1. Windows
1.1. Basic concepts
Window is the core of processing infinite flow. The window divides the flow into "buckets" of fixed size, which is convenient for programmers to apply various calculations on it.
Window operation is a very core abstraction of streaming data processing. It divides an infinite stream data set into bounded windows (or buckets), and then it is very convenient to define various computing operations acting on window.
1.2. Window classification
Windows are divided into two types. See the following for the general structure of window programs. The main difference is that for keyed windows, you need to first use keyBy to convert streams into keyed streams, and then use window for processing, but non keyed windows directly use windowAll for processing
1.2.1. Keyed Window
- The original stream will be imported stream Convert to multiple Keyed stream - each Keyed stream It will be calculated independently, so that multiple Task Yes Windowing Parallel processing of operations - Have the same Key The data elements will be sent to the same Task Process in
The commands in square brackets ([...]) are optional. This shows that Flink allows programmers to customize window logic in many different ways so that it is best suited to actual business needs.
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
1.2.2. Non-Keyed Window
- Original flow stream It will not be divided into multiple logical flows - be-all Windowing Operation logic can only be in one Task The calculation parallelism is 1
General structure of window program
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
1.3. Window life cycle
For time-based windows, the life cycle of the window is as follows:
- Create window: when the first element that should belong to the window arrives, a window will be created,
- Destroy window: when the time (event or processing time) passes its end timestamp plus the allowable delay specified by the user, the window will be completely deleted.
Flink only guarantees to delete time-based windows, not other types of windows, such as global windows.
If the window policy based on event time is used, a non overlapping (or rolling) window is created every 5 minutes, and the delay of 1 minute is allowed:
When the first element with time stamp reaches this time interval, Flink will create a new window for the time interval between 12:00 and 12:05. When the watermark passes the 12:06 time stamp, it will delete the window corresponding to the time interval.
Logical operations for windows:
- Window Functions: calculation logic executed in window data, which can be one of ReduceFunction, AggregateFunction or processwindowfunctions
- Trigger: Specifies the condition that the window is considered ready to apply the window function, such as when the number of elements in the window exceeds 4 and when the watermark passes through the window
- Each windowassignor has a default trigger. If the default trigger does not meet your needs, you can use trigger (...) to specify a custom trigger.
- Decides to clear the contents of a window at any time between creation and deletion.
- Evictor evictor: deletes elements from the window after the trigger is triggered and before or after the window function is applied
2. Window Assigners
Window assignors: defines how to assign an element to a window, and is responsible for assigning each incoming element to one or more windows.
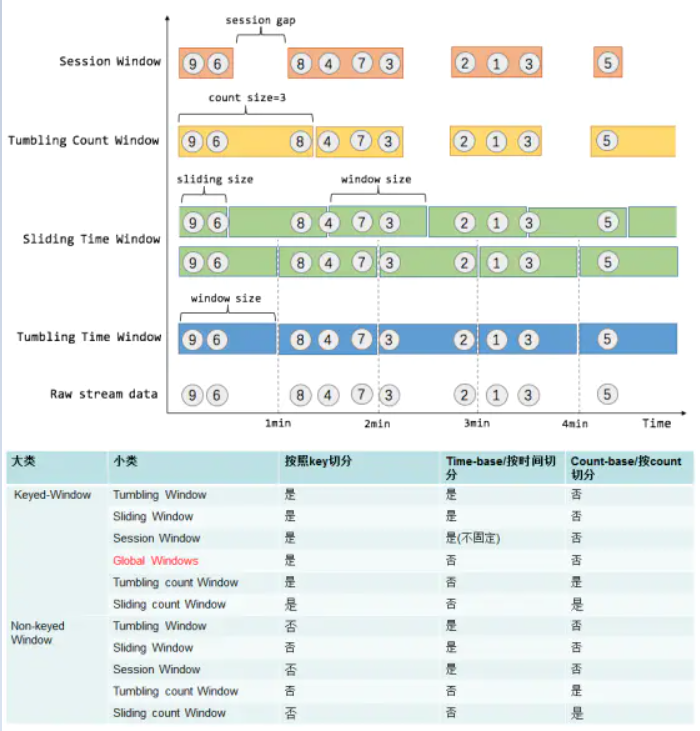
- flink provides four commonly used pre-defined window assignors: tumbling windows, sliding windows, session windows, and global windows [Note: except for global windows, allocation is based on time]
- You can extend the WindowAssigner class to implement a custom window assignor
The mechanism to measure the time progress of events in Flink is watermark
The watermark is a part of the data stream and has a time stamp t. Watermark(t) declares that the event time in the stream has reached time t, which means that there should be no more elements with time stamp t '< = t (i.e. events with time stamp greater than or equal to the watermark).
