Introduction to concurrent programming
java is a development language that supports multithreading. Multithreading can process multiple different tasks simultaneously on a machine containing multiple CPU cores, optimize the utilization of resources and improve the efficiency of programs. In some occasions with high performance requirements, multithreading is an important aspect of java program tuning.
Java Concurrent Programming mainly involves the following parts:
-
Three elements of concurrent programming
Atomicity: that is, an indivisible particle. In Java, atomicity means that one or more operations either all succeed or all fail.
Order: the sequence of program execution is in the order of code. (the processor may reorder instructions)
Visibility: when multiple threads access the same variable, if one thread modifies it, other threads can immediately obtain the latest value. -
Five states of threads
Creation state: when a thread is created with the new operator
Ready state: call the start method. The thread in ready state does not necessarily execute the run method immediately, and it also needs to wait for CPU scheduling
Running status: the CPU starts scheduling threads and starts executing the run method
Blocking state: the thread enters blocking state for some reasons during execution, such as calling sleep method, trying to get a lock, etc
Dead status: the run method has finished executing or encountered an exception during execution -
Pessimistic lock and optimistic lock
Pessimistic lock: each operation will lock, which will cause thread blocking.
Optimistic lock: an operation is completed without locking each time, assuming that there is no conflict. If the operation fails due to the conflict, it will be retried until it succeeds, without causing thread blocking. -
Collaboration between threads
Cooperation among threads includes wait/notify/notifyAll, etc -
synchronized keyword
synchronized is a keyword in Java. It is a kind of synchronous lock. It modifies the following objects:
Modify a code block: the modified code block is called a synchronization statement block. Its scope of action is the code enclosed in braces {}, and the object of action is the object calling the code block
Modify a method: the modified method is called a synchronous method. Its scope of action is the whole method, and the object of action is the object calling the method
Modify a static method: its scope of action is the whole static method, and the object of action is all objects of this class
Modify a class: its scope of action is the part enclosed in parentheses after synchronized, and the main object is all objects of this class. -
CAS
The full name of CAS is Compare And Swap, that is, compare and replace. It is a technology to realize concurrent application. The operation consists of three operands - memory location (V), expected original value (A), and new value (B). If the value of the memory location matches the expected original value, the processor automatically updates the location value to the new value. Otherwise, the processor does nothing.
CAS has three major problems: ABA problem, long cycle time, high overhead, and atomic operation that can only guarantee one shared variable. -
Thread pool if we create a thread when using threads, although it is simple, there are great problems. If there are a large number of concurrent threads and each thread executes a task for a short time, the efficiency of the system will be greatly reduced because it takes time to create and destroy threads frequently. Thread pool reuse can greatly reduce the performance loss caused by frequent thread creation and destruction.
Common multithreaded interview questions are:
- What are the categories of reordering? How to avoid?
- What are the advantages of the new Lock interface in Java over synchronized blocks? If you realize one
A high-performance cache that supports concurrent reads and single writes. How do you ensure data integrity. - How to implement a blocking queue in Java.
- Write a deadlock code. Talk about how you solve deadlocks in Java.
- What is the difference between volatile variables and atomic variables?
- Why use thread pools?
- Implement the difference between Runnable interface and Callable interface
- What is the difference between executing the execute() method and submitting () method?
- What is the implementation principle of AQS?
- Which classes in the java API use AQS?
- ...
Part I: multithreading & concurrent design principle
1 multithreading review
1.1 Thread and Runnable
1.1. 1 threads in Java
There are two ways to create an execution thread:
- Extend the Thread class.
- Implement the Runnable interface.
Create a new Thread by extending the Thread class:
public class MyThread extends Thread {
@Override
public void run() {
while (true) {
System.out.println(Thread.currentThread().getName() + " It's running");
try {
Thread.sleep(800);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Main {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}
}
Create a thread by implementing the Runnable interface:
public class MyRunnable implements Runnable {
@Override
public void run() {
while (true) {
System.out.println(Thread.currentThread().getName() + " It's running");
try {
Thread.sleep(800);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.start();
}
}
1.1. 2 threads in Java: features and states
-
All Java programs, whether concurrent or not, have a Thread object called the main Thread. When the program is executed, the Java virtual machine (JVM) creates a new Thread and executes the main() method in the Thread. This is the only Thread in a non concurrent application and the first Thread in a concurrent application.
-
Threads in Java share all resources in the application, including memory and open files, and share information quickly and easily. However, synchronization must be used to avoid data contention.
-
All threads in Java have a priority, and the integer value is between thread MIN_ Priority (1) and thread MAX_ Priority (10), the default priority is thread NORM_ PRIORITY(5). Although the priority is set, the execution order of threads is not guaranteed. Generally, higher priority threads will execute before lower priority processes.
-
In Java, you can create two threads:
The difference between daemon threads and non daemon threads is how they affect the end of the programWhen the Java program ends the execution process:
1) The program executes the exit() method of the Runtime class, and the user has the right to execute the method.
2) All non daemon threads of the application have ended execution, regardless of whether there are running daemon threads.Daemon threads are typically used in applications that act as garbage collectors or cache managers to perform ancillary tasks. Before the thread start is called, the isDaemon() method is used to check whether the thread is a daemon thread, or the setDaemon() method can be used to establish a thread as a daemon thread.
-
Thread. The state of the thread defined in the States class is as follows
New: the thread object has been created, but execution has not yet started.Runnable: the thread object is running in the Java virtual machine.
Blocked: thread object is waiting to be locked.
Waiting: the thread object is waiting for the action of another thread.
TIME_ Waiting: the thread object is waiting for the operation of another thread, but there is a time limit.
Terminated: the thread object has completed execution.
The getState() method obtains the state of the Thread object and can directly change the state of the Thread.
A thread can only be in one state at a given time. These states are used by the JVM and cannot be mapped to the thread state of the operating system.
Thread state source code: (enumeration)

1.1.3 Thread class and Runnable interface
The Runnable interface defines only one method: the run() method. This is the main method for each thread. When the start() method is executed to start a new thread, it calls the run() method.
Other common methods of Thread class:
- Method to get and set Thread object information.
getId(): returns the identifier of the Thread object. The identifier is a positive integer allocated when the money process is created. It is unique and unchangeable throughout the life cycle of a Thread.
getName()/setName(): allows you to get or set the name of the Thread object. This name is a String object, which can also be established in the constructor of the Thread class.
getPriority()/setPriority(): you can use these two methods to get or set the priority of the Thread object.
isDaemon()/setDaemon(): these two methods allow you to obtain or create daemon conditions for Thread objects.
getState(): this method returns the state of the Thread object. - interrupt(): interrupt the target thread, send an interrupt signal to the target thread, and the thread is marked with an interrupt flag.
- interrupted(): judge whether the target thread is interrupted, but the interrupt flag of the thread will be cleared.
- isinterrupted(): judge whether the target thread is interrupted, and the interrupt flag will not be cleared.
- sleep(long ms): this method pauses the execution of the thread for MS.
- join(): pauses the execution of the Thread until the execution of the Thread calling the method ends. You can use this method to wait for another Thread object to end.
- setUncaughtExceptionHandler(): this method is used to establish a controller for an uncalibrated exception when an uncalibrated exception occurs during thread execution.
- Currentthread(): the static method of the Thread class, which returns the Thread object that actually executes the code.
join() example
public class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("MyThread thread :" + i);
}
}
}
public class Main {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
myThread.start();
myThread.join();
System.out.println("main thread - Execution complete");
}
}
1.1.4 Callable
The Callable interface is very similar to the Runnable interface. The main features of the Callable interface are as follows.
- Interface. There are simple type parameters corresponding to the return type of the call() method.
- The call() method is declared. When the actuator runs a task, the method is executed by the actuator. It must return an object of the type specified in the declaration.
- The call() method can throw any kind of verification exception. You can implement your own executor and overload the afterExecute() method to handle these exceptions.
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
Thread.sleep(5000);
return "hello world call() invoked!";
}
}
public class Main {
public static void main(String[] args) throws ExecutionException, InterruptedException {
MyCallable myCallable = new MyCallable();
// Set the Callable object. Generics represent the return type of Callable
FutureTask<String> futureTask = new FutureTask<String>(myCallable);
// Start processing thread
new Thread(futureTask).start();
// Synchronize the results of waiting for the thread to run
String result = futureTask.get();
// The results were obtained after 5s
System.out.println(result);
}
}
public class Main2 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 5, 1, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10)){
@Override
protected void afterExecute(Runnable r, Throwable t) {
//If there is an error during the execution of the call method, it can be processed here
super.afterExecute(r, t);
}
};
Future<String> future = executor.submit(new MyCallable());
String s = future.get();
System.out.println(s);
executor.shutdown();
}
}
1.2 synchronized keyword
1.2. 1 object of lock
synchronized keyword "lock an object", example code:
public Class MyClass {
public void synchronized method1() {
// ...
}
public static void synchronized method2() {
// ...
}
}
//equivalence
public class MyClass {
public void method1() {
synchronized(this) { // ...
}
}
public static void method2() {
synchronized(MyClass.class) {
// ...
}
}
}
Lock the instance method on the object myClass; The lock of static method is added to myClass Class.
1.2. 2 essence of lock
If a resource needs to be accessed by multiple threads at the same time, the resource needs to be locked. After locking, it can ensure that only one thread can access the resource at the same time. A resource can be a variable, an object, a file, and so on.
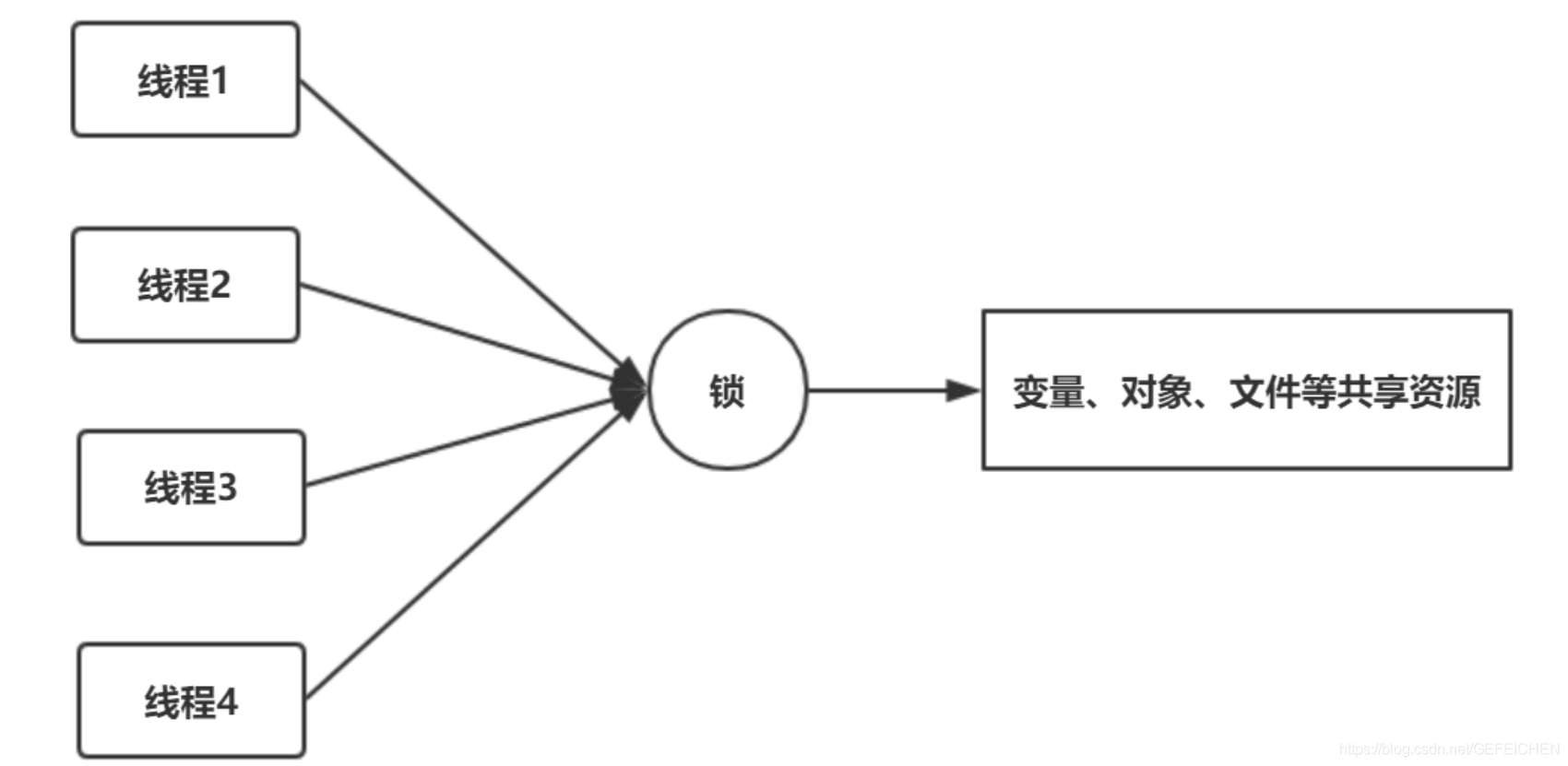
A lock is an "object" that functions as follows:
- There must be a flag bit (state variable) inside the object to record whether it is occupied by a thread. The simplest case is that the state has two values: 0 and 1. 0 means that no thread occupies the lock, and 1 means that a thread occupies the lock.
- If the object is occupied by a thread, record the thread ID of the thread.
- This object maintains a thread id list to record all other blocked threads waiting to get the lock. After the current thread releases the lock, take a thread from the thread id list to wake up.
The shared resource to be accessed is also an object, such as the previous object myClass. The two objects can be combined into one object. The code becomes synchronized(this) {...}. The shared resource to be accessed is object a, which is locked. Of course, you can also create another object, and the code becomes synchronized(obj1) {...}. At this time, the shared resource accessed is object a, and the lock is applied to the newly created object obj1.
Resources and locks are combined into one, so that in Java, the synchronized keyword can be added to the members of any object. This means that this object not only shares resources, but also has the function of "lock"!
1.2. 3 implementation principle
In the object header, there is a piece of data called Mark Word. On 64 bit machines, Mark Word is 8 bytes (64 bits). There are two important fields in the 64 bits: lock flag bit and thread ID occupying the lock. Because of different versions of JVM implementation, the data structure of object header will be different.
1.3 wait and notify
1.3. 1 producer consumer model
Producer consumer model is a common multi-threaded programming model, as shown in the following figure:
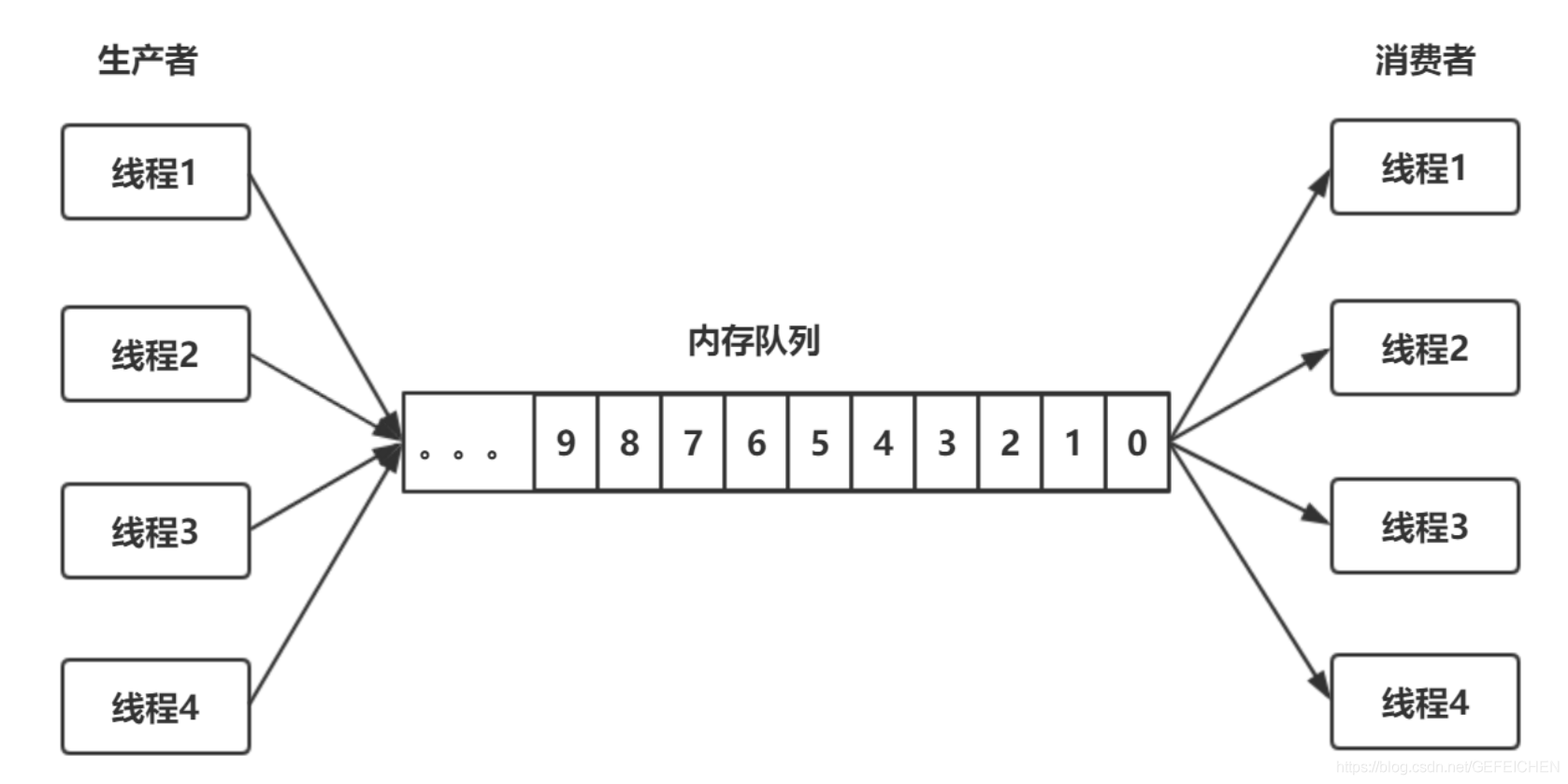
A memory queue, and multiple producer threads put data into the memory queue; Multiple consumer threads fetch data from the memory queue. To implement such a programming model, several things need to be done:
- The memory queue itself needs to be locked to achieve thread safety.
- Blocking: when the memory queue is full and the producer cannot put it in, it will be blocked; When the memory queue is empty, the consumer has nothing to do and will be blocked.
- Two way notification: after the consumer is blocked, the producer puts in new data and wants to notify() the consumer; After the producer is blocked, the consumer consumes the data and wants to notify() the producer.
The first thing must be done, and the second and third things do not have to be done. For example, a simple method can be adopted. After the producer can't put it in, sleep for hundreds of milliseconds and try again. After the consumer can't get the data, sleep for hundreds of milliseconds and try again. But this method is inefficient and not real-time. Therefore, we only discuss how to block and how to notify.
1. How to block?
Method 1: the thread blocks itself, that is, the producer and consumer threads call wait() and notify() respectively.
Method 2: use a blocking queue. When the data cannot be retrieved or put in, the in / out queue function itself is blocked.
2. How to notify each other?
Method 1: wait() and notify() mechanisms
Method 2: Condition mechanism
Case of single producer and single consumer thread:
public class Main {
public static void main(String[] args) {
MyQueue myQueue = new MyQueue();
ProducerThread producerThread = new ProducerThread(myQueue);
ConsumerThread consumerThread = new ConsumerThread(myQueue);
producerThread.start();
consumerThread.start();
}
}
public class MyQueue {
private String[] data = new String[10];
private int getIndex = 0;
private int putIndex = 0;
private int size = 0;
public synchronized void put(String element) {
if (size == data.length) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
data[putIndex] = element;
++putIndex;
if (putIndex == data.length) putIndex = 0;
++size;
notify();
}
public synchronized String get() {
if (size == 0) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
String result = data[getIndex];
++getIndex;
if (getIndex == data.length) getIndex = 0;
--size;
notify();
return result;
}
}
public class ProducerThread extends Thread {
private final MyQueue myQueue;
private final Random random = new Random();
private int index = 0;
public ProducerThread(MyQueue myQueue) {
this.myQueue = myQueue;
}
@Override
public void run() {
while (true) {
String tmp = "ele-" + index;
myQueue.put(tmp);
System.out.println("Add element:" + tmp);
index++;
try {
Thread.sleep(random.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class ConsumerThread extends Thread {
private final MyQueue myQueue;
private final Random random = new Random();
public ConsumerThread(MyQueue myQueue) {
this.myQueue = myQueue;
}
@Override
public void run() {
while (true) {
String s = myQueue.get();
System.out.println("\t\t Consumption elements:" + s);
try {
Thread.sleep(random.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Multiple producers and multiple consumers:
public class Main2 {
public static void main(String[] args) {
MyQueue2 myQueue = new MyQueue2();
for (int i = 0; i < 3; i++) {
new ConsumerThread(myQueue).start();
}
for (int i = 0; i < 5; i++) {
new ProducerThread(myQueue).start();
}
}
}
public class MyQueue2 extends MyQueue {
private String[] data = new String[10];
private int getIndex = 0;
private int putIndex = 0;
private int size = 0;
@Override
public synchronized void put(String element) {
if (size == data.length) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
put(element);
} else {
put0(element);
notify();
}
}
private void put0(String element) {
data[putIndex] = element;
++putIndex;
if (putIndex == data.length) putIndex = 0;
++size;
}
@Override
public synchronized String get() {
if (size == 0) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
return get();
} else {
String result = get0();
notify();
return result;
}
}
private String get0() {
String result = data[getIndex];
++getIndex;
if (getIndex == data.length) getIndex = 0;
--size;
return result;
}
}
1.3. 2 why must it be used with synchronized
In Java, wait() and notify() are the member functions of Object and the basis of the foundation. Why does Java put wait() and notify() in such a basic class instead of as member functions of Thread or other classes?
First, why do wait() and notify() have to be used with synchronized? See the following code:
class MyClass1 {
private Object obj1 = new Object();
public void method1() {
synchronized(obj1) {
//...
obj1.wait();
//...
}
}
public void method2() {
synchronized(obj1) {
//...
obj1.notify();
//...
}
}
}
public class MyClass1 {
public void synchronized method1() {
//...
this.wait();
//...
}
public void synchronized method2() {
//...
this.notify();
//...
}
}
Then, open two threads, thread A calls method1(), and thread B calls method2(). The answer is obvious: two threads need to communicate. For the same object, one thread calls the wait() of the object, and the other thread calls the notify() of the object. The object itself needs to be synchronized! Therefore, before calling wait () and notify (), synchronize the object through the synchronized keyword, that is, lock the object.
The synchronized keyword can be added to the instance method of any Object, and any Object can become a lock. Therefore, wait() and notify() can only be placed in Object.
1.3. 3 why do I have to release the lock when I wait()
When thread A enters synchronized(obj1), it locks obj1. At this time, call wait() to enter the blocking state and cannot exit the synchronized code block; Then, thread B can never enter the synchronized(obj1) synchronization block, and will never have A chance to call notify() to deadlock.
This involves a key problem: inside the wait(), the lock obj1 will be released first, and then it will enter the blocking state. Then, it will be awakened by another thread with notify() to regain the lock! Secondly, after the wait () call is completed, execute the following business logic code, and then exit the synchronized synchronization block to release the lock again.
The pseudo code inside wait() is as follows:
wait() {
// Release lock
// Blocking, waiting to be notified by other threads
// Reacquire lock
}
In this way, deadlock can be avoided.
1.3. 4. Problems with wait() and notify()
According to the above producer consumer model, the pseudo code is roughly as follows:
public void enqueue() {
synchronized(queue) {
while (queue.full()) {
queue.wait();
}
//... Data entry
queue.notify(); // Notify the consumer that there is data in the queue.
}
}
public void dequeue() {
synchronized(queue) {
while (queue.empty()) {
queue.wait();
}
// Data out of queue
queue.notify(); // Notify the producer that there is space in the queue and you can continue to put data.
}
}
While informing consumers, producers also inform other producers; Consumers not only inform producers, but also inform other consumers. The reason is that the objects used by wait() and notify() are the same as those used by synchronized. There can only be one object, and the two conditions of empty queue and full queue cannot be distinguished. This is the problem that Condition wants to solve.
1.4 InterruptedException and interrupt() methods
1.4.1 Interrupted exception
Under what circumstances will an Interrupted exception be thrown
Assuming that no blocking function is called in the while loop, it is the usual arithmetic operation or printing a line of log, as shown below.
public class MyThread extends Thread {
@Override
public void run() {
while (true) {
boolean interrupted = isInterrupted();
System.out.println("Interrupt flag:" + interrupted);
}
}
}
At this time, a thread. is called in the main thread.interrupt(), will the thread throw an exception? can't
public class Main42 {
public static void main(String[] args) throws InterruptedException {
MyThread42 myThread = new MyThread42();
myThread.start();
Thread.sleep(10);
myThread.interrupt();
Thread.sleep(100);
System.exit(0);
}
}
Only those functions that declare that they will throw InterruptedException will throw exceptions, that is, the following commonly used functions
public static native void sleep(long millis) throws InterruptedException {...}
public final void wait() throws InterruptedException {...}
public final void join() throws InterruptedException {...}
1.4. 2 lightweight blocking and heavyweight blocking
Blocking that can be interrupted is called lightweight blocking, and the corresponding thread state is waiting or TIMED_WAITING; Blocking that cannot be interrupted, such as synchronized, is called heavyweight blocking, and the corresponding state is BLOCKED. As shown in the figure: after calling different methods, the state migration process of a thread.

