preface
Digital thousandth division, 3-3-4 format splicing of mobile phone number, implementation of trim function, HTML escape, obtaining url query parameters... Do you often encounter them in interviews and work? Let's see how to catch them all with regular!!!
1. Division of thousands of digital prices
Change 123456789 to 123456789
It is estimated that this problem is often encountered in interviews and work, and the frequency is relatively high.
Regular results
'123456789'.replace(/(?!^)(?=(\d{3})+$)/g, ',') // 123,456,789
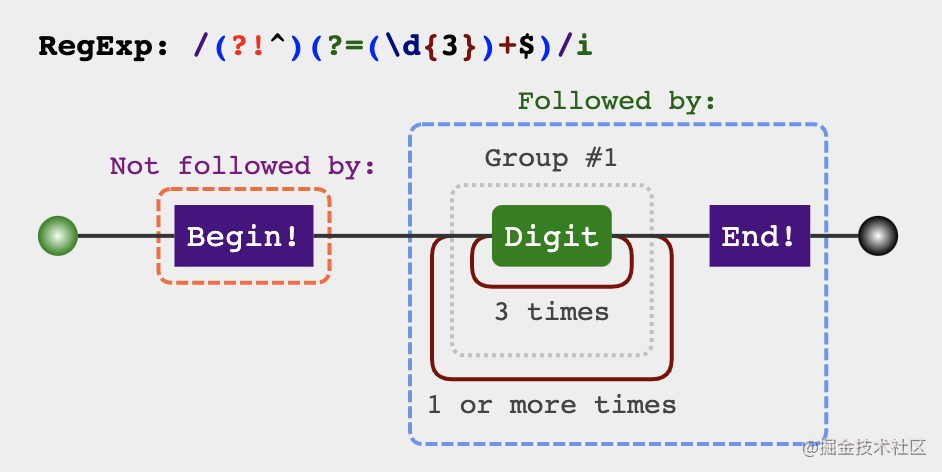
Analysis process
The title probably means:
-
Add a comma before every three numbers from the back to the front
-
No comma is allowed at the beginning (for example, 123 cannot be changed into 123 at the end)
Is it in line with the law of (? = p)? p can represent every three numbers. The position of the comma to be added is exactly the position matched by (? = p).
First, try to get the first comma out
let price = '123456789'
let priceReg = /(?=\d{3}$)/
console.log(price.replace(proceReg, ',')) // 123456,789
Step two, get all the commas out
To get all commas out, the main problem to be solved is how to represent a group of three numbers, that is, a multiple of 3. We know that regular brackets can turn a p pattern into a small whole, so we can write it this way by using the characteristics of brackets
let price = '123456789'
let priceReg = /(?=(\d{3})+$)/g
console.log(price.replace(priceReg, ',')) // ,123,456,789
Step 3, remove the comma in the first place,
The above requirements have been basically realized, but it is not enough. There will be commas in the first place. How to remove the commas in the first place? Think about whether there is a knowledge just to meet this scenario? Yes (?! p), it's him. The combination of the two is to add a comma before the position of every three numbers from the back to the front, but this position can't be the first place.
let price = '123456789'
let priceReg = /(?!^)(?=(\d{3})+$)/g
console.log(price.replace(priceReg, ',')) // 123,456,789
2. Cell phone number 3-4-4 Division
Convert mobile phone number 18379836654 to 183-7983-6654
Form collection scenarios, frequently encountered mobile phone formatting
Regular results
let mobile = '18379836654'
let mobileReg = /(?=(\d{4})+$)/g
console.log(mobile.replace(mobileReg, '-')) // 183-7983-6654

Analysis process
With the percentile division of the above numbers, I believe it will be much easier to do this problem, that is, find such a position from back to front:
The position before every four numbers and replace this position with-
let mobile = '18379836654'
let mobileReg = /(?=(\d{4})+$)/g
console.log(mobile.replace(mobileReg, '-')) // 183-7983-6654
3. Mobile number 3-4-4 segmentation extension
The following conditions must be met to convert the mobile phone number 18379836654 to 183-7983-6654
- 123 => 123
- 1234 => 123-4
- 12345 => 123-45
- 123456 => 123-456
- 1234567 => 123-4567
- 12345678 => 123-4567-8
- 123456789 => 123-4567-89
- 12345678911 => 123-4567-8911
Think about it. In fact, we often encounter that users need to constantly format their mobile phone number in the process of entering their mobile phone number.
Regular results
const formatMobile = (mobile) => {
return String(mobile).slice(0,11)
.replace(/(?<=\d{3})\d+/, ($0) => '-' + $0)
.replace(/(?<=[\d-]{8})\d{1,4}/, ($0) => '-' + $0)
}
console.log(formatMobile(18379836654))
Analysis process
It is not appropriate to use (? = p) here. For example, 1234 will become - 1234. We need to find another way,
Are there any other knowledge points in regular to deal with this scenario? Yes (< = P)
Step one, get the first one out
const formatMobile = (mobile) => {
return String(mobile).replace(/(?<=\d{3})\d+/, '-')
}
console.log(formatMobile(123)) // 123
console.log(formatMobile(1234)) // 123-4
Get the second one out
Then we get the second one, the second one - right in position 8 (1234567 -).
