Why did you write this article?
It's been a long time since I updated the crawler articles. How can I not learn the good technology from entry to prison. So, today I continue to roll. This paper will introduce a complete crawler from the perspective of actual combat. Here take the film paradise website known to women and children as an example. I hope readers can be inspired and gain.
Article catalog- Why did you write this article?
- 0. First analyze
- 1. Specify the contents to be crawled
- 2. Analyze crawling steps
- 2. Crawl list page
- 2.1. Find out the characteristics of the url of the list page
- 2.2. Find out the total number of pages
- 2.3. Find the url of the details page
- 3. Crawl detail page data
- 3.1 getting movie titles
- Get the movie title & Director & starring and other information
- Multithreading operation
- Save data
- Final complete source code
- Final operation effect
- Finally
- Exclusive benefits for fans
- 1. Specify the contents to be crawled
- 2. Analyze crawling steps
- 2.1. Find out the characteristics of the url of the list page
- 2.2. Find out the total number of pages
- 2.3. Find the url of the details page
- 3.1 getting movie titles
- Get the movie title & Director & starring and other information
- Final operation effect
0. First analyze
I always feel that before crawling, we first need to clarify the content to climb, and then analyze the steps of crawling, what to climb first and what to climb later; Then match the content to be extracted through Xpath; The last is to write crawler code.
1. Specify the contents to be crawled
- The content we crawl here is the detailed information and download links of each film under the latest film column. The page of the latest movie is shown in Figure 1:
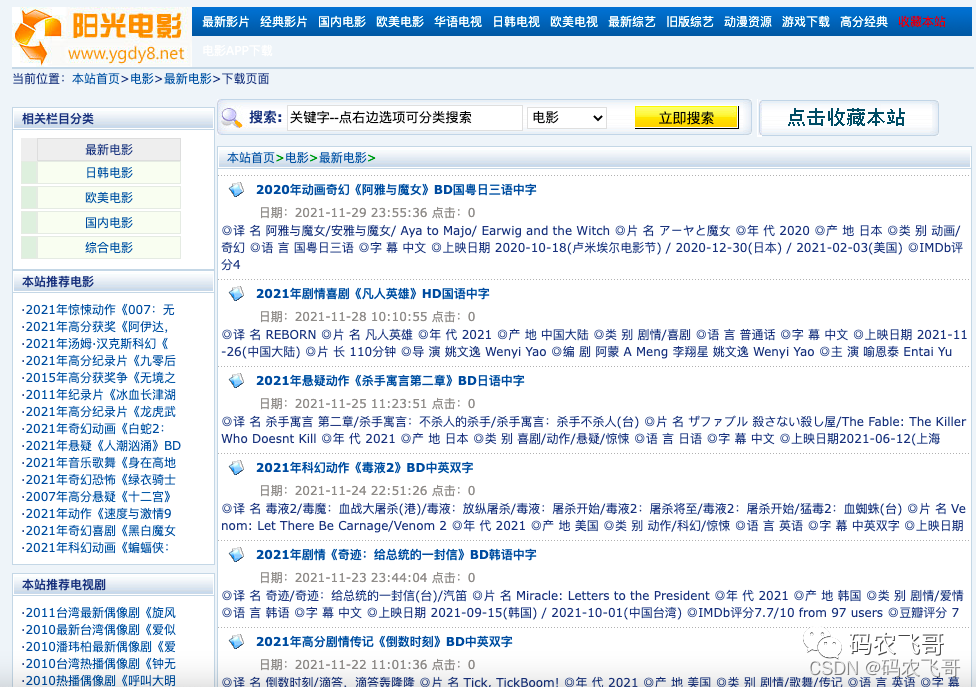
Here, take the movie mortal hero as an example. The detailed information of the movie, including the title, director, actor and other information, is what we need to crawl.
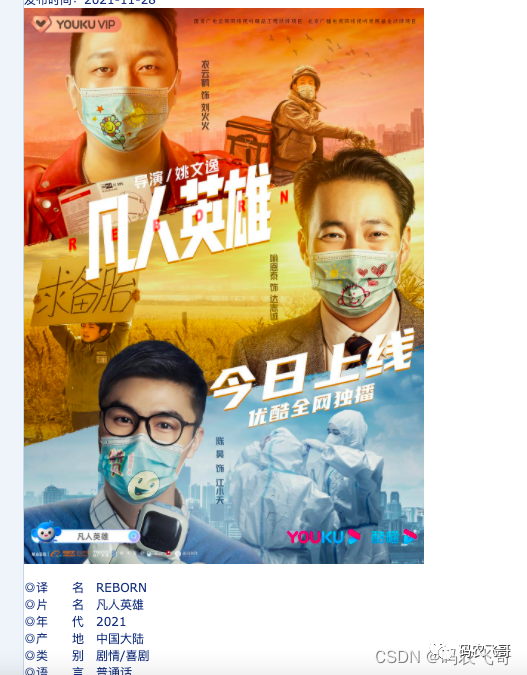
2. Analyze crawling steps
There is no doubt that in this scenario, we first need to crawl the data of the following table page of the latest film column. On this page, we mainly crawl the link of each film details page. Then you can crawl the detailed data of the detail page according to the link of the detail page.
