[source code analysis] PyTorch distributed elastic training (4) - Rendezvous architecture and logic
0x00 summary
In the previous article, we have learned the basic modules of PyTorch distribution and introduced several official examples. Next, we will introduce the flexibility training of PyTorch. This is the fourth article to see the structure and overall logic of Rendezvous.
The flexibility training series is as follows:
[Source code analysis] PyTorch distributed elastic training (1) - general idea
[ Source code analysis] PyTorch distributed elastic training (2) - start & single node process
[ Source code analysis] PyTorch distributed elastic training (3) - agent
0x01 general background
TE is composed of multiple elastic agent s based on Rendezvous, which is a separation of functions. Let's compare it.
- Agent focuses on the logic on specific nodes.
- The Agent is responsible for specific business logic related operations, such as starting the process, executing the user program, monitoring the operation of the user program, and notifying Rendezvous if there are exceptions.
- Agent is a worker manager, which is responsible for starting / managing the workers process, forming a worker group, monitoring the running status of workers, capturing failed workers, and restarting the worker group if there is a fault / new worker.
- The Agent is responsible for maintaining WORLD_SIZE and RANK information. The user does not need to provide it manually, and the Agent will process it automatically.
- Agent is a background process on a specific node and an independent individual. The agent itself cannot realize the overall elastic training, so it needs a mechanism to complete the mutual discovery between worker s, change synchronization, etc. (in fact, the information of WORLD_SIZE and RANK also needs the synchronization of multiple nodes to be determined). This is the following Rendezvous concept.
- Rendezvous is responsible for cluster logic to ensure that nodes reach a strong consensus on "which nodes participate in training".
- Each Agent includes a Rendezvous handler. These handlers generally form a Rendezvous cluster, thus forming an Agent cluster.
- After Rendezvous is completed, a shared key value store will be created, which implements a torch.distributed.Store API. This store is only shared by members who have completed Rendezvous. It is designed to allow Torch Distributed Elastic to exchange control and data information during initialization.
- Rendezvous is responsible for maintaining all relevant information of the current group on each agent. There is a rendezvous on each agent. They will communicate with each other and generally maintain a set of information, which is stored in the Store mentioned above.
- Rendezvous is responsible for cluster logic, such as adding new nodes, removing nodes, allocating rank, etc.
0x02 basic concepts
In the context of Torch Distributed Elastic, people use the term rendezvous to refer to a specific function: a distributed synchronization primitive combined with peer discovery.
It can be understood as a distributed governance process: rendezvous is used by Torch Distributed Elastic to collect participants of a training job (node), so that the participants can negotiate the list of participants and the roles of each participant, and also make a unanimous collective decision on when to start / resume the training. That is, through rendezvous, the system reaches a consensus with the participants, assigns rank and local rank to each participant, notifies world size, etc. when elastic scaling is required or failure occurs, The rendezvous operation will be repeated.
In order to realize elastic training, there needs to be a mechanism for nodes / processes to discover each other. In TorchElastic, rendezvous is the discovery mechanism or synchronization component, which is used as the distributed synchronization (Governance) mechanism of peer-to-peer discovery to synchronize and collect the information of each worker, including node list and worker role of each node, and then each Agent can jointly decide the start, end and recovery of training.
The picture comes from PyTorch source code.