const formatMobile = (mobile) => {
return String(mobile).slice(0,11)
.replace(/(?<=\d{3})\d+/, ($0) => '-' + $0)
.replace(/(?<=[\d-]{8})\d{1,4}/, ($0) => '-' + $0)
}
console.log(formatMobile(123)) // 123
console.log(formatMobile(1234)) // 123-4
console.log(formatMobile(12345)) // 123-45
console.log(formatMobile(123456)) // 123-456
console.log(formatMobile(1234567)) // 123-4567
console.log(formatMobile(12345678)) // 123-4567-8
console.log(formatMobile(123456789)) // 123-4567-89
console.log(formatMobile(12345678911)) // 123-4567-8911
4. Verify the validity of the password
The password is 6-12 digits long and consists of numbers, lowercase letters and uppercase letters, but it must contain at least 2 characters
Regular results
let reg = /((?=.*\d)((?=.*[a-z])|(?=.*[A-Z])))|(?=.*[a-z])(?=.*[A-Z])^[a-zA-Z\d]{6,12}$/
console.log(reg.test('123456')) // false
console.log(reg.test('aaaaaa')) // false
console.log(reg.test('AAAAAAA')) // false
console.log(reg.test('1a1a1a')) // true
console.log(reg.test('1A1A1A')) // true
console.log(reg.test('aAaAaA')) // true
console.log(reg.test('1aA1aA1aA')) // true
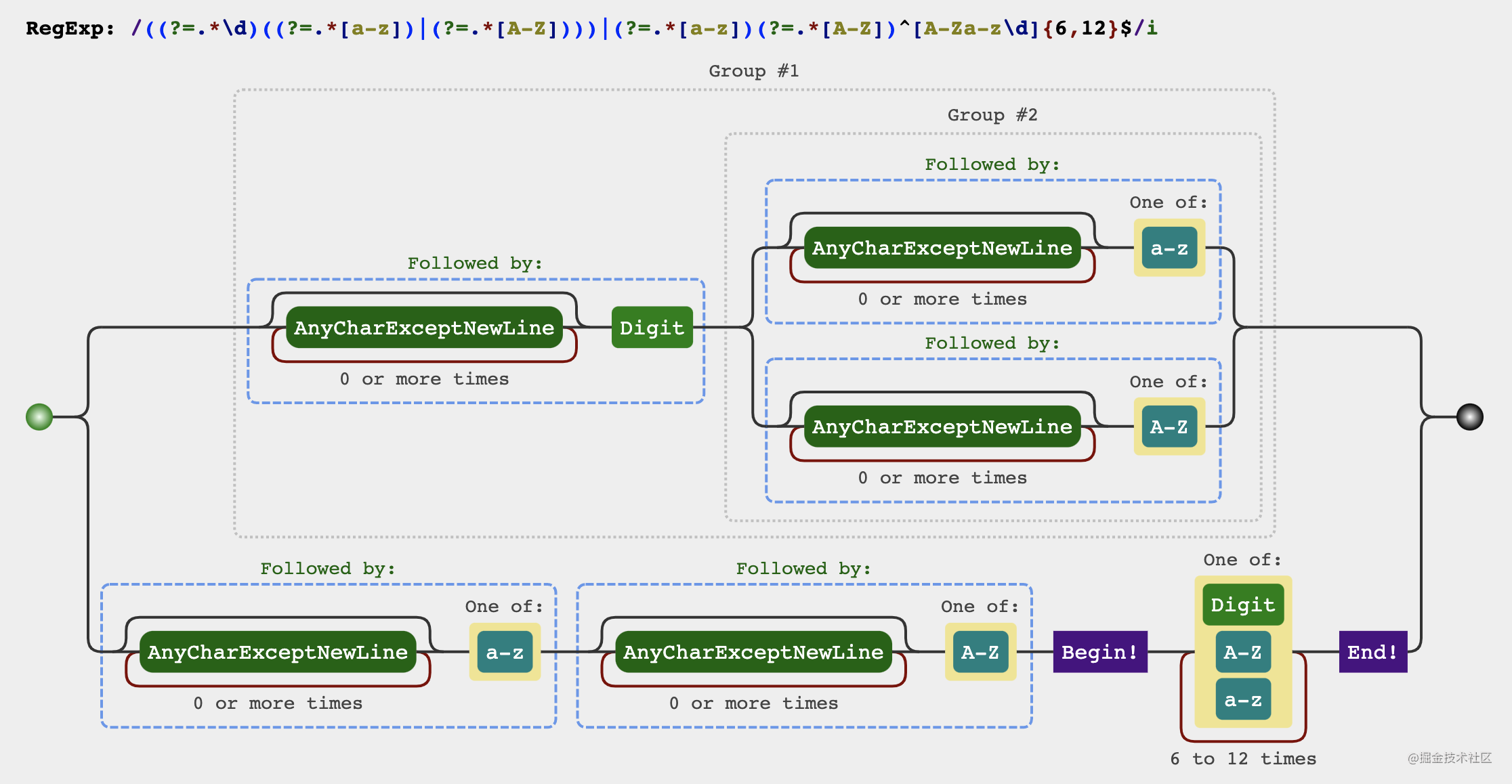
Analysis process
The topic consists of three conditions
-
The password length is 6-12 bits
-
It consists of numbers, lowercase characters and uppercase letters
-
Must include at least 2 characters
First, write conditions 1 and 2 and regular
let reg = /^[a-zA-Z\d]{6,12}$/
The second step must contain some characters (numbers, lowercase letters, uppercase letters)
let reg = /(?=.*\d)/
// This regular means that what matches is a position
// This position needs to satisfy 'any number of symbols, followed by a number',
// Notice that it ends up with a location, not something else
// (? =. * \ d) is often used for conditional restrictions
console.log(reg.test('hello')) // false
console.log(reg.test('hello1')) // true
console.log(reg.test('hel2lo')) // true
// The same applies to other types
The third step is to write a complete regular
It must contain two characters, which can be arranged and combined in the following four ways
-
Combination of numbers and lowercase letters
-
Combination of numbers and uppercase letters
-
Combination of lowercase and uppercase letters
-
Numbers, lowercase letters and uppercase letters are combined together (but in fact, the first three have covered the fourth)
// Indicates conditions 1 and 2
// let reg = /((?=.*\d)((?=.*[a-z])|(?=.*[A-Z])))/
// Indicates condition 3
// let reg = /(?=.*[a-z])(?=.*[A-Z])/
// Indicates condition 123
// let reg = /((?=.*\d)((?=.*[a-z])|(?=.*[A-Z])))|(?=.*[a-z])(?=.*[A-Z])/
// Indicates all conditions of the topic
let reg = /((?=.*\d)((?=.*[a-z])|(?=.*[A-Z])))|(?=.*[a-z])(?=.*[A-Z])^[a-zA-Z\d]{6,12}$/
console.log(reg.test('123456')) // false
console.log(reg.test('aaaaaa')) // false
console.log(reg.test('AAAAAAA')) // false
console.log(reg.test('1a1a1a')) // true
console.log(reg.test('1A1A1A')) // true
console.log(reg.test('aAaAaA')) // true
console.log(reg.test('1aA1aA1aA')) // true
5. Extract continuously repeated characters
Extract repeated characters, such as 1232345455666, and extract ['23', '45', '6']
Regular results
const collectRepeatStr = (str) => {
let repeatStrs = []
const repeatRe = /(.+)\1+/g
str.replace(repeatRe, ($0, $1) => {
$1 && repeatStrs.push($1)
})
return repeatStrs
}
Analysis process
Several key messages in the title are
- Consecutive repeated characters
- The length of consecutive repeated characters is unlimited (for example, 23 and 45 are two digits and 6 is one digit)
What is continuous repetition?
