Because the course assignment needs to carry out some analysis on NLP, and there is no particularly useful code on the Internet, so I just write a crawler myself, which can crawl the microblog content, comment content and microblog publisher related information according to the topic name. At present, there is no special problem in the author test.
The code in the article is scattered. If you want to test, it is recommended to test the complete code.
- First, the effect is displayed. The author did not climb all the data, but also climbed nearly 8000 data.
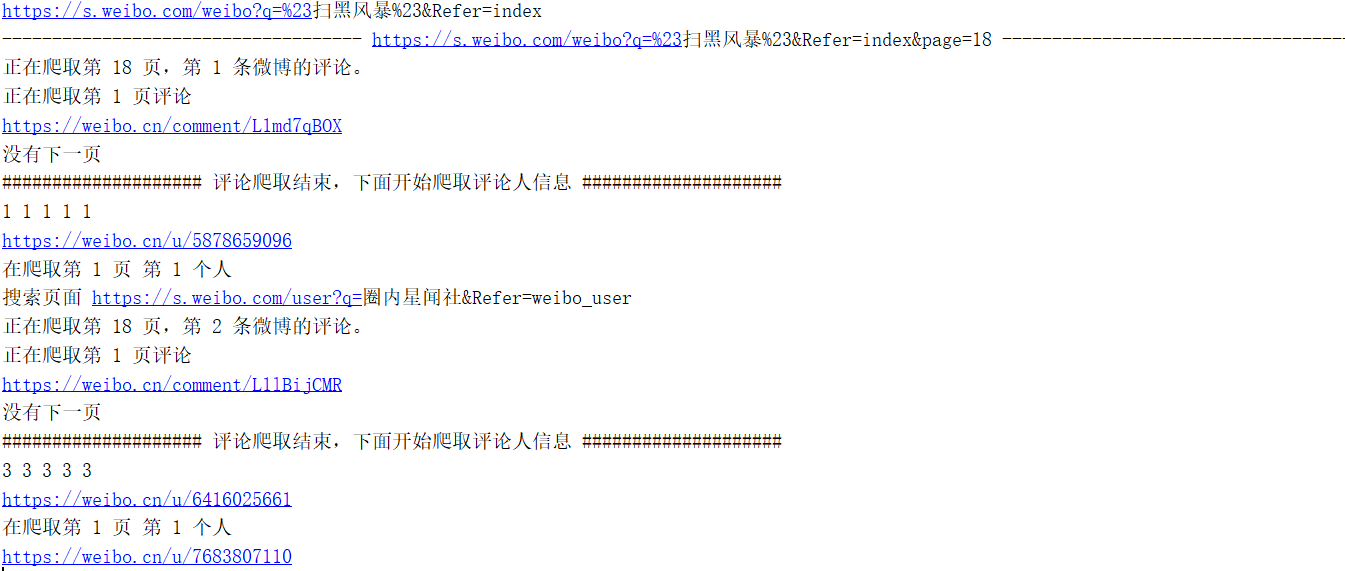

1, Environmental preparation
I won't say much here. These packages are used. Just use pip install to install.
import requests from lxml import etree import csv import re import time import random from html.parser import HTMLParser
2, According to Weibo Com to get microblog information about the topic
-First, determine the main fields such as the content of the captured microblog, the number of comments, the number of likes, the release time, and the publisher's name.
