Redis has five basic data structures:
1. String (string)
2. List
3. Hash (Dictionary)
4. Set
5. Zset (ordered set)
There are eight categories of data structures:
1. Array
2. Stack
3. Queue
4. Linked list
5. Tree
6. Hash table
7. Pile
8. Figure
Java has eight basic data types (it doesn't matter, but by the way 😜), They are:
1. Byte (bit)
2. Short (short integer)
3. Int (integer)
4. Long (long integer)
5. Float (single precision)
6. Double (double)
7. Char (character)
8. Boolean (Boolean)
Then this blog post will give a brief introduction to the five data structures of Redis and how to package them in JAVA.
String string
Introduction to string
The string structure is widely used, and its common purpose is to cache user information, such as the grocery store project in the blogger's grocery store practice column, the mailbox verification code generated during mailbox verification, and so on.
We serialize the object information to be stored into a string using JSON, and then use Redis to cache the serialized string. When fetching the stored information, we can perform a deserialization operation.
The difference between Redis String and Java String is that the String in Java is a final String, while Redis String is a dynamic String that can be modified. The internal implementation structure is similar to ArrayList in Java. Pre allocation of redundant space is used to reduce frequent memory allocation.
Redis will allocate a larger capacity (space) than the actual string. When expanding, it will double the existing space. However, the maximum length of the string is 512MB.
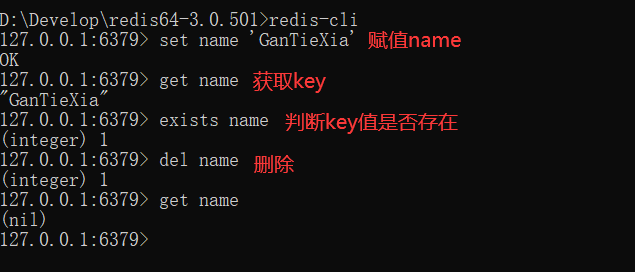
Some common operations such as set, get, exists and del are as follows:
Of course, you can also read and write in batches through mset and mget:

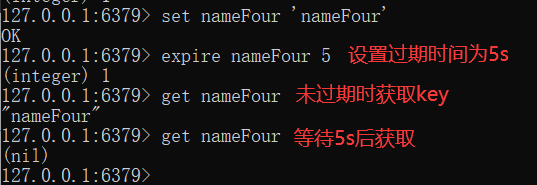
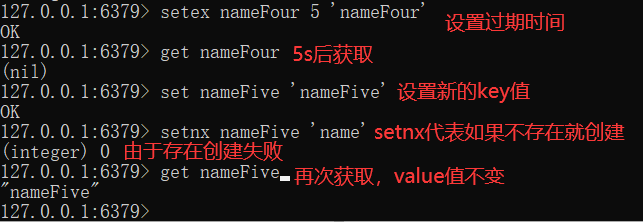
As we all know, some data will not be stored in the cache for a long time. Therefore, to set the corresponding expiration time, you can set it through expire and setex, and you can judge whether the key value exists or not through sexnx
When our value is an integer, we can also increase or decrease it through incr, decr, incrby and decrby. It should be noted that its return is between the maximum and minimum values of signed long. If it exceeds this range, an error will be reported:

Encapsulation of string string in Java (complete)
(Note: only the complete writing method of string type tool class is listed below, and only some writing methods are listed for other data structures)
First introduce dependencies in pom.xml:
<!-- redis Dependent package -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
Then write Redis's tool class:
package com.gantiexia.redis;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
/**
* @author GanTieXia
* @date 2021/11/21 18:07
*/
@Component
public class RedisUtils {
/** After the corresponding dependency is introduced, it can be injected*/
@Autowired
private RedisTemplate<String, String> redisTemplate;
/**
* Read cache
*
* @param key
* @return
*/
public String get(final String key) {
return redisTemplate.opsForValue().get(key);
}
/**
* Write cache
*/
public boolean set(final String key, String value) {
boolean result = false;
try {
redisTemplate.opsForValue().set(key, value);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* With failure time key
*
* @param key
* @param value
* @param timeOut
* @param timeUnit
* @return
*/
public boolean setKeyTimeOut(final String key,String value,long timeOut,TimeUnit timeUnit){
boolean result = false;
try {
redisTemplate.opsForValue().set(key, value, timeOut, timeUnit);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* Update cache
*/
public boolean getAndSet(final String key, String value) {
boolean result = false;
try {
redisTemplate.opsForValue().getAndSet(key, value);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* Delete cache
*/
public boolean delete(final String key) {
boolean result = false;
try {
redisTemplate.delete(key);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
}
List list
list introduction
Redis's list is equivalent to the LinkedList in the Java language, but it is a linked list rather than an array. This means that its insertion and deletion are very fast, while index positioning is relatively slow.
