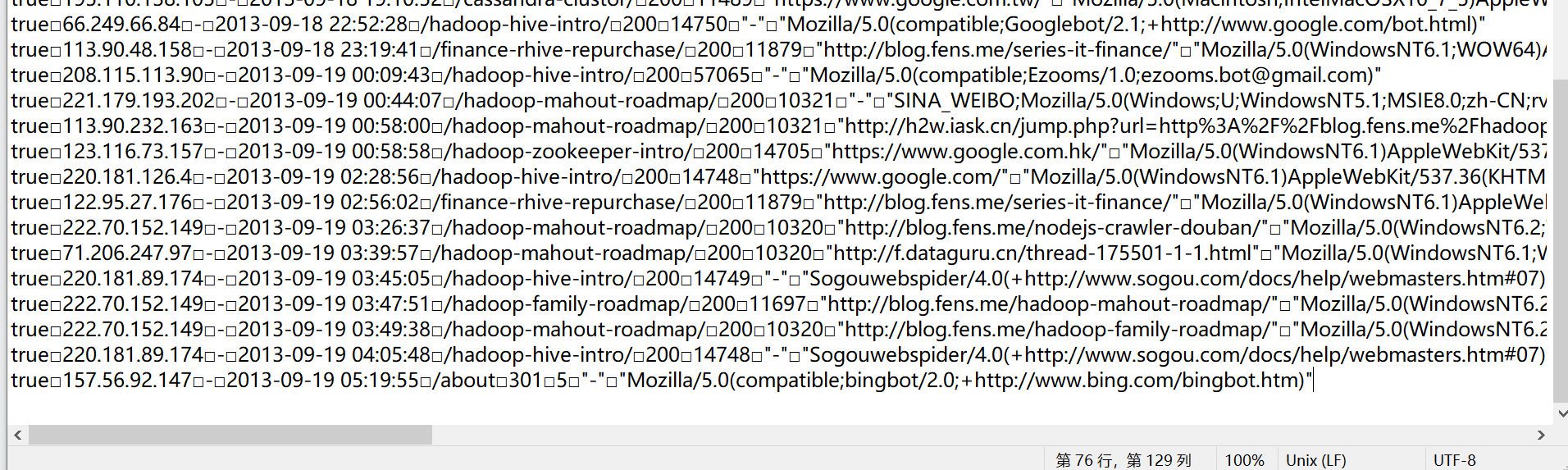
Introduction:
Functions: clean the collected log data, filter invalid data and static resources
Method: write MapReduce for processing
Classes involved:
1) Entity class Bean
Describe various fields of log data, such as client ip, request url, request status, etc
2) Tool class
Used to process beans: set the validity or invalidity of logs, and filter invalid logs
3) Map class
Write Map program
4) Driver class
Log data analysis first:
1. Log data splitting
Take a log data as an example for analysis:
194.237.142.21 - - [18/Sep/2013:06:49:18 +0000] "GET /wp-content/uploads/2013/07/rstudio-git3.png HTTP/1.1" 304 0 "-" "Mozilla/4.0 (compatible;)"
Log data has certain rules. Look at this log data. Each data is separated from each other by spaces, so we can:
1) Each log data is divided by spaces;
2) Define a string array to receive each log data;
//Create an entity Bean object
WebLogBean webLogBean = new WebLogBean();
//Split each line representing a log data and store it in a string array
String[] arr = line.split(" ");
However, not all log data will be the same as the above. Some may be very short (incomplete data) and some may be very long (the user browser information field is long)
Therefore, we need to judge the string array:
1) If the string length is less than 11, the data is incomplete. Do not use it directly
2) Length greater than 11
If the length is greater than 11 and greater than 12, the last field indicates that the user browser information is too long
At this time, we write the data in front of the string array into the Bean entity, store the string about the user browser in the string array into a StringBuilder object, and finally write it into the user browser information of the Bean entity
StringBuilder sb = new StringBuilder();
for(int i=11;i<arr.length;i++){ //Add all fields to sb from a[11] to the end
sb.append(arr[i]);
}If the length is greater than 11 but not greater than 12, that is, the length is equal to 12. For "standard" log data, you can directly write each data of the string array into the Bean entity
Therefore, there are three kinds of log data: 1. "Standard" 2. Incomplete data 3. Long data
2. Log data processing
1) Time
If the request time obtained from the string array is "null" or empty, write the entity "- invalid_time -" into the Bean
if(null==time_local || "".equals(time_local)) {
time_local="-invalid_time-";
}
webLogBean.setTime_local(time_local);Or if the time is not obtained, it is also considered invalid data
if("-invalid_time-".equals(webLogBean.getTime_local())){
webLogBean.setValid(false);
}2) Status code
If the request status code is greater than 400, it means that the request is wrong. We treat it as invalid data and write it to the Bean
if (Integer.parseInt(webLogBean.getStatus()) >= 400) {// Greater than 400, HTTP error
webLogBean.setValid(false);
}3) String array length
If the length of string array is less than 11 - incomplete data, it is invalid! Write Bean as null
webLogBean=null;
4) The requested url is not in our collection and is considered invalid! (collection customizable)
public static void filtStaticResource(WebLogBean bean, Set<String> pages) {