11 is a continuous repetition, 22 is a continuous repetition, and 111, of course. In other words, some characters x must be followed by X, which is called continuous repetition. If you know clearly that x is 1, then / 11 + / can be matched, but the key is that x here is not clear. What should we do?.
Using the regular knowledge of back reference can easily solve this problem.
The first step is to write a regular string indicating that there is a character repetition
// The X here is available That is, all characters are referenced in parentheses, followed by reverse application \ 1, which reflects the meaning of continuous repetition
let repeatRe = /(.)\1/
console.log(repeatRe.test('11')) // true
console.log(repeatRe.test('22')) // true
console.log(repeatRe.test('333')) // true
console.log(repeatRe.test('123')) // true
The second step is to write a regular expression that indicates that there are n character repetitions
Because it is uncertain whether to match 11 or 45, the usage word + in parentheses is required to reflect n repeated characters, and the back reference itself can be greater than one, such as 45
let repeatRe = /(.+)\1+/
console.log(repeatRe.test('11')) // true
console.log(repeatRe.test('22')) // true
console.log(repeatRe.test('333')) // true
console.log(repeatRe.test('454545')) // true
console.log(repeatRe.test('124')) // false
The third step is to extract all consecutive repeated characters
const collectRepeatStr = (str) => {
let repeatStrs = []
const repeatRe = /(.+)\1+/g
// Many times, replace is not used for replacement, but for data extraction
str.replace(repeatRe, ($0, $1) => {
$1 && repeatStrs.push($1)
})
return repeatStrs
}
console.log(collectRepeatStr('11')) // ["1"]
console.log(collectRepeatStr('12323')) // ["23"]
console.log(collectRepeatStr('12323454545666')) // ["23", "45", "6"]
6. Implement a trim function
Remove the leading and trailing spaces of the string
Regular results
// Space removal method
const trim = (str) => {
return str.replace(/^\s*|\s*$/g, '')
}
// Extracting non blank space method
const trim = (str) => {
return str.replace(/^\s*(.*?)\s*$/g, '$1')
}
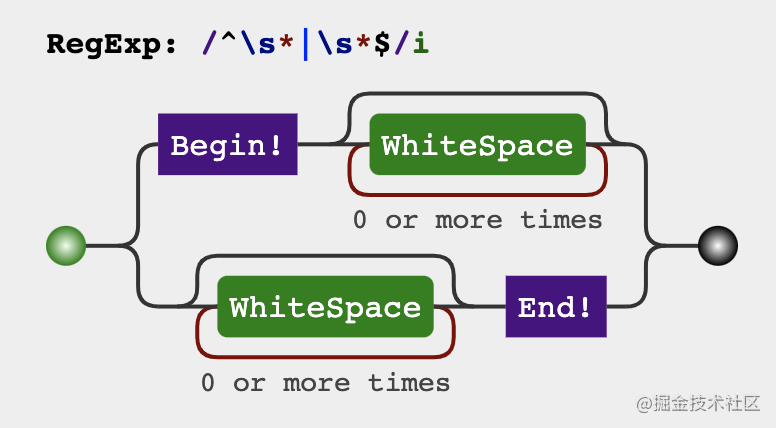

Analysis process
At first glance, the way that flashed through our mind is to delete the blank part and retain the non blank part, but we can also change our thinking, or extract the non blank part, regardless of the blank part. Next, let's write the implementation of two trim methods
Method 1: remove blank space method
const trim = (str) => {
return str.replace(/^\s*|\s*$/g, '')
}
console.log(trim(' Front fat head fish')) // Front fat head fish
console.log(trim('Front fat head fish ')) // Front fat head fish
console.log(trim(' Front fat head fish ')) // Front fat head fish
console.log(trim(' Front fat head fish ')) // Front fat head fish
Method 2: extracting non blank space
const trim = (str) => {
return str.replace(/^\s*(.*?)\s*$/g, '$1')
}
console.log(trim(' Front fat head fish')) // Front fat head fish
console.log(trim('Front fat head fish ')) // Front fat head fish
console.log(trim(' Front fat head fish ')) // Front fat head fish
console.log(trim(' Front fat head fish ')) // Front fat head fish
7. HTML escape
One of the ways to prevent XSS attacks is to do HTML escape. The escape rules are as follows. It is required to convert the corresponding characters into equivalent entities. The reverse meaning is to convert the escaped entity into the corresponding character
| character | Escaped entity |
|---|---|
| & | & |
| < | < |
| > | > |
| " | " |
| ' | ' |
Regular results
const escape = (string) => {
const escapeMaps = {
'&': 'amp',
'<': 'lt',
'>': 'gt',
'"': 'quot',
"'": '#39'
}
const escapeRegexp = new RegExp(`[${Object.keys(escapeMaps).join('')}]`, 'g')
return string.replace(escapeRegexp, (match) => `&${escapeMaps[match]};`)
}
Analysis process
Global match &, <, >, ", 'and replace them according to the above table. When a character like this may be one of many situations, we usually use character groups, that is [& < >"]
const escape = (string) => {
const escapeMaps = {
'&': 'amp',
'<': 'lt',
'>': 'gt',
'"': 'quot',
"'": '#39'
}
// The effect here is the same as / [& < > "'] / g
const escapeRegexp = new RegExp(`[${Object.keys(escapeMaps).join('')}]`, 'g')
return string.replace(escapeRegexp, (match) => `&${escapeMaps[match]};`)
}
console.log(escape(`
<div>
<p>hello world</p>
</div>
`))
/*
<div>
<p>hello world</p>
</div>
*/
8. HTML anti escape
Regular results
Anti escape, that is, the inverse process just now, we can easily write it
const unescape = (string) => {
const unescapeMaps = {
'amp': '&',
'lt': '<',
'gt': '>',
'quot': '"',
'#39': "'"
}
const unescapeRegexp = /&([^;]+);/g
return string.replace(unescapeRegexp, (match, unescapeKey) => {
return unescapeMaps[ unescapeKey ] || match
})
}
console.log(unescape(`
<div>
<p>hello world</p>
</div>
`))
/*
<div>
<p>hello world</p>
</div>
*/
9. Hump the string
According to the following rules, the corresponding string is changed into hump writing
1. foo Bar => fooBar 2. foo-bar---- => fooBar 3. foo_bar__ => fooBar
Regular results
const camelCase = (string) => {
const camelCaseRegex = /[-_\s]+(.)?/g
return string.replace(camelCaseRegex, (match, char) => {
return char ? char.toUpperCase() : ''
})
}

Analysis process
Analyze the law of the topic
- Each word is preceded by 0 or more - spaces_ E.g. (FOO, -- FOO, _FOO, _BAR, Bar)
- -Space_ It may not be followed by anything, such as (_, --)
const camelCase = (string) => {
// Attention (.)? there? To meet condition 2
const camelCaseRegex = /[-_\s]+(.)?/g
return string.replace(camelCaseRegex, (match, char) => {
return char ? char.toUpperCase() : ''
})
}
console.log(camelCase('foo Bar')) // fooBar
console.log(camelCase('foo-bar--')) // fooBar
console.log(camelCase('foo_bar__')) // fooBar
10. Convert the first letter of the string to uppercase and the rest to lowercase
For example, from Hello World to Hello World
Regular results
const capitalize = (string) => {
const capitalizeRegex = /(?:^|\s+)\w/g
return string.toLowerCase().replace(capitalizeRegex, (match) => match.toUpperCase())
}
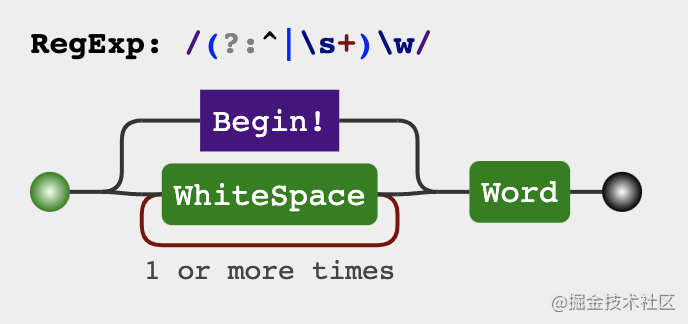
Analysis process
Find the first letter of the word and convert it into capital letters. The word may be preceded by a beginning or multiple spaces.