- After knowing the climbing target, further analyze the structure. The contents to be climbed are as follows:
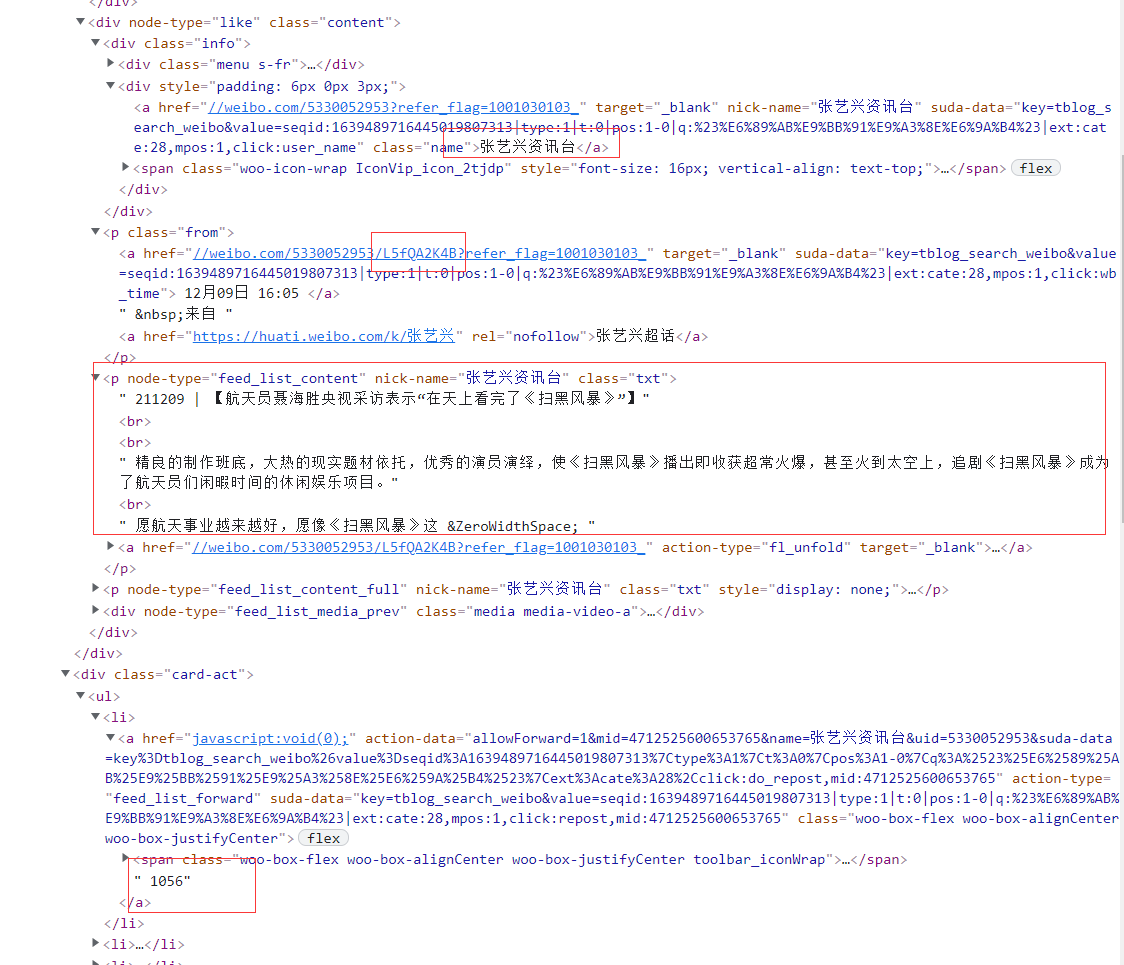
- According to the change of the url by turning the page, according to the observation, the url is mainly the change of the topic name and the number of pages, so the established scheme is as follows:
topic = 'Black storm' url = baseUrl.format(topic)
tempUrl = url + '&page=' + str(page)
- Knowing the general structure, we begin to extract the elements:
for i in range(1, count + 1):
try:
contents = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@node-type="feed_list_content_full"]')
contents = contents[0].xpath('string(.)').strip() # Read all strings under this node
except:
contents = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@node-type="feed_list_content"]')
# If there is an error, it means that there is a problem with the current microblog
try:
contents = contents[0].xpath('string(.)').strip()
except:
continue
contents = contents.replace('Put away the full text d', '')
contents = contents.replace('Put away d', '')
contents = contents.split(' 2')[0]
# The name of the person who posted the microblog
name = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/div[1]/div[2]/a')[0].text
# Microblog url
weibo_url = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@class="from"]/a/@href')[0]
url_str = '.*?com\/\d+\/(.*)\?refer_flag=\d+_'
res = re.findall(url_str, weibo_url)
weibo_url = res[0]
host_url = 'https://weibo.cn/comment/'+weibo_url
# Time of microblogging
timeA = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@class="from"]/a')[0].text.strip()
# Number of likes
likeA = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[2]/ul[1]/li[3]/a/button/span[2]')[0].text
hostComment = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[2]/ul[1]/li[2]/a')[0].text
# If the number of likes is empty, it means that the number of likes is 0
if likeA == 'fabulous':
likeA = 0
if hostComment == 'comment ':
hostComment = 0
if hostComment != 0:
print('Crawling to No',page,'Page, page',i,'Comments on Weibo.')
