sometimes when we grab a page with requests, the results may be different from those seen in the browser: the normally displayed page data can be seen in the browser, but not in the results obtained with requests. This is because requests obtain the original HTML document, while the pages in the browser are generated after JavaScript processing data. These data come from a variety of sources, which may be loaded through Ajax, included in the HTML document, or calculated by JavaScript and specific algorithms.
for the first case, data loading is an asynchronous loading method. The original page will not contain some data at first. After the original page is loaded, it will request an interface from the server to obtain data, and then the data will be processed and presented to the web page. In fact, it sends an ajax request.
according to the development trend of the Web, there will be more and more pages in this form. The original HTML document of the Web page does not contain any data. The data is uniformly loaded through Ajax and then presented. In this way, the front and back ends can be separated in Web development, and the pressure brought by the server to render the page directly can be reduced.
therefore, if you encounter such a page, you can't get valid data by directly using the requests and other libraries to grab the original page. At this time, you need to analyze the Ajax requests sent from the background of the web page to the interface,
The process of sending Ajax requests to web page updates can be simply divided into the following three steps:
- Send the request to the server through the XMLHttpRequest object of javascript
- Parse and convert the data returned by the server
- Apply the available data to the original html page through the DOM operation of javascript
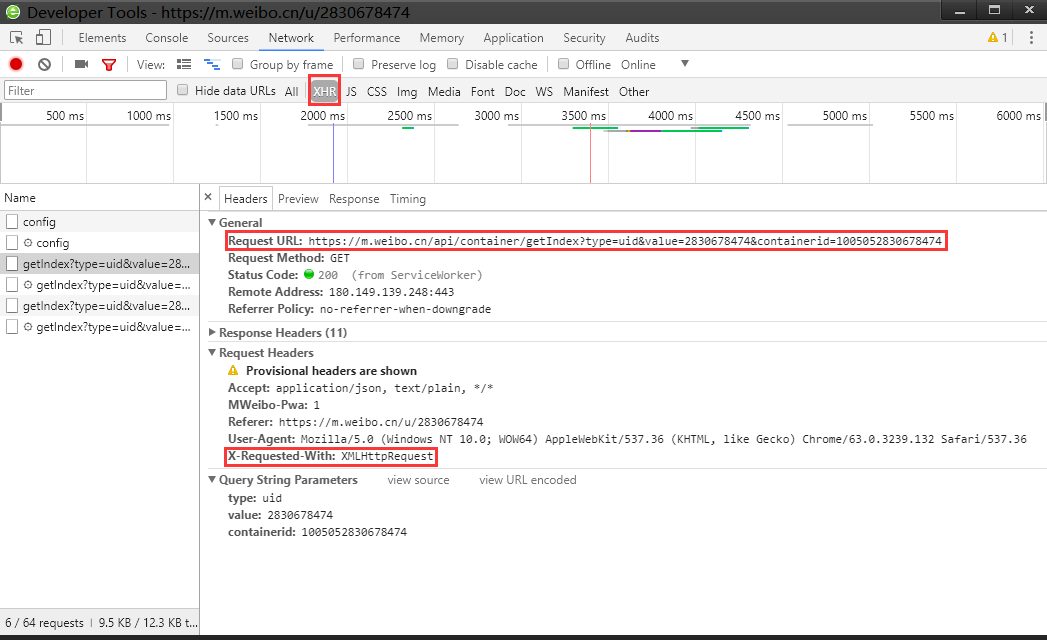
to simulate an ajax request for crawling, the first thing is to obtain the xhr request sent by the web page to the server. This is a specific request method for ajax. Analyze the requested data according to the URL of the ajax request. In the browser developer tool, you can also clearly see the json data returned by the server after the ajax request, javascript re renders pages based on packets like this.
Analyze through the developer tools of the browser:
json data returned by the server:
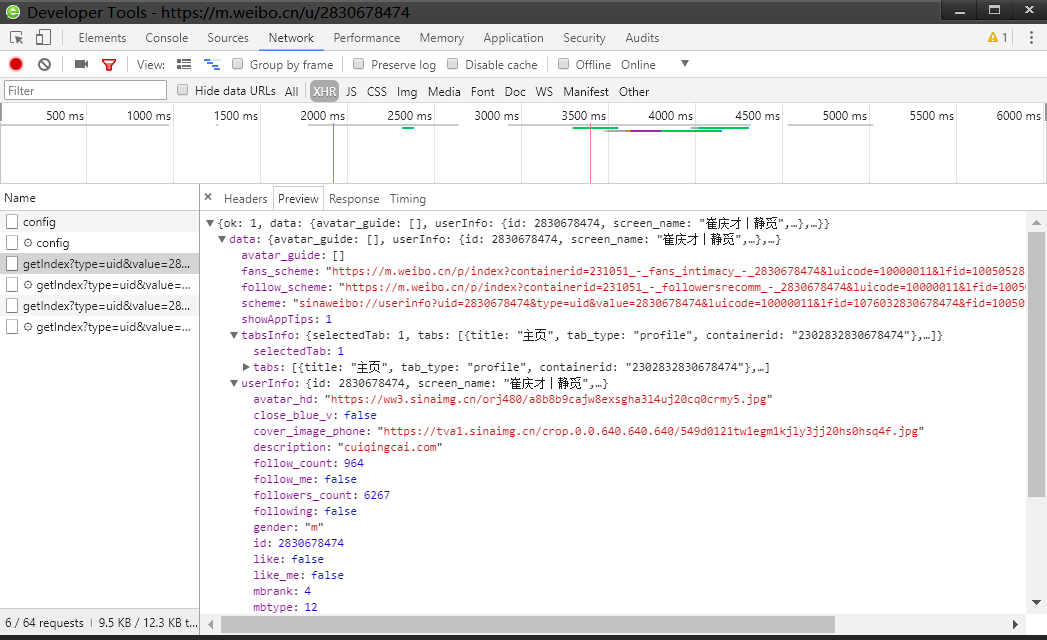
The following is an example of a crawler crawling information from a microblog (there are also ajax requests) page:
from urllib.parse import urlencode
import requests
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/2830678474',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# Simulate ajax request sending through requests to obtain a page of microblog page
def get_page(page):
params = {
'type': 'uid',
'value': '2830678474',
'containerid': '1076032830678474',
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
from pyquery import PyQuery as pq
# Extract the information in the returned json data
def parse_page(json):
if json:
items = json.get('data').get('cards')
print(type(items))
for item in items:
item = item.get('mblog')
if(item):
weibo = {}
# You can add elements inside an empty dictionary directly by assigning values to it
weibo['id'] = item.get('id')
weibo['text'] = pq(item.get('text')).text()
weibo['attitudes'] = item.get('attitudes_count')
weibo['comments'] = item.get('comments_count')
weibo['reposts'] = item.get('reposts_count')
yield weibo
if __name__ == '__main__':
for page in range(1, 10):
json = get_page(page)
results = parse_page(json)
for result in results:
with open('weibo.txt', 'wb') as file:
file.write(result)
# print(result)