background
In the layered code architecture, objects between layers cannot avoid many operations such as conversion and assignment. These operations are repeated and cumbersome, so many tools have been created to complete this operation gracefully and efficiently, including BeanUtils, BeanCopier, Dozer, Orika, etc. This paper will describe the use, performance comparison and principle analysis of the above tools.
performance analysis
In fact, what these tools need to do is very simple, and they are similar in use, so I think we should first show you the comparison results of performance analysis to give you a general understanding. I use JMH for performance analysis. The code is as follows:
The object to be copied is relatively simple, including some basic types; Once, warmup, because some tools need to be "precompiled" and cached, the comparison will be more objective; Copy 1000, 10000 and 100000 objects respectively, which is a common order of magnitude.
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Fork(1)
@Warmup(iterations = 1)
@State(Scope.Benchmark)
public class BeanMapperBenchmark {
@Param({"1000", "10000", "100000"})
private int times;
private int time;
private static MapperFactory mapperFactory;
private static Mapper mapper;
static {
mapperFactory = new DefaultMapperFactory.Builder().build();
mapperFactory.classMap(SourceVO.class, TargetVO.class)
.byDefault()
.register();
mapper = DozerBeanMapperBuilder.create()
.withMappingBuilder(new BeanMappingBuilder() {
@Override
protected void configure() {
mapping(SourceVO.class, TargetVO.class)
.fields("fullName", "name")
.exclude("in");
}
}).build();
}
public static void main(String[] args) throws Exception {
Options options = new OptionsBuilder()
.include(BeanMapperBenchmark.class.getName()).measurementIterations(3)
.build();
new Runner(options).run();
}
@Setup
public void prepare() {
this.time = times;
}
@Benchmark
public void springBeanUtilTest(){
SourceVO sourceVO = getSourceVO();
for(int i = 0; i < time; i++){
TargetVO targetVO = new TargetVO();
BeanUtils.copyProperties(sourceVO, targetVO);
}
}
@Benchmark
public void apacheBeanUtilTest() throws Exception{
SourceVO sourceVO = getSourceVO();
for(int i = 0; i < time; i++){
TargetVO targetVO = new TargetVO();
org.apache.commons.beanutils.BeanUtils.copyProperties(targetVO, sourceVO);
}
}
@Benchmark
public void beanCopierTest(){
SourceVO sourceVO = getSourceVO();
for(int i = 0; i < time; i++){
TargetVO targetVO = new TargetVO();
BeanCopier bc = BeanCopier.create(SourceVO.class, TargetVO.class, false);
bc.copy(sourceVO, targetVO, null);
}
}
@Benchmark
public void dozerTest(){
SourceVO sourceVO = getSourceVO();
for(int i = 0; i < time; i++){
TargetVO map = mapper.map(sourceVO, TargetVO.class);
}
}
@Benchmark
public void orikaTest(){
SourceVO sourceVO = getSourceVO();
for(int i = 0; i < time; i++){
MapperFacade mapper = mapperFactory.getMapperFacade();
TargetVO map = mapper.map(sourceVO, TargetVO.class);
}
}
private SourceVO getSourceVO(){
SourceVO sourceVO = new SourceVO();
sourceVO.setP1(1);
sourceVO.setP2(2L);
sourceVO.setP3(new Integer(3).byteValue());
sourceVO.setDate1(new Date());
sourceVO.setPattr1("1");
sourceVO.setIn(new SourceVO.Inner(1));
sourceVO.setFullName("alben");
return sourceVO;
}
}
The results after running under my macbook are as follows:
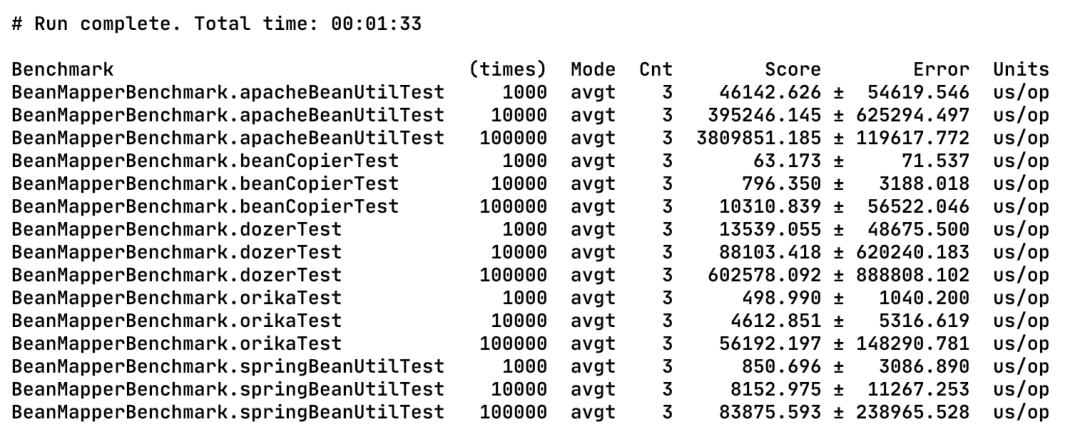
picture
Score is the average running time in microseconds. From the perspective of execution efficiency, we can see beancopier > orika > springbeanutil > dozer > Apache beanutil. Such results are closely related to their respective implementation principles,
The use and implementation principle of each tool will be described in detail below.
Spring's BeanUtils
use
This tool is probably the most commonly used tool, because it comes with Spring and is easy to use: BeanUtils copyProperties(sourceVO, targetVO);
principle
The implementation principle of Spring BeanUtils is also relatively simple. It is to obtain the propertydescriptors of two classes through the Java Introspector. Compare the two properties with the same name and type. If so, assign values (obtain values through ReadMethod and assign values through WriteMethod). Otherwise, ignore them.
To improve performance, Spring caches BeanInfo and PropertyDescriptor.
(source code: org. Springframework: Spring beans: 4.3.9. Release)
/**
* Copy the property values of the given source bean into the given target bean.
* <p>Note: The source and target classes do not have to match or even be derived
* from each other, as long as the properties match. Any bean properties that the
* source bean exposes but the target bean does not will silently be ignored.
