Concurrent framework Disruptor
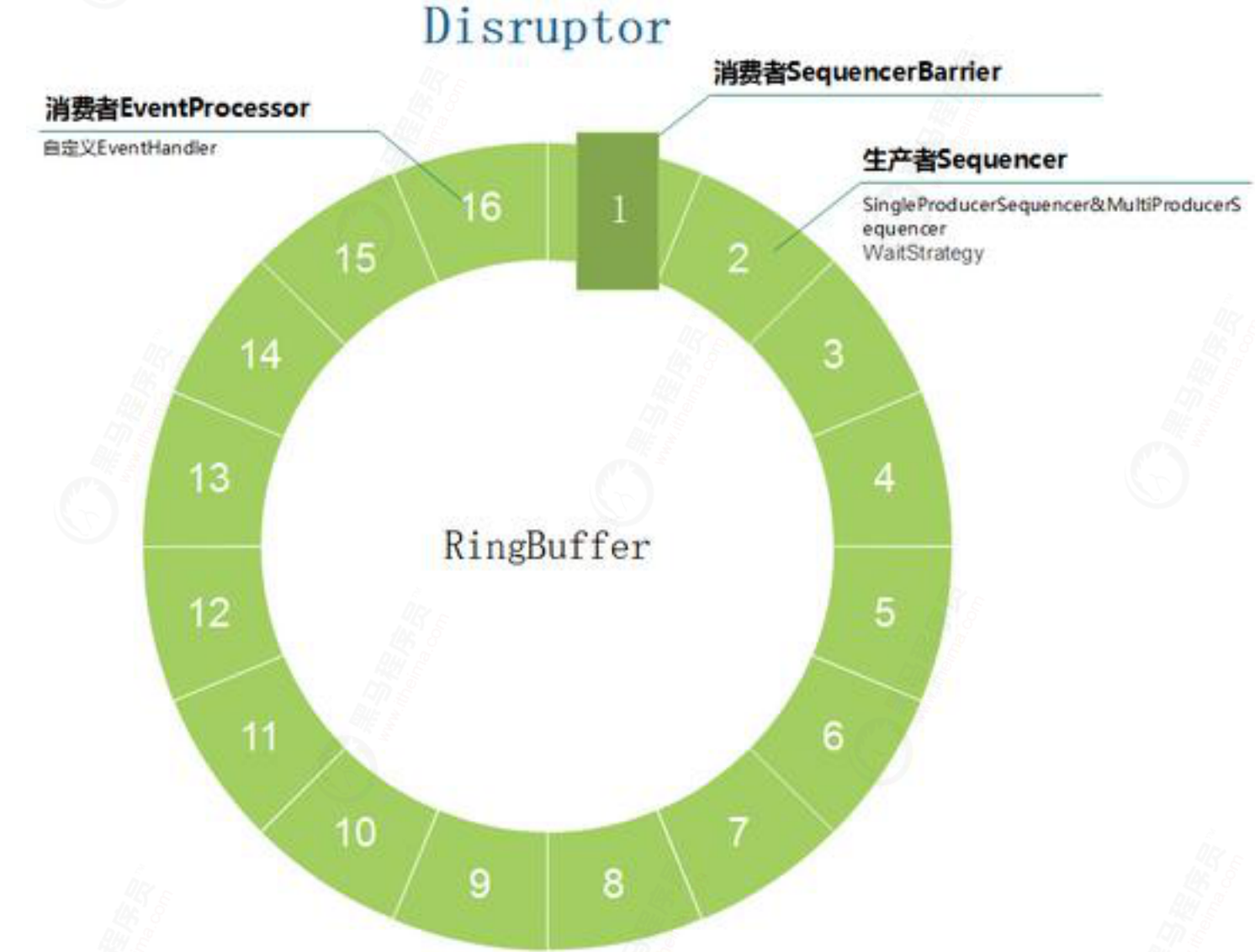
Disruptor overview
background
Disruptor is a high-performance queue developed by LMAX, a British foreign exchange trading company. Its original intention is to solve the delay problem of memory queue (it is found in the performance test that it is in the same order of magnitude as I/O operation). The system developed based on disruptor can support a single thread per second
6 million orders received the attention of the industry after QCon's speech in 2010. In 2011, Martin Fowler, an enterprise application software expert, specially wrote a long introduction. In the same year, it also won the official Duke award of Oracle.
At present, many well-known projects, including Apache Storm, Camel and Log4j 2, have applied Disruptor to obtain high performance.
It should be noted that the queues mentioned here are internal memory queues, not distributed queues such as Kafka.
What is a Disruptor
The Disruptor is used for message queues between multiple threads in a JVM. Its function is similar to that of ArrayBlockingQueue. However, the function and performance of the Disruptor are much better than that of ArrayBlockingQueue. When multiple threads transfer a large amount of data or have low performance requirements
When high, consider using Disruptor as an alternative to ArrayBlockingQueue.
Officials also compared the performance of Disruptor and ArrayBlockingQueue in different application scenarios, and the visual performance was only improved by about 5 ~ 10 times.
Why use Disruptor
Traditional blocked queues use locks to ensure thread safety, while locks are implemented through operating system kernel context switching. Threads will be suspended to wait for the lock until the lock is released.
Performing such a context switch will lose previously saved data and instructions. Due to the speed difference between consumers and producers, the queue is always close to the full or empty state, which will lead to a high level of write contention.
Traditional queue problem
First of all, the queue mentioned here is only limited to the message queue inside Java
Disruptor application scenario
Refer to some of the frameworks used to disrupt
log4j2
Log4j2 asynchronous logs use a disruptor. Generally, the log has a buffer and writes to the file when it is full. The incremental addition of files combined with NIO should also be fast. Therefore, the processing delay of both EventHandler and WorkHandler should be small, and there are not many files written, so the scenario is more appropriate.
Jstorm
In stream processing, there may be a lot of data exchange and data calculation in different threads. There may be a lot of calculation in memory. Stream calculation is fast in and fast out. The disruptor should be a good choice.
Baidu uid generator
Some of them use ring buffer and de pseudo sharing to cache the generated uid. They should also partially refer to the disruptor.
Core concepts of Disruptor
Start by understanding the core concept of Disruptor to understand how it works. The conceptual model described below is not only a domain object, but also a core object mapped to code implementation.
Ring Buffer
The data structure in the Disruptor is used to store the data produced by the producer
As the name suggests, a circular buffer. RingBuffer was once the most important object in the Disruptor, but since version 3.0, its responsibility has been simplified to only store and update the data (events) exchanged through the Disruptor. In some more advanced application scenarios, Ring Buffer can be completely replaced by the user-defined implementation.
Sequence
Serial number. In the Disruptor framework, there are serial numbers everywhere
This serial number determines where the producer's data is placed in the RingBuffer, where the consumer should consume the data, and what the data is in a certain location in the RingBuffer. This sequence number can be simply understood as a variable of type AtomicLong. It uses padding method to eliminate the pseudo sharing problem of cache.
Sequencer
Serial number generator, this class is mainly used to coordinate producers
When the producer produces data, the Sequencer will generate an available Sequence, and then the producer will know where the data is placed in the ring queue.
Sequencer is the real core of Disruptor. This interface has two implementation classes, SingleProducerSequencer and MultiProducerSequencer, which define the concurrent algorithm for fast and correct data transfer between producers and consumers.
Sequence Barrier
Serial number barrier
We all know that when consumers consume data, they need to know where to consume data. Consumers can't consume whatever data they want. The SequencerBarrier serves as such a barrier. If you want to consume data, I'll tell you a Sequence. You can consume the data at that location. If there is no data, just wait
Wait Strategy
Wait Strategy determines how a consumer waits for the producer to put an Event into the Disruptor.
Imagine a scenario where producers produce very slowly and consumers consume very quickly. Then there will inevitably be insufficient data. How can consumers wait at this time? WaitStrategy was born to solve problems.
Event
The data passed from producer to consumer is called Event. It is not a specific type defined by the Disruptor, but is defined and specified by the user of the Disruptor.
EventHandler
The event handling interface defined by the Disruptor is implemented by the user to handle events. It is the real implementation of the Consumer.
Producer
That is, the producer only refers to the user code that calls the Disruptor to publish events. The Disruptor does not define a specific interface or type.
Disruptor properties
The Disruptor is actually like a queue, which is used to migrate data between different threads. However, the Disruptor also implements some features that other queues do not have, such as:
- The same "event" can have multiple consumers. Consumers can either process in parallel or depend on each other to form the processing order (form a dependency graph);
- Pre allocate memory space for storing event content;
- Extreme optimization and lock free design for extremely high performance objectives;
Getting started with Disruptor
Let's use a simple example to experience the Disruptor. The producer will pass a long value to the consumer. After receiving the value, the consumer will print out the value.
Add dependency
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.2</version>
</dependency>
Disruptor API
The debugger API is very simple, mainly including the following steps
Define events
First, create a LongEvent class, which will be put into the ring queue as the message content.
An event is a data type exchanged through a Disruptor.
public class LongEvent {
private long value;
public void set(long value) {
this.value = value;
}
public long getValue() {
return value;
}
}
Define event factory
In order to use the memory pre allocation event of the Disruptor, we need to define an EventFactory
The event factory defines how to instantiate the event defined in step 1 above, and the interface com.com needs to be implemented lmax. disruptor. EventFactory.
The Disruptor pre creates an instance of Event in RingBuffer through EventFactory.
An Event instance is actually used as a "data slot". Before publishing, the publisher obtains an Event instance from RingBuffer, fills the Event instance with data, and then publishes it to RingBuffer. Then, the Consumer obtains the Event instance and reads data from it.
public class LongEventFactory implements EventFactory<LongEvent> {
public LongEvent newInstance() {
return new LongEvent();
}
}
Define the specific implementation of event handling
In order for consumers to handle these events, we define an event handler here, which is responsible for printing events
By implementing the interface com lmax. disruptor. EventHandler defines the concrete implementation of event handling.
public class LongEventHandler implements EventHandler<LongEvent> {
public void onEvent(LongEvent event, long sequence, boolean endOfBatch) {
CommonUtils.calculation();
System.out.println("consumer:" + Thread.currentThread().getName() + " Event: value=" + event.getValue() + ",sequence=" + sequence + ",endOfBatch=" + endOfBatch);
}
}
Specify wait policy
Disruptor defines com lmax. disruptor. The waitstrategy interface is used to abstract how consumers wait for new events. This is the application of the policy pattern
WaitStrategy YIELDING_WAIT = new YieldingWaitStrategy();
Start the Disruptor
N ote that the size of ringBufferSize must be the nth power of 2
// Specify event factory
LongEventFactory factory = new LongEventFactory();
// Specifies the byte size of ring buffer, which must be the nth power of 2
int bufferSize = 1024;
//Single threaded mode for additional performance
Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory,
bufferSize, Executors.defaultThreadFactory(),
ProducerType.SINGLE,
new YieldingWaitStrategy());
//Set event business processor - Consumer
disruptor.handleEventsWith(new LongEventHandler());
//Start the disruptor thread
disruptor.start();
Publishing events using Translators
In version 3.0 of Disruptor, due to the addition of rich Lambda style API s, it can be used to help group developers simplify the process. Therefore, after version 3.0, Event Publisher/Event Translator is preferred to publish events.
Make a mapping between entity class and long
public class LongEventProducerWithTranslator {
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducerWithTranslator(RingBuffer<LongEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
private static final EventTranslatorOneArg<LongEvent, Long> TRANSLATOR =
new EventTranslatorOneArg<LongEvent, Long>() {
public void translateTo(LongEvent event, long sequence, Long data) {
event.set(data);
}
};
public void onData(Long data) {
ringBuffer.publishEvent(TRANSLATOR, data);
}
}
Close the Disruptor
disruptor.shutdown();//Close the disruptor and the method will block until all events are handled
Code integration
LongEventMain
Consumer producer startup class, which calls the start() method to complete the startup thread by constructing the disruptor object. Disruptor requires ringbuffer ring, consumer data processing factory, WaitStrategy, etc
The ByteBuffer class is used to wrap messages. ProducerType.SINGLE is single threaded, which can improve performance
public static void main(String[] args) {
// Specify event factory
LongEventFactory factory = new LongEventFactory();
// Specifies the byte size of ring buffer, which must be the nth power of 2
int bufferSize = 1024;
//Single threaded mode for additional performance
Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory,
bufferSize, Executors.defaultThreadFactory(),
ProducerType.SINGLE,
new YieldingWaitStrategy());
//Set event business processor - Consumer
disruptor.handleEventsWith(new LongEventHandler());
//Start the disruptor thread
disruptor.start();
// Get the ring buffer ring, which is used to receive events produced by the producer
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
//Specify the event producer for ring buffer
LongEventProducerWithTranslator producer = new LongEventProducerWithTranslator(ringBuffer);
//Loop traversal
for (int i = 0; i < 100; i++) {
//Get a random number
long value = (long) ((Math.random() * 1000000) + 1);
//Publish data
producer.onData(value);
}
//Stop the disruptor thread
disruptor.shutdown();
}
Run test
test result
consumer:pool-1-thread-1 Event: value=579797,sequence=0 consumer:pool-1-thread-1 Event: value=974942,sequence=1 consumer:pool-1-thread-1 Event: value=978977,sequence=2 consumer:pool-1-thread-1 Event: value=398080,sequence=3 consumer:pool-1-thread-1 Event: value=867251,sequence=4 consumer:pool-1-thread-1 Event: value=796707,sequence=5 consumer:pool-1-thread-1 Event: value=786555,sequence=6 consumer:pool-1-thread-1 Event: value=182193,sequence=7 .....
Event: value = the data received by the consumer, and sequence is the position of the data in the ringbuffer ring.
Performance comparison test
In order to intuitively feel how fast the Disruptor is, a performance comparison test is designed: Producer releases 100 million events, timing starts from the first event, and captures the time taken by the Consumer to process all events.
