Crawl the historical net value of private placement network and crack the encrypted value
Recently, I crawled the historical net value of private placement online and wrote some experiences in the process of crawling.
There are many difficulties above. For example, if selenium is directly used, anti crawling will be detected, and the crawling value will be encrypted (the value seen on the page is different from that in html, with some hidden values). The crawling methods are mainly selenium, regular and beautiful soup. Here, import the library used here first.
from selenium import webdriver from bs4 import BeautifulSoup from selenium.webdriver.common.by import By import pandas import time import re from lxml import html from selenium.webdriver.common.action_chains import ActionChains # Import mouse event library
Overall process: open the web page, then log in, reach the page to be parsed, get the source code, then crack the encryption, and finally save the output data in excel.
1, Open web page
Some websites can be opened directly by using selenium, for example
driver = webdriver.Chrome() # boot drive
driver.get('https://www.simuwang.com/user/option ') # load web site
However, the following situations will occur here, because if you directly open the web page, you will be found to be a crawler.
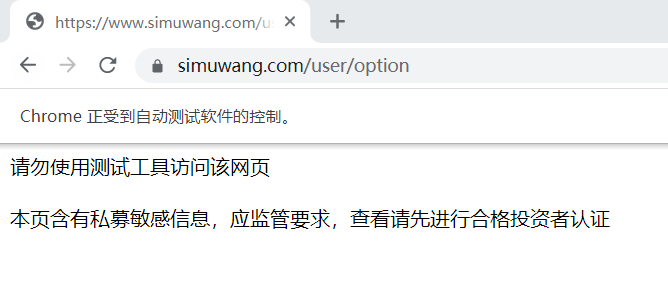
To solve this problem, use the following code
driver = webdriver.Chrome() # boot drive
# Google browser 79 and 79 versions prevent detection
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.get('https://www.simuwang.com/user/option ') # load web site
Finally, you can open the web page perfectly.
Note that it is not feasible to set the developer mode here!
2, selenium positioning element parsing web page
After entering the web page, the element positioning begins. selenium location has eight names, IDS and links_ text,partial_link_text,class_name,xpath,css,tag_name. At least one method, XPath or CSS, should be mastered (using these two methods can basically solve all positioning problems).