* @param source the source bean
* @param target the target bean
* @param editable the class (or interface) to restrict property setting to
* @param ignoreProperties array of property names to ignore
* @throws BeansException if the copying failed
* @see BeanWrapper
*/
private static void copyProperties(Object source, Object target, Class<?> editable, String... ignoreProperties)
throws BeansException {
Assert.notNull(source, "Source must not be null");
Assert.notNull(target, "Target must not be null");
Class<?> actualEditable = target.getClass();
if (editable != null) {
if (!editable.isInstance(target)) {
throw new IllegalArgumentException("Target class [" + target.getClass().getName() +
"] not assignable to Editable class [" + editable.getName() + "]");
}
actualEditable = editable;
}
//Get the attribute of target class (with cache)
PropertyDescriptor[] targetPds = getPropertyDescriptors(actualEditable);
List<String> ignoreList = (ignoreProperties != null ? Arrays.asList(ignoreProperties) : null);
for (PropertyDescriptor targetPd : targetPds) {
Method writeMethod = targetPd.getWriteMethod();
if (writeMethod != null && (ignoreList == null || !ignoreList.contains(targetPd.getName()))) {
//Get the properties of the source class (with cache)
PropertyDescriptor sourcePd = getPropertyDescriptor(source.getClass(), targetPd.getName());
if (sourcePd != null) {
Method readMethod = sourcePd.getReadMethod();
if (readMethod != null &&
//Judge whether the input parameter of setter method of target is consistent with the return type of getter method of source
ClassUtils.isAssignable(writeMethod.getParameterTypes()[0], readMethod.getReturnType())) {
try {
if (!Modifier.isPublic(readMethod.getDeclaringClass().getModifiers())) {
readMethod.setAccessible(true);
}
//Get source value
Object value = readMethod.invoke(source);
if (!Modifier.isPublic(writeMethod.getDeclaringClass().getModifiers())) {
writeMethod.setAccessible(true);
}
//Assign to target
writeMethod.invoke(target, value);
}
catch (Throwable ex) {
throw new FatalBeanException(
"Could not copy property '" + targetPd.getName() + "' from source to target", ex);
}
}
}
}
}
}
Summary
The implementation of Spring BeanUtils is so simple, which is also the reason for its high performance.
However, if it is too concise, it will lose flexibility and scalability. The use restrictions of Spring BeanUtils are also obvious. It is required that the name and type of class attributes should be consistent, which should be paid attention to when using.
Apache's BeanUtils
use
The use of Apache's BeanUtils and Spring's BeanUtils is the same:
BeanUtils.copyProperties(targetVO, sourceVO);
Note that the input positions of source and target are different.
principle
The implementation principle of Apache's BeanUtils is the same as that of Spring's BeanUtils. It mainly obtains the properties of the class through the Introspector mechanism of Java for assignment. BeanInfo and PropertyDescriptor are also cached, However, Apache beautils adds some features that are not used so much (including support for Map types, support for custom DynaBean types, support for expression of property names, etc.), which makes the performance lower than that of Spring beautils.
(source code based on: Commons beautils: Commons beautils: 1.9.3)
public void copyProperties(final Object dest, final Object orig)
throws IllegalAccessException, InvocationTargetException {
if (dest == null) {
throw new IllegalArgumentException
("No destination bean specified");
}
if (orig == null) {
throw new IllegalArgumentException("No origin bean specified");
}
if (log.isDebugEnabled()) {
log.debug("BeanUtils.copyProperties(" + dest + ", " +
orig + ")");
}
// Apache Common custom DynaBean
if (orig instanceof DynaBean) {
final DynaProperty[] origDescriptors =
((DynaBean) orig).getDynaClass().getDynaProperties();
for (DynaProperty origDescriptor : origDescriptors) {
final String name = origDescriptor.getName();
// Need to check isReadable() for WrapDynaBean
// (see Jira issue# BEANUTILS-61)
if (getPropertyUtils().isReadable(orig, name) &&
getPropertyUtils().isWriteable(dest, name)) {
final Object value = ((DynaBean) orig).get(name);
copyProperty(dest, name, value);
}
}
// Map type
} else if (orig instanceof Map) {
@SuppressWarnings("unchecked")
final
// Map properties are always of type <String, Object>
Map<String, Object> propMap = (Map<String, Object>) orig;
for (final Map.Entry<String, Object> entry : propMap.entrySet()) {
final String name = entry.getKey();
if (getPropertyUtils().isWriteable(dest, name)) {
copyProperty(dest, name, entry.getValue());
}
}
// Standard JavaBean s
} else {
final PropertyDescriptor[] origDescriptors =
//Get PropertyDescriptor
getPropertyUtils().getPropertyDescriptors(orig);
for (PropertyDescriptor origDescriptor : origDescriptors) {
final String name = origDescriptor.getName();
if ("class".equals(name)) {
continue; // No point in trying to set an object's class
}
//Is it readable and writable
if (getPropertyUtils().isReadable(orig, name) &&
getPropertyUtils().isWriteable(dest, name)) {
try {
//Get source value
final Object value =
getPropertyUtils().getSimpleProperty(orig, name);
//Assignment operation
copyProperty(dest, name, value);
} catch (final NoSuchMethodException e) {
// Should not happen
}
}
}
}
}
Summary
The implementation of Apache beautils is similar to spring beautils in general, but the performance is much lower. This can be seen from the performance comparison above. Ali's Java specification is not recommended.
BeanCopier
use
BeanCopier is in the cglib package, and its use is also relatively simple:
@Test
public void beanCopierSimpleTest() {
SourceVO sourceVO = getSourceVO();
log.info("source={}", GsonUtil.toJson(sourceVO));
TargetVO targetVO = new TargetVO();
BeanCopier bc = BeanCopier.create(SourceVO.class, TargetVO.class, false);
bc.copy(sourceVO, targetVO, null);
log.info("target={}", GsonUtil.toJson(targetVO));
}
You only need to define the source class and target class to be converted in advance. You can choose whether to use Converter, which will be discussed below.
In the above performance test, BeanCopier is the best of all, so let's analyze its implementation principle.
principle
The implementation principle of BeanCopier is quite different from that of BeanUtils. Instead of using reflection to assign values to attributes, it directly uses cglib to generate class classes with get/set methods and then execute them. Because it is directly generated bytecode execution, the performance of BeanCopier is close to handwriting
get/set.
BeanCopier.create method
public static BeanCopier create(Class source, Class target, boolean useConverter) {
Generator gen = new Generator();
gen.setSource(source);
gen.setTarget(target);
gen.setUseConverter(useConverter);
return gen.create();
}
public BeanCopier create() {
Object key = KEY_FACTORY.newInstance(source.getName(), target.getName(), useConverter);
return (BeanCopier)super.create(key);
}
This means using KEY_FACTORY creates a BeanCopier and then calls the create method to generate bytecode.