The test case designs two different implementations of how Producer notifies consumers of events:
2. The event publishing of producer and the event processing of Consumer are in different threads and passed to Consumer through ArrayBlockingQueue for processing;
3. The event publishing of the producer and the event processing of the Consumer are in different threads and passed to the Consumer through the Disruptor for processing;
code implementation
Calculation code
Perform CAS accumulation operation
public class CommonUtils {
private static AtomicLong count = new AtomicLong(0);
public static void calculation() {
count.incrementAndGet();
}
public static long get() {
return count.get();
}
}
abstract class
It takes time to perform 100 million CAS operations
public abstract class AbstractTask<T> {
private static final Logger logger = LoggerFactory.getLogger(AbstractTask.class);
//Thread pool
private static final ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors() + 1);
private static final CountDownLatch countDownLatch = new CountDownLatch(1);
//100 million tests
public static long tasksize = 100000000;
/**
* Start calling test
*/
public void invok() {
//Calculate current event
long currentTime = System.currentTimeMillis();
//Get listener
Runnable monitor = monitor();
if (null != monitor) {
executor.execute(monitor);
}
//start-up
start();
//Execute task release
Runnable runnable = getTask();
for (long i = 0; i < tasksize; i++) {
runnable.run();
}
//Stop task
stop();
//Wait for task publishing to complete
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
executor.shutdown();
//Get processing results
T result = getResult();
//Calculation time
long duration = System.currentTimeMillis() - currentTime;
//Compute throughput
long throughput = (tasksize / duration) * 1000;
logger.info("Throughput per second:[{}];({}/{})", throughput, result, duration);
}
/**
* Get listener
*
* @return
*/
public Runnable monitor() {
return null;
}
/**
* Start task
*/
public void start() {
}
/**
* Complete the task
*/
public void complete() {
countDownLatch.countDown();
}
/**
* Stop task
*/
public void stop() {
}
/**
* Get the tasks to be performed
*
* @return
*/
public abstract Runnable getTask();
/**
* Get run results
*
* @return
*/
public abstract T getResult();
}
Disruptor performance test code
public class DisruptorTest extends AbstractTask<Long> {
//Define random number generator
private static final Random r = new Random();
//Define the Disruptor object
private Disruptor disruptor = null;
//Define the Disruptor event publishing object
private LongEventProducerWithTranslator translator = null;
/**
* start-up
*/
@Override
public void start() {
//Define event factory
EventFactory<LongEvent> eventFactory = new LongEventFactory();
// RingBuffer size, which must be the nth power of 2;
int ringBufferSize = 1024 * 1024;
//Building a disruptor object
disruptor = new Disruptor<LongEvent>(eventFactory,
ringBufferSize, Executors.defaultThreadFactory(), ProducerType.SINGLE,
new YieldingWaitStrategy());
//Define event handling classes
EventHandler<LongEvent> eventHandler = new LongEventHandler();
//Configure event handling classes
disruptor.handleEventsWith(eventHandler);
//Start the disruptor
disruptor.start();
//Create event publishing object
translator = new LongEventProducerWithTranslator(disruptor.getRingBuffer());
}
/**
* Stop task
*/
@Override
public void stop() {
disruptor.shutdown();
System.out.println("Operation result:" + CommonUtils.get());
//Complete the task
complete();
}
/**
* Get the tasks to be performed
*
* @return
*/
@Override
public Runnable getTask() {
return () -> {
publishEvent();
};
}
/**
* Get run results
*
* @return
*/
@Override
public Long getResult() {
return CommonUtils.get();
}
/**
* Publish object
*/
private void publishEvent() {
//Get the business data to be passed through the event
Long data = r.nextLong();
// Publish event
translator.onData(data);
HashSet<Object> objects = new HashSet<>();objects.contains()
}
public static void main(String[] args) {
DisruptorTest disruptorTest = new DisruptorTest();
disruptorTest.invok();
}
}
Output results
10:45:22.941 [main] INFO com.heima.task.AbstractTask - Throughput per second:[18171000]; (100000000/5503)
ArrayBlockingQueue performance test code
public class ArrayBlockingQueueTest extends AbstractTask {
private static final Random r = new Random();
private static final ArrayBlockingQueue<Long> queue = new ArrayBlockingQueue(10000000);
@Override
public Runnable monitor() {
return () -> {
try {
for (int i = 0; i < tasksize; i++) {
//Get an element
queue.take();
//perform calculation
CommonUtils.calculation();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
complete();
};
}
public static void main(String[] args) {
ArrayBlockingQueueTest test = new ArrayBlockingQueueTest();
test.invok();
}
@Override
public Runnable getTask() {
return () -> {
publish();
};
}
@Override
public Object getResult() {
return CommonUtils.get();
}
public void publish() {
Long data = r.nextLong();
try {
queue.put(data);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Output results
10:45:46.379 [main] INFO com.heima.task.AbstractTask - Throughput per second:[6192000]; (100000000/16148)
Test comparison

Official performance test of Disruptor
The Disruptor paper describes an experiment:
The test program calls a function that automatically increments a 64 bit counter by 500 million times.
Machine environment: 2.4G 6-core operation: the 64 bit counter accumulates 500 million times
High performance principle
- Ring array structure is introduced: array elements will not be recycled to avoid frequent GC,
- Lock free design: CAS lock free mode is adopted to ensure thread safety
- Attribute filling: avoid pseudo sharing by adding additional useless information
- Location of element location: an index is added automatically in the same way as consistent hash
Pseudo sharing concept
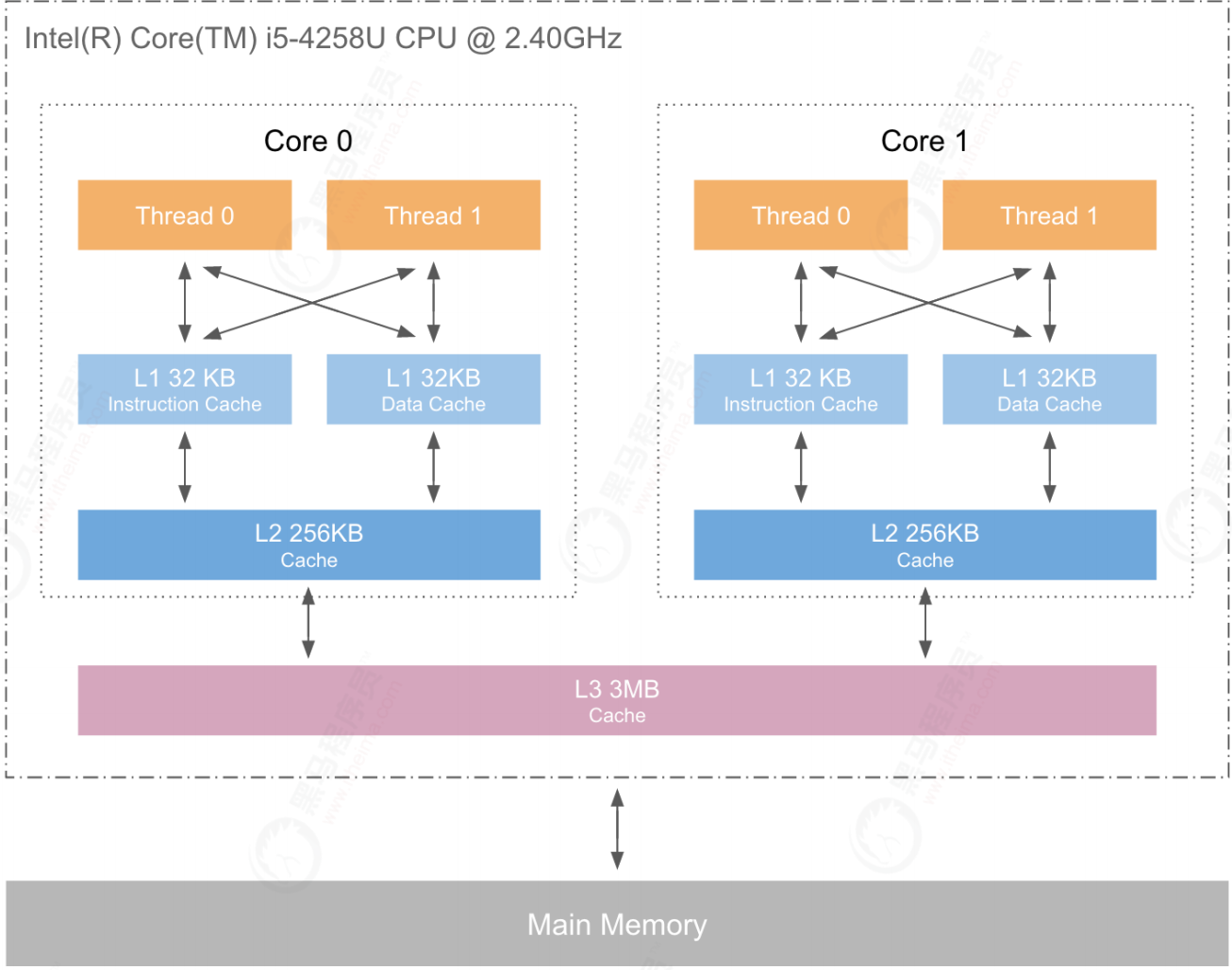
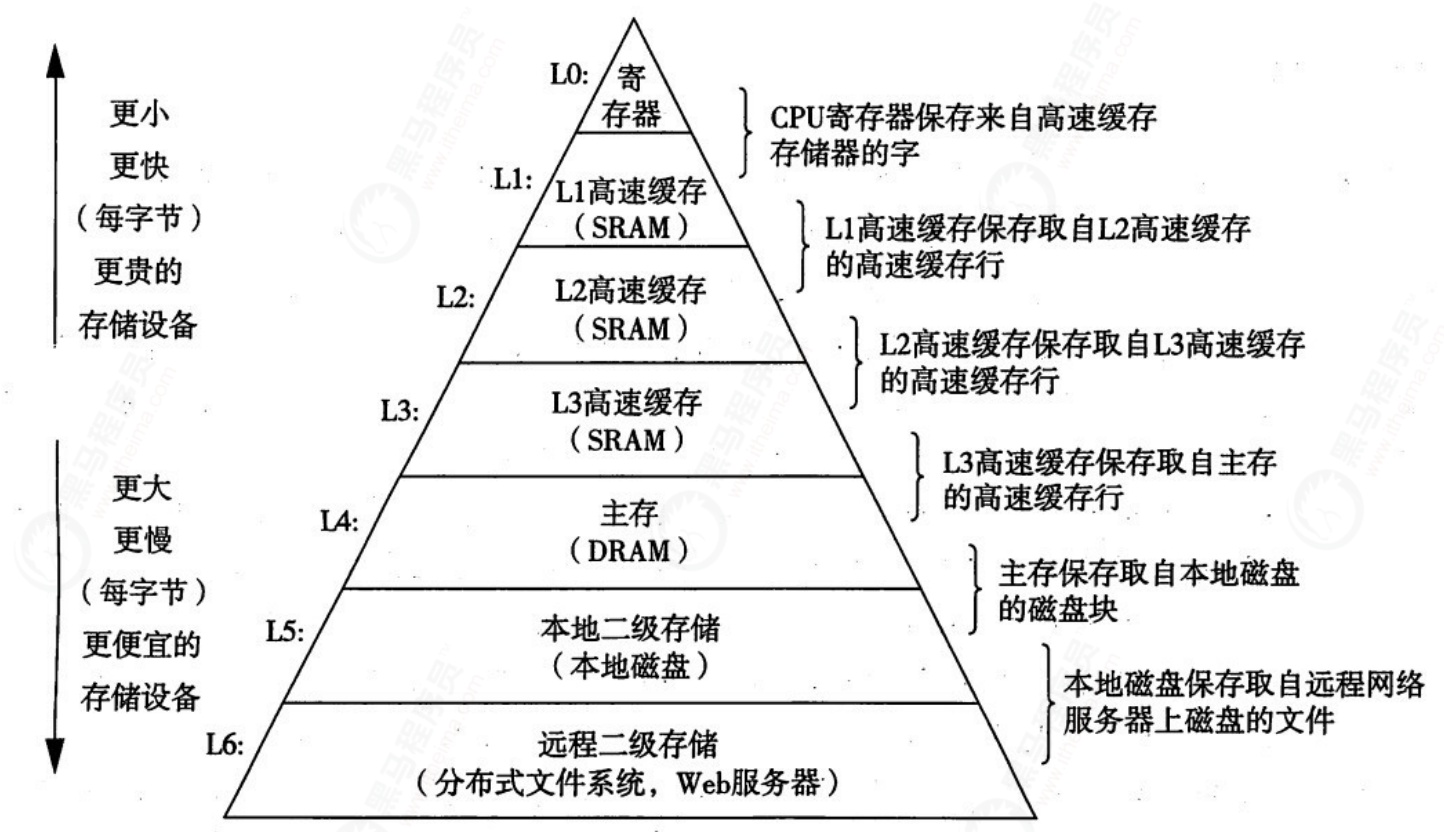
Computer cache composition
The following figure shows the basic structure of the calculation. L1, L2 and L3 represent L1 cache, L2 cache and L3 cache respectively. The closer to the CPU cache, the faster the speed and the smaller the capacity. Therefore, L1 cache is small but fast, and close to the CPU core using it; L2 is larger and slower, and can still only be used by a single CPU core; L3 is larger and slower, and is shared by all CPU cores on a single slot; Finally, main memory is shared by all CPU cores on all slots.
When the CPU wants to read a data, first look it up from the L1 cache. If not, then look it up from the L2 cache. If not, look it up from the L3 cache or memory. Generally speaking, the hit rate of each level of cache is about 80%, that is, 80% of all data can be found in the level-1 cache, and only 20% of the total data needs to be read from the level-2 cache, level-3 cache or memory. It can be seen that the level-1 cache is the most important part of the whole CPU cache architecture.