2. Crawl list page
The first is to crawl the list page to get the address of the details. On the Chrome browser, press the F12 button to open the debugging window for simple analysis.
2.1. Find out the characteristics of the url of the list page
The address of the front page is: https://www.ygdy8.net/html/gndy/dyzz/index.html We can't find any characteristics. Then we click the second page to see that the url on the second page becomes https://www.ygdy8.net/html/gndy/dyzz/list_23_2.html Click the third page and find that the url of the third page becomes https://www.ygdy8.net/html/gndy/dyzz/list_23_3.html By analogy, we can conclude that the page address on page n is: https://www.ygdy8.net/html/gndy/dyzz/list_23_n.html.
2.2. Find out the total number of pages
Open the XPath helper plug-in, and through analysis, you can get / / div[@class="x"] you can get the div tag containing the total number of pages, and then //div[@class="x"]//text() can get what we want. Expression interpretation: / / div[@class="x"] indicates that the div tag whose class attribute is x is matched from the whole page. //text() means to get all the text under the label.
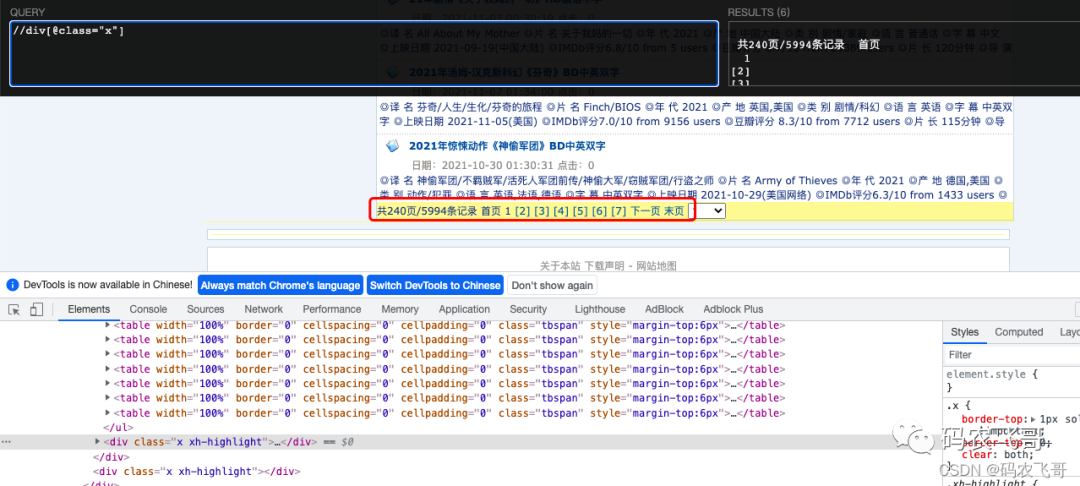
# Find the contents of the paging plug-in. The strip method is used to remove spaces
total_pages_element = html.xpath('//div[@class="x"]//text()')[1].strip()
#Extract the index position of common words
start_index = total_pages_element.find('common')
#Extract the index position of the page word
end_index = total_pages_element.find('page')
# Between total words and page words is the total number of pages we want
total_pages = total_pages_element[start_index + 1:end_index]
2.3. Find the url of the details page
Similarly, we can select a movie title on the list page. Through debugging, we can know that the link of each movie detail page is in the < a class = "ulink" > tag under the < tr > tag under the < table class = "tbspan" > tag and the < td > tag under the < td > tag. Isn't that a little windy. It doesn't matter. You only need to do this through xpath expression / / a[@class="ulink"]/@href expression. Expression interpretation: / / a[@class="ulink"] indicates that the matching class attribute is the a tag of ulink from the whole page/@ Href means to get the attribute value of href under the tag. Of course, the / / table[@class="tbspan"]//a/@href expression can extract the data we want. If you are not familiar with XPath expressions, you can read this article to learn about XPath (Mastering XPath syntax) [advanced introduction to python crawler] (03).