The initial thread is in the NEW state. After calling start() to start execution, it enters the RUNNING or READY state. If no blocking function is called, the thread will only switch between RUNNING and READY, that is, the time slice scheduling of the system. The switching between these two states is completed by the operating system, unless the yield() function is called manually to give up the occupation of CPU.
Once any blocking function in the graph is called, the thread will enter WAITING or timed_ The difference between the WAITING state and the WAITING state is that the former is BLOCKED indefinitely, while the latter passes in a time parameter to block for a limited time. If the synchronized keyword or synchronized block is used, it will enter the BLOCKED state.
A less common blocking / wake-up function, locksupport park()/unpark(). This is very important for functions. The implementation of Lock in Concurrent package depends on this pair of operation primitives.
So thread The precise meaning of interrupted () is "wake up lightweight blocking", rather than literally "interrupt a thread".
thread.isInterrupted() and thread The difference between interrupted()
Because thread Interrupted () is equivalent to sending a wake-up signal to the thread, so if the thread happens to be WAITING or timed at this time_ In the WAITING state, an InterruptedException is thrown and the thread is awakened. If the thread is not blocked at this time, the thread will do nothing. But in the follow-up, the thread can judge whether it has received the interrupt signal from other threads, and then do some corresponding processing.
These two methods are used by threads to determine whether they have received an interrupt signal. The former is an instance method and the latter is a static method. The difference between the two is that the former only reads the interrupt state and does not modify the state; The latter not only reads the interrupt status, but also resets the interrupt flag bit.
public class Main {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
myThread.start();
Thread.sleep(10);
myThread.interrupt();
Thread.sleep(7);
System.out.println("main Interrupt status check-1:" + myThread.isInterrupted());
System.out.println("main Interrupt status check-2:" + myThread.isInterrupted());
}
}
public class MyThread extends Thread {
@Override
public void run() {
int i = 0;
while (true) {
boolean interrupted = isInterrupted();
System.out.println("Interrupt flag:" + interrupted);
++i;
if (i > 200) {
// Check and reset the interrupt flag.
boolean interrupted1 = Thread.interrupted();
System.out.println("Reset interrupt status:" + interrupted1);
interrupted1 = Thread.interrupted();
System.out.println("Reset interrupt status:" + interrupted1);
interrupted = isInterrupted();
System.out.println("Interrupt flag:" + interrupted); break;
}
}
}
}
1.5 graceful shutdown of threads
1.5.1 stop and destroy functions
A thread is "a piece of running code", a running method. Can the thread running to half be forcibly killed? No.
In Java, there are methods such as stop(), destroy (), but these methods are officially not recommended. The reason is very simple. If the thread is forcibly killed, the resources used in the thread, such as file descriptors and network connections, cannot be closed normally.
Therefore, once a thread is running, do not forcibly close it. The reasonable way is to let it run (that is, after the method is executed), release all resources cleanly, and then exit. If it is a thread running in a loop, it needs to use the communication mechanism between threads to let the main thread notify it to quit.
1.5. 2 daemon thread
Comparison between daemon thread and non daemon thread:
public class Main {
public static void main(String[] args) {
MyDaemonThread myDaemonThread = new MyDaemonThread();
// Set to daemon thread
myDaemonThread.setDaemon(true);
myDaemonThread.start();
// Start the non daemon thread. When the non daemon thread ends, the JVM process ends regardless of whether the daemon thread ends or not.
new MyThread().start();
}
}
public class MyDaemonThread extends Thread {
@Override
public void run() {
while (true) {
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("wrong Daemon thread ");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
For the above program, in thread Start () is preceded by a line of code thread setDaemon(true). When the main() function exits, the thread will exit and the whole process will exit.
When multiple threads are opened in a JVM process, these threads are divided into two categories: daemon threads and non daemon threads. By default, all are non daemon threads.
There is a rule in Java: when all non daemon threads exit, the whole JVM process will exit. This means that the daemon thread "does not count". The daemon thread does not affect the exit of the entire JVM process.
For example, garbage collection threads are daemon threads. They work silently in the background. When all foreground threads (non daemon threads) of the developer exit, the whole JVM process exits.
1.5. 3 set the off flag bit
In development, the thread running in a loop is generally stopped by setting the flag bit.
public class MyThread extends Thread{
private boolean running = true;
@Override
public void run() {
while (running) {
System.out.println("Thread running...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void stopRunning() {
this.running = false;
}
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
myThread.start();
Thread.sleep(5000);
myThread.stopRunning();
myThread.join();
}
}
But there is a problem with the above code: if MyThread blocks somewhere in the while loop, for example, it calls object Wait() function, then it may never have a chance to execute while (! Stopped) code again, and it will never be able to exit the loop.
In this case, the InterruptedException() and interrupt() functions are used.
2 core concepts of concurrency
2.1 concurrency and parallelism
Using a single core to execute multiple tasks on a single processor is concurrent. In this case, the operating system's task scheduler will quickly switch from one task to another, so it seems that all tasks are running at the same time.
Running multiple tasks simultaneously on different computers, processors or processor cores at the same time is the so-called "parallel".
Another definition of concurrency is that running multiple tasks (different tasks) on the system at the same time is concurrency. Another definition of parallelism is that different instances of the same task running on different parts of a data set are parallel.
The last definition of parallelism is that multiple tasks run simultaneously in the system. The last definition of concurrency is a way to explain the different technologies and mechanisms by which programmers synchronize tasks with their access to shared resources.
The two concepts are very similar, and this similarity is increasing with the development of multi-core processors.
2.2 synchronization
In concurrency, we can define synchronization as a mechanism that coordinates two or more tasks to achieve the desired results. There are two ways to synchronize:
- Control synchronization: for example, when the start of one task depends on the end of another task, the second task cannot start before the completion of the first task.
- Data access synchronization: when two or more tasks access a shared variable, only one task can access the variable at any time.
A concept closely related to synchronization is critical section. A critical segment is a piece of code that can be executed by only one task at any given time because it can access shared resources. Mutual exclusion is a mechanism to ensure this requirement, and can be implemented in different ways.
Synchronization can help you avoid some errors while completing concurrent tasks, but it also introduces some overhead to your algorithm. You have to calculate the number of tasks very carefully. These tasks can be executed independently without mutual communication in parallel algorithms. This involves the granularity of concurrent algorithms. If the algorithm has coarse granularity (large tasks with low mutual communication), the overhead of synchronization will be low. However, you may not use all the cores of the system. If the algorithm has fine granularity (small tasks with high mutual communication), the overhead of synchronization will be high, and the throughput of the algorithm may not be very good.
There are different synchronization mechanisms in concurrent systems. From a theoretical point of view, the most popular mechanisms are as follows:
- Semaphore: a mechanism used to control access to one or more unit resources. It has a variable for storing the amount of available resources, and can be managed by two atomic operations. Mutex (short form of mutex: mutual exclusion) is a special type of semaphore. It can only take two values (i.e. resource free and resource busy), and only the process that sets mutex to busy can release it. Mutex can help you avoid race conditions by protecting critical segments.
- Monitor: a mechanism for mutual exclusion on shared resources. It has a mutex, a condition variable and two operations (wait condition and notification condition). Once you have notified the condition, only one of the tasks waiting for it will continue.
If all users sharing data are protected by the synchronization mechanism, the code (or method, object) is thread safe. The non blocking CAS (compare and swap) primitive of data is immutable, so that the code can be used in concurrent applications without any problems.
2.3 immutable objects
Is a very special object. After its initialization, its visual state (its attribute value) cannot be modified. If you want to modify an immutable object, you must create a new object.
The main advantage is that it is thread safe. You can use it in concurrent applications without any problems.
An example is the String class in java. When you assign a new value to a String object, a new String object will be created.
2.4 atomic operations and atomic variables
Compared with other tasks of the application, atomic operation is an operation that occurs in an instant. In concurrent applications, atomic operations can be implemented through a critical segment in order to adopt the synchronization mechanism for the whole operation.
Atomic variable is a variable whose value is set and obtained through atomic operation. You can use some synchronization mechanism to implement an atomic variable, or you can use CAS to implement an atomic variable in a lock free manner, which does not require any synchronization mechanism.
2.5 shared memory and messaging
Tasks can communicate with each other in two different ways.
The first method is shared memory, which is usually used to run multiple tasks on the same computer. Tasks use the same memory area when reading and writing values. In order to avoid problems, access to the shared memory must be completed within a critical segment protected by the synchronization mechanism.
Another synchronization mechanism is message passing, which is usually used to run multitasking on different computers. When a task needs to communicate with another task, it sends a message that follows a predefined protocol. If the sender remains blocked and waits for a response, the communication is synchronous; If the sender continues to execute its own process after sending the message, the communication is asynchronous.
3. Concurrent problems
3.1 data competition
If two or more tasks write to a shared variable outside the critical segment, that is, no synchronization mechanism is used, the application may have data contention (also known as contention condition).
In these cases, the end result of the application may depend on the order in which the tasks are executed.
public class ConcurrentDemo {
private float myFloat;
public void modify(float difference) {
float value = this.myFloat;
this.myFloat = value + difference;
}
public static void main(String[] args) {
}
}
Suppose two different tasks execute the same modify method. Because the execution order of the statements in the task is different, the final result will be different.
The modify method is not atomic, and the ConcurrentDemo is not thread safe.
3.2 deadlock
When two (or more) tasks are waiting for a shared resource that must be released by another thread, and the thread is waiting for another shared resource that must be released by one of the preceding tasks, a deadlock occurs in the concurrent application. This situation occurs when the following four conditions occur simultaneously in the system. We call it the Coffman condition.
- Mutual exclusion: the information and resources involved in the deadlock must not be shared. Only one task at a time can use this resource.
- Occupy and wait condition: when a task occupies a mutually exclusive resource, it requests another mutually exclusive resource. When it is waiting, it does not release any resources.
- Inalienable: resources can only be released by those who hold them.
- Cyclic waiting: Task 1 is waiting for the resources occupied by task 2, while task 2 is waiting for the resources occupied by task 3, and so on. Finally, task n is waiting for the resources occupied by task 1, so cyclic waiting occurs.
There are some mechanisms to avoid deadlocks.
- Ignore: This is the most commonly used mechanism. You can assume that your system will never deadlock, and if a deadlock occurs, the result is that you can stop the application and re execute it
- Detection: there is a special task in the system to analyze the system status, which can detect whether a deadlock has occurred. If it detects a deadlock, some measures can be taken to fix the problem, such as ending a task or forcibly releasing a resource.
- Prevention: if you want to prevent system deadlock, you must prevent one or more of the coffeman conditions.
- Avoidance: if you can get the information about the resources used by a task before it is executed, the deadlock can be avoided. When a task is to be executed, you can analyze the idle resources in the system and the resources required by the task, so as to judge whether the task can be executed.
3.3 movable lock
If there are two tasks in the system that always change their state due to each other's behavior, a livelock occurs. The end result is that they fall into a state change cycle and cannot continue down.
For example, there are two tasks: Task 1 and task 2. Both of them need two resources: resource 1 and resource 2. Suppose task 1 adds a lock to resource 1 and task 2 adds a lock to resource 2. When they cannot access the required resources, they release their resources and restart the cycle. This situation can continue indefinitely, so neither task will end its execution process.
3.4 insufficient resources
When a task cannot obtain the resources needed to maintain its continuous execution in the system, there will be insufficient resources. When multiple tasks are waiting for a resource and the resource is released, the system needs to select the next task that can use the resource. If there is no well-designed algorithm in your system, some threads in the system are likely to wait a long time to obtain the resource.
To solve this problem, we must ensure the principle of fairness. All tasks waiting for a resource must occupy the resource within a given time. One of the options is to implement an algorithm. When selecting the next task that will occupy a resource, the time factor of the task waiting for the resource will be considered. However, implementing lock fairness requires additional overhead, which may reduce the throughput of the program.
3.5 priority reversal
Priority reversal occurs when a low priority task holds the resources required by a high priority task. In this way, low priority tasks will be executed before high priority tasks.
4 JMM memory model
4.1 JMM and happy before
4.1. 1 Why is there a memory visibility problem
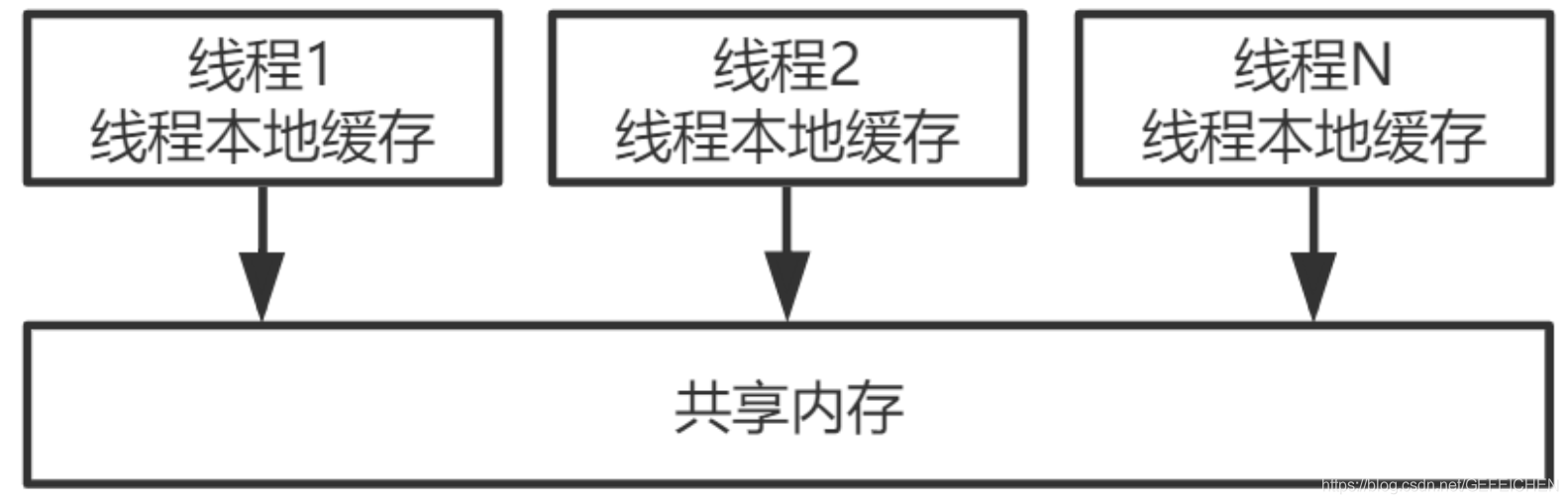
The following figure shows the layout of CPU cache under x86 architecture, that is, the layout of L1, L2 and L3 cache and main memory under a CPU 4 core. Each core has L1 and L2 caches, and L3 caches are shared by all cores.
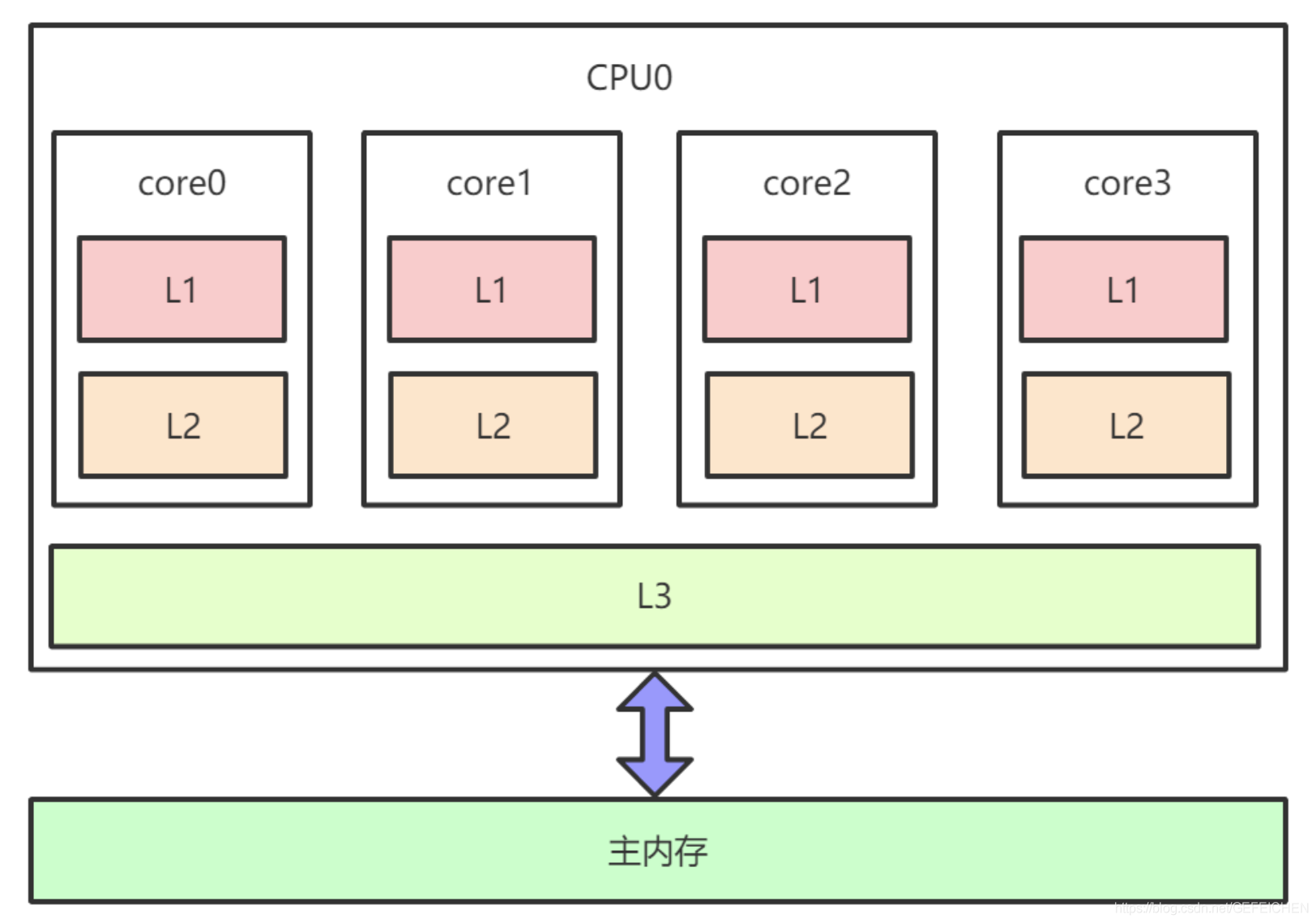
Because there is a CPU cache consistency protocol, such as MESI, there will be no asynchronous cache between multiple CPU cores and no "memory visibility" problem.
Cache consistency protocol has a great loss of performance. In order to solve this problem, various optimizations have been carried out. For example, Store Buffer, load buffer (and other buffers) are added between the computing unit and L1, as shown in the following figure:
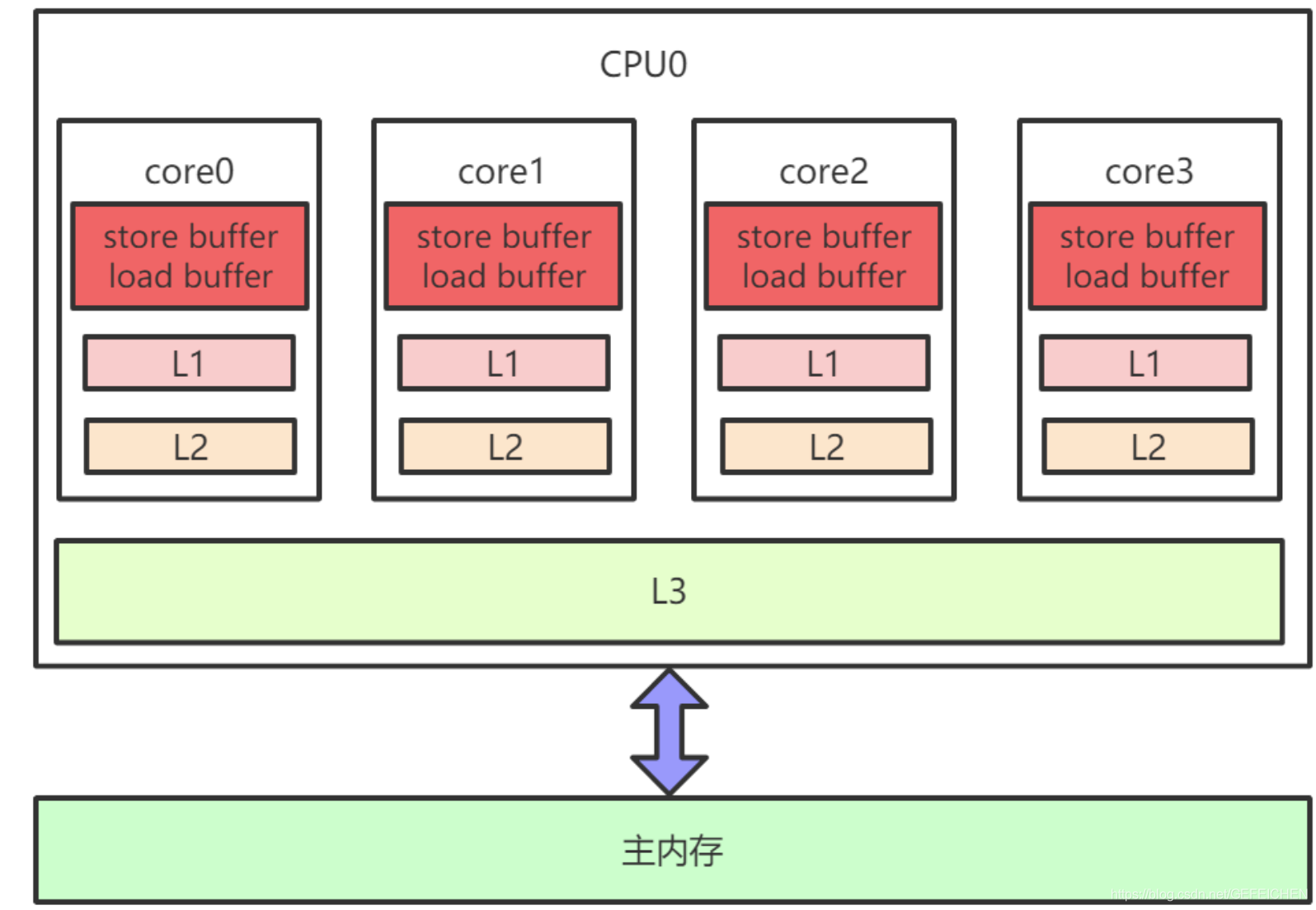
L1, L2, L3 and main memory are synchronous and guaranteed by cache consistency protocol, but Store Buffer, Load Buffer and L1 are asynchronous. Write a variable to the memory, which will be saved in the Store Buffer. Later, it will be asynchronously written to L1 and synchronously written to the main memory.
CPU cache model from the perspective of operating system kernel:

Multiple CPUs, each CPU has multiple cores, and there may be multiple hardware threads on each core. For the operating system, it is equivalent to one logical CPU. Each logical CPU has its own cache, which is not fully synchronized with the main memory.
Corresponding to Java, it is the JVM Abstract memory model, as shown in the following figure:
4.1. 2 Relationship between reordering and memory visibility
Delayed write to Store Buffer is a kind of reordering, which is called memory reordering. In addition, there is the instruction reordering of the compiler and CPU.
Reorder type:
- Compiler reordering. For statements that have no sequence dependency, the compiler can re adjust the execution order of statements.
- CPU instruction reordering. At the instruction level, parallel multiple instructions without dependencies.
- CPU memory reordering. The CPU has its own cache, and the execution order of instructions is not completely consistent with the order written into the main memory.
Among the three reordering, the third category is the main cause of the "memory visibility" problem, as shown in the following cases:
Thread 1:
X=1
a=Y
Thread 2:
Y=1
b=X
Suppose X and Y are two global variables. Initially, X=0 and Y=0. What should be the correct results of a and b after these two threads are executed?
Obviously, the execution order of thread 1 and thread 2 is uncertain. It may be executed sequentially or cross. The final correct result may be:
- a=0,b=1
- a=1,b=0
- a=1,b=1
That is, no matter who comes first, the execution result should be one of the three scenarios. But in fact, it may be a=0, b=0.
The instructions of both threads are not reordered. The execution order is the order of the code, but a=0 and b=0 may still occur. The reason is that thread 1 executes X=1 first and then a=Y, but X=1 is still in its own Store Buffer and is not written into the main memory in time. Therefore, the X seen by thread 2 is still 0. Thread 2 works the same way.
Although thread 1 feels that it executes normally in the code order, in thread 2's view, the order of a=Y and X=1 is reversed. The instructions are not reordered, because the operation of writing to memory is delayed, that is, the memory is reordered, which causes the problem of memory visibility.
4.1. 3 memory barrier
In order to prohibit compiler reordering and CPU reordering, there are corresponding instructions at the compiler and CPU levels, that is, memory barrier. This is also the underlying implementation principle of JMM and happy before rules.
The memory barrier of the compiler is just to tell the compiler not to reorder instructions. When the compilation is completed, the memory barrier disappears, and the CPU does not perceive the existence of the memory barrier in the compiler.
The memory barrier of the CPU is the instruction provided by the CPU, which can be displayed and called by the developer.
Memory barrier is a very low-level concept. For Java developers, volatile keyword is generally enough. However, starting with JDK 8, Java provides three memory barrier functions in the Unsafe class, as shown below.
public final class Unsafe {
// ...
public native void loadFence();
public native void storeFence();
public native void fullFence();
// ...
}
At the theoretical level, the basic CPU memory barriers can be divided into four types:
- LoadLoad: prohibit read and read reordering.
- StoreStore: write and write reordering are prohibited.
- LoadStore: read and write reordering is prohibited.
- StoreLoad: write and read reordering is prohibited.
Methods in Unsafe:
- loadFence=LoadLoad+LoadStore
- storeFence=StoreStore+LoadStore
- fullFence=loadFence+storeFence+StoreLoad
4.1. 4 as if serial semantics
What is the principle of reordering? What scenarios can be reordered and what scenarios cannot be reordered?
1. Reordering rules for single threaded programs
No matter what language, from the perspective of compiler and CPU, no matter how reordering, the execution results of single threaded programs cannot be changed. This is the reordering rule of single threaded programs.
That is, as long as there is no data dependency between operations, the compiler and CPU can reorder arbitrarily, because the execution result will not change, and the code looks like a complete serial execution line by line from beginning to end, which is the as if serial semantics.
For single threaded programs, the compiler and CPU may have reordered, but the developer is not aware of it, and there is no memory visibility problem.
2. Reordering rules for multithreaded programs
This behavior of the compiler and CPU has no impact on single threaded programs, but has an impact on multi-threaded programs.
For multithreaded programs, the data dependency between threads is too complex. The compiler and CPU can not fully understand this dependency and make the most reasonable optimization accordingly.
The compiler and CPU can only guarantee the as if serial semantics of each thread.
The data dependency and interaction between threads need to be determined by the compiler and the upper layer of the CPU.
The upper layer should tell the compiler and CPU when to reorder and when not to reorder in a multithreaded scenario.
4.1. 5 what is happy before
Use happy before to describe memory visibility between two operations.
java Memory Model (JMM) is a set of specifications. In multithreading, on the one hand, the compiler and CPU should be able to reorder flexibly; On the other hand, we should make some commitments to developers and clearly tell developers what kind of reordering they do not need to perceive and what kind of reordering they need to perceive. Then, decide whether this reordering has an impact on the program as needed. If there is an impact, developers need to explicitly prohibit reordering through thread synchronization mechanisms such as volatile and synchronized.
About happy before:
If a happens before B, it means that the execution result of a must be visible to B, that is, to ensure memory visibility across threads. A happen before B does not mean that a must execute before B. Because, for multithreaded programs, the execution order of the two operations is uncertain. Happy before only ensures that if a executes before B, the execution result of a must be visible to B. Defining constraints on memory visibility defines a series of reordering constraints.
Based on the description method of happen before, JMM has made a series of commitments to developers:
- For each operation in a single thread, the "happen before" corresponds to any subsequent operation in the thread (that is, as if serial semantic guarantee).
- For writes to volatile variables, happen before corresponds to subsequent reads to this variable.
- For the unlocking of synchronized, happen before corresponds to the subsequent locking of this lock.
...
JMM for compilers and CPU s, volatile variables cannot be reordered; Non volatile variables can be reordered arbitrarily.
4.1. 6. Transitivity of happy before
In addition to these basic happen before rules, happen before also has transitivity, that is, if a happen before B and B happen before C, then a happen before C.
If a variable is not a volatile variable, there may be problems when a thread reads and a thread writes. Doesn't that mean that in multithreaded programs, we either lock or declare all variables as volatile variables? This is obviously impossible, and this is due to the transitivity of happy before.
class A {
private int a = 0;
private volatile int c = 0;
public void set() {
a=5;// Operation 1
c=1;// Operation 2
}
public int get() {
intd=c;// Operation 3
return a; // Operation 4
}
}
Suppose thread A calls set first and sets a=5; Then thread B calls get, and the return value must be a=5. Why?
Operation 1 and operation 2 are executed in the same thread memory. Operation 1 happens before operation 2. Similarly, operation 3 happens before operation 4. Since c is a volatile variable, writing to c happens before reading to c, so operation 2 happens before operation 3. Using the transitivity of happy before, we can get:
Operation 1 happy before operation 2 happy before operation 3 happy before operation 4.
Therefore, the result of operation 1 must be visible to operation 4.
class A {
private int a = 0;
private int c = 0;
public synchronized void set() {
a=5;// Operation 1
c=1;// Operation 2
}
public synchronized int get() {
return a;
}
}
Suppose thread A calls set first and sets a=5; Then thread B calls get, and the return value must be a=5.
Because, like volatile, synchronized has the same happen before semantics. Expand the above code to get pseudo code similar to the following:
thread A: Lock; // Operation 1 a=5;// Operation 2 c=1;// Operation 3 Unlock; // Operation 4 thread B: Lock; // Operation 5 read a; // Operation 6 Unlock; // Operation 7
According to the synchronized happy before semantics, operation 4, happy before operation 5, combined with transitivity, you will finally get:
Operation 1, happy before operation 2... Happy before operation 7. Therefore, a and c are not volatile variables, but they still have memory visibility.
4.2 volatile keyword
4.2. 1 atomicity of 64 bit write (Half Write)
For the assignment and value of A long variable, in multi-threaded scenarios, thread A calls set(100), and thread B calls get(). In some scenarios, the return value may not be 100.
public class MyClass {
private long a = 0;
// Thread A calls set(100)
public void set(long a) {
this.a = a;
}
// Must the return value of thread B calling get() be 100?
public long get() {
return this.a;
}
}
Because the JVM specification does not require 64 bit long or double writes to be atomic. On a 32-bit machine, a 64 bit variable write may be split into two 32-bit write operations. In this way, the reading thread may read "half the value". The solution is also very simple. Add the volatile keyword before long.
4.2. 2 reordering: DCL problem
There are more than one ways to write thread safety in singleton mode. The common writing method is DCL(Double Checking Locking), as shown below:
public class Singleton {
private static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
// There is a problem with the code here
instance = new Singleton();
}
}
}
return instance;
}
}
instance = new Singleton(); There is a problem with the code: its bottom layer will be divided into three operations:
- Allocate a block of memory.
- Initializes member variables in memory.
- Point the instance reference to memory.
In these three operations, operations 2 and 3 may be reordered, that is, point instance to memory first, and then initialize member variables, because they have no sequential dependency. At this point, another thread may get an object that is not fully initialized. At this time, if you directly access the member variables inside, you may make an error. This is a typical "construction method overflow" problem.
The solution is also very simple, that is, add volatile modification to the instance variable.
The triple efficacy of volatile: atomicity of 64 bit writes, memory visibility, and prohibition of reordering.
4.2. 3 implementation principle of volatile
Due to the different cache systems and reordering strategies of different CPU architectures, the memory barrier instructions provided are different.
Here we only discuss a reference method to realize the semantics of volatile keyword:
- Insert a StoreStore barrier in front of volatile writes. Ensure that volatile writes are not reordered with previous writes.
- Insert a StoreLoad barrier after volatile writes. Ensure that volatile writes are not reordered with subsequent reads.
- Insert a LoadLoad barrier + LoadStore barrier after volatile read operations. Ensure that volatile read operations are not reordered with subsequent read and write operations.
Specifically, on the x86 platform, there will be no reordering of LoadLoad, LoadStore and StoreStore. There is only a reordering of StoreLoad (memory barrier), that is, you only need to add a StoreLoad barrier after volatile write operations.
4.2. 4. Enhancement of volatile semantics by jsr-133
In the old memory model before jsr-133, the read / write operation of a 64 bit long/ double variable can be split into two 32-bit read / write operations. Starting from jsr-133 memory model (i.e. JDK5), only the write operation of a 64 bit long/ double variable is allowed to be split into two 32-bit write operations. Any read operation must be atomic in jsr-133 (i.e. any read operation must be executed in a single read transaction).
This also reflects Java's strict adherence to the happy before rule.
4.3 final keyword
4.3. 1. Overflow of construction method
public class MyClass {
private int num1;
private int num2;
private static MyClass myClass;
public MyClass() {
num1 = 1;
num2 = 2;
}
/**
* Thread A executes write() first */
public static void write() {
myClass = new MyClass();
}
/**
* Thread B then executes write() */
public static void read() {
if (myClass != null) {
int num3 = myClass.num1;
int num4 = myClass.num2;
}
}
}
Are num3 and num4 values necessarily 1 and 2?
num3 and num4 are not necessarily equal to 1,2. Similar to the example of DCL, that is, the construction method overflow problem.
myClass = new MyClass(), which is broken down into three operations:
- Allocate a piece of memory;
- Initialize i=1, j=2 in memory;
- Point myClass to this memory.
Operations 2 and 3 may reorder, so thread B may see values that are not properly initialized. For construction method overflow, the construction of an object is not "atomic". When one thread is constructing an object, another thread can read the "half object" that has not been constructed.
4.3. 2. Happen before semantics of final
There is more than one way to solve this problem.
- Method 1: add volatile keyword to num1 and num2.
- Method 2: add the synchronized keyword to the read/write methods.
If num1 and num2 only need to be initialized once, you can also use the final keyword.
The reason why the problem can be solved is that, like volatile, the final keyword also has the corresponding happen before semantics:
- Writing to the final domain (inside the constructor) happens before the subsequent reading of the object where the final domain is located.
- The reading of the object in the final domain happens before the subsequent reading of the final domain.
This kind of semantic restriction of happen before ensures that the assignment of the final field must be completed before the construction method, and there will be no case that another thread reads the object, but the variables in the object have not been initialized, so as to avoid the problem of overflow of the construction method.
4.3. 3. Summary of happen before rules
- For each operation in a single thread, happen before is applied to any subsequent operation in the thread.
- Writing to a volatile variable happens before subsequent reading of the variable.
- The unlocking of synchronized is happy before the subsequent locking of this lock.
- For the writing of final variables, happen before is used for the reading of final domain objects, and happen before is used for the subsequent reading of final variables.
The four basic rules, coupled with the transitivity of happy before, constitute JMM's whole commitment to developers. Beyond this promise, programs can be reordered, requiring developers to carefully deal with memory visibility issues.
Part II: JUC
5 concurrent container
5.1 BlockingQueue
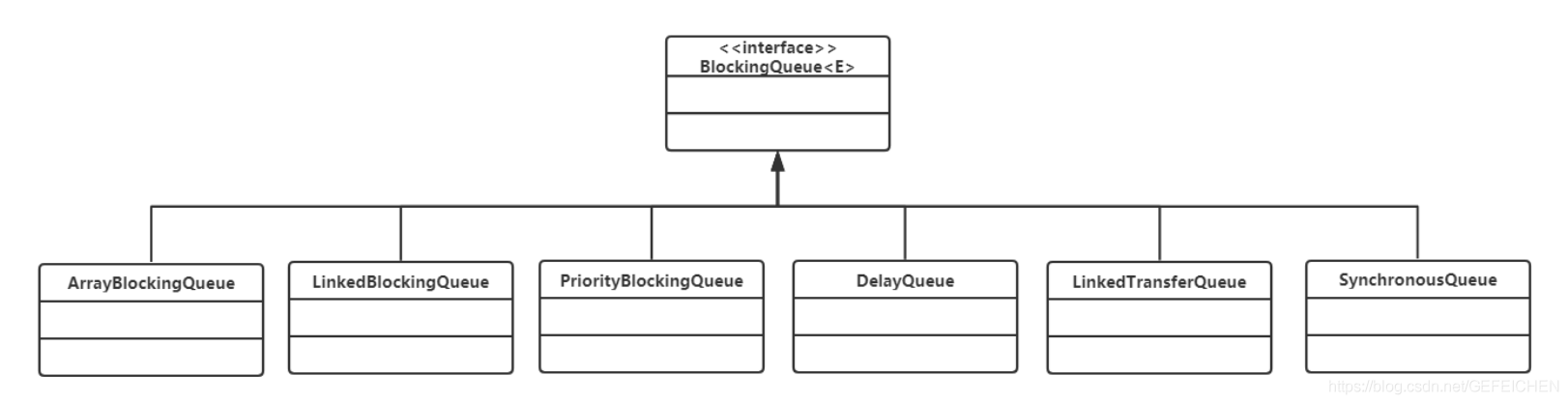
BlockingQueue is the most common of all concurrent containers. BlockingQueue is a queue with blocking function. When entering the queue, if the queue is full, the caller will be blocked; When out of the queue, if the queue is empty, the caller is blocked.
In the Concurrent package, BlockingQueue is an interface with many different implementation classes, as shown in the figure.
public interface BlockingQueue<E> extends Queue<E> {
//...
boolean add(E e);
boolean offer(E e);
void put(E e) throws InterruptedException;
boolean remove(Object o);
E take() throws InterruptedException;
E poll(long timeout, TimeUnit unit) throws InterruptedException;
//...
}
The interface is compatible with the Queue interface in the JDK collection package, and the blocking function is added to it. Here, there are three methods for joining the team: add(...), offer(...) and put(...). What's the difference? As can be seen from the above definition, the return values of add(...) and offer(...) are Boolean, while put has no return value and throws interrupt exceptions. Therefore, add(...) and offer(...) are non blocking interfaces defined by the Queue itself, and put(...) is blocking. There is little difference between add(...) and offer(...). When the Queue is full, the former will throw an exception, and the latter will directly return false.
The out of queue is similar to it. It provides methods such as remove(), poll(), take(). remove() is non blocking, and take() and poll() are blocking.
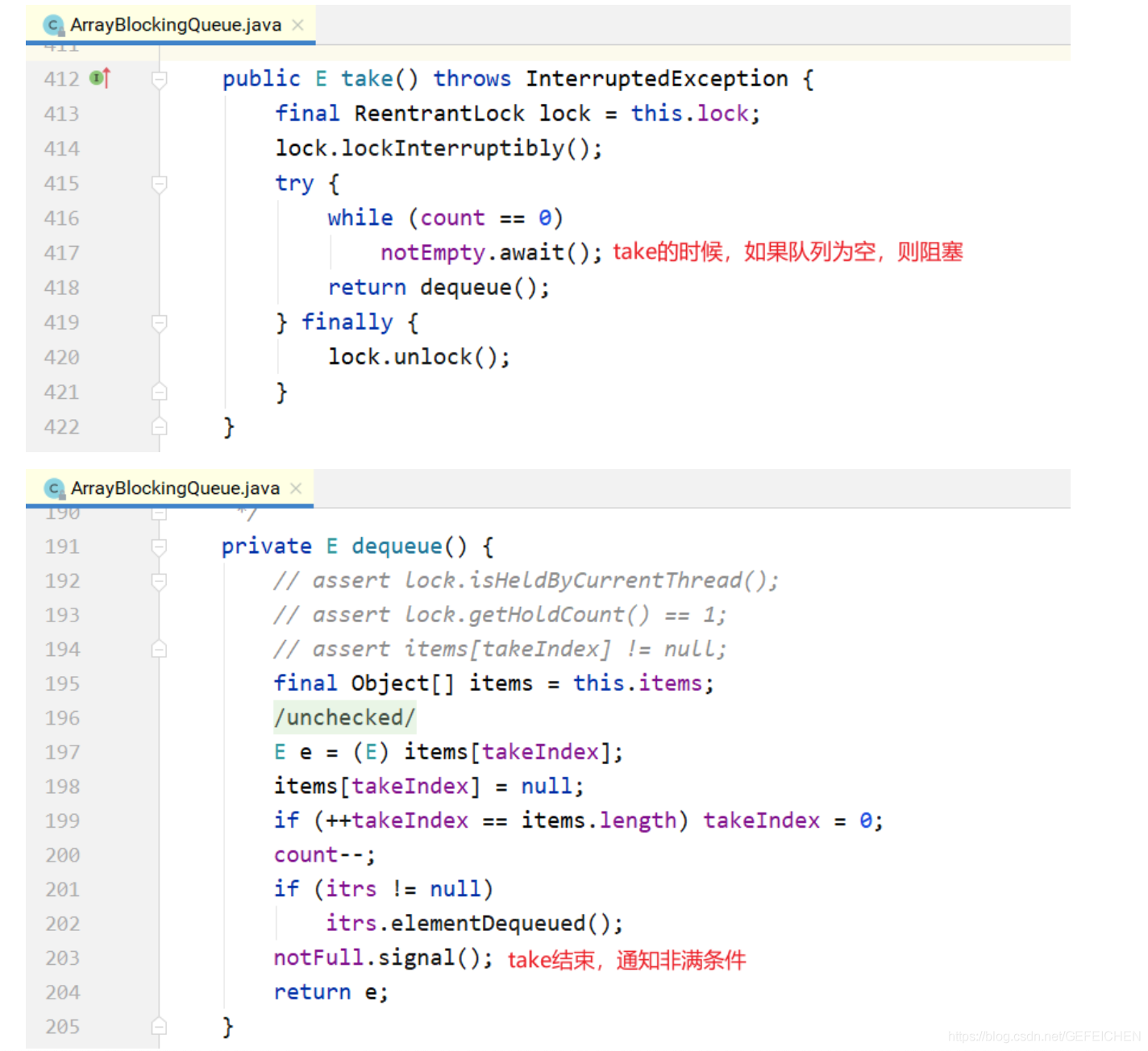
5.1.1 ArrayBlockingQueue
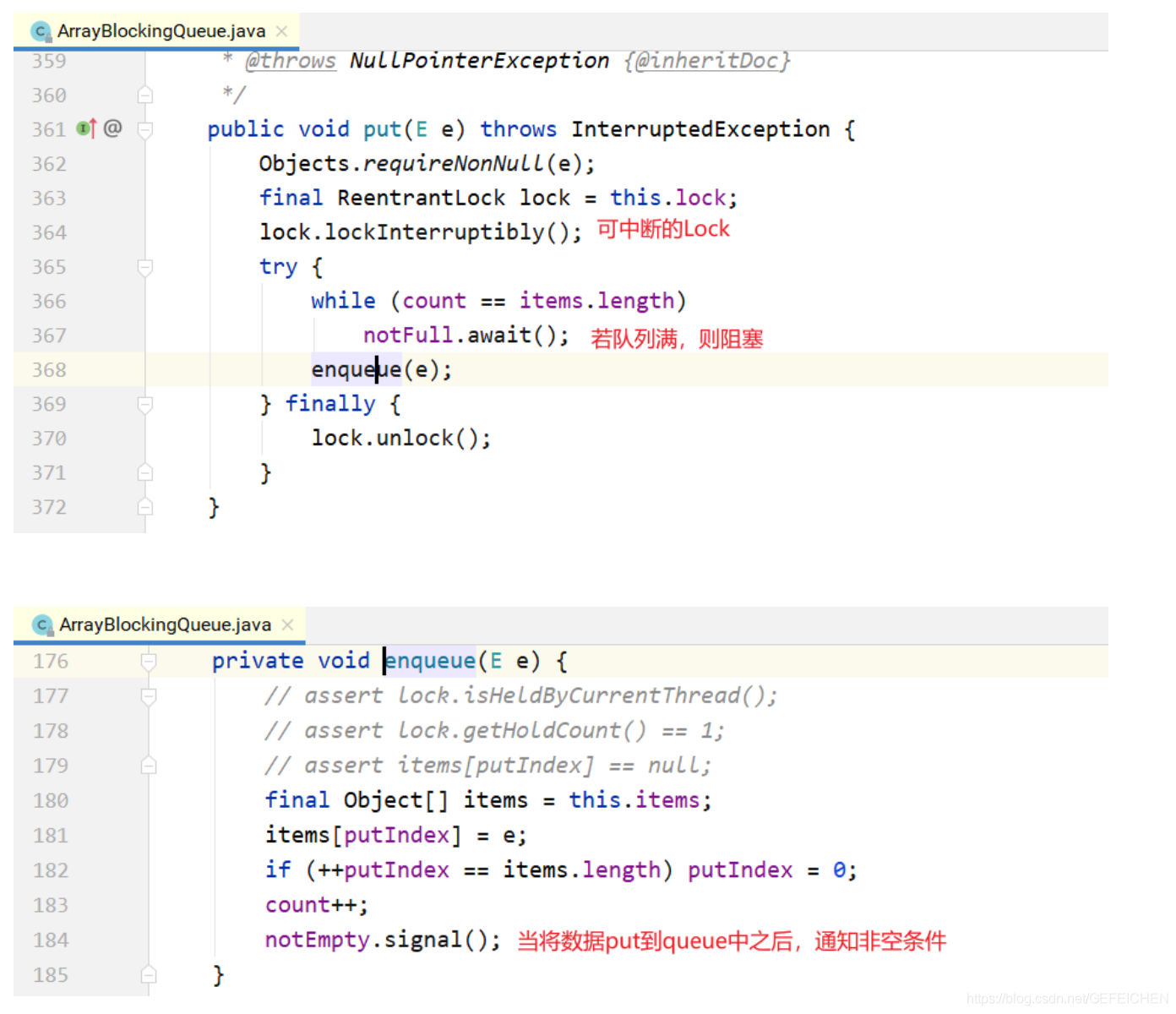
ArrayBlockingQueue is a ring queue implemented with an array. In the construction method, the capacity of the incoming array will be required.
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
// ...
}
public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extendsE> c) {
this(capacity, fair);
// ...
}
Its core data structure is as follows:
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
//...
final Object[] items;
// Queue head pointer
int takeIndex;
// Tail pointer
int putIndex;
int count;
// The core is one lock plus two conditions
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
//...
}
The put/take method is also very simple, as shown below.
put method:
take method:
5.1.2 LinkedBlockingQueue
LinkedBlockingQueue is a blocking queue based on one-way linked list. Because the head and tail of the queue are operated separately by two pointers, two locks + two conditions are used, and an atomic variable of AtomicInteger records the count number.
public class LinkedBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
// ...
private final int capacity;
// Atomic variable
private final AtomicInteger count = new AtomicInteger(0);
// Head of one-way linked list
private transient Node<E> head;
// Tail of one-way linked list
private transient Node<E> last;
// Two locks, two conditions
private final ReentrantLock takeLock = new ReentrantLock();
private final Condition notEmpty = takeLock.newCondition();
private final ReentrantLock putLock = new ReentrantLock();
private final Condition notFUll = putLock.newCondition();
// ...
}
In its construction method, you can also specify the total capacity of the queue. If not specified, the default is integer MAX_ VALUE.
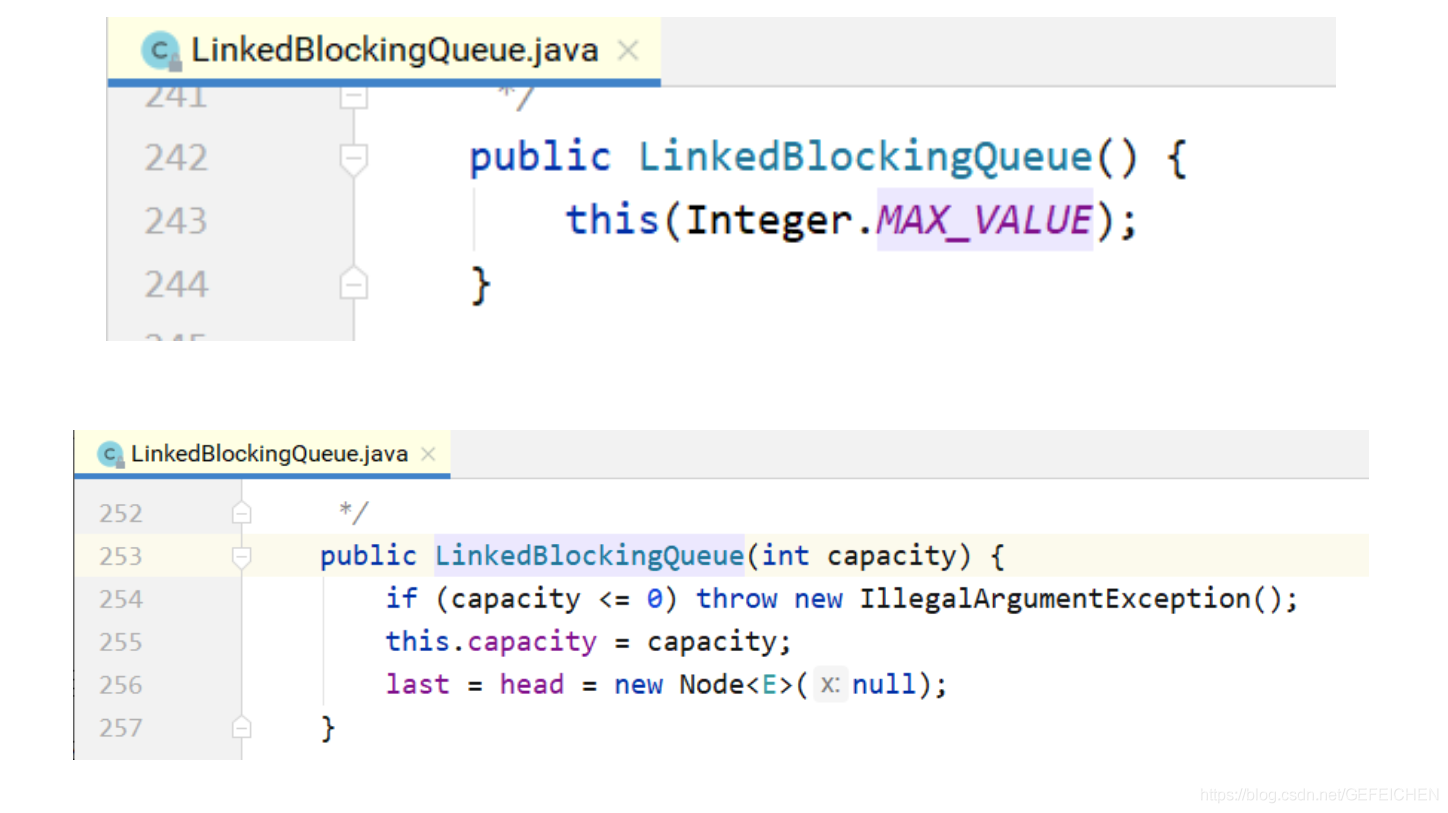
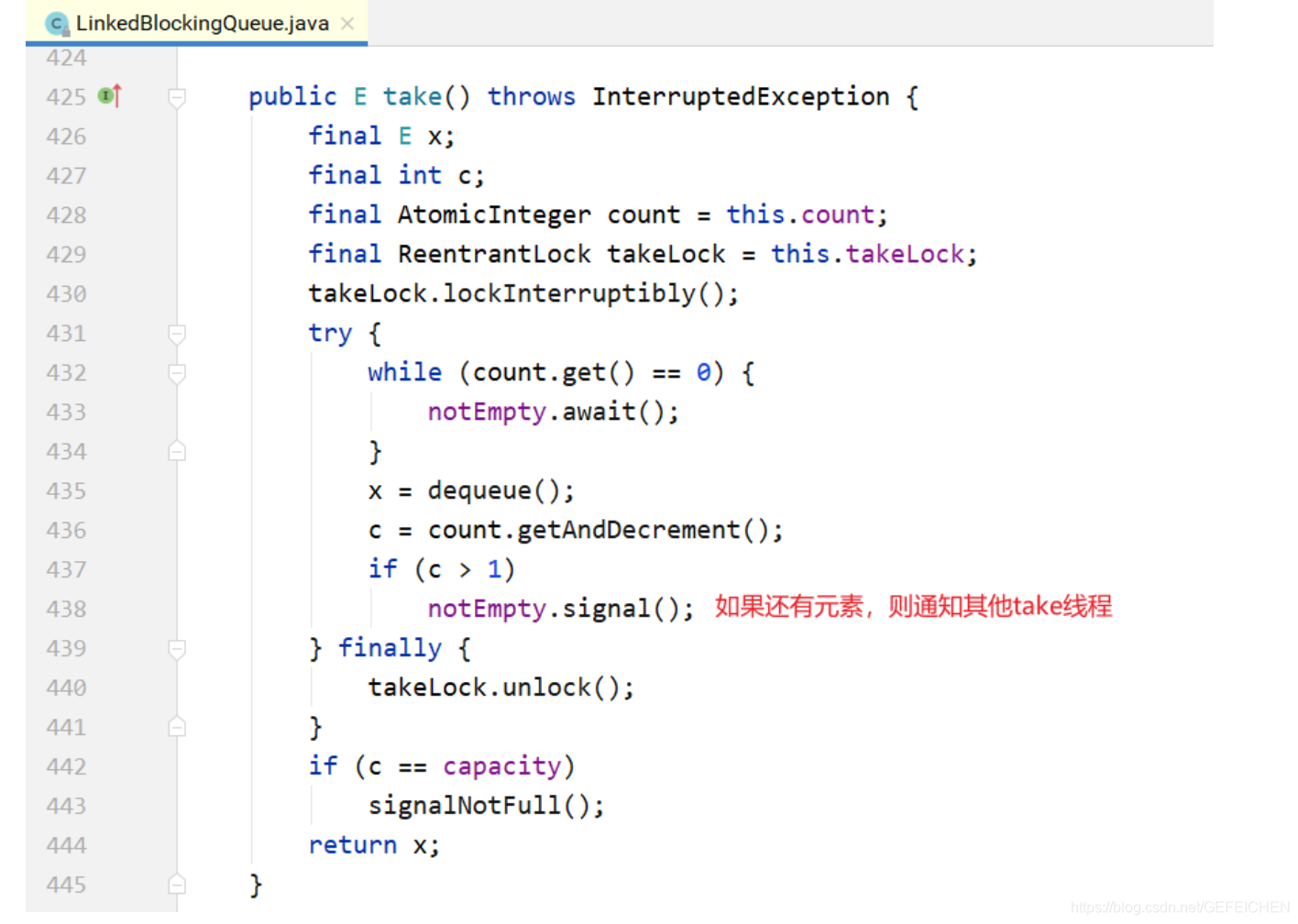
put/take implementation.