The following table shows the consumption data of some cache misses:
| From cpu to | About cpu cycles required | About time of need |
|---|---|---|
| Main memory | About 60-80ns | |
| QPI bus | About 20ns | |
| L3 cache | About 40-45 cycles | About 15ns |
| L2 cache | About 10 cycles | About 3ns |
| L1 cache | About 3-4 cycles | About 1ns |
| register | 1cycle |
It can be seen that the CPU reads the data in main memory nearly 2 orders of magnitude slower than reading from L1.
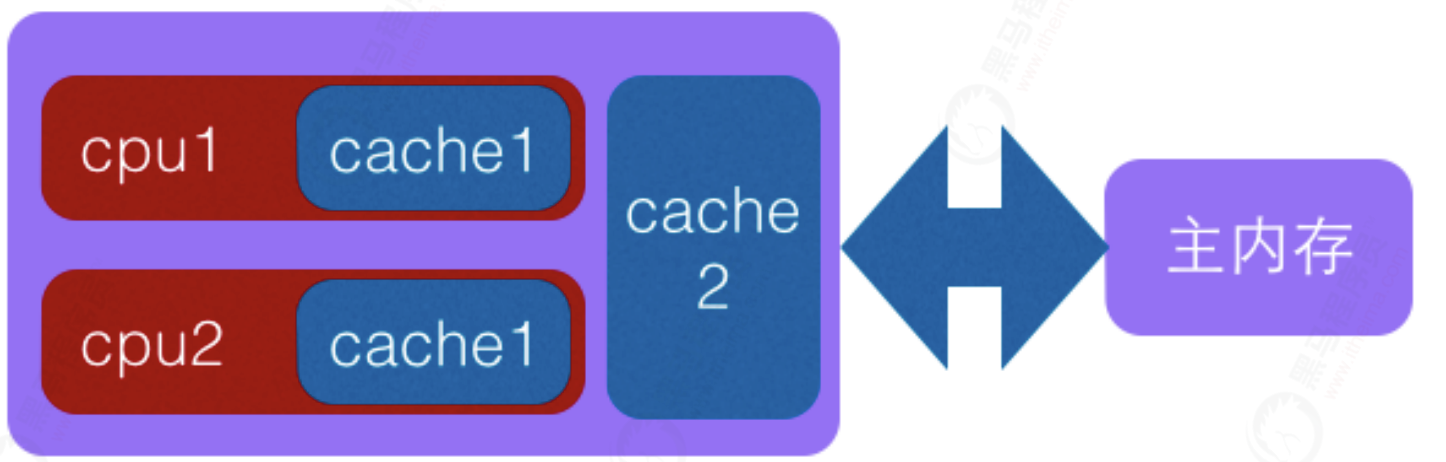
What are cache rows
In order to solve the problem of running speed difference between main memory and CPU in computer system, one or more levels of Cache will be added between CPU and main memory. This Cache is generally integrated into the CPU, so it is also called CPU Cache. As shown in the figure, it is a two-level Cache structure.
The internal cache is stored by rows. Each row is called a cache line, which is composed of many cache lines. Cache line is the smallest unit of data exchanged between cache and RAM. The size of cache rows is generally power bytes of 2, usually 64 bytes. Cache line is the unit of data exchange between cache and main memory.

When the CPU loads the memory data into the cache, it will put the adjacent 64 Byte data into the same Cache line because of the spatial locality: the adjacent data is likely to be accessed in the future.
linux view cache line size
more /sys/devices/system/cpu/cpu1/cache/index0/coherency_line_size 64
What is sharing
CPU cache is to cache rows (cache line) is stored in units. The cache line is usually 64 bytes, and it effectively refers to an address in main memory. A Java long type is 8 bytes, so 8 long variables can be stored in a cache line. Therefore, if you access a long group, when a value in the array is loaded into the cache, it will load another 7 So that you can traverse the array very quickly. In fact, you can traverse any data structure allocated in consecutive memory blocks very quickly. If the items in the data structure are not adjacent to each other in memory (such as linked list), you will not get the advantage of free cache loading, and each item in these data structures may have cache misses. The following figure is a schematic diagram of a CPU cache line:
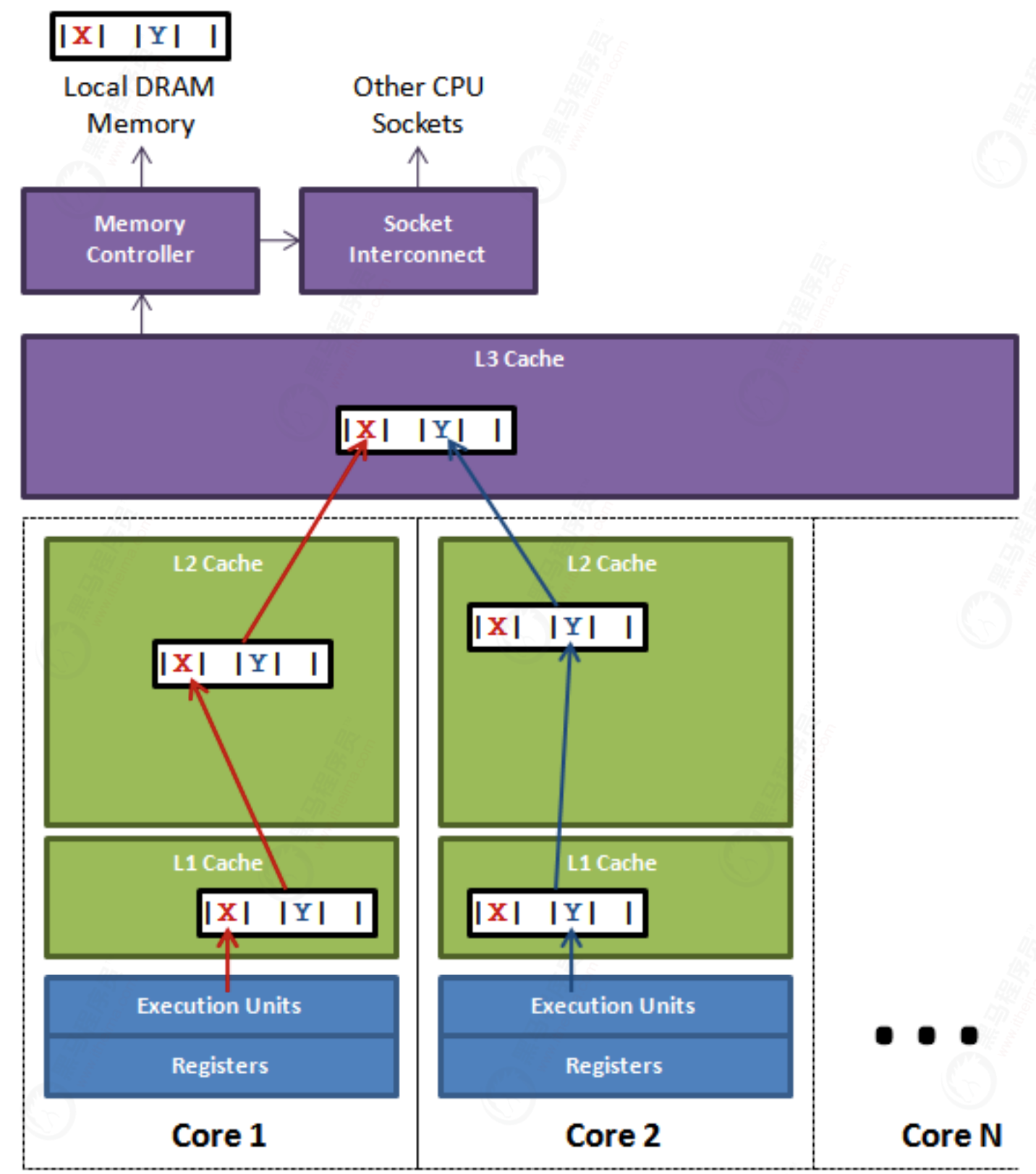
On the surface, X and Y are operated by independent threads, and there is no relationship between the two operations. They just share a cache row, but all contention conflicts come from sharing.
What is pseudo sharing
When the CPU accesses a variable, it will first check whether the variable exists in the CPU Cache. If so, it will be obtained directly from it. If not, it will obtain the variable from the main memory, and then copy the memory of a cache line size in the memory area where the variable is located to the cache (cache line is the unit for data exchange between the cache and the main memory).
Since memory blocks rather than single variables are stored in the cache line, multiple variables may be stored in one cache line. When multiple threads modify multiple variables in a cache line at the same time, since only one thread can operate the cache line at the same time, the performance will be reduced compared with putting each variable in one cache line, which is pseudo sharing.
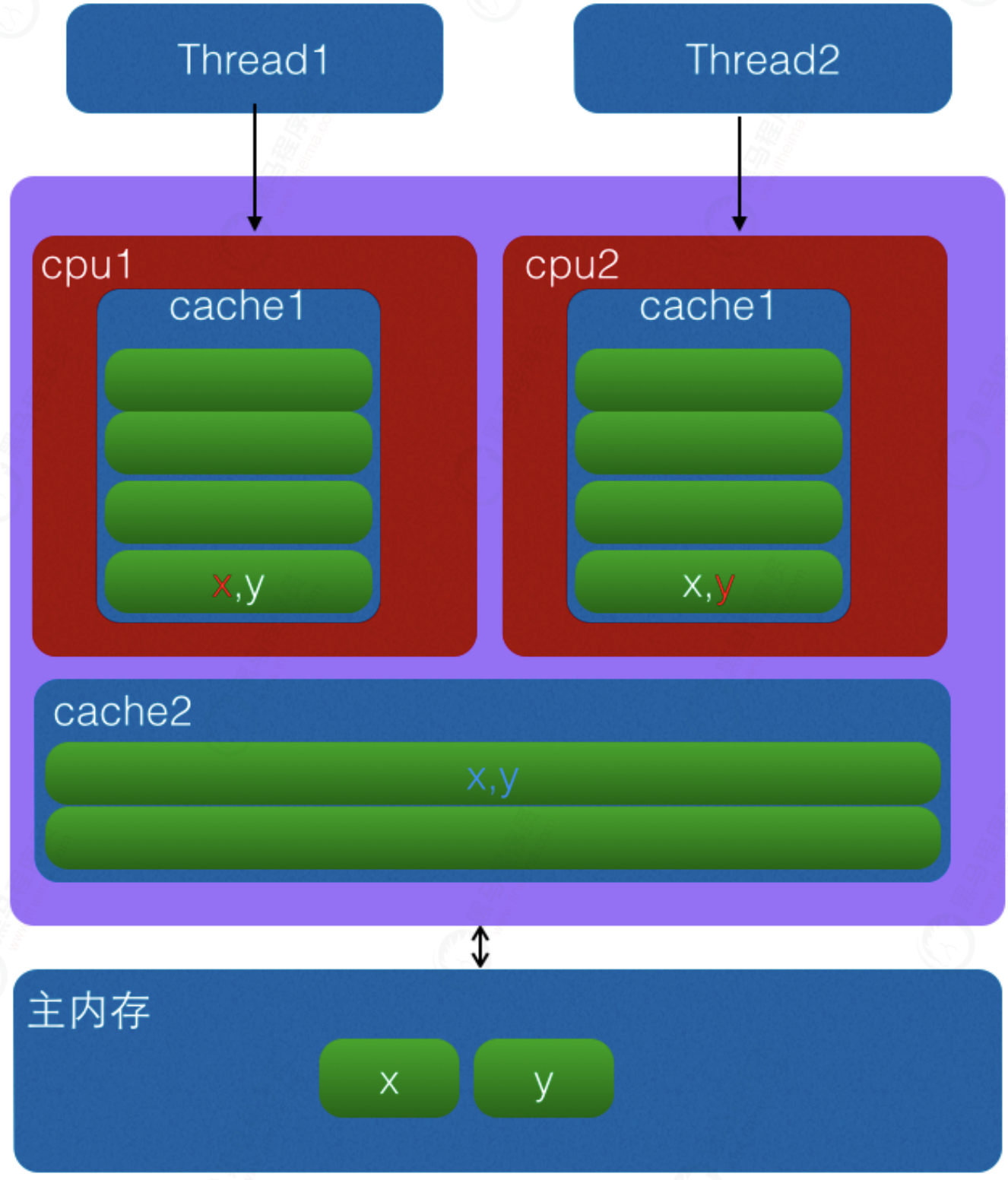
As shown in the figure above, variables X and y are placed in the primary and secondary caches of the CPU at the same time. When thread 1 uses CPU1 to update variable x, it will first modify the cache line of the primary cache variable X of CPU1. At this time, the cache consistency protocol will cause the cache line corresponding to variable x in cpu2 to be invalid. Then thread 2 can only go to the secondary cache to find when writing variable x, This destroys the L1 cache, which is faster than the L2 cache. Worse, if the CPU has only L1 cache, it will lead to frequent direct access to main memory.
Our caches are processed by cache lines as a unit, so invalidating the cache of x will also invalidate y, and vice versa.
Why does pseudo sharing occur
Pseudo sharing occurs because multiple variables are put into a Cache line, and multiple threads write different variables in the Cache line at the same time. So why are multiple variables put into one Cache line. In fact, the unit of data exchange between Cache and memory is Cache line. When the variable to be accessed by the CPU is not hit in the Cache, the variable will be placed in the memory with the size of Cache line, such as Cache line, according to the locality principle of program operation.
long a; long b; long c; long d;
The above code declares four long variables. Assuming that the size of cache line is 32 bytes, when the cpu accesses variable a and finds that the variable is not hit in the cache, it will go to the main memory and put variable a and B, C and D near the memory address into the cache line. That is, multiple variables with consecutive addresses may be put into one cache line. When an array is created, multiple elements in the array will be put into the same cache line. So how do multiple variables put into the cache line in a single thread affect performance? In fact, when a single thread accesses, because the array elements are put into one or more cache lines, it is beneficial to code execution, because the data is in the cache, and the code execution will be faster.
