Students who often pay attention to the latest developments in the academic community may be very familiar with arXiv. It is the largest academic open sharing platform in the world. At present, nearly 2 million academic articles in 8 disciplines are stored [1]. Scholars often hang their upcoming articles on arXiv for peer review, which greatly promotes the openness and collaboration of the academic community.
Many articles dazzle people and make people unable to get articles in their areas of concern immediately. The author recently used arXiv API[2] + Github Actions[3] to automatically obtain relevant topic articles from arXiv and publish them on Github and Github Page every day. Click preview here.
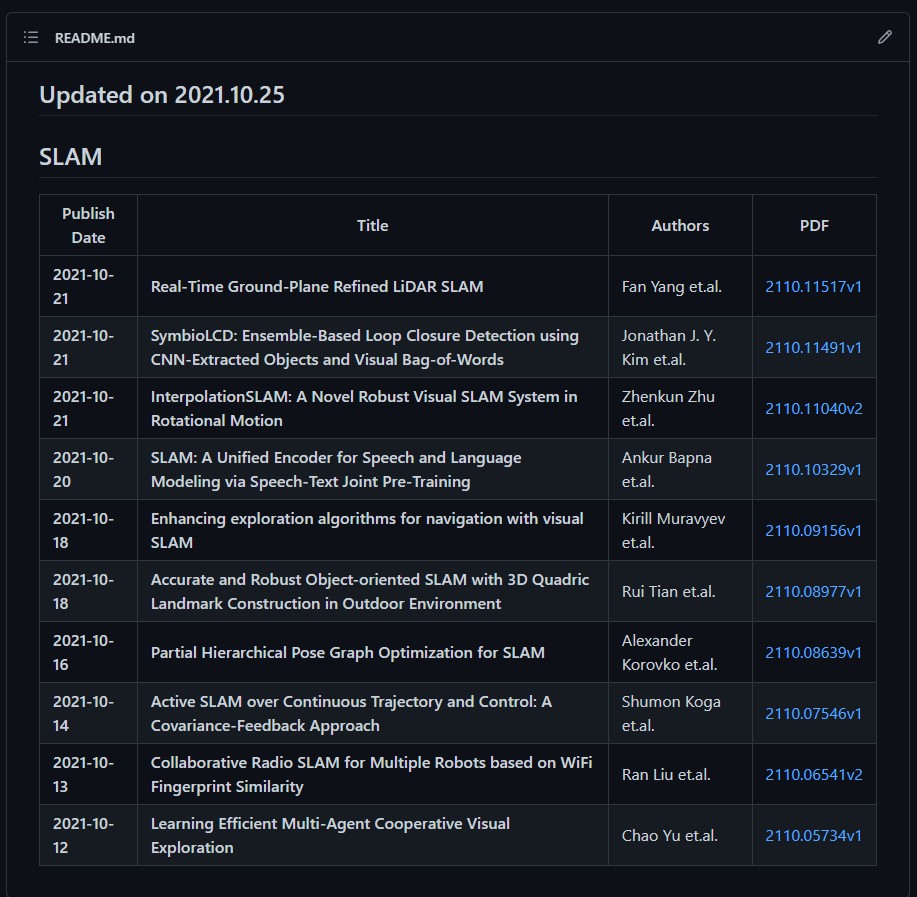
First, a preview is given. Github's README.md lists the latest articles on SLAM in the form of a table, which looks clear at a glance.
Introduction to arXiv API
Basic grammar
The arXiv API[2] allows users to programmatically access millions of electronic papers hosted on arXiv.org. The user manual of arXiv API[2] provides the basic syntax of paper retrieval. According to the syntax provided, the corresponding paper can be retrieved metadata , that is, metadata, including thesis title, author, abstract, comments and other information. The format of API call is as follows:
http://export.arxiv.org/api/{method_name}?{parameters}
In method_name=query as an example, we want to retrieve the articles by Adrian DelMaestro, the author of the paper, and the title of the paper contains checkerboard, which can be written as follows:
http://export.arxiv.org/api/query?search_query=au:del_maestro+AND+ti:checkerboard
Where the prefix au represents author, ti represents Title, and + is the encoding of spaces (because spaces cannot appear in the url).
| prefix | explanation |
|---|---|
| ti | Title |
| au | Author |
| abs | Abstract |
| co | Comment |
| jr | Journal Reference |
| cat | Subject Category |
| rn | Report Number |
| id | Id (use id_list instead) |
| all | All of the above |
In addition, AND represents AND operation. The query method of API supports Boolean operations: AND, OR AND ANDNOT.