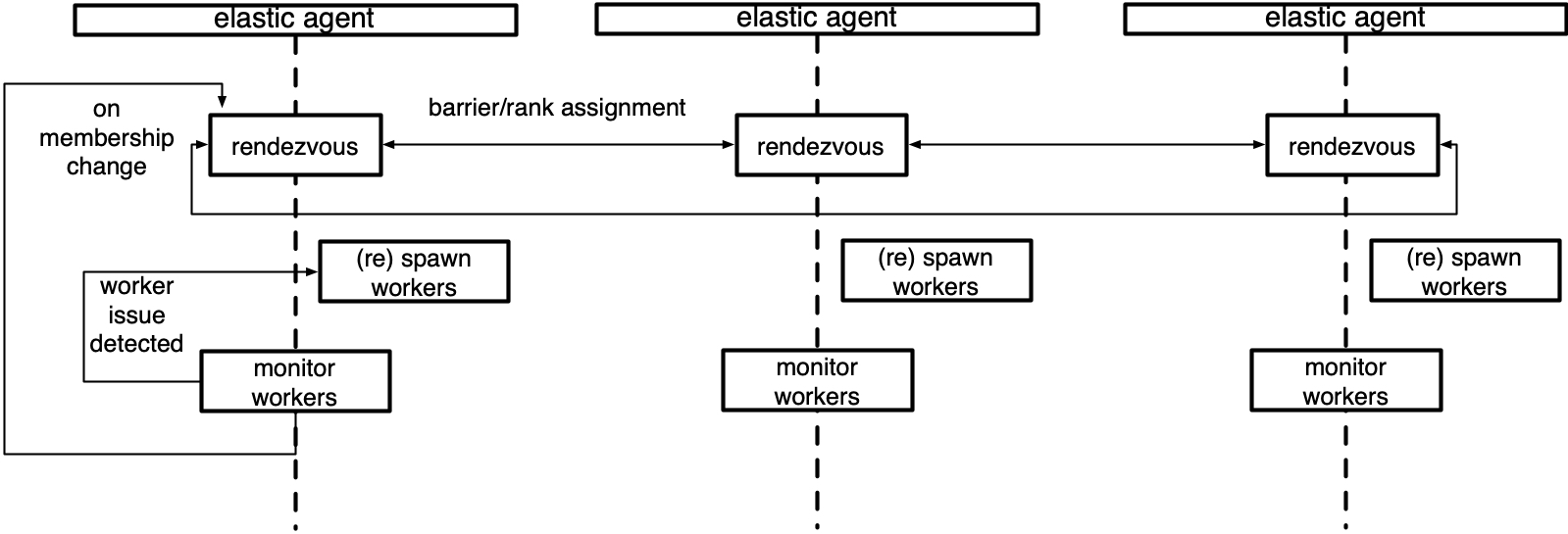
Or use the pictures in the TE source code to more clearly see that these are three nodes.

Rendezvous provides the following subdivision functions.
2.1 Barrier
All nodes executing rendezvous will be blocked until rendezvous is completed, that is, at least min nodes (for the same job) have joined the barrier, which also means that the barrier is unnecessary for the number of nodes with a fixed size.
After the number of "min" is reached, rendezvous will not announce the completion immediately, but will wait for an additional short period of time, which is used to ensure that rendezvous will not complete "too fast", because if it is completed immediately, it will miss those nodes that are only a little slower when joining. Of course, if max nodes are clustered at the Barrier, rendezvous is completed immediately.
In addition, there is a total timeout configuration: if min nodes are not reached within the timeout, it will lead to rendezvous failure. This is a simple fail safe solution to help release some allocated job resources and prevent resource waste.
2.2 Exclusivity
A simple distributed barrier is not enough, because we also need to ensure that there is only one group of nodes at any given time (for a given job). In other words, for the same job, new nodes (i.e. later joined nodes) cannot form a new parallel independent worker group.
The Torch Distributed Elastic ensures that if a group of nodes has completed rendezvous (may be training), other "late" nodes trying to join will only be considered as waiting and must wait until the existing rendezvous is completed.
2.3 Consistency
After rendezvous is completed, all its members will reach a consensus on job membership and everyone's role in it. This role is represented by an integer between 0 and world size, which is called rank.
Please note that the rank is unstable. For example, the same node may be assigned a different rank in the next (RE) rendezvous.
2.4 fault tolerance
The Torch Distributed Elastic rendezvous has a fault tolerance mechanism in the rendezvous process:
-
Between the start of join rendezvous and the completion of rendezvous, if there is a process crash (or network failure, etc.), a re rendezvous will be automatically triggered, and the remaining healthy nodes will be reorganized automatically.
-
Nodes may also fail after rendezvous is completed (or observed by other nodes). This scenario is responsible by the Torch Distributed Elastic train_loop, and a re rendezvous will also be triggered, and the training process will not be interrupted.
2.5 shared key value storage
After Rendezvous completes, a shared key value store will be created and returned to node. This store implements a torch.distributed.store API (see https://pytorch.org/docs/stable/distributed.html).
This storage is only shared by members who have completed rendezvous and is used by Torch Distributed Elastic to exchange information necessary to initialize job control and data plane.
