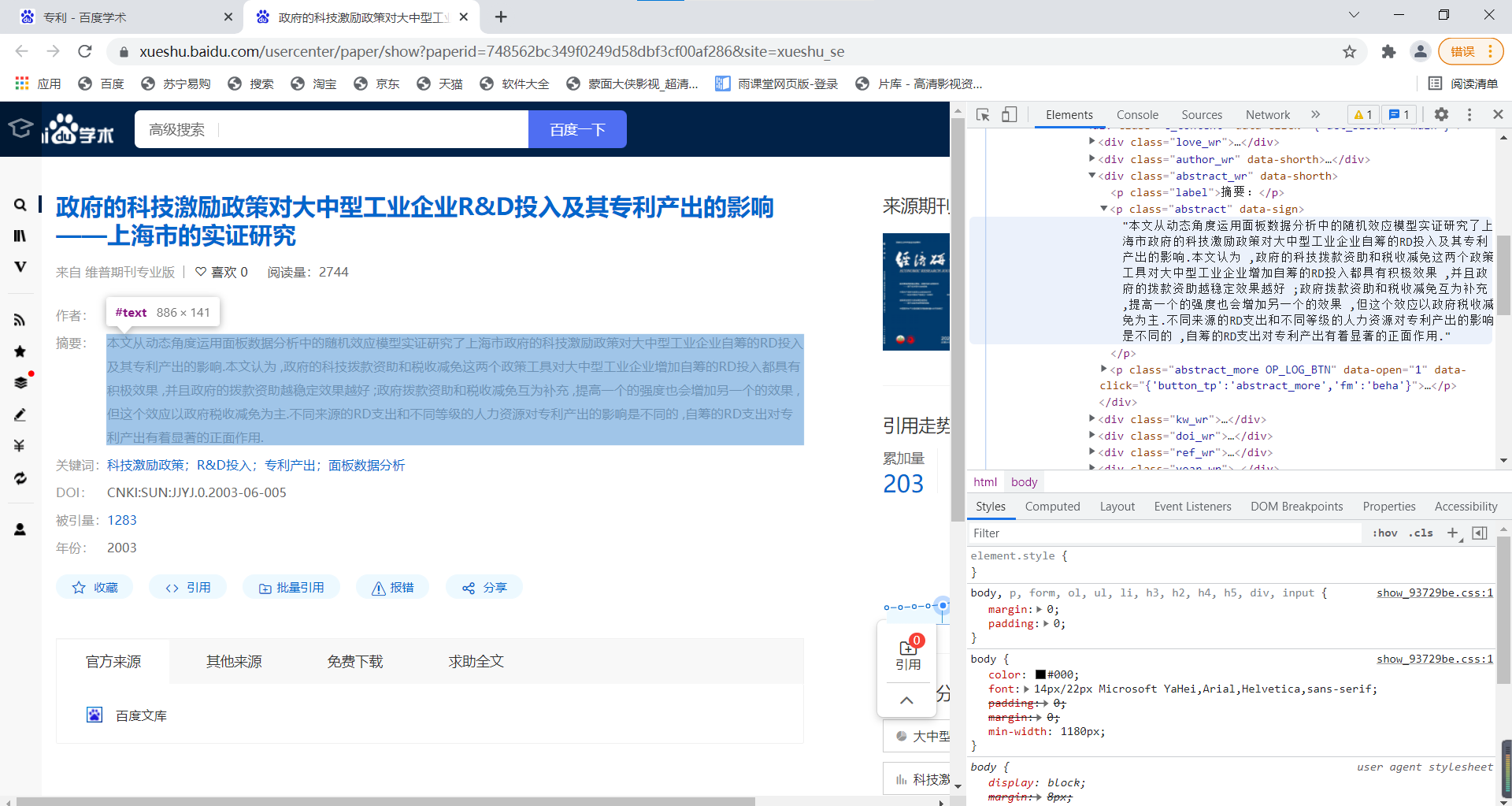
abstract = list(soup.select('div.abstract_wr p.abstract')[0].stripped_strings)[0].replace("\u3000", ' ')
except(IndexError):
abstract = ''
# Extract keywords
try:
key_words = ';'.join(key_word for key_word in list(soup.select('div.dtl_search_word > div')[0].stripped_strings)[1:-1:2])
except(IndexError):
key_words = ''
# data = {
# "title":title,
# "abstract":abstract,
# "key_words":key_words
# }
return title, abstract, key_wordsSo far, the third function analysis is completed
The following three functions are relatively simple. Let's briefly talk about them here
(4) def get_all_data(urls_list):
This function is mainly used to filter the crawled data and store the data whose three items are not empty in the dictionary
dit = defaultdict(list)
for url in urls_list:
title,abstract, key_words = get_item_info(url)
if (len(str(title)) > 0 and len(str(abstract)) > 0 and len(str(key_words)) > 0):
dit["title"].append(title)
dit["abstract"].append(abstract)
dit["key_words"].append(key_words)
return ditSo far, the fourth function analysis is completed
(5) def save_csv(dit,num):
This function is used to save the previously filtered data stored in the dictionary to the local csv file. The if statement is used to simply process the header
data = pd.DataFrame(dit)
columns = ["title", "abstract", "key_words"]
if num == 1:
data.to_csv("data.csv", mode='a',index=False, columns=columns)
else:
data.to_csv("data.csv", mode='a', index=False , header=False)
print("That's OK!")So far, the fifth function analysis is completed
(6) main function
The main function is responsible for looping each keyword in the given keyword list and calling the above functions. Each keyword is stored in about 300 pieces of data. Here are two keywords as examples
key_words=["patent","Beef quality"]
num=1
for key_word in key_words:
soup = driver_open(key_word)
urls_list = page_url_list(soup, page=100)
dit = get_all_data(urls_list)
save_csv(dit,num)
num+=1So far, the analysis of the crawler code is completed
2, Data set status

There are more than 5000 in total, meeting the requirements
summary
The above is the analysis of the crawler code in task 1. The next blog will conduct statistical analysis on the data set