Each element in the list is connected by two-way pointers and supports forward traversal and backward traversal. When the last element pops up in the list, the data structure is automatically deleted and memory is recycled.
Redis's list structure can be used as an asynchronous queue. We serialize the task structure that needs to be delayed into a string, store it in the redis list, and then enable another thread to obtain data from the list for processing.
queue
As we all know, queue is a first in first out data structure, which can be used for the message queue we often hear, and can ensure the access order of elements.

Stack
Stack is a data result of first in and last out, which is the same reason as our common withdrawal.
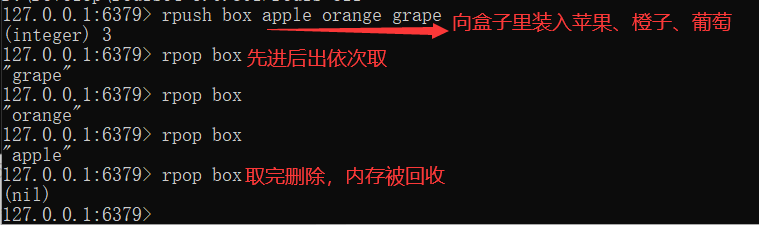
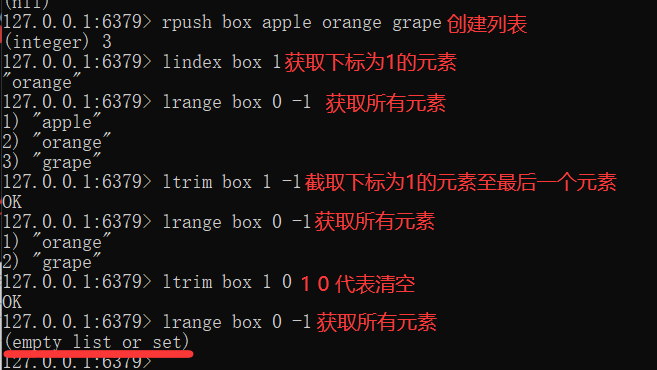
You can also find the elements in the corresponding position through lindex. lrange 0 -1 (- 1 represents the last element and - 2 represents the penultimate element) obtains all elements. ltrim can retain the elements in a certain interval and cut off the elements in other positions. However, the time complexity of these operations is O(n), so they are generally not recommended.
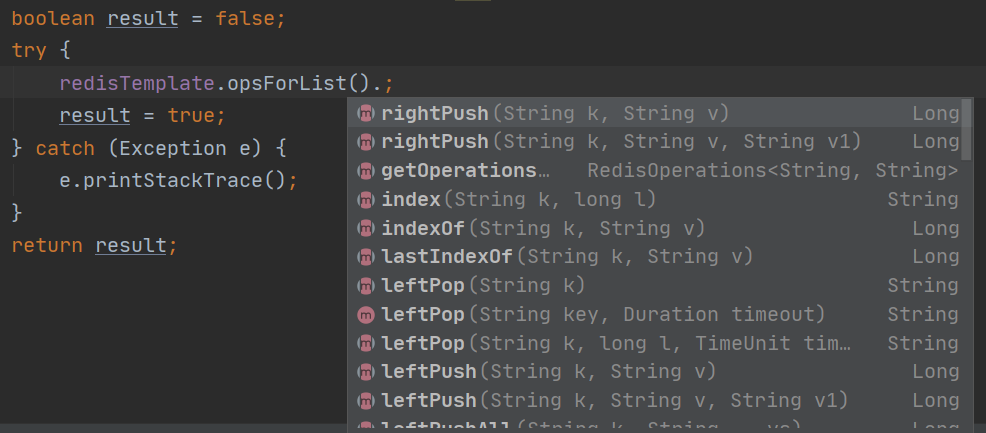
Encapsulation statement of list in Java (part)
// Pass in the corresponding parameters according to your needs // Main statements of set method redisTemplate.opsForList(). ; // The latter method is written according to your application scenario
Hash (Dictionary)
Introduction to hash dictionary
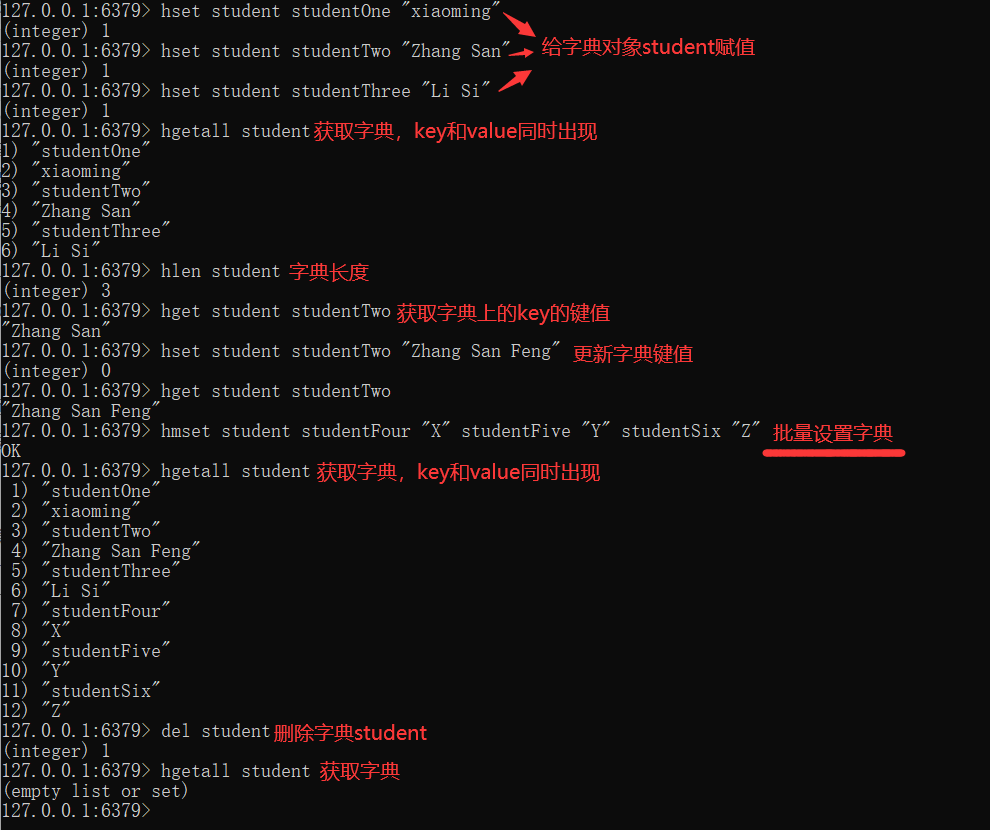
Redis's dictionary is equivalent to HashMap in JAVA language. It does not need a dictionary and stores many key value pairs internally.
For the conceptual model of HashMap, in the blogger's Advanced JAVA -- Analysis of HashMap underlying implementation (I) The explanation is very clear in the article.