getComment(host_url)
# print(name,weibo_url,contents, timeA,likeA, hostComment)
try:
hosturl,host_sex, host_location, hostcount, hostfollow, hostfans=getpeople(name)
list = ['micro-blog', name, hosturl, host_sex, host_location, hostcount, hostfollow, hostfans,contents, timeA, likeA]
writer.writerow(list)
except:
continue
Among them, this microblog url is particularly important, because subsequent crawling of the content below it needs to find relevant content according to this url.
weibo_url = html.xpath('//div[@class="card-wrap"][' + str(i) +']/div[@class="card"]/div[1]/div[2]/p[@class="from"]/a/@href')[0]
url_str = '.*?com\/\d+\/(.*)\?refer_flag=\d+_'
res = re.findall(url_str, weibo_url)
weibo_url = res[0]
host_url = 'https://weibo.cn/comment/'+weibo_url
It mainly needs the contents in the following figure

- Determine whether to turn the page according to the page elements
try:
if pageCount == 1:
pageA = html.xpath('//*[@id="pl_feedlist_index"]/div[5]/div/a')[0].text
print(pageA)
pageCount = pageCount + 1
elif pageCount == 50:
print('There is no next page')
break
else:
pageA = html.xpath('//*[@id="pl_feedlist_index"]/div[5]/div/a[2]')[0].text
pageCount = pageCount + 1
print(pageA)
except:
print('There is no next page')
break
- The result fields are as follows:
name,weibo_url,contents, timeA,likeA, hostComment
3, Microblog publisher information acquisition
weibo. The information in. Com is not intuitive enough, so in Weibo Cn, and the page structure is as follows:

- To enter the corresponding user interface, you need to obtain the relevant url. The scheme in this paper is based on the user name obtained in the previous step in Weibo For relevant search in. Com, we only need to get the relevant url of the first person searched. Because the obtained user names are complete, the first one is the content we need.
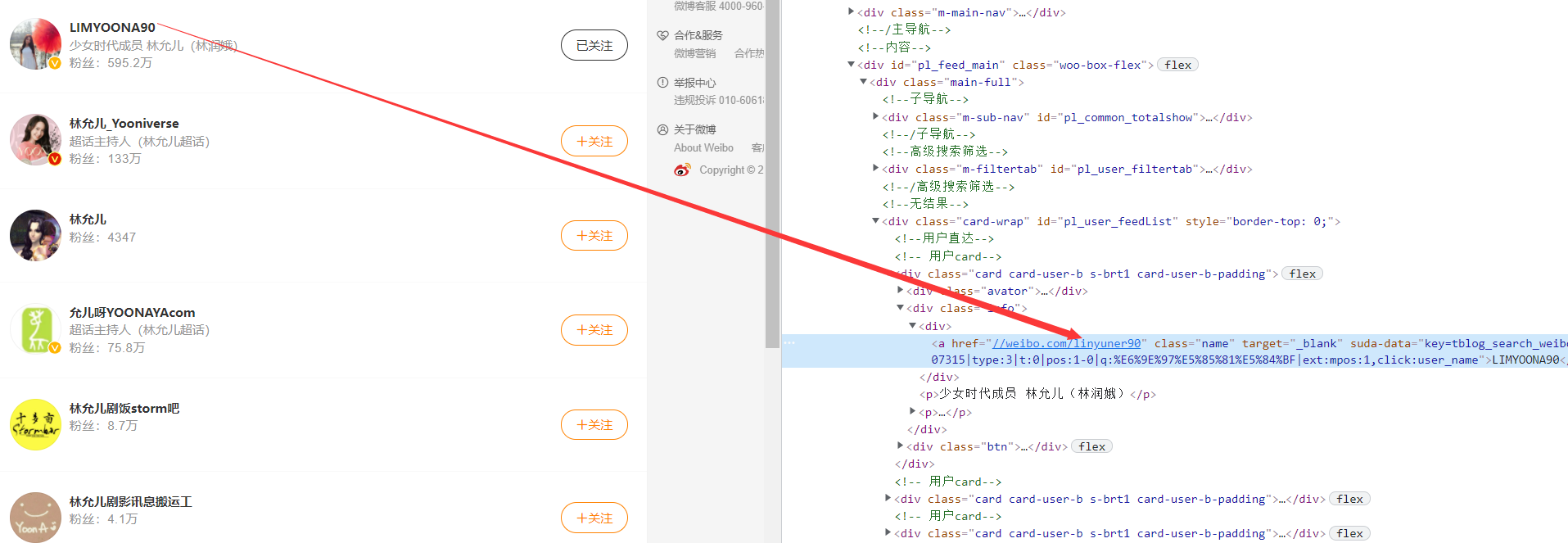
- Relevant codes are as follows:
url2 = 'https://s.weibo.com/user?q='
while True:
try:
response = requests.post('https://weibo. cn/search/? pos=search', headers=headers_ Cn, data = {suser ':' find someone ',' keyword': name})
tempUrl2 = url2 + str(name)+'&Refer=weibo_user'
print('Search page',tempUrl2)
response2 = requests.get(tempUrl2, headers=headers_com_1)