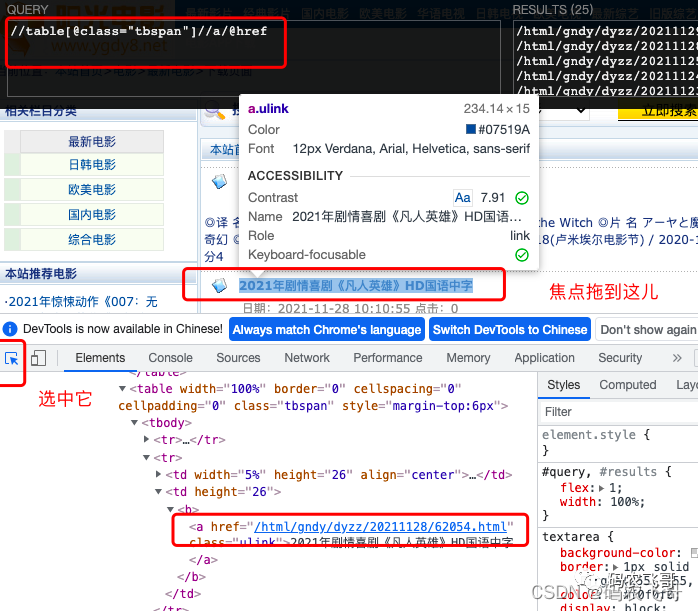
It should be noted that the link in the href tag is not a complete link. The complete link needs to be added with a domain name https://www.ygdy8.net . Therefore, the link code is:
BASE_DOMAIN = 'https://www.ygdy8.net'
resp = requests.get(page_url, headers=headers)
html = etree.HTML(resp.content.decode(BASE_ENCODING))
# Get the address of the movie details page
detail_url_list = html.xpath('//table[@class="tbspan"]//a/@href')
#Splice the address of the detail page into a complete address
new_detail_url_list = [BASE_DOMAIN + detail_url for detail_url in detail_url_list]
3. Crawl detail page data
After you get the address of the detail page, you can get the detailed data of the detail page. This is also relatively simple. First, open the details page for analysis. Here, take "mortal hero" as an example, and the analysis steps are similar to those on the list page.
3.1 getting movie titles
Through / / div[@class="title_all"]//font/text(), expression interpretation: / / div[@class="title_all"] means that the matching class attribute from the whole page is title_ Div tag for all// div[@class="title_all"] / / fontobtain the font tag from the div tag obtained in the first step of the tag. The text() method is still to get the label content.
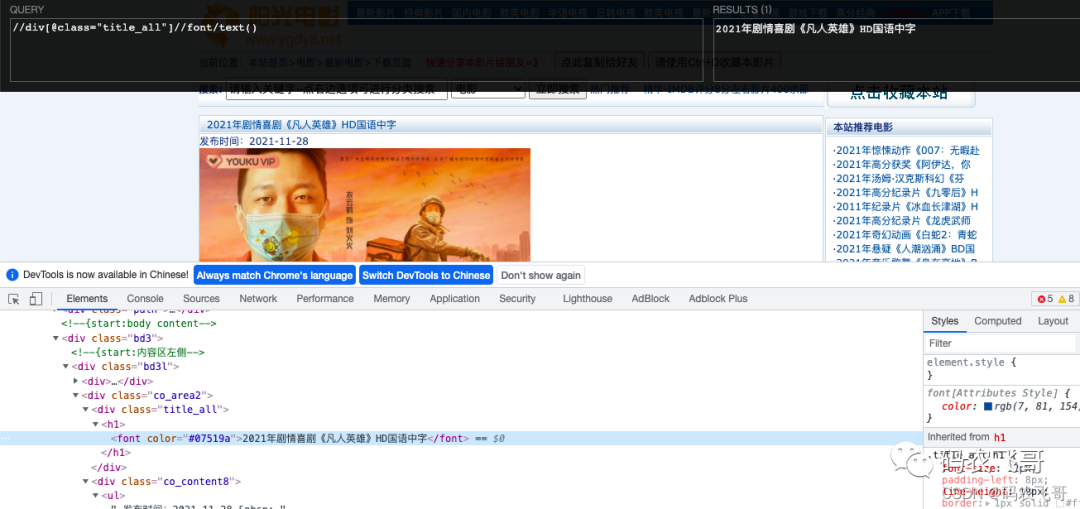
The release time of the movie and the acquisition of movie posters are similar to the movie title, so I won't repeat it here.
Get the movie title & Director & starring and other information
Through debugging, we can know that the film title, director and starring are under the < div id = "zoom" > label.
