Python data analysis and mining - statistics and visualization of vocabulary frequency of a real topic in postgraduate entrance examination English in recent ten years 2012-2021
statement This article is only published in CSDN, and others are pirated. Please support genuine!Genuine link:
https://blog.csdn.net/meenr/article/details/119039354
preface
Use Python language to climb the real topic of postgraduate entrance examination English in recent ten years (2012-2021), complete data persistence, data preprocessing, extract English vocabulary, remove deformed vocabulary and word frequency statistics.
development environment
Windows10,Python3.7. PyCharm, Google Chrome (Google browser);
Sponsored website (crawler)
Climb to the real test paper of English one for postgraduate entrance examination in recent ten years, and thank China Postgraduate Entrance Examination Network for its "support", Website address:http://www.chinakaoyan.com/
Real topic data acquisition over the years (this paper takes 2012 as an example)
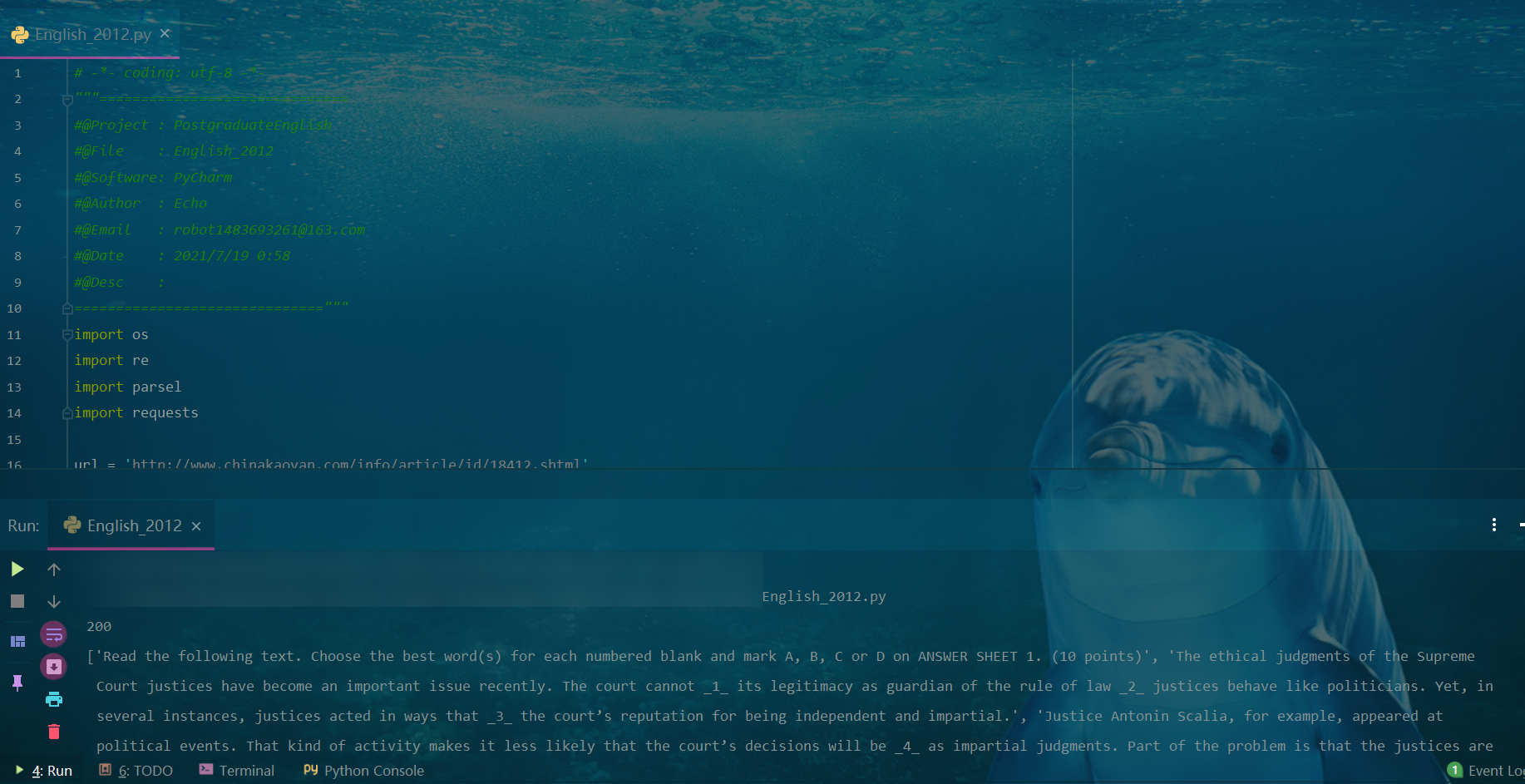
Crawling web content
# -*- coding: utf-8 -*-
"""==============================
#@Project : postgraduateEnglish
#@File : English_2012
#@Software: PyCharm
#@Author : Echo
#@Email : robot1483693261@163.com
#@Date : 2021/7/19 0:58
#@Desc :
=============================="""
import os
import re
import parsel
import requests
# 12 year test paper website
url = 'http://www.chinakaoyan.com/info/article/id/18412.shtml'
headers = {
'Host': 'www.chinakaoyan.com',
'User-Agent': 'Your browser user-agent'
}
response = requests.get(url=url, headers=headers)
print(response.status_code)
response.encoding = response.apparent_encoding
html_data = response.text
print(html_data)
Extract data
# Extract data and remove irrelevant elements
selector = parsel.Selector(html_data)
div = selector.xpath('//div[@class="cont"]')
p = div.xpath('//div[@class="cont"]/p/font/text()')
p_data = str(p.getall()).replace('<p><font face="Arial">', '').replace(r'</font></p>', '').replace(r'\r\n', '').replace(r'\xa0', '')
print(p_data)
Preliminary pretreatment
# Remove Chinese characters, punctuation, etc
english_data = ''.join(filter(lambda c: ord(c) < 256, p_data)) # Remove Chinese characters
# regular expression
cop = re.compile("[^a-zA-Z]") # Matches other characters that are not case sensitive
english_data1 = cop.sub(' ', english_data)
print(english_data1)
Data persistence
# Data persistence, new folder
if not os.path.exists(r'txt2012_2021'):
os.makedirs(r'txt2012_2021')
# Write data to txt file
with open(r'txt2012_2021/2012.txt', mode='w', encoding='utf-8') as f:
f.write(english_data1)
f.close()
The following steps can be carried out after ten years of vocabulary acquisition. This paper only takes 2012 as an example, and the acquisition method of all codes is provided at the end of the paper.
Deformed word processing (- s/-ed/-ing)
English vocabulary has the characteristics of deformation. Removing the deformed words such as plural + s or + es, past tense + ed and continuous tense + ing can improve the integrity and accuracy of word frequency analysis.
def get_word():
path1 = r'txt2012_2021/2012.txt'
with open(path1, mode='r', encoding='utf-8') as f:
data = f.read()
f.close()
split1 = data.split()
# Convert uppercase letters to lowercase letters
exchange = data.lower()