html = etree.HTML(response2.content, parser=etree.HTMLParser(encoding='utf-8'))
# print('/html/body/div[1]/div[2]/div/div[2]/div[1]/div[3]/div[1]/div[2]/div/a')
hosturl_01 =html.xpath('/html/body/div[1]/div[2]/div/div[2]/div[1]/div[3]/div[1]/div[2]/div/a/@href')[0]
url_str = '.*?com\/(.*)'
res = re.findall(url_str, hosturl_01)
hosturl = 'https://weibo.cn/'+res[0]
- After obtaining the url, enter weibo.com Cn to crawl relevant data:
while True:
try:
response = requests.get(hosturl, headers=headers_cn_1)
html = etree.HTML(response.content, parser=etree.HTMLParser(encoding='utf-8'))
# Number of microblogs
hostcount = html.xpath('/html/body/div[4]/div/span')[0].text
hostcount = re.match('(\S\S\S)(\d+)', hostcount).group(2)
# Number of concerns
hostfollow = html.xpath('/html/body/div[4]/div/a[1]')[0].text
hostfollow = re.match('(\S\S\S)(\d+)', hostfollow).group(2)
# Number of fans
hostfans = html.xpath('/html/body/div[4]/div/a[2]')[0].text
hostfans = re.match('(\S\S\S)(\d+)', hostfans).group(2)
# Gender and location
host_sex_location = html.xpath('/html/body/div[4]/table/tr/td[2]/div/span[1]/text()')
break
except:
print('Failed to find someone')
time.sleep(random.randint(0, 10))
pass
try:
host_sex_locationA = host_sex_location[0].split('\xa0')
host_sex_locationA = host_sex_locationA[1].split('/')
host_sex = host_sex_locationA[0]
host_location = host_sex_locationA[1].strip()
except:
host_sex_locationA = host_sex_location[1].split('\xa0')
host_sex_locationA = host_sex_locationA[1].split('/')
host_sex = host_sex_locationA[0]
host_location = host_sex_locationA[1].strip()
# print('microblog information ', name,hosturl,host_sex,host_location,hostcount,hostfollow,hostfans)
return hosturl,host_sex, host_location, hostcount, hostfollow, hostfans
3, Comment acquisition
-
In the first step, we obtained the microblog related logo and Weibo Cn, so we can crawl according to the url:

-
Analyze the general situation

-
It is found that the number of comments on each page is different, and the tag where the comment is located does not have any unique identification, so it is a little troublesome to obtain it according to xpath, so we use regular expression to obtain data.