The time-based window has a start timestamp and an end timestamp [which is the interval between closing before opening], which together describe the size of the window
2.1. Count-based window
- Tumbling CountWindow code example:. countWindow(windowSize)
- Sliding CountWindow code example:. countWindow(windowSize, slideSize)
2.2. Time-based window
2.2.1. Tumbling Windows
The scroll window evaluator assigns each element to a fixed length and size window. Scrolling windows have a fixed size and do not overlap each other,
It is applicable to BI Statistics (calculate the indicators of each time period).
characteristic:
- Time alignment: the default is aligned with epoch (integer point, integer minute, integer second, etc.), and the alignment can be changed through the offset parameter.
- Fixed window length
- event no overlap
Code example:
- .window(TumblingEventTimeWindows.of(Time.seconds(5)))
- .window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
- . window (tumbling eventtimewindows. Of (time. Days (1), time. Hours (- 8))) time offset 8 hours
An important use case for offset offset is to adjust the window to a time zone other than UTC-0
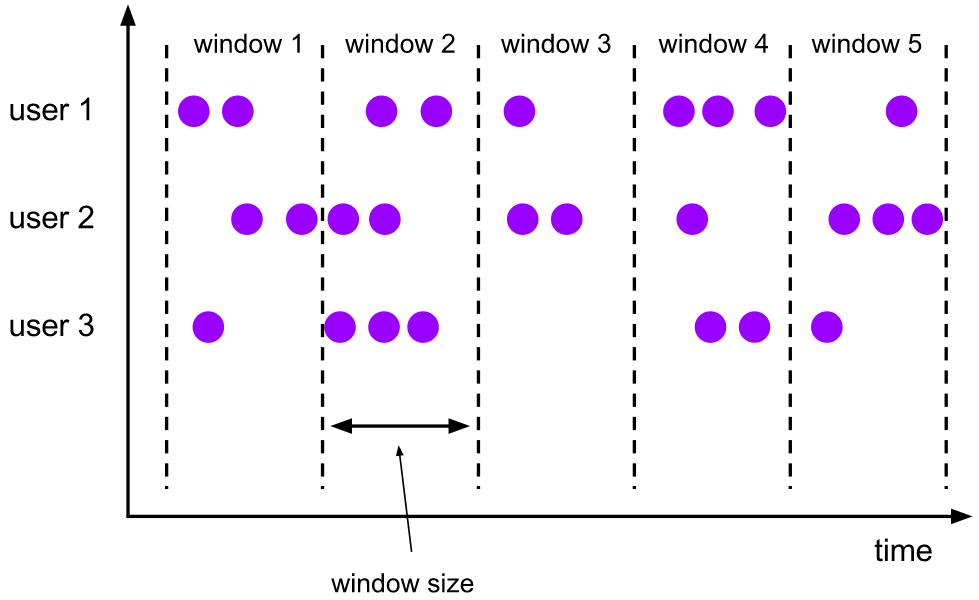
