[Paddle competition] iFLYTEK title - academic paper classification challenge 0.8+Baseline
1, Project introduction
1. Project introduction:
This project is iFLYTEK title - academic paper classification challenge paddle version Baseline, with a submission score of 0.8 +. At present, there is still a large space for optimization, and more attempts can be made to improve it. Interested can also be migrated to similar text classification projects.
2. Event address: (details can be viewed on the specific competition page)
Academic paper classification challenge
3. Introduction to the competition task:
The title of the competition is a more conventional English long text classification competition. There are 5W papers in the training set. Each paper contains four fields: paper id, title, abstract and category. Test set 1W papers. Each paper contains the paper id, title and abstract, excluding the paper category field. Contestants need to use the paper information: paper id, title and abstract to divide the specific categories of papers. At the same time, a paper only belongs to one category, and there is no complex situation that a paper belongs to multiple categories. The accuracy index shall be adopted as the evaluation standard, and special attention shall be paid to the competition rules. Other data other than the data provided shall not be used.
4.Baseline idea:
This Baseline is mainly based on PaddleHub to complete the training of the paper text classification model through the fine-tuning of the pre training model on the competition data set, and finally predict the test data set, export and submit the result file to complete the competition task. Note that the code of this project needs to run in GPU environment. If the video memory is insufficient, please reduce the batchsize.
Game related data sets have been uploaded AI Studio,Search the dataset'IFLYTEK competition questions-Data set of academic paper classification challenge'Add after.
2, Data reading and processing
2.1 read data and view
# Decompress the game dataset %cd /home/aistudio/data/data100192/ !unzip data.zip
/home/aistudio/data/data100192 Archive: data.zip inflating: sample_submit.csv inflating: test.csv inflating: train.csv
# Read dataset
import pandas as pd
train = pd.read_csv('train.csv', sep='\t') # Tagged training data file
test = pd.read_csv('test.csv', sep='\t') # Test data file to predict
sub = pd.read_csv('sample_submit.csv') # Example of submission of result documents
# View the top 5 items of training data train.head()
| paperid | title | abstract | categories | |
|---|---|---|---|---|
| 0 | train_00000 | Hard but Robust, Easy but Sensitive: How Encod... | Neural machine translation (NMT) typically a... | cs.CL |
| 1 | train_00001 | An Easy-to-use Real-world Multi-objective Opti... | Although synthetic test problems are widely ... | cs.NE |
| 2 | train_00002 | Exploration of reproducibility issues in scien... | This is the first part of a small-scale expl... | cs.DL |
| 3 | train_00003 | Scheduled Sampling for Transformers | Scheduled sampling is a technique for avoidi... | cs.CL |
| 4 | train_00004 | Hybrid Forests for Left Ventricle Segmentation... | Machine learning models produce state-of-the... | cs.CV |
# View training data file information train.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 50000 entries, 0 to 49999 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 paperid 50000 non-null object 1 title 50000 non-null object 2 abstract 50000 non-null object 3 categories 50000 non-null object dtypes: object(4) memory usage: 1.5+ MB
# View the distribution of total categories in training data train['categories'].value_counts()
cs.CV 11038 cs.CL 4260 cs.NI 3218 cs.CR 2798 cs.AI 2706 cs.DS 2509 cs.DC 1994 cs.SE 1940 cs.RO 1884 cs.LO 1741 cs.LG 1352 cs.SY 1292 cs.CY 1228 cs.DB 998 cs.GT 984 cs.HC 943 cs.PL 841 cs.IR 770 cs.CC 719 cs.NE 704 cs.CG 683 cs.OH 677 cs.SI 603 cs.DL 537 cs.DM 523 cs.FL 469 cs.AR 363 cs.CE 362 cs.GR 314 cs.MM 261 cs.ET 230 cs.MA 210 cs.NA 176 cs.SC 172 cs.SD 140 cs.PF 139 cs.MS 105 cs.OS 99 cs.GL 18 Name: categories, dtype: int64