-
The crawling code of comments is as follows:
page=0
pageCount=1
count = []#content
date = []#time
like_times = []#fabulous
user_url = []#User url
user_name = []#User nickname
while True:
page=page+1
print('Crawling to No',page,'Page comments')
if page == 1:
url = hosturl
else:
url = hosturl+'?page='+str(page)
print(url)
try:
response = requests.get(url, headers=headers_cn)
except:
break
html = etree.HTML(response.content, parser=etree.HTMLParser(encoding='utf-8'))
user_re = '<div\sclass="c"\sid="C_\d+.*?<a\shref="(.*?)"'
user_name_re = '<div\sclass="c"\sid="C_\d+.*?<a\shref=".*?">(.*?)</a>'
co_re = '<div\sclass="c"\sid="C_\d+.*?<span\sclass="ctt">(.*?)</span>'
zan_re = '<div\sclass="c"\sid="C_\d+.*?fabulous\[(.*?)\]'
date_re = '<div\sclass="c"\sid="C_\d+.*?<span\sclass="ct">(.*?);'
count_re = 'reply<a.*</a>:(.*)'
user_name2 = re.findall(user_name_re,response.text)
zan = re.findall(zan_re,response.text)
date_2 = re.findall(date_re,response.text)
count_2 = re.findall(co_re, response.text)
user_url2 = re.findall(user_re,response.text)
flag = len(zan)
for i in range(flag):
count.append(count_2[i])
date.append(date_2[i])
like_times.append(zan[i])
user_name.append(user_name2[i])
user_url.append('https://weibo.cn'+user_url2[i])
try:
if pageCount==1: #The first page looks for the next page, and the sign code is as follows
pageA = html.xpath('//*[@id="pagelist"]/form/div/a')[0].text
print('='*40,pageA,'='*40)
pageCount = pageCount + 1
else: #After the second page, look for the logo of the next page
pageA = html.xpath('//*[@id="pagelist"]/form/div/a[1]')[0].text
pageCount=pageCount+1
print('='*40,pageA,'='*40)
except:
print('No next page')
break
print("#"*20,'The comment crawling is over. Now start crawling the comment information',"#"*20)
print(len(like_times),len(count),len(date),len(user_url),len(user_name))
4, Microblog commentator information crawling
- Due to Weibo Cn can directly obtain the key parts of the user url, so you don't need to retrieve the user name, you can directly obtain the url and crawl further
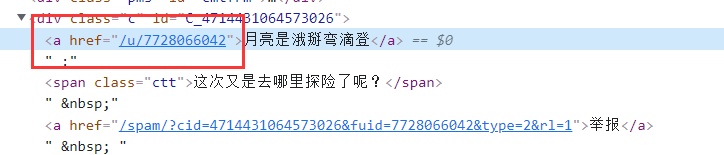
def findUrl(hosturl):
while True:
try:
print(hosturl)
response = requests.get(hosturl, headers=headers_cn_1)
html = etree.HTML(response.content, parser=etree.HTMLParser(encoding='utf-8'))
hostcount=html.xpath('/html/body/div[4]/div/span')[0].text
hostcount=re.match('(\S\S\S)(\d+)',hostcount).group(2)
hostfollow=html.xpath('/html/body/div[4]/div/a[1]')[0].text
hostfollow = re.match('(\S\S\S)(\d+)', hostfollow).group(2)
hostfans=html.xpath('/html/body/div[4]/div/a[2]')[0].text
hostfans = re.match('(\S\S\S)(\d+)', hostfans).group(2)
host_sex_location=html.xpath('/html/body/div[4]/table/tr/td[2]/div/span[1]/text()')
break
except:
print('Failed to find someone')
time.sleep(random.randint(0, 5))
pass
try:
host_sex_locationA=host_sex_location[0].split('\xa0')
host_sex_locationA=host_sex_locationA[1].split('/')
host_sex=host_sex_locationA[0]
host_location=host_sex_locationA[1].strip()
except:
host_sex_locationA=host_sex_location[1].split('\xa0')
host_sex_locationA = host_sex_locationA[1].split('/')
host_sex = host_sex_locationA[0]
host_location = host_sex_locationA[1].strip()
time.sleep(random.randint(0, 2))
# print('microblog information: ','url:', hosturl, 'gender:', host_sex, 'region:', host_location, 'microblogs:', hostcount, 'followers:', hostfollow, 'fans:', hostfans)
return host_sex,host_location,hostcount,hostfollow,hostfans
To sum up, the general idea is:
Microblog access:
1.weibo.com to obtain microblog url, user name, microblog content and other information
