js regular expression
Add, delete, modify and check the string
Ant design example
:formatter="value => `$ ${value}`.replace(/\B(?=(\d{3})+(?!\d))/g, ',')"
:parser="value => value.replace(/\$\s?|(,*)/g, '')"
Simple sample
Common methods:
test: the return value is true or false
Match: returns an array of matching characters. If no match is found, null is returned.
let hd='jingdezhnejig23487669djiel2345';
let nums=[...hd].filter(item => {
return item>='0' && item<='9'
})
console.log(nums)
nums=[...hd].filter(item => {
return !Number.isNaN(parseInt(item))
})
console.log(nums)
console.log(hd.match(/\d/g))
Create regular expressions
Literal
Variables cannot be used. eval is required to use variables
let hd='jingaghihecjijguirueit';
let a='u';
console.log(eval(`/${a}/g`).test(hd))
new RegExp
let pro = prompt('Please enter the character to be highlighted. Regular is supported')
let rg=new RegExp(pro,'g');
let titleDiv=document.querySelector('.title')
titleDiv.innerHTML=titleDiv.innerHTML.replace(rg,(search)=>{
return `<span style="color:red">${search}</span>`
})
------------—
Selector
First, / / the regular expression is a whole. How to divide it when you look at it.
|: selector. Parted ways, left and right
(): grouping. Subexpression, part of the entire expression.
let tel='010-66666666';
// 1. The problem is: '010' will also be matched, because | is divided.
console.log(/010|021\-\d{8}/g.test(tel))
// Correction method: add grouping ()
console.log(/(010|021)\-\d{8}/g.test(tel))
// 2. Add ^ at the beginning and end&
console.log(/^(010|021)\-\d{8}$/g.test(tel))
[] atomic table and () atomic group
[]
[xxx] Finally, the whole expression here is a single character. [abcde] expresses a or relationship, (a|b|c|d)
As long as characters appear in the atomic table, they match, which is optional.
-
[] expresses a range. [a-z], matching lowercase letters, where the - expression is a range. [abcde] expresses the a-e range.
-
The ^ symbol in [] expresses the meaning of taking non. For example, [^ a-z] is not lowercase.
-
Special characters in [] are treated as ordinary characters. For example [(a)], it will match the three characters (, a,) and.
Several examples
// Are they all in English const str=''; /^[a-zA-Z]+$/.test(str); // English included /[a-zA-Z]+/.test(str)
Three uses of brackets in regular expressions [] - JavaShuo
() grouping
Get (Reference) group
1.match
The result returned by match. In the case of matching, the first parameter is the result of the whole matching, followed by the matching content of each group.
2.RegExp.$1-$9
var regex=/(\d{4})-(\d{2})-(\d{2})/;
let dateStr='2021-11-26';
dateStr.match(regex);
console.log(RegExp.$1);
Back reference
Referring to a previously matched group is called a back reference.
\1 matches the same character before. I want to be the same as it. That's what I mean\ 2 \ 3 the same is true
var regex=/\d{4}(-|\/|\.)\d{2}\1\d{2}/; //Here is the code explanation
var string1="2017-06-12";
var string2="2017/06/12";
var string3="2017.06.12";
var string4="2016-06/12";
console.log(regex.test(string1)); // true
console.log(regex.test(string2)); // true
console.log(regex.test(string3)); // true
console.log(regex.test(string4)); // false
Here is an interesting example
var regex = /^((\d)(\d(\d)))\1\2\3\4$/; //Here is the code explanation var string = "1231231233"; console.log( regex.test(string) ); // true console.log( RegExp.$1 ); // 123 console.log( RegExp.$2 ); // 1 console.log( RegExp.$3 ); // 23 console.log( RegExp.$4 ); // 3
*There is an exception. When the referenced group does not exist, \ will escape the following characters\ 1 means that the following 1 has been escaped.
var regex = /\1\2\3\4\5\6\7\8\9/; console.log( regex.test("\1\2\3\4\5\6\7\8\9") ); //true console.log( "\1\2\3\4\5\6\7\8\9".split("") );// Here is the code explanation
Specific cases
Convert initial to uppercase
// There are several ways
var regex=/\b[a-zA-Z]/g
var regex=/(?:^|\s)\w/g
var str='my name is lucy !'