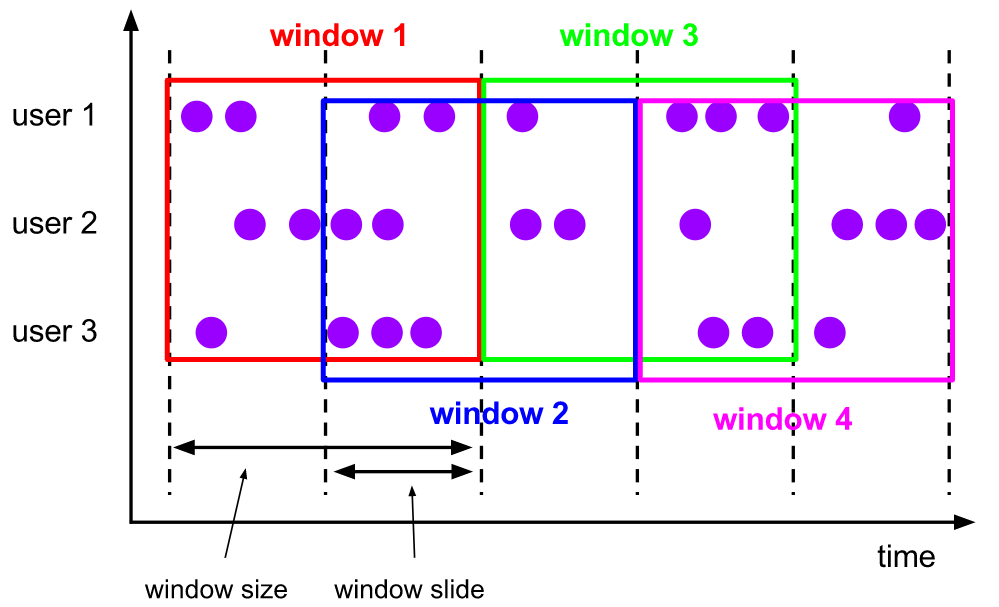
2.2.2. Sliding Windows
The sliding window assignor assigns each element to one or more windows of fixed length and size
- The window size parameter specifies the length and size of the window
- window slide controls the startup frequency of the sliding window.
Usage scenario: monitor the scenario and make statistics in the latest time period (determine whether to alarm by calculating the failure rate of an interface in the last 5min).
characteristic:
- Time alignment: the default is aligned with epoch (integer point, integer minute, integer second, etc.), and the alignment can be changed through the offset parameter.
- Fixed window length
- Events overlap
Code example:
- .window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
- .window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
- .window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
Therefore, when the slide is less than size, the sliding windows can overlap. In this case, the element is assigned to multiple windows.
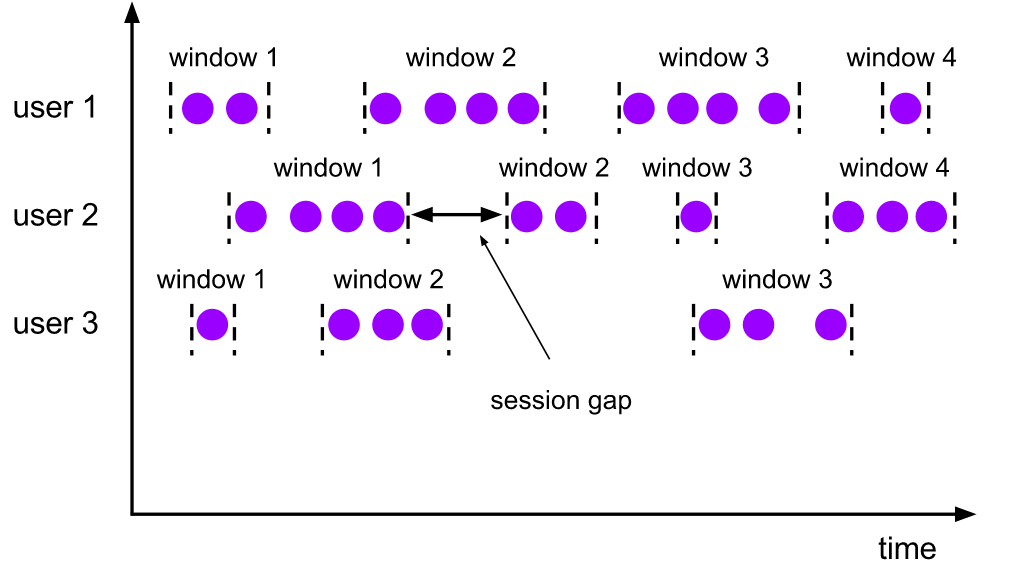
2.2.3. Session Windows
The session window allocator groups elements by active session.
