Reading Guide: piecemeal upload and breakpoint continuation, these two terms should not be unfamiliar to friends who have done or are familiar with file upload. To summarize this article, I hope to help or inspire students engaged in related work.
When our files are very large, does it take a long time to upload? With such a long connection, what if the network fluctuates? The intermediate network is disconnected? In such a long process, if there is instability, all the contents uploaded this time will fail and have to be uploaded again.
Fragment upload is to upload the files to be uploaded according to a certain size, Separate the entire file into multiple data blocks (we call it Part) to upload separately. After uploading, the server will summarize all uploaded files and integrate them into the original files. Fragment upload can not only avoid the problem of always uploading from the starting position of the file due to the poor network environment, but also use multithreading to send different block data concurrently, improve the transmission efficiency and reduce the cost Send time.
1, Background
After the sudden increase of system users, in order to better adapt to the customized needs of various groups. The business slowly realized the support of C-end user-defined layout and configuration, resulting in a surge in configuration data reading IO.
In order to better optimize such scenarios, user-defined configurations are statically managed! That is, the corresponding configuration file is generated into a static file. There are thorny problems in the process of generating the static file. The large configuration file leads to a long waiting time in the file upload server, resulting in the overall decline of the performance of the whole business scenario.
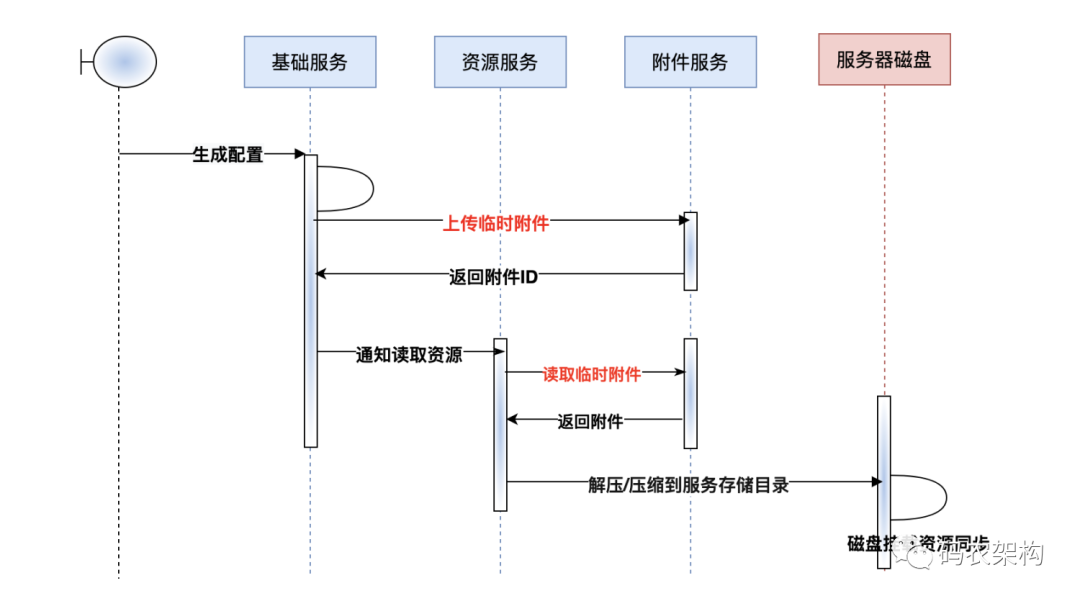
2, Generate profile
Three elements of generating files
- file name
- File content
- file store format
The file content and file storage format are easy to understand and process. Of course, the encryption methods commonly used in microservices have been sorted out previously
- Microservice architecture | what are the commonly used encryption methods for microservices (I)
- Microservice architecture | what are the common encryption methods for data encryption (2)
Here is a supplementary note. If you want to encrypt the file content, you can consider it. However, the case scenario in this paper has a low degree of confidentiality for the configuration information, so it is not expanded here.
The naming standard of file name is determined in combination with the business scenario, usually in the format of file profile + timestamp. However, such naming conventions can easily lead to file name conflicts, resulting in unnecessary follow-up trouble.
Therefore, I have made special treatment for the naming of file names here. Those who have handled front-end Route routing should be able to think that file names can be replaced by generating Hash values based on content.
After Spring 3.0, a method to calculate the summary is provided.
DigestUtils#md
Returns the hexadecimal string representation of the MD5 digest for the given byte.