if (!pages.contains(bean.getRequest())) {//If the requested url is not in the collection defined by us, it will be regarded as a static resource and set to false
bean.setValid(false);
}
}Summary
Log data:
1. Less than 11: invalid
2. Greater than 11: valid, write
3. Greater than 12: the user browser is long and can be written after processing
Three points where Bean is invalid:
1. The time is empty, null, or the time cannot be obtained
2. The request is a static resource
3. The requested url does not belong to the collection (custom)
The directory structure is as follows:
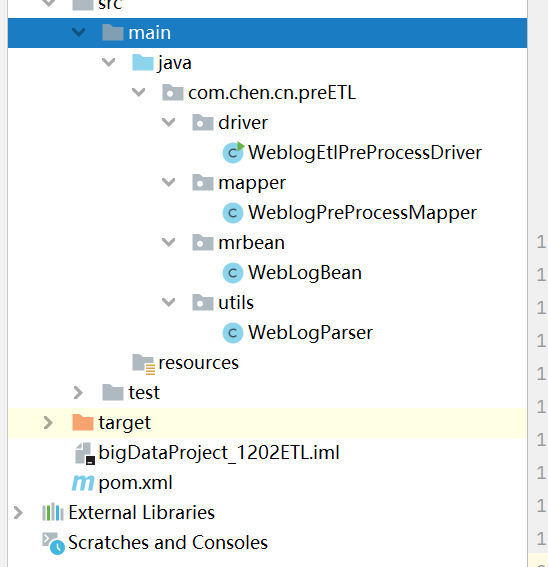
As the old rule, go to the pom file first:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.chen.cn</groupId>
<artifactId>bigDataProject_1202ETL</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<!--Set the item code to UTF-8-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--use java8 Encode-->
<maven.compiler.source>1.8</maven.compiler.source>
<!--use java8 To compile the source code-->
<maven.compiler.target>1.8</maven.compiler.target>
<!--set up hadoop Version of-->
<hadoop.version>3.1.2</hadoop.version>
</properties>
<!--jar Package dependency-->
<dependencies>
<!--Test dependent coordinates-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
<!--Dependent coordinates of log printing-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<!--hadoop Dependent coordinates of the general module-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--hadoop Yes HDFS Dependency coordinates of technical support for distributed file system access-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--hadoop Dependent coordinates for client access-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
</project>Entity class WebLogBean:
package com.chen.cn.preETL.mrbean;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class WebLogBean implements Writable {
private boolean valid = true;// Judge whether the data is legal
private String remote_addr;// Record the ip address of the client
private String remote_user;// Record client user name, ignoring attribute '-'
private String time_local;// Record access time and time zone
private String request;// Record the url and http protocol of the request
private String status;// Record request status; Success is 200
private String body_bytes_sent;// Record the file body a content size sent to the client
private String http_referer;// Used to record the links from that page
private String http_user_agent;// Record information about the client browser
public void set(boolean valid,String remote_addr, String remote_user, String time_local, String request, String status, String body_bytes_sent, String http_referer, String http_user_agent) {
this.valid = valid;
this.remote_addr = remote_addr;
this.remote_user = remote_user;
this.time_local = time_local;
this.request = request;
this.status = status;
this.body_bytes_sent = body_bytes_sent;
this.http_referer = http_referer;
this.http_user_agent = http_user_agent;
}
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return this.time_local;
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
/**
