
Author: Xiao Fu Ge
Blog: https://bugstack.cn
Precipitate, share and grow, so that you and others can gain something! 😄
1, Foreword
what? Java interview is like building a rocket 🚀

Simple! In the past, I always wanted to have a good interview in Java interview. GAHA always tests some things that can't be used in work. I can use Spring, MyBatis, Dubbo and MQ to realize the business requirements!
But after working for a few years, when I need to improve myself (I need to add money), I even began to feel that I was just a tool person who called the API to save the interface. There is no breadth of knowledge, no depth of technology, I can't think of it, and I don't realize it. I refine the common logic in the daily development business code and develop it into common components, and I don't think about what technology is used to realize some components in daily use.
So sometimes you say that the interview is like building a rocket. These technologies are not used at all. In fact, many times, it is not because this technology is not used, but because you are useless (well, I didn't use it before). When you have this idea and want to break through your salary bottleneck, you need to understand the necessary data structure, learn the algorithm logic of Java, be familiar with the general design pattern, and then combine the source code implementation logic such as Spring, ORM and RPC to enable the corresponding technical scheme to your daily business development, Solve common problems in a focused and refined way, which is the embodiment of your ability outside CRUD (salary chips).
Yes? It sounds reasonable. Let's take a chestnut for a demand analysis and logical implementation of database routing!
2, Demand analysis
If you want to do a database routing, what technical points do you need to do?
First of all, we need to know why we should use sub database and sub table. In fact, due to the large business volume and rapid data growth, we need to split user data into different database and tables to reduce the pressure on the database.
The operations of splitting databases and tables mainly include vertical splitting and horizontal splitting:
- Vertical splitting: it refers to classifying tables according to business and distributing them to different databases, so as to share the pressure of data to different databases. Finally, a database is composed of many tables, and each table corresponds to different businesses, that is, special database.
- Horizontal split: if a stand-alone bottleneck is encountered after vertical split, horizontal split can be used. Compared with vertical splitting, vertical splitting is to split different tables into different databases, while horizontal splitting is to split the same table into different databases. For example: user_001,user_002
In this chapter, we also want to realize the routing design of horizontal splitting, as shown in Figure 1-1

So, what technical knowledge points should such a database routing design include?
- This is about the use of AOP aspect interception, because the method of using database routing needs to be marked to facilitate the processing of database and table logic.
- Since there are sub databases, the switching operation of data sources will involve link switching between multiple data sources in order to allocate data to different databases.
- Database table addressing operation. Index calculation is required for which database and table a piece of data is allocated. In the process of method call, it is finally recorded through ThreadLocal.
- In order to distribute data evenly to different database tables, we also need to consider how to perform data hashing. After database and table splitting, let the data be concentrated in a table of a database, which will lose the significance of database and table splitting.
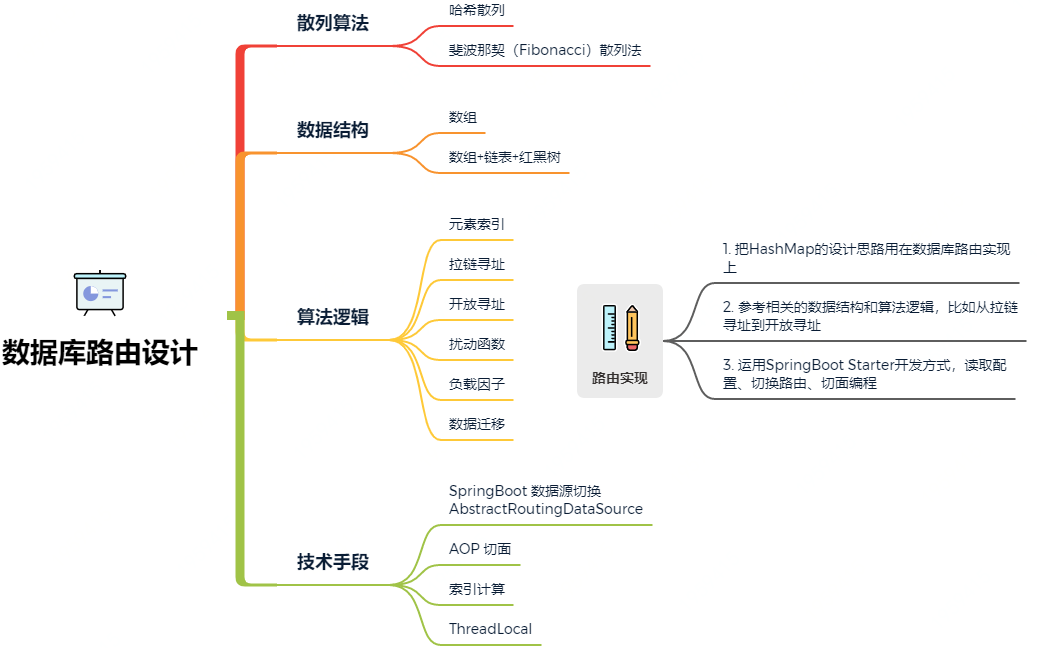
To sum up, we can see that the data storage is completed under the data structure of database and table. The technologies I need to use include AOP, data source switching, hash algorithm, hash addressing, ThreadLocal and SpringBoot's Starter development method. In fact, such technologies as hash hash, addressing and data storage have too many similarities with HashMap, so there is a chance to build a rocket after learning the source code. If you have deeply analyzed and studied the HashMap source code, Spring source code and middleware development, you will have a lot of ideas when designing such database routing components. Next, let's try to learn from the source code to build rockets!