2.6 wait for the worker and rendezvous to close
The Torch Distributed Elastic rendezvous handler provides additional functions:
- Query how many worker s join (are late) after the barrier, and they will participate in the next rendezvous.
- Set rendezvous to off state to notify all nodes not to participate in the next rendezvous.
2.7 DynamicRendzvousHandler
The Torch Distributed Elastic provides the DynamicRendzvousHandler class, which implements the rendezvous mechanism described above.
This class requires us to specify the backend (RendezvousBackend) during construction. Users can implement the backend themselves, or use one of the following PyTorch attached implementations:
- C10dRendezvousBackend uses C10d storage (TCPStore by default) as the rendezvous backend. Its advantage is that it does not need to rely on a third party, such as etcd, to build a rendezvous.
- EtcdRendezvousBackend uses EtcdRendezvousHandler, EtcdRendezvousBackend and other classes to complete based on Etcd. The disadvantage is that Etcd needs to be built.
For example:
store = TCPStore("localhost")
backend = C10dRendezvousBackend(store, "my_run_id")
rdzv_handler = DynamicRendezvousHandler.from_backend(
run_id="my_run_id",
store=store,
backend=backend,
min_nodes=2,
max_nodes=4
)
2.8 Problem & Design
Knowing the functions to be implemented, we can think about which internal modules Rendezvous should have to meet these requirements.
- A node concept is needed to express the system.
- There needs to be a state concept, that is, the state of the node.
- There needs to be an overall static class to maintain nodes, states and other information.
- There needs to be a shared key value storage, which can store the above information centrally, or exchange information with each other to reach a consensus.
- You need a dynamic server or handler that provides a set of API s for external access.
Let's analyze according to this idea, first look at the static structure, and then look at the dynamic logic.
0x03 static structure
Let's look at the supporting system. It should be noted that there is a Rendezvous in elastic, which is different from the original Rendezvous in distributed. Don't get confused. Distributed the original Rendezvous is a simple set of KV storage. elastic Rendezvous is much more complex.
Let's take a closer look at Rendezvous's support system.
3.1 startup parameters
RendezvousParameters are the parameters required to build RendezvousHandler.
- Backend: backend name.
- Endpoint: endpoint in [:].
- run_ id: id of rendezvous.
- min_nodes: the minimum number of nodes for rendezvous.
- max_nodes: the maximum number of nodes in rendezvous.
- kwargs: additional parameters for the backend.
class RendezvousParameters:
"""Holds the parameters to construct a :py:class:`RendezvousHandler`.
Args:
backend:
The name of the backend to use to handle the rendezvous.
endpoint:
The endpoint of the rendezvous, usually in form <hostname>[:<port>].
run_id:
The id of the rendezvous.
min_nodes:
The minimum number of nodes to admit to the rendezvous.
max_nodes:
The maximum number of nodes to admit to the rendezvous.
**kwargs:
Additional parameters for the specified backend.
"""
def __init__(
self,
backend: str,
endpoint: str,
run_id: str,
min_nodes: int,
max_nodes: int,
**kwargs,
):
if not backend:
raise ValueError("The rendezvous backend name must be a non-empty string.")
if min_nodes < 1:
raise ValueError(
f"The minimum number of rendezvous nodes ({min_nodes}) must be greater than zero."
)
if max_nodes < min_nodes:
raise ValueError(
f"The maximum number of rendezvous nodes ({max_nodes}) must be greater than or "
f"equal to the minimum number of rendezvous nodes ({min_nodes})."
)
self.backend = backend
self.endpoint = endpoint
self.run_id = run_id
self.min_nodes = min_nodes
self.max_nodes = max_nodes
self.config = kwargs
3.2 configuration
The RendezvousSettings class is used to store the configuration of rendezvous. It can be understood as static meta information.
- run_ id: id of rendezvous.
- min_nodes: the minimum number of nodes for rendezvous.
- max_nodes: the maximum number of nodes in rendezvous.
- Timeout: timeout.
- keep_alive_interval: the amount of time a node waits between sending heartbeats.
- keep_alive_max_attempt: maximum number of retries for heartbeat.
@dataclass(repr=False, eq=False, frozen=True)
class RendezvousSettings:
"""Holds the settings of the rendezvous.