How to solve pseudo sharing
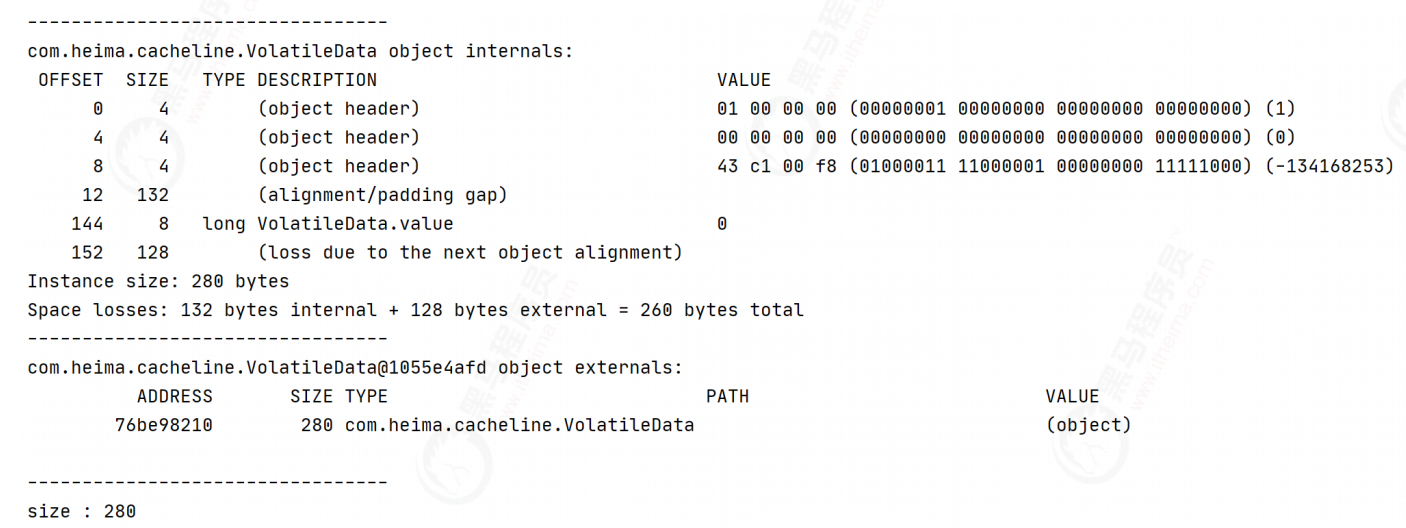
The most direct way to solve pseudo sharing is padding. For example, in the following volatile long, a long takes up 8 bytes, and the Java object header takes up 8 bytes (32-bit system) or 12 bytes (64 bit system, object header compression is enabled by default, and 16 bytes are not enabled). If a cache line is 64 bytes, we can fill 6 long (6 * 8 = 48 bytes).
Do not use field fill
public class VolatileData {
// Occupied 8 bytes + 48 + object header = 64 bytes
//Data to be manipulated
volatile long value;
public VolatileData() {
}
public VolatileData(long defValue) {
value = defValue;
}
public long accumulationAdd() {
//Because single threaded operations do not require locking
value++;
return value;
}
public long getValue() {
return value;
}
}
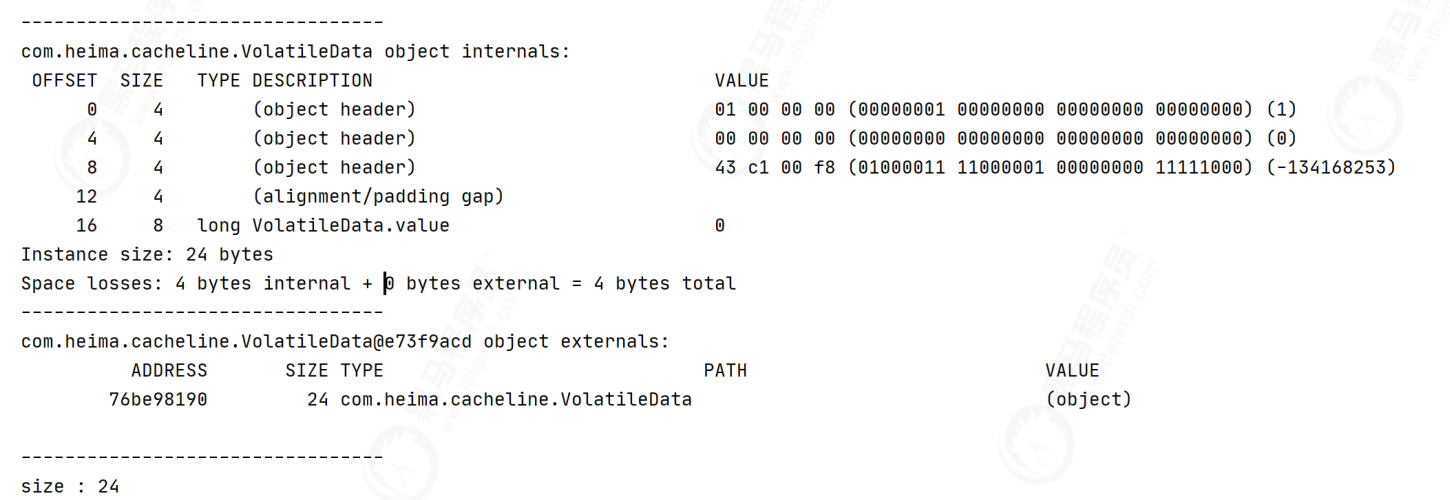
Fill field
Because jdk1 Automatic code optimization after 7 will delete useless code in jdk1 Versions after 7 do not take effect.
public class DataPadding {
//Fill 6 long type fields 8 * 5 = 40 bytes
private long p1, p2, p3, p4, p5;
//Data to be manipulated
volatile long value;
}
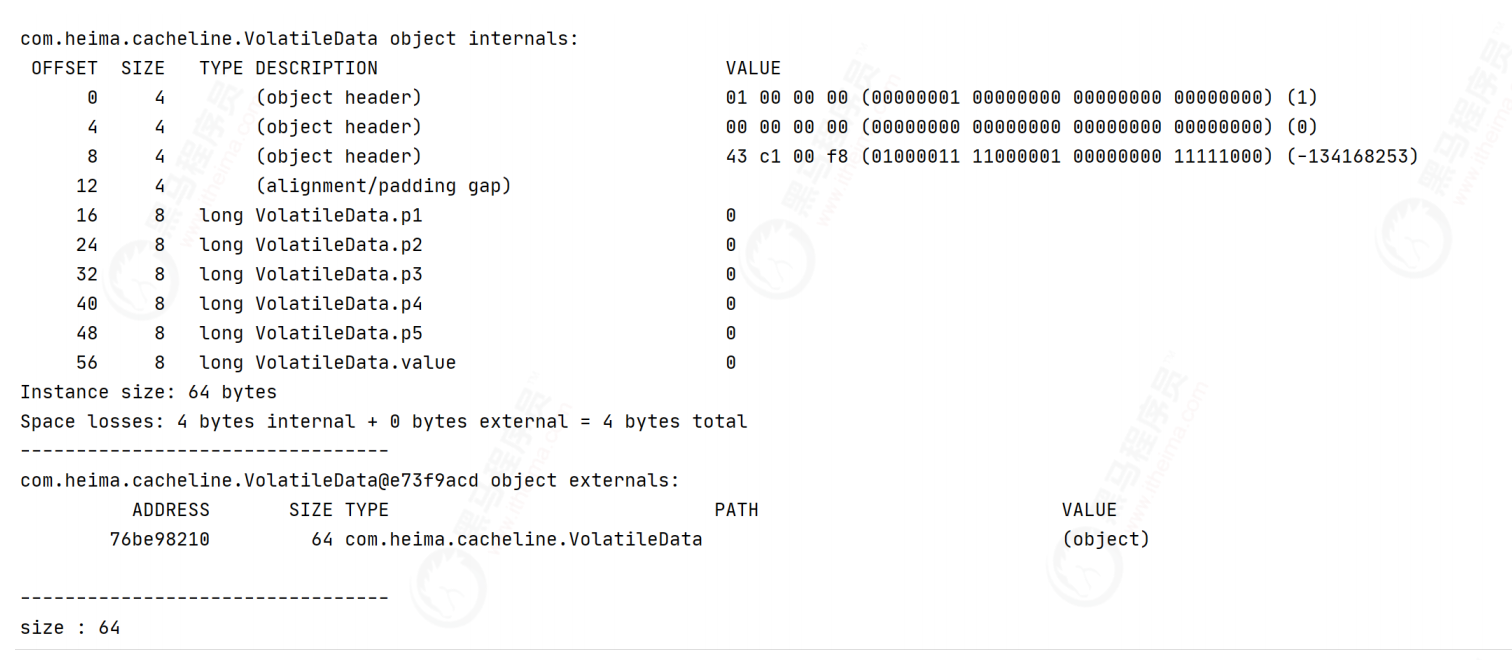
Mode of inheritance
public class DataPadding {
//Fill 6 long type fields 8 * 5 = 40 bytes
private long p1, p2, p3, p4, p5;
}
Inherit cache population class
public class VolatileData extends DataPadding {
// Occupied 8 bytes + 48 + object header = 64 bytes
//Data to be manipulated
volatile long value;
public VolatileData() {
}
public VolatileData(long defValue) {
value = defValue;
}
public long accumulationAdd() {
//Because single threaded operations do not require locking
value++;
return value;
}
public long getValue() {
return value;
}
}
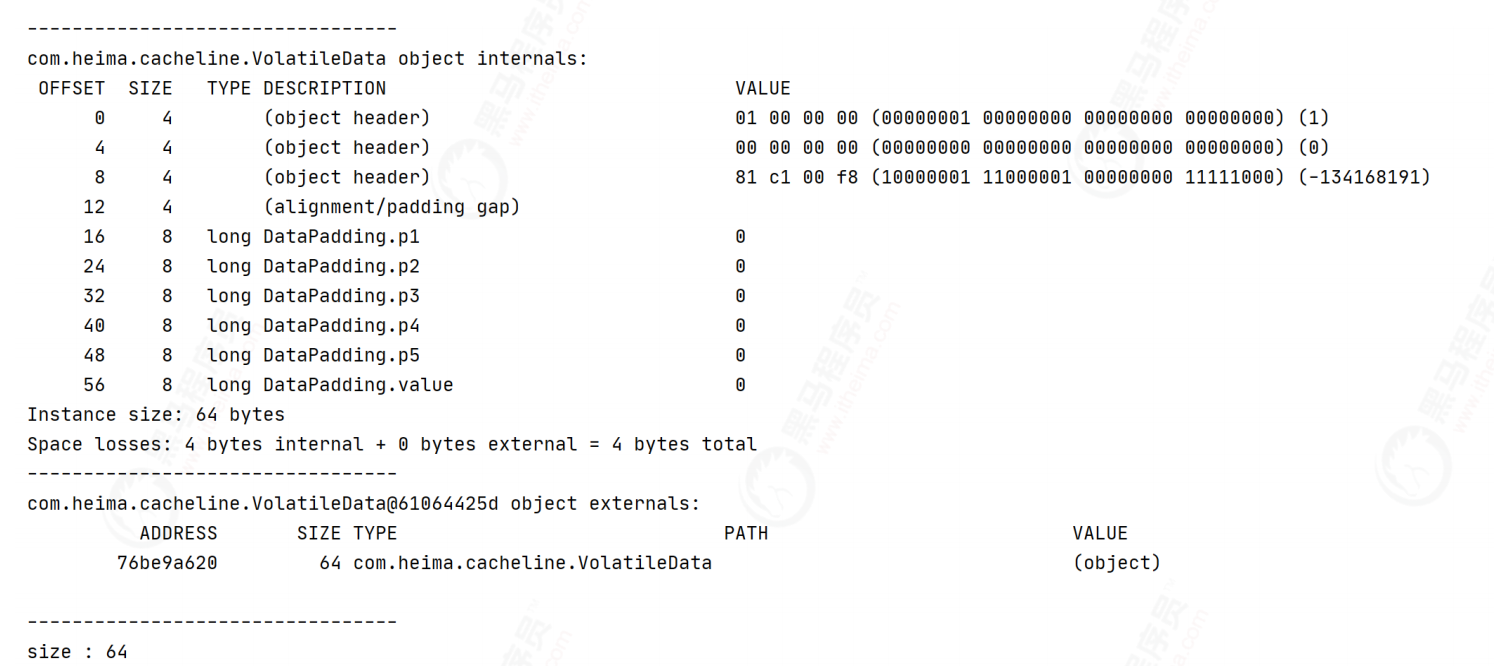
Disruptor fill mode
class LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
protected volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}
Inherit fill class
public class VolatileData extends RhsPadding {
// Occupied 8 bytes + 48 + object header = 64 bytes
//Data to be manipulated
volatile long value;
public VolatileData() {
}
public VolatileData(long defValue) {
value = defValue;
}
public long accumulationAdd() {
//Because single threaded operations do not require locking
value++;
return value;
}
public long getValue() {
return value;
}
}
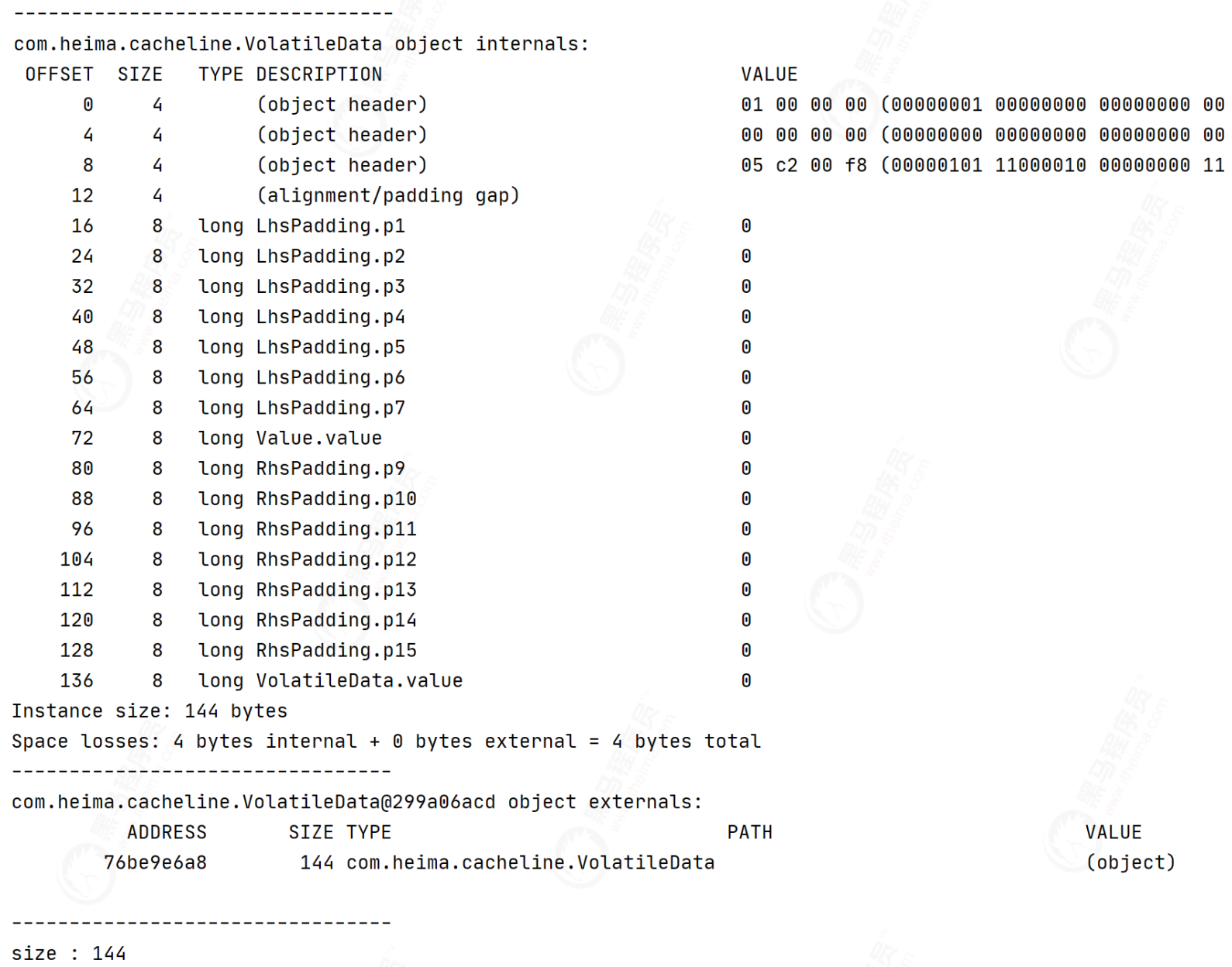
@Contented annotation
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD, ElementType.TYPE})
public @interface Contended {
/**
* The (optional) contention group tag.