# View the top 5 test data to be predicted test.head()
| paperid | title | abstract | |
|---|---|---|---|
| 0 | test_00000 | Analyzing 2.3 Million Maven Dependencies to Re... | This paper addresses the following question:... |
| 1 | test_00001 | Finding Higher Order Mutants Using Variational... | Mutation testing is an effective but time co... |
| 2 | test_00002 | Automatic Detection of Search Tactic in Indivi... | Information seeking process is an important ... |
| 3 | test_00003 | Polygon Simplification by Minimizing Convex Co... | Let $P$ be a polygon with $r>0$ reflex verti... |
| 4 | test_00004 | Differentially passive circuits that switch an... | The concept of passivity is central to analy... |
# View test data file information test.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 10000 entries, 0 to 9999 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 paperid 10000 non-null object 1 title 10000 non-null object 2 abstract 10000 non-null object dtypes: object(3) memory usage: 234.5+ KB
2.2 data processing and division training and verification set
# Process the data set, splice the title and abstract of the paper, and process it as text_ a. Label format train['text_a'] = train['title'] + ' ' + train['abstract'] test['text_a'] = test['title'] + ' ' + test['abstract'] train['label'] = train['categories'] train = train[['text_a', 'label']]
# Check the first 5 items of processed data to see if they comply with text_ a. Label format train.head()
| text_a | label | |
|---|---|---|
| 0 | Hard but Robust, Easy but Sensitive: How Encod... | cs.CL |
| 1 | An Easy-to-use Real-world Multi-objective Opti... | cs.NE |
| 2 | Exploration of reproducibility issues in scien... | cs.DL |
| 3 | Scheduled Sampling for Transformers Schedule... | cs.CL |
| 4 | Hybrid Forests for Left Ventricle Segmentation... | cs.CV |
# Divide training and validation sets:
# 50000 labeled training data are directly divided into training and verification sets by 9:1 according to the index
train_data = train[['text_a', 'label']][:45000]
valid_data = train[['text_a', 'label']][45000:]
# Random scrambling of data
from sklearn.utils import shuffle
train_data = shuffle(train_data)
valid_data = shuffle(valid_data)
# Save training and validation set files
train_data.to_csv('train_data.csv', sep='\t', index=False)
valid_data.to_csv('valid_data.csv', sep='\t', index=False)
3, Constructing baseline model based on PaddleHub
PaddleHub can easily acquire the pre training model under the PaddlePaddle ecosystem, and complete the management of the model and the one button prediction. With the fine tune API, the migration learning can be quickly completed based on the large-scale pre training model, so that the pre training model can better serve the application of user specific scenarios.
3.1 pre environment preparation
# Download the latest version of paddlehub !pip install -U paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
# Import paddlehub and paddle packages import paddlehub as hub import paddle
3.2 selection of pre training model
# Set 39 categories requiring paper classification
label_list=list(train.label.unique())
print(label_list)
label_map = {
idx: label_text for idx, label_text in enumerate(label_list)
}
print(label_map)
['cs.CL', 'cs.NE', 'cs.DL', 'cs.CV', 'cs.LG', 'cs.DS', 'cs.IR', 'cs.RO', 'cs.DM', 'cs.CR', 'cs.AR', 'cs.NI', 'cs.AI', 'cs.SE', 'cs.CG', 'cs.LO', 'cs.SY', 'cs.GR', 'cs.PL', 'cs.SI', 'cs.OH', 'cs.HC', 'cs.MA', 'cs.GT', 'cs.ET', 'cs.FL', 'cs.CC', 'cs.DB', 'cs.DC', 'cs.CY', 'cs.CE', 'cs.MM', 'cs.NA', 'cs.PF', 'cs.OS', 'cs.SD', 'cs.SC', 'cs.MS', 'cs.GL']