const string=str.replace(regex,(c)=>{
return c.toUpperCase();
})
console.log(string);
// There is another way
name = 'aaa bbb ccc';
uw=name.replace(/\b\w+\b/g, function(word){
return word.substring(0,1).toUpperCase()+word.substring(1);
});
// https://www.w3school.com.cn/jsref/jsref_replace.asp
Escape
\Usually indicates escape
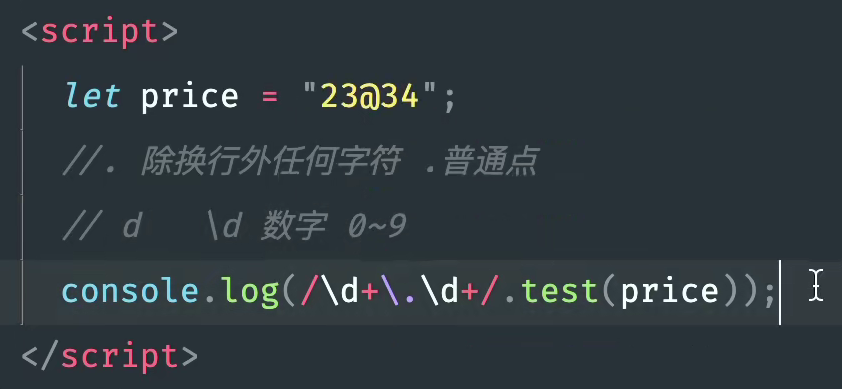
*Digression
In the object mode, because '\ d' = ='d ', new RegExp('\d+\.\d + ') may need to add an additional slash.
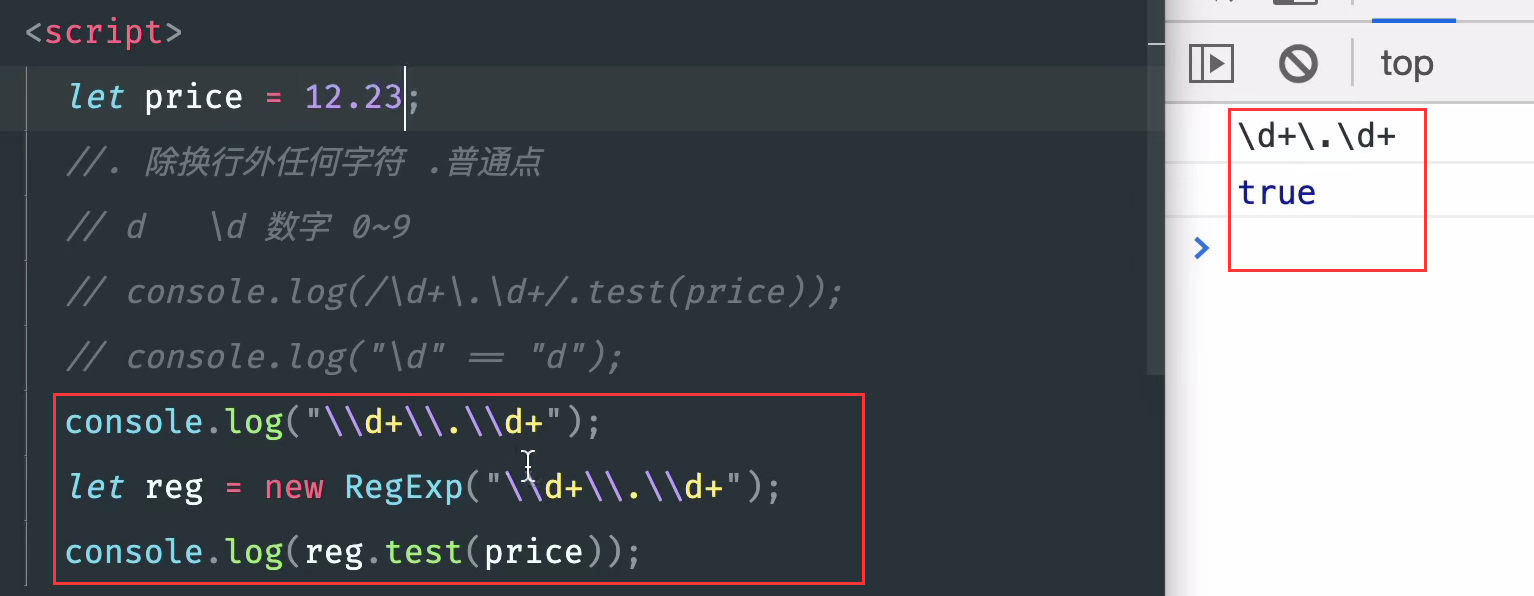
A character has multiple meanings. Convert it

^$: restricted boundary
^: start with xxx and define the start boundary
$: ends with xxx and defines the end boundary
This is defining our boundaries. It represents a complete and strict verification.