Attributes:
run_id:
The run id of the rendezvous.
min_nodes:
The minimum number of nodes to admit to the rendezvous.
max_nodes:
The maximum number of nodes to admit to the rendezvous.
timeout:
The timeout configuration of the rendezvous.
keep_alive_interval:
The amount of time a node waits before sending a heartbeat to keep
it alive in the rendezvous.
keep_alive_max_attempt:
The maximum number of failed heartbeat attempts after which a node
is considered dead.
"""
run_id: str
min_nodes: int
max_nodes: int
timeout: RendezvousTimeout
keep_alive_interval: timedelta
keep_alive_max_attempt: int
3.3 status
_ Rendezvous state is the state of rendezvous. It is dynamic information. Each node maintains a local state.
-
Round: current round of Rendezvous
-
complete: a Boolean value indicating whether the current round of rendezvous has been completed.
-
Deadline: deadline. If the current round has been waiting for nodes to join, if this parameter is set, it is the deadline for waiting.
-
closed: a Boolean value indicating whether rendezvous has ended.
-
Participants: a dictionary structure that stores participants and their corresponding ranks.
-
wait_list: set structure, which stores a group of nodes waiting to participate in the next round of rendezvous operation
-
last_ Heartbeat: a dictionary containing the last heartbeat time of each node.
class _RendezvousState:
"""Holds the state of a rendezvous.
Attributes:
round:
The current round of the rendezvous.
complete:
A boolean value indicating whether the current round of the
rendezvous is complete.
deadline:
The time at which the current round of the rendezvous will be
considered complete if it is still waiting for nodes to join.
closed:
A boolean value indicating whether the rendezvous is closed.
participants:
A dictionary of the participants and their corresponding ranks.
wait_list:
A set of nodes that are waiting to participate in the next round of
the rendezvous.
last_heartbeats:
A dictionary containing each node's last heartbeat time.
"""
round: int
complete: bool
deadline: Optional[datetime]
closed: bool
participants: Dict[_NodeDesc, int]
wait_list: Set[_NodeDesc]
last_heartbeats: Dict[_NodeDesc, datetime]
def __init__(self) -> None:
self.round = 0
self.complete = False
self.deadline = None
self.closed = False
self.participants = {}
self.wait_list = set()
self.last_heartbeats = {}
3.4 nodes
_ NodeDesc is a node of rendezvous.
@dataclass(eq=True, order=True, frozen=True)
class _NodeDesc:
"""Describes a node in the rendezvous.
Attributes:
fqdn:
The FQDN of the node.
pid:
The id of the process in which the rendezvous handler runs.
local_id:
A process-wide unique id.
"""
fqdn: str
pid: int
local_id: int
def __repr__(self) -> str:
return f"{self.fqdn}_{self.pid}_{self.local_id}"
3.5 back end
In PyTorch, the backend concept refers to the communication backend to be used by the current process. Generally speaking, the supported communication backend includes gloo, mpi and nccl. Nccl is recommended.
In elastic training, the DynamicRendezvousHandler requires us to specify the backend (RendezvousBackend) during construction. Users can implement the backend themselves, or use one of the following PyTorch attached implementations:
- C10dRendezvousBackend uses C10d storage (TCPStore by default) as the rendezvous backend. Its advantage is that it does not need to rely on a third party, such as etcd, to build a rendezvous.
- EtcdRendezvousBackend, which uses EtcdRendezvousHandler, EtcdRendezvousBackend and other classes to complete based on etcd.
Because EtcdRendezvousBackend must rely on ETCD and an ETCD cluster needs to be installed, c10d backend is recommended for better ease of use. Let's focus on the c10d backend.
C10d backend is mainly based on a TCPStore, which is synchronized through TCP. We introduced TCPStore in the previous article. TCPStore is a distributed key value storage implementation based on TCP (similar to Redis). It is a typical client server architecture. The server stores / saves data, and the storage client can connect to the server through TCP to store and perform peer-to-peer operations such as set() inserting key value pairs and get() retrieving key values.
Therefore, for the c10d backend, the TCPStore Master will run on one of the agents, which is responsible for listening to the port and providing API s. Various synchronization operations of Rendezvous are completed by connecting each agent to the centralized TCPStore Master.
The details can be shown in the figure below, which comes from Zhihu Bob Liu.
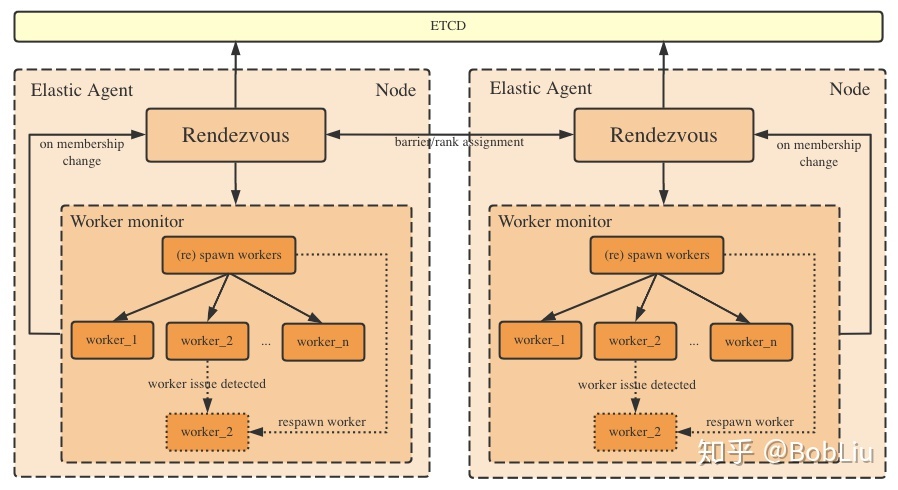
3.5. 1 use
The following figure shows how to configure the backend
store = TCPStore("localhost")
backend = C10dRendezvousBackend(store, "my_run_id") # Backend configured
rdzv_handler = DynamicRendezvousHandler.from_backend(
run_id="my_run_id",
store=store,
backend=backend,
min_nodes=2,
max_nodes=4
)
3.5. 2 base class
Let's first look at the back-end base class RendezvousBackend. This is a virtual class whose main function is to set and obtain State.
class RendezvousBackend(ABC):
"""Represents a backend that holds the rendezvous state."""
@property
@abstractmethod
def name(self) -> str:
"""Gets the name of the backend."""
@abstractmethod
def get_state(self) -> Optional[Tuple[bytes, Token]]:
"""Gets the rendezvous state.
Returns:
A tuple of the encoded rendezvous state and its fencing token or
``None`` if no state is found in the backend.
"""
@abstractmethod
def set_state(
self, state: bytes, token: Optional[Token] = None
) -> Optional[Tuple[bytes, Token, bool]]:
"""Sets the rendezvous state.
The new rendezvous state is set conditionally:
- If the specified ``token`` matches the fencing token stored in the
backend, the state will be updated. The new state will be returned
to the caller along with its fencing token.
- If the specified ``token`` does not match the fencing token stored
in the backend, the state won't be updated; instead the existing
state along with its fencing token will be returned to the caller.
- If the specified ``token`` is ``None``, the new state will be set
only if there is no existing state in the backend. Either the new
state or the existing state along with its fencing token will be
returned to the caller.
Args:
state:
The encoded rendezvous state.
token:
An optional fencing token that was retrieved by a previous call
to :py:meth:`get_state` or ``set_state()``.
Returns:
A tuple of the serialized rendezvous state, its fencing token, and
a boolean value indicating whether our set attempt succeeded.
Raises:
RendezvousConnectionError:
The connection to the backend has failed.
RendezvousStateError:
The rendezvous state is corrupt.
"""
3.5. 3 Create
The following code is how to create a backend. It first generated tcp store and then called C10dRendezvousBackend.
def create_backend(params: RendezvousParameters) -> Tuple[C10dRendezvousBackend, Store]:
"""Creates a new :py:class:`C10dRendezvousBackend` from the specified
parameters.
