Click on "end of life", pay attention to the official account.
Daily technical dry goods, delivered at the first time!
Up to 70% of the problems encountered with kubernetes can be attributed to network problems. Recently, it was found that if the kernel parameter: Bridge NF call iptables is not set properly, it will affect the pod on the Node in kubernetes. There will be a timeout when accessing other pods on the same Node through ClusterIP. Repeat the disk to record the cause and effect of the troubleshooting.
1. Problem phenomenon
The cluster environment is k8s v1 15.9, cni specifies the flannel vxlan and portmap, and Kube proxy uses the mode ipvs
The problem is that when the pod on a Node accesses other services through the service, some can pass, some can't pass, and if it doesn't pass, it will prompt timeout
Abnormal request:
$ curl -v http://panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080 * Rebuilt URL to: http://panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080/ * Trying 10.233.53.172... * TCP_NODELAY set # Wait here until it times out
Many pod s on this node have this problem, and no exceptions are found on other nodes
Normal request:
$ curl -v http://panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080 * Rebuilt URL to: http://panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080/ * Trying 10.233.53.172... * TCP_NODELAY set * Connected to panorama-v2-frontend-service.spring-prod.svc.cluster.local (10.233.53.172) port 8080 (#0) > GET / HTTP/1.1 > Host: panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080 > User-Agent: curl/7.52.1 > Accept: */* > < HTTP/1.1 200 OK
2. Troubleshooting process
First, check the abnormal Node because other nodes are normal. After checking the network, Kube proxy, iptables, ipvs rules and kubelet of the abnormal Node, no suspicious place is found, so the suspicion is temporarily eliminated.
The second suspect is DNS. coreDNS is responsible for resolving the service into ClusterIP. After many tests on the faulty Node, it can be resolved correctly. coreDNS eliminates the suspect.
If the suspicious places are screened and fruitless, we can only find them from the phenomenon to see if there are any similarities.
First, the access path is: Service – > ClusterIP – > PodIP
coreDNS has been excluded from service access exceptions. How about bypassing the service and using ClusterIP directly? After the test, the phenomenon remains the same. In addition, pay attention to the company's "final code life", reply to the keyword "data", and obtain video tutorials and the latest interview data!
What about bypassing ClusterIP and using PodIP directly? Bingo, previous visits that would cause problems are normal.
Then the problem lies in CluterIP – > podip, and there are the following possibilities:
ClusterIP is not correctly forwarded to PodIP, which may cause timeout
-
If forwarded correctly, the response does not return, which may also cause a timeout
The first possibility is easy to check. It has been confirmed that there are no problems with ipvs rules and iptables rules, and requests initiated through ClusterIP can reach PodIP, which basically eliminates the first possibility
In addition, by comparing normal and abnormal requests, it can be found that the original pod and the target pod of the abnormal request are on the same Node, while the normal request is on a different Node. Will this affect?
The second possibility above is that we can only sacrifice the packet capture artifact tcpdump. Through packet capture discovery (see the article for the packet capture process), we will find that Reset appears in the request
Then the question is changed: why does the PodB response not return when the podA accesses the PodB through service/ClusterIP on the same Node, but it is OK to access through PodIP?
It is added that the mutual access of pod s on the same Node does not need to pass through the Flannel, so the Flannel can eliminate the suspicion
so, what's the problem?
Returning to the packet capture data of tcpdump, we can find that the response data is not returned according to the requested path, um, Interesting
3. Culprit
In both iptables and ipvs modes, when accessing a service in Kubernetes, DNAT will be performed. The packet DNAT originally accessing the ClusterIP:Port will be transformed into an Endpoint (PodIP:Port) of the service, and then the kernel will insert the connection information into the conntrack table to record the connection. When the destination returns the packet, the kernel will match the connection from the conntrack table and SNAT, In this way, the original path returns to form a complete connection link
From tcpdump, we can see that the request has been reset. Yes, the bridge NF call iptables (net. Bridge. Bridge NF call IP6 tables if ipv6) parameter
But no, is this parameter enabled by default in linux? Did someone modify it?
Use the command to check whether the parameter is on:
$ cat /proc/sys/net/bridge/bridge-nf-call-iptables # 0
If 0 is returned, it indicates that it is not enabled (it was later confirmed that it was modified by colleagues). How does this parameter affect the return path?