KEY_FACTORY is actually a class generated by using cglib through the BeanCopierKey interface
private static final BeanCopierKey KEY_FACTORY =
(BeanCopierKey)KeyFactory.create(BeanCopierKey.class);
interface BeanCopierKey {
public Object newInstance(String source, String target, boolean useConverter);
}
By setting
System.setProperty(DebuggingClassWriter.DEBUG_LOCATION_PROPERTY, "path");
You can let cglib output the class file of the generated class. We can decompile the code inside
Here is key_ Class of factory
public class BeanCopier$BeanCopierKey$$KeyFactoryByCGLIB$$f32401fd extends KeyFactory implements BeanCopierKey {
private final String FIELD_0;
private final String FIELD_1;
private final boolean FIELD_2;
public BeanCopier$BeanCopierKey$$KeyFactoryByCGLIB$$f32401fd() {
}
public Object newInstance(String var1, String var2, boolean var3) {
return new BeanCopier$BeanCopierKey$$KeyFactoryByCGLIB$$f32401fd(var1, var2, var3);
}
public BeanCopier$BeanCopierKey$$KeyFactoryByCGLIB$$f32401fd(String var1, String var2, boolean var3) {
this.FIELD_0 = var1;
this.FIELD_1 = var2;
this.FIELD_2 = var3;
}
//Omit hashCode and other methods...
}
Continue tracking Generator Create method, because the Generator inherits AbstractClassGenerator, which is a template class used by cglib to generate bytecode, super. Of Generator Create is actually called
The create method of AbstractClassGenerator will eventually call the Generator's template method generateClass method. We won't go into the details of AbstractClassGenerator, but focus on generateClass.
This is a method for generating java classes, which is understood as if we were writing code at ordinary times.
public void generateClass(ClassVisitor v) {
Type sourceType = Type.getType(source);
Type targetType = Type.getType(target);
ClassEmitter ce = new ClassEmitter(v);
//Start to "write" the class. There are modifiers, class names, parent classes and other information
ce.begin_class(Constants.V1_2,
Constants.ACC_PUBLIC,
getClassName(),
BEAN_COPIER,
null,
Constants.SOURCE_FILE);
//No construction method
EmitUtils.null_constructor(ce);
//Start "writing" a method named copy
CodeEmitter e = ce.begin_method(Constants.ACC_PUBLIC, COPY, null);
//Obtain the PropertyDescriptor of source class and target class through the Introspector
PropertyDescriptor[] getters = ReflectUtils.getBeanGetters(source);
PropertyDescriptor[] setters = ReflectUtils.getBeanSetters(target);
Map names = new HashMap();
for (int i = 0; i < getters.length; i++) {
names.put(getters[i].getName(), getters[i]);
}
Local targetLocal = e.make_local();
Local sourceLocal = e.make_local();
if (useConverter) {
e.load_arg(1);
e.checkcast(targetType);
e.store_local(targetLocal);
e.load_arg(0);
e.checkcast(sourceType);
e.store_local(sourceLocal);
} else {
e.load_arg(1);
e.checkcast(targetType);
e.load_arg(0);
e.checkcast(sourceType);
}
//Generate converted code by attribute name
//Traversal with setter
for (int i = 0; i < setters.length; i++) {
PropertyDescriptor setter = setters[i];
//Get the getter according to the name of the setter
PropertyDescriptor getter = (PropertyDescriptor)names.get(setter.getName());
if (getter != null) {
//Get read / write method
MethodInfo read = ReflectUtils.getMethodInfo(getter.getReadMethod());
MethodInfo write = ReflectUtils.getMethodInfo(setter.getWriteMethod());
//If useConverter is used, perform the following code assembly method
if (useConverter) {
Type setterType = write.getSignature().getArgumentTypes()[0];
e.load_local(targetLocal);
e.load_arg(2);
e.load_local(sourceLocal);
e.invoke(read);
e.box(read.getSignature().getReturnType());
EmitUtils.load_class(e, setterType);
e.push(write.getSignature().getName());
e.invoke_interface(CONVERTER, CONVERT);
e.unbox_or_zero(setterType);
e.invoke(write);
//compatible is used to judge whether getter s and setter s have the same type
} else if (compatible(getter, setter)) {
e.dup2();
e.invoke(read);
e.invoke(write);
}
}
}
e.return_value();
e.end_method();
ce.end_class();
}
private static boolean compatible(PropertyDescriptor getter, PropertyDescriptor setter) {
// TODO: allow automatic widening conversions?
return setter.getPropertyType().isAssignableFrom(getter.getPropertyType());
}
Even if you haven't used cglib, you can understand the process of generating code. Let's take a look at the code generated without using useConverter:
public class Object$$BeanCopierByCGLIB$$d1d970c8 extends BeanCopier {
public Object$$BeanCopierByCGLIB$$d1d970c8() {
}
public void copy(Object var1, Object var2, Converter var3) {
TargetVO var10000 = (TargetVO)var2;
SourceVO var10001 = (SourceVO)var1;
var10000.setDate1(((SourceVO)var1).getDate1());
var10000.setIn(var10001.getIn());
var10000.setListData(var10001.getListData());
var10000.setMapData(var10001.getMapData());
var10000.setP1(var10001.getP1());
var10000.setP2(var10001.getP2());
var10000.setP3(var10001.getP3());
var10000.setPattr1(var10001.getPattr1());
}
}
In contrast, the code generated above is not broad and cheerful.
Take another look at the use of useConverter:
public class Object$$BeanCopierByCGLIB$$d1d970c7 extends BeanCopier {
private static final Class CGLIB$load_class$java$2Eutil$2EDate;
private static final Class CGLIB$load_class$beanmapper_compare$2Evo$2ESourceVO$24Inner;
private static final Class CGLIB$load_class$java$2Eutil$2EList;
private static final Class CGLIB$load_class$java$2Eutil$2EMap;
private static final Class CGLIB$load_class$java$2Elang$2EInteger;
private static final Class CGLIB$load_class$java$2Elang$2ELong;
private static final Class CGLIB$load_class$java$2Elang$2EByte;
private static final Class CGLIB$load_class$java$2Elang$2EString;
public Object$$BeanCopierByCGLIB$$d1d970c7() {
}
public void copy(Object var1, Object var2, Converter var3) {
TargetVO var4 = (TargetVO)var2;
SourceVO var5 = (SourceVO)var1;
var4.setDate1((Date)var3.convert(var5.getDate1(), CGLIB$load_class$java$2Eutil$2EDate, "setDate1"));
var4.setIn((Inner)var3.convert(var5.getIn(), CGLIB$load_class$beanmapper_compare$2Evo$2ESourceVO$24Inner, "setIn"));
var4.setListData((List)var3.convert(var5.getListData(), CGLIB$load_class$java$2Eutil$2EList, "setListData"));
var4.setMapData((Map)var3.convert(var5.getMapData(), CGLIB$load_class$java$2Eutil$2EMap, "setMapData"));
var4.setP1((Integer)var3.convert(var5.getP1(), CGLIB$load_class$java$2Elang$2EInteger, "setP1"));
var4.setP2((Long)var3.convert(var5.getP2(), CGLIB$load_class$java$2Elang$2ELong, "setP2"));
var4.setP3((Byte)var3.convert(var5.getP3(), CGLIB$load_class$java$2Elang$2EByte, "setP3"));
var4.setPattr1((String)var3.convert(var5.getPattr1(), CGLIB$load_class$java$2Elang$2EString, "setPattr1"));
var4.setSeq((Long)var3.convert(var5.getSeq(), CGLIB$load_class$java$2Elang$2ELong, "setSeq"));
}
static void CGLIB$STATICHOOK1() {
CGLIB$load_class$java$2Eutil$2EDate = Class.forName("java.util.Date");
CGLIB$load_class$beanmapper_compare$2Evo$2ESourceVO$24Inner = Class.forName("beanmapper_compare.vo.SourceVO$Inner");
CGLIB$load_class$java$2Eutil$2EList = Class.forName("java.util.List");
CGLIB$load_class$java$2Eutil$2EMap = Class.forName("java.util.Map");
CGLIB$load_class$java$2Elang$2EInteger = Class.forName("java.lang.Integer");
CGLIB$load_class$java$2Elang$2ELong = Class.forName("java.lang.Long");
CGLIB$load_class$java$2Elang$2EByte = Class.forName("java.lang.Byte");
CGLIB$load_class$java$2Elang$2EString = Class.forName("java.lang.String");
}
static {
CGLIB$STATICHOOK1();
}
}
Summary
The performance of BeanCopier is really high, but it can be seen from the source code that BeanCopier will only copy attributes with the same name and type. Moreover, once Converter is used, BeanCopier will only copy attributes using the rules defined by Converter, so all attributes should be considered in the convert method.