const capitalize = (string) => {
const capitalizeRegex = /(?:^|\s+)\w/g
return string.toLowerCase().replace(capitalizeRegex, (match) => match.toUpperCase())
}
console.log(capitalize('hello world')) // Hello World
console.log(capitalize('hello WORLD')) // Hello World
11. Get the picture addresses of all img tags in the web page
The requirement must be an online link, e.g https://xxx.juejin.com/a.jpg , http://xxx.juejin.com/a.jpg ,//xxx.juejjin.com/a.jpg
Analysis process
Students who have written some crawlers must be familiar with the url matching the img tag. In order to accurately capture the picture address of your little sister, you must have used all your talents, and finally achieved your wish.
The title defines
- Picture label img
- It needs to be in the form of online links, and some base64 images need to be filtered out
Next, let's look directly at the results and see what the regularization means in the form of visualization
const matchImgs = (sHtml) => {
const imgUrlRegex = /<img[^>]+src="((?:https?:)?\/\/[^"]+)"[^>]*?>/gi
let matchImgUrls = []
sHtml.replace(imgUrlRegex, (match, $1) => {
$1 && matchImgUrls.push($1)
})
return matchImgUrls
}
Let's divide the regular into several parts
-
The part between img tag and src, as long as it is not >, everything else is OK
-
The part in parentheses, that is, the url part we want to extract, exists as a capture group for direct access
2.1 (?:https? 😃? Indicates that the supported protocol header is http: or HTTPS:
2.2?, outside the brackets?, It means that there can be no protocol header, that is, / / XXX is supported juejjin. Link in the form of COM / a.jpg
2.3 followed by two slashes
2.4 because the part within src = "" double quotation marks is a link, [^ "] + means that everything except" is OK
-
Then there is the part between "to img end tag". Everything except > [^ >] *?

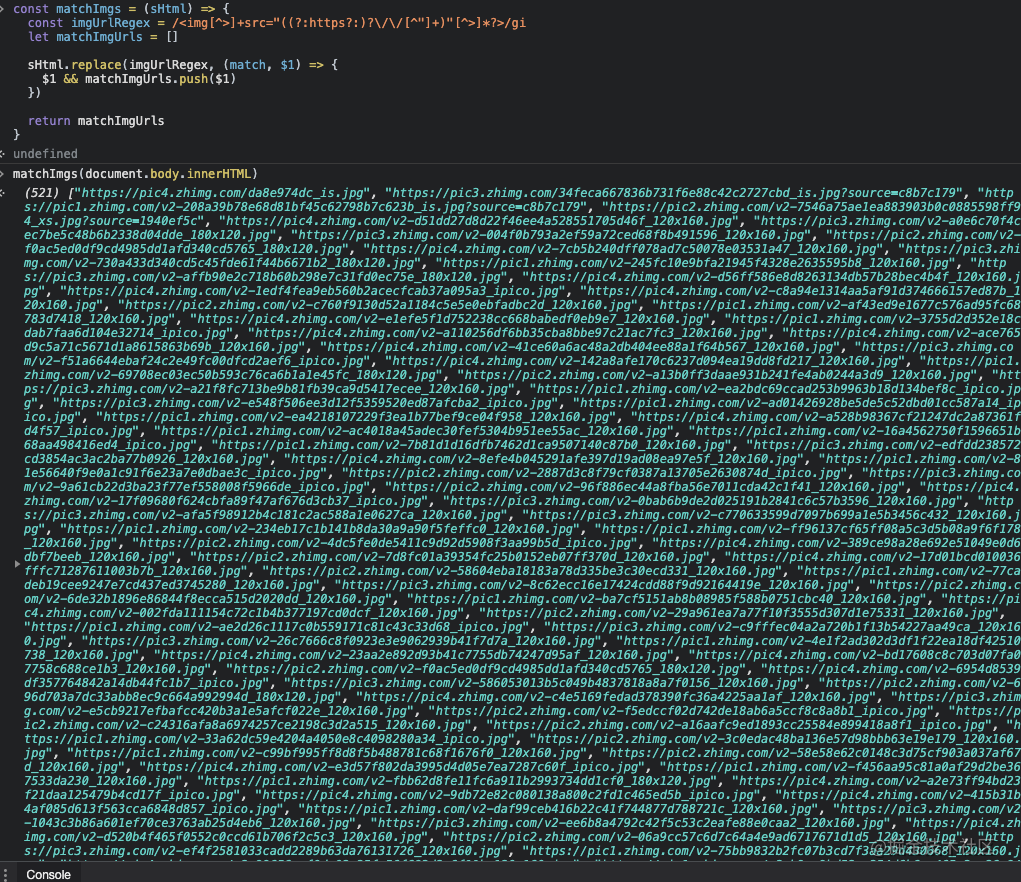
Try the results
We're here Know , open the console and you can see that it is in line with expectations.