Here is an example:
If you do not add ^ $, you will be considered successful if you find it;
Now we need an exact match to qualify the entire string. Used for integrity verification, otherwise it is partial verification.
<input type="text" name="user"> <span></span>
document.querySelector('input[name="user"]').addEventListener('keyup',function(){
console.log(this.value)
var reg=/^[a-zA-Z]{3,6}$/
var text=reg.test(this.value)?'correct':'error'
document.querySelector('span').innerHTML=text
})
Metacharacter
Repeated quantifiers represent the number of repeated quantifiers that match a series of strings, that is, a greedy match.
For example \ d+
const str='houdunren 2021'; const reg=/\d+/g; // +: one or more // It matches four here at once str.match(reg); // ['2021']
\D and \ D
let str='houdunren 2021'; console.log(str.match(/\D+/g)); // ['houdunren '] str=` Zhang San:010-88888888,Li Si:021-88888888 ` // Now we want to match to Chinese str.match(/[^:\d-,\s]+/g) // ['Zhang San', 'Li Si']
\S and \ s
\s stands for white space characters: space, tab, line break, page break. These are all white space characters
\W and \ w
Here is an example of matching user names
Requirements: start with a letter, followed by letters, numbers and underscores, 5-10 digits
Comprehensive use: combined with poor paste matching, prohibition of greed, pattern modifier, assertion matching
const str='8houdunren';
const reg=/^[a-zA-Z]\w{4,9}$/;
console.log(reg.test(str));
Dot metacharacter
-
Dot metacharacter: any character (except newline character). So if you want to simply match points, you have to escape\
let str='https://wetest.qq.com' let reg=/^https?:\/\/\w+\.\w+\.\w+$/ console.log(str.match(reg))
-
But it cannot match the newline character
s mode: regarded as single line mode. Use line breaks as normal white space.
let hd=` houdunrencom houdun ` console.log(hd); console.log([...hd]); console.log(hd.match(/.+/g)); console.log(hd.match(/.+/s));
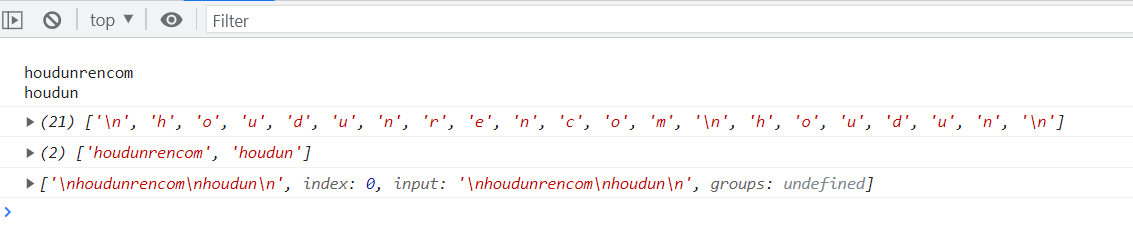
Extra: spaces are ordinary characters in regular. Just type spaces in regular, or use \ s.