* This tag is only meaningful for field level annotations.
*
* @return contention group tag.
*/
String value() default "";
}
@Contended
public class VolatileData {
// Occupied 8 bytes + 48 + object header = 64 bytes
//Data to be manipulated
volatile long value;
public VolatileData() {
}
public VolatileData(long defValue) {
value = defValue;
}
public long accumulationAdd() {
//Because single threaded operations do not require locking
value++;
return value;
}
public long getValue() {
return value;
}
}
matters needing attention
@ sun. Com is provided in Java 8 misc. When using contented to avoid pseudo sharing, you need to set the JVM startup parameter - XX: - restrictcontented at runtime, otherwise it may not take effect.
Performance comparison
Test code
Comparison between using and not using cache row padding
public class CacheLineTest {
/**
* Variables populated by cache rows
*/
private VolatileData volatileData1 = new VolatileData(0);
private VolatileData volatileData2 = new VolatileData(0);
private VolatileData volatileData3 = new VolatileData(0);
private VolatileData volatileData4 = new VolatileData(0);
private VolatileData volatileData5 = new VolatileData(0);
private VolatileData volatileData6 = new VolatileData(0);
private VolatileData volatileData7 = new VolatileData(0);
/**
* Number of cycles
*/
private final long size = 100000000;
/**
* Carry out accumulation operation
*/
public void accumulationX(VolatileData volatileData) {
//Calculation time
long currentTime = System.currentTimeMillis();
long value = 0;
//Cyclic accumulation
for (int i = 0; i < size; i++) {
//How to use cache row padding
value = volatileData.accumulationAdd();
}
//Print
System.out.println(value);
//Printing time
System.out.println("Time consuming:" + (System.currentTimeMillis() - currentTime));
}
public static void main(String[] args) {
//create object
CacheLineTest cacheRowTest = new CacheLineTest();
//Create thread pool
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
//Start three threads and call their respective methods
executorService.execute(() -> cacheRowTest.accumulationX(cacheRowTest.volatileData1));
executorService.execute(() -> cacheRowTest.accumulationX(cacheRowTest.volatileData2));
executorService.execute(() -> cacheRowTest.accumulationX(cacheRowTest.volatileData3));
executorService.execute(() -> cacheRowTest.accumulationX(cacheRowTest.volatileData4));
executorService.execute(() -> cacheRowTest.accumulationX(cacheRowTest.volatileData5));
executorService.execute(() -> cacheRowTest.accumulationX(cacheRowTest.volatileData6));
executorService.execute(() -> cacheRowTest.accumulationX(cacheRowTest.volatileData7));
executorService.shutdown();
}
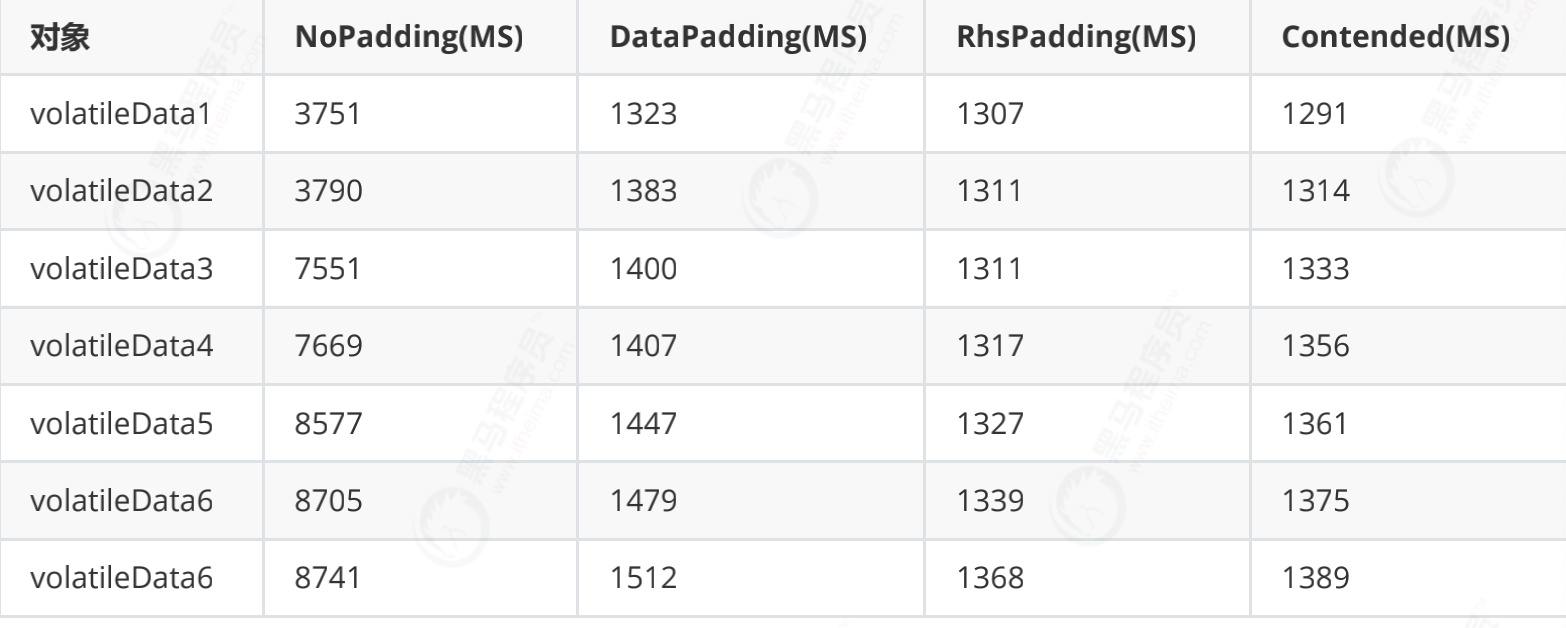
test data
With the same structure, there is a speed difference of nearly 50 times between them
Disruptor resolves pseudo sharing
There is an important class Sequence in the Disruptor, which packages a volatile modified long type data value. Whether it is the array based buffer RingBuffer in the Disruptor, or the producer and consumer, they all have their own independent sequences. In the RingBuffer buffer, the Sequence indicates the write progress. For example, every time the producer wants to write data into the buffer, RingBuffer should be called Next() to get the next available relative position. For producers and consumers, Sequence indicates their event Sequence number. Let's see the source code of Sequence class:
class LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
protected volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding{
static final long INITIAL_VALUE=-1L;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static {
UNSAFE= Util.getUnsafe();
try {
VALUE_OFFSET=UNSAFE.objectFieldOffset(Value.class.getDeclaredField("value"));
}catch (final Exception e){
throw new RuntimeException(e);
}
}
public Sequence(){
this(INITIAL_VALUE);
}
public Sequence(final long initialValue){
UNSAFE.putOrderedLong(this,VALUE_OFFSET,initialValue);
}
}
From lines 1 to 11, we can see that the front and back spaces of the actually used variable value are filled by 8 long variables. For a cache line with a size of 64 bytes, It is just full (a long variable value, 8 bytes plus the first / last 7 long variables, 7 * 8 = 56, 56 + 8 = 64 bytes). In this way, the cache line can be filled every time the variable value is read into the cache (for a cache line with a size of 64 bytes, if the cache line size is greater than 64 bytes, there will still be a pseudo sharing problem), so as to ensure that there will be no conflict with other variables every time the data is processed.
Lockless design
Problems in locking mechanism
- Under multi-threaded competition, locking and releasing locks will lead to more context switching and scheduling delays, resulting in performance problems. Moreover, during context switching, the instructions and data cached in front of the cpu will fail, which will have a great loss of performance. Although user state locks avoid these problems, they are only effective when there is no real competition.
- A thread holding a lock causes all other threads that need the lock to hang until the lock is released.
- If a high priority thread waits for a low priority thread to release the lock, it will lead to priority inversion and performance risk.
CAS lock free algorithm
There are many ways to implement lock free non blocking algorithms. Among them, CAS (Compare and swap) is A well-known lock free algorithm. The semantics of CAS is "I think the value of V should be A, if so, update the value of V to B, otherwise, do not modify and tell the actual value of V" , CAS is an optimistic locking technology. When multiple threads try to update the same variable at the same time using CAS, only one thread can update the value of the variable, while other threads fail. The failed thread will not be suspended, but will be told that it has failed in the competition and can try again. CAS has three operands, memory value V, old expected value A, and new value B to be modified. If and only if the expected value A is the same as the memory value V, modify the memory value V to B, otherwise do nothing.
This is a CPU level instruction. In my mind, it works a bit like an optimistic lock - the CPU updates a value, but if the value you want to change is no longer the original value, the operation fails, because obviously, other operations change the value first.
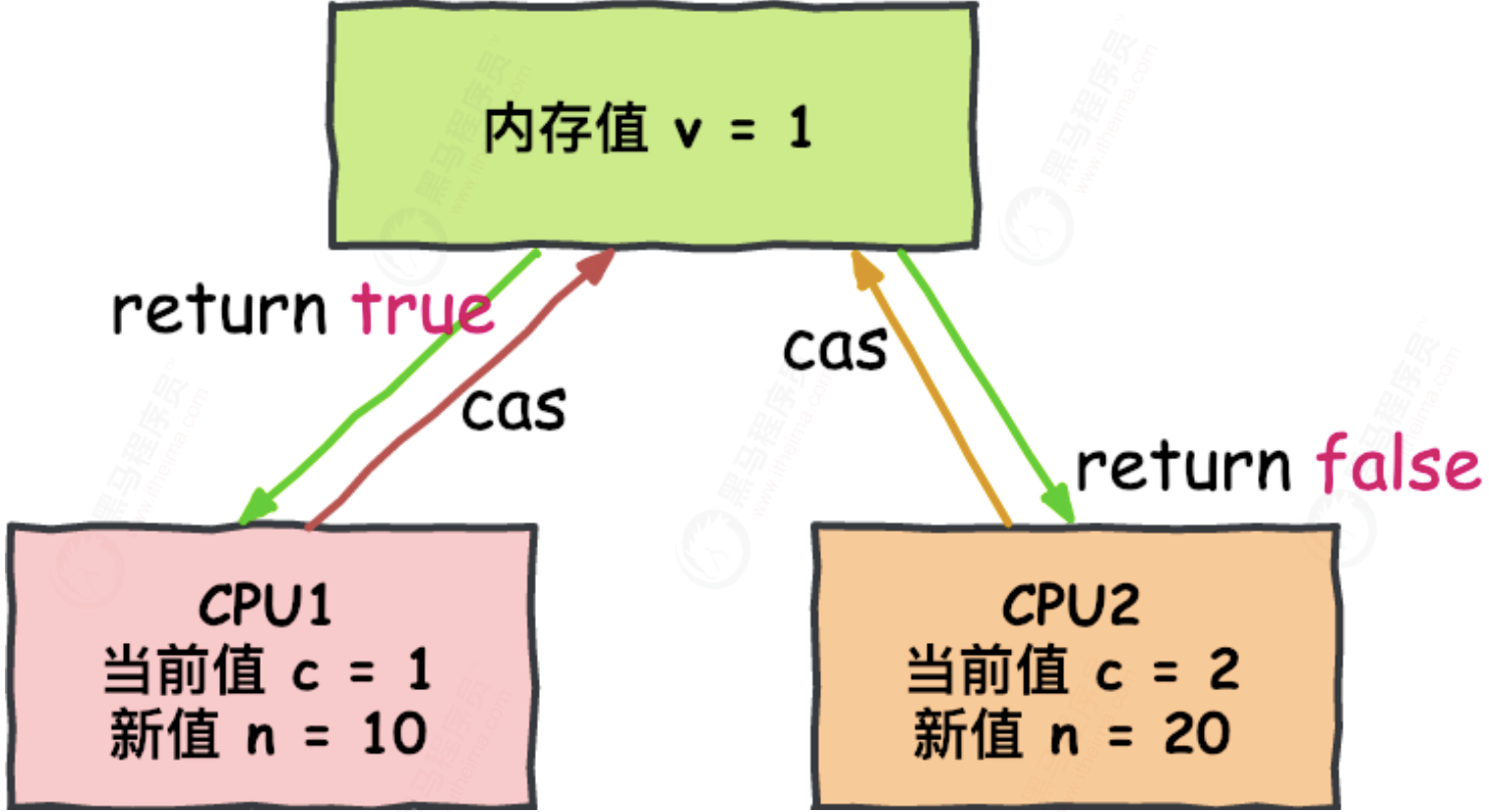
Note that this can be two different cores of the CPU, but not two separate CPUs.