The difference is that redis's Dictionary values can only be strings, and their rehash is also different. When the dictionary of Java's HashMap is very large, rehash is a very time-consuming operation, and it has to rehash all at once. In order to continue high performance and avoid congestion, redis adopts a progressive rehash strategy.
The progressive rehash strategy is to retain the old and new hash structures while rehash. When querying, the two hash structures will be queried at the same time, and then the old hash structure will be transferred to the new hash structure through subsequent scheduled tasks and hash operation instructions. After the last hash element is moved, the old hash structure will be deleted and the memory will be recycled.
What are the advantages of hash? For example, when we store user information, string directly serializes the whole piece of information and stores it. After taking it out, we also need to deserialize it to obtain the information we want. Using hash, we can store each single field in the user structure. For example, after we want to obtain the user name, we don't need to get a whole piece of user information Information, which can save network traffic.
But the drawback is that the storage consumption of hash structure is higher than that of a single string.
Next, let's look at the operation:
Encapsulation statement of hash dictionary in Java (part)
// Pass in the corresponding parameters according to your needs // Main statements of set method redisTemplate.opsForHash(). ; // The latter method is written according to your application scenario

Set
Introduction to set set
The Redis collection is equivalent to the HashSet in Java. The internal key values are unordered and unique, that is, we often use Set to remove duplication in Java.
The Redis collection is equivalent to a special dictionary. The key value of each key in the dictionary is NULL. Like other data structures, when the last element is removed, the data structure is deleted and the memory is recycled.