{0: 'cs.CL', 1: 'cs.NE', 2: 'cs.DL', 3: 'cs.CV', 4: 'cs.LG', 5: 'cs.DS', 6: 'cs.IR', 7: 'cs.RO', 8: 'cs.DM', 9: 'cs.CR', 10: 'cs.AR', 11: 'cs.NI', 12: 'cs.AI', 13: 'cs.SE', 14: 'cs.CG', 15: 'cs.LO', 16: 'cs.SY', 17: 'cs.GR', 18: 'cs.PL', 19: 'cs.SI', 20: 'cs.OH', 21: 'cs.HC', 22: 'cs.MA', 23: 'cs.GT', 24: 'cs.ET', 25: 'cs.FL', 26: 'cs.CC', 27: 'cs.DB', 28: 'cs.DC', 29: 'cs.CY', 30: 'cs.CE', 31: 'cs.MM', 32: 'cs.NA', 33: 'cs.PF', 34: 'cs.OS', 35: 'cs.SD', 36: 'cs.SC', 37: 'cs.MS', 38: 'cs.GL'}
# Select ernie_v2_eng_large pre training model and set the fine-tuning task as 39 classification task model = hub.Module(name="ernie_v2_eng_large", task='seq-cls', num_classes=39, label_map=label_map) # In multi classification tasks, num_classes needs to explicitly specify the number of categories, which is set to 39 according to the dataset
Download https://bj.bcebos.com/paddlehub/paddlehub_dev/ernie_v2_eng_large_2.0.2.tar.gz
[##################################################] 100.00%
Decompress /home/aistudio/.paddlehub/tmp/tmp8enjb395/ernie_v2_eng_large_2.0.2.tar.gz
[##################################################] 100.00%
[2021-08-01 17:43:16,200] [ INFO] - Successfully installed ernie_v2_eng_large-2.0.2
[2021-08-01 17:43:16,203] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie_v2_large/ernie_v2_eng_large.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-2.0-large-en
[2021-08-01 17:43:16,205] [ INFO] - Downloading ernie_v2_eng_large.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie_v2_large/ernie_v2_eng_large.pdparams
100%|██████████| 1309198/1309198 [00:19<00:00, 68253.50it/s]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
The parameter usage of hub.Module is as follows:
- Name: model name. You can select ernie or ernie_tiny, Bert base cased, Bert base Chinese, Roberta WwM ext, Roberta WwM ext large, etc.
- Task: fine tune task. Here is SEQ CLS, indicating text classification task.
- num_classes: indicates the number of categories of the current text classification task. It is determined according to the specific data set used. The default is 2.
PaddleHub also provides models such as BERT to choose from. The loading examples corresponding to the models currently supporting text classification tasks are as follows:
| Model name | PaddleHub Module |
|---|---|
| ERNIE, Chinese | hub.Module(name='ernie') |
| ERNIE tiny, Chinese | hub.Module(name='ernie_tiny') |
| ERNIE 2.0 Base, English | hub.Module(name='ernie_v2_eng_base') |
| ERNIE 2.0 Large, English | hub.Module(name='ernie_v2_eng_large') |
| BERT-Base, English Cased | hub.Module(name='bert-base-cased') |
| BERT-Base, English Uncased | hub.Module(name='bert-base-uncased') |
| BERT-Large, English Cased | hub.Module(name='bert-large-cased') |
| BERT-Large, English Uncased | hub.Module(name='bert-large-uncased') |
| BERT-Base, Multilingual Cased | hub.Module(nane='bert-base-multilingual-cased') |
| BERT-Base, Multilingual Uncased | hub.Module(nane='bert-base-multilingual-uncased') |
| BERT-Base, Chinese | hub.Module(name='bert-base-chinese') |
| BERT-wwm, Chinese | hub.Module(name='chinese-bert-wwm') |
| BERT-wwm-ext, Chinese | hub.Module(name='chinese-bert-wwm-ext') |
| RoBERTa-wwm-ext, Chinese | hub.Module(name='roberta-wwm-ext') |
| RoBERTa-wwm-ext-large, Chinese | hub.Module(name='roberta-wwm-ext-large') |
| RBT3, Chinese | hub.Module(name='rbt3') |
| RBTL3, Chinese | hub.Module(name='rbtl3') |
| ELECTRA-Small, English | hub.Module(name='electra-small') |
| ELECTRA-Base, English | hub.Module(name='electra-base') |
| ELECTRA-Large, English | hub.Module(name='electra-large') |
| ELECTRA-Base, Chinese | hub.Module(name='chinese-electra-base') |
| ELECTRA-Small, Chinese | hub.Module(name='chinese-electra-small') |
Through the above line of code, the model is initialized as a model suitable for text classification tasks, and a fully connected network is spliced after the pre training model of ERNIE.