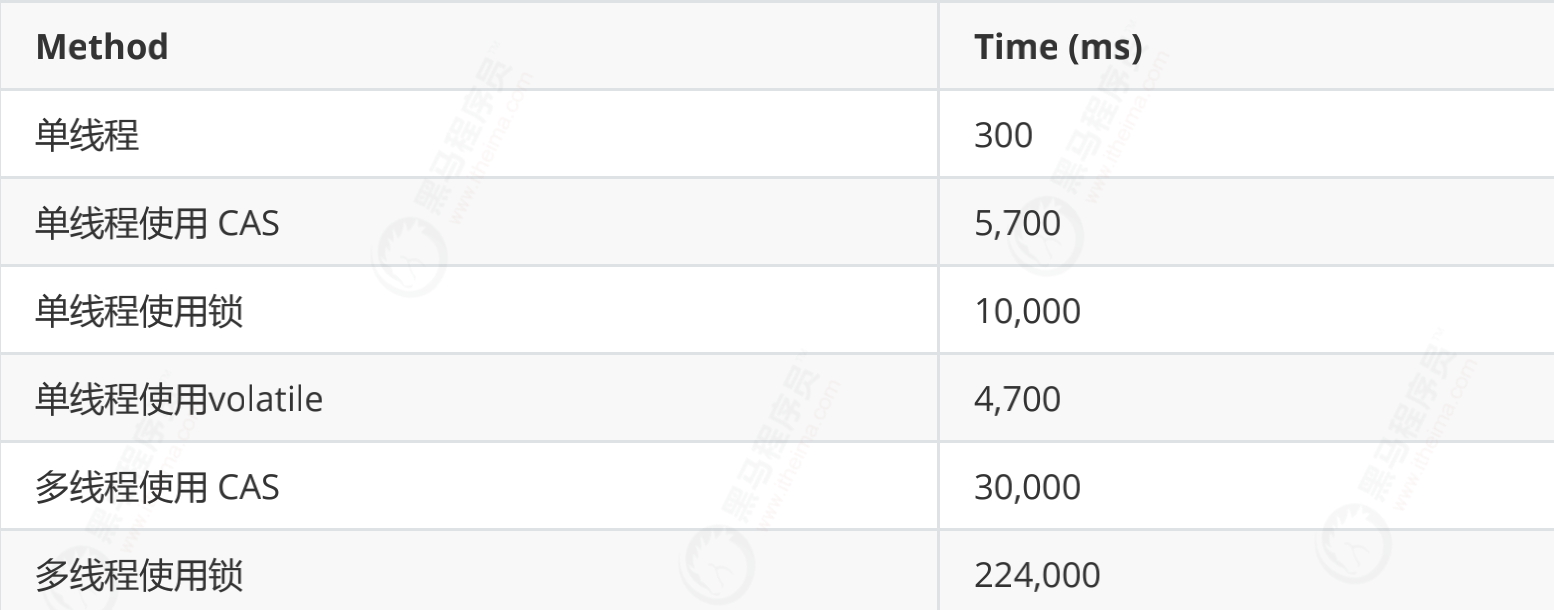
CAS operations consume much less resources than locks because they do not involve the operating system. They operate directly on the CPU. But they are not without cost - in the above test, it takes 300ms for a single thread to have a lock, 10000ms for a single thread to have a lock, and 5700ms for a single thread to use CAS. Therefore, it takes less time than using locks, but it takes more time than one-way without considering competition.
Traditional queue problem
The underlying data structure of queue is generally divided into three types: array, linked list and heap. Here, the heap is to realize the queue with priority characteristics, which is not considered for the time being.
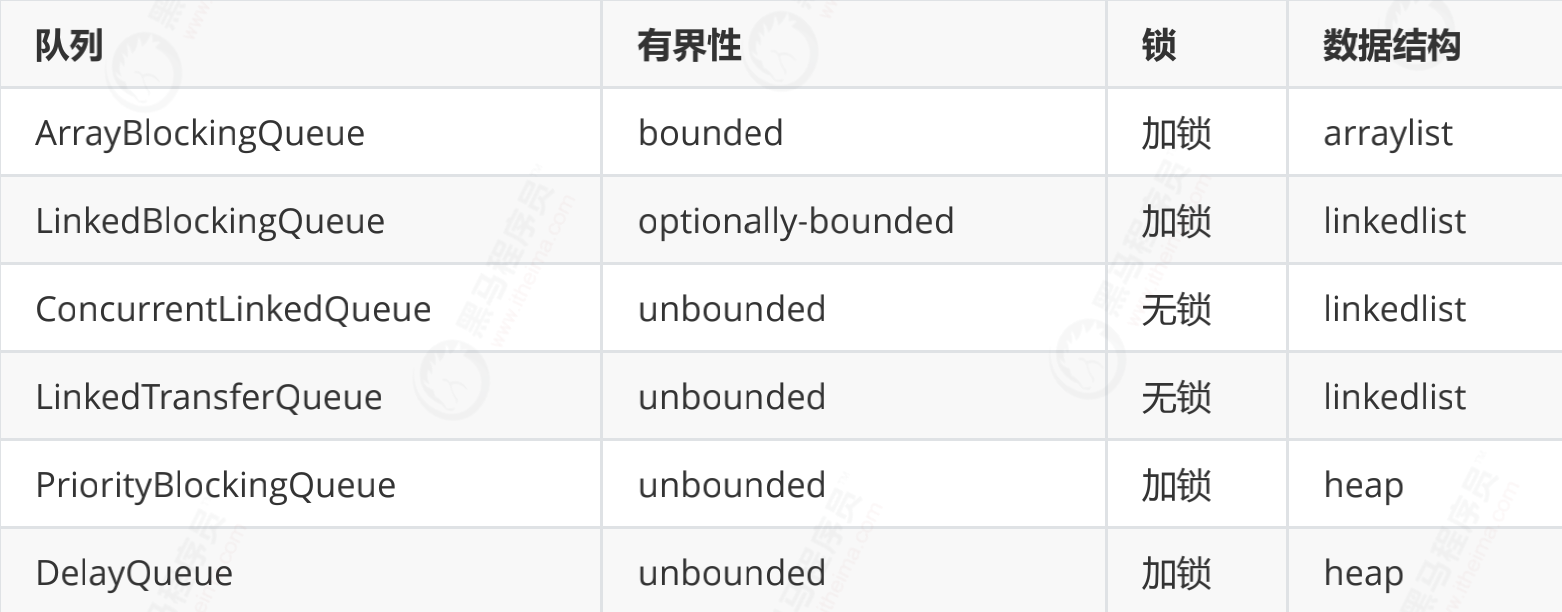
In the system with high stability and performance requirements, in order to prevent the memory overflow caused by too fast producer speed, only bounded queue can be selected;
At the same time, in order to reduce the impact of Java garbage collection on system performance, the data structure in array/heap format will be selected as much as possible. After filtering, only ArrayBlockingQueue meets the conditions. However, ArrayBlockingQueue ensures thread safety by locking, and ArrayBlockingQueue also has the problem of pseudo sharing. These two problems seriously affect the performance.
Lock free design of Disruptor
In multi-threaded environment, multiple producers judge whether the space of each application has been occupied by other producers through the conditional CAS of do/while loop. If it has been occupied, the function will return failure, and the While loop will be re executed to apply for write space.
do
{
current = cursor.get();
next = current + n;
if (!hasAvailableCapacity(gatingSequences, n, current))
{
throw InsufficientCapacityException.INSTANCE;
}
}
while (!cursor.compareAndSet(current, next));
//next is analogous to the array index index of ArrayBlockQueue
return next;
Ring array structure
The ring array structure is the core of the whole Disruptor.
What is a circular array
RingBuffer is a ring (end-to-end ring) used as a buffer for transferring data between different contexts (threads). RingBuffer has a sequence number, which points to the next available element in the array.
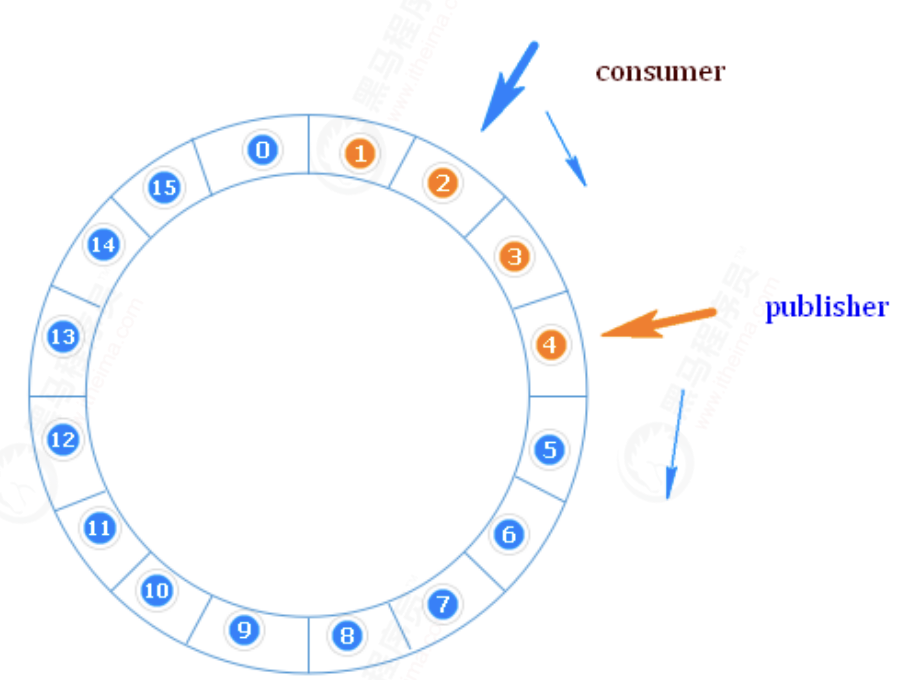
Why ring arrays
To avoid garbage collection, use arrays instead of linked lists. At the same time, the array is more friendly to the processor cache mechanism
First, because it is an array, it is faster than a linked list. Moreover, according to our explanation of the cache line above, when an element in the array is loaded, the adjacent array elements will also be preloaded. Therefore, in such a structure, the cpu does not need to load the next element in the main memory from time to time.
Moreover, you can pre allocate memory for the array so that the array object always exists (unless the program terminates). This means that you don't need to spend a lot of time on garbage collection.
In addition, unlike the linked list, you need to create node objects for each object added to it - correspondingly, when deleting a node, you need to perform the corresponding memory cleaning operation. The elements in the ring array are overwritten to avoid the GC of the jvm.
Secondly, the structure is a ring, and the size of the array is the nth power of 2. In this way, the element location can be passed, and the operation efficiency will be higher. This is a bit like the ring strategy in consistent hash. In the disruptor, the awesome ring structure is RingBuffer. Since it is an array, it has a size, and the size must be the nth power of 2. The structure is as follows:
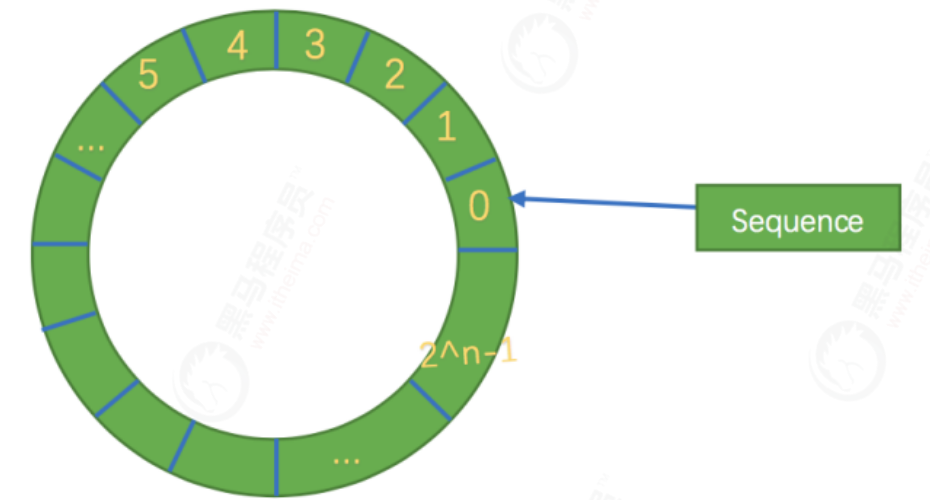
Its essence is just an ordinary array. Only when the data is filled in the queue (i.e. reaching the 2^n-1 position), and then the data is filled, it will start from 0 and overwrite the previous data, so it is equivalent to a ring.