* \001 It is the default separator in hive and will not be typed by the user
* @return
*/
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(this.valid);
sb.append("\001").append(this.getRemote_addr());
sb.append("\001").append(this.getRemote_user());
sb.append("\001").append(this.getTime_local());
sb.append("\001").append(this.getRequest());
sb.append("\001").append(this.getStatus());
sb.append("\001").append(this.getBody_bytes_sent());
sb.append("\001").append(this.getHttp_referer());
sb.append("\001").append(this.getHttp_user_agent());
return sb.toString();
}
@Override
public void readFields(DataInput in) throws IOException {
this.valid = in.readBoolean();
this.remote_addr = in.readUTF();
this.remote_user = in.readUTF();
this.time_local = in.readUTF();
this.request = in.readUTF();
this.status = in.readUTF();
this.body_bytes_sent = in.readUTF();
this.http_referer = in.readUTF();
this.http_user_agent = in.readUTF();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeBoolean(this.valid);
out.writeUTF(null==remote_addr?"":remote_addr);
out.writeUTF(null==remote_user?"":remote_user);
out.writeUTF(null==time_local?"":time_local);
out.writeUTF(null==request?"":request);
out.writeUTF(null==status?"":status);
out.writeUTF(null==body_bytes_sent?"":body_bytes_sent);
out.writeUTF(null==http_referer?"":http_referer);
out.writeUTF(null==http_user_agent?"":http_user_agent);
}
}
Tool class WebLogParser
package com.chen.cn.preETL.utils;
import com.chen.cn.preETL.mrbean.WebLogBean;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Locale;
import java.util.Set;
//This is a tool class used to write the information of Bean entities,
public class WebLogParser {
public static SimpleDateFormat df1 = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.US);
public static SimpleDateFormat df2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss", Locale.US);
public static WebLogBean parser(String line) {
WebLogBean webLogBean = new WebLogBean();
//Cut our data through spaces, and then splice strings to splice the data in the same field
//222.66.59.174 -- [18/Sep/2013:06:53:30 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0"
String[] arr = line.split(" ");
if (arr.length > 11) {
webLogBean.setRemote_addr(arr[0]);
webLogBean.setRemote_user(arr[1]);
//Convert our string into Chinese customary string
// [18/Sep/2013:06:52:32 +0000]
// 18/Sep/2013:06:52:32------>2013-09-18 06:52:32
String time_local = formatDate(arr[3].substring(1)); //Gets the characters from 1 to the end
//If the obtained time is judged to be null or empty, it will be set as invalid time
if(null==time_local || "".equals(time_local)) {
time_local="-invalid_time-";
}
webLogBean.setTime_local(time_local);
webLogBean.setRequest(arr[6]); //Write the url requested by the user
webLogBean.setStatus(arr[8]); //Write the returned status code
webLogBean.setBody_bytes_sent(arr[9]); //The byte size of the returned content written
webLogBean.setHttp_referer(arr[10]); //Write the page from which the user accesses the open source
//If there are many useragent elements, splice useragent.
// "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; MDDR; InfoPath.2; .NET4.0C)"
