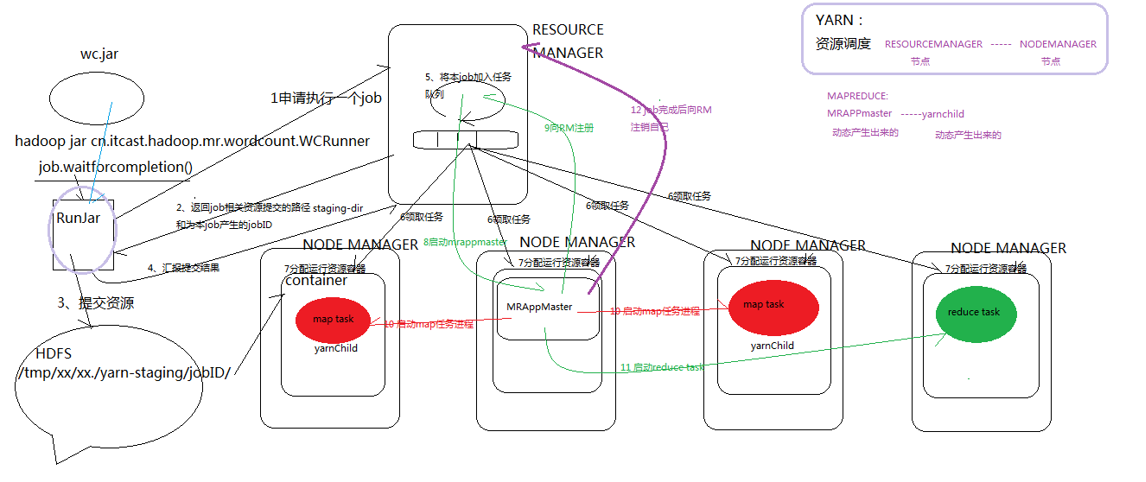
job submission process - supplemental
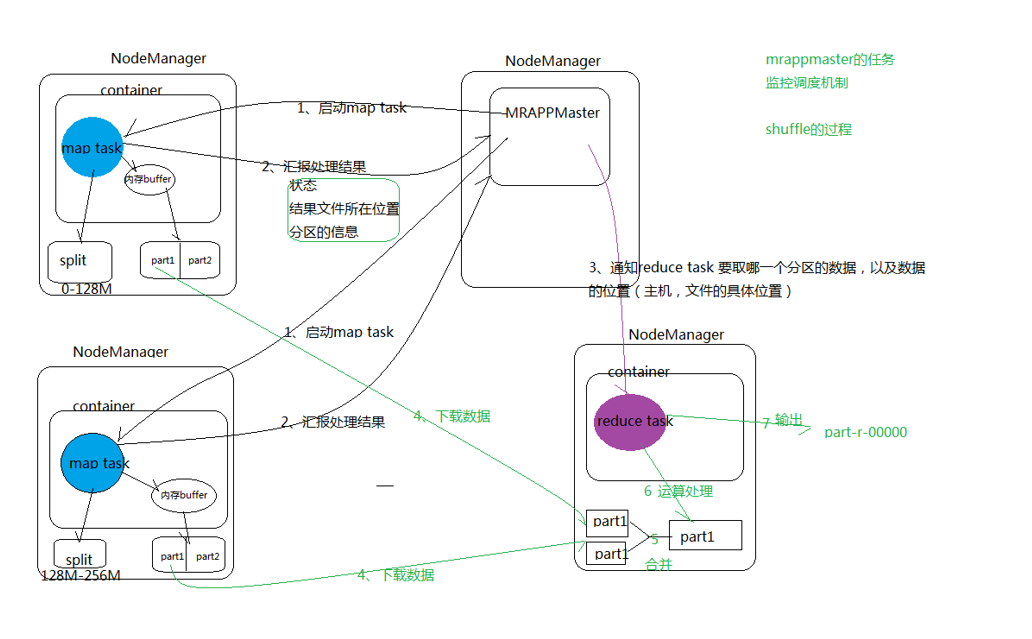
map task returns the processing result to MRAPPmaster
reduce task combines the map processing results, processes the operations, and then outputs them
1. Steps to realize Zoning:
1.1 First analyze the specific business logic to determine how many partitions there are 1.2 First write a class that inherits org.apache.hadoop.mapreduce.Partitioner This class 1.3 rewrite public int getPartition This method reads the database or returns the same number according to the specific logic 1.4 stay main Set in method Partioner Class, job.setPartitionerClass(DataPartitioner.class); 1.5 set up Reducer Number of, job.setNumReduceTasks(6);
AreaPartitioner extends Partitioner<KEY, VALUE>
int getPartition()
package cn.itcast.hadoop.mr.areapartition;
import java.util.HashMap;
import org.apache.hadoop.mapreduce.Partitioner;
public class AreaPartitioner<KEY, VALUE> extends Partitioner<KEY, VALUE>{
private static HashMap<String,Integer> areaMap = new HashMap<>();
static{
areaMap.put("135", 0);
areaMap.put("136", 1);
areaMap.put("137", 2);
areaMap.put("138", 3);
areaMap.put("139", 4);
}
@Override
public int getPartition(KEY key, VALUE value, int numPartitions) {
//Get the mobile phone number from the key, query the mobile phone ownership dictionary, and return different group numbers for different provinces
int areaCoder = areaMap.get(key.toString().substring(0, 3))==null?5:areaMap.get(key.toString().substring(0, 3));
return areaCoder;
}
}
FlowSumArea- FlowSumAreaMapper/FlowSumAreaReducer/main
main
//Set our custom grouping logic definition
job.setPartitionerClass(AreaPartitioner.class);
package cn.itcast.hadoop.mr.areapartition;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.itcast.hadoop.mr.flowsum.FlowBean;
/**
* Carry out traffic statistics on the original traffic log, and output the user statistics results of different provinces to different files
* Two mechanisms need to be customized:
* 1,Transform the partition logic and customize a partitioner
* 2,Number of concurrent tasks of custom reduer task
*
* @author duanhaitao@itcast.cn
*
*/
public class FlowSumArea {
public static class FlowSumAreaMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//Take a row of data
String line = value.toString();
//Cut into fields
String[] fields = StringUtils.split(line, "\t");
//Get the fields we need
String phoneNB = fields[1];
long u_flow = Long.parseLong(fields[7]);
long d_flow = Long.parseLong(fields[8]);
//The encapsulated data is kv and output
context.write(new Text(phoneNB), new FlowBean(phoneNB,u_flow,d_flow));
}
}
public static class FlowSumAreaReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
@Override
protected void reduce(Text key, Iterable<FlowBean> values,Context context)
throws IOException, InterruptedException {
long up_flow_counter = 0;
long d_flow_counter = 0;
for(FlowBean bean: values){
up_flow_counter += bean.getUp_flow();
d_flow_counter += bean.getD_flow();
}
context.write(key, new FlowBean(key.toString(), up_flow_counter, d_flow_counter));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowSumArea.class);
job.setMapperClass(FlowSumAreaMapper.class);
job.setReducerClass(FlowSumAreaReducer.class);
//Set our custom grouping logic definition
job.setPartitionerClass(AreaPartitioner.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//Set the number of concurrent tasks in reduce, which should be consistent with the number of groups
job.setNumReduceTasks(1);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
2. Sorting
MR is sorted by key2 by default. If you want to customize the sorting rules, the sorted objects should implement the WritableComparable interface, implement the sorting rules in the compareTo method, and then use this object as a key to complete the sorting