- Compared with scrolling windows and sliding windows, session windows do not overlap and have no fixed start and end times.
- When the session window does not receive elements for a period of time, that is, an inactive gap [session gap] occurs, the session window will be closed.
- session gap
- Fixed gap, also known as static session gap
- Dynamic gap: implements SessionWindowTimeGapExtractor, which defines the length of inactivity
- When this period of time [session gap] expires, the current session is closed and subsequent elements are assigned to a new session window.
It is applicable to online user behavior analysis.
be careful:
- Internally, the session window allocator creates a new window for each arriving record. If the distance between the windows is closer than the defined gap, they are merged together,
- To merge, the session window operator requires a merge trigger and a merge window function, such as ReduceFunction, AggregateFunction, or ProcessWindowFunction
characteristic:
- Time no alignment
- event does not overlap
- There is no fixed start and end time
Code example:
- .window(EventTimeSessionWindows.withGap(Time.minutes(10)))
- .window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
})) - .window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
- .window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
2.2.4. Global Windows
The global window assignor assigns all elements with the same key to the same global window. This window mode is only useful when you specify a custom trigger. Otherwise, no calculation will be performed because none of the global windows can handle the natural end of the aggregated element.
Code example:. window(GlobalWindows.create())

Code examples are as follows:
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.assigners.{GlobalWindows, ProcessingTimeSessionWindows, SlidingProcessingTimeWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger
import org.apache.flink.streaming.api.windowing.windows.{GlobalWindow, TimeWindow}
import org.apache.flink.util.Collector
object FlinkWindowProcessGlobal {
def main(args: Array[String]): Unit = {
//1. Create a flow computing execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2. Create DataStream - refine
val text = env.socketTextStream("Centos",9999)
//3. Perform the conversion calculation of DataStream
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(word=>(word._1))
.window(GlobalWindows.create())
.trigger(CountTrigger.of(4))
.apply(new UserDefineGlobalWindowFunction)
.print()
//5. Perform flow calculation tasks
env.execute("Tumbling Window Stream WordCount")
}
}
class UserDefineGlobalWindowFunction extends WindowFunction[(String,Int),(String,Int),String,GlobalWindow]{
override def apply(key: String,
window: GlobalWindow,
input: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val sum = input.map(_._2).sum
out.collect((s"${key}",sum))
}
}
2.3. Summary
3. Window Functions
The window function encapsulates the calculation logic of window data. When the system determines that a window is ready for processing, the window function will be triggered
- The window function can be one of ReduceFunction, AggregateFunction or ProcessWindowFunction.
- The first two can be performed more efficiently because Flink can incrementally aggregate the elements of each window as they arrive.
- ProcessWindowFunction obtains the iteratable of all elements contained in a window and the additional meta information of the window to which these elements belong. Before calling the function, all elements of the window are buffered internally, so the execution efficiency is a little poor
3.1. ReduceFunction
ReduceFunction specifies how two elements from input are combined to produce output elements of the same type. Flink uses ReduceFunction to incrementally aggregate elements in a window.
Code examples are as follows:
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce { (v1, v2) => (v1._1, v1._2 + v2._2) }
3.2. AggregateFunction
AggregateFunction is a generalized version of ReduceFunction. It has three types:
- Input type (IN): the type of element in the input stream
- Accumulation type (ACC): intermediate result type during aggregation
- Output type (OUT): the final result type of aggregation
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
override def createAccumulator() = (0L, 0L)
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate)
3.3. ProcessWindowFunction
ProcessWindowFunction obtains an iteratable containing all elements of the window and a Context object that can access time and state information, which makes it more flexible than other window functions [this is at the cost of performance and resource consumption, because elements cannot be aggregated incrementally, but need to be buffered internally until the window is considered ready for processing.]