Dozer
use
The functions of BeanUtils and BeanCopier mentioned above are relatively simple. They need the same attribute name and even the same type. However, in most cases, this requirement is relatively harsh. You should know that some Vos cannot be modified for various reasons, and some are objects of the external interface SDK,
Some objects have different naming rules, such as humped, underlined and so on. So what we need more is more flexible and rich functions, and even customized conversion.
Dozer provides these functions. It supports implicit mapping with the same name, mutual conversion of basic types, display of specified mapping relationship, exclude field, recursive matching mapping, depth matching, date format of Date to String, user-defined conversion Converter, one mapping definition for multiple uses, EventListener event listening, etc. Moreover, dozer not only supports API, but also supports XML and annotation to meet everyone's preferences. More functions can be found here
Due to its rich functions, it is impossible to demonstrate each one. Here is just a general understanding, more detailed functions, or XML and annotation configuration. Please see the official documents.
private Mapper dozerMapper;
@Before
public void setup(){
dozerMapper = DozerBeanMapperBuilder.create()
.withMappingBuilder(new BeanMappingBuilder() {
@Override
protected void configure() {
mapping(SourceVO.class, TargetVO.class)
.fields("fullName", "name")
.exclude("in");
}
})
.withCustomConverter(null)
.withEventListener(null)
.build();
}
@Test
public void dozerTest(){
SourceVO sourceVO = getSourceVO();
log.info("sourceVO={}", GsonUtil.toJson(sourceVO));
TargetVO map = dozerMapper.map(sourceVO, TargetVO.class);
log.info("map={}", GsonUtil.toJson(map));
}
principle
The implementation principle of Dozer is essentially the reflection / Introspector, but it has rich functions, And supporting multiple implementation methods (API, XML and annotation) makes the code look a little complex. When browsing the code, we don't need to pay attention to these classes. We just need to know their general functions and focus on the implementation of the core process and code. Let's focus on the build method of building mapper and the map method of mapping.
The build method is very simple. It is an initialization action, which is to build a series of configuration objects, context objects, or other encapsulated objects to be used later through the user's configuration. We don't have to go deep into how these objects are implemented. We can guess what these objects are and what they are responsible for from the name.
DozerBeanMapper(List<String> mappingFiles,
BeanContainer beanContainer,
DestBeanCreator destBeanCreator,
DestBeanBuilderCreator destBeanBuilderCreator,
BeanMappingGenerator beanMappingGenerator,
PropertyDescriptorFactory propertyDescriptorFactory,
List<CustomConverter> customConverters,
List<MappingFileData> mappingsFileData,
List<EventListener> eventListeners,
CustomFieldMapper customFieldMapper,
Map<String, CustomConverter> customConvertersWithId,
ClassMappings customMappings,
Configuration globalConfiguration,
CacheManager cacheManager) {
this.beanContainer = beanContainer;
this.destBeanCreator = destBeanCreator;
this.destBeanBuilderCreator = destBeanBuilderCreator;
this.beanMappingGenerator = beanMappingGenerator;
this.propertyDescriptorFactory = propertyDescriptorFactory;
this.customConverters = new ArrayList<>(customConverters);
this.eventListeners = new ArrayList<>(eventListeners);
this.mappingFiles = new ArrayList<>(mappingFiles);
this.customFieldMapper = customFieldMapper;
this.customConvertersWithId = new HashMap<>(customConvertersWithId);
this.eventManager = new DefaultEventManager(eventListeners);
this.customMappings = customMappings;
this.globalConfiguration = globalConfiguration;
this.cacheManager = cacheManager;
}
The map method is the process of mapping objects, and its entry is the mapGeneral method of MappingProcessor
private <T> T mapGeneral(Object srcObj, final Class<T> destClass, final T destObj, final String mapId) {
srcObj = MappingUtils.deProxy(srcObj, beanContainer);
Class<T> destType;
T result;
if (destClass == null) {
destType = (Class<T>)destObj.getClass();
result = destObj;
} else {
destType = destClass;
result = null;
}
ClassMap classMap = null;
try {
//Build ClassMap
//ClassMap is an encapsulation that includes src and dest classes and other configurations
classMap = getClassMap(srcObj.getClass(), destType, mapId);
//Registration event
eventManager.on(new DefaultEvent(EventTypes.MAPPING_STARTED, classMap, null, srcObj, result, null));
//See if there is a custom converter
Class<?> converterClass = MappingUtils.findCustomConverter(converterByDestTypeCache, classMap.getCustomConverters(), srcObj
.getClass(), destType);
if (destObj == null) {
// If this is a nested MapperAware conversion this mapping can be already processed
// but we can do this optimization only in case of no destObject, instead we must copy to the dest object
Object alreadyMappedValue = mappedFields.getMappedValue(srcObj, destType, mapId);
if (alreadyMappedValue != null) {
return (T)alreadyMappedValue;
}
}
//The custom converter is preferred for mapping
if (converterClass != null) {
return (T)mapUsingCustomConverter(converterClass, srcObj.getClass(), srcObj, destType, result, null, true);
}
//It also encapsulates the configuration
BeanCreationDirective creationDirective =
new BeanCreationDirective(srcObj, classMap.getSrcClassToMap(), classMap.getDestClassToMap(), destType,
classMap.getDestClassBeanFactory(), classMap.getDestClassBeanFactoryId(), classMap.getDestClassCreateMethod(),
classMap.getDestClass().isSkipConstructor());
//Continue mapping
result = createByCreationDirectiveAndMap(creationDirective, classMap, srcObj, result, false, null);
} catch (Throwable e) {
MappingUtils.throwMappingException(e);
}
eventManager.on(new DefaultEvent(EventTypes.MAPPING_FINISHED, classMap, null, srcObj, result, null));
return result;
}
Generally, the createbycreationdirectionandmap method will call the mapFromFieldMap method, and the mapOrRecurseObject method will be called without a custom converter
