Local operation mode
Basic introduction
Spark's Local operation mode is also called Local operation mode and pseudo distributed mode. This is called Local mode because all spark processes in this mode run in the virtual machine of a Local machine without any resource manager. It mainly uses multiple threads of a single machine to simulate spark distributed computing. It is generally used for testing.
The standard writing method of Local mode is Local[N] mode, where N refers to the number of threads for multi-threaded simulation Spark distribution calculation mentioned earlier. If N is not specified, the default is 1 thread (the thread has 1 core). If it is Local [*], it means Spark is running locally, and the number of worker threads is the same as the number of logical cores on the computer.
Operation flow chart
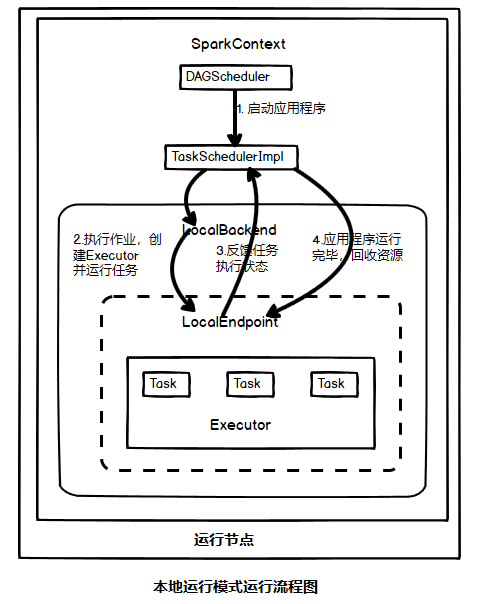
The operation flow of local operation mode is shown in the following figure
Detailed introduction to operation process
1. Start the application
Starting the application is to start the SparkContext object. This stage is mainly for the scheduler (DAGScheduler, TaskSchedulerImpl
)And initialization of local endpoint (LocalBackend, LocalEndpoint).
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
...
//When the number of running threads is not specified, it runs in single thread mode, and the runtime starts to a thread to process tasks
case "local" =>
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
//Start a single threaded task
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, 1)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_REGEX(threads) =>
//Get the number of cpu cores that the running node can use. When the matching character is local [*], the number of processes that start the number of cpu cores
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*] estimates the number of cores on the machine; local[N] uses exactly N threads.
val threadCount = if (threads == "*") localCpuCount else threads.toInt
if (threadCount <= 0) {
throw new SparkException(s"Asked to run locally with $threadCount threads")
}
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_FAILURES_REGEX(threads, maxFailures) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*, M] means the number of cores on the computer with M failures
// local[N, M] means exactly N threads with M failures
val threadCount = if (threads == "*") localCpuCount else threads.toInt
val scheduler = new TaskSchedulerImpl(sc, maxFailures.toInt, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
...
}
2. Execute the job, create the Executor and run the task
The execution of jobs first divides the scheduling state to form a task set. Then, the task set is sent to the local terminal point LocalEndpoint in the order of splitting. After receiving the task set, it starts the Executor locally. After starting, it directly executes the received task set on the started Executor.
private[spark] class LocalEndpoint(
override val rpcEnv: RpcEnv,
userClassPath: Seq[URL],
scheduler: TaskSchedulerImpl,
executorBackend: LocalSchedulerBackend,
private val totalCores: Int)
extends ThreadSafeRpcEndpoint with Logging {
...
//Start the executor. If islocal is true, it means local startup
private val executor = new Executor(
localExecutorId, localExecutorHostname, SparkEnv.get, userClassPath, isLocal = true)
...
def reviveOffers() {
val offers = IndexedSeq(new WorkerOffer(localExecutorId, localExecutorHostname, freeCores,
Some(rpcEnv.address.hostPort)))
//Start the corresponding thread processing task according to the set number of threads
for (task <- scheduler.resourceOffers(offers).flatten) {
freeCores -= scheduler.CPUS_PER_TASK
executor.launchTask(executorBackend, task)
}
}
}
If multithreading is set, multiple Executor parallel processing tasks are started
3. Feedback task execution status
The Executor is responsible for executing the task, and the local endpoint feeds back the task execution status to the upper level job scheduler. The upper layer job scheduler updates the task status according to the received message, and adjusts the status of the whole task set in real time according to this feedback.
private[spark] class LocalEndpoint(
override val rpcEnv: RpcEnv,
userClassPath: Seq[URL],
scheduler: TaskSchedulerImpl,
executorBackend: LocalSchedulerBackend,
private val totalCores: Int)
extends ThreadSafeRpcEndpoint with Logging {
...
//Task update
case StatusUpdate(taskId, state, serializedData) =>
scheduler.statusUpdate(taskId, state, serializedData)
if (TaskState.isFinished(state)) {
freeCores += scheduler.CPUS_PER_TASK
reviveOffers()
}
...
}
If the task set is completed, proceed to the next task set
4. The program is completed and resources are recovered
According to the feedback status, when all the task sets are completed, the task will be completed at this time. At this time, the upper layer job scheduler logs off the Executor running in LocalBackend, then releases DAGScheduler, TaskScheduler, LocalBackend and other processes, and finally logs off SparkContext for resource recycling.
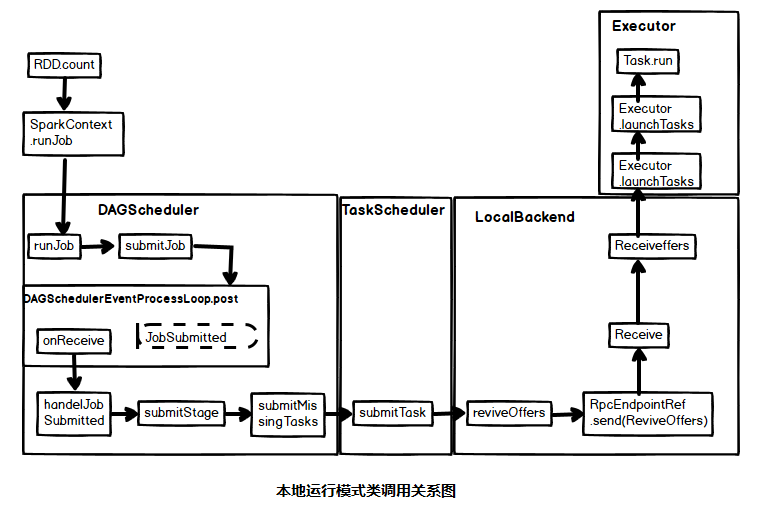
Implementation principle
The class call diagram under local operation mode is as follows