2. Further, according to the user name in Weibo Get user url in com
3. According to the constructed user url, it can be found in weibo.com Crawl the information of microblog publishers in CN
Access to microblog comments:
1. Build Weibo according to the microblog logo obtained above Address of corresponding microblog in CN
2. Get comments according to regular expressions
5, Save to CSV
- New related file
topic = 'Black storm'
url = baseUrl.format(topic)
print(url)
writer.writerow(['category', 'user name', 'User link', 'Gender', 'region', 'Number of microblogs', 'Number of concerns', 'Number of fans', 'Comment content', 'Comment time', 'Like times'])
- Deposit in microblog
hosturl,host_sex, host_location, hostcount, hostfollow, hostfans=getpeople(name) list = ['micro-blog', name, hosturl, host_sex, host_location, hostcount, hostfollow, hostfans,contents, timeA, likeA] writer.writerow(list)
- Deposit comments
list111 = ['comment',user_name[i], user_url[i] , host_sex, host_location,hostcount, hostfollow, hostfans,count[i],date[i],like_times[i]] writer.writerow(list111)
6, Complete code
# -*- coding: utf-8 -*-
# @Time : 2021/12/8 10:20
# @Author : MinChess
# @File : weibo.py
# @Software: PyCharm
import requests
from lxml import etree
import csv
import re
import time
import random
from html.parser import HTMLParser
headers_com = {
'Cookie': 'Can't see me',
'user-agent': 'Can't see me'
}
headers_cn = {
'Cookie': 'Can't see me',
'user-agent': 'Can't see me'
}
baseUrl = 'https://s.weibo.com/weibo?q=%23{}%23&Refer=index'
topic = 'Black storm'
csvfile = open(topic+ '.csv', 'a', newline='', encoding='utf-8-sig')
writer = csv.writer(csvfile)
def getTopic(url):
page = 0
pageCount = 1
while True:
weibo_content = []
weibo_liketimes = []
weibo_date = []
page = page + 1
tempUrl = url + '&page=' + str(page)
print('-' * 36, tempUrl, '-' * 36)
response = requests.get(tempUrl, headers=headers_com)
html = etree.HTML(response.text, parser=etree.HTMLParser(encoding='utf-8'))
count = len(html.xpath('//div[@class="card-wrap"]')) - 2
for i in range(1, count + 1):
try:
contents = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@node-type="feed_list_content_full"]')
contents = contents[0].xpath('string(.)').strip() # Read all strings under this node
except:
contents = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@node-type="feed_list_content"]')
# If there is an error, it means that there is a problem with the current microblog
try:
contents = contents[0].xpath('string(.)').strip()
except:
continue
contents = contents.replace('Put away the full text d', '')
contents = contents.replace('Put away d', '')
contents = contents.split(' 2')[0]
# The name of the person who posted the microblog
name = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/div[1]/div[2]/a')[0].text
# Microblog url
weibo_url = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@class="from"]/a/@href')[0]
url_str = '.*?com\/\d+\/(.*)\?refer_flag=\d+_'
res = re.findall(url_str, weibo_url)
weibo_url = res[0]
host_url = 'https://weibo.cn/comment/'+weibo_url
# Time of microblogging
timeA = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@class="from"]/a')[0].text.strip()
# Number of likes
likeA = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[2]/ul[1]/li[3]/a/button/span[2]')[0].text
hostComment = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[2]/ul[1]/li[2]/a')[0].text
# If the number of likes is empty, it means that the number of likes is 0
if likeA == 'fabulous':
likeA = 0
if hostComment == 'comment ':
hostComment = 0
if hostComment != 0:
print('Crawling to No',page,'Page, page',i,'Comments on Weibo.')