In most cases, the field mapping will be generally parsed in this method
private Object mapOrRecurseObject(Object srcObj, Object srcFieldValue, Class<?> destFieldType, FieldMap fieldMap, Object destObj) {
Class<?> srcFieldClass = srcFieldValue != null ? srcFieldValue.getClass() : fieldMap.getSrcFieldType(srcObj.getClass());
Class<?> converterClass = MappingUtils.determineCustomConverter(fieldMap, converterByDestTypeCache, fieldMap.getClassMap()
.getCustomConverters(), srcFieldClass, destFieldType);
//Processing of custom converter
if (converterClass != null) {
return mapUsingCustomConverter(converterClass, srcFieldClass, srcFieldValue, destFieldType, destObj, fieldMap, false);
}
if (srcFieldValue == null) {
return null;
}
String srcFieldName = fieldMap.getSrcFieldName();
String destFieldName = fieldMap.getDestFieldName();
if (!(DozerConstants.SELF_KEYWORD.equals(srcFieldName) && DozerConstants.SELF_KEYWORD.equals(destFieldName))) {
Object alreadyMappedValue = mappedFields.getMappedValue(srcFieldValue, destFieldType, fieldMap.getMapId());
if (alreadyMappedValue != null) {
return alreadyMappedValue;
}
}
//If it is only a shallow copy, return directly (configurable)
if (fieldMap.isCopyByReference()) {
// just get the src and return it, no transformation.
return srcFieldValue;
}
//Processing of Map type
boolean isSrcFieldClassSupportedMap = MappingUtils.isSupportedMap(srcFieldClass);
boolean isDestFieldTypeSupportedMap = MappingUtils.isSupportedMap(destFieldType);
if (isSrcFieldClassSupportedMap && isDestFieldTypeSupportedMap) {
return mapMap(srcObj, (Map<?, ?>)srcFieldValue, fieldMap, destObj);
}
if (fieldMap instanceof MapFieldMap && destFieldType.equals(Object.class)) {
destFieldType = fieldMap.getDestHintContainer() != null ? fieldMap.getDestHintContainer().getHint() : srcFieldClass;
}
//Mapping of basic types
//The PrimitiveOrWrapperConverter class supports conversions between compatible basic types
if (primitiveConverter.accepts(srcFieldClass) || primitiveConverter.accepts(destFieldType)) {
// Primitive or Wrapper conversion
if (fieldMap.getDestHintContainer() != null) {
Class<?> destHintType = fieldMap.getDestHintType(srcFieldValue.getClass());
// if the destType is null this means that there was more than one hint.
// we must have already set the destType then.
if (destHintType != null) {
destFieldType = destHintType;
}
}
//#1841448 - if trim-strings=true, then use a trimmed src string value when converting to dest value
Object convertSrcFieldValue = srcFieldValue;
if (fieldMap.isTrimStrings() && srcFieldValue.getClass().equals(String.class)) {
convertSrcFieldValue = ((String)srcFieldValue).trim();
}
DateFormatContainer dfContainer = new DateFormatContainer(fieldMap.getDateFormat());
if (fieldMap instanceof MapFieldMap && !primitiveConverter.accepts(destFieldType)) {
return primitiveConverter.convert(convertSrcFieldValue, convertSrcFieldValue.getClass(), dfContainer);
} else {
return primitiveConverter.convert(convertSrcFieldValue, destFieldType, dfContainer, destFieldName, destObj);
}
}
//Mapping of collection types
if (MappingUtils.isSupportedCollection(srcFieldClass) && (MappingUtils.isSupportedCollection(destFieldType))) {
return mapCollection(srcObj, srcFieldValue, fieldMap, destObj);
}
//Mapping of enumeration types
if (MappingUtils.isEnumType(srcFieldClass, destFieldType)) {
return mapEnum((Enum)srcFieldValue, (Class<Enum>)destFieldType);
}
if (fieldMap.getDestDeepIndexHintContainer() != null) {
destFieldType = fieldMap.getDestDeepIndexHintContainer().getHint();
}
//Handling of other complex object types
return mapCustomObject(fieldMap, destObj, destFieldType, destFieldName, srcFieldValue);
}
mapCustomObject method. In fact, you will find that the most important point of this method is to do recursive processing, whether it is the last call to createByCreationDirectiveAndMap or mapToDestObject.
private Object mapCustomObject(FieldMap fieldMap, Object destObj, Class<?> destFieldType, String destFieldName, Object srcFieldValue) {
srcFieldValue = MappingUtils.deProxy(srcFieldValue, beanContainer);
// Custom java bean. Need to make sure that the destination object is not
// already instantiated.
Object result = null;
// in case of iterate feature new objects are created in any case
if (!DozerConstants.ITERATE.equals(fieldMap.getDestFieldType())) {
result = getExistingValue(fieldMap, destObj, destFieldType);
}
// if the field is not null than we don't want a new instance
if (result == null) {
// first check to see if this plain old field map has hints to the actual
// type.
if (fieldMap.getDestHintContainer() != null) {
Class<?> destHintType = fieldMap.getDestHintType(srcFieldValue.getClass());
// if the destType is null this means that there was more than one hint.
// we must have already set the destType then.
if (destHintType != null) {
destFieldType = destHintType;
}
}
// Check to see if explicit map-id has been specified for the field
// mapping
String mapId = fieldMap.getMapId();
Class<?> targetClass;
if (fieldMap.getDestHintContainer() != null && fieldMap.getDestHintContainer().getHint() != null) {
targetClass = fieldMap.getDestHintContainer().getHint();
} else {
targetClass = destFieldType;
}
ClassMap classMap = getClassMap(srcFieldValue.getClass(), targetClass, mapId);
BeanCreationDirective creationDirective = new BeanCreationDirective(srcFieldValue, classMap.getSrcClassToMap(), classMap.getDestClassToMap(),
destFieldType, classMap.getDestClassBeanFactory(), classMap.getDestClassBeanFactoryId(),
fieldMap.getDestFieldCreateMethod() != null ? fieldMap.getDestFieldCreateMethod() :
classMap.getDestClassCreateMethod(),
classMap.getDestClass().isSkipConstructor(), destObj, destFieldName);
result = createByCreationDirectiveAndMap(creationDirective, classMap, srcFieldValue, null, false, fieldMap.getMapId());
} else {
mapToDestObject(null, srcFieldValue, result, false, fieldMap.getMapId());
}
return result;
}
Summary
Dozer is powerful, but the bottom layer still uses reflection, so its performance in performance test is average, second only to Apache's BeanUtils. If you do not pursue performance, you can use.