3, Technical research
In the JDK source code, the data structure design includes: array, linked list, Queue, Stack and red black tree. The specific implementation includes ArrayList, LinkedList, Queue and Stack. These data are stored in sequence and are not processed by hash index. HashMap and ThreadLocal use hash index, hash algorithm, zipper addressing and open addressing when data expands, so we will focus on these two functions for analysis and reference.
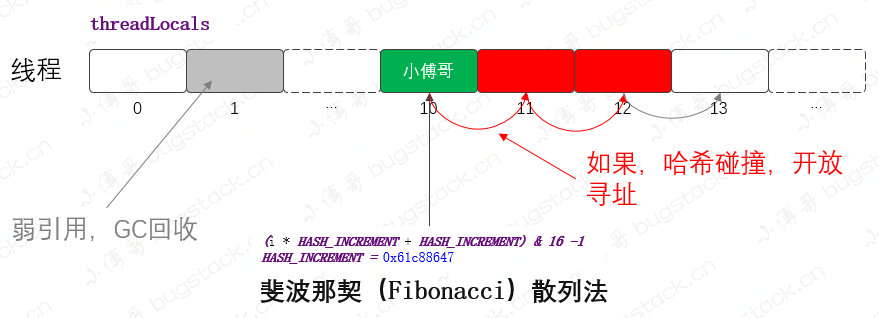
1. ThreadLocal
@Test
public void test_idx() {
int hashCode = 0;
for (int i = 0; i < 16; i++) {
hashCode = i * 0x61c88647 + 0x61c88647;
int idx = hashCode & 15;
System.out.println("Fibonacci hash:" + idx + " Normal hash:" + (String.valueOf(i).hashCode() & 15));
}
}
Fibonacci hash: 7 normal hash: 0
Fibonacci hash: 14 general hash: 1
Fibonacci hash: 5 general hash: 2
Fibonacci hash: 12 normal hash: 3
Fibonacci hash: 3 ordinary hash: 4
Fibonacci hash: 10 normal hash: 5
Fibonacci hash: 1 General hash: 6
Fibonacci hash: 8 normal hash: 7
Fibonacci hash: 15 normal hash: 8
Fibonacci hash: 6 normal hash: 9
Fibonacci hash: 13 normal hash: 15
Fibonacci hash: 4 normal hash: 0
Fibonacci hash: 11 normal hash: 1
Fibonacci hash: 2 normal hash: 2
Fibonacci hash: 9 normal hash: 3
Fibonacci hash: 0 normal hash: 4
- Data structure: array structure of hash table
- Hash algorithm: Fibonacci hash method
- Addressing mode: Fibonacci hashing method can make the data more dispersed, open addressing in case of data collision, and find the location from the collision node to store the elements. Formula: F (k) = ((k * 2654435769) > > x) < < y for common 32-bit integers, that is, f (k) = (k * 2654435769) > > 28, golden section point: (√ 5 - 1) / 2 = 0.6180339887 1.618:1 = = 1:0.618
- What to learn: you can refer to the addressing mode and hash algorithm, but this data structure is quite different from the structure to be designed and implemented on the database, but ThreadLocal can be used to store and transfer data index information.
2. HashMap

public static int disturbHashIdx(String key, int size) {
return (size - 1) & (key.hashCode() ^ (key.hashCode() >>> 16));
}
- Data structure: hash bucket array + linked list + red black tree
- Hash algorithm: perturbation function and hash index can make the data more hash distributed
- Addressing mode: solve data collision through zipper addressing. Index address will be carried out during data storage. In case of collision, data linked list will be generated, and capacity expansion or tree will be carried out for more than 8 elements in a certain capacity.
- What to learn: hash algorithm and addressing mode can be applied to the design and implementation of database routing, as well as the whole array + linked list mode. In fact, the library + table mode is also similar.
4, Design and Implementation
1. Define route annotation
definition
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface DBRouter {
String key() default "";
}
use
@Mapper
public interface IUserDao {
@DBRouter(key = "userId")
User queryUserInfoByUserId(User req);
@DBRouter(key = "userId")
void insertUser(User req);
}
- First, we need to customize an annotation to be placed on the method to be routed by the database.