The above search results are returned in the form of Atom feeds. Any language that can make HTTP requests and parse Atom feeds can call this API. Take Python as an example:
import urllib.request as libreq
with libreq.urlopen('http://export.arxiv.org/api/query?search_query=au:del_maestro+AND+ti:checkerboard') as url:
r = url.read()
print(r)
The printed result contains the metadata of the paper, so the next task is to parse the data and write down the information we pay attention to in a certain format.
arxiv.py ox knife
Someone has helped us to analyze the above results. We don't have to build wheels again. Of course, the way of paper query is also more elegant. Here we recommend arxiv.py[5].
Install arxiv.py first:
pip install arxiv
Then import arxiv in the Python script.
Taking the search SLAM as the keyword, it is required to return 10 results and sort them according to the release date. The script is as follows:
import arxiv search = arxiv.Search( query = "SLAM", max_results = 10, sort_by = arxiv.SortCriterion.SubmittedDate ) for result in search.results(): print(result.entry_id, '->', result.title)
In the above script, the (Search).results() function returns the metadata of the paper. arxiv.py has been parsed for us. We can directly call elements such as result.title, similar to:
| element | explanation |
|---|---|
| entry_id | A url http://arxiv.org/abs/{id}. |
| updated | When the result was last updated. |
| published | When the result was originally published. |
| title | The title of the result. |
| authors | The result's authors, as arxiv.Authors. |
| summary | The result abstract. |
| comment | The authors' comment if present. |
| journal_ref | A journal reference if present. |
| doi | A URL for the resolved DOI to an external resource if present. |
| primary_category | The result's primary arXiv category. See arXiv: Category Taxonomy[4]. |
| categories | All of the result's categories. See arXiv: Category Taxonomy. |
| links | Up to three URLs associated with this result, as arxiv.Links. |
| pdf_url | A URL for the result's PDF if present. Note: this URL also appears among result.links. |
The above search script prints the following results on the terminal:
http://arxiv.org/abs/2110.11040v1 -> InterpolationSLAM: A Novel Robust Visual SLAM System in Rotational Motion http://arxiv.org/abs/2110.10329v1 -> SLAM: A Unified Encoder for Speech and Language Modeling via Speech-Text Joint Pre-Training http://arxiv.org/abs/2110.09156v1 -> Enhancing exploration algorithms for navigation with visual SLAM http://arxiv.org/abs/2110.08977v1 -> Accurate and Robust Object-oriented SLAM with 3D Quadric Landmark Construction in Outdoor Environment http://arxiv.org/abs/2110.08639v1 -> Partial Hierarchical Pose Graph Optimization for SLAM http://arxiv.org/abs/2110.07546v1 -> Active SLAM over Continuous Trajectory and Control: A Covariance-Feedback Approach http://arxiv.org/abs/2110.06541v2 -> Collaborative Radio SLAM for Multiple Robots based on WiFi Fingerprint Similarity http://arxiv.org/abs/2110.05734v1 -> Learning Efficient Multi-Agent Cooperative Visual Exploration http://arxiv.org/abs/2110.03234v1 -> Self-Supervised Depth Completion for Active Stereo http://arxiv.org/abs/2110.02593v1 -> InterpolationSLAM: A Novel Robust Visual SLAM System in Rotating Scenes
Next script daily_arxiv.py The paper on SLAM will be obtained from arXiv, and the release time, paper name, author, code and other information of the paper will be made into a Markdown table and written as README.md file.