if (arr.length > 12) { //If it is greater than 12, it means that the last field (user browser information) is too long for processing (add it all to the last field)
//StringBuilder is similar to StringBuffer. The object is a string with variable character sequence, that is, the object can be modified and re assigned. The difference is that StringBuilder has safe wireless process and slightly higher performance
StringBuilder sb = new StringBuilder();
for(int i=11;i<arr.length;i++){ //Add all fields to sb from a[11] to the end
sb.append(arr[i]);
}
webLogBean.setHttp_user_agent(sb.toString()); //Finally, sb is converted into a string and written into the entity Bean
} else { //Greater than 11 but not greater than 12, i.e. equal to 12. If equal to 12, it will be written directly into the entity Bean
webLogBean.setHttp_user_agent(arr[11]);
}
//If the request status code is greater than 400, it is considered that the request is wrong, and the wrong data is directly considered as invalid data
if (Integer.parseInt(webLogBean.getStatus()) >= 400) {// Greater than 400, HTTP error
webLogBean.setValid(false);
}
//If the acquisition time is not obtained, it is also considered invalid data
if("-invalid_time-".equals(webLogBean.getTime_local())){
webLogBean.setValid(false);
}
} else { //If the length of the cut array is less than 11, it indicates that the data is incomplete and is directly discarded
//58.215.204.118 - - [18/Sep/2013:06:52:33 +0000] "-" 400 0 "-" "-"
webLogBean=null;
}
return webLogBean; //Return entity Bean
}
//Summary: field: 1. Less than 11: invalid; 2. Greater than 11: valid; 3. Greater than 12: the last field (user browser information) is too long,
// Just define a StringBuilder to store them, and then write the StringBuilder to the last field
// The Bean is invalid for three points: 1. The time is invalid. 2. The request is a static resource. 3. The requested url is not our custom url
//Filter according to the custom url. If the url requested by this Bean does not belong to the page collection, it is not the log data we want, so it is eliminated
public static void filtStaticResource(WebLogBean bean, Set<String> pages) {
if (!pages.contains(bean.getRequest())) {
bean.setValid(false);
}
}
//Format time method
public static String formatDate(String time_local) {
try {
return df2.format(df1.parse(time_local));
} catch (ParseException e) {
return null;
}
}
}
WeblogPreProcessMapper
package com.chen.cn.preETL.mapper;
import com.chen.cn.preETL.mrbean.WebLogBean;
import com.chen.cn.preETL.utils.WebLogParser;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
public class WeblogPreProcessMapper extends Mapper<LongWritable, Text, Text, NullWritable>
{
// It is used to store website url classification data, i.e. customized url. Log data can be filtered according to this collection. If the url requested by the user is not in this collection, it is "invalid" data
Set<String> pages = new HashSet<String>();
Text k = new Text();
NullWritable v = NullWritable.get();
/**
* map Initialization method of phase
* Load the useful url classification data of the website from the external configuration file and store it in the memory of maptask to filter the log data