- It is used by configuring annotations through methods, which can be intercepted by the AOP aspect specified by us. After interception, the corresponding database routing calculation and judgment are carried out, and the corresponding operation data source is switched.
2. Resolve routing configuration
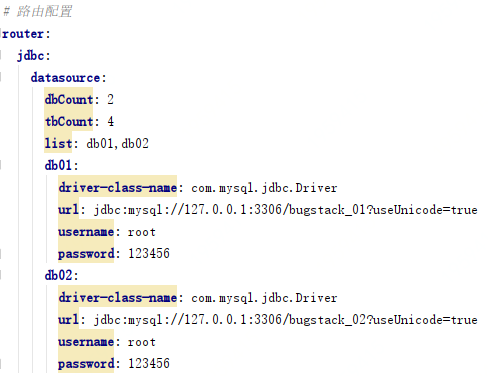
- The above is a data source configuration after we have implemented the database routing component. In the use of data sources under sub database and sub table, we need to support the information configuration of multiple data sources, so as to meet the expansion of different needs.
- For this kind of customized large information configuration, you need to use org springframework. context. Environmentaware interface to obtain the configuration file and extract the required configuration information.
Data source configuration extraction
@Override
public void setEnvironment(Environment environment) {
String prefix = "router.jdbc.datasource.";
dbCount = Integer.valueOf(environment.getProperty(prefix + "dbCount"));
tbCount = Integer.valueOf(environment.getProperty(prefix + "tbCount"));
String dataSources = environment.getProperty(prefix + "list");
for (String dbInfo : dataSources.split(",")) {
Map<String, Object> dataSourceProps = PropertyUtil.handle(environment, prefix + dbInfo, Map.class);
dataSourceMap.put(dbInfo, dataSourceProps);
}
}
- prefix is the beginning information of data source configuration. You can customize the required beginning content.
- dbCount, tbCount, dataSources and dataSourceProps all extract configuration information and store it in dataSourceMap for subsequent use.
3. Data source switching
In the Starter developed in combination with SpringBoot, we need to provide an instantiation object of DataSource. Then we will implement this object in DataSourceAutoConfig, and the data source provided here can be transformed dynamically, that is, it supports dynamic switching of data sources.
create data source
@Bean
public DataSource dataSource() {
// create data source
Map<Object, Object> targetDataSources = new HashMap<>();
for (String dbInfo : dataSourceMap.keySet()) {
Map<String, Object> objMap = dataSourceMap.get(dbInfo);
targetDataSources.put(dbInfo, new DriverManagerDataSource(objMap.get("url").toString(), objMap.get("username").toString(), objMap.get("password").toString()));
}
// set up data sources
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
return dynamicDataSource;
}
- Here is a simplified creation case, which instantiates and creates based on the data source information read from the configuration information.
- After the data source is created, it is stored in DynamicDataSource. It is an implementation class that inherits AbstractRoutingDataSource. This class can store and read the data source information of the corresponding specific call.
4. Section interception
It needs to be completed in the section interception of AOP; Database routing calculation, hash enhancement of disturbance function, calculation of database table index, setting to ThreadLocal to transfer data source. The overall case code is as follows:
@Around("aopPoint() && @annotation(dbRouter)")
public Object doRouter(ProceedingJoinPoint jp, DBRouter dbRouter) throws Throwable {
String dbKey = dbRouter.key();
if (StringUtils.isBlank(dbKey)) throw new RuntimeException("annotation DBRouter key is null!");
// Compute routing
String dbKeyAttr = getAttrValue(dbKey, jp.getArgs());
int size = dbRouterConfig.getDbCount() * dbRouterConfig.getTbCount();
// Disturbance function
int idx = (size - 1) & (dbKeyAttr.hashCode() ^ (dbKeyAttr.hashCode() >>> 16));
// Library table index
int dbIdx = idx / dbRouterConfig.getTbCount() + 1;
int tbIdx = idx - dbRouterConfig.getTbCount() * (dbIdx - 1);
// Set to ThreadLocal
DBContextHolder.setDBKey(String.format("%02d", dbIdx));
DBContextHolder.setTBKey(String.format("%02d", tbIdx));
logger.info("Database routing method: {} dbIdx: {} tbIdx: {}", getMethod(jp).getName(), dbIdx, tbIdx);
// Return results
try {
return jp.proceed();
} finally {
DBContextHolder.clearDBKey();
DBContextHolder.clearTBKey();
}
}
- The simplified core logic implementation code is as above. First, we extract the number of library table products and use them as the same length as HashMap.
- Next, the same perturbation function logic as HashMap is used to make the data more scattered and hashed.