import datetime
import requests
import json
import arxiv
import os
def get_authors(authors, first_author = False):
output = str()
if first_author == False:
output = ", ".join(str(author) for author in authors)
else:
output = authors[0]
return output
def sort_papers(papers):
output = dict()
keys = list(papers.keys())
keys.sort(reverse=True)
for key in keys:
output[key] = papers[key]
return output
def get_daily_papers(topic,query="slam", max_results=2):
"""
@param topic: str
@param query: str
@return paper_with_code: dict
"""
# output
content = dict()
search_engine = arxiv.Search(
query = query,
max_results = max_results,
sort_by = arxiv.SortCriterion.SubmittedDate
)
for result in search_engine.results():
paper_id = result.get_short_id()
paper_title = result.title
paper_url = result.entry_id
paper_abstract = result.summary.replace("\n"," ")
paper_authors = get_authors(result.authors)
paper_first_author = get_authors(result.authors,first_author = True)
primary_category = result.primary_category
publish_time = result.published.date()
print("Time = ", publish_time ,
" title = ", paper_title,
" author = ", paper_first_author)
# eg: 2108.09112v1 -> 2108.09112
ver_pos = paper_id.find('v')
if ver_pos == -1:
paper_key = paper_id
else:
paper_key = paper_id[0:ver_pos]
content[paper_key] = f"|**{publish_time}**|**{paper_title}**|{paper_first_author} et.al.|[{paper_id}]({paper_url})|\n"
data = {topic:content}
return data
def update_json_file(filename,data_all):
with open(filename,"r") as f:
content = f.read()
if not content:
m = {}
else:
m = json.loads(content)
json_data = m.copy()
# update papers in each keywords
for data in data_all:
for keyword in data.keys():
papers = data[keyword]
if keyword in json_data.keys():
json_data[keyword].update(papers)
else:
json_data[keyword] = papers
with open(filename,"w") as f:
json.dump(json_data,f)
def json_to_md(filename):
"""
@param filename: str
@return None
"""
DateNow = datetime.date.today()
DateNow = str(DateNow)
DateNow = DateNow.replace('-','.')
with open(filename,"r") as f:
content = f.read()
if not content:
data = {}
else:
data = json.loads(content)
md_filename = "README.md"
# clean README.md if daily already exist else create it
with open(md_filename,"w+") as f:
pass
# write data into README.md
with open(md_filename,"a+") as f:
f.write("## Updated on " + DateNow + "\n\n")
for keyword in data.keys():
day_content = data[keyword]
if not day_content:
continue
# the head of each part
f.write(f"## {keyword}\n\n")
f.write("|Publish Date|Title|Authors|PDF|\n" + "|---|---|---|---|\n")
# sort papers by date
day_content = sort_papers(day_content)
for _,v in day_content.items():
if v is not None:
f.write(v)
f.write(f"\n")
print("finished")
if __name__ == "__main__":
data_collector = []
keywords = dict()
keywords["SLAM"] = "SLAM"
for topic,keyword in keywords.items():
print("Keyword: " + topic)
data = get_daily_papers(topic, query = keyword, max_results = 10)
data_collector.append(data)
print("\n")
# update README.md file
json_file = "cv-arxiv-daily.json"
if ~os.path.exists(json_file):
with open(json_file,'w')as a:
print("create " + json_file)
# update json data
update_json_file(json_file,data_collector)
# json data to markdown
json_to_md(json_file)
The key points of the above script are:
- The retrieved topics and keywords are SLAM, and the latest 10 articles are returned;
- Note that the above topic is used as the name of the first two-level title of the table, and the keyword is the real content to be retrieved. Pay special attention to the multi search format for keywords with spaces, such as "camera Localization", in which the "table" is escaped. You can add the keywords you are interested in according to the rules;
- The list of papers is sorted according to the time published on arXiv, and the latest ones are at the top;
This seems to have been completed, but there are two problems: 1. It must be run manually every time it is used; 2. It can only be viewed locally. Github Actions comes in handy in order to automatically run the above scripts every day and synchronize them in Github warehouse.
Introduction to Github Actions
Once again, our goal is to use GitHub Actions to automatically obtain the papers on SLAM from arXiv every day, and make the release time, title, author, code and other information of the papers into a Markdown table and publish them on Github.
What is Github Actions?
Github Actions is a continuous integration service of GitHub, which was launched in October 2018.