Differences between LinkedBlockingQueue and ArrayBlockingQueue:
- In order to improve concurrency, two locks are used to control the operation of team head and team tail respectively. This means that put(...) and put(...), take() and take() are mutually exclusive, and put(...) and take() are not mutually exclusive. However, for the count variable, both sides need to operate, so it must be of atomic type.
- Because they each have a lock, when they need to call the signal of the other party's condition, they must also add the other party's lock, that is, the signalNotEmpty() and signalNotFull() methods. An example is shown below.
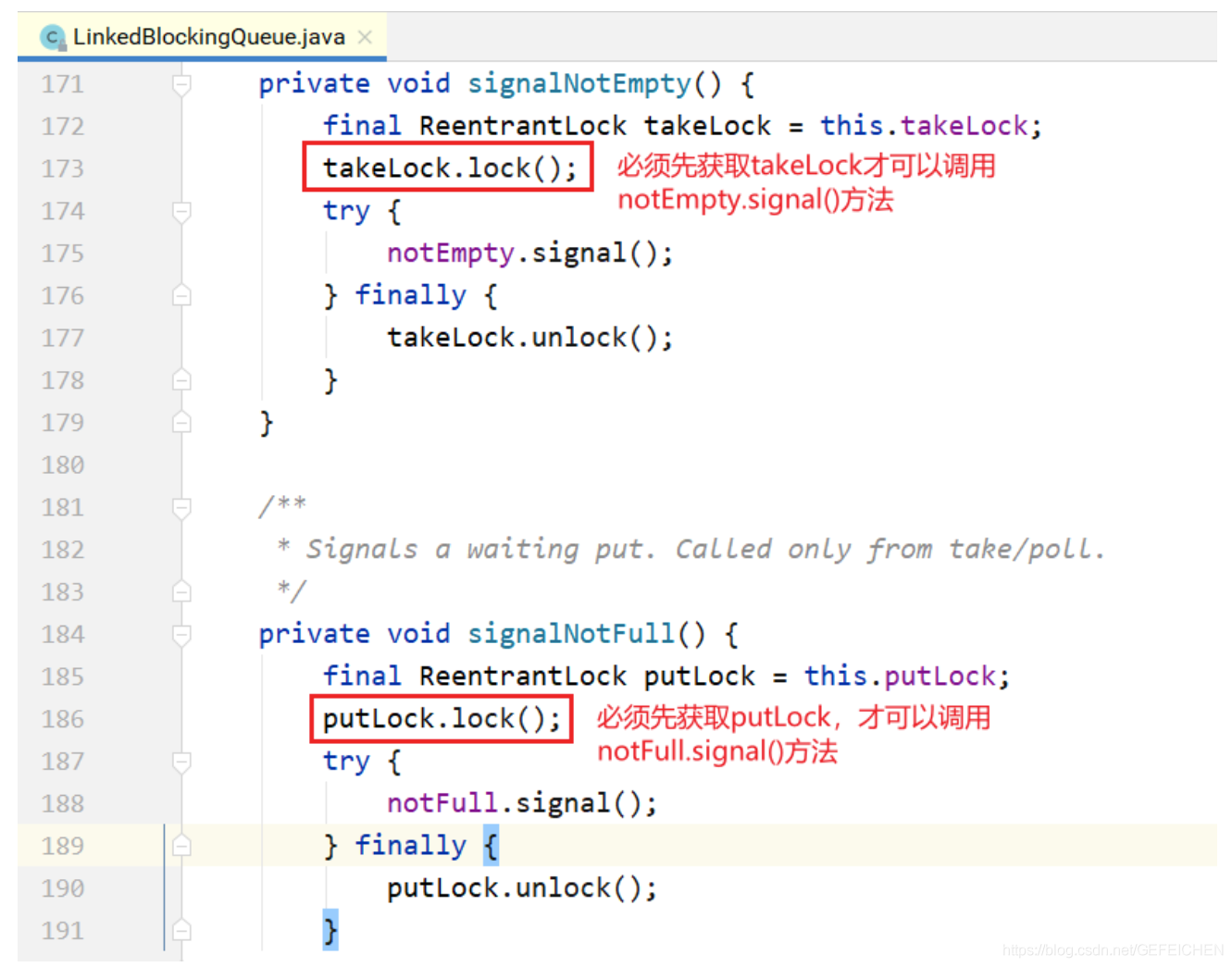
- Not only will put notify take, but also take will notify put. When the put is found to be not full, it will also notify other put threads; When take finds that it is not empty, it will also notify other take threads.
5.1.3 PriorityBlockingQueue
Queues are usually first in first out, and PriorityQueue goes out of the queue from small to large according to the priority of elements. Because of this, the two elements in the PriorityQueue need to be able to compare sizes and implement the Comparable interface.
Its core data structure is as follows:
public class PriorityBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
//...
// Two inserted small root heap realized by array
private transient Object[] queue;
private transient int size;
private transient Comparator<? super E> comparator;
// 1 lock + 1 condition, no non full condition
private final ReentrantLock lock;
private final Condition notEmpty;
//...
}
The construction method is as follows. If the initial size is not specified, a default value of 11 will be set internally. When the number of elements exceeds this size, the capacity will be expanded automatically.
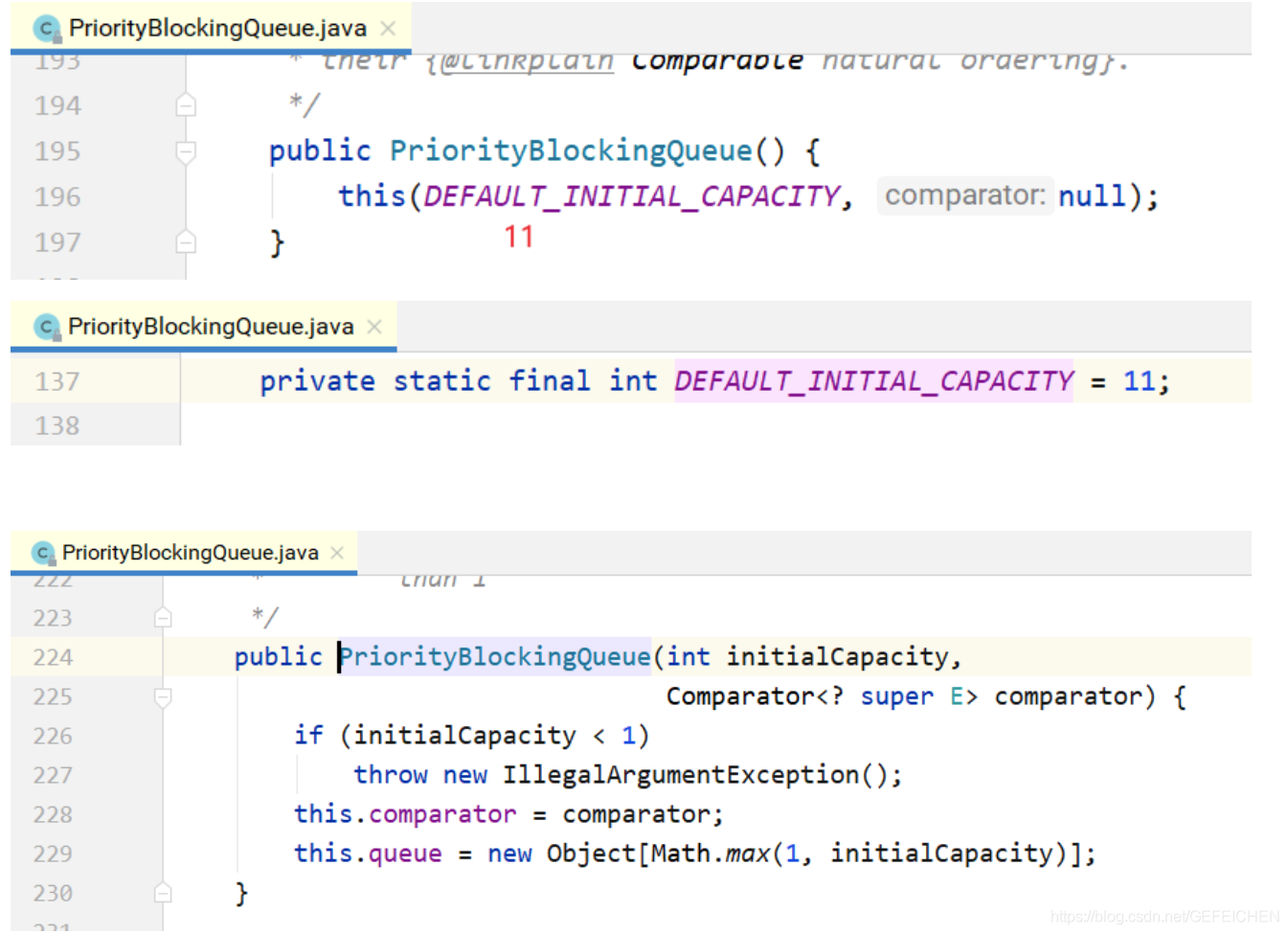
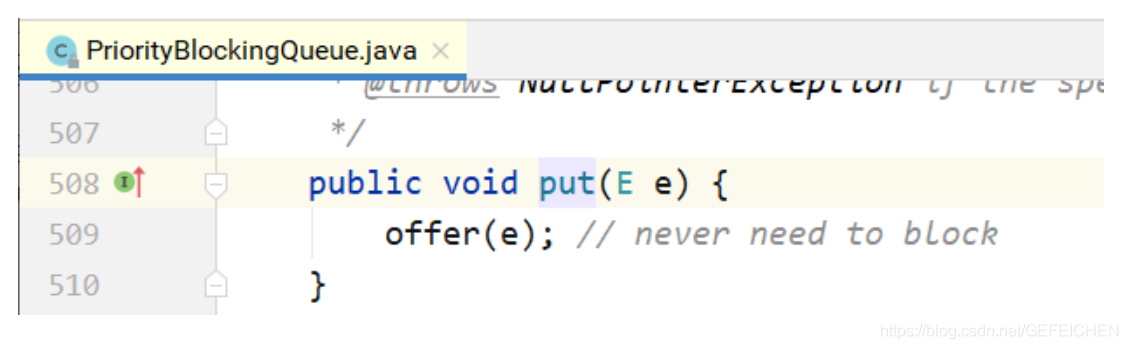
Implementation of put method:

Implementation of take:

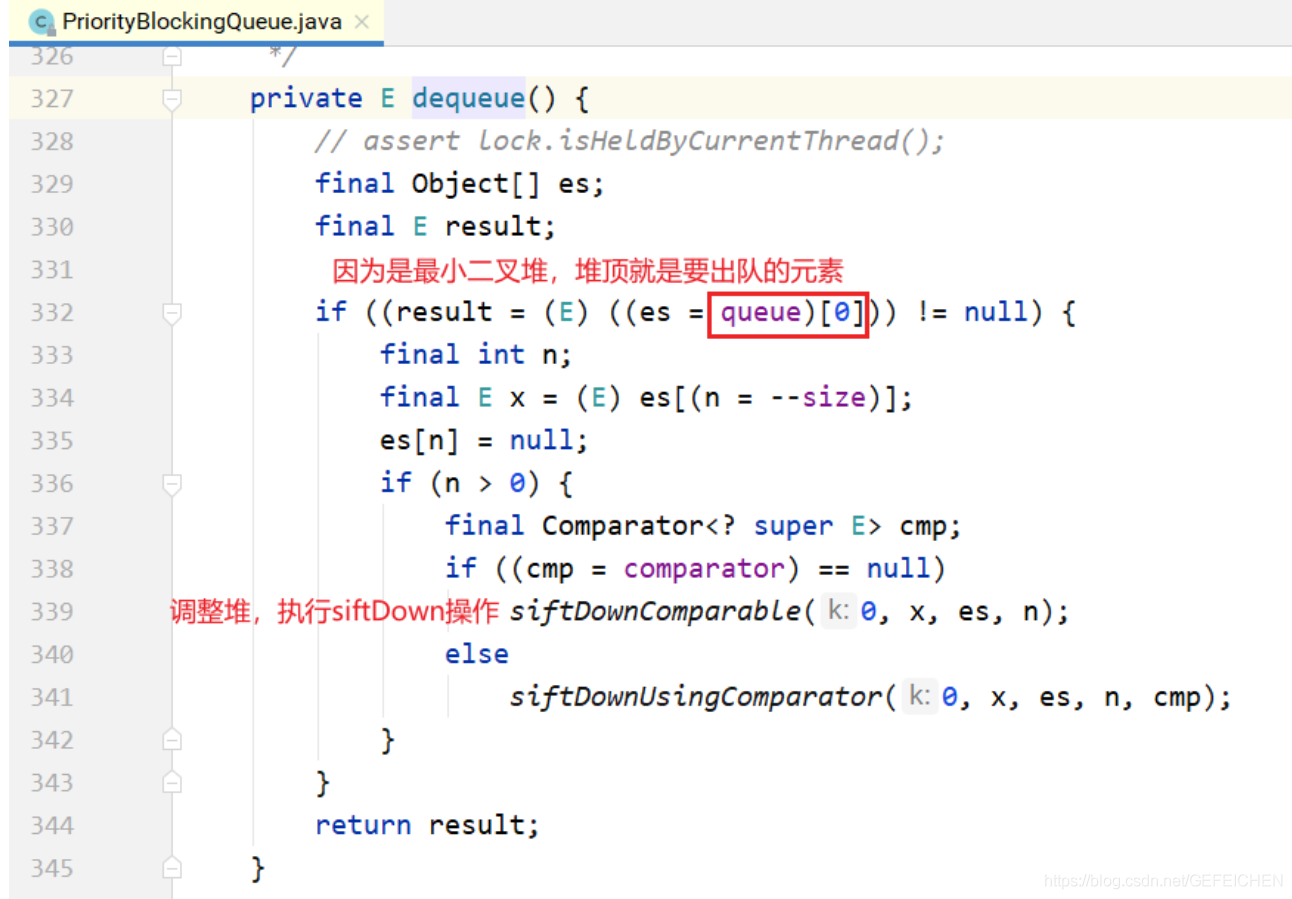
As can be seen from the above, the blocking mechanism is similar to that of ArrayBlockingQueue. The main difference is that a binary heap is implemented with an array, so as to realize the queue from small to large according to priority. Another difference is that there is no notFull condition. When the number of elements exceeds the length of the array, the capacity expansion operation is performed.
5.1.4 DelayQueue
DelayQueue is a delay queue, that is, a PriorityQueue that goes out of the queue from small to large according to the delay time. The so-called delay time is "time to be executed in the future" minus "current time". To do this, the elements placed in the DelayQueue must implement the Delayed interface, as shown below.
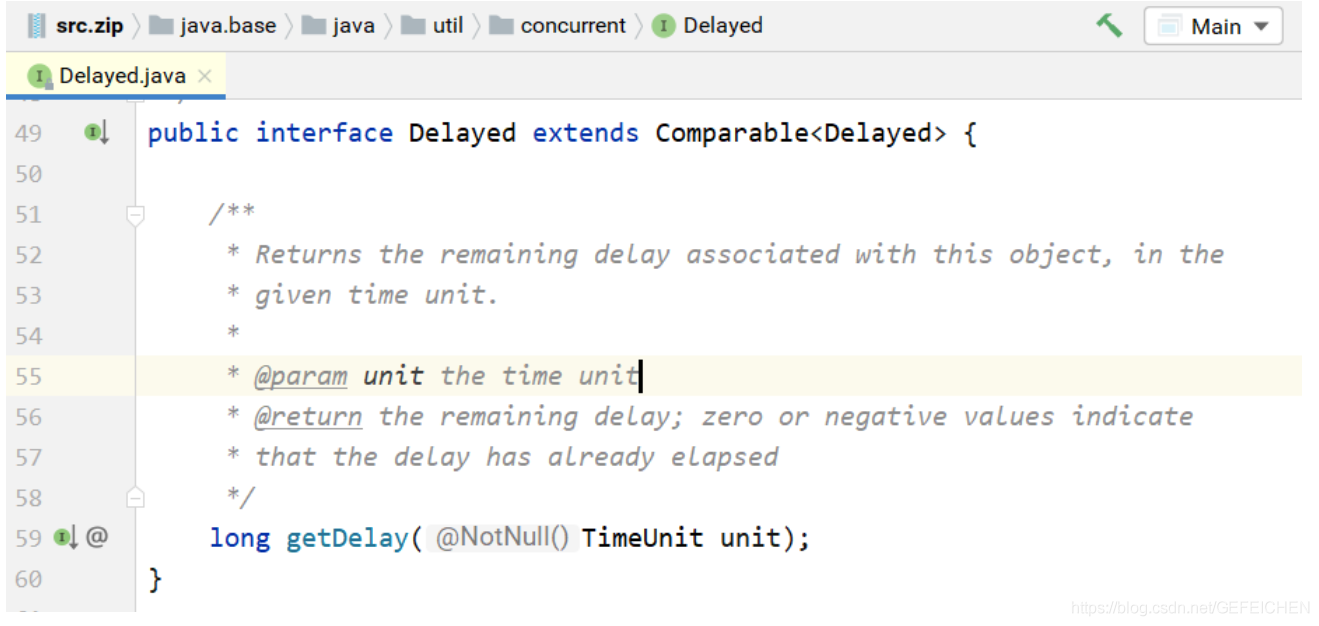
About this interface:
- If the return value of getDelay is less than or equal to 0, the element expires and needs to be taken out of the queue for execution.
- This interface first inherits the Comparable interface, so to implement this interface, you must implement the Comparable interface. Specifically, the size of the two elements is compared based on the return value of getDelay().
Let's take a look at the core data structure of DelayQueue.
public class DelayQueue<E extends Delayed> extends AbstractQueue<E> implements BlockingQueue<E> {
// ...
// A lock and a non null condition
private final transient ReentrantLock lock = new ReentrantLock();
private final Condition available = lock.newCondition();
// Priority queue
private final PriorityQueue<E> q = new PriorityQueue<E>();
// ...
}
Implementation of take:
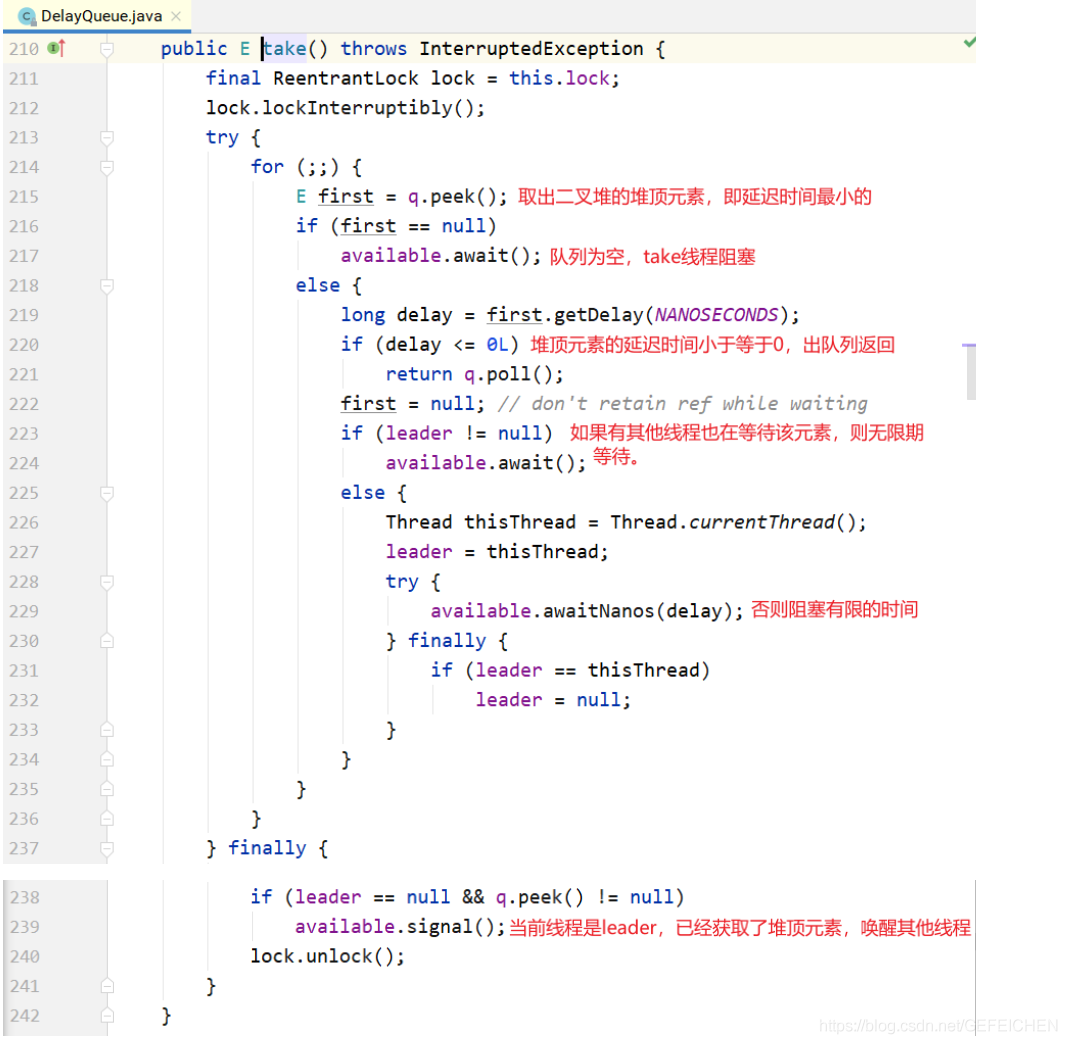
About the take() method:
- Different from the general blocking queue, blocking occurs only when the queue is empty. If the delay time of the heap top element does not arrive, it will also be blocked.
- In the above code, an optimization technique is used to record the first thread waiting for the top element of the heap with a Thread leader variable. Why? Through getDelay(...), you can know when the heap top element expires. You don't have to wait indefinitely. You can use condition Awaitnanos() waits for a limited time; You need to wait indefinitely only when you find that other threads are also waiting for the top of the heap element (leader!=NULL).
Implementation of put:
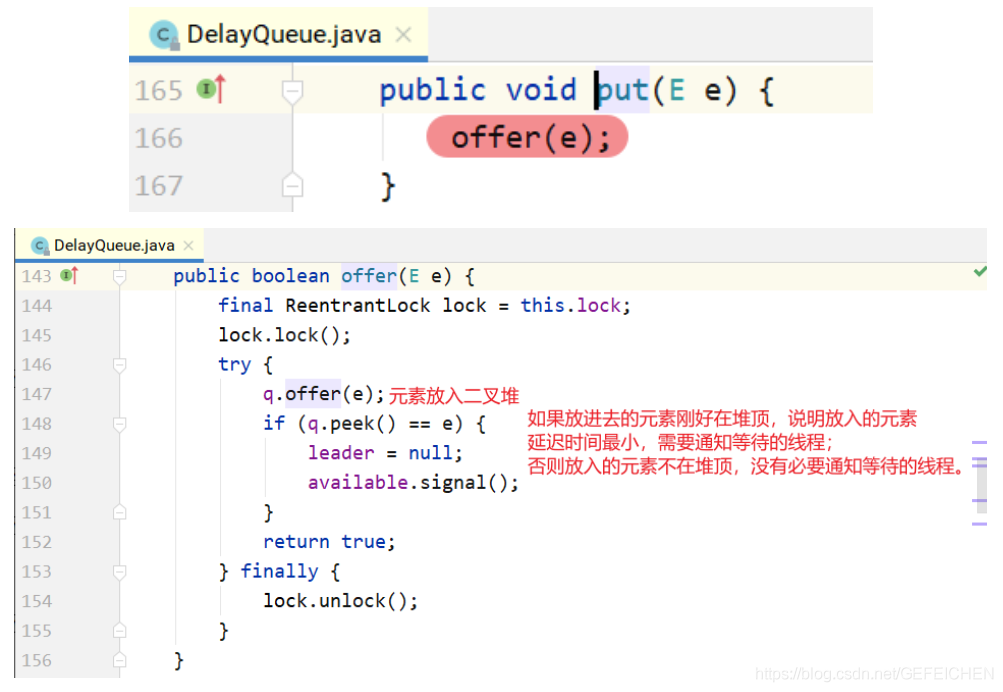
Note: it is not necessary to notify the waiting thread for each element. If the delay time of the put element is greater than the delay time of the element at the top of the current heap, it is not necessary to notify the waiting thread; Only when the delay time is minimal and at the top of the heap, it is necessary to notify the waiting thread, that is, if(q.peek() == e) in the above code.
5.1.5 SynchronousQueue
Synchronous queue is a special BlockingQueue that has no capacity. Call put(...) first, and the thread will block; The two threads are not unlocked at the same time until another thread calls take (), and vice versa. For multiple threads, for example, three threads call put(...) three times, and all three threads will be blocked; Six threads are unlocked at the same time until another thread calls take() three times, and vice versa.
Next, let's look at the implementation of synchronous queue.
Construction method:

Like locks, there are fair and unfair models. If it is a fair mode, it is implemented with TransferQueue; If it is an unfair mode, it is implemented with TransferStack. What are the two classes? Let's take a look at the implementation of put/take.

You can see that both put/take call the transfer(...) interface. TransferQueue and TransferStack implement this interface respectively. The interface is inside the SynchronousQueue, as shown below. If it is put(...), the first parameter is the corresponding element; If it is take(), the first parameter is null. The last two parameters are whether to set timeout and corresponding timeout.
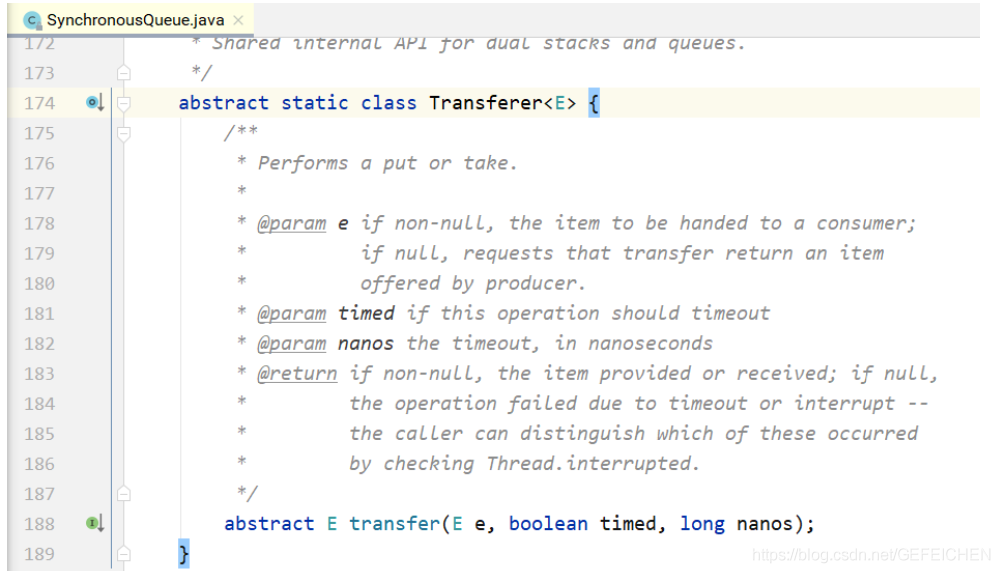
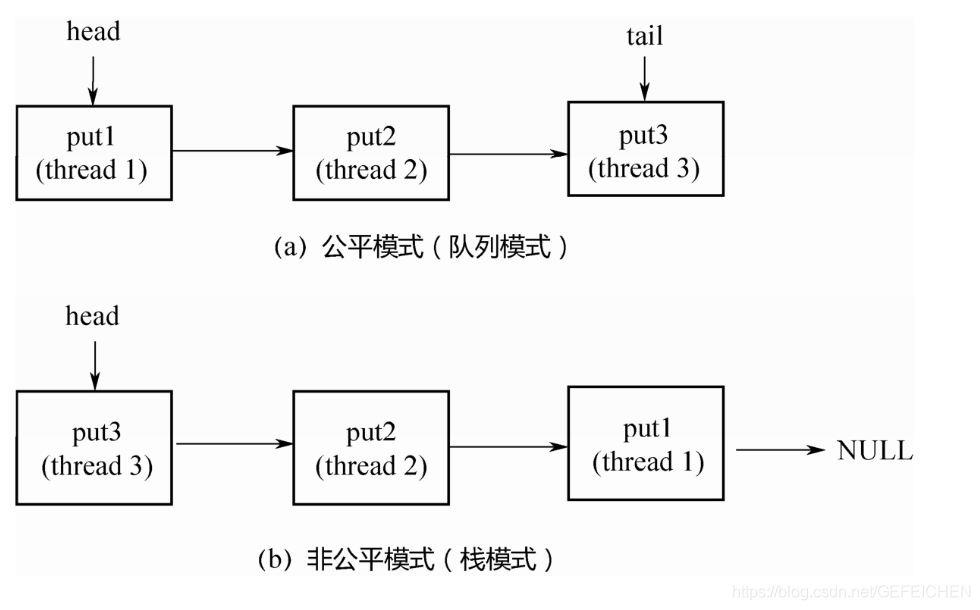
Next, let's look at what is fair mode and unfair mode. Suppose that three threads call put(...) respectively, and the three threads will enter the blocking state until other threads call take() three times and pair the three put(...) one by one.
If it is fair mode (queue mode), the first thread 1 calling put(...) will be at the head of the queue, and the first incoming take() thread will pair with it, following the principle of first come first pair, so it is fair; If it is in the unfair mode (stack mode), the third thread calling put(...) will be at the top of the stack, and the first incoming take() thread will pair with it. It follows the principle of last to first pairing, so it is unfair.
Let's take a look at the implementation of TransferQueue and TransferStack respectively.
1.TransferQueue
public class SynchronousQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
// ...
static final class TransferQueue<E> extends Transferer<E> {
static final class QNode {
volatile QNode next;
volatile Object item;
volatile Thread waiter;
final boolean isData;
//...
}
transient volatile QNode head;
transient volatile QNode tail;
// ...
}
}
As can be seen from the above code, TransferQueue is a queue based on a one-way linked list. The head and tail are recorded through two pointers: head and tail. Initially, head and tail will point to an empty node. The construction method is as follows.
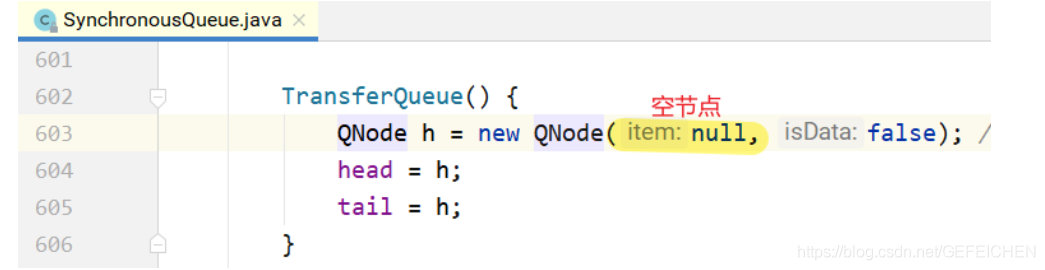
Phase (a): there is an empty node in the queue, and the head/tail points to this empty node.
Stage (b): three threads call put respectively, generate three qnodes and enter the queue.
stage ©: When a thread calls take, it will pair with the first QNode in the queue head.
Phase (d): the first QNode exits the queue.