Match any character
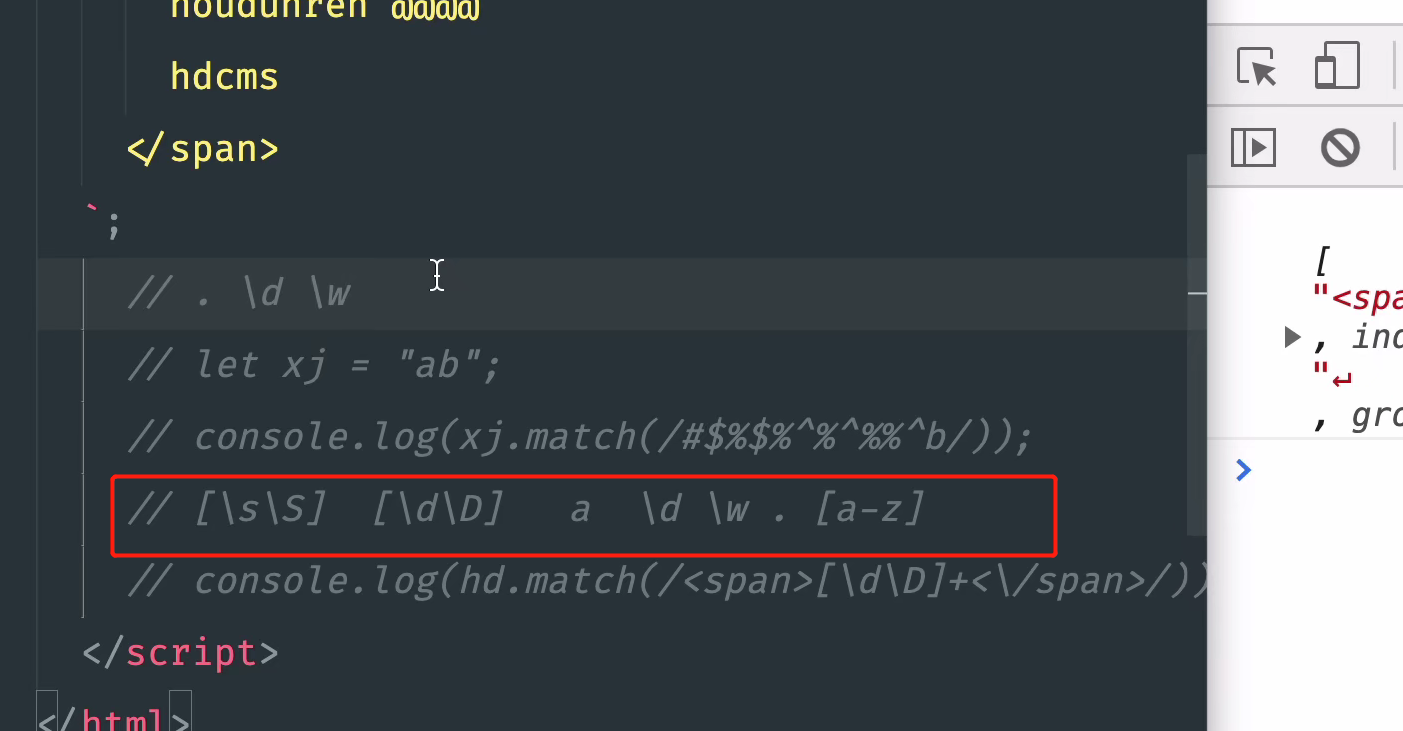
This expression is very ingenious. The blank expressed by \ s and the non blank expressed by \ s are the relationship of taking non. Then I [\ s \ S] express arbitrary characters. [\s\S] [\d\D]
let hd=`
<span>
houdunrencom @@@@@
houdun
</span>
`
console.log([...hd]);
console.log(hd.match(/<span>[\s\S]+<\/span>/));
Range of expression from small to large: a \ D \ W. [\ s \ S]
i and g mode modifiers
Pattern modifier: changes the way regular expressions run
/i: Ignore case. For example, e-mail and website capitalization are also OK
/g: Overall situation. greedy
m mode
This example is a little complicated
-
/m: First, multiline mode. Each line is extracted separately for matching. The M multi line mode mainly works for ^ $, making it match the head and tail of each line, because if / M is not set, a string has only a start ^ and end $, whether line feed or not. When each line of a large string needs to be processed separately, M mode is very suitable.
-
Then there is another detail. Pay attention to the spaces at the beginning and end of the line, and add \ s if necessary*
let hd=`
#1 js,200 element #
#2 php,300 element #
#91 houdunren.com # Backing person
#3 node.js,180 element #
`
console.log([...hd]);
// console.log(hd.match(/\s*#\d+\s+.+\s+#\s+/g))
// Pay particular attention to the \ s at the beginning and end of the line*
console.log(hd.match(/^\s*#\d+\s+.+\s+#$/gm))
let lines = hd.match(/^\s*#\d+\s+.+\s+#$/gm);
let lessons=lines.map(line=>{
console.log(line)
console.log('line.match===')
console.log(line.match(/\s*#\d+\s+(.+),(.+)\s+#/))
let [,name, price]=line.match(/\s*#\d+\s+(.+),(.+)\s+#/);
// Another way is to use replace to replace both the head and tail with ''
// let [name,price]=
// line.replace(/\s*#\d+\s+/,'').replace(/\s+#/,'').split(',')
return {name,price}
})
console.log('lessons:')
console.log(lessons)
u mode
Many knowledge points of character coding are involved here.