For detailed usage, you can visit another article about selenium crawler, which introduces in detail the usage of eight positioning of selenium. Installation and use of Selenium and practical climbing of 51job recruitment website (I) _panda4ublog - CSDN blog
Let's talk about the usage of selenium here. The method I use is xpath.
1. Enter the account and password and click login
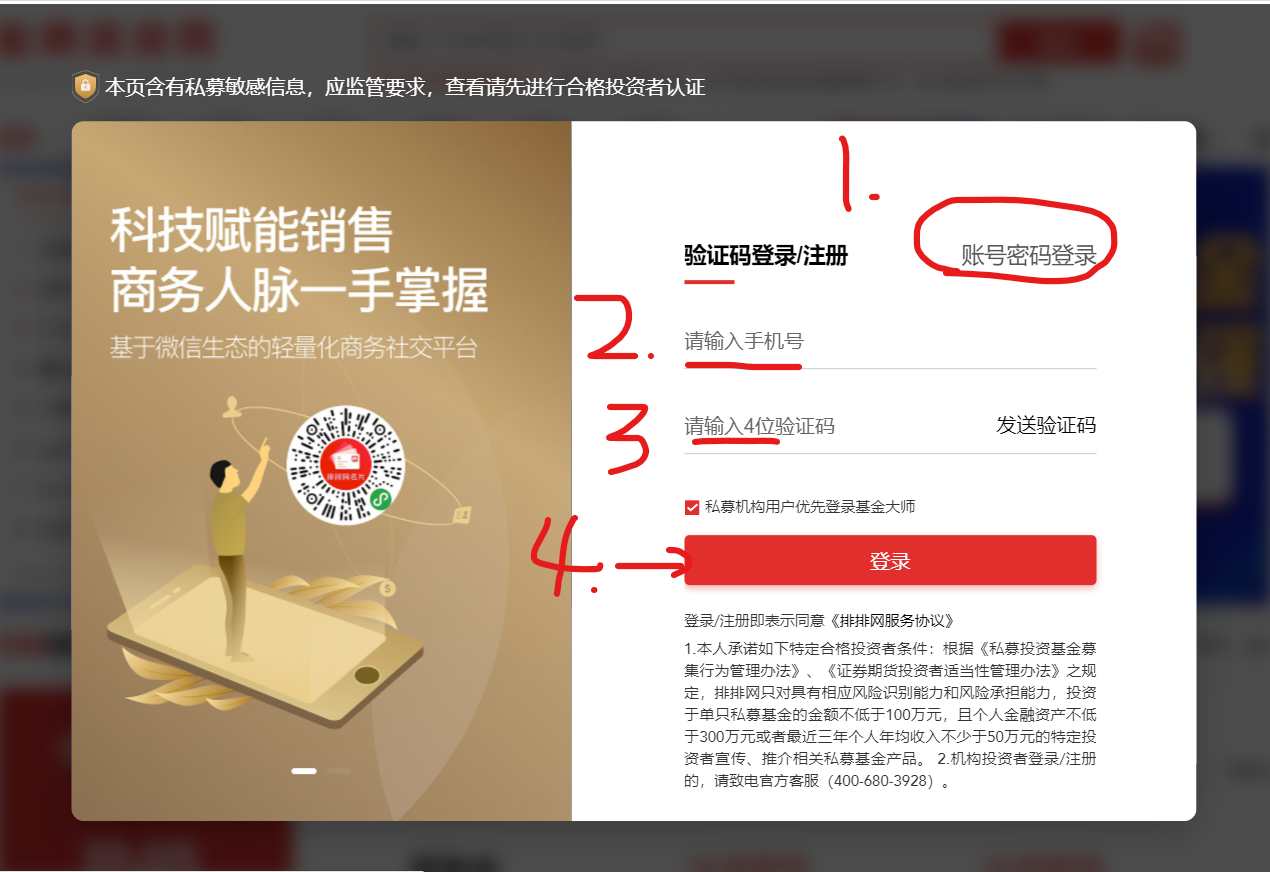
driver.find_element(By.XPATH,'//button[@class="comp-login-method comp-login-b2"]').click() # click the account password to log in
driver.find_element(By.XPATH,'//input[@name="username"]').send_keys('xxxxxxxxxxxx ') # enter the account number
driver.find_element(By.XPATH,'//input[@type="password"]').send_keys('xxxxxxxxxxxx ') # enter the password
driver.find_element(By.XPATH,'//button[@style="margin-top: 65px;"]').click() # Click to log in
Supplement:
(1). It is better to use By (that is, the above method) for positioning in the future, and driver.find_element_by_xpath(), because the latter is not conducive to encapsulation.
(2). What does element positioning do? Why should we locate elements? What's the use?
Element positioning is to find the element corresponding to the content we see in the web page in html. After finding it, you can use mouse events and keyboard events to simulate the web page manually. Here is the simple keyboard event send_keys and mouse event click.
2. Cross off the advertisement and the web page goes back
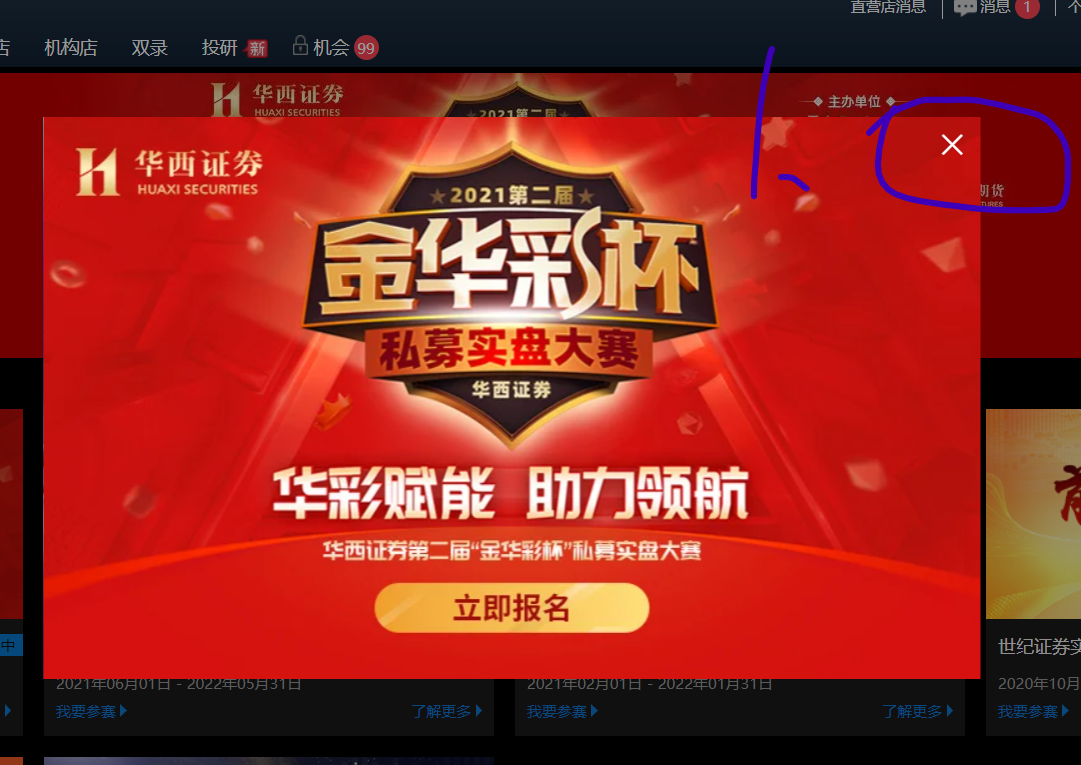
time.sleep(15) # Waiting login time driver.find_element(By.XPATH,'//span[@class="el-icon-close close-icon"]').click() # cross out the advertisement driver.back() # Web page back
Supplement:
(1). Note that you must sleep for a few seconds. That's because the login process takes time to load, otherwise an error will be reported.