12. Get the url query parameter through name
Regular results
const getQueryByName = (name) => {
const queryNameRegex = new RegExp(`[?&]${name}=([^&]*)(&|$)`)
const queryNameMatch = window.location.search.match(queryNameRegex)
// Generally, it will be decoded through the decodeURIComponent
return queryNameMatch ? decodeURIComponent(queryNameMatch[1]) : ''
}
Analysis process
The parameter name = on url query may be the location of the front-end fat head fish
-
Followed by a question mark? name = fat head fish & sex = boy
-
In the last position? Sex = Boy & name = fat head fish
-
Between 1 and 2? Sex = Boy & name = front fat head fish & age = 100
So as long as we deal with three places, we can get them through regularization
- name can only be preceded by? Or&
- The value of value can be anything except what is & thought
- value can only be followed by & or end position
const getQueryByName = (name) => {
const queryNameRegex = new RegExp(`[?&]${name}=([^&]*)(?:&|$)`)
const queryNameMatch = window.location.search.match(queryNameRegex)
// Generally, it will be decoded through the decodeURIComponent
return queryNameMatch ? decodeURIComponent(queryNameMatch[1]) : ''
}
// 1. name is at the front
// https://juejin.cn/?name= Front fat head fish & sex = boy
console.log(getQueryByName('name')) // Front fat head fish
// 2. name at the end
// https://juejin.cn/?sex=boy&name= Front fat head fish
console.log(getQueryByName('name')) // Front fat head fish
// 2. name in the middle
// https://juejin.cn/?sex=boy&name= Front fat head fish & age = 100
console.log(getQueryByName('name')) // Front fat head fish
13. Matching 24-hour time
The matching rules for judging whether the time meets the requirements of 24-hour system are as follows
- 01:14
- 1:14
- 1:1
- 23:59
Regular results
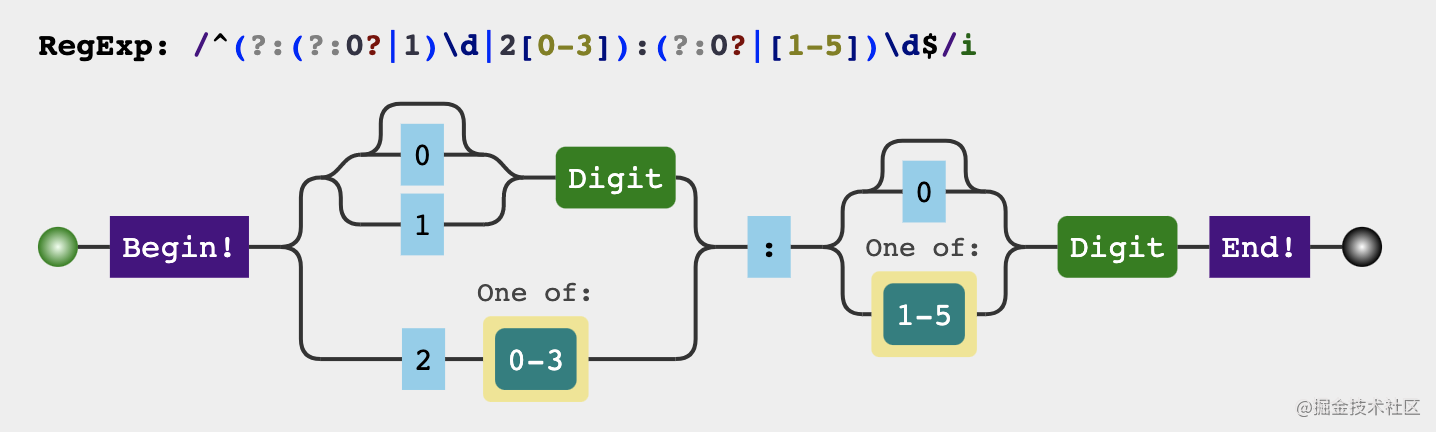
const check24TimeRegexp = /^(?:(?:0?|1)\d|2[0-3]):(?:0?|[1-5])\d$/
Analysis process
The hours and minutes of the 24-hour system need to be met respectively
Time
-
The first can be 012
-
Second place
2.1 When the first digit is 01, the second digit can be any number
2.2 when the second bit is 2, the second bit can only be 0, 1, 2 and 3
branch
- The first bit can be 0, 1, 2, 3, 4, 5
- The second digit can be any number
The first step is to write out the regular rules that comply with rules 1 and 4
const check24TimeRegexp = /^(?:[01]\d|2[0-3]):[0-5]\d$/
console.log(check24TimeRegexp.test('01:14')) // true
console.log(check24TimeRegexp.test('23:59')) // true
console.log(check24TimeRegexp.test('23:60')) // false
console.log(check24TimeRegexp.test('1:14')) // false actually needs support
console.log(check24TimeRegexp.test('1:1')) // false actually needs support