input
FlowBean implements WritableComparable
FlowBean {phoneNB,up_flow,d_flow}
@Override
public int compareTo(FlowBean o) {
return s_flow>o.getS_flow()?-1:1;
}
package cn.itcast.hadoop.mr.flowsum,times);
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable<FlowBean>{
private String phoneNB;
private long up_flow;
private long d_flow;
private long s_flow;
private long times;
//During deserialization, the reflection mechanism needs to call the empty parameter constructor, so the display defines an empty parameter constructor
public FlowBean(){}
//For the convenience of object data initialization, a constructor with parameters is added
public FlowBean(String phoneNB, long up_flow, long d_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.s_flow = up_flow + d_flow;
}
public void set(String phoneNB, long up_flow, long d_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.s_flow = up_flow + d_flow;
}
public String getPhoneNB() {
return phoneNB;
}
public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
}
public long getUp_flow() {
return up_flow;
}
public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
}
public long getD_flow() {
return d_flow;
}
public void setD_flow(long d_flow) {
this.d_flow = d_flow;
}
public long getS_flow() {
return s_flow;
}
public void setS_flow(long s_flow) {
this.s_flow = s_flow;
}
public long getTimes() {
return times;
}
public void setTimes(long times) {
this.times = times;
}
//Serialize object data into a stream
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(d_flow);
out.writeLong(s_flow);
}
//Lists the data of objects in reverse order from the data flow
//When reading object fields from the data stream, they must be in the same order as when serializing
@Override
public void readFields(DataInput in) throws IOException {
phoneNB = in.readUTF();
up_flow = in.readLong();
d_flow = in.readLong();
s_flow = in.readLong();
}
@Override
public String toString() {
return "" + up_flow + "\t" +d_flow + "\t" + s_flow;
}
@Override
public int compareTo(FlowBean o) {
return s_flow>o.getS_flow()?-1:1;
}
}
SortMRmain() ,classSortMapper ,SortReducer
class SortMR {
classSortMapper extends Mapper<LongWritable, Text, FlowBean, NullWritable>{}
SortReducer extends Reducer<FlowBean, NullWritable, Text, FlowBean>{}
main(String[] args) throws Exception {
}
package cn.itcast.hadoop.mr.flowsort;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.RecordReader;
import org.apache.hadoop.mapred.RecordWriter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.itcast.hadoop.mr.flowsum.FlowBean;
public class SortMR {
public static class SortMapper extends Mapper<LongWritable, Text, FlowBean, NullWritable>{
//Get a row of data, cut out each field, package it into a flow bean and output it as a key
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
String phoneNB = fields[0];
long u_flow = Long.parseLong(fields[1]);
long d_flow = Long.parseLong(fields[2]);
context.write(new FlowBean(phoneNB, u_flow, d_flow), NullWritable.get());
}
}
public static class SortReducer extends Reducer<FlowBean, NullWritable, Text, FlowBean>{
@Override
protected void reduce(FlowBean key, Iterable<NullWritable> values,Context context)
throws IOException, InterruptedException {
String phoneNB = key.getPhoneNB();
context.write(new Text(phoneNB), key);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SortMR.class);
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//RecordReader<K, V>
//org.apache.hadoop.mapreduce.RecordWriter<K, V>
System.exit(job.waitForCompletion(true)?0:1);
}
}
3. Function of combiner