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction())
/* ... */
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]) = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
}
Note that using ProcessWindowFunction for simple aggregation (such as count) is very inefficient. The following sections show how to combine ReduceFunction or AggregateFunction with ProcessWindowFunction to obtain incremental aggregation and added ProcessWindowFunction information.
3.3.1. Incremental Window Aggregation with ReduceFunction
Combine ReduceFunction with ProcessWindowFunction to obtain incremental aggregation and added ProcessWindowFunction information
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object FlinkWindowProcessTumblingWithProcessWindowFunctionAndReduceFunction {
def main(args: Array[String]): Unit = {
//1. Create a flow computing execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2. Create DataStream - refine
val text = env.socketTextStream("172.25.21.22",19999)
//3. Perform the conversion calculation of DataStream
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(t=>t._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new UserDefineReduceFunction2,new UserDefineProcessWindowFunction2)
.print()
//5. Execution flow calculation task
env.execute("Aggregate Window Stream WordCount")
}
}
class UserDefineProcessWindowFunction2 extends ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
val sdf = new SimpleDateFormat("HH:mm:ss")
override def process(key: String,
context: Context,
elements: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val window = context.window//Get window metadata
val start = sdf.format(window.getStart)
val end = sdf.format(window.getEnd)
val sum = elements.map(_._2).sum
println("list---->"+elements.toList)
out.collect((key+"\t["+start+"---"+end+"]",sum))
}
}
class UserDefineReduceFunction2 extends ReduceFunction[(String,Int)]{
override def reduce(t: (String, Int), t1: (String, Int)): (String, Int) = {
println("reduce:"+t+"\t"+t1)
(t._1,t._2+t1._2)
}
}
3.3.2. Incremental Window Aggregation with AggregateFunction
Combine AggregateFunction with ProcessWindowFunction to obtain incremental aggregated and added ProcessWindowFunction information
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate(), new MyProcessWindowFunction())
// Function definitions
/**
* The accumulator is used to keep a running sum and a count. The [getResult] method
* computes the average.
*/
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
override def createAccumulator() = (0L, 0L)
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
class MyProcessWindowFunction extends ProcessWindowFunction[Double, (String, Double), String, TimeWindow] {
def process(key: String, context: Context, averages: Iterable[Double], out: Collector[(String, Double)]) = {
val average = averages.iterator.next()
out.collect((key, average))
}
}
3.4. Using per-window state in ProcessWindowFunction
In addition to accessing the keyed state (as allowed by any rich function), a ProcessWindowFunction can also use the keyed state, which is limited to the window currently being processed by the function.
In this case, it is important to understand what the window referenced by each window state is. There are different "windows" related to:
- Specify the window defined during window operation: this may be a tumble window for 1 hour or a sliding window for 2 hours. Slide for 1 hour.
- Actual instance of a defined window for a given key: for user ID xyz, this may be a time window from 12:00 to 13:00. This is defined based on the window, and there will be many windows based on the number of keys currently being processed by the job and which time slot the event belongs to.
The state of each window is related to the latter of the two. This means that if we process 1000 events with different keys and the events of all current events fall into the [12:00, 13:00) time window, there will be 1000 window instances, each with its own state of each window.
In the process() method, you can call two methods on the Context object, which allow access to two types of states:
- globalState(), which allows access to key states that are not within the scope of the window
- windowState(), which allows access to key states that also act on windows
This feature is useful if you expect the same window to trigger multiple times, for example, when there is a late trigger for late data, or when you have a custom trigger for speculative early trigger. In this case, you will store information about the previous trigger or the number of triggers in each window state.