Element location
The array length is 2^n. the positioning speed is accelerated through bit operation. Subscripts are incremented. Don't worry about index overflow. Index is a long type. Even if the processing speed of 1 million QPS, it will take 300000 years to run out.
Waiting strategy
Defines how consumers wait for the next event. (Note: Disruptor defines a variety of different strategies and provides different performance performance for different scenarios) different performance improvements can be achieved by selecting appropriate strategies according to the hardware characteristics of the CPU in the actual running environment and cooperating with the configuration parameters of a specific JVM.
BlockingWaitStrategy
The default policy of the Disruptor is BlockingWaitStrategy. Within BlockingWaitStrategy, locks and condition s are used to control the wake-up of threads
BlockingWaitStrategy is the most inefficient strategy, but it consumes the least CPU and can provide more consistent performance in various deployment environments.
SleepingWaitStrategy
The performance of SleepingWaitStrategy is similar to that of BlockingWaitStrategy, and the CPU consumption is also similar, but it has the least impact on the producer thread through the use of locksupport Parknanos (1) to realize circular waiting, which is suitable for scenarios similar to asynchronous logs;
YieldingWaitStrategy
YieldingWaitStrategy is one of the strategies that can be used in low delay systems. YieldingWaitStrategy increases the spin to wait sequence to an appropriate value. In the loop body, thread. Is called Yield() to allow other queued threads to run. This strategy is recommended in scenarios where extremely high performance is required and the number of event processing lines is less than the number of CPU logical cores;
BusySpinWaitStrategy
It has the best performance and is suitable for low latency systems. This strategy is recommended in scenarios where extremely high performance is required and the number of event processing threads is less than the number of CPU logical cores;
PhasedBackoffWaitStrategy
Spin + yield + custom policy, CPU resource shortage, throughput and latency are not important scenarios.
Production and consumption patterns
According to the above ring structure, let's specifically analyze the working principle of the Disruptor.
Unlike the traditional queue, the Disruptor is divided into a queue head pointer and a queue tail pointer. Instead, it has only one corner mark (seq above). How can this ensure that the produced messages will not cover the messages that are not consumed.
In Disruptor, producers are divided into single producers and multiple producers, while consumers are not distinguished.
In the case of a single producer, ordinary Producers place data in the RingBuffer, so that consumers can obtain the maximum consumption location and consume. When there are multiple producers, another Buffer with the same size as RingBuffer is added, which is called AvailableBuffer.
Among multiple producers, each producer first obtains the writable space through CAS competition, and then slowly puts the data in. If consumers want to consume data at this time, each consumer needs to obtain the maximum consumable subscript, which is the longest continuous sequence subscript obtained in the available buffer.
Single producer production data
The process for the producer to write data in a single thread is relatively simple:
- Apply to write m elements;
- If there are m elements that can be entered, the maximum serial number is returned. Here we mainly judge whether unread elements will be overwritten;
- If the return is correct, the producer starts writing elements.
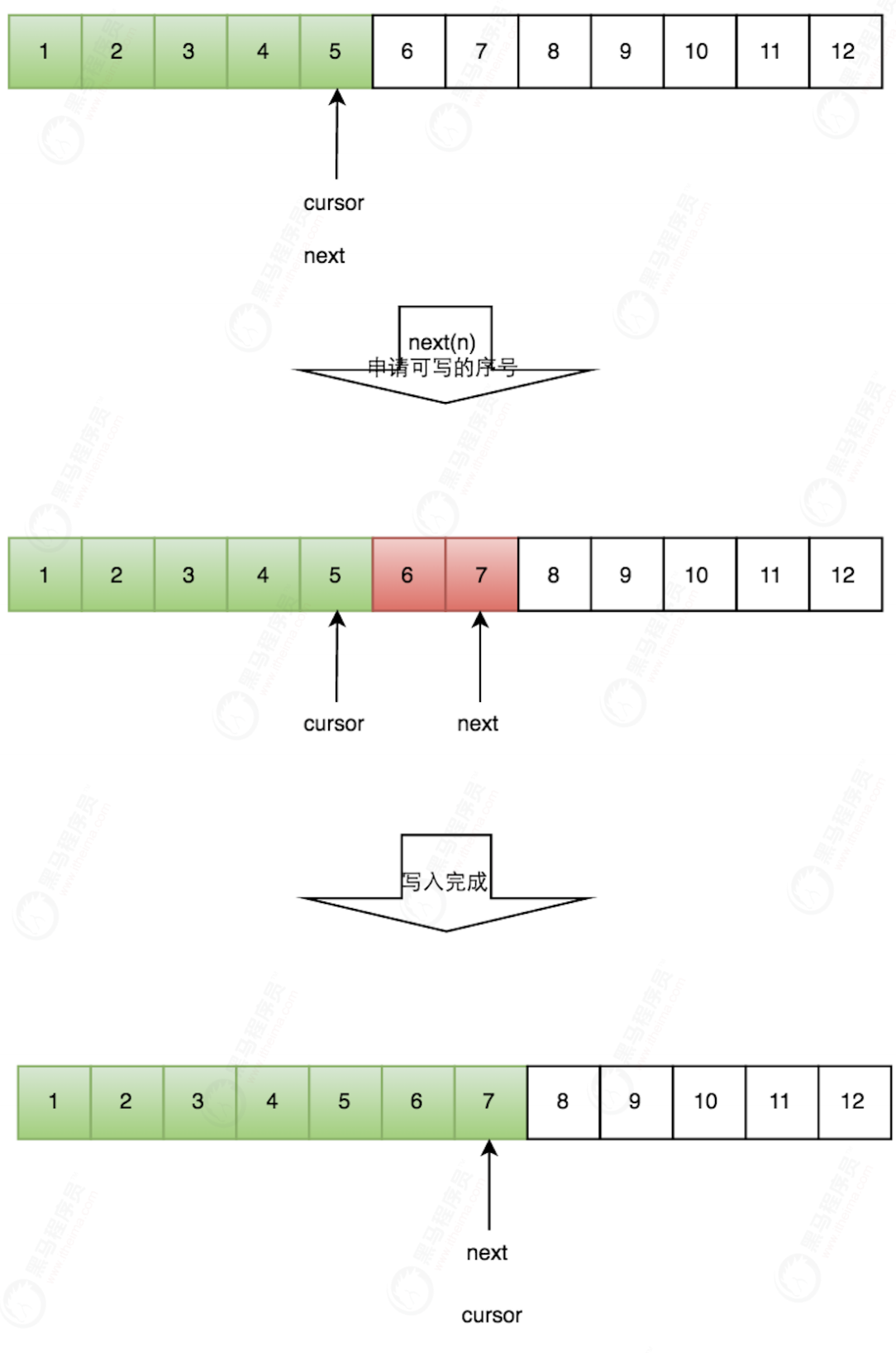
Multi producer production data
In the case of multiple producers, you will encounter the problem of "how to prevent multiple threads from writing the same element repeatedly". The solution of Disruptor is that each thread obtains a different section of array space for operation. This is easily achieved through CAS. You only need to judge whether this space has been allocated through CAS when allocating elements.
However, we will encounter a new problem: how to prevent reading elements that have not been written when reading. In the case of multiple producers, the Disruptor introduces a buffer with the same size as the Ring Buffer: available Buffer. When a location is successfully written, the corresponding location of the available Buffer is set and marked as successful. When reading, it will traverse the available Buffer to judge whether the element is ready.
production process
- Apply to write m elements;
- If there are m elements that can be written, the maximum serial number is returned. Each producer will be allocated an exclusive space;
- The producer writes the element and sets the corresponding position in the available Buffer while writing the element to mark which positions have been successfully written.
As shown in the figure below, both writer1 and Writer2 threads write arrays and apply for writable array space. Writer1 is allocated the space from subscript 3 to table 5 below, and Writer2 is allocated the space from subscript 6 to subscript 9.
Writer1 writes the element at the subscript 3 position and sets the corresponding position of the available Buffer to mark that it has been written successfully. Move back one bit and start writing the element at the subscript 4 position. Writer2 in the same way. Finally, the writing is completed.
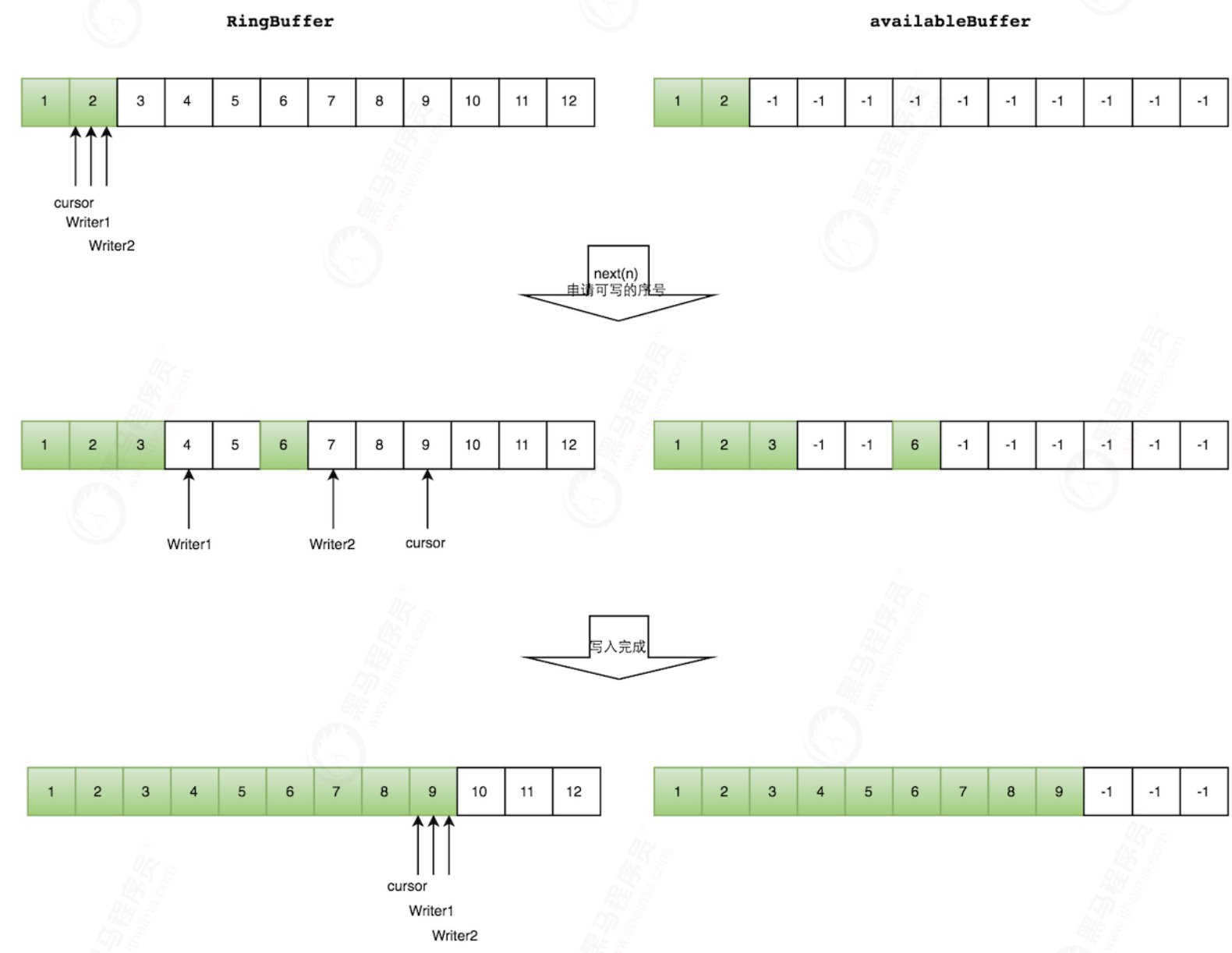
CAS detection space occupation
Codes that prevent different producers from writing to the same space are as follows:
Condition cursor through do/while loop Compareandset (current, next) to judge whether the space applied for each time has been occupied by other producers. If it has been occupied, the function will return failure, and the While loop will be re executed to apply for write space.
public long tryNext(int n) throws InsufficientCapacityException
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do
{
current = cursor.get();
next = current + n;
if (!hasAvailableCapacity(gatingSequences, n, current))
{
throw InsufficientCapacityException.INSTANCE;
}
}
while (!cursor.compareAndSet(current, next));
return next;
}
Multi producer consumption data
Green indicates that the OK data has been written
Assuming that three producers are writing and have not set the AvailableBuffer, the consumer can only obtain 6 consumption subscripts. Then, after the producers write OK, notify the consumer, and the consumer continues to repeat the above steps.
