How do crawlers deal with streaming loading pages? Please collect these 100 lines of code!
In the previous article, the academic committee made an article Take photos of the website , if you find that the screen capture page is a streaming page, what if you cut off part of it?
The so-called streaming loading page, the page height is constantly growing, this page can not get the real height of the whole page at one load!
Are there any streaming pages around? such as Hot list of CSDN I didn't run away.
This streaming loading window is like turning on the faucet. The content is displayed in a crash. If it is turned off, it will not be loaded.
Friends who often rush to the list know that when they open the hot list, they find that there are only a few Top 5. They need the browser to pull down before they can continue to dynamically load more content. Keep pulling down and slowly pull the whole hot list out.
The implementation process of this paper is summarized as follows:
First question: how to achieve this operation of obtaining the height of streaming window?
How to start setting the crawler? In the previous article, please read it yourself.
Let's focus on how to get the height of the dynamic streaming content window.
'''
Tips for solving crawlers on streaming pages
Core code:
'''
def resolve_height(driver, pageh_factor=5):
js = "return action=document.body.scrollHeight"
height = 0
page_height = driver.execute_script(js)
ref_pageh = int(page_height * pageh_factor)
step = 150
max_count = 15
count = 0
while count < max_count and height < page_height:
#scroll down to page bottom
for i in range(height, ref_pageh, step):
count+=1
vh = i
slowjs='window.scrollTo(0, {})'.format(vh)
print('exec js: %s' % slowjs)
driver.execute_script(slowjs)
sleep(0.3)
if i >= ref_pageh- step:
print('not fully read')
break
height = page_height
sleep(2)
page_height = driver.execute_script(js)
print("finish scroll")
return page_height
Not much code.
Core idea
- Continuously scroll through the learning window
- Then until a page is no longer loaded or the page is loaded to the limit value
- Stop updating (because some streaming pages have no lower limit. As long as you keep pulling down, you will always see new things)
Look at the renderings:
'''
Tips for solving crawlers on streaming pages
Core code of screenshot:
'''
def resolve_height(driver, pageh_factor=5):
js = "return action=document.body.scrollHeight"
height = 0
page_height = driver.execute_script(js)
ref_pageh = int(page_height * pageh_factor)
step = 150
max_count = 15
count = 0
while count < max_count and height < page_height:
#scroll down to page bottom
for i in range(height, ref_pageh, step):
count+=1
vh = i
slowjs='window.scrollTo(0, {})'.format(vh)
print('[Lei Xuewei Demo]exec js: %s' % slowjs)
driver.execute_script(slowjs)
sleep(0.3)
if i >= ref_pageh- step:
print('[Lei Xuewei Demo]not fully read')
break
height = page_height
sleep(2)
page_height = driver.execute_script(js)
print("finish scroll")
return page_height
#Gets the actual height of the window
page_height = resolve_height(driver)
print("[Lei Xuewei Demo]page height : %s"%page_height)
sleep(5)
driver.execute_script('document.documentElement.scrollTop=0')
sleep(1)
driver.save_screenshot(img_path)
page_height = driver.execute_script('return document.documentElement.scrollHeight') # Page height
print("get accurate height : %s" % page_height)
if page_height > window_height:
n = page_height // window_height #floor
for i in range(n):
driver.execute_script(f'document.documentElement.scrollTop={window_height*(i+1)};')
sleep(1)
driver.save_screenshot(f'./leixuewei_rank_{i}.png')
There are still not many codes.