getComment(host_url)
try:
hosturl,host_sex, host_location, hostcount, hostfollow, hostfans=getpeople(name)
list = ['micro-blog', name, hosturl, host_sex, host_location, hostcount, hostfollow, hostfans,contents, timeA, likeA]
writer.writerow(list)
except:
continue
print('=' * 66)
try:
if pageCount == 1:
pageA = html.xpath('//*[@id="pl_feedlist_index"]/div[5]/div/a')[0].text
print(pageA)
pageCount = pageCount + 1
elif pageCount == 50:
print('There is no next page')
break
else:
pageA = html.xpath('//*[@id="pl_feedlist_index"]/div[5]/div/a[2]')[0].text
pageCount = pageCount + 1
print(pageA)
except:
print('There is no next page')
break
def getpeople(name):
findPoeple=0
url2 = 'https://s.weibo.com/user?q='
while True:
try:
response = requests.post('https://weibo. cn/search/? pos=search', headers=headers_ Cn, data = {suser ':' find someone ',' keyword': name})
tempUrl2 = url2 + str(name)+'&Refer=weibo_user'
print('Search page',tempUrl2)
response2 = requests.get(tempUrl2, headers=headers_com)
html = etree.HTML(response2.content, parser=etree.HTMLParser(encoding='utf-8'))
hosturl_01 =html.xpath('/html/body/div[1]/div[2]/div/div[2]/div[1]/div[3]/div[1]/div[2]/div/a/@href')[0]
url_str = '.*?com\/(.*)'
res = re.findall(url_str, hosturl_01)
hosturl = 'https://weibo.cn/'+res[0]
print('Find someone home page:',hosturl)
break
except:
if findPoeple==10:
stop=random.randint(60,300)
print('IP Be sealed and wait for some time to climb',stop,'second')
time.sleep(stop)
if response.status_code==200:
return
print('look for sb.')
time.sleep(random.randint(0,10))
findPoeple=findPoeple+1
while True:
try:
response = requests.get(hosturl, headers=headers_cn)
# print('microblog owner's personal home page ', hosturl)
html = etree.HTML(response.content, parser=etree.HTMLParser(encoding='utf-8'))
# Get the number of microblogs
# html2 = etree.HTML(html)
# print(html2)
hostcount = html.xpath('/html/body/div[4]/div/span')[0].text
# Regular expression, only get the numeric part
# print(hostcount)
hostcount = re.match('(\S\S\S)(\d+)', hostcount).group(2)
# Get number of concerns
hostfollow = html.xpath('/html/body/div[4]/div/a[1]')[0].text
# Regular expression, only get the numeric part
hostfollow = re.match('(\S\S\S)(\d+)', hostfollow).group(2)
# Get fans
hostfans = html.xpath('/html/body/div[4]/div/a[2]')[0].text
# Regular expression, only get the numeric part
hostfans = re.match('(\S\S\S)(\d+)', hostfans).group(2)
# Obtain gender and location
host_sex_location = html.xpath('/html/body/div[4]/table/tr/td[2]/div/span[1]/text()')
# print(hostcount, hostfollow, hostfans, host_sex_location)
break
except:
print('Failed to find someone')
time.sleep(random.randint(0, 10))
pass
try:
host_sex_locationA = host_sex_location[0].split('\xa0')
host_sex_locationA = host_sex_locationA[1].split('/')
host_sex = host_sex_locationA[0]
host_location = host_sex_locationA[1].strip()
except:
host_sex_locationA = host_sex_location[1].split('\xa0')
host_sex_locationA = host_sex_locationA[1].split('/')
host_sex = host_sex_locationA[0]
host_location = host_sex_locationA[1].strip()
# print('microblog information ', name,hosturl,host_sex,host_location,hostcount,hostfollow,hostfans)
# nickname, hosturl, host_sex, host_location, hostcount, hostfollow, hostfans
return hosturl,host_sex, host_location, hostcount, hostfollow, hostfans
def getComment(hosturl):
page=0
pageCount=1
count = []#content
date = []#time
like_times = []#fabulous
user_url = []#User url
user_name = []#User nickname
while True:
page=page+1
print('Crawling to No',page,'Page comments')
if page == 1:
url = hosturl
else:
url = hosturl+'?page='+str(page)
print(url)
try:
response = requests.get(url, headers=headers_cn)
except:
break
html = etree.HTML(response.content, parser=etree.HTMLParser(encoding='utf-8'))
user_re = '<div\sclass="c"\sid="C_\d+.*?<a\shref="(.*?)"'