Consumption process
- The application reads the serial number n;
- If writer cursor > = n, it is still impossible to determine the maximum subscript that can be read continuously. Read the available Buffer from the reader cursor until the first unavailable element is found, and then return the position of the largest continuous readable element;
- Consumer read element
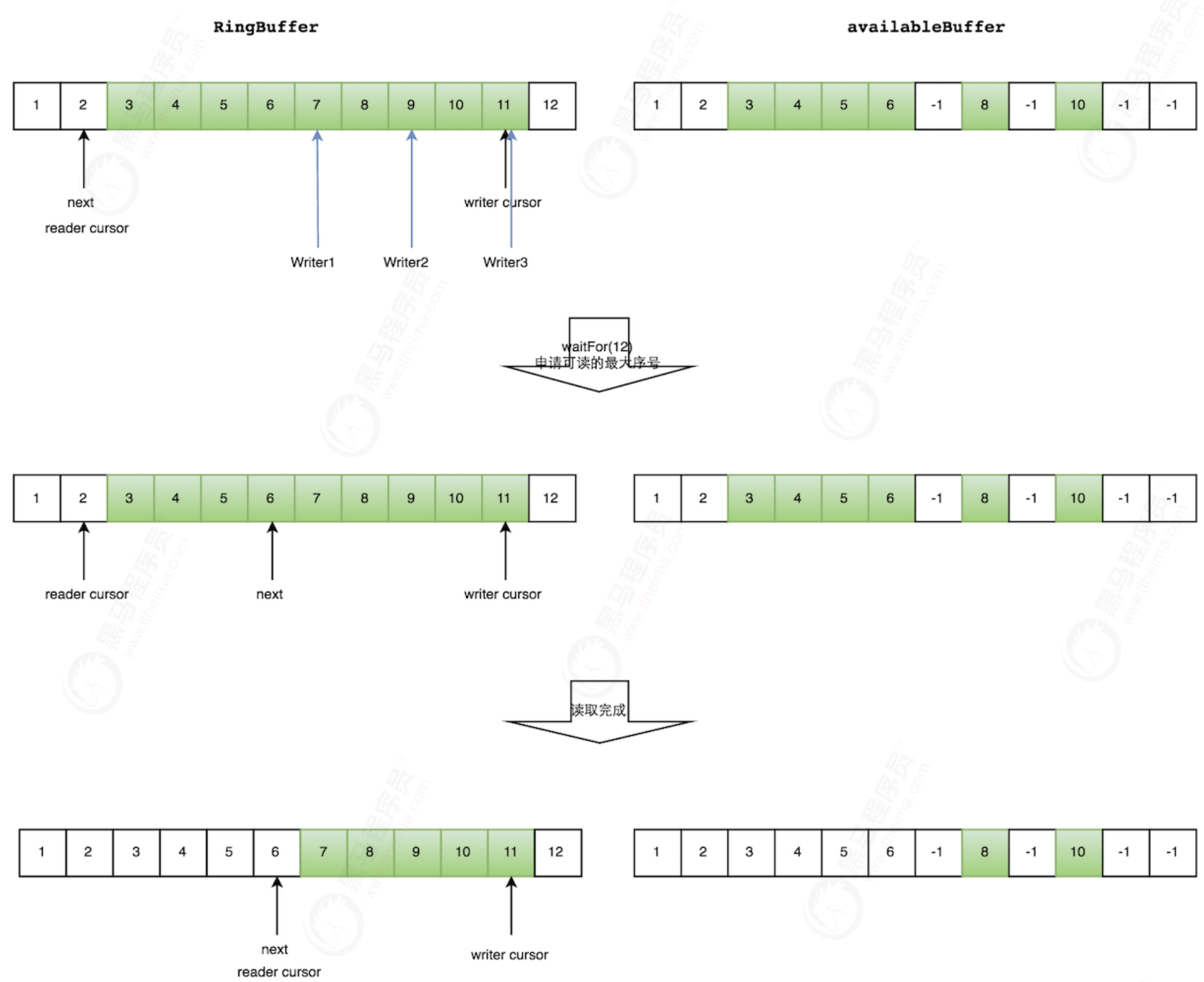
As shown in the following figure, the reading thread reads an element with a subscript of 2, the three threads Writer1/Writer2/Writer3 are writing data to the corresponding position of RingBuffer, and the maximum element subscript allocated to the writing thread is 11.
The reading thread requests to read elements with subscripts from 3 to 11, and judges that writer cursor > = 11. Then start reading the availableBuffer. Start from 3 and read later. It is found that the element with subscript 7 has not been successfully produced, so WaitFor(11) returns 6.
Then, the consumer reads four elements with subscripts from 3 to 6.
Advanced use
Parallel mode
Single writer mode
One of the best ways to improve performance in concurrent systems is the single writer principle, which is also applicable to Disruptor. If there is only one event producer in your code, you can set it to single producer mode to improve the performance of the system.
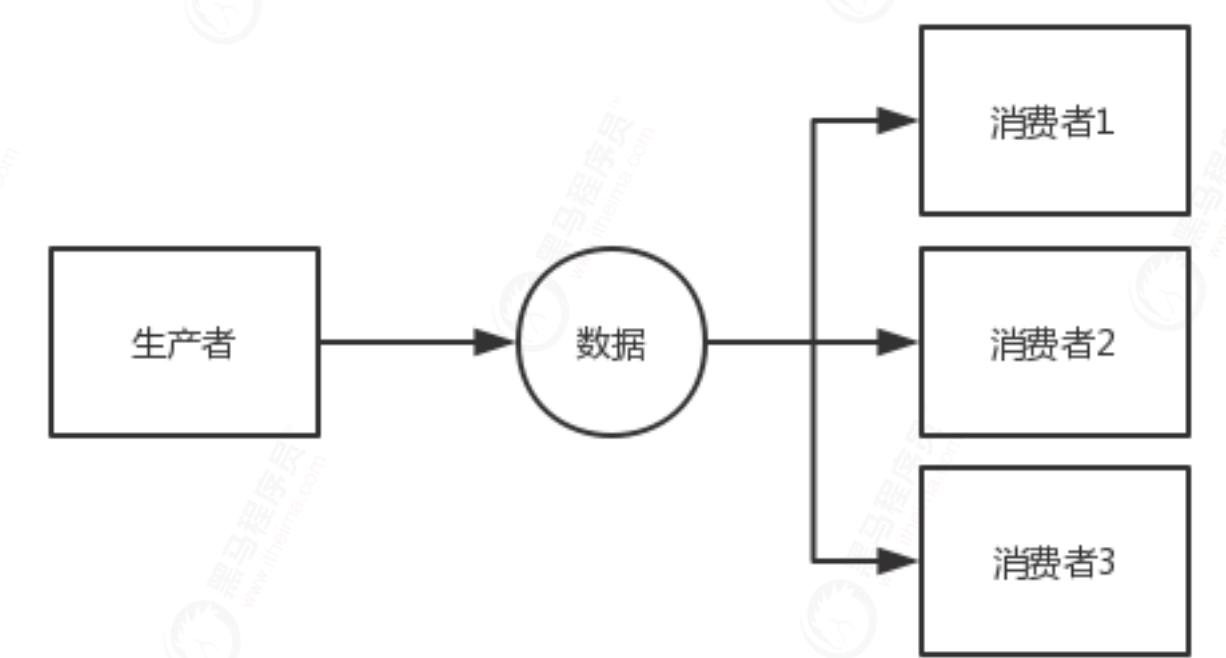
public static Disruptor singleWrite(LongEventFactory factory) {
//Single threaded mode for additional performance
Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory,
bufferSize, Executors.defaultThreadFactory(),
//Single write mode
ProducerType.SINGLE,
new YieldingWaitStrategy());
//Set event business processor - Consumer
//Multi consumer model
disruptor.handleEventsWith(new OneEventHandler(), new TwoEventHandler());
return disruptor;
}
Serial consumption
For example, to trigger a registered Event, you need a Handler to store information, a Hanlder to send e-mail, and so on.

public static Disruptor serial(LongEventFactory factory) {
//Single threaded mode for additional performance
Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory,
bufferSize, Executors.defaultThreadFactory(),
//Single write mode
ProducerType.SINGLE,
new YieldingWaitStrategy());
//Set event business processor - Consumer
//Multi consumer model
disruptor.handleEventsWith(new OneEventHandler()).then(new TwoEventHandler());
return disruptor;
}
Diamond execution

public static Disruptor diamond(LongEventFactory factory) {
//Single threaded mode for additional performance
Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory,
bufferSize, Executors.defaultThreadFactory(),
//Single write mode
ProducerType.SINGLE,
new YieldingWaitStrategy());
//Set event business processor - Consumer
//Multi consumer model
disruptor.handleEventsWith(new OneEventHandler(), new TwoEventHandler()).then(new ThreeEventHandler());
return disruptor;
}
Chain parallel computing
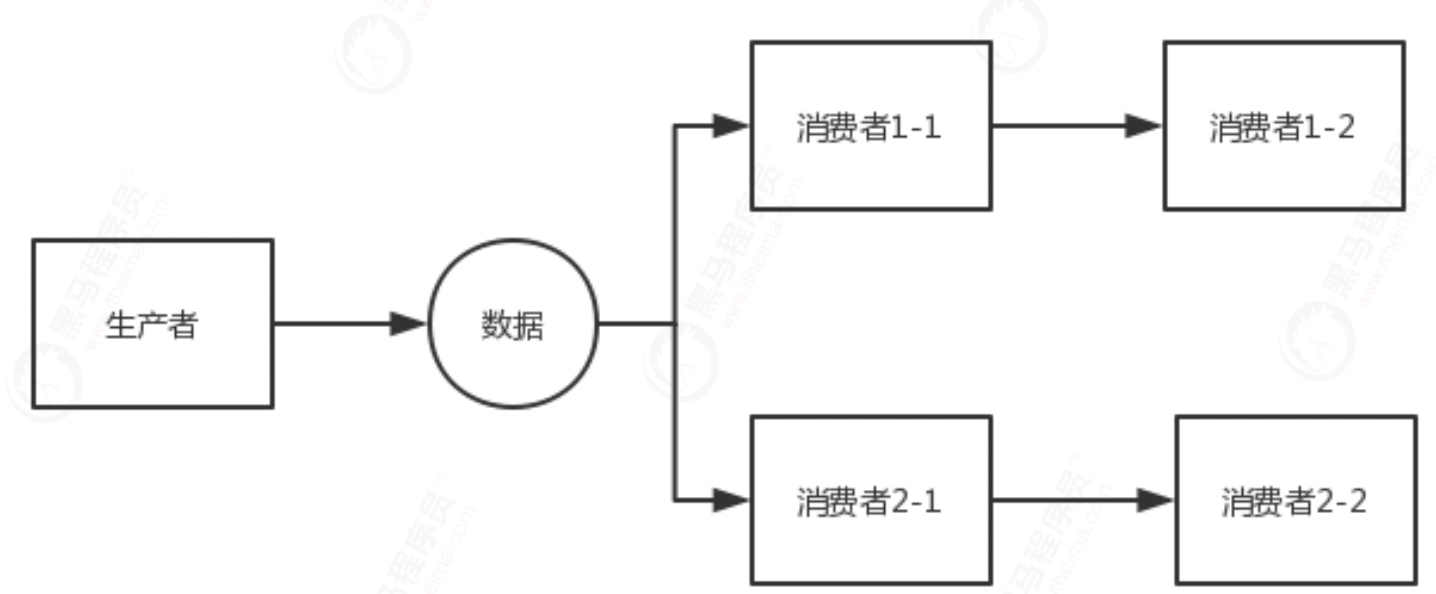
public static Disruptor chain(LongEventFactory factory) {
//Single threaded mode for additional performance
Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory,
bufferSize, Executors.defaultThreadFactory(),
//Single write mode
ProducerType.SINGLE,
new YieldingWaitStrategy());
//Set event business processor - Consumer
//Multi consumer model
disruptor.handleEventsWith(new OneEventHandler()).then(new TwoEventHandler());
disruptor.handleEventsWith(new ThreeEventHandler()).then(new FourEventHandler());
return disruptor;
}
Mutual isolation mode
public static void parallelWithPool(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWithWorkerPool(new C11EventHandler(),new
C11EventHandler());
disruptor.handleEventsWithWorkerPool(new C21EventHandler(),new
C21EventHandler());
disruptor.start();
}
Channel mode
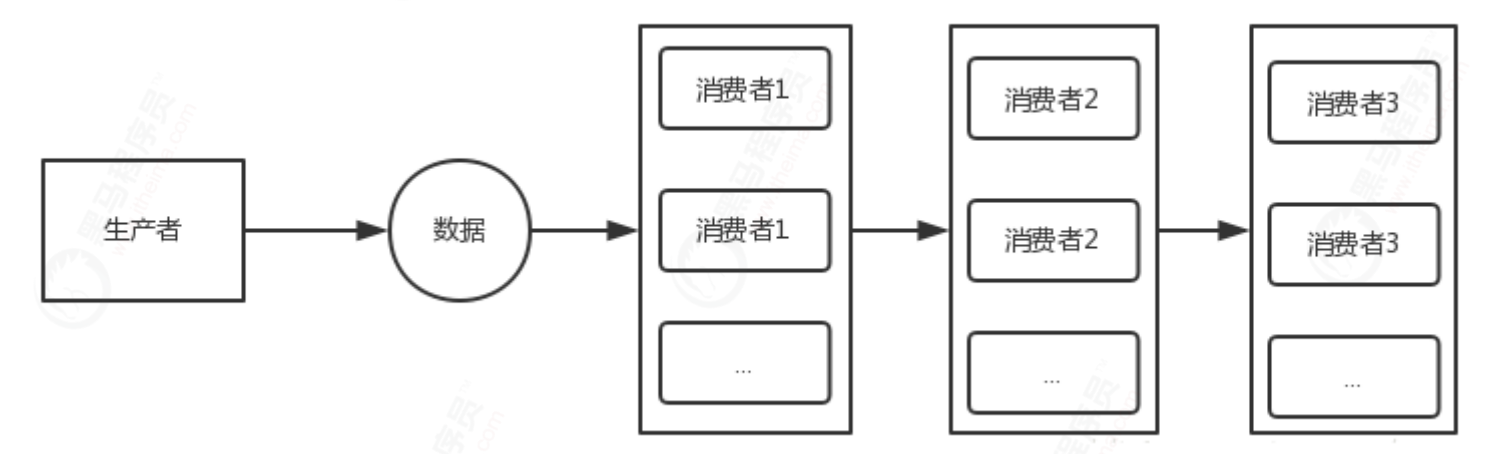
public static void serialWithPool(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWithWorkerPool(new C11EventHandler(),new
C11EventHandler()).then(new C21EventHandler(),new C21EventHandler());
disruptor.start();
}