Here is a key point: once the put node and take node meet, they will pair out of the queue. Therefore, it is impossible to have both put node and take node in the queue. Either all nodes are put nodes or all nodes are take nodes.
Next, let's look at the code implementation of TransferQueue.

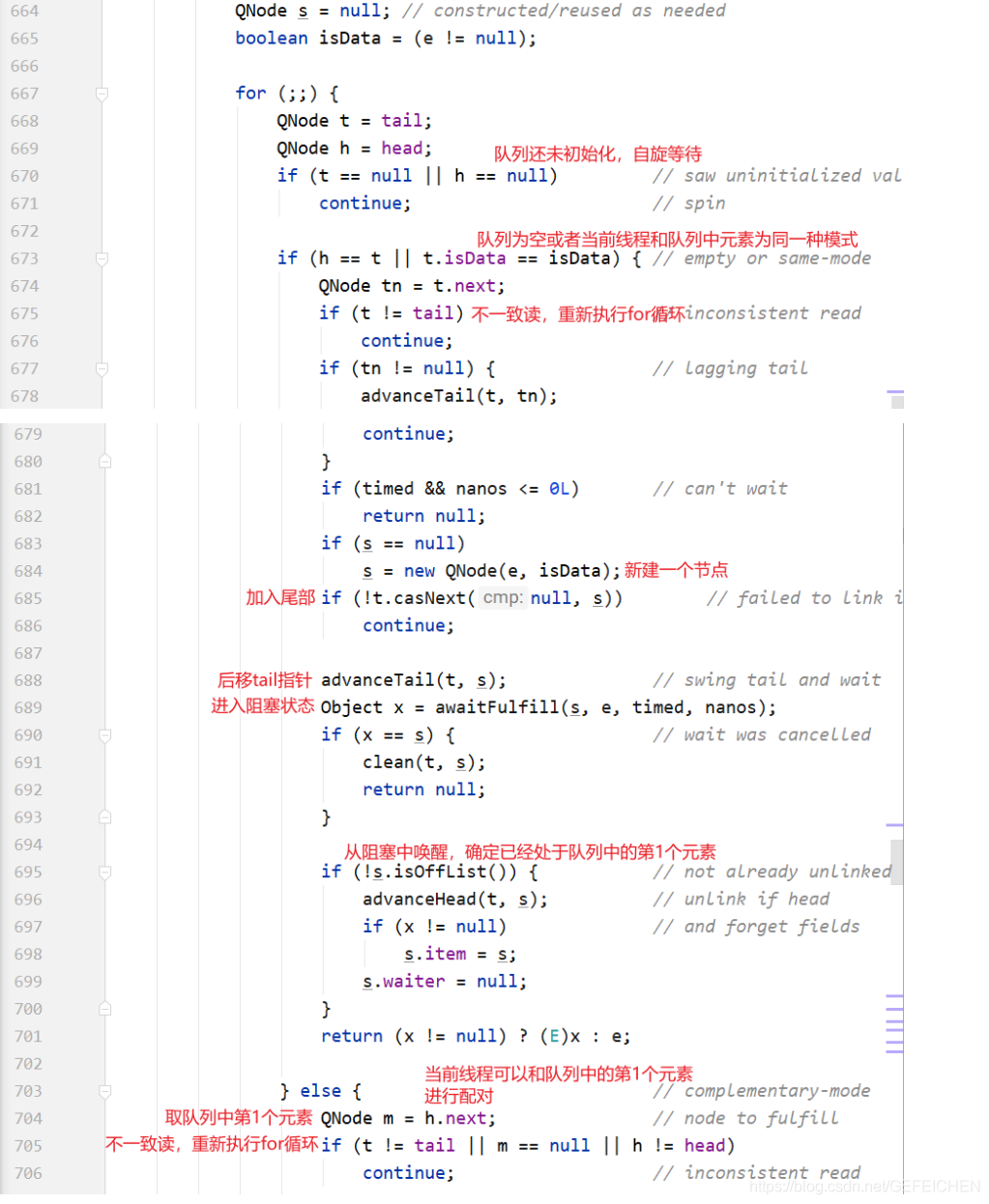

The whole for loop has two large if else branches. If the current thread and the elements in the queue are in the same mode (both put nodes or take nodes), the nodes corresponding to the current thread are added to the end of the queue and blocked; If it is not the same mode, the first element of the queue header is selected for pairing.
The pairing here is m.casItem(x, e). Replace your own item x with the other party's item e. if the CAS operation is successful, the pairing is successful. If it is a put node, isData=true, item=null; If it is a take node, isData=false and item=null. If the CAS operation is unsuccessful, there will be inconsistency between isData and item, that is, isData= (x! = null). This condition can be used to judge whether the node has been matched.
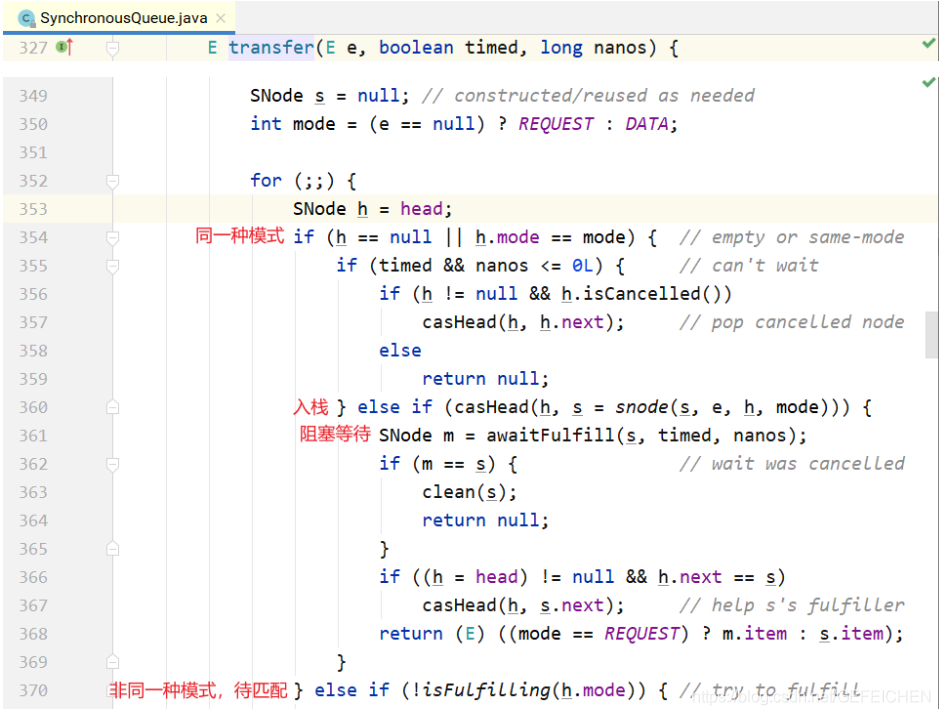
2.TransferStack
The definition of TransferStack is as follows. First, it is also a one-way linked list. Different from the queue, only the head pointer is needed to realize the stack in and out operations.
static final class TransferStack extends Transferer {
static final int REQUEST = 0;
static final int DATA = 1;
static final int FULFILLING = 2;
static final class SNode {
volatile SNode next; // Unidirectional linked list
volatile SNode match; // Paired nodes
volatile Thread waiter; // Corresponding blocking thread
Object item;
int mode; //Three modes
//...
}
volatile SNode head;
}
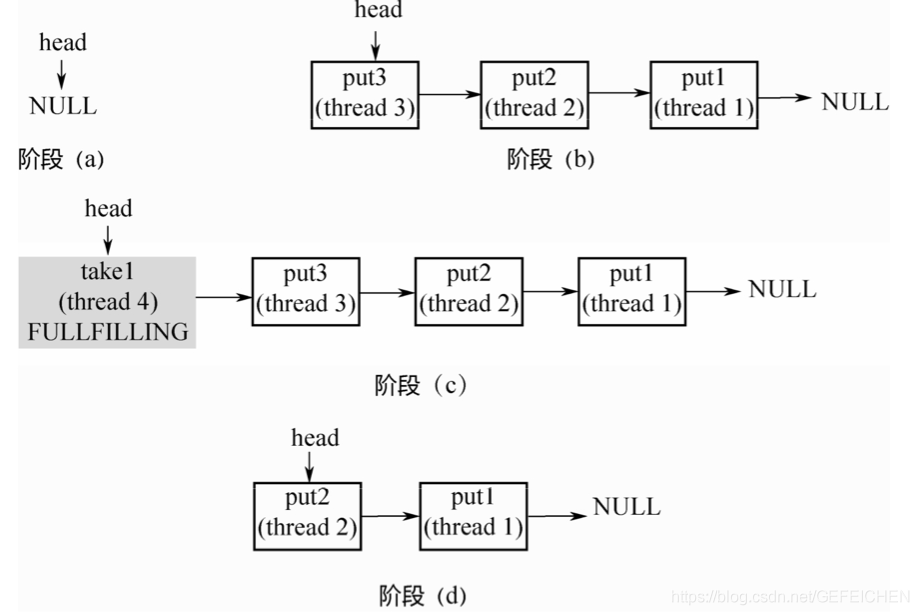
The nodes in the linked list have three states. REQUEST corresponds to the take node and DATA corresponds to the put node. After the two are paired, a filling node will be generated and put into the stack, and then the filling node and the paired node will be put out of the stack together.
Stage (a):head points to NULL. Unlike TransferQueue, there is no empty header node.
Stage (b): three threads call put three times and put it on the stack in turn.
stage ©: Thread 4 calls take, pairs with the first element at the top of the stack, generates a FULLFILLING node, and enters the stack.
Stage (d): two elements at the top of the stack are put on the stack at the same time.

5.2 BlockingDeque
BlockingDeque defines a blocked two terminal queue interface, as shown below.
public interface BlockingDeque<E> extends BlockingQueue<E>, Deque<E> {
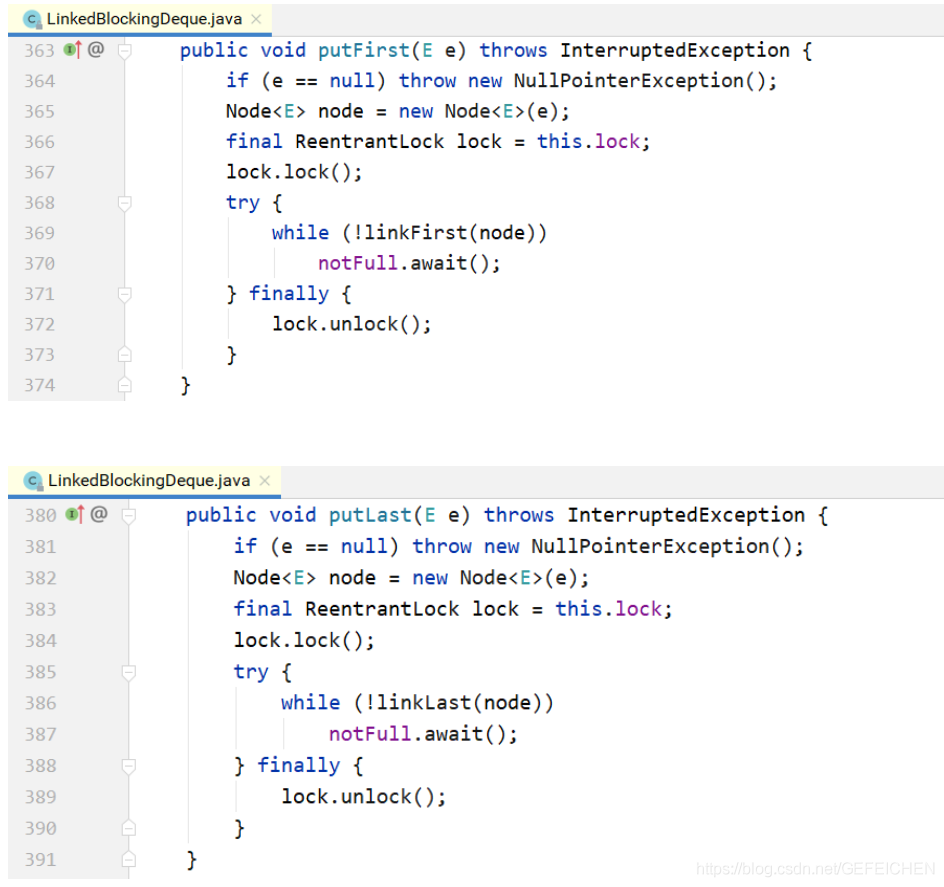
void putFirst(E e) throws InterruptedException;
void putLast(E e) throws InterruptedException;
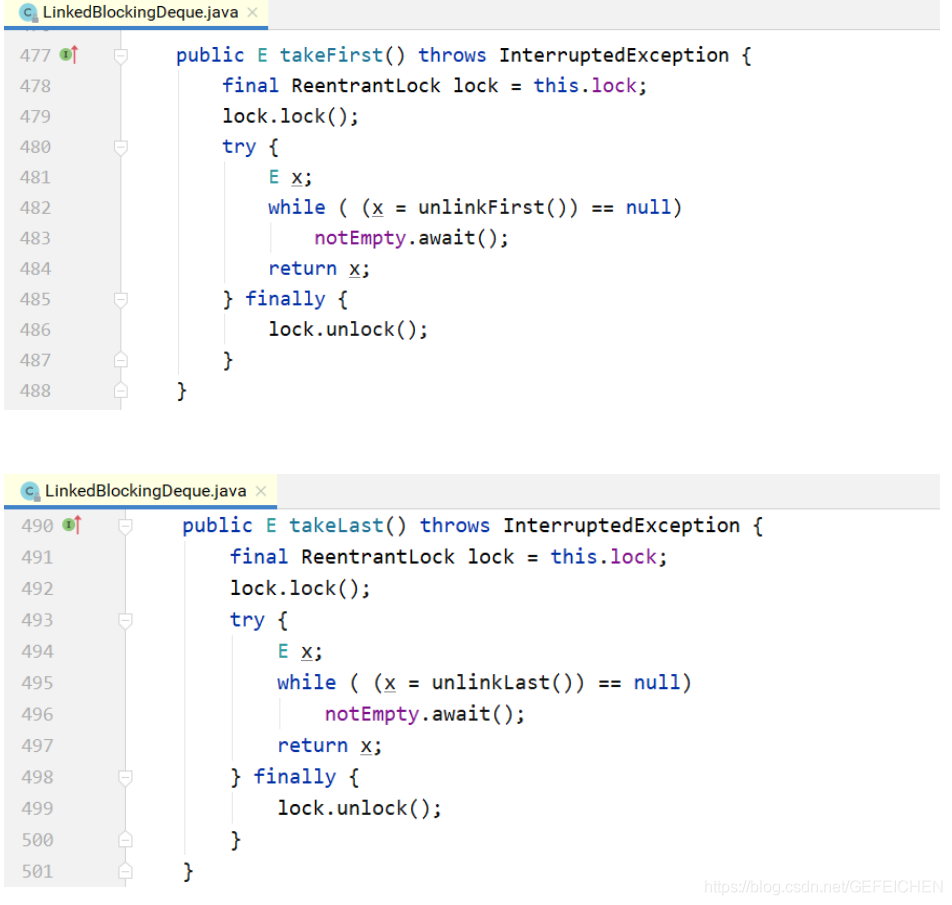
E takeFirst() throws InterruptedException;
E takeLast() throws InterruptedException;
// ...
}
This interface inherits the BlockingQueue interface and adds the corresponding two terminal queue operation interface. There is only one implementation of this interface, LinkedBlockingDeque.
Its core data structure is as follows. It is a two-way linked list.
public class LinkedBlockingDeque<E> extends AbstractQueue<E> implements BlockingDeque<E>, java.io.Serializable {
static final class Node<E> {
E item;
Node<E> prev; // Bidirectional linked list
Node Node<E> next;
Node(E x) {
item = x;
}
}
transient Node<E> first; // Head and tail of queue
transient Node<E> last;
private transient int count; // Number of elements
private final int capacity; // capacity
// One lock + two conditions
final ReentrantLock lock = new ReentrantLock();
private final Condition notEmpty = lock.netCondition();
private final Condition notFull = lock.newCondition();
// ...
}
The corresponding implementation principle is basically the same as LinkedBlockingQueue, except that LinkedBlockingQueue is a one-way linked list and LinkedBlockingDeque is a two-way linked list.
5.3 CopyOnWrite
CopyOnWrite means that when "writing", instead of "writing" the source data directly, it copies the data for modification, and then writes it back through pessimistic lock or optimistic lock.
Then why not modify it directly, but copy it?
This is to "read" without locking.
5.3.1 CopyOnWriteArrayList
Like ArrayList, the core data structure of CopyOnWriteArrayList is also an array. The code is as follows:
public class CopyOnWriteArrayList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// ...
private volatile transient Object[] array;
}
Here are several "read" methods of CopyOnArrayList:
final Object[] getArray() {
return array;
}
//
public E get(int index) {
return elementAt(getArray(), index);
}
public boolean isEmpty() {
return size() == 0;
}
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
Object[] es = getArray();
return indexOfRange(o, es, 0, es.length);
}
private static int indexOfRange(Object o, Object[] es, int from, int to){
if (o == null) {
for (int i = from; i < to; i++)
if (es[i] == null)
return i;
} else {
for (int i = from; i < to; i++)
if (o.equals(es[i]))
return i;
}
return -1;
}
Since these "read" methods are not locked, how to ensure "thread safety"? The answer is in the "write" method.
public class CopyOnWriteArrayList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// Lock object
final transient Object lock = new Object();
public boolean add(E e) {
synchronized (lock) { // Synchronization lock object
Object[] es = getArray();
int len = es.length;
es = Arrays.copyOf(es, len + 1); // CopyOnWrite: when writing, first copy a previous array.
es[len] = e;
setArray(es);
return true;
}
}
public void add(int index, E element) {
synchronized (lock) { // Synchronization lock object
Object[] es = getArray();
int len = es.length;
if (index > len || index < 0)
throw new IndexOutOfBoundsException(outOfBounds(index,len));
Object[] newElements;
int numMoved = len - index;
if (numMoved == 0)
newElements = Arrays.copyOf(es, len + 1);
else
newElements = new Object[len + 1];
System.arraycopy(es, 0, newElements, 0, index); // CopyOnWrite: when writing, first copy a previous array.
System.arraycopy(es, index, newElements, index + 1, numMoved);
newElements[index] = element;
setArray(newElements); // Assign the new array to the old array
}
}
}
Other "write" methods, such as remove and add, are similar and will not be detailed here.
5.3.2 CopyOnWriteArraySet
CopyOnWriteArraySet is a Set implemented with Array to ensure that all elements are not repeated. Inside it is a CopyOnWriteArrayList encapsulated.
public class CopyOnWriteArraySet<E> extends AbstractSet<E> implements java.io.Serializable {
// Newly encapsulated CopyOnWriteArrayList
private final CopyOnWriteArrayList<E> al;
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
public boolean add(E e) {
return al.addIfAbsent(e); // Add it without repetition
}
}
5.4 ConcurrentLinkedQueue/Deque
Implementation principle of blocking queue in AQS: Based on the two-way linked list, the queue in and out can be realized by CAS operation on the head/tail.
The implementation principle of ConcurrentLinkedQueue is similar to the blocking queue in AQS: it is also based on CAS and records the head and tail of the queue through the head/tail pointer, but there is still a slight difference.
First, it is a one-way linked list, which is defined as follows:
public class ConcurrentLinkedQueue<E> extends AbstractQueue<E> implements Queue<E>, java.io.Serializable {
private static class Node<E> {
volatile E item;
volatile Node<E> next;
//...
}
private transient volatile Node<E> head;
private transient volatile Node<E> tail;
//...
}
Secondly, in the blocking queue of AQS, the tail must move back one position after each queue entry; Every time you leave the queue, the head must be moved back one position to ensure that the head points to the head of the queue and the tail points to the tail of the linked list.
However, in the ConcurrentLinkedQueue, the update of the head/tail may lag behind the enqueue and dequeue of the Node, because it does not directly perform CAS operations on the head/tail pointer, but on the item s in the Node. The following is a detailed analysis:
1. Initialization
Initially, both head and tail point to a null node. The corresponding codes are as follows.
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
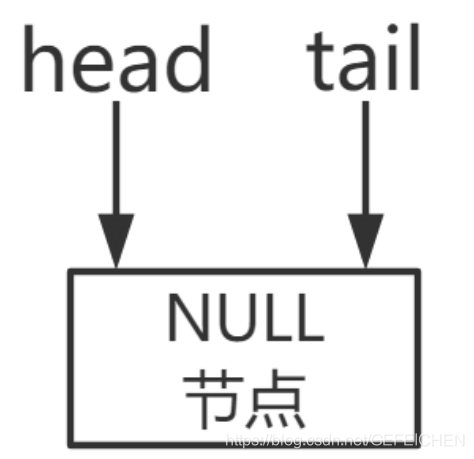
2. Queue
public boolean offer(E e) {
final Node<E> newNode = new Node<E>(Objects.requireNonNull(e));
for (Node<E> t = tail, p = t;;) { Node<E> q = p.next;
if (q == null) {
if (NEXT.compareAndSet(p, null, newNode)) {
if (p != t)
TAIL.weakCompareAndSet(this, t, newNode);
return true
}
}
else if (p == q)
p = (t != (t = tail)) ? t : head;
else
p = (p != t && t != (t = tail)) ? t : q;
}
}
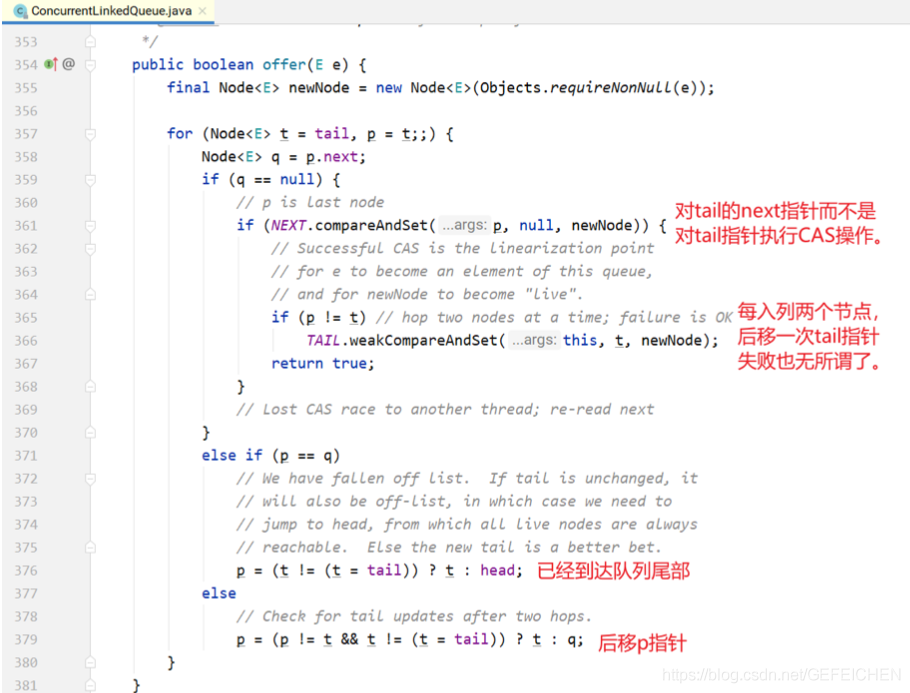
The above queue entry actually moves the tail node once every time two nodes are added at the end of the queue. As shown in the figure below:
Initially, there is a node item1 in the queue, and tail points to this node. Suppose thread 1 wants to join the item2 node:
step1:p=tail,q=p.next=NULL.
Step 2: perform CAS operation on p's next and append item2. After success, p=tail. Therefore, the above casTail method will not be executed and will return directly. The tail pointer does not change at this time.
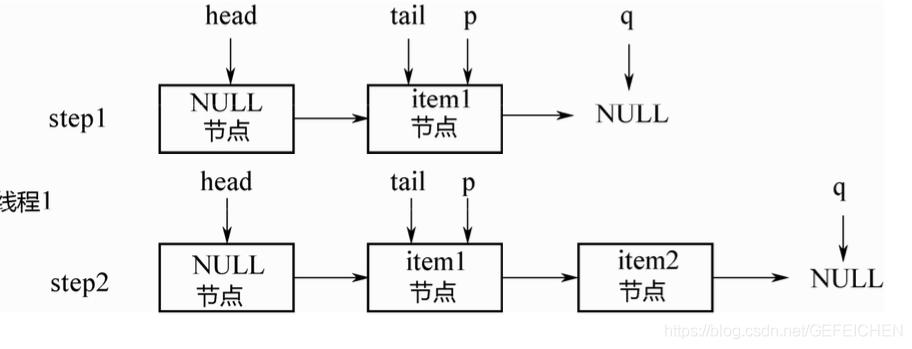
Then, suppose that thread 2 wants to join the item3 node, as shown in the following figure:
step3:p=tail,q=p.next.
step4:q!=NULL, so new nodes will not be queued. p. Q is shifted back by 1 bit.
step5:q=NULL, perform CAS operation on p's next and queue the item3 node.
step6:p!=t. If the conditions are met, execute the above casTail operation, and move the tail back 2 positions to reach the end of the queue.