3.3 loading and processing data
# The length of statistical data is convenient to determine max_seq_len
print('The maximum length of the title and summary after the splicing of the training data set is{}'.format(train['text_a'].map(lambda x:len(x)).max()))
print('The minimum length of the title and summary after the splicing of the training data set is{}'.format(train['text_a'].map(lambda x:len(x)).min()))
print('The average length of the title and summary after the splicing of the training data set is{}'.format(train['text_a'].map(lambda x:len(x)).mean()))
print('The maximum length of the title and summary after the splicing of the test data set is{}'.format(test['text_a'].map(lambda x:len(x)).max()))
print('The minimum length of the title and summary after splicing of the test data set is{}'.format(test['text_a'].map(lambda x:len(x)).min()))
print('The average length of the title and summary after the splicing of the test data set is{}'.format(test['text_a'].map(lambda x:len(x)).mean()))
The maximum length of the title and summary after the splicing of the training data set is 3713 The minimum length of the title and summary after the splicing of the training data set is 69 The average length of the title and summary after the splicing of the training data set is 1131.28478 The maximum length of the title and summary after splicing of the test data set is 3501 The minimum length of the title and summary after splicing of the test data set is 74 The average length of the title and summary after the splicing of the test data set is 1127.0977
import os, io, csv from paddlehub.datasets.base_nlp_dataset import InputExample, TextClassificationDataset # Data set storage location DATA_DIR="/home/aistudio/data/data100192/"
# Process the training data into a format acceptable to the model
class Papers(TextClassificationDataset):
def __init__(self, tokenizer, mode='train', max_seq_len=128):
if mode == 'train':
data_file = 'train_data.csv'
elif mode == 'dev':
data_file = 'valid_data.csv'
super(Papers, self).__init__(
base_path=DATA_DIR,
data_file=data_file,
tokenizer=tokenizer,
max_seq_len=max_seq_len,
mode=mode,
is_file_with_header=True,
label_list=label_list
)
# Parsing samples in text files
def _read_file(self, input_file, is_file_with_header: bool = False):
if not os.path.exists(input_file):
raise RuntimeError("The file {} is not found.".format(input_file))
else:
with io.open(input_file, "r", encoding="UTF-8") as f:
reader = csv.reader(f, delimiter="\t") # '\ t' delimited data
examples = []
seq_id = 0
header = next(reader) if is_file_with_header else None
for line in reader:
example = InputExample(guid=seq_id, text_a=line[0], label=line[1])
seq_id += 1
examples.append(example)
return examples
# Maximum sequence length max_seq_len is a parameter that can be adjusted. The recommended value is 128. This value can be adjusted according to the length of task text, but the maximum value is no more than 512. The text here is long, so it is set to 512.
train_dataset = Papers(model.get_tokenizer(), mode='train', max_seq_len=512)
dev_dataset = Papers(model.get_tokenizer(), mode='dev', max_seq_len=512)
# After processing, view the first 2 items in the data
for e in train_dataset.examples[:2]:
print(e)
for e in dev_dataset.examples[:2]:
print(e)
[2021-08-01 17:44:12,576] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie_v2_large/vocab.txt 100%|██████████| 227/227 [00:00<00:00, 2484.96it/s] [2021-08-01 17:46:28,717] [ INFO] - Found /home/aistudio/.paddlenlp/models/ernie-2.0-large-en/vocab.txt text=Enforcing Label and Intensity Consistency for IR Target Detection This study formulates the IR target detection as a binary classification problem of each pixel. Each pixel is associated with a label which indicates whether it is a target or background pixel. The optimal label set for all the pixels of an image maximizes aposteriori distribution of label configuration given the pixel intensities. The posterior probability is factored into (or proportional to) a conditional likelihood of the intensity values and a prior probability of label configuration. Each of these two probabilities are computed assuming a Markov Random Field (MRF) on both pixel intensities and their labels. In particular, this study enforces neighborhood dependency on both intensity values, by a Simultaneous Auto Regressive (SAR) model, and on labels, by an Auto-Logistic model. The parameters of these MRF models are learned from labeled examples. During testing, an MRF inference technique, namely Iterated Conditional Mode (ICM), produces the optimal label for each pixel. The detection performance is further improved by incorporating temporal information through background subtraction. High performances on benchmark datasets demonstrate effectiveness of this method for IR target detection. label=cs.CV text=Saliency Preservation in Low-Resolution Grayscale Images Visual salience detection originated over 500 million years ago and is one of nature's most efficient mechanisms. In contrast, many state-of-the-art computational saliency models are complex and inefficient. Most saliency models process high-resolution color (HC) images; however, insights into the evolutionary origins of visual salience detection suggest that achromatic low-resolution vision is essential to its speed and efficiency. Previous studies showed that low-resolution color and high-resolution grayscale images preserve saliency information. However, to our knowledge, no one has investigated whether saliency is preserved in low-resolution grayscale (LG) images. In this study, we explain the biological and computational motivation for LG, and