The following is the official interpretation [3]:
GitHub Actions help you automate tasks within your software development life cycle. GitHub Actions are event-driven, meaning that you can run a series of commands after a specified event has occurred. For example, every time someone creates a pull request for a repository, you can automatically run a command that executes a software testing script.
In short, GitHub Actions is driven by Events to automate tasks.
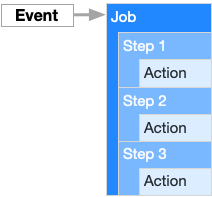
Basic concepts
GitHub Actions has its own terms [10], [9].
- Workflow: the process of continuously integrating one operation is a workflow;
- job: a workflow is composed of one or more jobs, which means that a continuous integration run can complete multiple tasks;
- Step: each job consists of multiple steps, which are completed step by step;
- action: each step can execute one or more commands (actions) in turn;
deploy
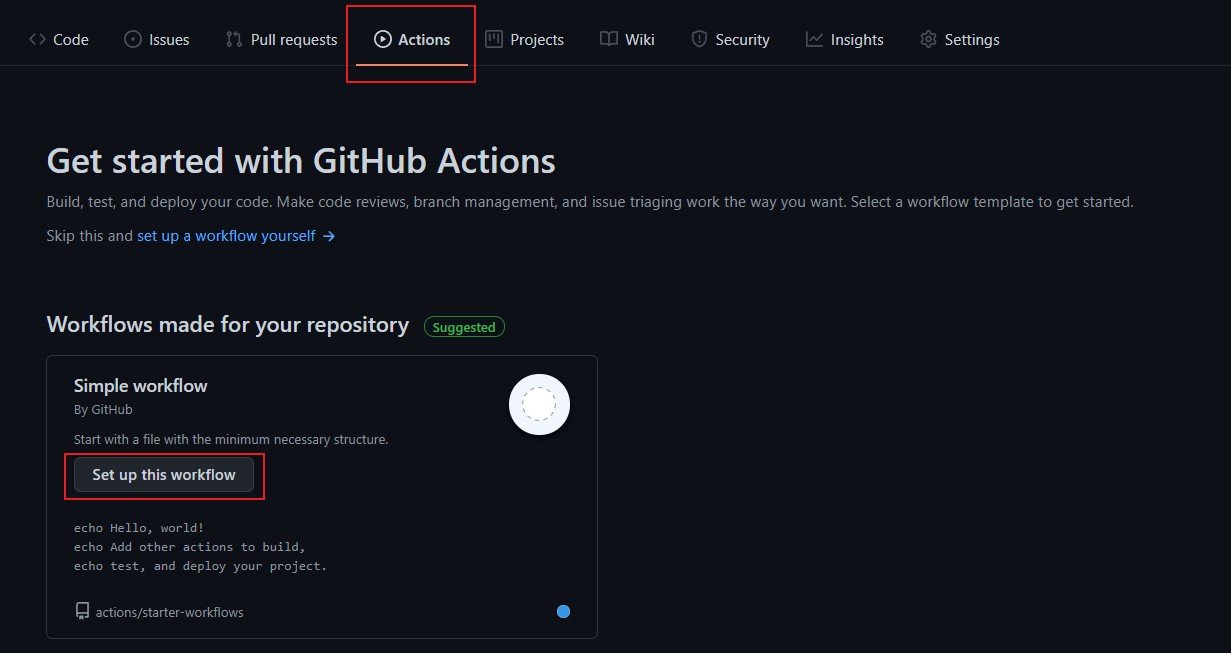
Log in to your Github account, create a new warehouse, such as CV arXiv daily, click Actions, and then click Set up this workflow, as shown in the following figure:
After the above steps, a new file named black.yml will be created (as shown in the figure below). Its directory is. github/workflows /. Note that this directory cannot be changed. The workflow to be executed, that is, workflow, is stored in this folder. GitHub Actions will automatically identify the YML workflow file in this folder and execute it according to the rules.