Regular expression (3): Unicode problems (Part 2)_ carvin_happy's column - CSDN blog
The use of front-end js regular \ p and the problem of global flag g_ Wang Weiren's blog - CSDN blog
Character encoding notes: ASCII, Unicode and UTF-8 - Ruan Yifeng's network log
Thoroughly understand unicode encoding_ Blog of hezh1994 - CSDN blog_ unicode encoding
In fact, here is the knowledge of unicode coding.
\p needs to be used in combination with / u mode
\p{L}: indicates a letter
\p{N}: represents a number
\p{P}: match punctuation
And its unicode script attribute, which can distinguish languages of different countries
let hd=`houdunren2010.Keep releasing tutorials, come on! English Punctuation!`
console.log(hd.match(/\p{P}/gu))
console.log(hd.match(/\p{sc=Han}/gu))
Another thing to note: if you encounter wide bytes, that is, 4 bytes, you also need to add / u
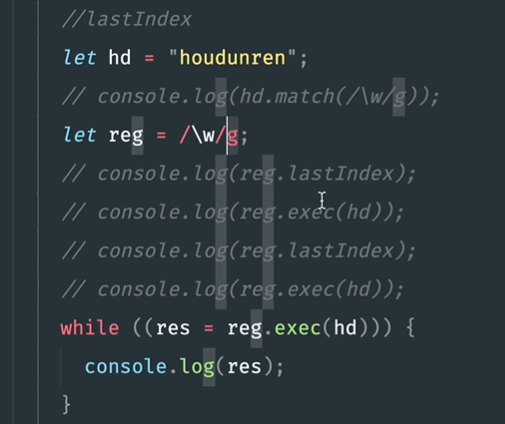
lastIndex and exec methods
The advantage of exec method is that it can record the details of each matching string. Its principle is to change lastIndex.
Get each master information
var str="I love antzone ,this is animate";
var reg=/an/;
console.log('Non Global-----------');
console.log(str.match(reg));
console.log('-----------');
console.log(reg.lastIndex);
console.log(reg.exec(str));
console.log(reg.lastIndex);
reg=/an/g;
console.log('overall situation-----------');
console.log('match-----------');
console.log(reg.lastIndex);
console.log(str.match(reg));
console.log(reg.lastIndex);
console.log('exec-----------');
console.log(reg.lastIndex);
console.log(reg.exec(str));
console.log(reg.lastIndex);
console.log(reg.exec(str));
console.log(reg.lastIndex);
console.log('while-----------');
reg.lastIndex=0;
console.log(reg.lastIndex);
let mat=[]
while(mat=reg.exec(str)){
console.log(mat);
}
Explanation of exec method of js regular expression_ uwenhao2008 blog - CSDN blog_ Regular Exec
y mode
lastIndex only works in g mode and y mode. In other cases, this lastIndex is completely ignored. Only g mode and y mode will read and update the value of lastIndex.
The difference between y mode and g mode: g mode will skip the mismatched string and continue to search backward; In y mode, as long as the current position string of lastIndex does not match, it will stop immediately and will not continue to search backward. That's the difference between the two. The y pattern means that the matching will stop when it does not meet the requirements. It will not continue to match in the future. It must meet the conditions continuously.
Grammatically speaking, y mode changes the meaning of ^ character and no longer represents the starting position of the whole string, but the current offset position.
var re = /^./y;
console.log(re.test("foo")); //true
console.log(re.lastIndex); //1
console.log(re.test("foo")); //true
console.log(re.lastIndex); //2
JavaScript: regular expression / y logo - ziyunfei - blog Garden
Function: let's match large strings more efficiently
let hd=`Backing person QQ group:6666666666,8888888888,9999999999 Backers continue to share video tutorials. The backers' website is www.houdunren.com`
let reg=/(\d+),?/y
let res;
console.log('---')
reg.lastIndex=7
let qq=[]
while(res=reg.exec(hd)){
console.log(res)
qq.push(res[1])
}
console.log('qq')
console.log(qq)