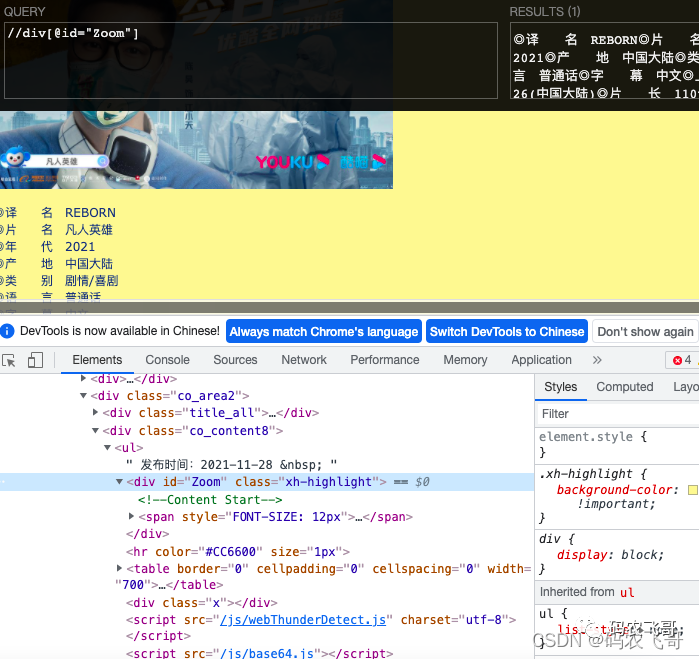
Other basic information is divided by < br > tags. Therefore, after obtaining all the text information under the / / div[@id="Zoom"] tag, we can obtain the data we want, and then match the obtained data. Here is the complete code.
movie = {}
# Get all information
zoomE = html.xpath('//div[@id="Zoom"]')[0]
# Get all information
infos = zoomE.xpath('.//text()')
for info in infos:
info = info.strip()
if info.startswith('◎translate name'):
movie['translate_name'] = info.replace('◎translate name', "")
elif info.startswith('◎slice name'):
movie['name'] = info.replace('◎slice name', "")
elif info.startswith('◎year generation'):
movie['year'] = info.replace('◎year generation', "")
elif info.startswith('◎yield land'):
movie['place'] = info.replace('◎yield land', "'")
elif info.startswith('◎Release date'):
movie['release_time'] = info.replace('◎Release date', "")
elif info.startswith('◎Douban score'):
movie['score'] = info.replace('◎Douban score', "")
elif info.startswith('◎slice long'):
movie['film_time'] = info.replace('◎slice long', "")
elif info.startswith('◎guide Play'):
movie['director'] = info.replace('◎guide Play', "")
elif info.startswith('◎main Play'):
# Get actors
index = infos.index(info)
info = info.replace('◎main Play', "")
actors = [info]
for x in range(index + 1, len(infos)):
actor = infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie['actors'] = actors
elif info.startswith('◎mark sign'):
movie['label'] = info.replace('◎mark sign', "")
elif info.startswith('◎simple Introduce'):
try:
index = infos.index(info)
for x in range(index + 1, len(infos)):
profile = infos[x].strip()
if profile.startswith('Magnetic chain'):
break
movie['profile'] = profile
except Exception:
pass
A movie dictionary is defined here to store the obtained movie details. Here, all the data obtained are traversed, and each row of data is obtained by string matching. Take the translation name as an example. First, whether the matching current string starts with the translation name of ◎. If so, replace the ◎ translation name to get the data REBORN we want. The principle of other film titles and places of origin is the same, so I won't repeat it here. The key point is: the starring information, because there is more than one starring, all need special treatment.
elif info.startswith('◎main Play'):
# Get actors
index = infos.index(info)
info = info.replace('◎main Play', "")
actors = [info]
for x in range(index + 1, len(infos)):
actor = infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie['actors'] = actors
The first is to obtain the position index of the current information info in the infos list, which is to define a list. The first element in the list is the starring name ranked first. Then traverse the elements in infos. The start position of traversal is index+1, and the end position is len(infos), excluding this position. When matching to the next ◎ symbol, the cycle ends.