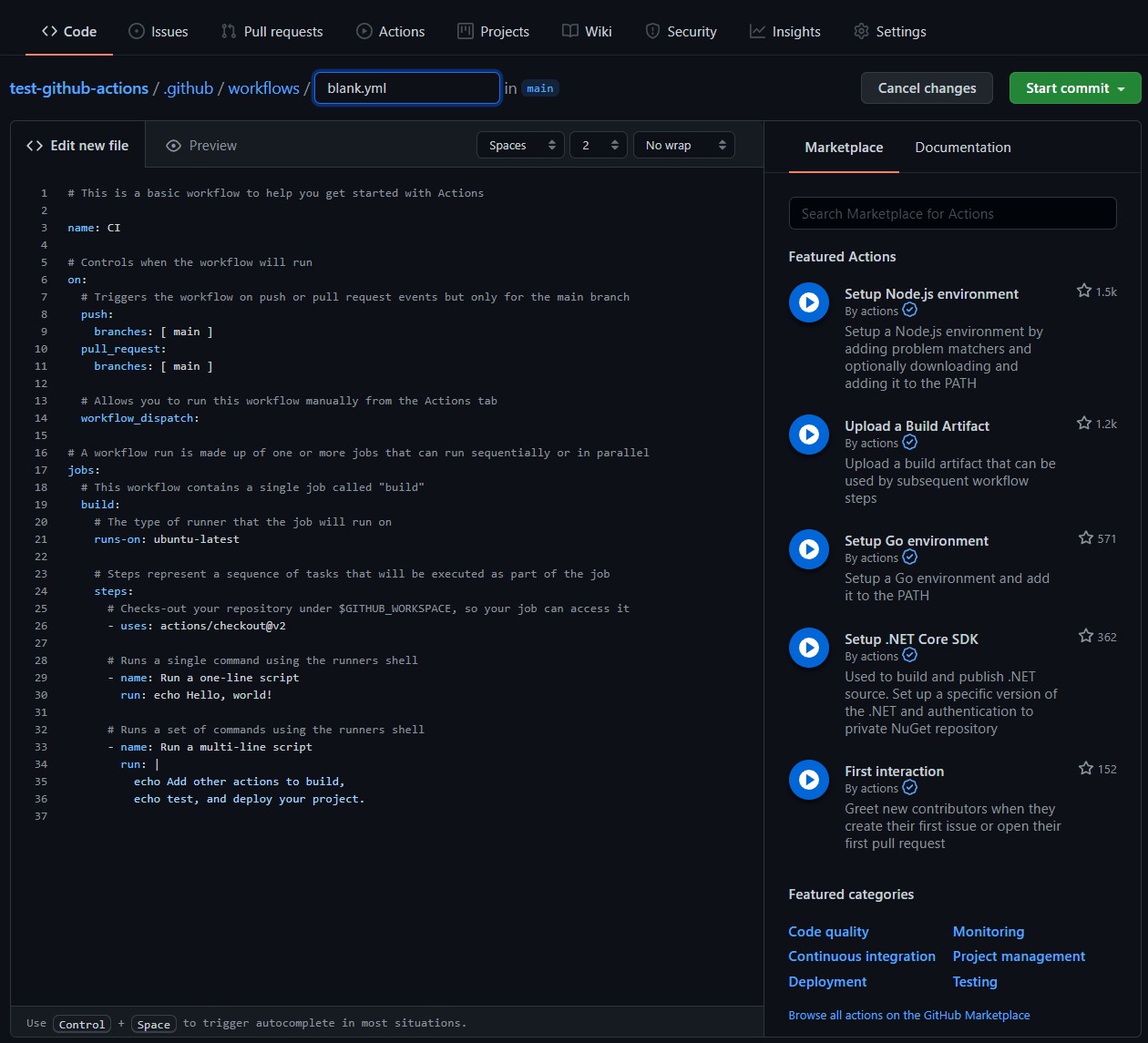
This black.yml implements the simplest workflow: print Hello, world!.
It should be noted that GitHub Actions workflow has its own set of syntax. Due to space constraints, it will not be described in detail here. For details, please refer to [9].
In order to implement the python script in the previous section daily_arxiv.py Automatically run, it is not difficult to get the following workflow configuration cv-arxiv-daily.yml Note that the two environment variables GITHUB_USER_NAME and GITHUB_USER_EMAIL are replaced with their own ID and mailbox respectively.