When using window state, it is important to clear the state when clearing the window. This should happen in the clear() method.
import java.text.SimpleDateFormat
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object FlinkWindowProcessTumblingWithProcessWindowFunctionState {
def main(args: Array[String]): Unit = {
//1. Create a flow computing execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2. Create DataStream - refine
val text = env.socketTextStream("172.25.21.22",19999)
//3. Perform the conversion calculation of DataStream
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(t=>t._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new UserDefineProcessWindowFunction3)
.print()
//5. Execution flow calculation task
env.execute("Aggregate Window Stream WordCount")
}
}
class UserDefineProcessWindowFunction3 extends ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
val sdf = new SimpleDateFormat("HH:mm:ss")
var wvsd:ValueStateDescriptor[Int]=_
var gvsd:ValueStateDescriptor[Int]=_
override def open(parameters: Configuration): Unit = {
wvsd=new ValueStateDescriptor[Int]("ws",createTypeInformation[Int])
gvsd=new ValueStateDescriptor[Int]("gs",createTypeInformation[Int])
}
override def process(key: String,
context: Context,
elements: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val window = context.window //Get window metadata
val start = sdf.format(window.getStart)
val end = sdf.format(window.getEnd)
val sum = elements.map(_._2).sum
var wvs:ValueState[Int]=context.windowState.getState(wvsd)
var gvs:ValueState[Int]=context.globalState.getState(gvsd)
wvs.update(wvs.value()+sum)
gvs.update(gvs.value()+sum)
println(key+"\tWindow Count\t"+wvs.value()+"\tGlobal Count\t"+gvs.value())
out.collect((key+"\t["+start+"---"+end+"]",sum))
}
}
3.5 WindowFunction (Legacy)
Where ProcessWindowFunction can be used, you can also use WindowFunction. This is an old version of ProcessWindowFunction. It provides less context information and does not have some advanced features, such as the key state of each window. This interface will be deprecated at some time.
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object FlinkWindowProcessSessionWithWindowFunction {
def main(args: Array[String]): Unit = {
//1. Create a flow computing execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2. Create DataStream - refine
val text = env.socketTextStream("172.25.21.22",19999)
//3. Perform the conversion calculation of DataStream
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(word=>(word._1))
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)))
.apply(new UserDefineWindowFunction)
.print()
//5. Perform flow calculation tasks
env.execute("Tumbling Window Stream WordCount")
}
}
class UserDefineWindowFunction extends WindowFunction[(String,Int),(String,Int),String,TimeWindow]{
override def apply(key: String,
window: TimeWindow,
input: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val format = new SimpleDateFormat("HH:mm:ss")
val start = format.format(window.getStart)
val end = format.format(window.getEnd)
val sum = input.map(_._2).sum
out.collect((s"${key}\t${start}~${end}",sum))
}
}
4. Triggers
4.1 basic concept and operation
Trigger defines when to start using the window calculation function to calculate windows. Each window allocator will have a default trigger. If the default trigger does not meet the actual business requirements, you can use trigger(...) to specify a custom trigger.
The Trigger interface has five methods that allow the Trigger to respond to different events:
- onElement(): this method is called for each element added to the window.
- onEventTime(): called when the event time timer is triggered.
- onProcessingTime(): called when the processing time timer is triggered.
- onMerge(): related to stateful triggers. When their corresponding windows are merged, the states of the two triggers are merged, such as when using a session window.
- clear(): perform any operations required to remove the corresponding window.
There are two points to note about the above methods:
- The first three functions decide how to handle their call events by returning TriggerResult. The operation can be one of the following:
- CONTINUE: do nothing,
- FIRE: trigger calculation,
- PURGE: clears the elements in the window
- FIRE_AND_PURGE: triggers the calculation and then clears the elements in the window.
- Any of these methods can be used to register a processing or event timer for future operations.
4.2. Default Triggers of WindowAssigners
The default trigger of windowassignor is applicable to many cases. For example, all window allocators based on event time use EventTimeTrigger as the default trigger. This trigger will directly trigger the calculation output when the watermark passes the end of a window.
The default trigger for GlobalWindow is NeverTrigger, which never fires. Therefore, when using GlobalWindow, you must always define a custom trigger
See org.apache.flink.streaming.api.windowing.triggers for the source code
Flink has some built-in triggers:
- EventTimeTrigger: trigger the window based on the event time and watermark mechanism.
- ProcessingTimeTrigger: triggered based on processing time.
- CountTrigger: the calculation will be triggered if the number of window elements exceeds the preset limit value.
