2021SC@SDUSC
1, Overview
In the distributed system, load balancing is a very important function. In HBase, Region is a data Region segmented by the table according to the row direction, which is managed by the RegionServer and provides data reading and writing services to the outside. If there are too many regions on a RegionServer, the corresponding Region server will undertake too many read-write and other service requests, which may lead to server performance degradation or even downtime in the case of high concurrent access. In this way, the dynamic load balancing of regions among regional servers has become a problem to be solved for HBase to achieve high-performance read-write request access.
HBase realizes load balancing through the number of regions, that is, it realizes user-defined load balancing algorithm through hbase.master.loadbalancer.class.
HBase system load balancing is a periodic operation. Region s are evenly distributed to each RegionServer through load balancing. The time interval of load balancing is controlled through hbase.balancer.period attribute. The default is 5 minutes. It is conditional to trigger the load balancing operation, but the load balancing operation will not be triggered if:
- Automatic operation of load balancing_ Switch is closed, i.e. balance_switch false;
- HBase Master node is initializing;
- RIT is being executed in HBase cluster, that is, the Region is being migrated;
- HBase cluster is processing offline RegionServer;
2, Load balancing
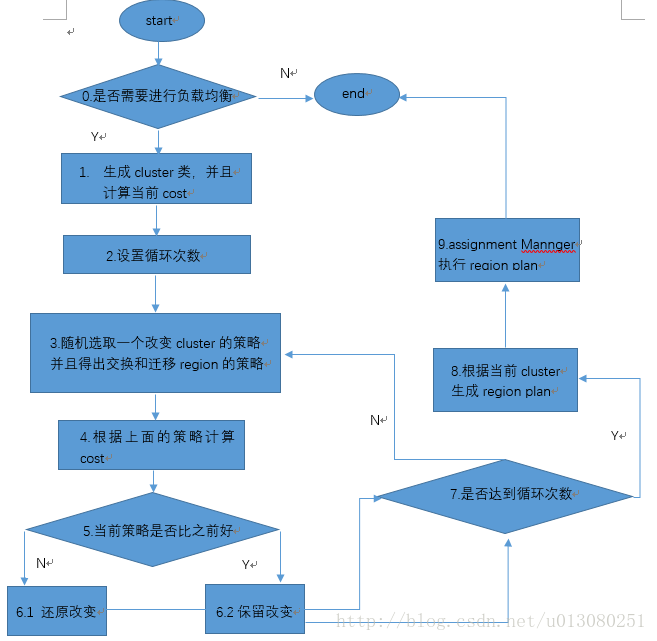
The specific process is as follows:
//initialize load balancer this.balancer.setClusterStatus(getClusterStatus()); this.balancer.setMasterServices(this); this.balancer.initialize();
HMaster initializes the Balancer: insert the cluster status, set the master, and then perform initialization
Map>> assignmentsByTable =
this.assignmentManager.getRegionStates().getAssignmentsByTable();
List plans = new ArrayList();
//Give the balancer the current cluster state.
this.balancer.setClusterStatus(getClusterStatus());
for (Map> assignments :assignmentsByTable.values()) {
List partialPlans = this.balancer.balanceCluster(assignments);
if (partialPlans != null) plans.addAll(partialPlans);
}
It is called in the balance () method of HMaster. Balance the table and return the balance scheme. For the global situation, it may not be the optimal solution. You can see that it first obtains the allocation of the current cluster according to the map > in the table, then traverses the values of the map, calls balancer.balanceCluster(assignments) to generate a partialPlans and a RegionPlan(Region's move plan).
Next, you can switch to StochasticLoadBalancer
Each load balancing operation can be divided into two steps:
1. Generate load balancing schedule
2. Assignment Manager class execution schedule
1. Generate load balancing schedule
First of all, we should make it clear that load balancing is based on each Table. Load balancing will not be performed in the following cases:
1. If the master is not initialized
2. At present, there are already load balancing methods running
3. Currently, there are region s in splitting status
4. Region servers in the current cluster have failed
hbase execution
Generate RegionPlan table:
Code package path: org.apache.hadoop.hbase.master.balancer.StochasticLoadBalancer
The method to generate the regionPlan table is:
StochasticLoadBalancer. balanceCluster(Map<ServerName, List<HRegionInfo>> clusterState)
StochasticLoadBalancer has a set of algorithms to calculate the cluster load score of a table. The lower the value, the more reasonable the load is. This algorithm is calculated according to the dimensions of Region Load (the number of regions per region server), Table Load, Data Locality, memory sizes and Storefile Sizes.
First, calculate the score x (0 < = x < = 1) for a single region server according to the above five dimensions, and then add up the scores of all region servers under the same table to get the cluster load score of the current table. The lower the score, the more reasonable it is.
balanceCluster first needs to judge whether it is balanced. If it is unbalanced, it will exit
if (!needsBalance(new ClusterLoadState(clusterState))) {
return null;
}
float average = cs.getLoadAverage(); // for logging
int floor = (int) Math.floor(average * (1 - slop));
int ceiling = (int) Math.ceil(average * (1 + slop));
if (!(cs.getMinLoad() > ceiling || cs.getMaxLoad() <<span style="word-wrap: break-word; margin: 0px; padding: 0px;"> floor)) {
.....return false;
}
return true;
The maximum and minimum load values of the cluster should be within ± slop of the average. The balance condition is that the maximum and minimum load values should be within ± slop of the average (region / server), but the average value is based on the table, because the passed parameter clusterState is based on the table
If balanced, continue to calculate the cost.