This is to merge the output on the map side first to reduce the amount of data transmitted to the reducer.
4.MR startup process
start-mapred.sh --> hadoop-daemon.sh --> hadoop --> org.apache.hadoop.mapred.JobTracker Jobtracker Call order: main --> startTracker --> new JobTracker In its construction method, first create a scheduler, and then create a RPC of server(interTrackerServer)tasktracker Will pass PRC Mechanism and its communication
Then we call the offerService method to provide services externally, start RPC server in the offerService method, initialize jobtracker, invoke the start method of taskScheduler - > eagerTaskInitializationListener calling start method.
> > calling the start method of jobInitManagerThread, because it is a thread, calling the run method of JobInitManager -- > jobInitQueue task queue to get the first task, then dropping it into the thread pool, then invoking the run method of >InitJob.
– > initJob method of jobtracker -- > inittasks of jobinprogress -- > maps = new taskinprogress [nummaptasks] and reduces = new TaskInProgress[numReduceTasks];
TaskTracker Call order: main --> new TaskTracker It is called in its construction method. initialize Method, in initialize Call in method RPC.waitForProxy Get one jobtracker Proxy object for
Then tasktracker calls its own run method, – > offerservice method -- > the return value of transmittheartbeat is (HeartbeatResponse) is the instruction of jobTracker. In the transmittheartbeat method, InterTrackerProtocol calls heartbeat to send the status of tasktracker to jobTracker through RPC mechanism, and the return value is the instruction of jobTracker
heartbeatResponse.getActions() gets the specific instruction, then judges the specific type of the instruction and starts to execute the task
The addtotasqueue startup type instruction is added to the queue, and the TaskLauncher adds the task to the task queue. – > TaskLauncher's run method -- > startnewtask method -- > localizejob downloads resources -- > launchtaskforjob starts loading tasks -- > launchtask -- > runner. Start() starts the thread; -- > Taskrunner calls the run method -- > launchjvmandwait to start the java child process
5 inverted index
Input preparation 3 txt a b c
The contents of each document are as follows
a.txt
hello tom
hello jerry
hello tom
b.txt
hello jerry
hello jerry
tom jerry
c.txt
hello jerry
hello tom
Inverted indexing process
The first step is to count the number of times hello appears in each file and divide it into sections
---------------------------------mapper
//context.wirte("hello->a.txt", "1")
//context.wirte("hello->a.txt", "1")
//context.wirte("hello->a.txt", "1")
<"hello->a.txt", {1,1,1}>
---------------------------------reducer
/context.write("hello", "a.txt->3")
//context.write("hello", "b.txt->2")
//context.write("hello", "c.txt->2")
The second step is to generate an index key with hello, and summarize the number of occurrences in each file
-----------------------------------------------mapper
//context.write("hello", "a.txt->3")
//context.write("hello", "b.txt->2")
//context.write("hello", "c.txt->2")
<"hello", {"a.txt->3", "b.txt->2", "c.txt->2"}>
-------------------------------- reducer
context.write("hello", "a.txt->3 b.txt->2 c.txt->2")
final result
At this time, there is no data on the number of occurrences in each document
hello a.txt->3 b.txt->2 c.txt->2
jerry a.txt->1 b.txt->3 c.txt->1
tom a.txt->2 b.txt->1 c.txt->1
When a web search engine searches hello, the display list is a/b/c
InverseIndexStepOne StepOneMapper StepOneReducer
package cn.itcast.hadoop.mr.ii;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.itcast.hadoop.mr.flowsort.SortMR;
import cn.itcast.hadoop.mr.flowsort.SortMR.SortMapper;
import cn.itcast.hadoop.mr.flowsort.SortMR.SortReducer;