Core idea
- Continuous scrolling of screenshot window contents
- Keep as picture (with up and down marks)
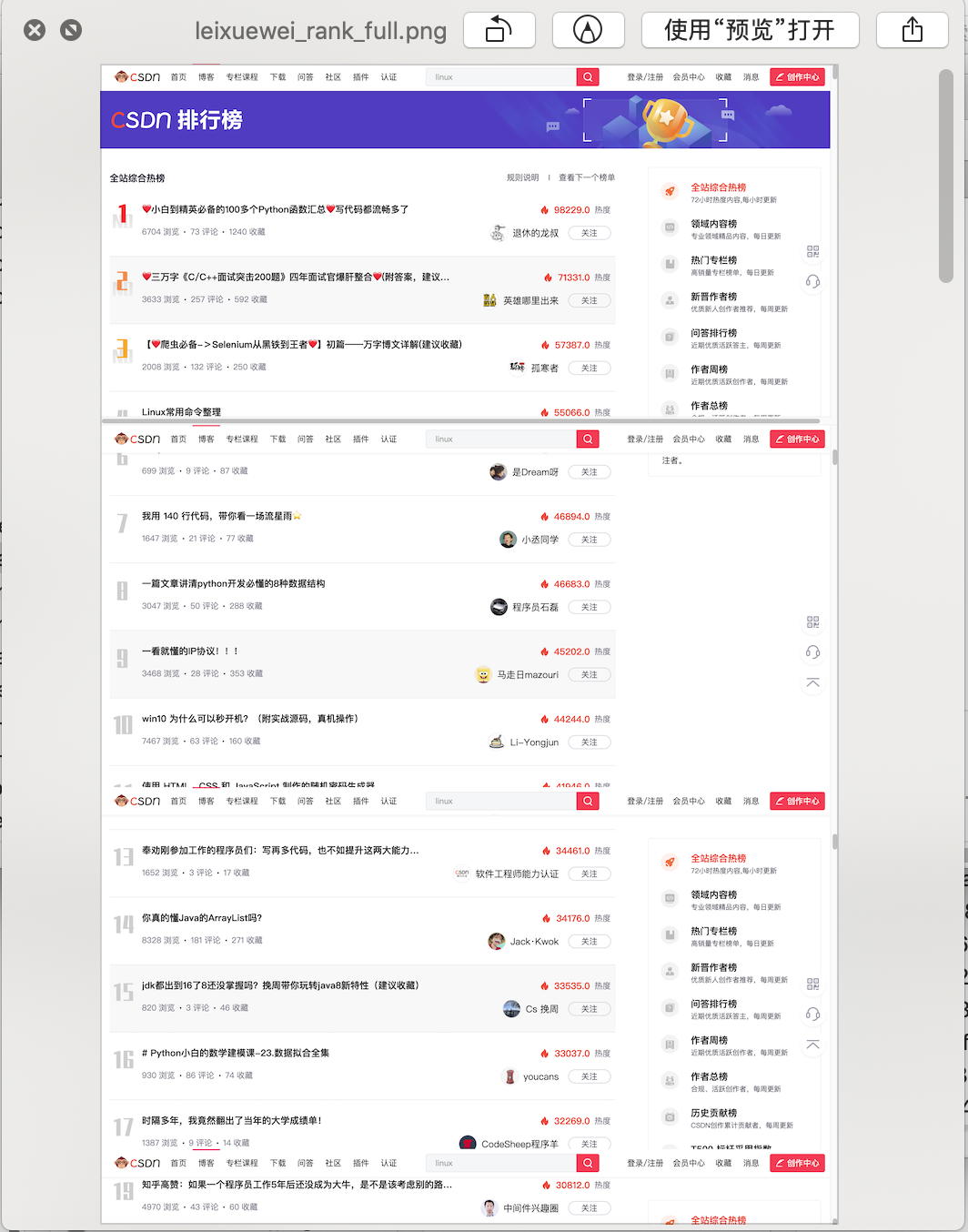
The following is a picture taken in the middle:
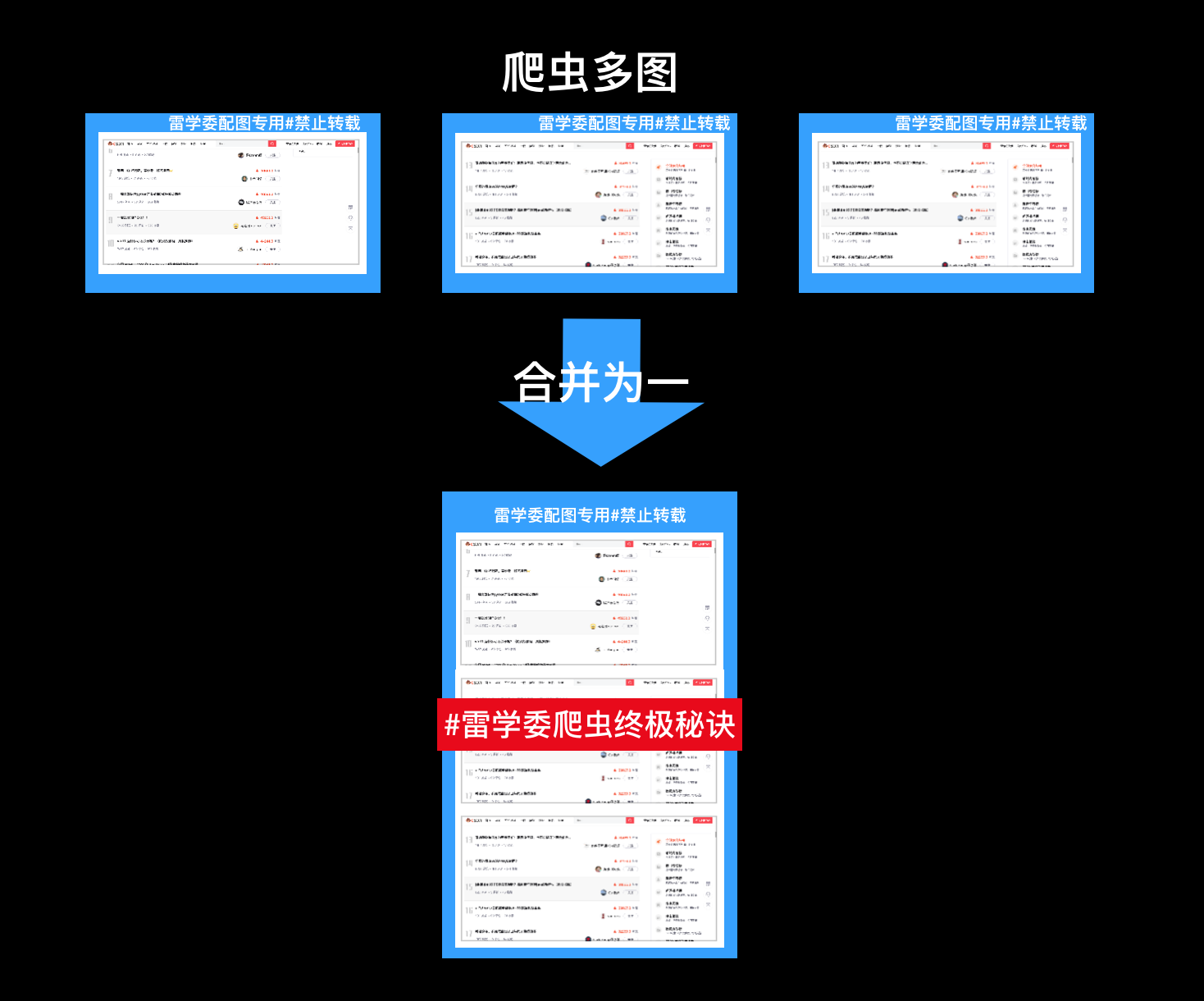
So how can multiple pictures be combined into one?
In the code project directory, we can see that multiple pictures (as shown in the figure below) have been generated here. Can't you do it yourself?
First understand what the picture is?
A picture is essentially a matrix of 2d pixels.
Each picture we see is actually a picture with many pixels arranged horizontally and vertically.
It's easy to do. The idea of merging is available. Use the numpy library directly
Let's transform the above code:
'''
Tips for solving crawlers on streaming pages
Core code of screenshot:
'''
import numpy as np
if page_height > window_height:
n = page_height // window_height #floor
base_matrix = np.atleast_2d(Image.open(img_path))
for i in range(n):
driver.execute_script(f'document.documentElement.scrollTop={window_height*(i+1)};')
sleep(1)
driver.save_screenshot(f'./leixuewei_rank_{i}.png')
delta_matrix = np.atleast_2d(Image.open(f'./leixuewei_rank_{i}.png'))
#concentrate the image
base_matrix = np.append(base_matrix, delta_matrix, axis=0)
Image.fromarray(base_matrix).save('./leixuewei_rank_full.png')
Niubi, just add a little code. The key is thinking.
Code parsing
In fact, here is the continuous conversion of pictures into 2d matrix in the screenshot cycle.
Then add multiple 2d matrices, so that the horizontal length remains unchanged, but the vertical content is added to form a complete picture.
Here is a screenshot of the hot list.
summary
The whole idea is still very smooth. The code is less than 100 lines, but it can't be done if the idea is wrong. The following libraries are mainly used.
selenium numpy Pillow
Finally, you must be careful when using crawlers. Don't climb institutional websites as a child's play. You can't brush the serious network when you study. This behavior will make you eat LAO rice sooner or later!
This article is for display purposes only. If you have any objection to the demonstration website, please inform us of the modification.
Continuous learning and continuous development, I'm Lei Xuewei!
Programming is very interesting. The key is to understand the technology thoroughly.
It's not easy to create. Please support the collection and support the school committee!