Three adjustment cluster load strategies:
pickers = new RegionPicker[] {
new RandomRegionPicker(),
new LoadPicker(),
localityPicker
};
RandomRegionPicker
In the virtual cluster (the virtual cluster is only used as a record and does not involve the actual region migration operation. The cluster contains the relevant information of all the region servers under a table and the regions under the region server.) Randomly select two region servers, and then randomly obtain a region in the region server, and then exchange the regions under the two region servers, and then calculate the score. If the score is low, it indicates that the exchange of the two regions is conducive to the load balancing of the cluster, and keep the change. Otherwise, restore to the previous state, and the two regions will be restored Exchange region servers. A region server with relatively few regions may be randomly empty. In fact, it becomes a migration region instead of an exchange region.
LoadPicker
@Override
Pair, Pair> pick(Cluster cluster) {
cluster.sortServersByRegionCount();
//Select the server with the highest load first
int thisServer = pickMostLoadedServer(cluster, -1);
//Then select the server with the lowest load except the server with the highest load
int otherServer = pickLeastLoadedServer(cluster, thisServer);
Pair regions = pickRandomRegions(cluster, thisServer, otherServer);
return new Pair, Pair>(
new Pair(thisServer, regions.getFirst()),
new Pair(otherServer, regions.getSecond())
);
}
Loadpicker, region number balancing strategy. In the virtual cluster, first obtain the two region servers with the largest and smallest number of regions, so as to make the final number of regions of the two region servers more average. The following process is the same as the above.
LocalityPicker
@Override
Pair, Pair> pick(Cluster cluster) {
if (this.masterServices == null) {
return new Pair, Pair>(
new Pair(-1,-1),
new Pair(-1,-1)
);
}
// Pick a random region server
int thisServer = pickRandomServer(cluster);
// Pick a random region on this server
int thisRegion = pickRandomRegion(cluster, thisServer, 0.0f);
if (thisRegion == -1) {
return new Pair, Pair>(
new Pair(-1,-1),
new Pair(-1,-1)
);
}
// Pick the server with the highest locality
int otherServer = pickHighestLocalityServer(cluster, thisServer, thisRegion);
// pick an region on the other server to potentially swap
int otherRegion = this.pickRandomRegion(cluster, otherServer, 0.5f);
return new Pair, Pair>(
new Pair(thisServer,thisRegion),
new Pair(otherServer,otherRegion)
);
}
Locality picker is the most local equalization strategy. Locality means that the underlying data of Hbase is actually stored on HDFS. If the proportion of data files of a region stored in a region server is higher than that of other region servers, then this region server is called the highest local region server of the region. In this strategy, first select one randomly A region server and the regions below it. Then find the region server with the highest locality of the region. The region server with the highest locality will randomly select a region server. The processes behind the two region servers are the same as those above.
protected double computeCost(Cluster cluster, double previousCost) {
double total = 0;
for (CostFunction c:costFunctions) {
if (c.getMultiplier() <= 0) {
continue;
}
total += c.getMultiplier() * c.cost(cluster);
if (total > previousCost) {
return total;
}
}
return total;
}
Calculate the function computeCost(cluster, Double.MAX_VALUE), traverse the CostFunction, and calculate the weighted average sum of costs, that is, in each dimension, calculate the cost value of the region server. Finally, the total score is added according to (weight * cost value). The smaller the score, the more balanced it is, and the smaller the difference between each region server. This cost value is determined by the cluster (maximum difference / (current difference - minimum difference)).
long computedMaxSteps = Math.min( this .maxSteps, (( long )cluster.numRegions * ( long ) this .stepsPerRegion * ( long )cluster.numServers));
Set the number of cycles - related to the total number of region server s in the cluster and the total number of regions. The maximum mapSteps is 1000000.
Cluster cluster = new Cluster(clusterState, loads, regionFinder);
//Calculate the current cost
double currentCost = computeCost(cluster, Double.MAX_VALUE);
double initCost = currentCost;
double newCost = currentCost;
for (step = 0; step < computedMaxSteps; step++) {
int pickerIdx = RANDOM.nextInt(pickers.length);
RegionPicker p = pickers[pickerIdx];
Pair<Pair<Integer, Integer>, Pair<Integer, Integer>> picks = p.pick(cluster);
int leftServer = picks.getFirst().getFirst();
int leftRegion = picks.getFirst().getSecond();
int rightServer = picks.getSecond().getFirst();
int rightRegion = picks.getSecond().getSecond();
cluster.moveOrSwapRegion(leftServer,
rightServer,
leftRegion,
rightRegion);
newCost = computeCost(cluster, currentCost);
if (newCost < currentCost) {
currentCost = newCost;
} else {
cluster.moveOrSwapRegion(leftServer,
rightServer,
rightRegion,
leftRegion);
}
if (initCost > currentCost) {
List<RegionPlan> plans = createRegionPlans(cluster);
return plans;
}
A random strategy is to exchange or migrate the RandomRegionPicker, LoadPicker and LocalityPicker in the above region, and then calculate the score. If the score is lower than before, keep it, otherwise restore it.
int pickerIdx = RANDOM.nextInt(pickers.length); Randomly select a "number selector", and then use the number selector to randomly jump out a pair from the cluster, the < server, region > pair to be processed. newCost = computeCost(cluster, currentCost); After moving or swapping, see if the new overhead continues
2. Assignment Manager class execution schedule
The cycle continues until the end, and the output region plan is handed over to the assignment manager to actually migrate the region. The format of regionPlan is as follows:
egionPlan rp = new RegionPlan(region, initialServer, newServer); //The region of initialServer needs to be migrated to newServer
At this point, the load balancing algorithm ends.
4, Summary
Maintain the HBase cluster. For example, after restarting several RegionServer nodes, unbalanced regions may be sent. At this time, if you need to immediately make the regions on other regionservers in the current cluster balanced after enabling automatic balancing, you can use manual balancing. In addition, the time consumption of each regional server of HBase cluster can reflect the health status of the current cluster.