# name of workflow
name: Run Arxiv Papers Daily
# Controls when the workflow will run
on:
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
schedule:
- cron: "* 12 * * *" # Runs every minute of 12th hour
env:
GITHUB_USER_NAME: xxx # your github id
GITHUB_USER_EMAIL: xxx # your email address
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
name: update
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Set up Python Env
uses: actions/setup-python@v1
with:
python-version: 3.6
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install arxiv
pip install requests
- name: Run daily arxiv
run: |
python daily_arxiv.py
- name: Push new cv-arxiv-daily.md
uses: github-actions-x/commit@v2.8
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
commit-message: "Github Action Automatic Update CV Arxiv Papers"
files: README.md cv-arxiv-daily.json
rebase: 'true'
name: ${{ env.GITHUB_USER_NAME }}
email: ${{ env.GITHUB_USER_EMAIL }}
Among them, workflow_dispatch means that users can run by clicking manually, and schedule[7] means regular execution. Please check the specific rules Events that trigger workflows.
Used here cron It has five fields separated by spaces, as follows:
┌───────────── minute (0 - 59) │ ┌───────────── hour (0 - 23) │ │ ┌───────────── day of the month (1 - 31) │ │ │ ┌───────────── month (1 - 12 or JAN-DEC) │ │ │ │ ┌───────────── day of the week (0 - 6 or SUN-SAT) │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * * * * *
Supplementary syntax:
| Operator | Description | Example |
|---|---|---|
| * | Any value | * * * * * runs every minute of every day. |
| , | Value list separator | 2,10 4,5 * * * runs at minute 2 and 10 of the 4th and 5th hour of every day. |
| - | Range of values | 0 4-6 * * * runs at minute 0 of the 4th, 5th, and 6th hour. |
| / | Step values | 20/15 * * * * runs every 15 minutes starting from minute 20 through 59 (minutes 20, 35, and 50). |
The key points of the above workflow are summarized as follows:
- The event is triggered at 12:00 UTC time every day. The workflow is run and the push is not triggered;
- There is only one job named build, which runs in the virtual machine environment Ubuntu latest;
- The first step is to obtain the source code, and the actions used are actions/checkout@v2 ;
- The second step is to configure the python environment. The actions used are actions/setup-python@v1 , python version is 3.6;
- The third step is to install the dependent library, upgrade pip, install arxiv.py library and requests library respectively;
- The fourth step is to run the daily_arxiv.py script, which generates the json temporary file and the corresponding README.md;