show, through a range of human eye-tracking and computational modeling experiments, that saliency information is preserved in LG images. Moreover, we show that using LG images leads to significant speedups in model training and detection times and conclude by proposing LG images for fast and efficient salience detection. label=cs.CV text=RT-Gang: Real-Time Gang Scheduling Framework for Safety-Critical Systems In this paper, we present RT-Gang: a novel real-time gang scheduling framework that enforces a one-gang-at-a-time policy. We find that, in a multicore platform, co-scheduling multiple parallel real-time tasks would require highly pessimistic worst-case execution time (WCET) and schedulability analysis - even when there are enough cores - due to contention in shared hardware resources such as cache and DRAM controller. In RT-Gang, all threads of a parallel real-time task form a real-time gang and the scheduler globally enforces the one-gang-at-a-time scheduling policy to guarantee tight and accurate task WCET. To minimize under-utilization, we integrate a state-of-the-art memory bandwidth throttling framework to allow safe execution of best-effort tasks. Specifically, any idle cores, if exist, are used to schedule best-effort tasks but their maximum memory bandwidth usages are strictly throttled to tightly bound interference to real-time gang tasks. We implement RT-Gang in the Linux kernel and evaluate it on two representative embedded multicore platforms using both synthetic and real-world DNN workloads. The results show that RT-Gang dramatically improves system predictability and the overhead is negligible. label=cs.DC text=AI Enabling Technologies: A Survey Artificial Intelligence (AI) has the opportunity to revolutionize the way the United States Department of Defense (DoD) and Intelligence Community (IC) address the challenges of evolving threats, data deluge, and rapid courses of action. Developing an end-to-end artificial intelligence system involves parallel development of different pieces that must work together in order to provide capabilities that can be used by decision makers, warfighters and analysts. These pieces include data collection, data conditioning, algorithms, computing, robust artificial intelligence, and human-machine teaming. While much of the popular press today surrounds advances in algorithms and computing, most modern AI systems leverage advances across numerous different fields. Further, while certain components may not be as visible to end-users as others, our experience has shown that each of these interrelated components play a major role in the success or failure of an AI system. This article is meant to highlight many of these technologies that are involved in an end-to-end AI system. The goal of this article is to provide readers with an overview of terminology, technical details and recent highlights from academia, industry and government. Where possible, we indicate relevant resources that can be used for further reading and understanding. label=cs.AI
3.4 selection of optimization strategy and operation configuration
# Optimizer selection optimizer = paddle.optimizer.AdamW(learning_rate=4e-6, parameters=model.parameters()) # run setup trainer = hub.Trainer(model, optimizer, checkpoint_dir='./ckpt', use_gpu=True, use_vdl=True) # Performer of fine tune task
3.5 model training and verification
trainer.train(train_dataset, epochs=4, batch_size=12, eval_dataset=dev_dataset, save_interval=1) # Configure training parameters, start training, and specify validation sets
trainer.train mainly controls the specific training process, including the following controllable parameters:
- train_dataset: the dataset used in training;
- Epichs: number of training rounds;
- batch_size: the batch size of training. If GPU is used, please adjust the batch according to the actual situation_ size;
- num_ Workers: the number of works, which is 0 by default;
- eval_dataset: validation set;
- log_interval: the interval between printing the log, in the number of times the batch training is executed.
- save_interval: the interval frequency of saving the model. The unit is the number of rounds of training.
3.6 model prediction and saving result file
# Predict the test set
import numpy as np
# Process the input data into list format
new = pd.DataFrame(columns=['text'])
new['text'] = test["text_a"]
# First, convert the data read by pandas into array
data_array = np.array(new)
# Then it is converted to list form
data_list =data_array.tolist()
# Define categories to classify
label_list=list(train.label.unique())
label_map = {
idx: label_text for idx, label_text in enumerate(label_list)
}
# Load the trained model
model = hub.Module(
name="ernie_v2_eng_large",
version='2.0.2',
task='seq-cls',
load_checkpoint='./ckpt/best_model/model.pdparams',
num_classes=39,
label_map=label_map)
# Prediction of test set data
predictions = model.predict(data_list, max_seq_len=512, batch_size=2, use_gpu=True)
# Generate the result file to submit
sub = pd.read_csv('./sample_submit.csv')
sub['categories'] = predictions
sub.to_csv('submission.csv',index=False)
# Move the result file to the work directory for easy saving
it.csv')
sub['categories'] = predictions
sub.to_csv('submission.csv',index=False)
# Move the result file to the work directory for easy saving !cp -r /home/aistudio/data/data100192/submission.csv /home/aistudio/work/
After the prediction is completed, enter data/data100192 / on the left, download the generated result file submission.csv and submit it, with a score of 0.8 +. At present, there is still much room for improvement. Those who are interested can try more!