Then I have to say linux bridge!
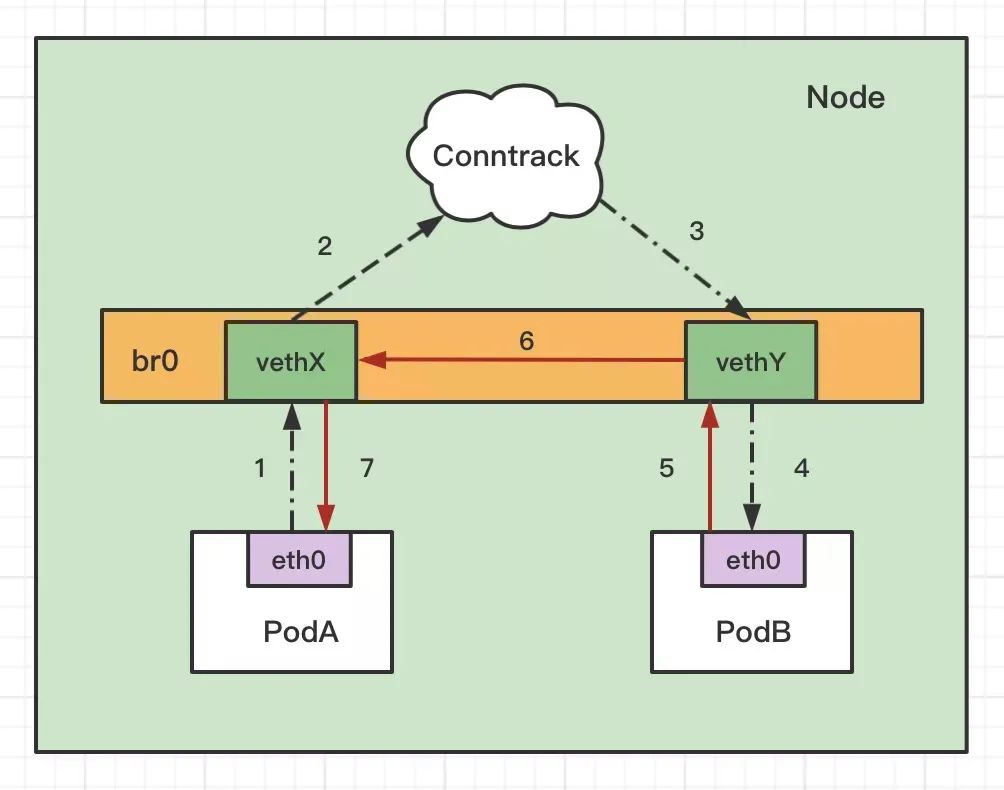
Although CNI uses flannel, flannel also encapsulates linux bridge. linux bridge is a virtual layer-2 forwarding device, while iptables conntrack is on layer-3. Therefore, if you directly access the address (ip, the same network segment) in the same bridge, you will directly go through layer-2 forwarding without going through conntrack:
According to the above figure, the access path of the same Node accessing the pod through the service is as follows:
PodA accesses the service and resolves it into Cluster IP through coreDNS, which is not the address in the bridge (ClusterIP is generally not in the same network segment as PodIP). Go to Conntrack for DNAT to convert ClusterIP into PodIP:Port
-
After DNAT, it is found that the packet is to be forwarded to PodB on the same node. When PodB returns the packet, it is found that the destination IP (at this time, it is the IP of PodA) is on the same bridge (the IP segment of PodA is the same as that of PodB), so it will directly go through layer 2 forwarding without adjusting conntrack, resulting in no original return during packet return
Failure to return a packet causes the requestor to wait until it times out
This also explains why there is no problem accessing the ClusterIP of applications on other nodes, because the target PodIP and the source PodIP are not on the same network segment, so you must go to conntrack
4. Problem solving
In general, the problem is solved after opening the parameters
$ echo "net.bridge.bridge-nf-call-iptables=1" >> /etc/sysctl.conf $ echo "net.bridge.bridge-nf-call-ip6tables=1" >> /etc/sysctl.conf $ sysctl -p /etc/sysctl.conf
5,linux conntrack
In fact, conntrack is also a knowledge point worth studying. There are tools in each release to see the records in conntrack. The format is as follows:
$ conntrack -L tcp 6 119 SYN_SENT src=10.224.1.34 dst=10.233.53.172 sport=56916 dport=8080 [UNREPLIED] src=10.224.1.56 dst=10.224.1.34 sport=8080 dport=56916 mark=0 use=1
The famous DNS 5s timeout[1] problem is related to the conntrack mechanism. Due to the limited space, it will not be expanded here
6,tcpdump
Packet capture command in container
$ tcpdump -vvv host 10.224.1.34 or 10.233.53.172 or 10.224.1.56
The three IPS correspond to podA IP, podB clusterip and podb PodIP respectively
Due to the length, only key information is saved here, and notes are added by the author for easy understanding
The tcpdump for exception requests is as follows:
#podA request = PodB panorama-frontend-deploy-c8f6fd4b6-52tvf.45954 > panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080: Flags [S], cksum 0x4cc5 (incorrect -> 0xba1b), seq 1108986852, win 28200, options [mss 1410,sackOK,TS val 1345430037 ecr 0,nop,wscale 7], length 0 # 10-224-1-56 is the podIP of PodB. The analysis process is omitted here. You can see the returned data to PodA 10-224-1-56.panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080 > panorama-frontend-deploy-c8f6fd4b6-52tvf.45954: Flags [S.], cksum 0x1848 (incorrect -> 0x99ac), seq 3860576650, ack 1108986853, win 27960, options [mss 1410,sackOK,TS val 2444502128 ecr 1345430037,nop,wscale 7], length 0 # Important: podA reset s the request directly panorama-frontend-deploy-c8f6fd4b6-52tvf.45954 > 10-224-1-56.panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080: Flags [R], cksum 0xb6b5 (correct), seq 1108986853, win 0, length 0
Finally, it will be found that PodA sent PodB an R flag, that is, reset, because when PodB returned the handshake confirmation to PodA, PodA did not recognize the request, so it directly reset it, and the three hand handshake was not established. this is why!
For net bridge. The tcpdump of the normal request for bridge NF call iptables = 1 is as follows:
# You can see the normal three handshakes, which are omitted here # Turn on data transfer panorama-frontend-deploy-c8f6fd4b6-52tvf.36434 > panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080: Flags [P.], cksum 0x4d3c (incorrect -> 0x6f84), seq 1:128, ack 1, win 221, options [nop,nop,TS val 1346139372 ecr 2445211463], length 127: HTTP, length: 127 GET / HTTP/1.1 Host: panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080 User-Agent: curl/7.52.1 Accept: */* panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080 > panorama-frontend-deploy-c8f6fd4b6-52tvf.36434: Flags [.], cksum 0x4cbd (incorrect -> 0xe8a6), seq 1, ack 128, win 219, options [nop,nop,TS val 2445211463 ecr 1346139372], length 0 panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080 > panorama-frontend-deploy-c8f6fd4b6-52tvf.36434: Flags [P.], cksum 0x4dac (incorrect -> 0x0421), seq 1:240, ack 128, win 219, options [nop,nop,TS val 2445211463 ecr 1346139372], length 239: HTTP, length: 239 HTTP/1.1 200 OK Server: nginx/1.17.1 Date: Wed, 18 Aug 2021 15:10:17 GMT Content-Type: text/html Content-Length: 1540 Last-Modified: Fri, 09 Jul 2021 06:36:53 GMT Connection: keep-alive ETag: "60e7ee85-604" Accept-Ranges: bytes
I believe the request path is still very clear, so I won't be wordy
7. Conclusion
Disable net bridge. Of course, the parameter bridge NF call ip6tables is also good, that is, considering the IP access of the same network segment, it is not necessary to use conntrack, which is helpful to the performance to a certain extent.
The official document [2] of kubernetes clearly mentions that this parameter needs to be enabled on the Node, otherwise it is only a matter of time to encounter various strange phenomena, so it is still not necessary to adjust it at will.
In case of future trouble, you can monitor whether the parameter is turned on to prevent it from being modified by mistake.
PS: in case you can't find this article, you can collect some likes for easy browsing and searching.