Finally, summarize the two key points of entering the queue:
- Even if the tail pointer does not move, as long as the CAS operation is successfully performed on the next pointer of p, it will be successfully queued.
- Only when p= The tail pointer will be moved back only when the tail is. That is, the tail pointer is moved back once every 2 consecutive nodes are added. Even if CAS fails, it doesn't matter. The next thread can move the tail pointer.
3. Out of queue
As mentioned above, after entering the queue, the tail pointer does not change. Will there be a case that after entering the queue, there are no elements to exit the queue?
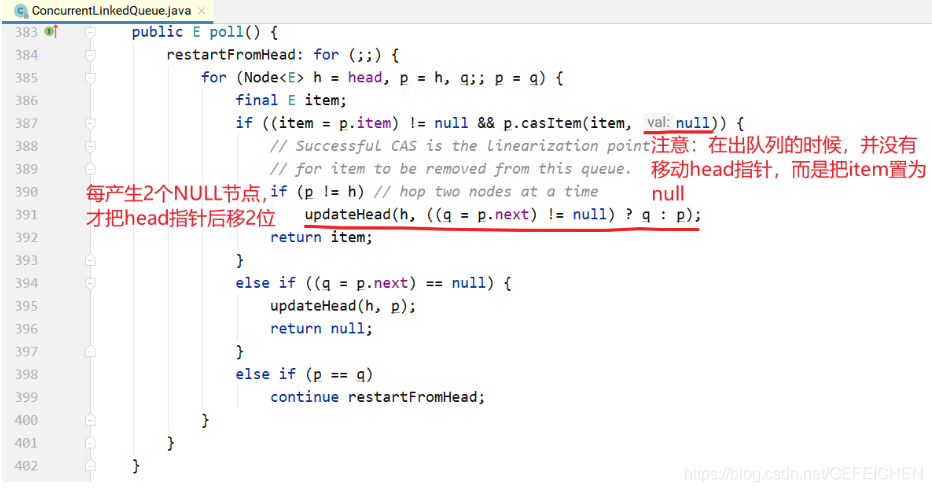 The code of outgoing queue is similar to that of incoming queue. There are also p and q2 pointers. The whole change process is shown in Figure 5-8. It is assumed that at the beginning, the head points to an empty node, and there are three nodes item1, item2 and item3 in the queue.
The code of outgoing queue is similar to that of incoming queue. There are also p and q2 pointers. The whole change process is shown in Figure 5-8. It is assumed that at the beginning, the head points to an empty node, and there are three nodes item1, item2 and item3 in the queue.
step1:p=head,q=p.next.p!=q.
Step 2: move the p pointer back so that p=q.
step3: out of queue. Key point: the item1 node is not directly deleted here, but the item of the node is set to NULL through CAS operation.
step4:p!=head. At this time, there are two NULL nodes in the queue. Move the head pointer forward again and perform updateHead operation on it.
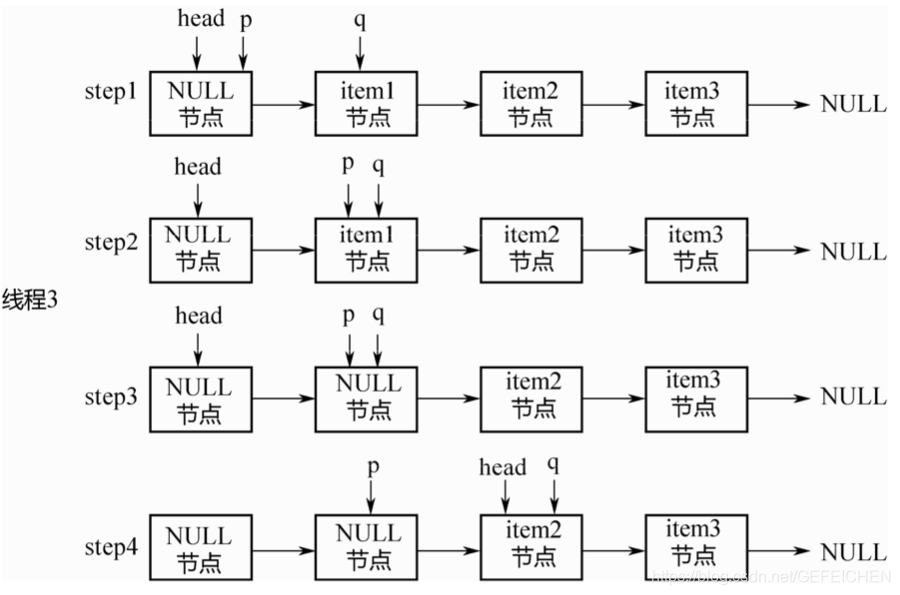
Finally, summarize the key points of the queue:
- The out of queue judgment does not observe the position of the tail pointer, but depends on whether the subsequent node of the head pointer is NULL.
- As long as the CAS operation is performed on the item of the node and it is set to NULL, the queue exit is successful. Even if the head pointer does not move successfully, it can be completed by the next thread.
4. Empty queue
Because the head/tail does not exactly point to the head and tail of the queue, you cannot simply compare the head/tail pointer to determine whether the queue is empty. Instead, you need to traverse from the head pointer to find the first node that is not NULL. If found, the queue is not empty; If not found, the queue is empty. The code is as follows:
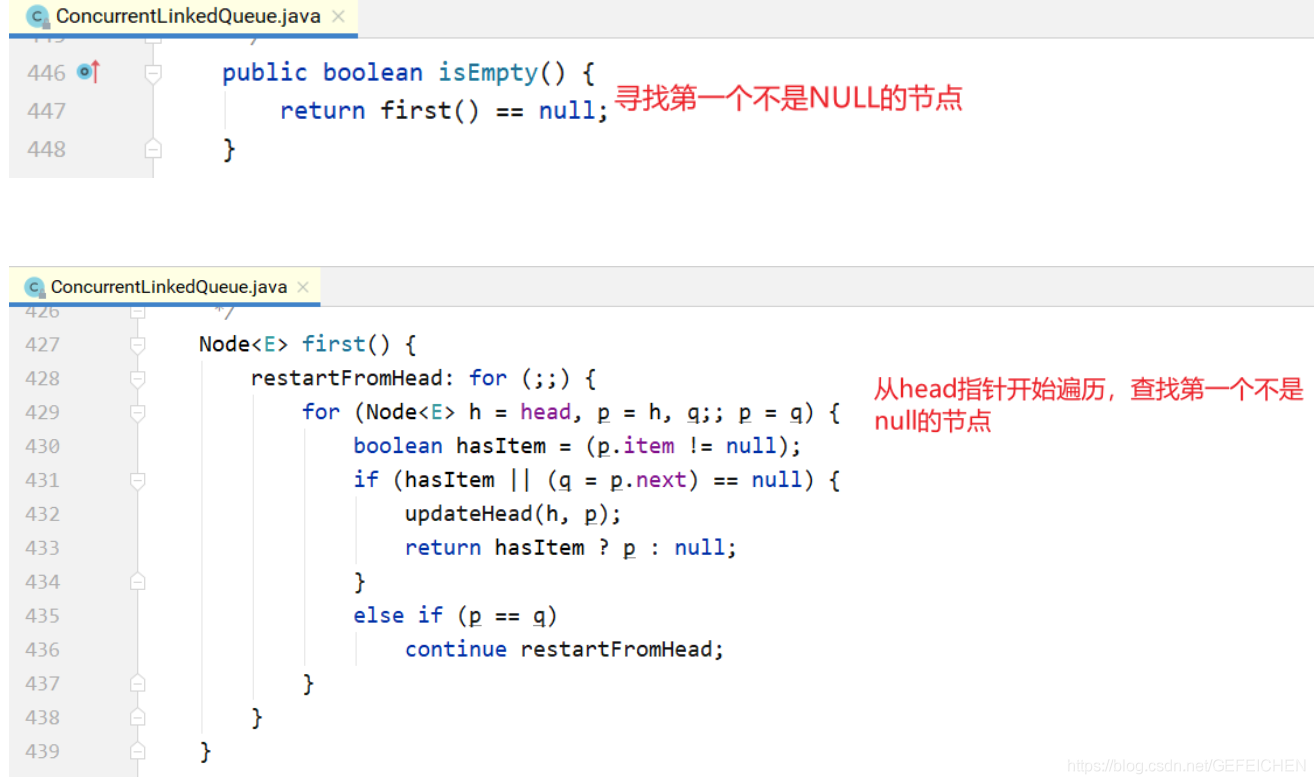
5.5 ConcurrentHashMap
The usual implementation of HashMap is "array + linked list", which is called "zipper method". Concurrent HashMap makes various optimizations based on this basic principle.
First, all data is placed in a large HashMap; The second is the introduction of red and black trees.
Its principle is shown in the figure below:
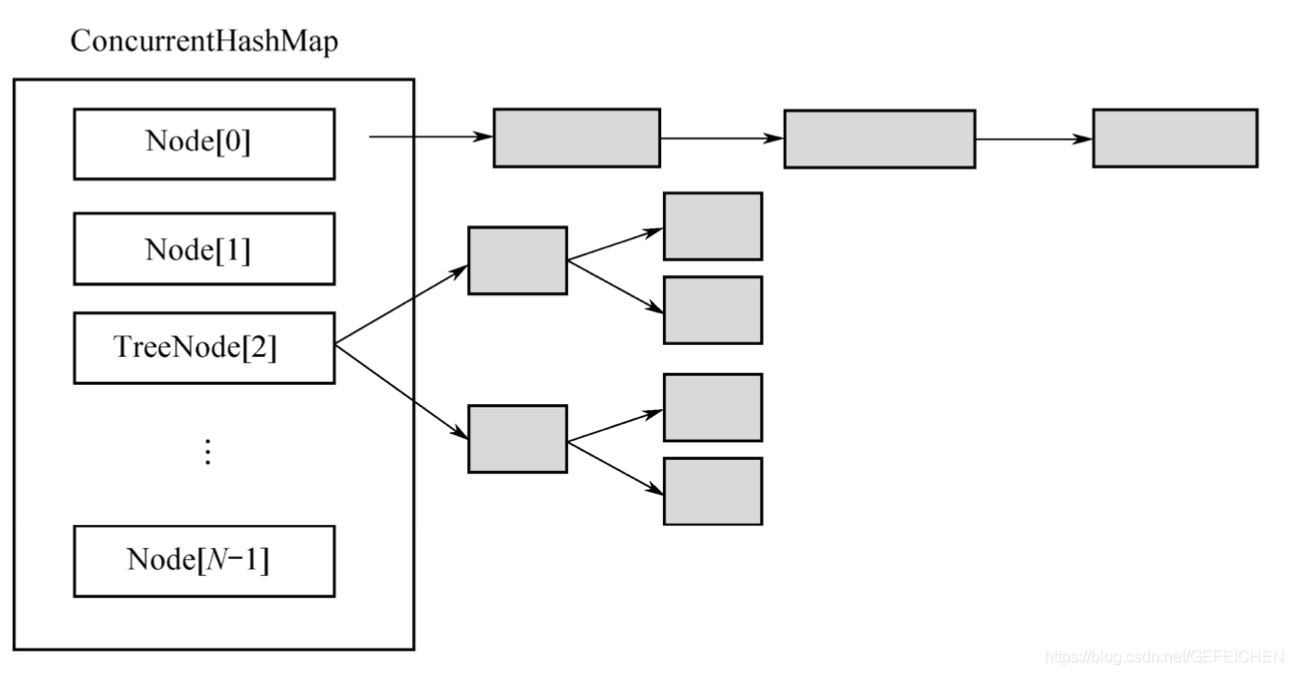 If the head Node is of Node type, it is followed by an ordinary linked list;
If the head Node is of Node type, it is followed by an ordinary linked list;
If the head Node is of TreeNode type, it is followed by a red black tree. TreeNode is a subclass of Node.
The linked list and red black tree can be converted to each other: the initial time is the linked list. When the elements in the linked list exceed a certain threshold, the linked list is converted into a red black tree; On the contrary, when the number of elements in the red black tree is less than a certain threshold, it is converted to a linked list.
Then why do you do this design?
- Using the red black tree, when there are many elements in a slot, its query and update speed will be much faster than the linked list, and the problem of Hash conflict can be better solved.
- The granularity of locking is not the entire ConcurrentHashMap, but each head Node is locked separately, that is, the concurrency is the length of the Node array, and the initial length is 16.
- Concurrent capacity expansion is the most difficult. When a thread wants to expand the Node array, other threads have to read and write, so the processing process is very complex, which will be analyzed in detail later.
It can be concluded from the above comparison: on the one hand, this design reduces Hash conflict, on the other hand, it also improves concurrency.
Next, start with the construction method and analyze its implementation step by step.
1. Analysis of construction method


In the above code, the variable cap is the length of the Node array, which is maintained to the integer power of 2. The tableSizeFor(...) method calculates an appropriate array length according to the initial capacity passed in. Specifically, 1.5 times the initial capacity + 1, and then take the nearest integer power of 2 as the initial value of the array length cap.
sizeCtl here means to control the number of threads during initialization or concurrent capacity expansion, but its initial value is set to cap.
2. Initialization
In the above construction method, only the initial size of the array is calculated, and the array is not initialized. When multiple threads put elements into it, it is initialized. There is a problem: multiple threads are initialized repeatedly. Let's see how it is handled.
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // Spin waiting
else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) { // Important: set sizeCtl to - 1
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; // initialization
table = tab = nt;
// sizeCtl is not an array length, so after successful initialization, it will no longer be equal to the array length
// Instead, N - (n > > > 2) = 0.75n, indicating the threshold of next capacity expansion: n-n/4
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc; // Set the value of sizeCtl to sc.
}
break;
}
}
return tab;
}
As can be seen from the above code, the competition of multiple threads is realized by CAS operation on sizeCtl. If a thread successfully sets sizeCtl to - 1, it has the right to initialize, enter the initialized code module, wait until initialization is completed, and then set sizeCtl back; Other threads keep executing the while loop and spin waiting until the array is not null, that is, when initialization ends, exit the whole method.
Because the workload of initialization is very small, the strategy selected here is to keep other threads waiting without helping them initialize.
3.put(...) implementation analysis

final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
// Branch 1: entire array initialization
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// Branch 2: initialization of the ith element
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
// Branch 3: capacity expansion
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
// Branch 4: put element
else {
V oldVal = null; // Key points: locking
synchronized (f) {
// Linked list
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) { //Red black tree
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
// If it is a linked list, the binCount above will always accumulate
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i); // Beyond the threshold, convert to red black tree
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount); // The total number of elements is accumulated by 1
return null;
}
The for loop above has four large branches:
The first branch is the initialization of the entire array, as mentioned earlier;
The second branch is that the slot is empty, indicating that the element is the first element of the slot. Directly create a new header node and return;
The third branch indicates that the slot is being expanded to help it expand;
The fourth branch is to put elements into slots. The slot may be a linked list or a red black tree, which can be determined by the type of head node. The fourth branch is wrapped in synchronized (f). F corresponds to the header node of the array subscript position, which means that each array element has a lock, and the concurrency is equal to the length of the array.
The binCount above indicates the number of elements in the linked list. When the number exceeds treeify_ When threshold = 8, convert the linked list into a red black tree, that is, the treeifyBin(tab, i) method. However, within this method, red black tree conversion is not necessary, and only capacity expansion may be performed, so let's start with capacity expansion.
4. Capacity expansion
The implementation of capacity expansion is the most complex. Let's start with treeifybin (node < K, V > [] tab, int index).
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
// If the array length is less than the threshold value of 64, no red black tree conversion is performed and the capacity is expanded directly
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
// Convert linked list to red black tree
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
// Traverse the linked list and initialize the red black tree
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd))
}
}
}
}
}
In the above code, min_ TREEIFY_ Capability = 64, which means that when the length of the array does not exceed 64, each node of the array is a linked list, which will only be expanded and will not be converted into a red black tree. Only when the array length is greater than or equal to 64 can we consider converting the linked list into a red black tree.