Next, let's look at the operation instructions:

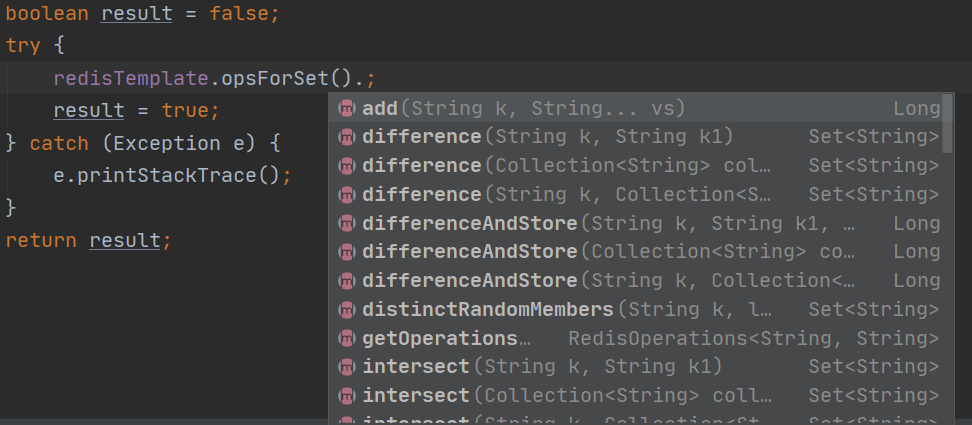
Encapsulation statement (part) of set set in Java
// Pass in the corresponding parameters according to your needs // Main statements of set method redisTemplate.opsForSet(). ; //The latter method is written according to your application scenario
Zset (ordered list)
zset has a sequence table
zset is also a set, which ensures the uniqueness of the internal value, and gives each value a score to represent the sorting weight of the value.
What can zset be used for? For example, if you open the fan list, value stores user information, score stores attention time, and the fan list can be displayed in order of attention time... And so on. I won't elaborate too much here.
Let's take a look at the operation:
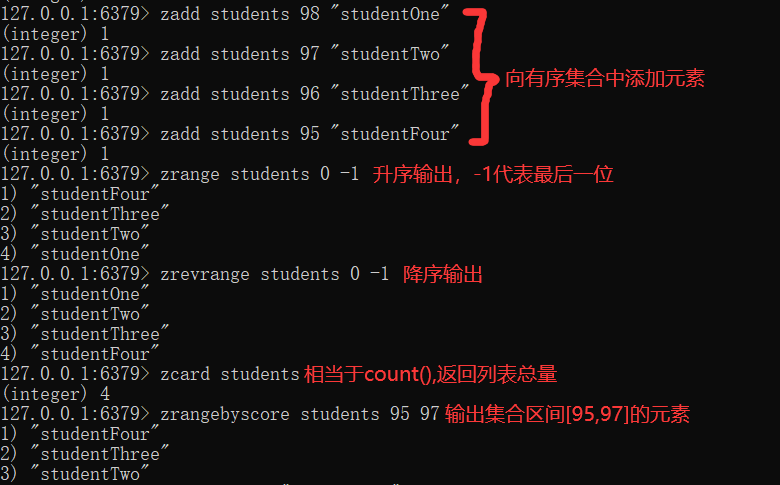
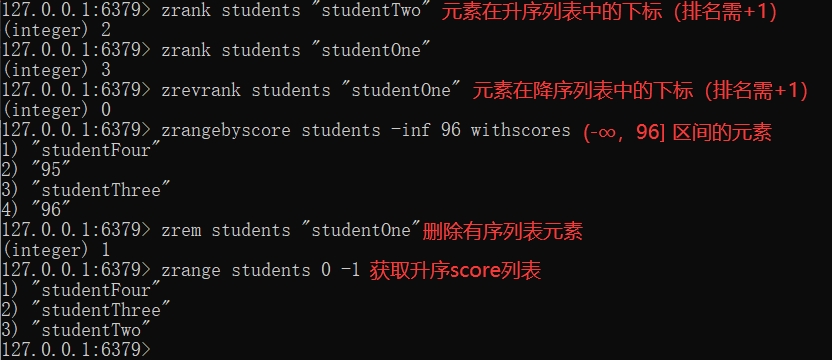
Encapsulation statement (part) of zset with sequence table in Java
// Pass in the corresponding parameters according to your needs // Main statements of set method redisTemplate.opsForZSet(). ; // The latter method is written according to your application scenario
