2021SC@SDUSC
Peptide drug analysis based on Artificial Intelligence
Subject: protein pre training model (5)
code analysis
 Visualization Section
Visualization Section
ProtTrans/Visualization/ProtAlbert_attention_head_view.ipynb
Load the necessary libraries, including huggingface and bertvis transformer
import torch from transformers import AlbertTokenizer, AlbertModel from bertviz.bertviz import head_view import re
def call_html():
import IPython
display(IPython.core.display.HTML('''
<script src="/static/components/requirejs/require.js"></script>
<script>
requirejs.config({
paths: {
base: '/static/base',
"d3": "https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.8/d3.min",
jquery: '//ajax.googleapis.com/ajax/libs/jquery/2.0.0/jquery.min',
},
});
</script>
'''))
Load vocabulary and ProtAlbert models
model = AlbertModel.from_pretrained("Rostlab/prot_albert", output_attentions=True)
tokenizer = AlbertTokenizer.from_pretrained("Rostlab/prot_albert", do_lower_case=False)
If GPU is available, load the model into GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
model = model.eval()
Create a visualization method for attention head
def show_head_view(model, tokenizer, sequence):
inputs = tokenizer.encode_plus(sequence, return_tensors='pt', add_special_tokens=True)
input_ids = inputs['input_ids']
attention = model(input_ids.to(device))[-1]
input_id_list = input_ids[0].tolist() # Batch index 0
tokens = tokenizer.convert_ids_to_tokens(input_id_list)
head_view(attention, tokens)
Create or load sequences to map rare amino acids (U,Z,O,B) to (X)
sequence = "N L Y I Q W L K D G G P S S G R P P P S" sequence = re.sub(r"[UZOB]", "X", sequence)
Call the visualization method to create the attention visualization
call_html() show_head_view(model, tokenizer, sequence)
Thesis learning
Attention mechanism model
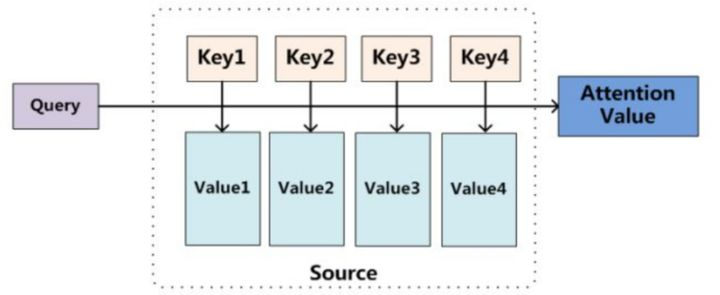
In essence, Attention is to filter out a small amount of important information from a large amount of information, focus on these important information, and ignore most unimportant information. The larger the weight, the more it focuses on its corresponding Value, that is, the weight represents the importance of information, and Value is its corresponding information.
As for the specific calculation process of Attention mechanism, if most current methods are abstracted, they can be summarized into two processes: the first process is to calculate the weight coefficient according to Query and Key
In the second process, Value is weighted and summed according to the weight coefficient. The first process can be divided into two stages: the first stage calculates the similarity or correlation between Query and Key; The second stage normalizes the original score of the first stage; In this way, the calculation process of Attention can be abstracted into three stages as shown in the figure.
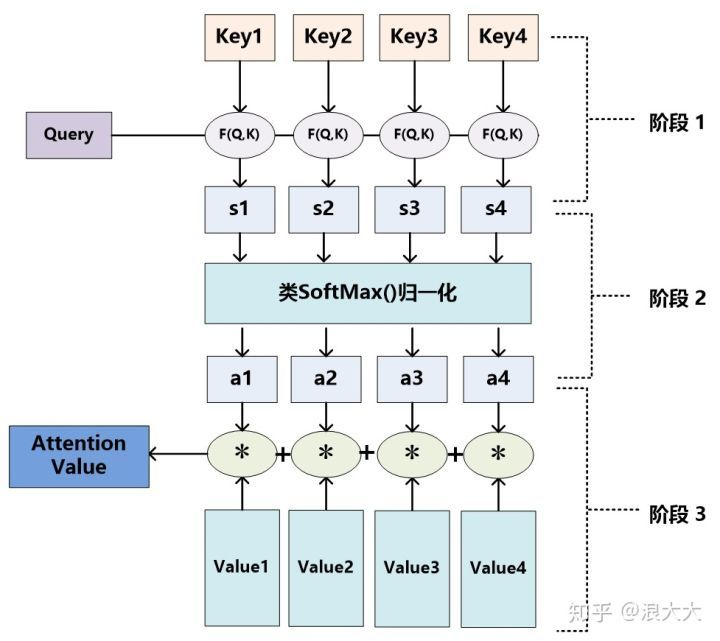 In the first stage, different functions and computer systems can be introduced to calculate the similarity or correlation between Query and a Key. The most common methods include: finding the vector dot product of both, finding the vector Cosine similarity of both, or evaluating by introducing additional divine network.
In the first stage, different functions and computer systems can be introduced to calculate the similarity or correlation between Query and a Key. The most common methods include: finding the vector dot product of both, finding the vector Cosine similarity of both, or evaluating by introducing additional divine network.
The score generated in the first stage is different according to the specific generation method, and its value range is also different. In the second stage, a calculation method similar to SoftMax is introduced to convert the score in the first stage. On the one hand, the original calculated score can be normalized and sorted into a probability distribution in which the sum of the weights of all elements is 1; On the other hand, you can also highlight the weight of important elements through the internal mechanism of SoftMax.
Through the above three-stage calculation, the Attention value for Query can be obtained. At present, most specific Attention mechanism calculation methods comply with the above three-stage abstract calculation process.
Self attention mechanism
Self attention mechanism is a variant of attention mechanism, which reduces the dependence on external information and is better at capturing the internal correlation of data or features.
The application of self attention mechanism in text mainly solves the problem of long-distance dependence by calculating the interaction between words.
Calculation process of self attention mechanism:
1. Convert the input word into an embedded vector;
2. Get three vectors q, k and v according to the embedded vector;
3. Calculate a score for each vector: score = Q k ;
4. In order to stabilize the gradient, Transformer uses score normalization;
5. Apply softmax activation function to score;
6.softmax dot multiplies the Value v to obtain the weighted score v of each input vector;
7. Add to get the final output z.
reference material: https://zhuanlan.zhihu.com/p/265108616