(2). driver.back() returns the current page to the previous level. So driver Forward() advances to the previous level.
3. Mouse over and click self selection
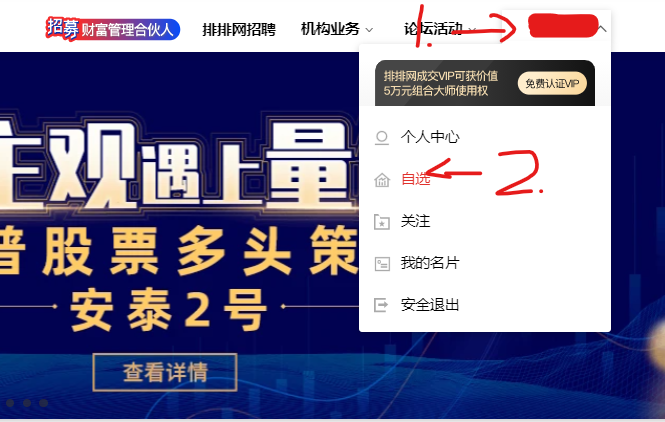
Hover over the user, and then click Select to enter the web page.
time.sleep(5) # Waiting time required to load web pages mouse = driver.find_element(By.XPATH,'//div[@class="comp-header-nav-item fz14"]/div/span[@class="ellipsis"]') ActionChains(driver).move_to_element(mouse).perform() # Hover over the business card driver.find_element(By.XPATH,'//a[@class="comp-header-user-item icon-trade"]').click() # Click to select
The hover operation here is to locate the user, then hover with ActionChains, find the self selection in the hover and click.
4. Analyze web pages
After the above steps, we come to the page where we need to crawl data. We need the historical net value of the data in each fund. So we first need to get the website of each fund, and then enter the website for processing.
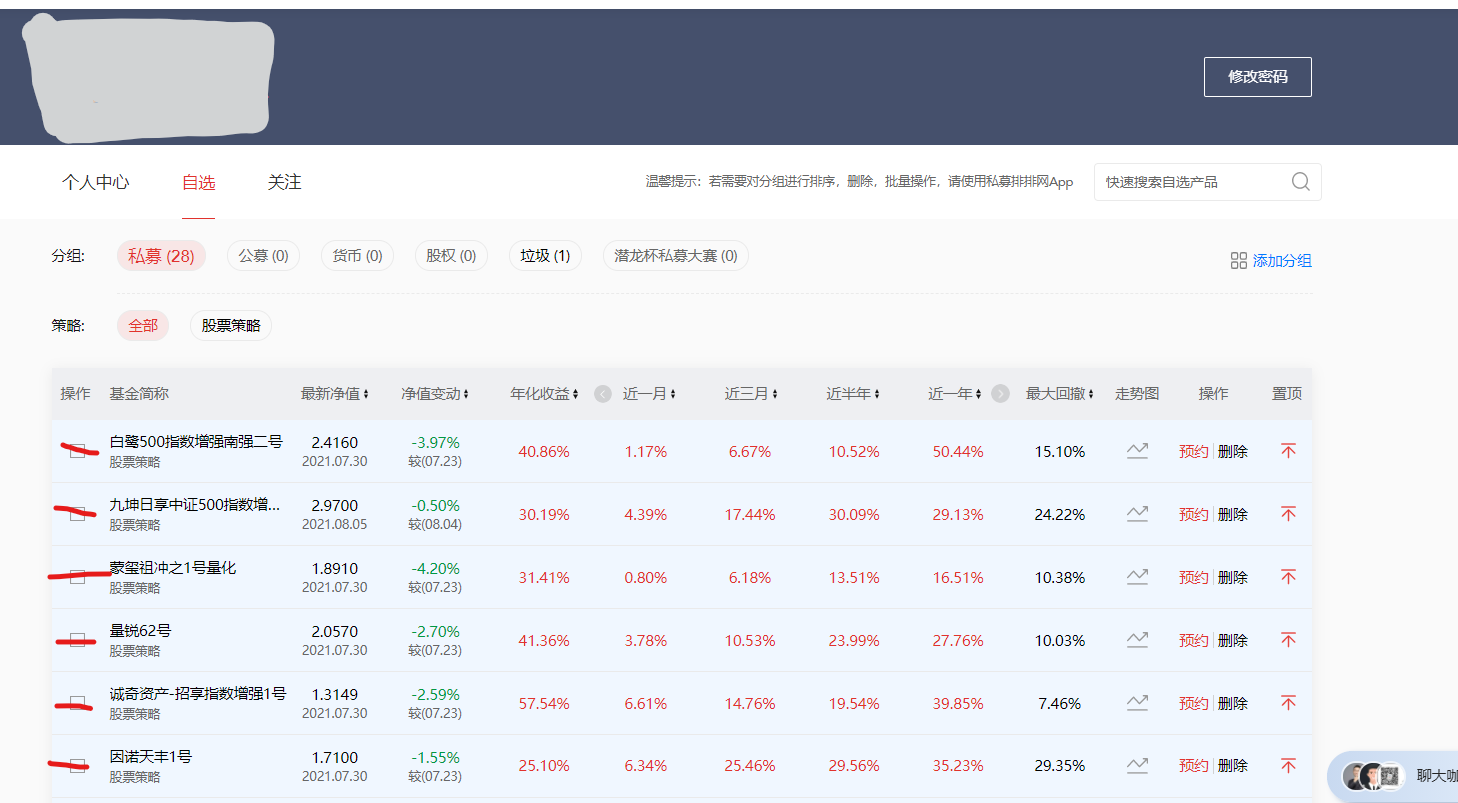
# Parsing web pages
page = driver.page_source
soup = BeautifulSoup(page,'html.parser')
list_url = [] # Used to save the target site
list_name = [] # Name used to save the target
url_a = soup.select('div:nth-child(2) > div.shortName > a') # Find the page you crawled
names = soup.select('div> div > div:nth-child(2) > div.shortName > a') # Name found
for u in url_a:
url = u['href'] # Get website
list_url.append(url)
for name in names:
list_name.append(name.get_text())
Here, the page is parsed with BeautifulSoup, and then the select location is used to find the website address and fund name of each fund.