Orika
Orika can be said to almost integrate the advantages of the above tools. It not only has rich functions, but also uses Javassist to generate bytecode at the bottom, which is very efficient.
use
Orika basically supports the functions supported by Dozer. Here I also briefly introduce the use of orika. For more detailed API s, please refer to the User Guide.
private MapperFactory mapperFactory;
@Before
public void setup() {
mapperFactory = new DefaultMapperFactory.Builder().build();
ConverterFactory converterFactory = mapperFactory.getConverterFactory();
converterFactory.registerConverter(new TypeConverter());
mapperFactory.classMap(SourceVO.class, TargetVO.class)
.field("fullName", "name")
.field("type", "enumType")
.exclude("in")
.byDefault()
.register();
}
@Test
public void main() {
MapperFacade mapper = mapperFactory.getMapperFacade();
SourceVO sourceVO = getSourceVO();
log.info("sourceVO={}", GsonUtil.toJson(sourceVO));
TargetVO map = mapper.map(sourceVO, TargetVO.class);
log.info("map={}", GsonUtil.toJson(map));
}
principle
When explaining the implementation principle, let's first look at what Orika is doing behind the scenes.
By adding the following configuration, we can see that Orika generates the source code and bytecode of mapper during mapping.
System.setProperty("ma.glasnost.orika.writeSourceFiles", "true");
System.setProperty("ma.glasnost.orika.writeClassFiles", "true");
System.setProperty("ma.glasnost.orika.writeSourceFilesToPath", "path");
System.setProperty("ma.glasnost.orika.writeClassFilesToPath", "path");
Using the above example, let's take a look at the java code generated by Orika:
package ma.glasnost.orika.generated;
public class Orika_TargetVO_SourceVO_Mapper947163525829122$0 extends ma.glasnost.orika.impl.GeneratedMapperBase {
public void mapAtoB(java.lang.Object a, java.lang.Object b, ma.glasnost.orika.MappingContext mappingContext) {
super.mapAtoB(a, b, mappingContext);
// sourceType: SourceVO
beanmapper_compare.vo.SourceVO source = ((beanmapper_compare.vo.SourceVO)a);
// destinationType: TargetVO
beanmapper_compare.vo.TargetVO destination = ((beanmapper_compare.vo.TargetVO)b);
destination.setName(((java.lang.String)source.getFullName()));
if ( !(((java.lang.Integer)source.getType()) == null)){
destination.setEnumType(((beanmapper_compare.vo.TargetVO.EnumType)((ma.glasnost.orika.Converter)usedConverters[0]).convert(((java.lang.Integer)source.getType()), ((ma.glasnost.orika.metadata.Type)usedTypes[0]), mappingContext)));
} else {
destination.setEnumType(null);
}
if ( !(((java.util.Date)source.getDate1()) == null)){
destination.setDate1(((java.util.Date)((ma.glasnost.orika.Converter)usedConverters[1]).convert(((java.util.Date)source.getDate1()), ((ma.glasnost.orika.metadata.Type)usedTypes[1]), mappingContext)));
} else {
destination.setDate1(null);
}if ( !(((java.util.List)source.getListData()) == null)) {
java.util.List new_listData = ((java.util.List)new java.util.ArrayList());
new_listData.addAll(mapperFacade.mapAsList(((java.util.List)source.getListData()), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), ((ma.glasnost.orika.metadata.Type)usedTypes[3]), mappingContext));
destination.setListData(new_listData);
} else {
if ( !(((java.util.List)destination.getListData()) == null)) {
destination.setListData(null);
};
}if ( !(((java.util.Map)source.getMapData()) == null)){
java.util.Map new_mapData = ((java.util.Map)new java.util.LinkedHashMap());
for( java.util.Iterator mapData_$_iter = ((java.util.Map)source.getMapData()).entrySet().iterator(); mapData_$_iter.hasNext(); ) {
java.util.Map.Entry sourceMapDataEntry = ((java.util.Map.Entry)mapData_$_iter.next());
java.lang.Integer newMapDataKey = null;
java.util.List newMapDataVal = null;
if ( !(((java.lang.Long)sourceMapDataEntry.getKey()) == null)){
newMapDataKey = ((java.lang.Integer)((ma.glasnost.orika.Converter)usedConverters[2]).convert(((java.lang.Long)sourceMapDataEntry.getKey()), ((ma.glasnost.orika.metadata.Type)usedTypes[3]), mappingContext));
} else {
newMapDataKey = null;
}
if ( !(((java.util.List)sourceMapDataEntry.getValue()) == null)) {
java.util.List new_newMapDataVal = ((java.util.List)new java.util.ArrayList());
new_newMapDataVal.addAll(mapperFacade.mapAsList(((java.util.List)sourceMapDataEntry.getValue()), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), ((ma.glasnost.orika.metadata.Type)usedTypes[4]), mappingContext));
newMapDataVal = new_newMapDataVal;
} else {
if ( !(newMapDataVal == null)) {
newMapDataVal = null;
};
}
new_mapData.put(newMapDataKey, newMapDataVal);
}
destination.setMapData(new_mapData);
} else {
destination.setMapData(null);
}
destination.setP1(((java.lang.Integer)source.getP1()));
destination.setP2(((java.lang.Long)source.getP2()));
destination.setP3(((java.lang.Byte)source.getP3()));
destination.setPattr1(((java.lang.String)source.getPattr1()));
if ( !(((java.lang.String)source.getSeq()) == null)){
destination.setSeq(((java.lang.Long)((ma.glasnost.orika.Converter)usedConverters[3]).convert(((java.lang.String)source.getSeq()), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), mappingContext)));
} else {
destination.setSeq(null);
}
if(customMapper != null) {
customMapper.mapAtoB(source, destination, mappingContext);
}
}
public void mapBtoA(java.lang.Object a, java.lang.Object b, ma.glasnost.orika.MappingContext mappingContext) {
super.mapBtoA(a, b, mappingContext);
// sourceType: TargetVO
beanmapper_compare.vo.TargetVO source = ((beanmapper_compare.vo.TargetVO)a);
// destinationType: SourceVO
beanmapper_compare.vo.SourceVO destination = ((beanmapper_compare.vo.SourceVO)b);
destination.setFullName(((java.lang.String)source.getName()));
if ( !(((beanmapper_compare.vo.TargetVO.EnumType)source.getEnumType()) == null)){
destination.setType(((java.lang.Integer)((ma.glasnost.orika.Converter)usedConverters[0]).convert(((beanmapper_compare.vo.TargetVO.EnumType)source.getEnumType()), ((ma.glasnost.orika.metadata.Type)usedTypes[3]), mappingContext)));
} else {
destination.setType(null);
