Migrate Chinese bert Model( chinese-bert-wwm),Complete the emotion classification of more than 20000 comment data, which is divided into 0-Good, 1-General, 2-Poor. Learn bert After the model became powerful, I couldn't help but sigh that the model used in the previous competition was too rubbish to see and think bert Training models to simulate the game, So it's time bert The model is migrated and trained on its own data set
Text classification using ktrain Library
0. Allocate GPU (CPU version omitted)
%reload_ext autoreload %autoreload 2 %matplotlib inline import os os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"; os.environ["CUDA_VISIBLE_DEVICES"]="0"; #Specify GPU
Configure GPU stepping
1.Python 3.0 in win10 environment 7+cuda10. 1+cudnn7. 6+tensorflow-gpu1. 13 installation of
2.Note the installation of CUDA and cuDNN (environment variables)
3.Tensorflow GPU version, cuda version and python version can be downloaded accordingly
Download and install in combination with these three articles
1. Load data
#0 - very good, 1 - average, 2 - poor
import pandas as pd
import numpy as np
train = pd.read_excel('D:/python relevant/data/train_sentiment.xls')
test = pd.read_excel('D:/python relevant/data/test_sentiment.xls')
2. Disrupt data
X_data=train.content
y_data=np.asarray(train.cls, dtype=np.float32)
x_data_test=test.content
y_data_test=np.asarray(test.cls, dtype=np.float32)
nums = []
nums_ = []
x_train = []
y_train = []
x_test = []
y_test = []
nums = np.arange(9999)
np.random.shuffle(nums)
for i in nums:
x_train.append(X_data[i])
y_train.append(y_data[i])
nums_ = np.arange(3602)
np.random.shuffle(nums_)
for i in nums_:
x_test.append(x_data_test[i])
y_test.append(y_data_test[i])
y_train=np.asarray(y_train, dtype=np.int)
y_test=np.asarray(y_test, dtype=np.int)
3. Preprocess the data and construct a Chinese trasnformer model
import ktrain from ktrain import text MODEL_NAME = 'hfl/chinese-bert-wwm' t = text.Transformer(MODEL_NAME, maxlen=300, class_names=[0,1,2])#300 is a little small. You can set 400 / 500 trn = t.preprocess_train(x_train, y_train) val = t.preprocess_test(x_test, y_test) model = t.get_classifier() learner = ktrain.get_learner(model, train_data=trn, val_data=val, batch_size=1) #The GPU capacity is limited, and the parameters are adjusted as small as possible, and the results will be affected accordingly
*[preprocessing train...
language: zh-cn
Is Multi-Label? False
preprocessing test...
language: zh-cn]
Estimate a better learning rate
For the transformer model, combined with experience and great God test summary, the learning rate of 2e-5 - 5e-5 will achieve better performance. Here, we can use lr_find method to try to find a better learning rate on specific data
Here, we only run one epoch (because it takes too long, GPU students can try other parameters)
learner.lr_find(show_plot=True, max_epochs=1)
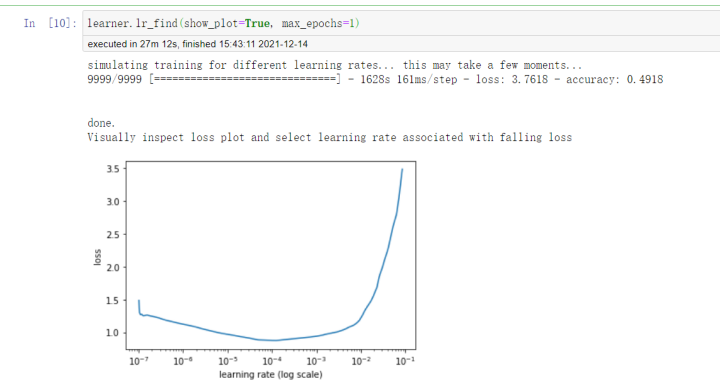
Use the loss function to determine the best learning rate. The smaller the loss, the better
Training model
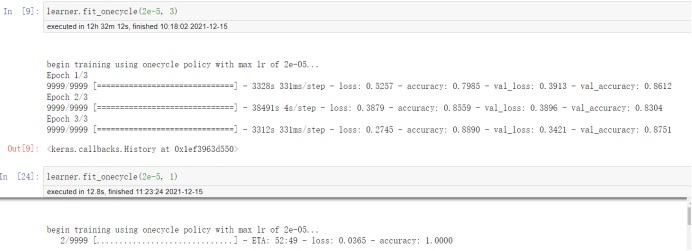
Parameter setting: learning_rate = 2e-5, epochs = 4
CPU time is very long. GPU is more than ten times that of CPU
learner.fit_onecycle(2e-5, 4)
Evaluation model
learner.validate(class_names=t.get_classes())

Category: the accuracy of 0 is significantly lower than that of the other two categories, which may be due to the amount of data
Test on new data
Find the sample with the largest loss
learner.view_top_losses(n=1, preproc=t)
#id:397 | loss:7.4 | true:0 | pred:2)
*# check the error. The reason for this error is very clear. It is a counter example (Category 2: bad comments)*
It shows that the model is quite good.
print(x_test[397])
#1. Due to the design of the keyboard, some keys are not very convenient to press. 2. The lens of the camera is not protected and is exposed. If the lens surface is accidentally scratched, it will affect the effect of taking pictures. 3. The mobile phone is a little big and heavy. It's not very convenient to carry. 4. The sound box attached to the fuselage is not very good, and there will be some noise when the volume is high. 5. The battery life is a little
Test on new data
predictor = ktrain.get_predictor(learner.model, preproc=t)
predictor.predict('How come it's like this... Even copying the Hollywood structure is not enough! "Seven days off" and "the first day of the Spring Festival" are obviously speculation. Be sensational. Two elders died')
2 # results (poor evaluation)
predictor.explain('How come it's like this... Even copying the Hollywood structure is not enough! "Seven days off" and "the first day of the Spring Festival" are obviously speculation. Be sensational. Two elders died')
Save the model so that it can be called later.
predictor.save('/my_commentgroup_predictor')
reloaded_predictor = ktrain.load_predictor('/my_commentgroup_predictor')
Result analysis
The bert model is used to realize the emotion classification of Chinese comments. The data comes from the case data of a competition, with a total of 20000 pieces. There are hardware problems and high training difficulties, so it is reduced to 9999 pieces of training data and 3602 pieces of test data. It may be that the data itself is not accurate enough and the parameters are adjusted. The accuracy result is 88%. The results are better in the case of English classification using English model. Before pre training, I checked many blogs and learned the process, but it is still difficult to get started. The computer GPU has a small capacity and does not support larger model training, which also directly leads to the adjustability of model parameters.
Experimental summary
The results can also be optimized for competition. The difficulty is mainly in the debugging of model pre training. The computer CPU training is slow, and there are many pits in the process. Therefore, the GPU environment is configured, but it has been reporting errors, and it still encounters many pits, which makes it tired to step on. The environment is configured, but the computational power and capacity are limited. Let's stop here for the time being. It further reminds me of my ability. There is a long way to go. Come on!