# Generate word list
original_list = exchange.split()
# enchant library check out words
words_list = []
chant = enchant.Dict("en_US")
for i in original_list:
if chant.check(i):
words_list.append(i)
return words_list
words_list = get_word()
# backups
nos_list1 = words_list.copy()
nos_list2 = words_list.copy()
ss_list = []
eds_list = []
# Check out the plural and past tense
for word in nos_list1:
if word[-1] == 's' or word[-3:] == 'ies' or word[-3:] == 'hes':
ss_list.append(word)
nos_list2.remove(word)
nos_list2.append(word[:-1])
if word[-2:] == 'ed':
eds_list.append(word)
nos_list2.remove(word)
nos_list2.append(word[:-1])
pass
pass
word frequency count
# Generate word frequency statistics
dic1 = {}
for i in word_list:
count = word_list.count(i)
dic1[i] = count
# print(dic1)
print('dic1:', len(dic1))
# Exclude specific words such as prepositions and conjunctions
# stop word
word = {
'a', 'an', 'above', 'b', 'c','d', 'e', 'f', 'h', 'm', 'n', 't', 'the',
'and', 'or', 'but', 'because', 'so', 'while', 'if', 'though', 'however', 'whether', 'once', 'no', 'not',
'none',
'in', 'by', 'on', 'from', 'for', 'of', 'to', 'at', 'about', 'before', 'down', 'up', 'into', 'over',
'between', 'through', 'during', 'with', 'without', 'since', 'among', 'under', 'off',
'also', 'ago', 'likely', 'then', 'even', 'well', 'around', 'after', 'yet', 'just', 'already', 'very',
'i', 'we', 'our', 'you', 'your', 'he', 'she', 'her', 'it', 'these', 'that',
'here', 'there', 'those', 'them', 'they', 'their', 'other', 'another', 'any', 'own',
'are', 'were', 'be', 'being', 'been',
'should', 'will', 'would', 'could', 'can', 'might', 'may', 'need', 'do', 'doing', 'did',
'have', 'had', 'must',
'like', 'which', 'what', 'who', 'when', 'how', 'why', 'where',
}
for i in word:
del (dic1[i])
# print(dic1)
# sort
dic2 = sorted(dic1.items(), key=lambda d: d[1], reverse=True)
# Output the first 50 words with the highest word frequency
for i in range(50):
print(dic2[i])
Data visualization
# Dictionary generated word cloud
bimg = imageio.imread('p3.jpg')
for color in range(len(bimg)):
bimg[color] = list(map(transform_format, bimg[color]))
wc = WordCloud(
mask=bimg,
font_path='simhei.ttf'
).generate_from_frequencies(word_counts)
wc.generate_from_frequencies(word_counts) # Generate word cloud from dictionary
image_colors = ImageColorGenerator(bimg)
wc.recolor(color_func=image_colors)
plt.imshow(wc) # Show word cloud
plt.axis('off')
plt.show() # Display image

2 binary – echo July 2021
If you have read this, please click like + comment + collection. If you pay attention, it will greatly support me. Your support is the driving force for me to move forward!
If this article is helpful to you and solves your problems, please treat me to baola bar:

Code and other data acquisition
The reason for the length is not to repeat all the codes in detail. If interested readers need relevant codes and other materials in this article, they can obtain them in the following two ways:
Way 1
Pay attention to the official account of WeChat below, reply: "vocabulary of postgraduate entrance examination"

Approach 2
Join the QQ group below and download the group files by yourself or contact the administrator to obtain them

Sincerely
Thank you for your reading, likes, comments, collection and appreciation.