- After calculating an index position on the total length, you also need to convert this position into the database table to see which database and table the index of the total length falls into.
- Finally, the calculated index information is stored in ThreadLocal to pass the index information that can be extracted during method call.
5. Test verification
5.1 library table creation
create database `bugstack_01`; DROP TABLE user_01; CREATE TABLE user_01 ( id bigint NOT NULL AUTO_INCREMENT COMMENT 'Self increasing ID', userId varchar(9) COMMENT 'user ID', userNickName varchar(32) COMMENT 'User nickname', userHead varchar(16) COMMENT 'User Avatar', userPassword varchar(64) COMMENT 'User password', createTime datetime COMMENT 'Creation time', updateTime datetime COMMENT 'Update time', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DROP TABLE user_02; CREATE TABLE user_02 ( id bigint NOT NULL AUTO_INCREMENT COMMENT 'Self increasing ID', userId varchar(9) COMMENT 'user ID', userNickName varchar(32) COMMENT 'User nickname', userHead varchar(16) COMMENT 'User Avatar', userPassword varchar(64) COMMENT 'User password', createTime datetime COMMENT 'Creation time', updateTime datetime COMMENT 'Update time', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DROP TABLE user_03; CREATE TABLE user_03 ( id bigint NOT NULL AUTO_INCREMENT COMMENT 'Self increasing ID', userId varchar(9) COMMENT 'user ID', userNickName varchar(32) COMMENT 'User nickname', userHead varchar(16) COMMENT 'User Avatar', userPassword varchar(64) COMMENT 'User password', createTime datetime COMMENT 'Creation time', updateTime datetime COMMENT 'Update time', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DROP TABLE user_04; CREATE TABLE user_04 ( id bigint NOT NULL AUTO_INCREMENT COMMENT 'Self increasing ID', userId varchar(9) COMMENT 'user ID', userNickName varchar(32) COMMENT 'User nickname', userHead varchar(16) COMMENT 'User Avatar', userPassword varchar(64) COMMENT 'User password', createTime datetime COMMENT 'Creation time', updateTime datetime COMMENT 'Update time', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- Create multiple inventory information with the same table structure, bugstack_01,bugstack_02
5.2 statement configuration
<select id="queryUserInfoByUserId" parameterType="cn.bugstack.middleware.test.infrastructure.po.User"
resultType="cn.bugstack.middleware.test.infrastructure.po.User">
SELECT id, userId, userNickName, userHead, userPassword, createTime
FROM user_${tbIdx}
where userId = #{userId}
</select>
<insert id="insertUser" parameterType="cn.bugstack.middleware.test.infrastructure.po.User">
insert into user_${tbIdx} (id, userId, userNickName, userHead, userPassword,createTime, updateTime)
values (#{id},#{userId},#{userNickName},#{userHead},#{userPassword},now(),now())
</insert>
- In the use of MyBatis statements, the only change is to add a placeholder after the table name, ${tbIdx} to write the current table ID.
5.3 annotation configuration
@DBRouter(key = "userId") User queryUserInfoByUserId(User req); @DBRouter(key = "userId") void insertUser(User req);
- Add annotations to the method that needs to use sub database and sub table. After adding annotations, this method will be managed by AOP.
5.4 unit test
22:38:20.067 INFO 19900 --- [ main] c.b.m.db.router.DBRouterJoinPoint : Database routing method: queryUserInfoByUserId dbIdx: 2 tbIdx: 3
22:38:20.594 INFO 19900 --- [ main] cn.bugstack.middleware.test.ApiTest : Test results:{"createTime":1615908803000,"id":2,"userHead":"01_50","userId":"980765512","userNickName":"Little brother Fu","userPassword":"123456"}
22:38:20.620 INFO 19900 --- [extShutdownHook] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService 'applicationTaskExecutor'1
- The above is a log information when we use our own database routing component. We can see that routing operations are included here. In the 2 library 3 table: database routing method: queryuserinfo byuserid dbidx: 2 tbIdx: 3
5, Summary
To sum up, we learned the internal principle of technology from the learning of HashMap, ThreadLocal, Spring and other source codes, and applied such technology to the design of a database routing. If you haven't experienced the technical precipitation of making rockets, it's almost impossible to successfully develop such a middleware. Most of the time, it's not that the technology is useless, but that you don't have the opportunity to use it. Don't always think about the repeated CRUD, and see what knowledge can really improve your personal ability! reference material: https://codechina.csdn.net/MiddlewareDesign
6, Series recommendation
- "Hand rolling Spring" PDF, 260 pages, 65000 words, sorting and sharing
- Unified white list verification of service governance Middleware
- Develop a distributed im (instant messaging) system!
- Interpretation of Spring Bean IOC and AOP circular dependency
- I wrote 200000 lines of code before graduation, which made me a bully in the eyes of my classmates!