2, Treatment of each fund
After parsing the web page in the previous step, we can get the website of each fund. Now cycle through these URLs and crawl the data.
1. Analyze each fund web page
Analyze each fund web page or use driver Get loads the web page and uses page_source parses the web page.
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
for ind in range(len(list_name)):
driver.get(list_url[ind]) # Load web site
But on page_ Before parsing the web page, there is one thing you must pay attention to!
That is, if there is only a small part of the historical net value obtained by directly parsing the web page, it is because the historical net value is dynamic. Before parsing, we need to use selenium to slide the embedded box of historical net value to the end, and the embedded box is loaded asynchronously (after sliding, another section will come out). Multiple slides are required to meet the conditions.
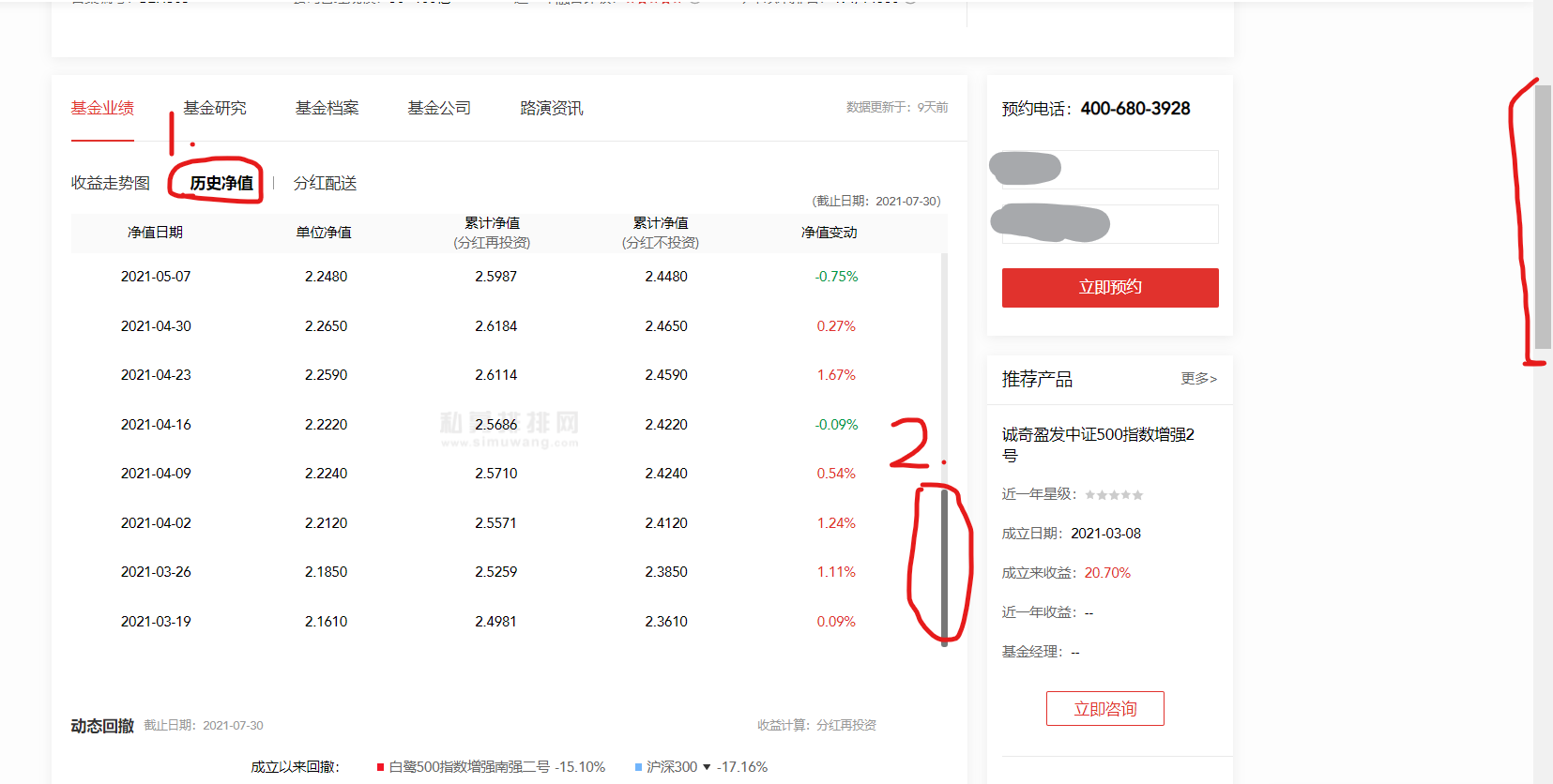
Key points to solve the problem: first click the historical net value, and then locate the historical net value box.
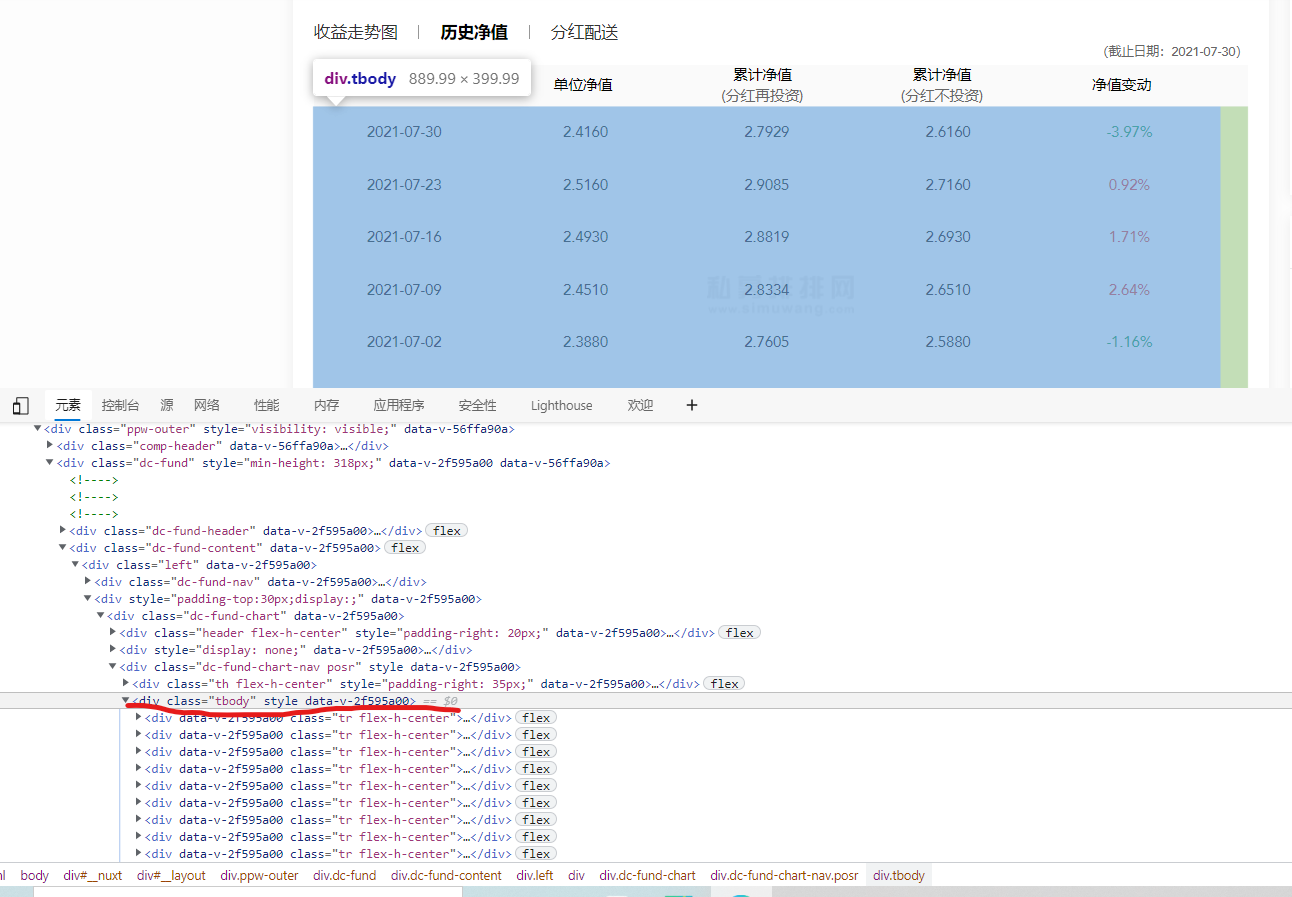
As shown in the figure, the embedded frame has been positioned, and the slide is opened below
driver.find_element(By.XPATH,'//div/div[2]/div[2]/div[1]/div[2]/div[1]/div[1]/a[2]').click() # click historical net value
for i in range(50):
js = 'document.getElementsByClassName("tbody")[0].scrollTop=100000' # Sliding in the historical net value should be enough for 50 here. If it is not enough, just increase it
driver.execute_script(js)