Multithreading operation
As the title says, in order to improve the efficiency of the crawler, the data crawling task of each page is handed over to a separate thread to execute. These threads are managed by the thread pool. The specific code is:
from multiprocessing.pool import ThreadPool
#Create a thread pool of size 20
page_pool = ThreadPool(processes=20)
#Asynchronous request details page data
page_pool.apply_async(func=get_current_page_detail_url,
args=(
BASE_DOMAIN + '/html/gndy/dyzz/' + 'list_23_' + str(
current_page) + '.html',))
Save data
Here, the crawled data is simply saved to txt text. The code for saving data is:
def save_data(content):
content_json = json.dumps(content, ensure_ascii=False)
with open(file='content.txt', mode='a', encoding='utf-8') as f:
f.write(content_json + '\n')
Final complete source code
# -*- utf-8 -*-
"""
@url: https://blog.csdn.net/u014534808
@Author: Mainong Feige
@File: list.py
@Time: 2021/12/3 10:15
@Desc: Crawl list page
"""
from lxml import etree
import requests
from multiprocessing.pool import ThreadPool
import threading
import json
BASE_DOMAIN = 'https://www.ygdy8.net'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36',
'Cookie': 'XLA_CI=f6efcd6e626919703161043f280f26e6'
}
BASE_ENCODING = 'gbk'
page_pool = ThreadPool(processes=20)
# Get the addresses of all pages
def get_total_page():
url = 'https://www.ygdy8.net/html/gndy/dyzz/index.html'
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.content.decode(BASE_ENCODING))
total_pages_element = html.xpath('//div[@class="x"]//text()')[1].strip()
start_index = total_pages_element.find('common')
end_index = total_pages_element.find('page')
total_pages = total_pages_element[start_index + 1:end_index]
for current_page in range(1, int(total_pages)):
page_pool.apply_async(func=get_current_page_detail_url,
args=(
BASE_DOMAIN + '/html/gndy/dyzz/' + 'list_23_' + str(
current_page) + '.html',))
def get_current_page_detail_url(page_url):
resp = requests.get(page_url, headers=headers)
html = etree.HTML(resp.content.decode(BASE_ENCODING))
# Get the address of the movie details page
detail_url_list = html.xpath('//table[@class="tbspan"]//a/@href')
new_detail_url_list = [BASE_DOMAIN + detail_url for detail_url in detail_url_list]
movies = []
for detail_url in new_detail_url_list:
print(threading.current_thread().getName() + " " + detail_url)
movies.append(get_movie_detail(detail_url))
save_data(movies)
return movies
def get_movie_detail(movie_url):
resp = requests.get(movie_url, headers)
html = etree.HTML(resp.content.decode(BASE_ENCODING))
movie = {}
# Get movie title
movie_title = html.xpath('//div[@class="title_all"]//font/text()')[0].strip()
movie['movie_title'] = movie_title
# Get publishing time
publish_time = html.xpath('//div[@class="co_content8"]/ul/text()')[0].strip()
movie['publish_time'] = publish_time
# Get movie posters
movie_poster_url = html.xpath('//div[@class="co_content8"]//img/@src')[0].strip()
movie['movie_poster_url'] = movie_poster_url
# Get all information
zoomE = html.xpath('//div[@id="Zoom"]')[0]
# Get all information
infos = zoomE.xpath('.//text()')
for info in infos:
info = info.strip()
if info.startswith('◎translate name'):
movie['translate_name'] = info.replace('◎translate name', "")
elif info.startswith('◎slice name'):
movie['name'] = info.replace('◎slice name', "")
elif info.startswith('◎year generation'):
movie['year'] = info.replace('◎year generation', "")
elif info.startswith('◎yield land'):
movie['place'] = info.replace('◎yield land', "'")
elif info.startswith('◎Release date'):
movie['release_time'] = info.replace('◎Release date', "")
elif info.startswith('◎Douban score'):
movie['score'] = info.replace('◎Douban score', "")
elif info.startswith('◎slice long'):
movie['film_time'] = info.replace('◎slice long', "")
elif info.startswith('◎guide Play'):
movie['director'] = info.replace('◎guide Play', "")
elif info.startswith('◎main Play'):
# Get actors
index = infos.index(info)
info = info.replace('◎main Play', "")
actors = [info]
for x in range(index + 1, len(infos)):
actor = infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie['actors'] = actors
elif info.startswith('◎mark sign'):
movie['label'] = info.replace('◎mark sign', "")
elif info.startswith('◎simple Introduce'):
try:
index = infos.index(info)
for x in range(index + 1, len(infos)):
profile = infos[x].strip()
if profile.startswith('Magnetic chain'):
break
movie['profile'] = profile
except Exception:
pass
return movie
def save_data(content):
content_json = json.dumps(content, ensure_ascii=False)
with open(file='content.txt', mode='a', encoding='utf-8') as f:
f.write(content_json + '\n')
if __name__ == '__main__':
get_total_page()
page_pool.close()
page_pool.join()
Final operation effect

Finally
Taking movie paradise as an example, this paper mainly uses the learned xpath expressions and the relevant knowledge points of requests library to crawl.