* Filter out some static resources in our log files, including JS, CSS, IMG and other request logs
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//Define a collection
pages.add("/about");
pages.add("/black-ip-list/");
pages.add("/cassandra-clustor/");
pages.add("/finance-rhive-repurchase/");
pages.add("/hadoop-family-roadmap/");
pages.add("/hadoop-hive-intro/");
pages.add("/hadoop-zookeeper-intro/");
pages.add("/hadoop-mahout-roadmap/");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//Get us a line of data
String line = value.toString();
WebLogBean webLogBean = WebLogParser.parser(line);
if (webLogBean != null) { //webLogBean is null only when there are less than 11 fields (incomplete data)
// Filter static resources such as js / pictures / css
WebLogParser.filtStaticResource(webLogBean, pages);
if (!webLogBean.isValid()) return;
k.set(webLogBean.toString());
context.write(k, v);
}
}
}
WeblogEtlPreProcessDriver
package com.chen.cn.preETL.driver;
import com.chen.cn.preETL.mapper.WeblogPreProcessMapper;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class WeblogEtlPreProcessDriver {
static { //dll files must be added to run on windows
try {
// Set HADOOP_HOME directory
System.setProperty("hadoop.home.dir", "E:\\winutils-master\\hadoop-3.0.0");
// Load library file
System.load("E:\\winutils-master\\hadoop-3.0.0\\bin\\hadoop.dll");
} catch (UnsatisfiedLinkError e) {
System.err.println("Native code library failed to load.\n" + e);
System.exit(1);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
FileInputFormat.addInputPath(job,new Path("D:\\data\\ETL_Input")); //Set input file path
job.setInputFormatClass(TextInputFormat.class); //Enter file type
FileOutputFormat.setOutputPath(job,new Path("///D:\data\weblogPreOut2 "); / / set the storage path of processed files
job.setOutputFormatClass(TextOutputFormat.class); //Output file type
job.setJarByClass(WeblogEtlPreProcessDriver.class); //Set the driver class to this class
job.setMapperClass(WeblogPreProcessMapper.class);//Specifies the map class to run
job.setOutputKeyClass(Text.class);//Set the data type of the output key
job.setOutputValueClass(NullWritable.class); //Set the data type of the output value
job.setNumReduceTasks(0);
boolean res = job.waitForCompletion(true);
}
}
Driver class:
The storage and output locations of log data files are configured:
Set the input file type and output file type; specify the map class to run;
Set the data types of key and value output by the map class
Since the program is debugged and run on Windows, you need to configure hadoop.dll file:
static { //dll files must be added to run on windows
try {
// Set HADOOP_HOME directory
System.setProperty("hadoop.home.dir", "E:\\winutils-master\\hadoop-3.0.0");
// Load library file
System.load("E:\\winutils-master\\hadoop-3.0.0\\bin\\hadoop.dll");
} catch (UnsatisfiedLinkError e) {
System.err.println("Native code library failed to load.\n" + e);
System.exit(1);
}
}There are less than 15000 files before executing the program to filter the log:
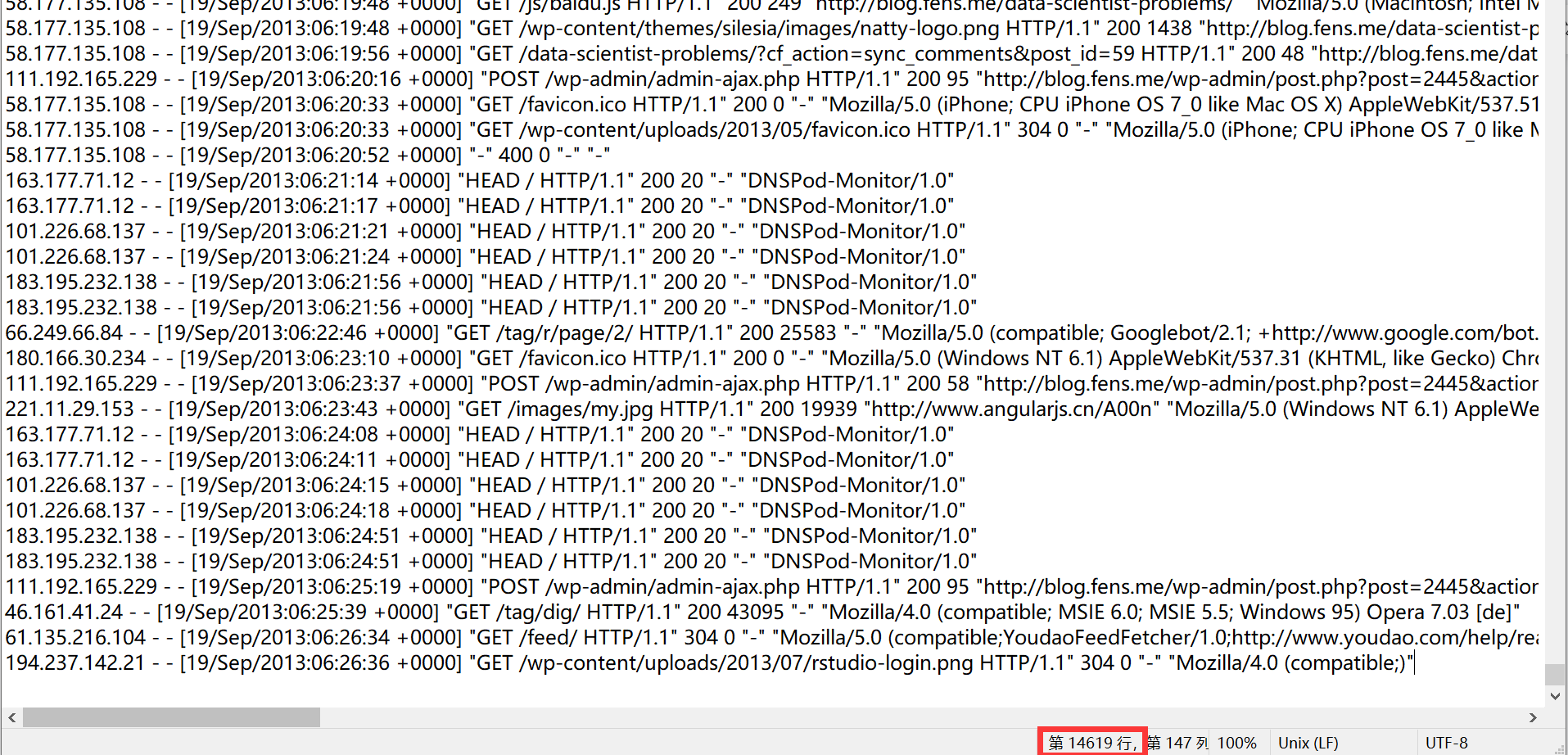
Execution procedure:

Successfully run view results:
After cleaning, the log data ranges from 15000 to 76: