1: Title
Sina Weibo can embed "topic" in the speech, that is, the topic text in the speech can be written between a pair of "#" to generate a topic link. Click the link to see how many people are discussing the same or similar topics with themselves. Sina Weibo will also update the list of hot topics at any time, and put the most popular topics in an eye-catching position to recommend everyone's attention.
This topic requires a simplified hot topic recommendation function to analyze topics from a large number of English microblogs (because Chinese word segmentation is troublesome) and find out the topics mentioned by the most microblogs.
Input format:
Input Description: the input first gives a positive integer N (≤ 10)
5
), followed by N lines, each line gives an English microblog with a length of no more than 140 characters. Any content contained in # a recent pair is considered as a topic, and the input is guaranteed to # appear in pairs.
Output format:
The first line outputs the topics mentioned by the most microblogs, and the second line outputs the number of microblogs mentioned. If such topics are not unique, the topics with the smallest alphabetical order will be output, and And k more... Will be output in the third line, where k is the number of other hot topics. The input ensures that at least one topic exists.
Note: the two topics are considered to be the same. If the symbols of all non English letters and numbers are removed and the case distinction is ignored, they are the same string; At the same time, they have exactly the same participle. When outputting, only lowercase English letters and numbers are reserved except the first capital letter, and a space is used to separate the words in the original text.
Input example:
4 This is a #test of topic#. Another #Test of topic.# This is a #Hot# #Hot# topic Another #hot!# #Hot# topic
Output example:
Hot 2 And 1 more ...
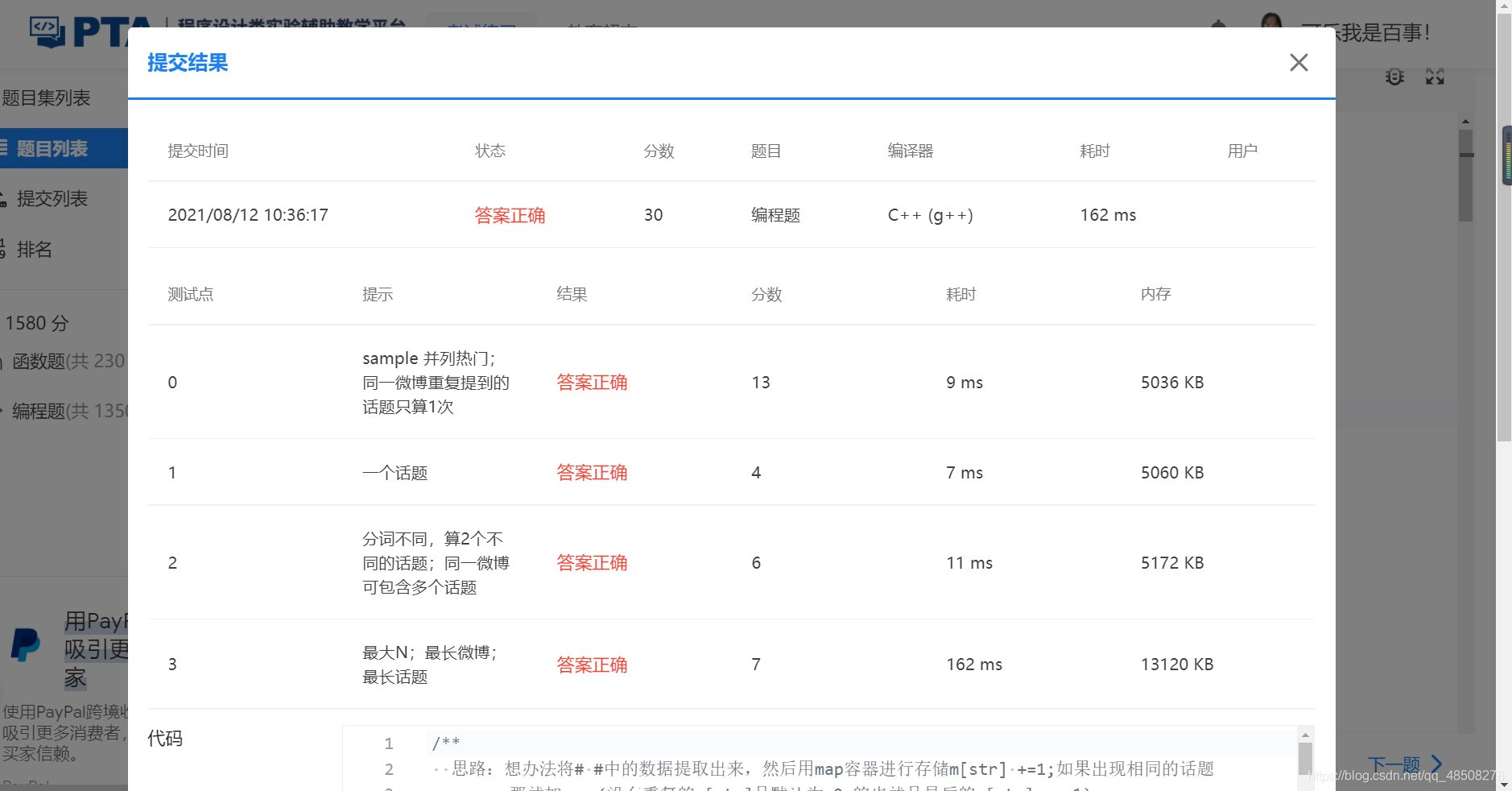
2: Train of thought analysis
Idea: find a way to extract the data in ##, and then store it in the map container, m[str] +=1; If the same topic appears
Then add one, (m[str] without repetition defaults to 0, that is, the last m[str] == 1)
Next, the last value in the map container is the largest. Of course, duplicate values may occur, but it doesn't matter. We'll use the known values
The maximum value can be obtained, and then the number of the same topic is the second item required to be output by the topic
Here I use the set container to extract each topic from the microblog
It should also be noted that this question does not make the largest number of statistical topics. It is to look at the topics mentioned in each microblog. No matter how many times they are mentioned in a microblog, they are counted as the topics appearing in this microblog.