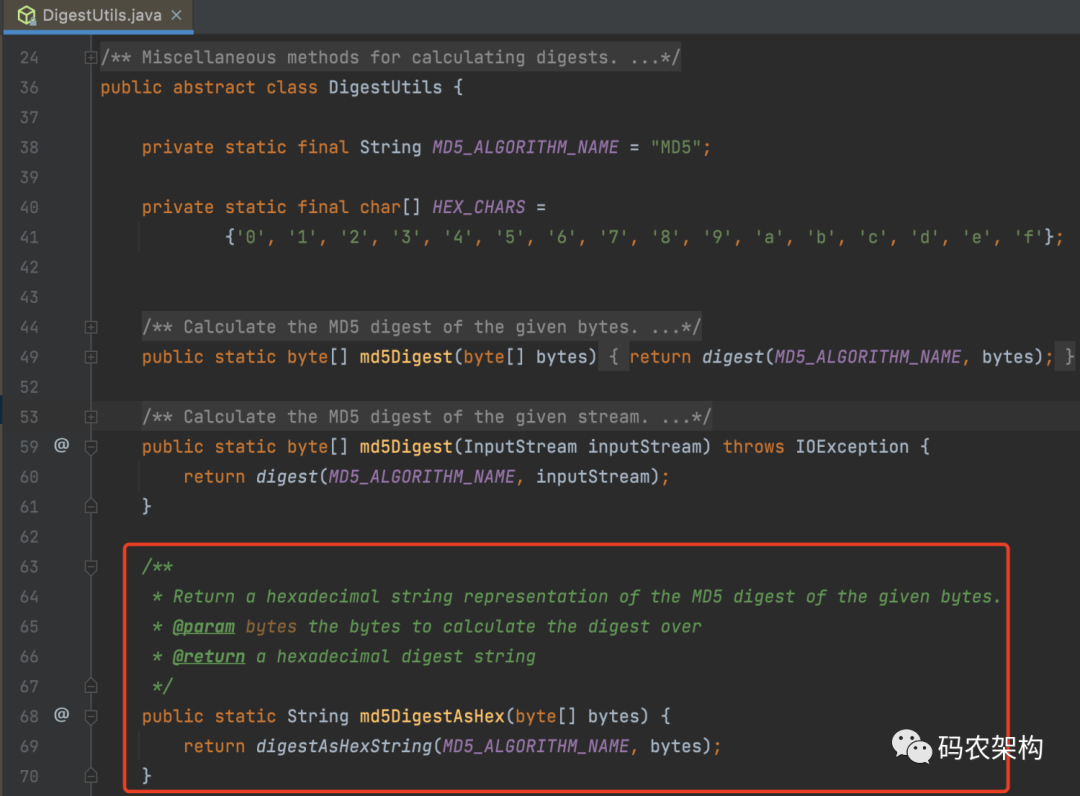
md5DigestAsHex source code
/**
* Bytes of calculation summary
* @param A hexadecimal summary character
* @return String returns the hexadecimal string representation of the MD5 digest for a given byte.
*/
public static String md5DigestAsHex(byte[] bytes) {
return digestAsHexString(MD5_ALGORITHM_NAME, bytes);
}After the file name, content and suffix (storage format) are determined, the file is directly generated
/**
* Generate files directly from content
*/
public static void generateFile(String destDirPath, String fileName, String content) throws FileZipException {
File targetFile = new File(destDirPath + File.separator + fileName);
//Ensure that the parent directory exists
if (!targetFile.getParentFile().exists()) {
if (!targetFile.getParentFile().mkdirs()) {
throw new FileZipException(" path is not found ");
}
}
//Set file encoding format
try (PrintWriter writer = new PrintWriter(new BufferedWriter(new OutputStreamWriter(new FileOutputStream(targetFile), ENCODING)))
) {
writer.write(content);
return;
} catch (Exception e) {
throw new FileZipException("create file error",e);
}
}The advantages of generating files through content are self-evident, which can greatly reduce our initiative to generate new files based on content comparison. If the file content is large and the corresponding file name is the same, it means that the content has not been adjusted. At this time, we do not need to do subsequent file update operations.
3, Fragment upload attachment
The so-called piecemeal upload is to upload the files according to a certain size, Separate the entire file into multiple data blocks (we call it Part) to upload separately. After uploading, the server will summarize all uploaded files and integrate them into the original files. Fragment upload can not only avoid the problem of always uploading from the starting position of the file due to the poor network environment, but also use multithreading to send different block data concurrently, improve the transmission efficiency and reduce the cost Send time.
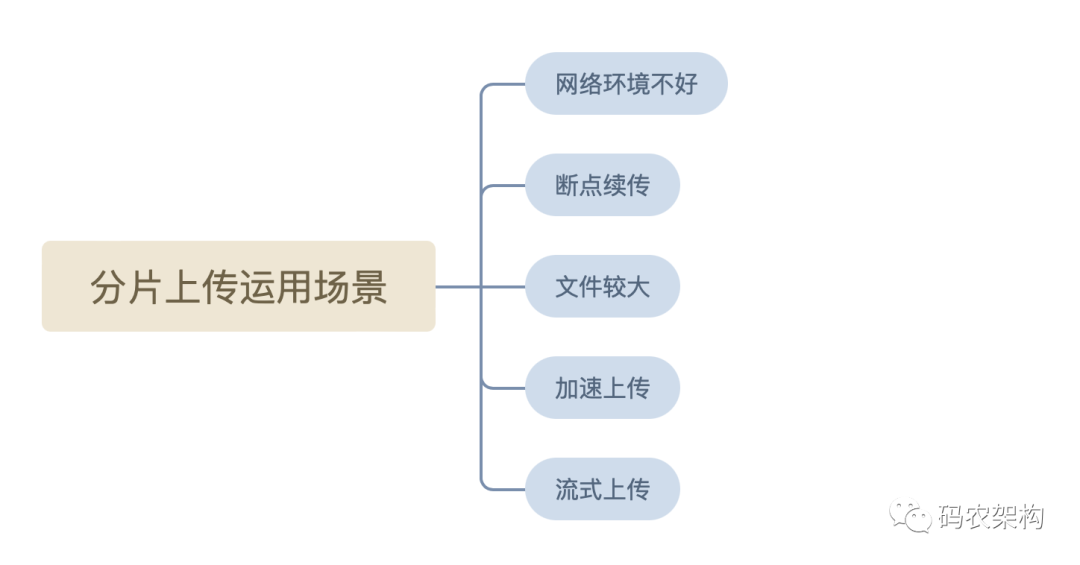
Fragment upload is mainly applicable to the following scenarios:
- Bad network environment: in case of upload failure, you can retry the failed Part independently without uploading other parts again.
- Resume at breakpoint: after a pause, you can continue to upload from the location of the last uploaded Part.
- Speed up upload: when the local file to be uploaded to the OSS is large, you can upload multiple parts in parallel to speed up the upload.
- Streaming upload: you can start uploading when the size of the file to be uploaded is uncertain. This scenario is common in video surveillance and other industries.
- Large file: generally, when the file is large, it will be uploaded in pieces by default.
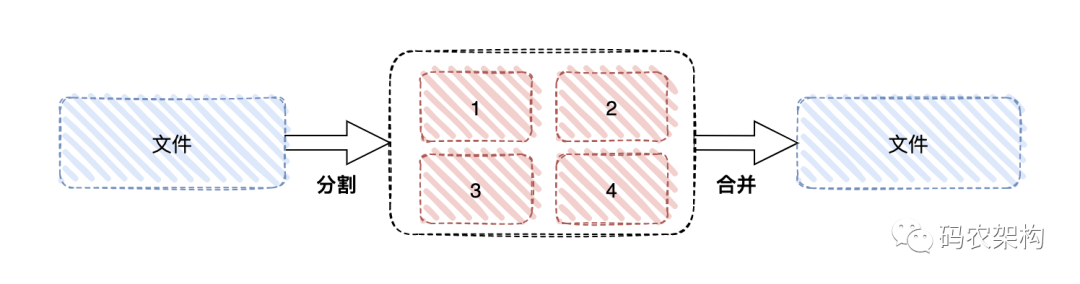
The whole process of fragment upload is roughly as follows:
- Divide the files to be uploaded into data blocks of the same size according to certain segmentation rules;
- Initialize a slice upload task and return the unique ID of this slice upload;
- Send each fragment data block according to a certain strategy (serial or parallel);
- After sending, the server judges whether the data upload is complete according to the. If it is complete, it will synthesize the data blocks to obtain the original file
Defines the size of the fragmentation rule
By default, the file reaches 20MB for forced fragmentation
/** * Force fragment file size (20MB) */ long FORCE_SLICE_FILE_SIZE = 20L* 1024 * 1024;
In order to facilitate debugging, the threshold value of the mandatory fragment file is adjusted to 1KB
Η define the fragment upload object
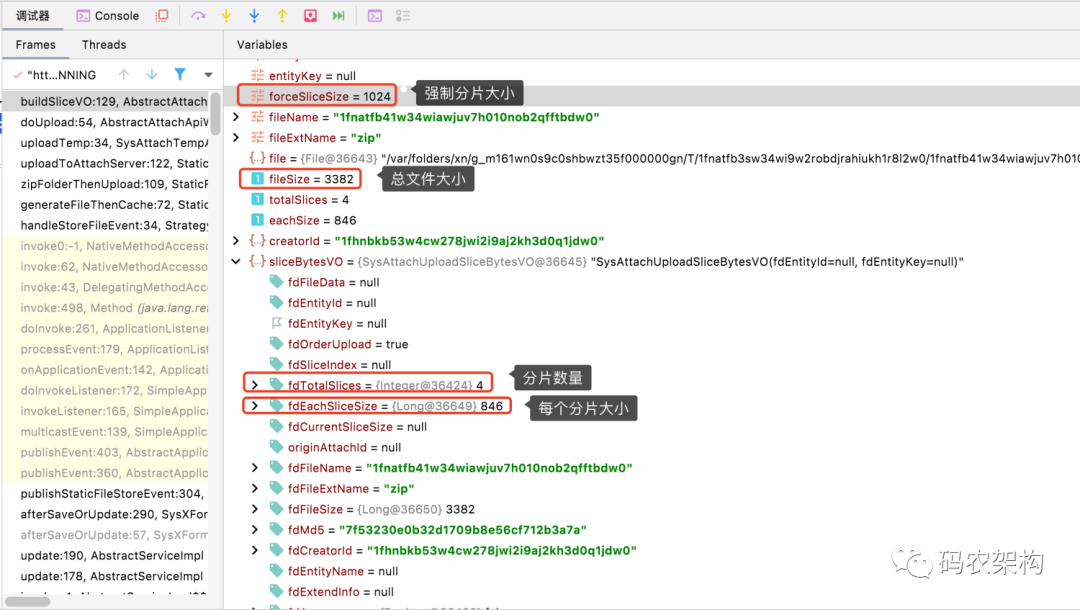
As shown in the above figure, the basic attributes of the fragment upload object are defined, including attachment file name, original file size, original file MD5 value, total number of fragments, size of each fragment, current fragment size, current fragment sequence number, etc