import cn.itcast.hadoop.mr.flowsum.FlowBean;
/**
* Inverted index step 1 job
* @author duanhaitao@itcast.cn
*
*/
public class InverseIndexStepOne {
public static class StepOneMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//Get a row of data
String line = value.toString();
//Cut out the words
String[] fields = StringUtils.split(line, " ");
//Get the file slice where this row of data is located
FileSplit inputSplit = (FileSplit) context.getInputSplit();
//Get file name from file slice
String fileName = inputSplit.getPath().getName();
for(String field:fields){
//Encapsulate kv output, k: hello -- > a.txt V: 1
context.write(new Text(field+"-->"+fileName), new LongWritable(1));
}
}
}
public static class StepOneReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
// <hello-->a.txt,{1,1,1....}>
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Context context)
throws IOException, InterruptedException {
long counter = 0;
for(LongWritable value:values){
counter += value.get();
}
context.write(key, new LongWritable(counter));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(InverseIndexStepOne.class);
job.setMapperClass(StepOneMapper.class);
job.setReducerClass(StepOneReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
//Check whether the output path specified by the parameter exists. If it already exists, delete it first
Path output = new Path(args[1]);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)){
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
System.exit(job.waitForCompletion(true)?0:1);
}
}
StepTwoMapper StepTwoReducer
package cn.itcast.hadoop.mr.ii;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
import cn.itcast.hadoop.mr.ii.InverseIndexStepOne.StepOneMapper;
import cn.itcast.hadoop.mr.ii.InverseIndexStepOne.StepOneReducer;
public class InverseIndexStepTwo {
public static class StepTwoMapper extends Mapper<LongWritable, Text, Text, Text>{
//k: Line start offset V: {hello -- > a.txt 3}
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
String[] wordAndfileName = StringUtils.split(fields[0], "-->");
String word = wordAndfileName[0];
String fileName = wordAndfileName[1];
long count = Long.parseLong(fields[1]);
context.write(new Text(word), new Text(fileName+"-->"+count));
//The output of the map is in this form: < Hello, a.txt -- > 3 >
}
}
public static class StepTwoReducer extends Reducer<Text, Text,Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
//Obtained data < Hello, {a.txt -- > 3, b.txt -- > 2, c.txt -- > 1} >
String result = "";
for(Text value:values){
result += value + " ";
}
context.write(key, new Text(result));
//The output is K: Hello V: a.txt -- > 3 b.txt -- > 2 c.txt -- > 1
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//Construct the job first_ one
// Job job_one = Job.getInstance(conf);
//
// job_one.setJarByClass(InverseIndexStepTwo.class);
// job_one.setMapperClass(StepOneMapper.class);
// job_one.setReducerClass(StepOneReducer.class);
//......
//Construct job_two
Job job_tow = Job.getInstance(conf);
job_tow.setJarByClass(InverseIndexStepTwo.class);
job_tow.setMapperClass(StepTwoMapper.class);
job_tow.setReducerClass(StepTwoReducer.class);
job_tow.setOutputKeyClass(Text.class);
job_tow.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job_tow, new Path(args[0]));
//Check whether the output path specified by the parameter exists. If it already exists, delete it first
Path output = new Path(args[1]);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)){
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job_tow, output);
//Submit job first_ One execution
// boolean one_result = job_one.waitForCompletion(true);
// if(one_result){
System.exit(job_tow.waitForCompletion(true)?0:1);
// }
}
}