user_name_re = '<div\sclass="c"\sid="C_\d+.*?<a\shref=".*?">(.*?)</a>'
co_re = '<div\sclass="c"\sid="C_\d+.*?<span\sclass="ctt">(.*?)</span>'
zan_re = '<div\sclass="c"\sid="C_\d+.*?fabulous\[(.*?)\]'
date_re = '<div\sclass="c"\sid="C_\d+.*?<span\sclass="ct">(.*?);'
count_re = 'reply<a.*</a>:(.*)'
user_name2 = re.findall(user_name_re,response.text)
zan = re.findall(zan_re,response.text)
date_2 = re.findall(date_re,response.text)
count_2 = re.findall(co_re, response.text)
user_url2 = re.findall(user_re,response.text)
flag = len(zan)
for i in range(flag):
count.append(count_2[i])
date.append(date_2[i])
like_times.append(zan[i])
user_name.append(user_name2[i])
user_url.append('https://weibo.cn'+user_url2[i])
try:
if pageCount==1: #The first page looks for the next page, and the sign code is as follows
pageA = html.xpath('//*[@id="pagelist"]/form/div/a')[0].text
print('='*40,pageA,'='*40)
pageCount = pageCount + 1
else: #After the second page, look for the logo of the next page
pageA = html.xpath('//*[@id="pagelist"]/form/div/a[1]')[0].text
pageCount=pageCount+1
print('='*40,pageA,'='*40)
except:
print('No next page')
break
print("#"*20,'The comment crawling is over. Now start crawling the comment information',"#"*20)
print(len(like_times),len(count),len(date),len(user_url),len(user_name))
flag=min(len(like_times),len(count),len(date),len(user_url),len(user_name))
for i in range(flag):
host_sex,host_location,hostcount,hostfollow,hostfans=findUrl(user_url[i])
# print('comment ', user_name [i], user_url [i], host_sex, host_location, hostcount, hostfollow, hostfans, count [i], date [i], like_times [i])
print('Climbing to the third floor', page,'page','The first',i+1, 'personal')
list111 = ['comment',user_name[i], user_url[i] , host_sex, host_location,hostcount, hostfollow, hostfans,count[i],date[i],like_times[i]]
writer.writerow(list111)
time.sleep(random.randint(0, 2))
def findUrl(hosturl):
while True:
try:
print(hosturl)
response = requests.get(hosturl, headers=headers_cn)
html = etree.HTML(response.content, parser=etree.HTMLParser(encoding='utf-8'))
hostcount=html.xpath('/html/body/div[4]/div/span')[0].text
hostcount=re.match('(\S\S\S)(\d+)',hostcount).group(2)
hostfollow=html.xpath('/html/body/div[4]/div/a[1]')[0].text
hostfollow = re.match('(\S\S\S)(\d+)', hostfollow).group(2)
hostfans=html.xpath('/html/body/div[4]/div/a[2]')[0].text
hostfans = re.match('(\S\S\S)(\d+)', hostfans).group(2)
host_sex_location=html.xpath('/html/body/div[4]/table/tr/td[2]/div/span[1]/text()')
break
except:
print('Failed to find someone')
time.sleep(random.randint(0, 5))
pass
try:
host_sex_locationA=host_sex_location[0].split('\xa0')
host_sex_locationA=host_sex_locationA[1].split('/')
host_sex=host_sex_locationA[0]
host_location=host_sex_locationA[1].strip()
except:
host_sex_locationA=host_sex_location[1].split('\xa0')
host_sex_locationA = host_sex_locationA[1].split('/')
host_sex = host_sex_locationA[0]
host_location = host_sex_locationA[1].strip()
time.sleep(random.randint(0, 2))
# print('microblog information: ','url:', hosturl, 'gender:', host_sex, 'region:', host_location, 'microblogs:', hostcount, 'followers:', hostfollow, 'fans:', hostfans)
return host_sex,host_location,hostcount,hostfollow,hostfans
if __name__=='__main__':
topic = 'Black storm'
url = baseUrl.format(topic)
print(url)
writer.writerow(['category', 'user name', 'User link', 'Gender', 'region', 'Number of microblogs', 'Number of concerns', 'Number of fans', 'Comment content', 'Comment time', 'Like times'])
getTopic(url) #Go to the topic page to get microblog
- There are a lot of codes, but if you look closely, there are four main functions, which are nested with each other. The ideas and methods are relatively simple
- There are still some details in the middle that may not be very clear, but I think the general idea should be very clear, that is to obtain them layer by layer. I hope all watchers will wait and see!