+--------------+-----------------------------------------------------------+
| Parameter | Description |
+==============+===========================================================+
| store_type | The type of the C10d store. As of today the only |
| | supported type is "tcp" which corresponds to |
| | :py:class:`torch.distributed.TCPStore`. Defaults to "tcp".|
+--------------+-----------------------------------------------------------+
| read_timeout | The read timeout, in seconds, for store operations. |
| | Defaults to 60 seconds. |
+--------------+-----------------------------------------------------------+
| is_host | A boolean value indicating whether this backend instance |
| | will host the C10d store. If not specified it will be |
| | inferred heuristically by matching the hostname or the IP |
| | address of this machine against the specified rendezvous |
| | endpoint. Defaults to ``None``. |
| | |
| | Note that this configuration option only applies to |
| | :py:class:`torch.distributed.TCPStore`. In normal |
| | circumstances you can safely skip it; the only time when |
| | it is needed is if its value cannot be correctly |
| | determined (e.g. the rendezvous endpoint has a CNAME as |
| | the hostname or does not match the FQDN of the machine). |
+--------------+-----------------------------------------------------------+
"""
# As of today we only support TCPStore. Other store types do not have the
# required functionality (e.g. compare_set) yet.
store_type = params.get("store_type", "tcp").strip().lower()
if store_type != "tcp":
raise ValueError("The store type must be 'tcp'. Other store types are not supported yet.")
store = _create_tcp_store(params)
return C10dRendezvousBackend(store, params.run_id), store
3.5.3.1 TCPStore
_ create_tcp_store establishes a TCPStore.
def _create_tcp_store(params: RendezvousParameters) -> TCPStore:
host, port = parse_rendezvous_endpoint(params.endpoint, default_port=29400)
cfg_is_host = params.get_as_bool("is_host") # Get configuration
# If the user has explicitly specified whether our process should host the
# the store, respect it.
if cfg_is_host is not None: # If configured, use
is_host = cfg_is_host
# Otherwise try to determine whether we are the host based on our hostname
# and IP address.
else: # Otherwise, dynamically check whether the local machine is host
is_host = _matches_machine_hostname(host)
# The timeout
read_timeout = cast(int, params.get_as_int("read_timeout", 60))
if read_timeout <= 0:
raise ValueError("The read timeout must be a positive integer.")
# In specific cases we attempt to instantiate the store twice. For details
# see the explanation in the except clause below.
for is_server in [is_host, False]:
try:
store = TCPStore( # type: ignore[call-arg]
host, port, is_master=is_server, timeout=timedelta(seconds=read_timeout)
)
if is_server:
log.info(
f"Process {os.getpid()} hosts the TCP store for the C10d rendezvous backend."
)
break
except (ValueError, RuntimeError) as exc:
# If we heuristically inferred the value of is_host as True and our
# first attempt to instantiate the TCP store has failed, try it one
# more time with is_host set to False. As an edge case there can be
# more than one process that is part of the same rendezvous on this
# machine and only one of them will eventually host the store.
if not is_server or cfg_is_host is not None:
raise RendezvousConnectionError(
"The connection to the C10d store has failed. See inner exception for details."
) from exc
return store
3.5.3.2 C10dRendezvousBackend
You can see that the core of C10dRendezvousBackend is a store to store relevant information. The following code is simplified through set_state and get_state to read and write the store.
class C10dRendezvousBackend(RendezvousBackend):
"""Represents a C10d-backed rendezvous backend.
Args:
store:
The :py:class:`torch.distributed.Store` instance to use to
communicate with the C10d store.
run_id:
The run id of the rendezvous.
"""
# See the explanation in the __init__ method.
_NULL_SENTINEL = "Y2FuaW1hZGFt"
_store: Store
_key: str
def __init__(self, store: Store, run_id: str) -> None:
if not run_id:
raise ValueError("The run id must be a non-empty string.")
self._store = store
self._key = "torch.rendezvous." + run_id
# The read operation of a store blocks the caller until the specified
# key becomes available. This behavior makes it tricky to use a store
# as a regular key-value dictionary.
#
# As a workaround we initially set a sentinel value as the rendezvous
# state. Whenever this value gets returned we treat it as a None.
self._call_store("compare_set", self._key, "", self._NULL_SENTINEL)
@property
def name(self) -> str:
"""See base class."""
return "c10d"
def get_state(self) -> Optional[Tuple[bytes, Token]]:
"""See base class."""