Step 2, write the case where both hours and minutes can be singular
const check24TimeRegexp = /^(?:(?:0?|1)\d|2[0-3]):(?:0?|[1-5])\d$/
console.log(check24TimeRegexp.test('01:14')) // true
console.log(check24TimeRegexp.test('23:59')) // true
console.log(check24TimeRegexp.test('23:60')) // false
console.log(check24TimeRegexp.test('1:14')) // true
console.log(check24TimeRegexp.test('1:1')) // true
14. Match date format
Matching is required (yyyy MM DD, yyyy.mm.dd, yyyy/mm/dd), such as 2021-08-22, 2021.08 22. Leap years may not be considered on August 22, 2021
Regular results
const checkDateRegexp = /^\d{4}([-\.\/])(?:0[1-9]|1[0-2])\1(?:0[1-9]|[12]\d|3[01])$/

Analysis process
Date format is mainly divided into three parts
-
Yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy
-
mm month part
2.1 there are only 12 months in a year. 0\d can be used in the first 10 months
2.2 October and beyond 1 [0-2]
-
dd day part
3.1 the maximum date of a month is 31 days
3.2 the minimum is No. 1
Separator
It should be noted that the delimiters must be the same and cannot be -/ Three kinds of mixed use, such as August 22, 2021
According to the above analysis, we can write
const checkDateRegexp = /^\d{4}([-\.\/])(?:0[1-9]|1[0-2])\1(?:0[1-9]|[12]\d|3[01])$/
console.log(checkDateRegexp.test('2021-08-22')) // true
console.log(checkDateRegexp.test('2021/08/22')) // true
console.log(checkDateRegexp.test('2021.08.22')) // true
console.log(checkDateRegexp.test('2021.08/22')) // false
console.log(checkDateRegexp.test('2021/08-22')) // false
There is a Backref #1 in the visual form, that is, the first group is referenced back ([- \. \ /]), which ensures that the delimiters must be the same

15. Match hexadecimal color values
It is required to match similar #ffbbad and #FFF16 hexadecimal color values from the string string
Regular results
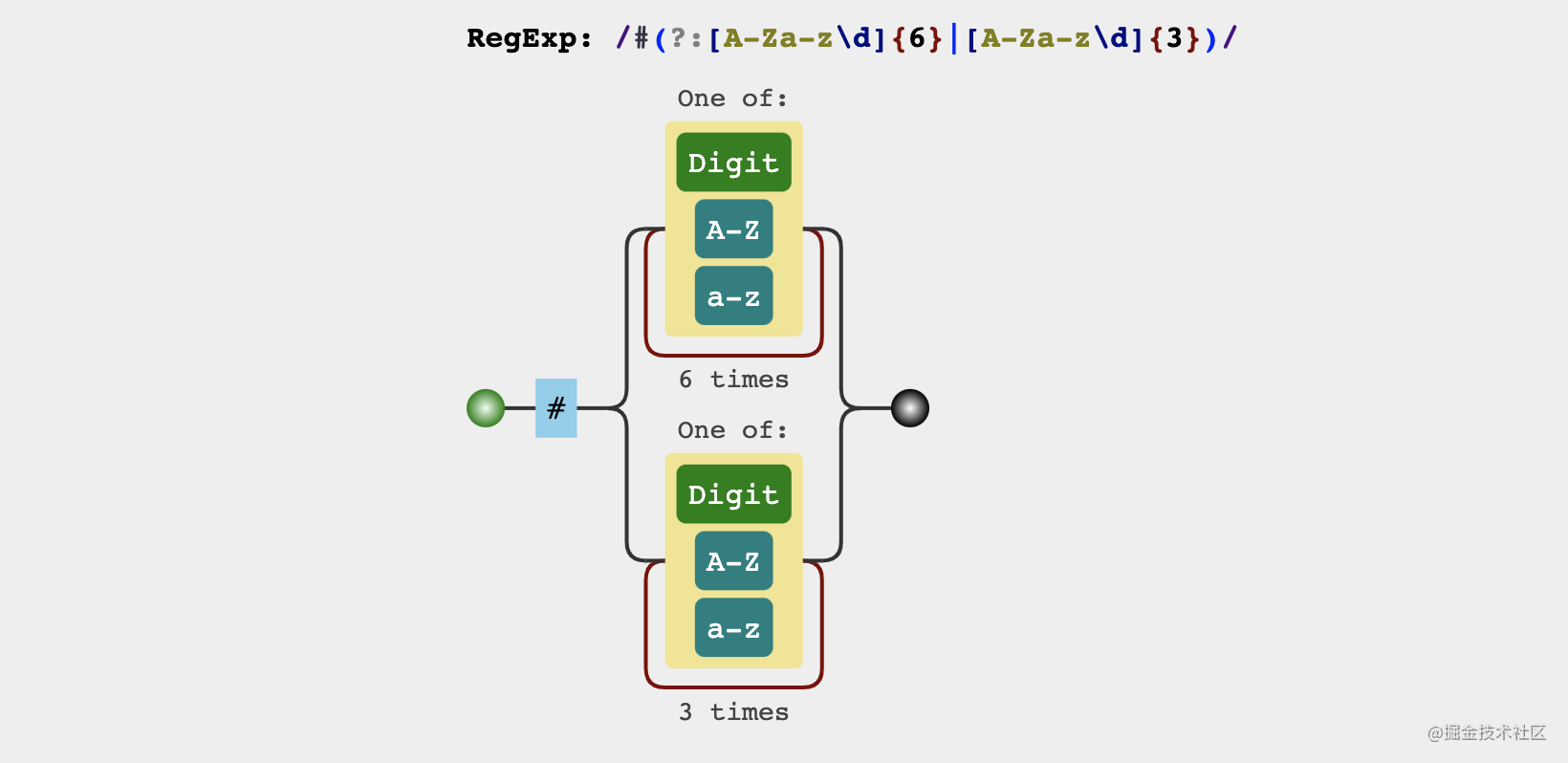
const matchColorRegex = /#(?:[\da-zA-Z]{6}|[\da-zA-Z]{3})/g
Analysis process
The hexadecimal color value consists of the following two parts
- #
- It is composed of 6 or 3 digits, upper and lower case letters
const matchColorRegex = /#(?:[\da-zA-Z]{6}|[\da-zA-Z]{3})/g
const colorString = '#12f3a1 #ffBabd #FFF #123 #586'
console.log(colorString.match(matchColorRegex))
// [ '#12f3a1', '#ffBabd', '#FFF', '#123', '#586' ]
We cannot write the regular as / # ([\ da-zA-Z]{3}|[\da-zA-Z]{6})/g, because the multiple branches | in the regular are inert matching, and the previous branches are matched first. At this time, match '#12f3a1 #ffBabd #FFF #123 #586', and you will get ['#12f', 'FFB', 'FFF', '123', #586 ']
16. Detect URL prefix
Check whether a url is an http or https protocol header
This is relatively simple, but it is often encountered in daily work.