- PurgingTrigger is used as the parameter of other triggers to convert it into a purging trigger.
// Triggered for each element
@Override
public TriggerResult onElement(Object element, long timestamp, TimeWindow window, TriggerContext ctx) throws Exception {
if (window.maxTimestamp() <= ctx.getCurrentWatermark()) {
// if the watermark is already past the window fire immediately
// The maximum timestamp of the window is smaller than the current watermark, and the window needs to be calculated immediately
return TriggerResult.FIRE;
} else {
// Register an event time event. When watermark exceeds window.maxTimestamp, onEventTime method will be called
ctx.registerEventTimeTimer(window.maxTimestamp());
return TriggerResult.CONTINUE;
}
}
@Override
public TriggerResult onEventTime(long time, TimeWindow window, TriggerContext ctx) {
// The current time is the maximum timestamp of the window, triggering the calculation
return time == window.maxTimestamp() ?
TriggerResult.FIRE :
TriggerResult.CONTINUE;
}
@Override
public TriggerResult onProcessingTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
// For processing time, no processing is performed
return TriggerResult.CONTINUE;
}
4.3. Fire and Purge
Once the trigger determines that a window is ready for processing, it triggers, returning FIRE or FIRE_AND_PURGE
This is the signal that the window operator sends the result of the current window.
- Given a window with ProcessWindowFunction, all elements are passed to ProcessWindowFunction (possibly after passing them to the ejector)
- Windows with ReduceFunction or AggregateFunction will only issue the results of their incremental aggregation.
When the trigger is triggered, it can be FIRE or FIRE_AND_PURGE. Although FIRE retains the contents of the window, FIRE_AND_PURGE deletes its contents. By default, the pre implemented trigger is just FIRE and does not clear the window state.
Note: clearing will simply delete the contents of the window and retain any potential meta information about the window and any trigger state.
5. Evictors
Evictors can delete elements from the window after the trigger is triggered and * * before or after the window function is applied * *. For this purpose, the Evictor interface has two methods:
public interface Evictor<T, W extends Window> extends Serializable {
/**
* Optionally evicts elements. Called before windowing function.
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictBefore(
Iterable<TimestampedValue<T>> elements,
int size,
W window,
EvictorContext evictorContext);
/**
* Optionally evicts elements. Called after windowing function.
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictAfter(
Iterable<TimestampedValue<T>> elements,
int size,
W window,
EvictorContext evictorContext);
Flink has three built-in ejectors. By default, these built-in ejectors apply their logic before the window function
- CountEvictor: keep the number of elements specified by the user in the window. If it is more than the number specified by the user, discard the redundant elements from the beginning of the window buffer.
- DeltaEvictor: accepts a DeltaFunction and a threshold value, calculates the increment between the last element in the window buffer and each remaining element, and deletes elements with an increment greater than or equal to the threshold value
- TimeEvictor: takes the interval in milliseconds as the parameter. For a given window, it will find the maximum timestamp Max in its element_ Ts and delete the time stamp less than max_ts - all elements of interval.
be careful:
- By default, all built-in ejectors are used before window functions. Specifying a evictor avoids pre aggregation because all elements in the window must be passed to the evictor before the window is calculated.
- Flink does not guarantee the order of elements in the window. This means that although the ejector can remove elements from the beginning of the window, they do not necessarily come first or last.
6. Allowed Lateness
When using the event time window, the element may arrive late, that is, the watermark used by Flink to track the time progress of the event has exceeded the end timestamp of the window to which the element belongs.
By default, late elements are deleted when the watermark exceeds the end timestamp of the window.
However, Flink allows you to specify the maximum allowable delay for window operators and how long an element can be delayed before being deleted. Its default value is 0
If the element arrives before the window's end timestamp + maximum allowable delay, the element is still added to the window.
Depending on the trigger used, delayed but undeleted elements may cause the window to fire again. Such as EventTimeTrigger.