# Read data from store
base64_state: bytes = self._call_store("get", self._key)
return self._decode_state(base64_state)
def set_state(
self, state: bytes, token: Optional[Token] = None
) -> Optional[Tuple[bytes, Token, bool]]:
"""See base class."""
base64_state_str: str = b64encode(state).decode()
if token:
# Shortcut if we know for sure that the token is not valid.
if not isinstance(token, bytes):
result = self.get_state()
if result is not None:
tmp = *result, False
# Python 3.6 does not support tuple unpacking in return
# statements.
return tmp
return None
token = token.decode()
else:
token = self._NULL_SENTINEL
# Insert data into the store
base64_state: bytes = self._call_store("compare_set", self._key, token, base64_state_str)
state_token_pair = self._decode_state(base64_state)
if state_token_pair is None:
return None
new_state, new_token = state_token_pair
# C10d Store's compare_set method does not offer an easy way to find out
# whether our write attempt was successful. As a brute-force solution we
# perform a bitwise comparison of our local state and the remote state.
return new_state, new_token, new_state == state
def _call_store(self, store_op: str, *args, **kwargs) -> Any:
return getattr(self._store, store_op)(*args, **kwargs)
def _decode_state(self, base64_state: bytes) -> Optional[Tuple[bytes, Token]]:
if base64_state == self._NULL_SENTINEL.encode():
return None
state = b64decode(base64_state)
return state, base64_state
3.6 StateHolder
3.6.1 _RendezvousStateHolder
The function of this class is to save the rendezvous state synchronized with other nodes, but a derived class is required to complete the function.
class _RendezvousStateHolder(ABC):
"""Holds the shared rendezvous state synced with other nodes."""
@property
@abstractmethod
def state(self) -> _RendezvousState:
"""Gets the local state."""
@abstractmethod
def sync(self) -> Optional[bool]:
"""Reads or writes the latest state.
Returns:
A boolean value indicating whether the local state, in case marked
as dirty, was successfully synced with other nodes.
"""
@abstractmethod
def mark_dirty(self) -> None:
"""Marks the local state as dirty."""
3.6.2 _BackendRendezvousStateHolder
_ BackendRendezvousStateHolder extends_ RendezvousStateHolder. Its sync is to call the internal back end to read and write the store.
class _BackendRendezvousStateHolder(_RendezvousStateHolder):
"""Holds the rendezvous state synced with other nodes via a backend.
Args:
backend:
The rendezvous backend to use.
settings:
The rendezvous settings.
cache_duration:
The amount of time, in seconds, to cache the last rendezvous state
before requesting it from the backend again.
"""
_backend: RendezvousBackend
_state: _RendezvousState
_settings: RendezvousSettings
_cache_duration: int
_token: Token
_dirty: bool
_last_sync_time: float
_dead_nodes: List[_NodeDesc]
def __init__(
self, backend: RendezvousBackend, settings: RendezvousSettings, cache_duration: int = 1
) -> None:
self._backend = backend
self._state = _RendezvousState()
self._settings = settings
self._cache_duration = cache_duration
self._token = None
self._dirty = False
self._last_sync_time = -1
self._dead_nodes = []
@property
def state(self) -> _RendezvousState:
"""See base class."""
return self._state
def sync(self) -> Optional[bool]:
"""See base class."""
state_bits: Optional[bytes] = None
token = None
has_set: Optional[bool]
if self._dirty:
has_set = False
state_bits = pickle.dumps(self._state)
# The backend will be set here
set_response = self._backend.set_state(state_bits, self._token)
if set_response is not None:
state_bits, token, has_set = set_response
else:
has_set = None
if self._cache_duration > 0:
# Avoid overloading the backend if we are asked to retrieve the
# state repeatedly. Try to serve the cached state.
if self._last_sync_time >= max(time.monotonic() - self._cache_duration, 0):
return None
get_response = self._backend.get_state()
if get_response is not None:
state_bits, token = get_response
if state_bits is not None:
try:
self._state = pickle.loads(state_bits)
except pickle.PickleError as exc:
raise RendezvousStateError(
"The rendezvous state is corrupt. See inner exception for details."
