
create table test( name string, friends array<string>, children map<string, int>, address struct<street:string, city:string> ) row format delimited fields terminated by ',' collection items terminated by '_' map keys terminated by ':' lines terminated by '\n';
Field interpretation:
Row format defined fields terminated by ',' -- column separator
collection items terminated by '_' -- Separator for map structure and ARRAY (data split symbol)
map keys terminated by ':'
--Separator between key and value in MAP
lines terminated by '\n'; -- line separator
example:
First, prepare the data: create a new test file test txt

Load local file data into hive table
load data local inpath '/usr/local/apache-hive-1.2.1-bin/test.txt' into table test;
View content

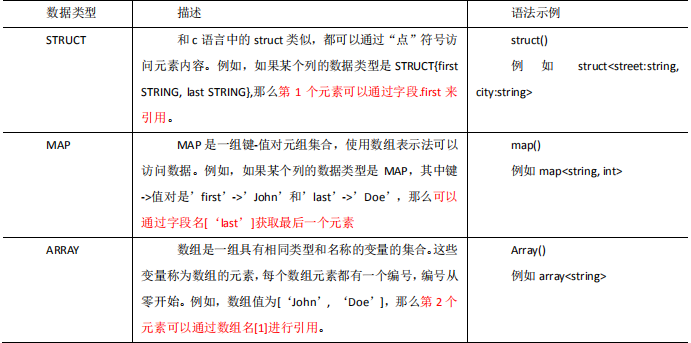
Different structure access methods

3. Database and table operations
3.1. Database operation
Default storage path of database on HDFS: / user / hive / warehouse / * db
create database db_hive; --Create database
create database if not exists db_hive ; --Standard writing: avoid that the database already exists, if not exists Used to determine whether the database exists
show databases like 'db_*'; --Fuzzy search database
use db_hive; --Switch database;
create database db_hive location '/db_hive.db'; --Specify the database in hdfs Storage path on
show databases like 'db_hive*'; --Fuzzy query database
desc databases db_hive; --Display database information
desc database extended db_hive; --Display database details (see creation time)
alter database db_hive set dbproperties('createtime'='21823');--Set properties for the database through key value pairs
drop database db_hive; --Delete database
drop database if exists db_hive4; --use if exists Judge whether the database exists before deleting it3.2 table operation
Syntax:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] [AS select_statement]
example:
Create an external table for students (excluding external is the internal table), take gender as partition, specify storage location and store it as text type
create external table if not exists student( uid int,name string ) partitioned by(sex string) row format delimited fields terminated by '\t' stored as textfile location '/user/hive/warehouse/student/';
Common database table commands
--Create table based on query results
create table if not exists student3 as select id, name from student;
hive (default)> desc formatted student3; --Type of query table (external table or internal table)
Table Type: MANAGED_TABLE
hive>alter table student2 set tblproperties('EXTERNAL'='TRUE'); --Modify internal table student2 Is an external table, FALSE Is an internal table
hive>ALTER TABLE table_name RENAME TO new_table_name; --rename table
hive (default)> alter table dept add columns(deptdesc string); --Add column
hive>desc dept; --Structure of query table
hive>alter table dept change column deptdesc desc string; --Change the column name, or change the column type
hive>alter table student replace columns(id string,name string,loc string) --Replace the fields in parentheses with the fields in the table
hive>drop table student; --Delete tableInsert data into table
--insert Insert data: insert into: Insert the mode of appended data into the table or partition; insert overwrite : Insert in overlay mode into a table or partition
hive> insert into table people values(4,'xiaoli'),(5,'ming'); --Basic data insertion (a little slow)
hive> insert overwrite table people select id,name from people; --Insert data into the database according to the query results hive In the table
hive>insert overwrite local derectory '/usr/test/student' select * from studnet; --Import query results to local
hive(default)>insert into local directory '/student' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student; --Format export to local
--Insert into different partitions according to the query results of multiple tables
hive (default)> from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';hive> load data [local] inpath 'Data path' [overwrite] into table student [partition (partcol1=val1,...)];
Interpretation of terms:
(1) load data: indicates loading data
(2) local: means to load data locally to the hive table; otherwise, load data from HDFS to the hive table
(3) inpath: indicates the path to load data
(4) Overwrite: it means to overwrite the existing data in the table, otherwise it means to append
(5) into table: indicates which table to load
(6) student: represents a specific table
(7) Partition: indicates to upload to the specified partition
(1) Import local data into hive table (just change the path in quotation marks and the table you want to import)
hive> load data local inpath '/usr/local/people.txt' into table people;
(2) HDFS creates a directory, and HDFS imports and exports data
hive>dfs -mkdir /studnet; --stay HDFS Create directory on hive> dfs -put /usr/local/people.txt /student; --Import local files into hdfs hive> dfs -get /user/hive/warehoues/student/student.txt /usr/local/test/student.txt; --from hdfs Export to local on
(3) Import the data at the specified location on HDFS into the hive table
hive> load data inpath '/user/hive/people.txt' into table default.people; --Upgrading: overlay mode(overwrite)Overwrite the original data hive> load data inpath '/user/hive/warehouse/people.txt' overwrite into table default.people;
(4) Import the data in the hive table into the specified hive table
hive (default)> import table student2 from '/user/hive/warehouse/export/student';
(5) Export and export data to HDFS (export and import are commonly used for hive table migration between two hadoop platform clusters)
hive>export table default.student to '/user/hive/warehouse/export/studnet';
(6) , Hive Shell command export:
[user@root ]#bin/hive -e 'select * from default.studnet;' > /usr/local/test/student.txt;