4, Subsequent lifting direction
-
Data enhancement attempts (synonym replacement, random insertion, random exchange, random deletion, mutual translation, etc.)
-
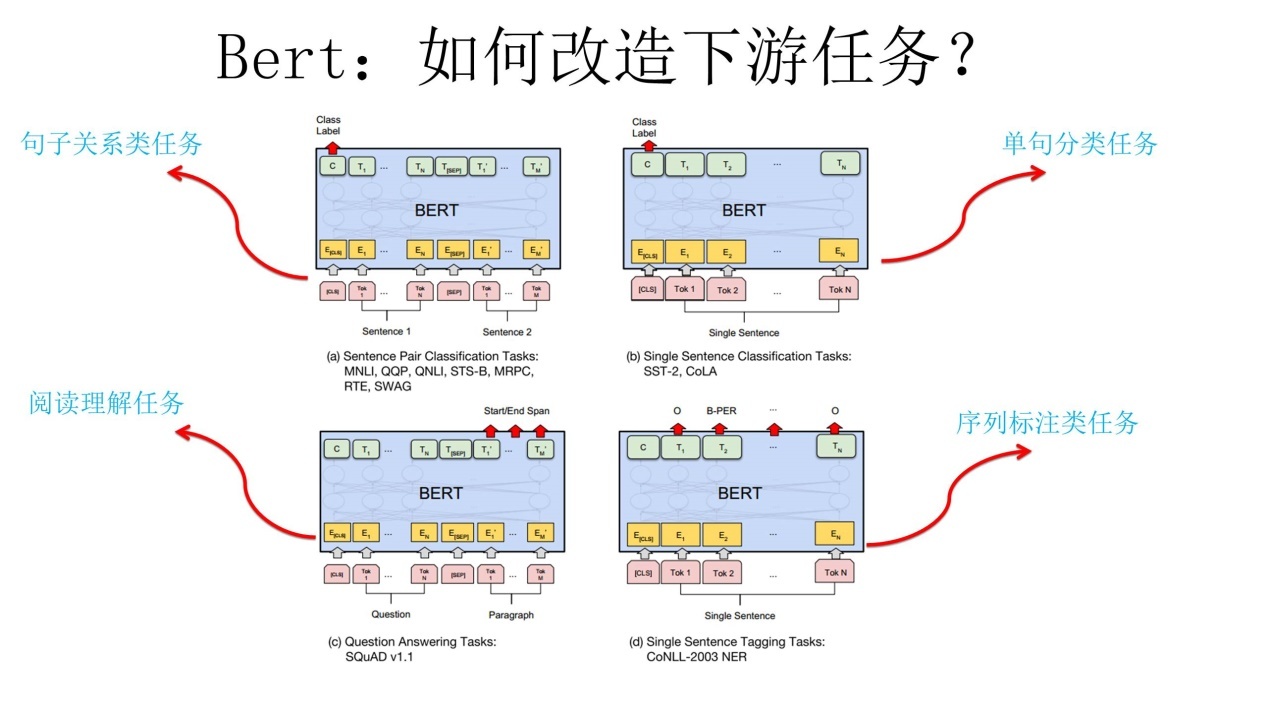
Parameter tuning optimization and improvement of pre training model( A sharp tool for text classification: Bert trim)
-
5fodls cross validation and Voting Fusion of multi model results( Big killer of machine learning competition -- model fusion)
-
Refer to the Top sharing of similar competitions, eg: Internet news emotion analysis competition sharing
About the use of PaddleHub:
github address of PaddleHub: (issue if you have any questions)
https://github.com/PaddlePaddle/PaddleHub
API lookup of the paddle related functions:
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/index_cn.html