Example code:
.allowedLateness()
6.1. Getting late data as a side output
Using Flink's side output feature, you can get a delayed discarded data stream.
public class SolveLateness {
public static void main(String[] args) throws Exception {
streamCompute();
}
private static void streamCompute() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// The default is 200ms
env.getConfig().setAutoWatermarkInterval(1L);
DataStreamSource<String> source = env.socketTextStream("localhost", 7777);
SingleOutputStreamOperator<SensorReading> stream = source.map(data -> new SensorReading(
data.split(",")[0].trim(),
Long.parseLong(data.split(",")[1].trim()),
Double.parseDouble(data.split(",")[2].trim())
)
).returns(SensorReading.class);
OutputTag<SensorReading> laterTag = new OutputTag<SensorReading>("laterData") {
};
// Generate watermark intermittently, and set the maximum time to tolerate disordered data to 5
SingleOutputStreamOperator<SensorReading> result = stream.assignTimestampsAndWatermarks(WatermarkStrategy.<SensorReading>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(new SerializableTimestampAssigner<SensorReading>() {
@Override
public long extractTimestamp(SensorReading element, long recordTimestamp) {
return element.getTimestamp();
}
})).keyBy(SensorReading::getId)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
// Maximum time allowed for data
.allowedLateness(Time.seconds(2))
// The side output stream is used to process the late data
.sideOutputLateData(laterTag)
.apply(
new WindowFunction<SensorReading, SensorReading, String, TimeWindow>() {
@Override
public void apply(String s, TimeWindow window, Iterable<SensorReading> input, Collector<SensorReading> out) throws Exception {
System.out.println("window : [" + window.getStart() + ", " + window.getEnd() + "]");
ArrayList<SensorReading> list = new ArrayList<>((Collection<? extends SensorReading>) input);
list.forEach(out::collect);
}
});
result.print();
result.getSideOutput(laterTag).print("later data");
env.execute();
}
}
@Data
@AllArgsConstructor
public class SensorReading {
private String id;
private long timestamp;
private double temperature;
}
6.2. Late elements considerations
When the specified allowable delay time is greater than 0, the window and its contents will be retained after the watermark passes through the end of the window. In these cases, when an element arrives late but has not been deleted, it may trigger another trigger for the window. These triggers are called delayed triggers because they are triggered by delayed events. In contrast to the main trigger, the main trigger is the first trigger of the window.
In the case of session windows, delayed triggering may further lead to the merging of windows, because they may "bridge" the gap between two existing unmerged windows.
7. Working with window results
The result of window operation is still a DataStream, and the information of window operation will not be retained in the result element. Therefore, if you want to retain the meta information about the window, you must manually encode this information in the result element of your ProcessWindowFunction.
7.1. Interaction of watermarks and windows
When the watermark reaches the window operator, two things are triggered:
- When the maximum timestamp (end timestamp - 1) is less than the new watermark, the watermark triggers all Windows calculations,
- The watermark is forwarded to the downstream operation
a watermark "flushes" out any windows that would be considered late in downstream operations once they receive that watermark.
7.2. Consecutive windowed operations
This can be useful when you want to perform two consecutive window operations and want to use different keys, but still want elements from the same upstream window to eventually reach the same downstream window
val input: DataStream[Int] = ...
val resultsPerKey = input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new Summer())
val globalResults = resultsPerKey
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new TopKWindowFunction())
In this example, the result of the time window [0,5) of the first operation will also end in the time window [0,5) of the subsequent window operation. This allows the sum of each key to be calculated, and then the top-k elements in the same window to be calculated in the second operation.
8. Useful state size considerations
Windows can be defined over a long period of time (such as days, weeks, or months), so they accumulate very large states.
There are several rules to keep in mind when estimating the storage requirements calculated by the window:
- Flink creates a copy of each element for each window to which it belongs.
- Scrolling the window keeps a copy of each element (an element belongs to only one window unless it is deleted late)
- Sliding windows create several copies of each element
- ReduceFunction and AggregateFunction can significantly reduce storage requirements because they incrementally aggregate elements and store only one value per window. On the contrary, using ProcessWindowFunction alone requires accumulating all elements.
- Using Evictor prevents any pre aggregation because all elements of the window must pass through Evictor before applying calculations