This method is very complex. It is analyzed step by step as follows:
-
The basic principle of capacity expansion is shown in the figure below. First, build a new HashMap whose array length is twice the length of the old array, and then migrate the old elements one by one. Therefore, the above method has two parameters. The first parameter tab is the HashMap before capacity expansion, and the second parameter nextTab is the HashMap after capacity expansion. When nextTab=null, the method initially initializes nextTab. Here is a key point to note: this method will be called by multiple threads, so each thread only expands the old HashMap part, which involves how to divide tasks.
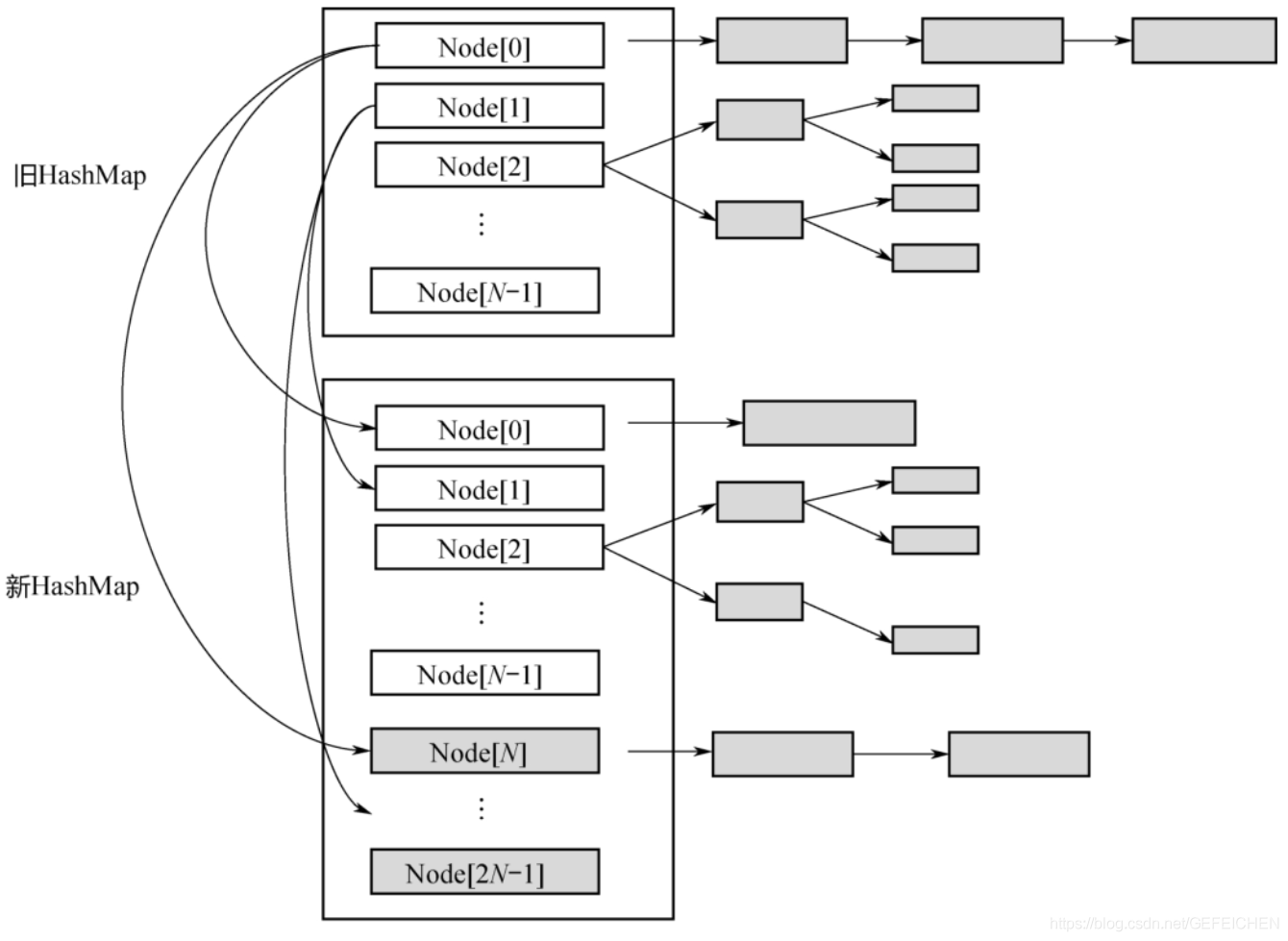
-
The figure above shows the parallel capacity expansion task division of multiple threads. The length of the old array is N, and each thread expands a section. The length of a section is expressed by the variable stripe (step length), and transferIndex represents the progress of the expansion of the whole array.
The calculation formula of stripe is shown in the above code, that is, in the single core mode, it is directly equal to N, because in the single core mode, there is no way to expand the capacity of multiple threads in parallel, and only one thread is needed to expand the entire array; (n > > > 3) / ncpu in multi-core mode, and the minimum step size is 16. Obviously, the number of threads required is about n / stripe.

transferIndex is a member variable of ConcurrentHashMap, which records the expansion progress. The initial value is n, from large to small, reduce stripe positions each time, and finally reduce to n < = 0, indicating that the whole expansion is completed. Therefore, the position from [0, transferIndex-1] indicates the part that has not been allocated to the thread for capacity expansion, and the position from [transferIndex, n-1] indicates that it has been allocated to a thread for capacity expansion, is currently in the process of capacity expansion, or has been successfully expanded.
Because transferIndex will be modified by multiple threads concurrently, minus stripe each time, it needs to be operated through CAS, as shown in the following code.

-
Before the expansion is completed, some slots corresponding to the array subscript have been migrated to the new HashMap, and some are still in the old HashMap. At this time, all threads calling get(k, v) will still access the old HashMap. What should I do?
The following figure shows the forwarding diagram during capacity expansion: when Node[0] has been migrated successfully and other nodes are still migrating, if a thread wants to read the data of Node[0], the access will fail. To this end, create a ForwardingNode, that is, a forwarding Node. In this Node, the reference of the new ConcurrentHashMap is recorded. In this way, when the thread accesses the ForwardingNode, it will query the new ConcurrentHashMap. -
Because the length of the array is tab Length is an integer power of 2, and each expansion is twice. The Hash function is hashcode% tab Length, equivalent to hashcode & (tab.length-1). This means that the element in position i must be in position i or i+n in the array of the new Hash table, as shown in the following figure.
For a simple example: suppose the length of the array is 8, and after the expansion is 16:
If hashCode=5, 5% 8 = 0, after capacity expansion, 5% 16 = 0, the position remains unchanged;
If hashCode=24, 24% 8 = 0, after capacity expansion, 24% 16 = 8, move back 8 positions;
If hashCode=25, 25% 8 = 1, after capacity expansion, 25% 16 = 9, move back 8 positions;
If hashCode=39, 39% 8 = 7, after capacity expansion, 39% 8 = 7, the position remains unchanged;
...

Because of this rule, there are codes as follows:

That is, reassemble the linked list or red black tree of tab[i] into two parts, one is linked to the position of nextTab[i], and the other is linked to the position of nextTab[i+n], as shown in the above figure. Then point the position of tab[i] to a ForwardingNode node.At the same time, when the tab[i] is followed by a linked list, the optimization method similar to that in JDK 7 during capacity expansion is used. All nodes from lastRun do not need to be copied in turn, but are directly linked to the new linked list header. All nodes from lastRun forward need to be copied in turn.
After understanding the core migration function transfer(tab, nextTab), look back at the tryprevize (int size) function. The input of this function is the number of elements of the entire Hash table. In the function, expand the entire Hash table as needed. To understand this function, you need to thoroughly understand the sizeCtl variable. The following comment is taken from the source code.

When sizecl = - 1, it means that the whole HashMap is initializing;
When sizecl = some other negative number, it indicates that multiple threads are concurrently expanding HashMap;
When sizeCtl=cap, tab=null, indicating the initial capacity before initialization (as shown in the constructor above);
After the capacity expansion is successful, sizeCtl stores the threshold of the next capacity expansion, that is, N - (n > > > 2) = 0.75n in the initialization code above.
Therefore, sizeCtl variables express different meanings when the Hash table is in different states. After understanding this, let's look at the tryprevize (int size) function above.

Tryprevize (int size) is to expand the entire Hash table according to the expected number of elements. The core is to call the transfer function. During the first capacity expansion, sizeCtl will be set to a large negative number U.compareAndSwapInt(this, sizeCtl, sc, (RS < < resize_stamp_shift) + 2); After that, when each thread is expanded, sizecl will be increased by 1, U.compareAndSwapInt(this, sizecl, sc, sc+1). After the expansion is completed, sizecl will be reduced by 1.
5.6 ConcurrentSkipListMap/Set
ConcurrentHashMap is a HashMap with disordered keys, while ConcurrentSkipListMap is an orderly key. It implements the NavigableMap interface, which inherits the SortedMap interface.
5.6.1 ConcurrentSkipListMap
1. Why use SkipList to implement Map?
In the util package of Java, there is a non thread safe HashMap, that is, TreeMap, which is key ordered and implemented based on red black tree.
In the Concurrent package, the provided key ordered HashMap, that is, ConcurrentSkipListMap, is implemented based on skiplist (skip table). Why not use red black tree instead of jump look-up table?
To borrow Doug Lea's words:
The reason is that there are no known efficient lock0free insertion and deletion algorithms for search trees.
That is, at present, there is no efficient, lock free method to add and delete nodes in the computer field.
So why can SkipList add and delete nodes without locks? This should start with the implementation of chainless table.
2. Chainless table
In the previous explanation of AQS, the lock free queue was repeatedly used, and its implementation is also a linked list. What is the difference between the two?
The lock free queue and stack mentioned above are CAS operations only at the head and tail of the queue, and there is usually no problem. If you insert or delete in the middle of the linked list, problems will occur according to the usual CAS practice!
Doug Lea's paper clearly discusses this issue, which is quoted here as follows:
Operation 1: insert node 20 after node 10. As shown in the following figure, first point the next pointer of node 20 to node 30, and then perform CAS operation on the next pointer of node 10 to point to node 20.
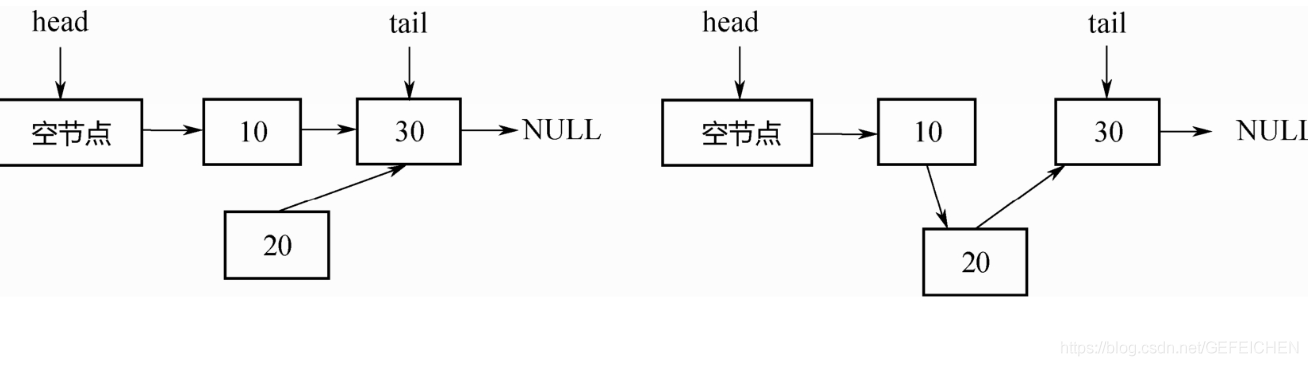
Action 2: delete node 10. As shown in the figure below, just take the next pointer of the head node and perform CAS operation to node 30.

However, if two threads operate at the same time, one deletes node 10 and the other inserts node 20 after node 10. And these two operations are CAS respectively, so a problem will occur at this time. As shown in the figure below, deleting node 10 will delete the newly inserted node 20 at the same time! This problem is beyond the scope of CAS.
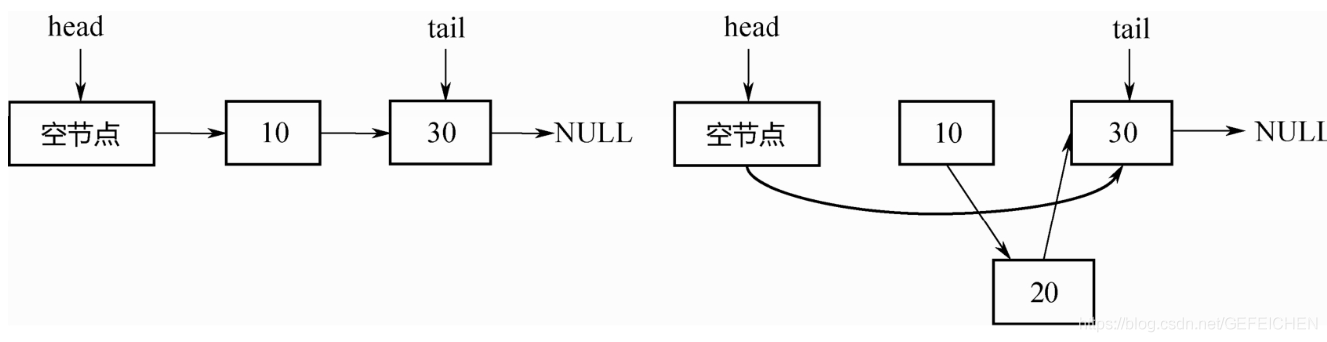
Why is this problem?
The reason: when deleting node 10, the actual operation is the precursor of node 10, that is, the head node. Node 10 itself has not changed. Therefore, if you insert the thread of node 20 after node 10, you don't know that node 10 has been deleted!
To solve this problem, the following solutions are proposed in the paper. As shown in the figure below, the deletion of node 10 is divided into two 2 steps:
In the first step, mark the next pointer of node 10 as delete, that is, soft delete;
The second step is to find an opportunity to physically delete.
After marking, when the thread inserts node 20 after node 10, it can first judge whether node 10 has been deleted, so as to avoid inserting node 20 after a deleted node 10. This solution has a key point: "point the next pointer of node 10 to node 20 (insertion operation)" and "judge whether node 10 itself has been deleted (judgment operation)", which must be atomic and must be completed in one CAS operation!

There are two ways to achieve this:
Method 1: AtomicMarkableReference
Ensure that each next is of type AtomicMarkableReference. But this method is not efficient enough. Doug Lea uses another method in the implementation of ConcurrentSkipListMap.
Method 2:Mark node
Our purpose is to mark that node 10 has been deleted, that is, to mark its next field. Then a new marker node can be created so that the next pointer of node 10 points to the marker node. In this way, when inserting node 20 behind node 10, you can judge whether the next pointer of node 10 points to a marker node while inserting. These two operations can be completed in one CAS operation.
3. Skip table
It solves the problem of inserting or deleting the chainless table, and also solves a key problem of skip look-up table. Because the jump look-up table is a multi-layer linked list.
Let's take a look at the data structure of the jump look-up table first (the codes used below are all quoted from JDK 7, and the codes in JDK 8 are slightly different, but do not affect the following principle analysis).
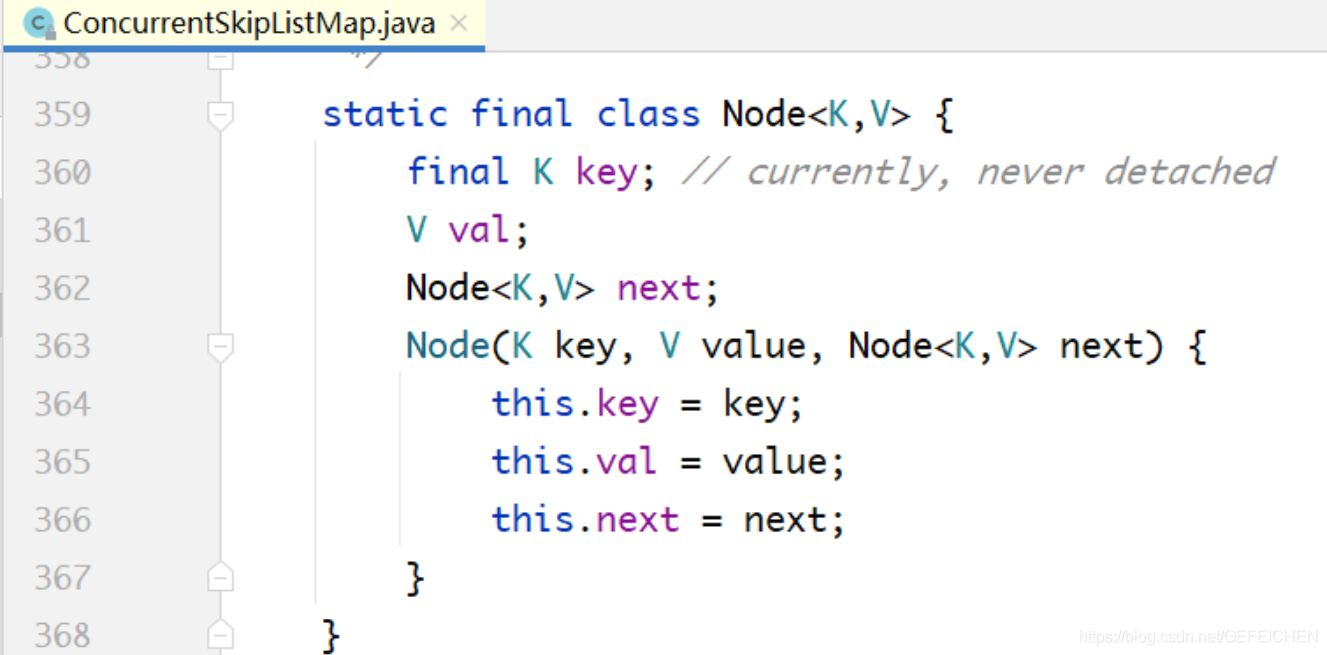
The Node in the figure above is the underlying Node type of the jump query table. All < K, V > pairs are linked by this one-way linked list.
Nodes of the Index layer above:
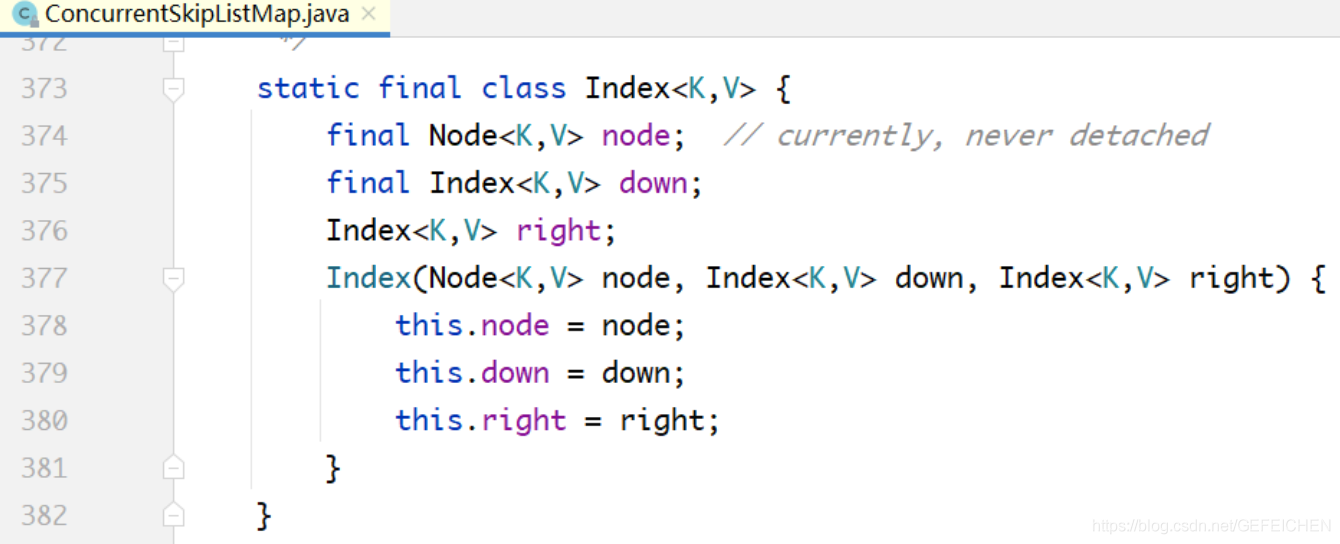
The node attribute in the figure above does not store actual data, but points to the node.
down attribute: each Index node must have a pointer to the node corresponding to its next Level.
right attribute: Index also forms a one-way linked list.
The entire ConcurrentSkipListMap only needs to record the top-level head node:

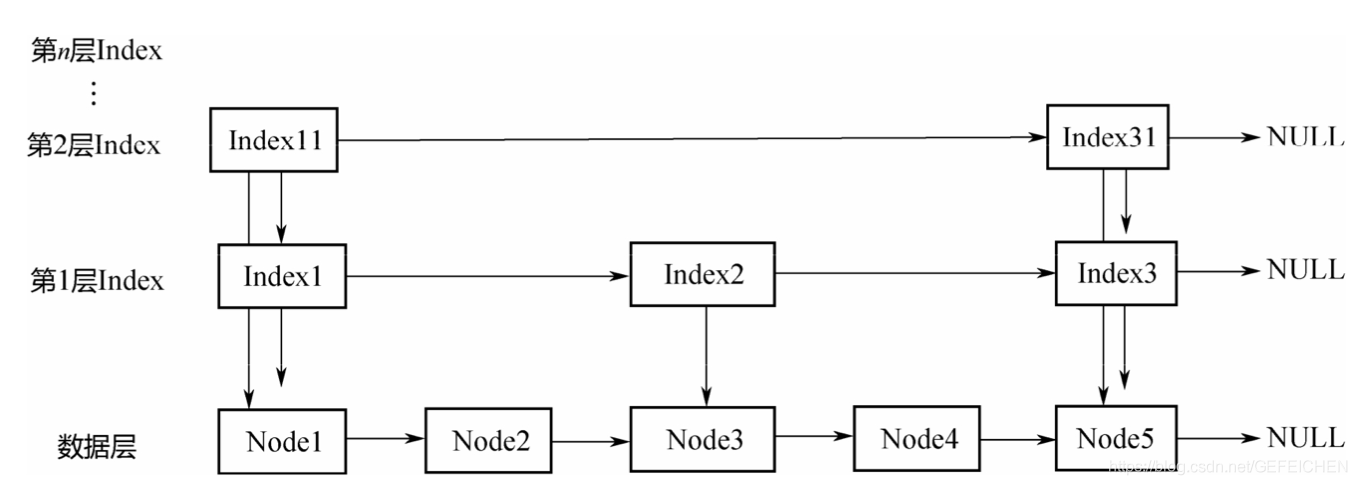
The following is a detailed analysis of how to find, insert and delete elements from the jump table.
-
put implementation analysis


At the bottom layer, the nodes are arranged in the order from small to large, and the index layers above are strung together at intervals, because they are arranged from small to large. When searching, start from the top index, from left to right and from top to bottom to form the traversal curve shown in the figure. Assuming that the element to be searched is 32, the traversal process is as follows:First traverse the Index of the second layer and find it behind 21;
Descend from 21 to the Index of the first layer, traverse back from 21, and find that it is between 21 and 35;
Descend from 21 to the bottom, traverse back from 21, and finally find that it is between 29 and 35.In the whole search process, the range is shrinking, and finally located between the two elements of the bottom layer.

There is a key point to note about the put(...) method above: after finding the element to be inserted between [b, n] through findPredecessor, it cannot be inserted immediately. Because other threads are also operating the linked list, B and N may be deleted, so a series of check logic is executed before insertion, which is the complexity of the chainless list.
-
remove(...) analysis

The logic of the above deletion method is very similar to that of the insertion method, because whether inserting or deleting, you must first find the precursor of the element, that is, locate the interval where the element is located [b, n]. After positioning, perform the following steps:- If it is found that b and n have been deleted, execute the corresponding deletion cleaning logic;
- Otherwise, if the (k, v) to be deleted is not found, null is returned;
- If the element to be deleted, that is, node n, is found, set the value of n to null, add the Marker node after n, and check whether the Index level needs to be reduced.
-
get analysis

Whether inserting, deleting or searching, there are similar logic. You need to locate the element position [b, n] first, and then judge whether B and n have been deleted. If so, you need to execute the corresponding deletion cleaning logic. This is where the chainless table is complex.
5.6.2 ConcurrentSkipListSet