}
if ( !(((java.util.Date)source.getDate1()) == null)){
destination.setDate1(((java.util.Date)((ma.glasnost.orika.Converter)usedConverters[1]).convert(((java.util.Date)source.getDate1()), ((ma.glasnost.orika.metadata.Type)usedTypes[1]), mappingContext)));
} else {
destination.setDate1(null);
}if ( !(((java.util.List)source.getListData()) == null)) {
java.util.List new_listData = ((java.util.List)new java.util.ArrayList());
new_listData.addAll(mapperFacade.mapAsList(((java.util.List)source.getListData()), ((ma.glasnost.orika.metadata.Type)usedTypes[3]), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), mappingContext));
destination.setListData(new_listData);
} else {
if ( !(((java.util.List)destination.getListData()) == null)) {
destination.setListData(null);
};
}if ( !(((java.util.Map)source.getMapData()) == null)){
java.util.Map new_mapData = ((java.util.Map)new java.util.LinkedHashMap());
for( java.util.Iterator mapData_$_iter = ((java.util.Map)source.getMapData()).entrySet().iterator(); mapData_$_iter.hasNext(); ) {
java.util.Map.Entry sourceMapDataEntry = ((java.util.Map.Entry)mapData_$_iter.next());
java.lang.Long newMapDataKey = null;
java.util.List newMapDataVal = null;
if ( !(((java.lang.Integer)sourceMapDataEntry.getKey()) == null)){
newMapDataKey = ((java.lang.Long)((ma.glasnost.orika.Converter)usedConverters[2]).convert(((java.lang.Integer)sourceMapDataEntry.getKey()), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), mappingContext));
} else {
newMapDataKey = null;
}
if ( !(((java.util.List)sourceMapDataEntry.getValue()) == null)) {
java.util.List new_newMapDataVal = ((java.util.List)new java.util.ArrayList());
new_newMapDataVal.addAll(mapperFacade.mapAsList(((java.util.List)sourceMapDataEntry.getValue()), ((ma.glasnost.orika.metadata.Type)usedTypes[4]), ((ma.glasnost.orika.metadata.Type)usedTypes[2]), mappingContext));
newMapDataVal = new_newMapDataVal;
} else {
if ( !(newMapDataVal == null)) {
newMapDataVal = null;
};
}
new_mapData.put(newMapDataKey, newMapDataVal);
}
destination.setMapData(new_mapData);
} else {
destination.setMapData(null);
}
destination.setP1(((java.lang.Integer)source.getP1()));
destination.setP2(((java.lang.Long)source.getP2()));
destination.setP3(((java.lang.Byte)source.getP3()));
destination.setPattr1(((java.lang.String)source.getPattr1()));
if ( !(((java.lang.Long)source.getSeq()) == null)){
destination.setSeq(((java.lang.String)((ma.glasnost.orika.Converter)usedConverters[4]).convert(((java.lang.Long)source.getSeq()), ((ma.glasnost.orika.metadata.Type)usedTypes[5]), mappingContext)));
} else {
destination.setSeq(null);
}
if(customMapper != null) {
customMapper.mapBtoA(source, destination, mappingContext);
}
}
}
The mapper class has two methods mapAtoB and mapBtoA. From the name, I guess that the former is responsible for the mapping of SRC - > dest and the latter is responsible for the mapping of DeST - > Src.
OK, let's look at the implementation process.
The use of Orika is similar to that of Dozer. First, a mapperfactory is generated through configuration, and then mapperface is used as the unified entry for mapping. Here, mapperfactory and mapperface are single examples. Maperfactory only registered ClassMap when making configuration class mapping, but did not really generate the bytecode of mapper. Mapper was initialized when getMapperFacade method was called for the first time. Let's take a look at getMapperFacade.
(the source code is based on Ma. Glasnost. Orika: orika core: 1.5.4)
public MapperFacade getMapperFacade() {
if (!isBuilt) {
synchronized (mapperFacade) {
if (!isBuilt) {
build();
}
}
}
return mapperFacade;
}
The mapper is constructed by using the registered ClassMap information and MappingContext context information
public synchronized void build() {
if (!isBuilding && !isBuilt) {
isBuilding = true;
MappingContext context = contextFactory.getContext();
try {
if (useBuiltinConverters) {
BuiltinConverters.register(converterFactory);
}
converterFactory.setMapperFacade(mapperFacade);
for (Map.Entry<MapperKey, ClassMap<Object, Object>> classMapEntry : classMapRegistry.entrySet()) {
ClassMap<Object, Object> classMap = classMapEntry.getValue();
if (classMap.getUsedMappers().isEmpty()) {
classMapEntry.setValue(classMap.copyWithUsedMappers(discoverUsedMappers(classMap)));
}
}
buildClassMapRegistry();
Map<ClassMap<?, ?>, GeneratedMapperBase> generatedMappers = new HashMap<ClassMap<?, ?>, GeneratedMapperBase>();
//Focus here
//When configuring the classMap using maperfactory, it will be stored in the classMapRegistry
for (ClassMap<?, ?> classMap : classMapRegistry.values()) {
//Generate a mapper for each classMap, focusing on the buildMapper method
generatedMappers.put(classMap, buildMapper(classMap, false, context));
}
Set<Entry<ClassMap<?, ?>, GeneratedMapperBase>> generatedMapperEntries = generatedMappers.entrySet();
for (Entry<ClassMap<?, ?>, GeneratedMapperBase> generatedMapperEntry : generatedMapperEntries) {
buildObjectFactories(generatedMapperEntry.getKey(), context);
initializeUsedMappers(generatedMapperEntry.getValue(), generatedMapperEntry.getKey(), context);
}
} finally {
contextFactory.release(context);
}
isBuilt = true;
isBuilding = false;
}
}
public Set<ClassMap<Object, Object>> lookupUsedClassMap(MapperKey mapperKey) {
Set<ClassMap<Object, Object>> usedClassMapSet = usedMapperMetadataRegistry.get(mapperKey);
if (usedClassMapSet == null) {
usedClassMapSet = Collections.emptySet();
}
return usedClassMapSet;
}
Trace buildMapper method
private GeneratedMapperBase buildMapper(ClassMap<?, ?> classMap, boolean isAutoGenerated, MappingContext context) {
register(classMap.getAType(), classMap.getBType(), isAutoGenerated);
register(classMap.getBType(), classMap.getAType(), isAutoGenerated);
final MapperKey mapperKey = new MapperKey(classMap.getAType(), classMap.getBType());
//Call the build method of mapperGenerator to generate mapper
final GeneratedMapperBase mapper = mapperGenerator.build(classMap, context);
mapper.setMapperFacade(mapperFacade);
