Summary:
- HashMap adopts the chain address method. When there is a conflict, it will be transformed into a linked list. When the linked list is too long, it will be transformed into a red black tree to improve efficiency.
- HashMap limits red and black trees so that red and black trees can only withstand pressure in a few extreme cases.
When there are more and more data in HashMap, the probability of hash conflict will be higher and higher. Through array expansion, space can be used for time to maintain the search efficiency at constant time complexity. When will the capacity be expanded? It is controlled by a key parameter of HashMap: loading factor.
Load factor = number of nodes in HashMap / array length, which is a proportional value. When the number of nodes in the HashMap reaches the loading factor, capacity expansion will be triggered; That is, the load factor controls the threshold of the number of nodes that the current array can carry. If the array length is 16 and the loading factor is 0.75, the number of nodes that can be accommodated is 16 * 0.75 = 12. The value of the loading factor needs to be carefully weighed. The larger the loading factor, the higher the array utilization and the higher the probability of hash conflict; The smaller the load factor, the lower the array utilization, but the probability of hash collision is also reduced. Therefore, the size of the loading factor needs to weigh the relationship between space and time. In the theoretical calculation, 0.75 is a more appropriate value. The probability of hash conflicts greater than 0.75 increases exponentially, while the reduction of conflicts less than 0.75 is not obvious. The default size of the load factor in HashMap is 0.75. It is not recommended to modify its value without special requirements.
So how does HashMap expand after reaching the threshold? HashMap will expand the length of the array to twice the original, and then migrate the data of the old array to the new array. HashMap optimizes the migration: use the feature that the length of the HashMap array is an integer power of 2 to complete the data migration in a more efficient way.
JDK1. The data migration before 7 is relatively simple, that is, traverse all nodes, calculate the new subscript through the hash function, and then insert it into the linked list of the new array. This has two disadvantages: * * 1. Each node needs to perform a residual calculation; 2. When inserting into a new array, the head insertion method is adopted, and linked list links will be formed in a multi-threaded environment** jdk1. The reason is that the length of the array is always an integer power of 2. Each time the array is expanded, it is twice the original. The advantage is that there are only two hash results for the key in the new array: in the original position, or in the original position + the length of the original array. Why can we look at the following figure:
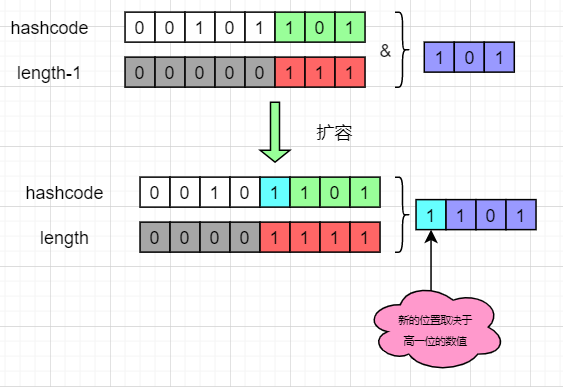
From the figure, we can see that the hash result in the new array only depends on the higher value. If the higher bit is 0, the calculation result is in the original position, and if it is 1, add the length of the original array. In this way, we only need to judge that the higher bit of a node is 1 or 0 to get its position in the new array without repeating the hash calculation. HashMap divides each linked list into two linked lists, corresponding to the original position or the original position + the length of the original array, and then inserts them into the new array respectively, retaining the original node order, as follows:
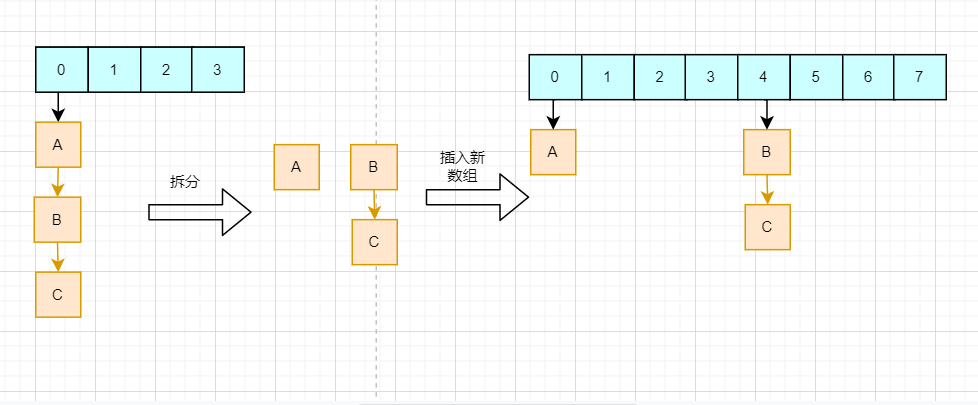
There is still a problem left: head insertion will form linked list links. This problem is explained in the thread safety section.
Summary:
- The loading factor determines the threshold of HashMap expansion, which needs to weigh time and space. Generally, it remains unchanged at 0.75;
- HashMap capacity expansion mechanism combines the characteristics of integer power with array length of 2 to complete data migration with a higher efficiency and avoid linked list links caused by header interpolation.
As a collection, HashMap's main function is CRUD, that is, adding, deleting, querying and modifying data, so it must involve multi-threaded concurrent data access. The problem of concurrency needs our special attention.
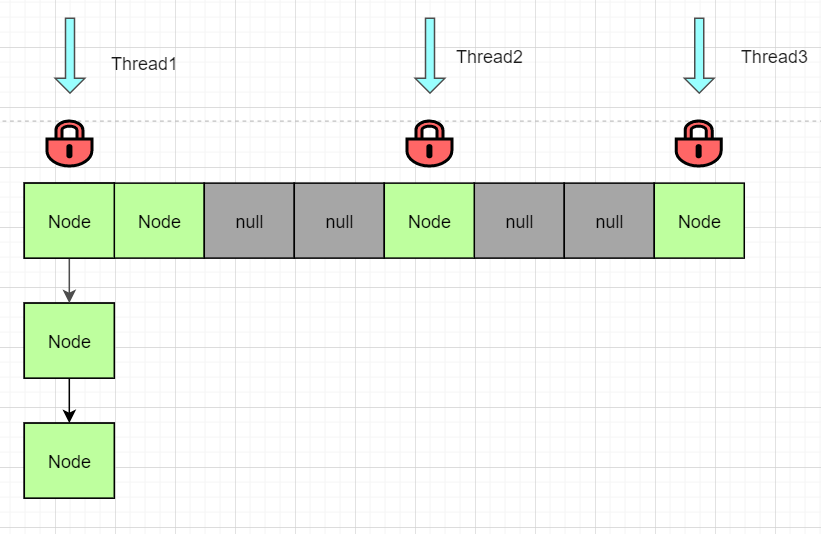
HashMap is not thread safe, and data consistency cannot be guaranteed in the case of multithreading. For example, if the position of HashMap subscript 2 is null, thread A needs to insert node X into the position of subscript 2. After determining whether it is null, the thread is suspended; At this time, thread B inserts the new node Y into the position of subscript 2; When restoring thread A, node X will be directly inserted into subscript 2, overwriting node Y, resulting in data loss, as shown in the following figure:
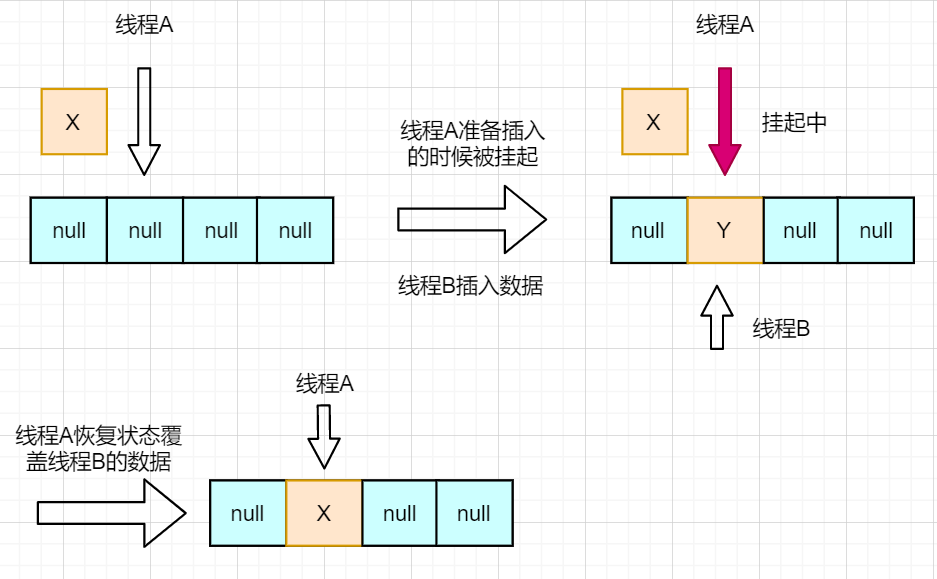
jdk1.7 and before, the head insertion method was used for capacity expansion. This method has fast insertion speed, but it will cause a linked list ring in a multi-threaded environment, and the linked list ring will not find the tail of the linked list in the next insertion, resulting in a life and death cycle.
What if the result data consistency problem? There are three solutions to this problem:
-
Hashtable is adopted
-
Call collections Synchronizemap () method to make HashMap multi-threaded
-
Use ConcurrentHashMap
The ideas of the first two schemes are similar. In each method, the whole object is locked. Hashtable is a collection framework of the older generation. Many designs are backward. It adds the synchronize keyword to each method to ensure thread safety
// Hashtable
public synchronized V get(Object key) {...}
public synchronized V put(K key, V value) {...}
public synchronized V remove(Object key) {...}
public synchronized V replace(K key, V value) {...}
...
The second method is to return a synchronized map object. By default, each method will lock the whole object. The source code is as follows:
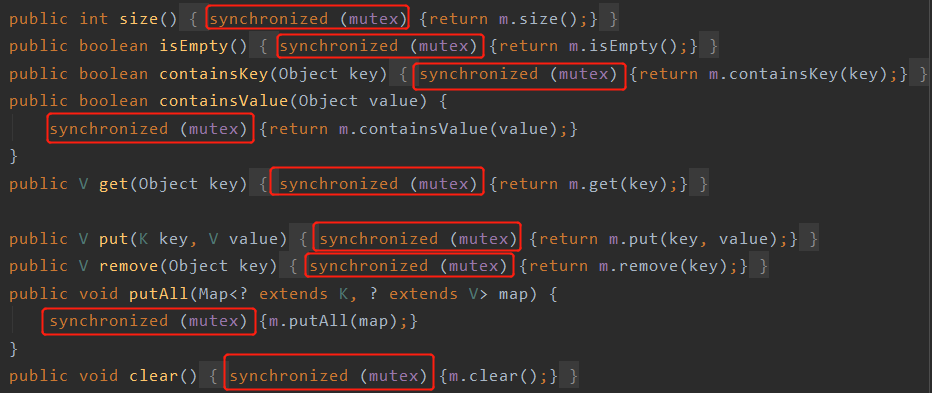
What is the mutex here? See the constructor directly:
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
// The default is this object
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
You can see that the default lock is itself, and the effect is actually the same as that of Hashtable. The consequences of this simple and crude way of locking the entire object are:
-
Locks are very heavyweight and can seriously affect performance.
-
Only one thread can read and write at a time, which limits the concurrency efficiency.
Concurrent HashMap is designed to solve this problem. It improves efficiency by reducing lock granularity + CAS. In short, the concurrent HashMap locks not the entire object, but a node of an array. If other threads access the array, other nodes will not affect each other, which greatly improves the concurrency efficiency; At the same time, the concurrent HashMap read operation does not need to obtain a lock, as shown in the following figure:
For more information about concurrent HashMap and Hashtable, I will explain it in another article.
So, is it absolutely thread safe to use the above three solutions? First observe the following code:
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();
map.put("abc","123");
Thread1:
if (map.containsKey("abc")){
String s = map.get("abc");
}
Thread2:
map.remove("abc");
When Thread1 releases the lock after calling containsKey, Thread2 obtains the lock and removes "abc" and then releases the lock. At this time, the s read by Thread1 is null, which leads to a problem. So the ConcurrentHashMap class or collections The synchronizemap () method or Hashtable can only guarantee thread safety to a certain extent, but cannot guarantee absolute thread safety.
On thread safety, there is also a fast fail problem, that is, fast failure. When the HashMap iterator is used to traverse the HashMap, if there are structural changes in the HashMap, such as inserting new data, removing data, expanding capacity, etc., the iterator will throw a fast fail exception to prevent concurrent exceptions and ensure thread safety to a certain extent. The source code is as follows:
final Node<K,V> nextNode() {
...
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
...
}
When creating an iterator object, the modCount variable of the HashMap will be recorded. Whenever there is a structural change in the HashMap, the modCount will be increased by 1. During iteration, judge whether the modCount of HashMap is consistent with the expected modCount saved by yourself to judge whether structural changes have occurred.
Fast fail exception can only be used as a security guarantee during traversal, but not as a means for multithreading to access HashMap concurrently. If there is a need for concurrency, you still need to use the above three methods.
Summary
- HashMap can not guarantee thread safety. Unexpected problems will occur under multi-threaded concurrent access, such as data loss
- HashMap1.8. The tail insertion method is used for capacity expansion to prevent the dead cycle problem caused by linked list links
- Solutions to concurrency problems include Hashtable and collections synchronizeMap(),ConcurrentHashMap. The best solution is concurrenthashmap
- The above solution does not fully guarantee thread safety
- Fast failure is a concurrent security guarantee in HashMap iteration mechanism
Understanding of key variables
There are many internal variables in the HashMap source code. These variables often appear in the following source code analysis. First, you need to understand the meaning of these variables.
// Array for storing data
transient Node<K,V>[] table;
// Number of stored key value pairs
transient int size;
// The number of changes to the HashMap structure is mainly used to judge fast fail
transient int modCount;
// The maximum number of stored key value pairs (threshodl=table.length*loadFactor), also known as the threshold
int threshold;
// Load factor, which represents the proportion of the maximum amount of data that can be accommodated
final float loadFactor;
// Static internal class, node type stored in HashMap; It can store key value pairs, which is a linked list structure.
static class Node<K,V> implements Map.Entry<K,V> {...}
Capacity expansion
The HashMap source code also puts the initialization operation into the capacity expansion method, so the capacity expansion method source code is mainly divided into two parts: determining the new array size and migrating data. The detailed source code analysis is as follows. I have made very detailed comments, which you can choose to view. The steps of capacity expansion have been described above. Readers can analyze how HashMap realizes the above design by combining the source code.
final Node<K,V>[] resize() {
// The variables are the original array, the size of the original array and the original threshold; New array size, new threshold
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// If the original array length is greater than 0
if (oldCap > 0) {
// If the set maximum length has been exceeded (1 < < 30, that is, the maximum integer positive number)
if (oldCap >= MAXIMUM_CAPACITY) {
// Set the threshold directly to the maximum positive number
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// Set to twice the original
newThr = oldThr << 1;
}
// The length of the original array is 0, but the maximum is not 0. Set the length as the threshold
// The corresponding case is that the array length is specified when creating a HashMap
else if (oldThr > 0)
newCap = oldThr;
// The first initialization defaults to 16 and 0.75
// Corresponding to using the default constructor to create a new HashMap object
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// If the length of the original array is less than 16 or the maximum limit length is exceeded after doubling, the threshold is recalculated
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// Create a new array
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// Loop through the original array and calculate the new position for each node
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// If it does not have a successor node, it can directly use the new array length module to get a new subscript
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// If it is a red black tree, call the disassembly method of the red black tree
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// There are only two possibilities for the new position: the original position, the original position + the length of the old array
// Split the original linked list into two linked lists, and then insert them into the two positions of the new array respectively
// Do not call the put method multiple times
else {
// They are the linked list with the original position unchanged and the linked list with the original position + the length of the original array
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// Traverse the old linked list and judge whether the new judgment location is 1or0 for classification
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// Finally assigned to the new array
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// Returns a new array
return newTab;
}
last
Here comes the interview question document, with a lot of content, 485 pages!
Because there are too many contents in the notes, we can't show them all. Only some contents are intercepted below. Friends who want to get the full version of notes, Click here for free after you like
1111 interview questions for Java engineers

MyBatis 27 questions + ZooKeeper 25 questions + Dubbo 30 questions:

Elasticsearch 24 questions + Memcached + Redis 40 questions:

Spring 26 questions + micro service 27 questions + Linux 45 questions:

Java interview questions collection:
ewTab;
}
### last > **Here comes the interview question document, with a lot of content, 485 pages!** > > **Because there are too many contents in the notes, we can't show them all. Only some contents are intercepted below. Friends who want to get the full version of notes,[Click here for free after you like](https://gitee.com/vip204888/java-p7)** # 1111 interview questions for Java engineers [External chain picture transfer...(img-6orXGvSA-1628393594208)] **MyBatis 27 topic + ZooKeeper 25 topic + Dubbo 30 Question:** [External chain picture transfer...(img-OdY8P4MV-1628393594210)] **Elasticsearch 24 topic +Memcached +** **Redis 40 Question:** [External chain picture transfer...(img-ybdKgWEb-1628393594211)] **Spring 26 topic+ Microservices 27 questions+ Linux 45 Question:** [External chain picture transfer...(img-DBTjPCO2-1628393594214)] **Java Collection of interview questions:** 