time.sleep(0.1) # Prevent sliding too fast and no results are read
page_url = driver.page_source # Parse current web page
Note that getElementsByClassName("tbody") [0] here is to find the first element in the attribute class whose attribute value is tbody (be sure to bring the following 0, because it returns a collection. If you slide 4 elements, it will be followed by 3)
The following is the method to locate the document object, which is the same as css positioning.
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-bdmkotgo-1628908656748) (crawl the historical net value of private placement network and crack the encrypted value. assets/image-20210808190751925.png)]
If you are interested, you can see the JavaScript learning link
http://www.runoob.com/jsref/dom-obj-document.html
2. Decrypt the hidden value in the historical net value
(1) Hidden value principle
After the previous step, we got the web page of each fund, and then we began to decrypt it.
Before decryption, let's see how it is encrypted!
You can see that there is content in html that is not in the web page. This is encryption.
To tell you the truth, I spent a lot of time here. Let me talk about my ideas first.
-
Find rules
At the beginning of trying to find rules, the first rule is that span in each value must be useful, but later it is found that some do not have span, and then, then there is no span. Just give up this idea.
-
css offset
Then there is css offset, which is to use css style to disorder the normal values in the web page. However, it is found that the value order here is normal, but there are only some more values, so the page excludes this idea.
-
There are hidden values
Finally found the law,
Existing values (values displayed on Web pages)
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-rrkscm8j-1628908656750) (crawl the historical net value of private placement network and crack the encrypted value. assets/image-20210808200015651.png)]
Values that do not exist (values that do not appear on Web pages)
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (IMG pyfcivck-1628908656751) (crawl the historical net value of private placement network and crack the encrypted value. assets/image-20210808200204943.png)]
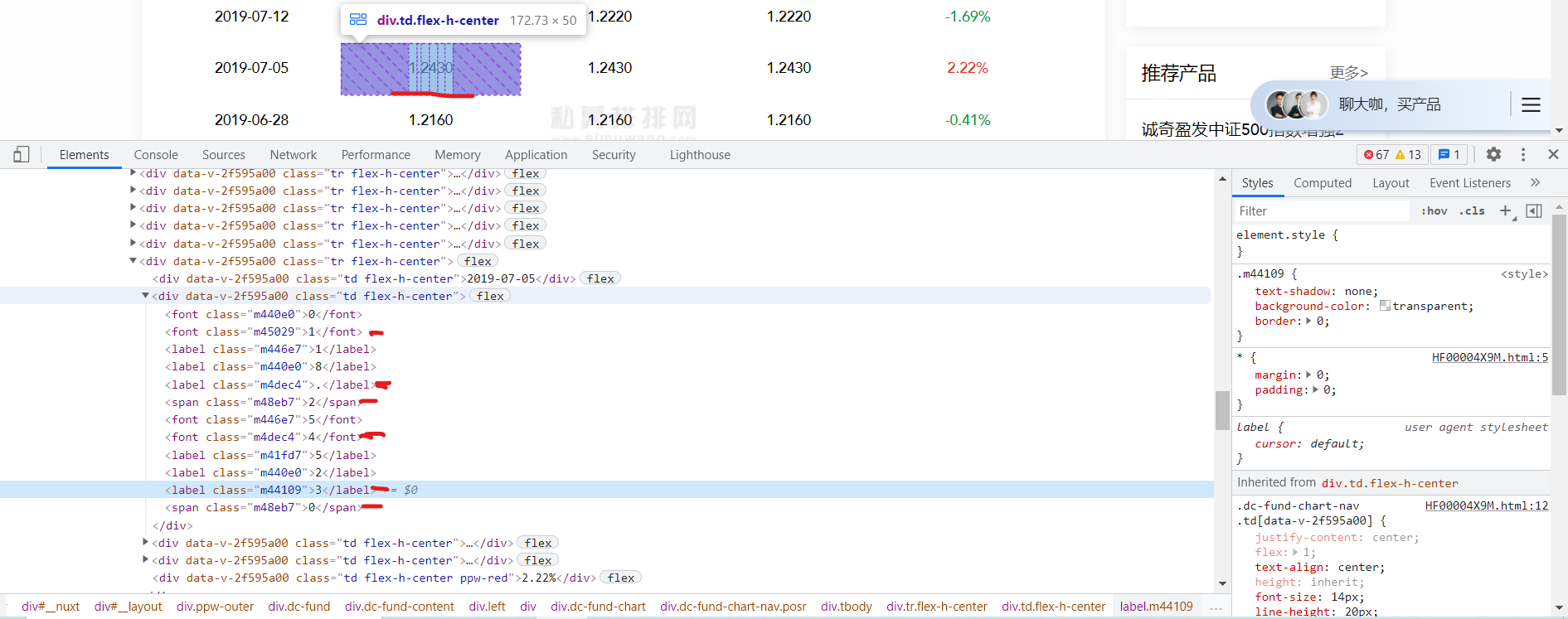
You will find that there are too many non-existent values on the web page font: 0/0 a.
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-hfaoqwnu-1628908656752) (crawl the historical net value of private placement network and crack the encrypted value. assets/image-20210808201653244.png)]
When the border of font: 0/0 a is unchecked, it will be found that there will be many values in the web page with spaces in the middle. It can be concluded that the extra values in html are not redundant. It also exists in the web page, but it is hidden.
Then we will seize this feature and continue to look for it.
When we found encode_ The content corresponding to style is the same as the rule found. [the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-bzifleqr-1628908656753) (crawl the historical net value of private placement network and crack the encrypted value. assets/image-20210808201017372.png)]