mapper.setFromAutoMapping(isAutoGenerated);
if (classMap.getCustomizedMapper() != null) {
final Mapper<Object, Object> customizedMapper = (Mapper<Object, Object>) classMap.getCustomizedMapper();
mapper.setCustomMapper(customizedMapper);
}
mappersRegistry.remove(mapper);
//The generated mapper is stored in mappers registry
mappersRegistry.add(mapper);
classMapRegistry.put(mapperKey, (ClassMap<Object, Object>) classMap);
return mapper;
}
build method of MapperGenerator
public GeneratedMapperBase build(ClassMap<?, ?> classMap, MappingContext context) {
StringBuilder logDetails = null;
try {
compilerStrategy.assureTypeIsAccessible(classMap.getAType().getRawType());
compilerStrategy.assureTypeIsAccessible(classMap.getBType().getRawType());
if (LOGGER.isDebugEnabled()) {
logDetails = new StringBuilder();
String srcName = TypeFactory.nameOf(classMap.getAType(), classMap.getBType());
String dstName = TypeFactory.nameOf(classMap.getBType(), classMap.getAType());
logDetails.append("Generating new mapper for (" + srcName + ", " + dstName + ")");
}
//Build context for generating source code and bytecode
final SourceCodeContext mapperCode = new SourceCodeContext(classMap.getMapperClassName(), GeneratedMapperBase.class, context,
logDetails);
Set<FieldMap> mappedFields = new LinkedHashSet<FieldMap>();
//Add mapAtoB method
mappedFields.addAll(addMapMethod(mapperCode, true, classMap, logDetails));
//Add mapBtoA method
//The addMapMethod method is basically the process of writing code. Interested readers can see it
mappedFields.addAll(addMapMethod(mapperCode, false, classMap, logDetails));
//Generate a mapper instance
GeneratedMapperBase instance = mapperCode.getInstance();
instance.setAType(classMap.getAType());
instance.setBType(classMap.getBType());
instance.setFavorsExtension(classMap.favorsExtension());
if (logDetails != null) {
LOGGER.debug(logDetails.toString());
logDetails = null;
}
classMap = classMap.copy(mappedFields);
context.registerMapperGeneration(classMap);
return instance;
} catch (final Exception e) {
if (logDetails != null) {
logDetails.append("\n<---- ERROR occurred here");
LOGGER.debug(logDetails.toString());
}
throw new MappingException(e);
}
Generate mapper instance
T instance = (T) compileClass().newInstance();
protected Class<?> compileClass() throws SourceCodeGenerationException {
try {
return compilerStrategy.compileClass(this);
} catch (SourceCodeGenerationException e) {
throw e;
}
}
The compiler strategy here defaults to Javassist (you can also customize the strategy for generating bytecode)
compileClass method of JavassistCompilerStrategy
This is basically a process of using Javassist. After various foreshadowing (through configuration information, context information, assembling java source code, etc.), we finally come to this step
public Class<?> compileClass(SourceCodeContext sourceCode) throws SourceCodeGenerationException {
StringBuilder className = new StringBuilder(sourceCode.getClassName());
CtClass byteCodeClass = null;
int attempts = 0;
Random rand = RANDOM;
while (byteCodeClass == null) {
try {
//Create a class
byteCodeClass = classPool.makeClass(className.toString());
} catch (RuntimeException e) {
if (attempts < 5) {
className.append(Integer.toHexString(rand.nextInt()));
} else {
// No longer likely to be accidental name collision;
// propagate the error
throw e;
}
}
}
CtClass abstractMapperClass;
Class<?> compiledClass;
try {
//Write the source code to disk (through the configuration mentioned above)
writeSourceFile(sourceCode);
Boolean existing = superClasses.put(sourceCode.getSuperClass(), true);
if (existing == null || !existing) {
classPool.insertClassPath(new ClassClassPath(sourceCode.getSuperClass()));
}
if (registerClassLoader(Thread.currentThread().getContextClassLoader())) {
classPool.insertClassPath(new LoaderClassPath(Thread.currentThread().getContextClassLoader()));
}
abstractMapperClass = classPool.get(sourceCode.getSuperClass().getCanonicalName());
byteCodeClass.setSuperclass(abstractMapperClass);
//Add field
for (String fieldDef : sourceCode.getFields()) {
try {
byteCodeClass.addField(CtField.make(fieldDef, byteCodeClass));
} catch (CannotCompileException e) {
LOG.error("An exception occurred while compiling: " + fieldDef + " for " + sourceCode.getClassName(), e);
throw e;
}
}
//Add methods, mainly mapAtoB and mapBtoA methods
//Directly use the source code to "add" methods to the class through Javassist
for (String methodDef : sourceCode.getMethods()) {
try {
byteCodeClass.addMethod(CtNewMethod.make(methodDef, byteCodeClass));
} catch (CannotCompileException e) {
LOG.error(
"An exception occured while compiling the following method:\n\n " + methodDef + "\n\n for "
+ sourceCode.getClassName() + "\n", e);
throw e;
}
}
//Generate class
compiledClass = byteCodeClass.toClass(Thread.currentThread().getContextClassLoader(), this.getClass().getProtectionDomain());
//Bytecode file write to disk
writeClassFile(sourceCode, byteCodeClass);
} catch (NotFoundException e) {
throw new SourceCodeGenerationException(e);
} catch (CannotCompileException e) {
throw new SourceCodeGenerationException("Error compiling " + sourceCode.getClassName(), e);
} catch (IOException e) {
throw new SourceCodeGenerationException("Could not write files for " + sourceCode.getClassName(), e);
}
return compiledClass;
}
OK, the mapper class has been generated. Now let's see how to use this mapper class when calling the map method of MapperFacade.
In fact, it's very simple. Remember whether the generated mapper is placed in mappers registry. Track the code. Find the mapper in mappers registry according to typeA and typeB in resolveMappingStrategy method, and call mapAtoB or mapBtoA methods of mapper.
Summary
Overall, Orika is a powerful and high-performance tool, which is recommended.
summary
Through the comparison of BeanUtils, BeanCopier, Dozer and Orika, we know their performance and implementation principle. When using, we can choose according to our actual situation and recommend Orika.