Regular results
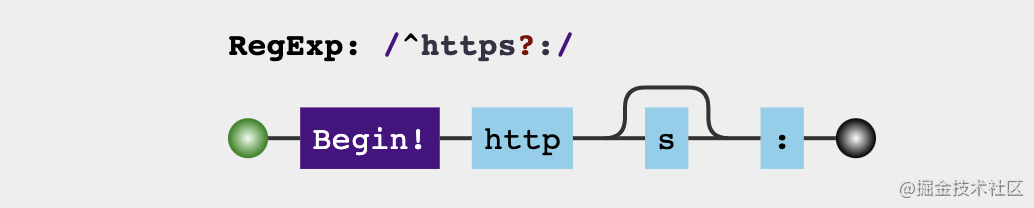
const checkProtocol = /^https?:/
console.log(checkProtocol.test('https://juejin.cn/')) // true
console.log(checkProtocol.test('http://juejin.cn/')) // true
console.log(checkProtocol.test('//juejin.cn/')) // false
17. Test Chinese
Check whether the string str is all composed of Chinese
The most important thing is to determine the coding range of Chinese in unicode Unicode coding range of Chinese characters , if you want to add matching other than basic Chinese characters, you only need to use multiple branches
Analysis process
const checkChineseRegex = /^[\u4E00-\u9FA5]+$/
console.log(checkChineseRegex.test('Front fat head fish'))
console.log(checkChineseRegex.test('1 Front fat head fish'))
console.log(checkChineseRegex.test('Front fat head fish 2'))
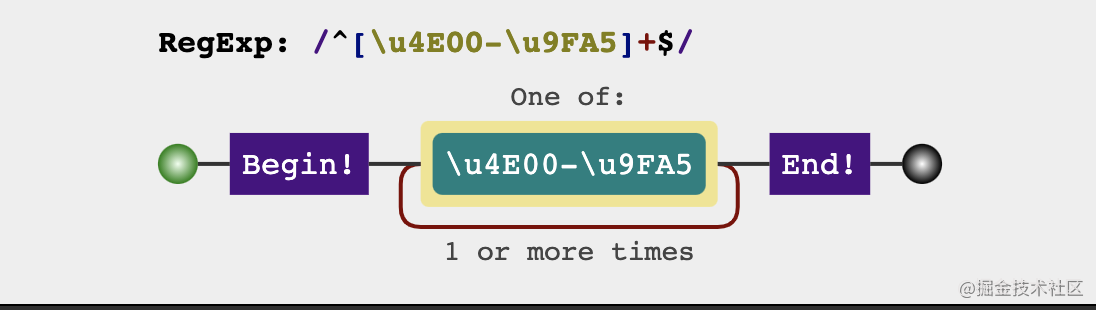
18. Matching mobile phone number
Check whether a string conforms to the rules of mobile phone number
Timeliness
The mobile phone number itself has timeliness. Major operators sometimes launch new numbers, so our regular number also has timeliness and needs to be supplemented in time
Regularity
Specific rules can be viewed Chinese mainland mobile terminal communication number
Analytical process
Regular reference self ChinaMobilePhoneNumberRegex
const mobileRegex = /^(?:\+?86)?1(?:3\d{3}|5[^4\D]\d{2}|8\d{3}|7(?:[235-8]\d{2}|4(?:0\d|1[0-2]|9\d))|9[0-35-9]\d{2}|66\d{2})\d{6}$/
console.log(mobileRegex.test('18379867725'))
console.log(mobileRegex.test('123456789101'))
console.log(mobileRegex.test('+8618379867725'))
console.log(mobileRegex.test('8618379867725'))
When we encounter a very long and complex regular, what is a good way for us to understand it?
Visual tools can help us disassemble regular.
So mobileRegex can be divided into the following parts
- (?:\+?86)?: Mobile phone prefix, with?: Identify non reference groups
- 1: All mobile phone numbers start with 1
- (a|b|c |...): various situations of 2 ~ 5 bits are explained one by one through multiple branches |
- \d{6}: 6 arbitrary digits
After disassembly, you will find that it is not complicated, but in the third part, because there are too many possibilities, many multi-choice branches are used to explain. As long as you clarify the mobile phone number rules, it is not difficult to understand the rules in each group.

19. English words with spaces before and after
A character string composed of alphabetic Chinese characters. Use regular to add spaces before and after English words.
For example, you say come and go = > you say come and go
Analytical process
Here, you only need to understand the concept of \ b position in regular, which means the boundary of words. Specifically, there are three rules
-
\Position between W and \ w
-
^Location between and \ w
-
\Position between w and $
So:
The first word, you, conforms to rule 2
The second word come s in accordance with rule 1
The third word complies with go and rule 3
const wordRegex = /\b/g
console.log('you Yes come,Go yes go'.replace(/\b/g, ' ')) // `you say come and go`
20. Reverse case of string
Reverse the case of the string, for example, hello world = > Hello world
Analytical process
It is easy to think of this problem that the case is determined through ASCII code, and then converted to the corresponding value. However, since it is a regular summary, we will try to complete it through regular.
How to determine whether a character is capitalized without ASCII code? In fact, as long as it becomes a capital character, and then compared with the meta character, it means that the far character is also capital. such as
For Strings x = `A`
'A'.toUpperCase()Get y yes A
y === x
that x Just uppercase characters
So the title can be written like this
const stringCaseReverseReg = /[a-z]/ig
const string = 'hello WORLD'
const string2 = string.replace(stringCaseReverseReg, (char) => {
const upperStr = char.toUpperCase()
// Uppercase to lowercase, lowercase to uppercase
return upperStr === char ? char.toLowerCase() : upperStr
})
console.log(string2) // HELLO world
21. Folder and file path under Windows
The following paths are required to match
-
C:\Documents\Newsletters\Summer2018.pdf
-
C:\Documents\Newsletters\
-
C:\Documents\Newsletters
-
C:\
Regular results
const windowsPathRegex = /^[a-zA-Z]:\\(?:[^\\:*<>|"?\r\n/]+\\?)*(?:(?:[^\\:*<>|"?\r\n/]+)\.\w+)?$/;
Analytical process
The file rules under windows are probably composed of these parts
Disk symbol: \ folder \ folder \ file
-
Disk symbol: only in English [a-zA_Z]:\
-
Folder name: does not contain some special symbols and can appear any time. The last \ can not ([^ \ \: * < > | "? \ R \ n /] + \ \?)*
-
File name: ([^ \ \: * < > | "? \ R \ n /] +) \. \ W +, but the file can be empty
const windowsPathRegex = /^[a-zA-Z]:\\(?:[^\\:*<>|"?\r\n/]+\\?)*(?:(?:[^\\:*<>|"?\r\n/]+)\.\w+)?$/;
console.log( windowsPathRegex.test("C:\\Documents\\Newsletters\\Summer2018.pdf") ); // true
console.log( windowsPathRegex.test("C:\\Documents\Newsletters\\") ); // true
console.log( windowsPathRegex.test("C:\\Documents\Newsletters") ); // true
console.log( windowsPathRegex.test("C:\\") ); // true

22. Matching id (often used by write crawlers to get html)
Require id box in < div id = "box" > Hello World < / div >
Regular results
const matchIdRegexp = /id="([^"]*)"/
console.log(`
<div id="box">
hello world
</div>
`.match(matchIdRegexp)[1])
Analytical process
In the process of writing a crawler, you often need to match the dom elements of the specified conditions, and then do the corresponding operation. So how to get the box
<div id="box"> hello world </div>
I believe you first think of this regular id = "(. *)"
const matchIdRegexp = /id="(.*)"/
console.log(`
<div id="box">
hello world
</div>
`.match(matchIdRegexp)[1])
However, id = "(. *)" can easily lead to backtracking, which takes more matching time. Is there any optimization method?