.m440e0{font: 0/0 a;color: transparent;text-shadow: none;background-color: transparent;border: 0;}.m446e7{font: 0/0 a;color: transparent;text-shadow: none;background-color: transparent;border: 0;}.m48eb7{text-shadow: none;background-color: transparent;border: 0;}.m45029{text-shadow: none;background-color: transparent;border: 0;}.m41fd7{font: 0/0 a;color: transparent;text-shadow: none;background-color: transparent;border: 0;}.m4dec4{text-shadow: none;background-color: transparent;border: 0;}.m44109{text-shadow: none;background-color: transparent;border: 0;}
You can verify and find elements with m440e0 as the attribute value. You can find that they are all hidden values. Similarly, m48eb7 for attribute values, all elements are real values.
Conclusion: the extra value in html is not redundant. It also exists in the web page, but it is hidden. These hidden and real values are in encode_ In the style attribute. So you only need to use encode_ font: 0/0 a attribute value found in style is a hidden value.
(2) Code implementation
# Hidden attribute values found
def getHideIds(htmlEtree):
encode_styles = "".join(htmlEtree.xpath('//div[@id="ENCODE_STYLE"]/style/text()')).replace("\n", "")
# Clean the data and remove continuous spaces
new_encode_styles = re.sub(" +", "", encode_styles)
# Get all h id den IDS
hideIds1 = re.findall("\.(\w+) {font: 0/0 a;", new_encode_styles) # Formatted html
hideIds2 = re.findall("\.(\w+){font: 0/0 a;", new_encode_styles) # Unformatted html
result = set(hideIds1 + hideIds2)
return result
Define a function to call the page parsed by xpath_ Source, the return value is the attribute value of the hidden value. That is, values similar to m440e0, m41fd7.