- The fifth step is to push the code to the warehouse. The action used is github-actions-x/commit@v2.8[11] , the parameters to be configured include commit message to be submitted, files to be submitted, Github user name and email;
After the workflow is successfully deployed, a json file and README.md file will be generated under Github repo. At the same time, you will see the article list at the beginning of this article. The log in the background of Github Action is as follows:
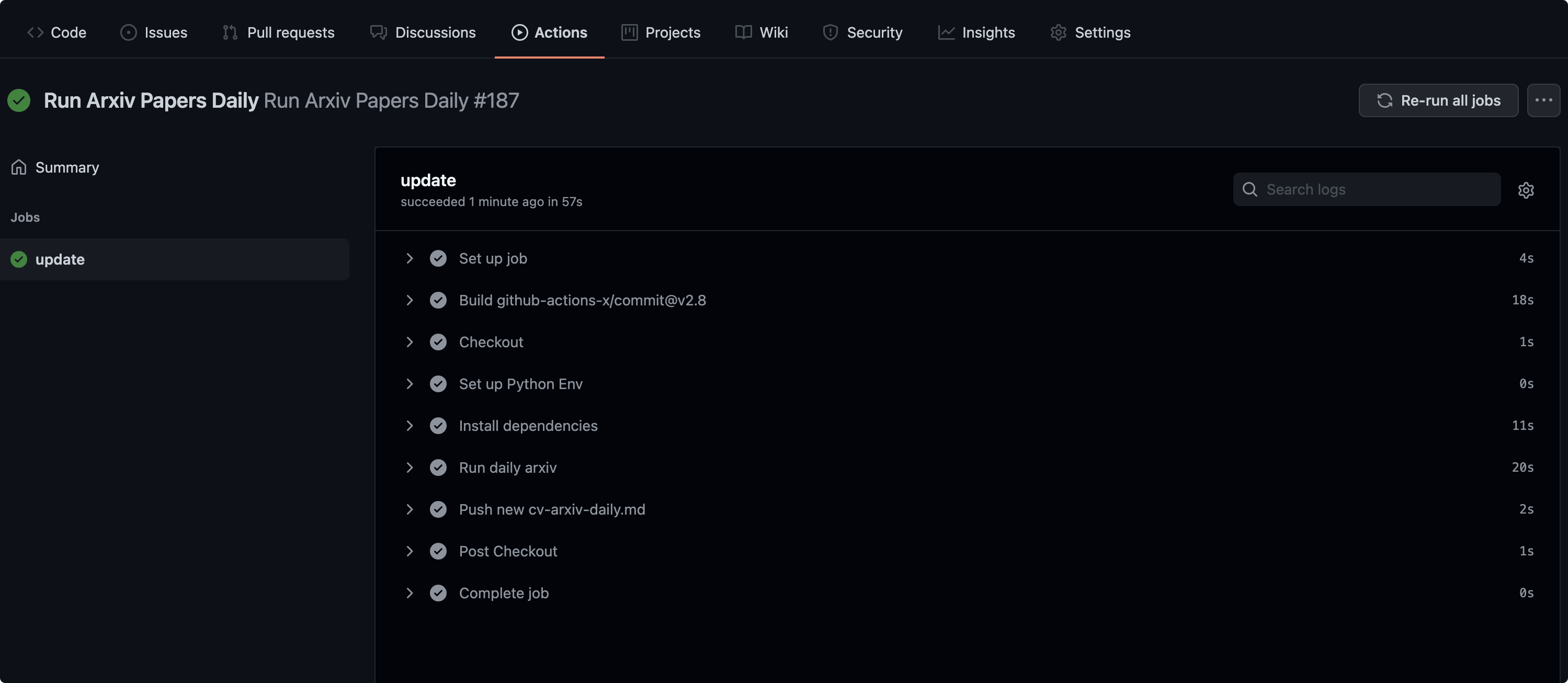
summary
This paper introduces a method of automatically obtaining arXiv papers every day using Github Actions, which can easily obtain and preview the latest articles of interest. The examples listed in this article are more convenient to modify. Readers can select topics of interest by adding keywords. All the code in the article has been open source. See the end of the article for the address. The latest code adds the function of obtaining arXiv paper source code, adding several keywords and the function of automatically deploying to a Github Page.
In addition, the methods listed in this paper have several problems: 1. The generated json file is a temporary file, which can be deleted optimally; 2. The size of readme.md file will gradually increase over time, and the archiving function can be added later; 3. Not everyone will browse Github every day. In the future, the function of sending articles to the mailbox will be added.
Welcome to fork & star to create your own paper weapon:)
code: github.com/Vincentqyw/cv-arxiv-daily
Welcome to fork & star to create your own paper weapon:)

reference resources
[1]: About arXiv, https://arxiv.org/about
[2]: arXiv API User's Manual, https://arxiv.org/help/api/user-manual
[3]: Github Actions: https://docs.github.com/en/actions/learn-github-actions
[4]: arXiv Category Taxonomy: https://arxiv.org/category_taxonomy
[5]: Python wrapper for the arXiv API, https://github.com/lukasschwab/arxiv.py
[6]: Full package documentation: arxiv.arxiv, http://lukasschwab.me/arxiv.py/index.html
[7]: Github Actions on.schedule: https://docs.github.com/en/actions/learn-github-actions/workflow-syntax-for-github-actions#onschedule
[8]: Github Actions Events that trigger workflows: https://docs.github.com/en/actions/learn-github-actions/events-that-trigger-workflows#scheduled-events
[9]: Workflow syntax for GitHub Actions, https://docs.github.com/en/actions/learn-github-actions/workflow-syntax-for-github-actions
[10]: GitHub Actions Getting Started tutorial, http://www.ruanyifeng.com/blog/2019/09/getting-started-with-github-actions.html
[11]: Git commit and push, https://github.com/github-actions-x/commit
[12]: Generate a list of papers daily arxiv, https://github.com/zhuwenxing/daily_arxiv