Yes, just put it Replace it with [^ "]. When" is encountered, the regular rule will think that the matching is over, and backtracking will not occur.
const matchIdRegexp = /id="([^"]*)"/
console.log(`
<div id="box">
hello world
</div>
`.match(matchIdRegexp)[1])
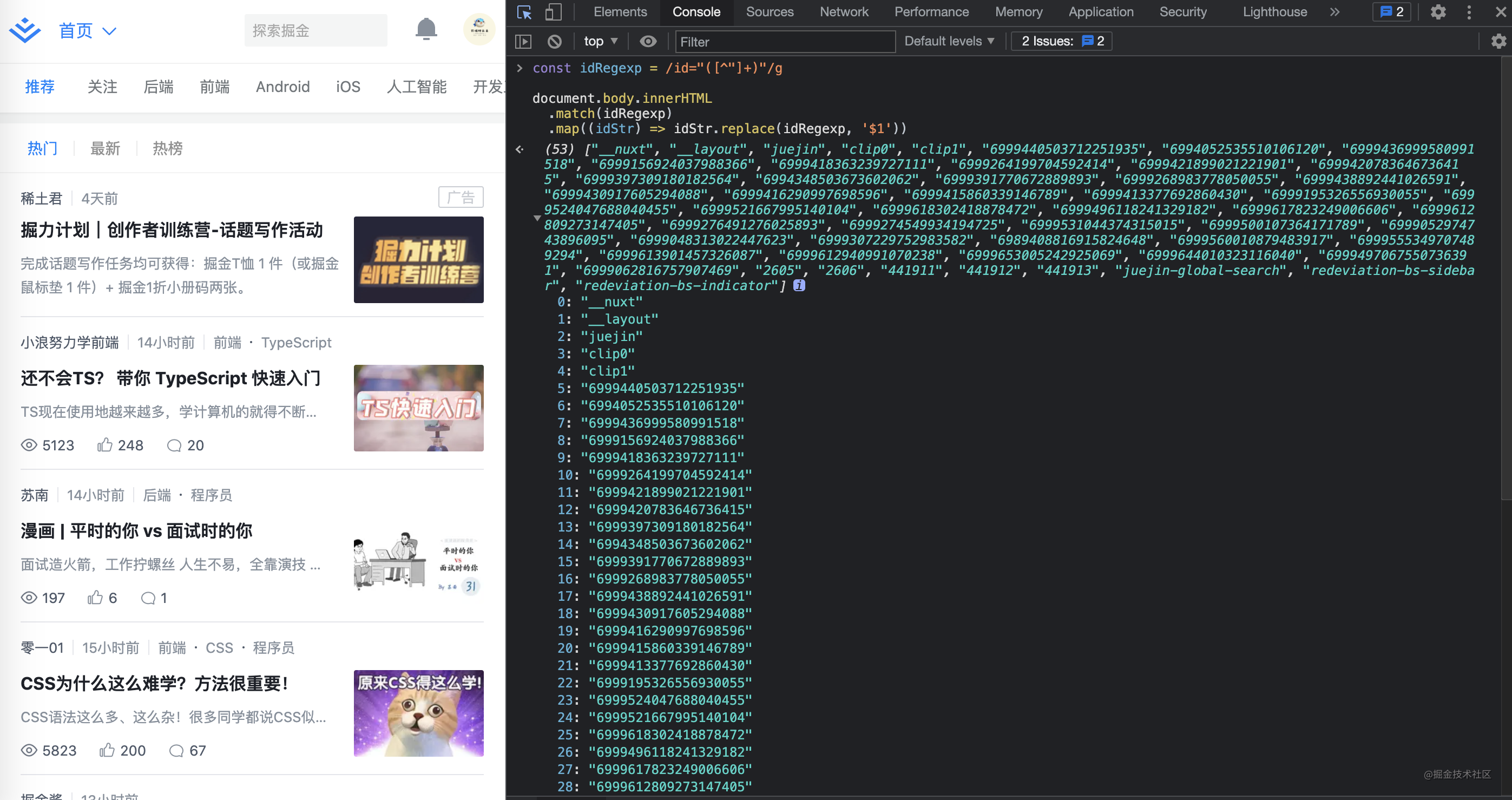
23. Matching id extension (get all IDs of nuggets homepage html)
Let's see if we can get IDS in batch
Regular results
const idRegexp = /id="([^"]+)"/g document.body.innerHTML .match(idRegexp) .map((idStr) => idStr.replace(idRegexp, '$1'))
24. Greater than or equal to 0 and less than or equal to 150. 5 decimal places are supported, such as 145.5, which is used to judge the score of the test paper
Regular results
const pointRegex = /^(?:[1-9]?\d|1[0-4]\d)$/

Analysis process
We can divide the problem into two parts
-
Integer part
- Bit integer
- Ten digit integer
- A hundredth integer but less than 150
-
Decimal part: can only be. 5 or none
Try to write the integer part first
// 1. How to represent single digits/ \d/ // 2. How to represent ten digits/ [1-9]\d/ // 3. How to express one digit and ten digit together/ [1-9]?\d/ // 4. What about the hundredths less than 150/ 1[0-4]\d/ // So combined, the integer part can be represented by the following regular expression const pointRegex = /^(?:[1-9]?\d|1[0-4]\d)$/ console.log(pointRegex.test(0)) // true console.log(pointRegex.test(10)) // true console.log(pointRegex.test(100)) // true console.log(pointRegex.test(110.5)) // false console.log(pointRegex.test(150)) // false
Add the decimal part
// The decimal part is relatively simple / (?: \. 5)? /, So the whole is const pointRegex = /^(?:[1-9]?\d|1[0-4]\d)(?:\.5)?$/ console.log(pointRegex.test(0)) console.log(pointRegex.test(10)) console.log(pointRegex.test(100)) console.log(pointRegex.test(110.5)) console.log(pointRegex.test(150))
25. Judge the version number
The version number must be in X.Y.Z format, where XYZ is at least one digit
Regular results
// x.y.z
const versionRegexp = /^(?:\d+\.){2}\d+$/
console.log(versionRegexp.test('1.1.1'))
console.log(versionRegexp.test('1.000.1'))
console.log(versionRegexp.test('1.000.1.1'))
See you later
There is still a long way to go to make good use of regularization. I hope these parsing will be helpful to you! If there are any errors in the article, or you have a better regular writing method, welcome to put forward oh.