Then you just need to find the element corresponding to the hidden value.
htmlEtree = etree.HTML(text=htmlData)
# Get hidden id
hideIds = getHideIds(htmlEtree)
# Processing data
divList = htmlEtree.xpath('//div[@class="tr flex-h-center"]')
# print(divList)
tdDivs = []
for div in divList:
nextDivs = div.xpath('./div[@class="td flex-h-center"]')
for nextDiv in nextDivs:
if nextDivs.index(nextDiv) == 0:
continue
tdDivs.append(nextDiv)
resultList = []
for tdDiv in tdDivs:
labels = tdDiv.xpath("./*")
nowResultList = []
for label in labels:
classStr = label.xpath("./@class")[0]
if classStr not in hideIds:
nowResultList.append(label.xpath("./text()")[0])
resultList.append("".join(nowResultList))
# print(resultList)
# for reslut in resultList:
# print(reslut)
3, Write all data to excel
Finally, find the net value date and net value change (these two are not doped with hidden values, which can be easily found), and then use pandas to write them into excel.
write = pandas.ExcelWriter(r"C:\Users\86178\Desktop\Historical net worth crawling of private placement network.xlsx") # Create a new xlsx file.
list_info.append([list_date[index], resultList[i], resultList[i + 1], resultList[i + 2], list_net[index]]) # Corresponding to net value date, unit net value, cumulative net value, cumulative net value and net value change respectively
pd = pandas.DataFrame(list_info, columns=['Net worth date', 'Average NAV', 'Cumulative net worth (dividend reinvestment)', 'Cumulative net worth (dividends not invested)', 'Change in net worth'])
# print(pd)
pd.to_excel(write, sheet_name=list_name[ind], index=False)
write.save() # Be sure to save it here
Finally, the results are obtained
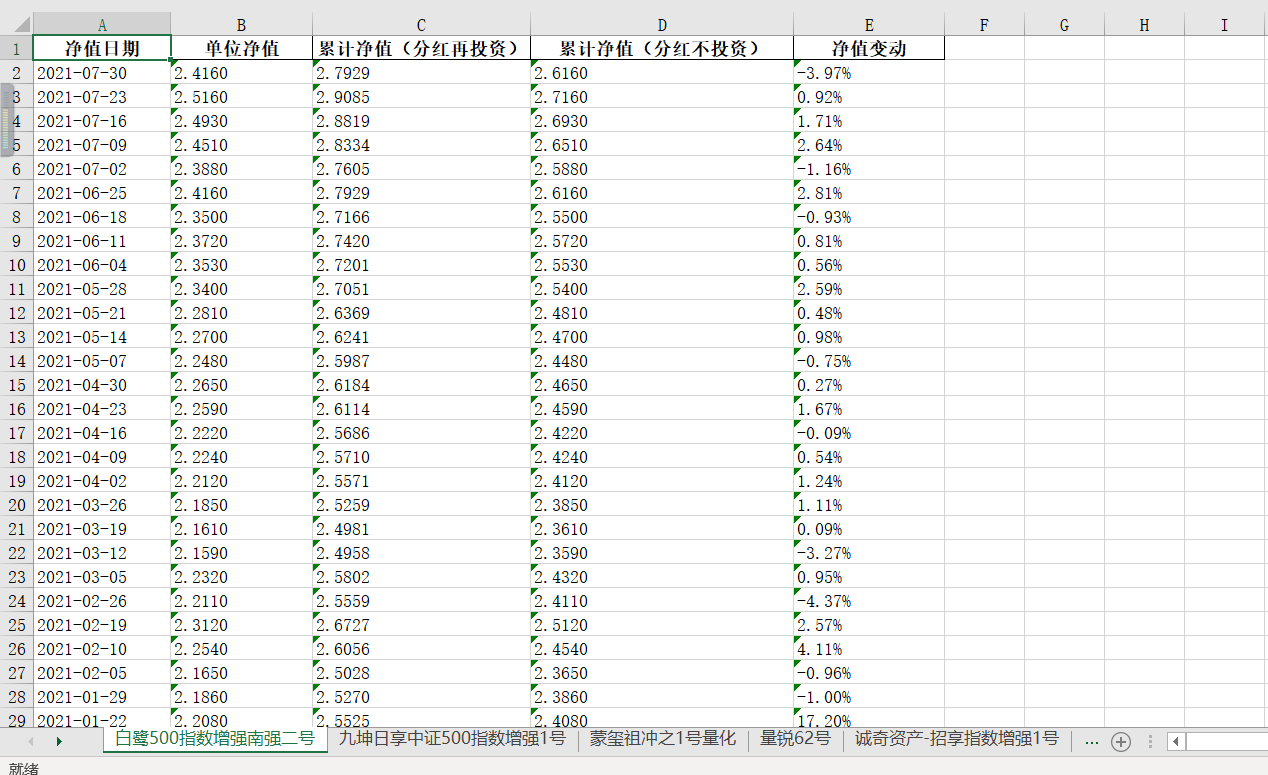
4, Summary
This article mainly talks about some basic operations of selenium, such as mouse events, keyboard events and mouse hover. Then decrypt the hidden value.
I met many pits here and thought about it all afternoon. I'm glad I didn't give up when I was in the most difficult time. In fact, the greater harvest this time is to make myself have a deeper insight into reptiles.