The definition basis is to facilitate subsequent business expansion such as reasonable file segmentation and fragment consolidation. Of course, the expansion attribute can be defined according to the business scenario.
- Total number of slices
long totalSlices = fileSize % forceSliceSize == 0 ?
fileSize / forceSliceSize : fileSize / forceSliceSize + 1;
- Size of each slice
long eachSize = fileSize % totalSlices == 0 ?
fileSize / totalSlices : fileSize / totalSlices + 1;
- MD5 value of the original file
MD5Util.hex(file)
For example:
The current attachment size is 3382KB, and the mandatory partition size is limited to 1024KB
Through the above calculation, the number of slices is 4, and the size of each slice is 846KB
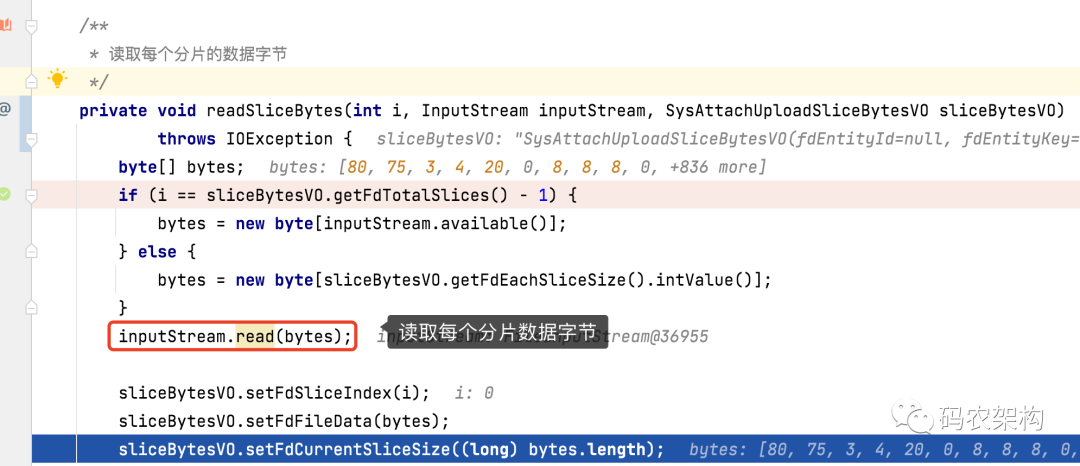
♪ read the data bytes of each partition
Mark the current byte subscript and read the data bytes of 4 slices circularly
try (InputStream inputStream = new FileInputStream(uploadVO.getFile())) {
for (int i = 0; i < sliceBytesVO.getFdTotalSlices(); i++) {
// Read the data bytes of each partition
this.readSliceBytes(i, inputStream, sliceBytesVO);
// Call the function of fragment upload API
String result = sliceApiCallFunction.apply(sliceBytesVO);
if (StringUtils.isEmpty(result)) {
continue;
}
return result;
}
} catch (IOException e) {
throw e;
}
3, Summary
The so-called fragment upload is to separate the file to be uploaded into multiple data blocks (we call them parts) according to a certain size.
Processing large files for slicing, the main core is to determine three points
- File fragmentation granularity
- How to read slices
- How are shards stored
This article mainly analyzes and deals with how to compare and segment the contents of large files in the process of uploading large files. Reasonably set the fragment threshold and how to read and mark the fragment. I hope it can help or inspire students engaged in related work. Later, we will explain in detail how to store, mark and merge files.