3: Upper code
/**
Idea: find a way to extract the data in ##, and then store it in the map container, m[str] +=1; If the same topic appears
Then add one, (m[str] without repetition defaults to 0, that is, the last m[str] == 1)
Next, the last value in the map container is the largest. Of course, duplicate values may occur, but it doesn't matter. We'll use the known values
The maximum value can be obtained, and then the number of the same topic is the second item required to be output by the topic
Here I use the set container to extract each topic from the microblog
*/
#include<bits/stdc++.h>
using namespace std;
set<string>s[100010];
set<string>:: iterator st;
//Extract the content in ## the middle of the string
void deal(string str,int x){
int flag = 0;
int count = 0;
string word = "";//String initialization
string str1 = "";
str += "!";//Add an end flag to the end of the string
for( int i = 0; i < str.size(); i++ ){
//This is a #test of topic#.
if( str[i] == '#'){
flag = 1;
count++;
if( i < str.size() - 1)
i++;
}
if( isalpha(str[i]) && flag == 1 || isdigit(str[i]) && flag == 1){//Judge whether the character is alphanumeric
if( isalpha(str[i]))
word += tolower(str[i]);//Change uppercase letters to lowercase letters
if( isdigit(str[i]))
word += str[i];
}else if( flag == 1 ) {//Here, flag = 1 ensures that the extracted characters are ## inside
// cout << word << endl;
if( word != " ")
str1 += word;
word = " ";//Clean up the last word, store a new word (and add spaces to other words except the first word)
}
//Represents a hot spot in a topic
if( count == 2){
flag = 0;
count = 0;//There may be more than one # number in a row
if(str1 != " " )
s[x].insert(str1);
word = ""; //If there are two hot topics in a statement, then (because word is assigned to "" after str1 is finally executed, and the new hot topic needs no space at the beginning)
str1.clear();
}
}
}
int main(){
int N;
map<string,int>m2;
map<string,int>::iterator t;
cin >> N;
getchar();
for( int i = 0; i < N; i++ ){
string str;
getline(cin,str);
deal(str,i);
for( st = s[i].begin(); st != s[i].end(); st++ ){
m2[*st] += 1;
}
}
// cout << "******************"<< endl;
int max = 0;
for( t = m2.begin(); t != m2.end(); t++ ){
if( t->second > max ){
max = t->second;
}
}
// cout << max << endl;
int num;
for( t = m2.begin(); t != m2.end(); t++ ){
if( t->second == max ){
string str = t->first;
str[0] = toupper(str[0]);
cout << str << endl;
cout << t->second << endl;
num = t->second;
break;
}
}
int count = -1;//Eliminate yourself first
for( t = m2.begin(); t != m2.end(); t++ ){
if(t->second == num )
count++;
}
//cout << m2.size() << endl;
if( count > 0)
cout << "And " << count << " more ...";
}
//4
//This is a #test of topic#.
//
//This is a #Hot# #Hot# topic
//Another #hot!# #Hot# topic
//1
//This is a #test of topic#.
//1
//Another #hot!# #Hot# topic
//Another #Hot# topic
//4
//This is a #test of topic#.
//Another #Test of topic.# #Hot#
//This is a #Hot# #Hot# topic
//Another #hot!# #Hot# topic
//
//Another #Test1 of topic.#
//This is a #test of topic#.
//Another #hot!# #Hot# topic
4: Summary
Finally, there is a mistake at the beginning. That's because the range of set above me is too small. Increase the range to the 5th power of 10. Come on boy!