) from exc
else:
self._state = _RendezvousState()
if has_set and self._dead_nodes and log.isEnabledFor(logging.DEBUG):
node_list = ", ".join(f"'{dead_node}'" for dead_node in self._dead_nodes)
self._token = token
self._dirty = False
self._last_sync_time = time.monotonic()
self._sanitize()
return has_set
def _sanitize(self) -> None:
expire_time = datetime.utcnow() - (
self._settings.keep_alive_interval * self._settings.keep_alive_max_attempt
)
# Filter out the dead nodes.
self._dead_nodes = [
node
for node, last_heartbeat in self._state.last_heartbeats.items()
if last_heartbeat < expire_time
]
for dead_node in self._dead_nodes:
del self._state.last_heartbeats[dead_node]
try:
del self._state.participants[dead_node]
except KeyError:
pass
try:
self._state.wait_list.remove(dead_node)
except KeyError:
pass
def mark_dirty(self) -> None:
"""See base class.
If the local rendezvous state is dirty, the next sync call will try to
write the changes back to the backend. However this attempt might fail
if another node, which had the same state, also made changes and wrote
them before us.
"""
self._dirty = True
3.6. 3 how to use
How to use StateHolder_ In the distributedrendezvousopexecution (the following code is simplified):
- Pass_ state_holder.sync() synchronizes various states because the latest state is rendezvous.
- Through self_ state_ holder. State gets the latest status.
- Conduct business processing.
- Pass_ state_holder.mark_dirty() synchronizes again and synchronizes its state to other nodes
def run(
self, state_handler: Callable[[_RendezvousContext, float], _Action], deadline: float
) -> None:
"""See base class."""
action = None
while action != _Action.FINISH:
# Reads or writes the latest rendezvous state shared by all nodes in
# the rendezvous. Note that our local changes might get overridden
# by another node if that node synced its changes before us.
has_set = self._state_holder.sync() # Here we need to synchronize various states, because the latest state is rendezvous.
self._state = self._state_holder.state # Get the latest status
ctx = _RendezvousContext(self._node, self._state, self._settings)
# Determine the next action to take based on the current state of
# the rendezvous.
action = state_handler(ctx, deadline)
# Omit some codes
if action == _Action.SYNC:
# Delay the execution by one second to avoid overloading the
# backend if we are asked to poll for state changes.
_delay(seconds=1)
else:
if action == _Action.KEEP_ALIVE:
self._keep_alive()
elif action == _Action.ADD_TO_PARTICIPANTS:
self._add_to_participants()
elif action == _Action.ADD_TO_WAIT_LIST:
self._add_to_wait_list()
elif action == _Action.REMOVE_FROM_PARTICIPANTS:
self._remove_from_participants()
elif action == _Action.REMOVE_FROM_WAIT_LIST:
self._remove_from_wait_list()
elif action == _Action.MARK_RENDEZVOUS_COMPLETE:
self._mark_rendezvous_complete()
elif action == _Action.MARK_RENDEZVOUS_CLOSED:
self._mark_rendezvous_closed()
# Attempt to sync our changes back to other nodes.
self._state_holder.mark_dirty() # Synchronize again and synchronize your status to other nodes
3.7 summary
We summarize the current logic as follows, two_ BackendRendezvousStateHolder carries out information exchange through TCPStore.
+ +-------------------------------+ | +-------------------------------+ | _BackendRendezvousStateHolder | | | _BackendRendezvousStateHolder | | | +-------------------+ | +--------------------+ | | | _settings +-----------> | RendezvousSettings| | | RendezvousSettings | <----------+ _settings | | | +-------------------+ | +--------------------+ | | | | +-------------------+ | +--------------------+ | | | _state +--------------> | _RendezvousState | | | _RendezvousState | <----------+ _state | | | | | | | | | | | | +-------------------+ | +--------------------+ | | | | | | | | | +-----------------------+ + +----------------------+ | | | _backend +------------> | C10dRendezvousBackend | | C10dRendezvousBackend| <-------+ _backend | | | | | +---------+ | | | | | | | _store +-----> |TCPStore | <---------+ _store | | | | | | | | | | | | | | | +-----------------------+ +---------+ +----------------------+ | | | | | | | | ^ + ^ | | | | | | | | | | | | | | | | | sync +----------------------+ | +---------------------+ sync | | | set_state | set_state | | +-------------------------------+ + +-------------------------------+
Mobile phones are as follows:

0x04 dynamic logic
4.1 entrance
Let's first look at how to use Rendezvous.
launch_agent starts a LocalElasticAgent and calls its run method. Rdzv is generated before calling run_ Handler, and then set it into the WorkerSpec.
import torch.distributed.elastic.rendezvous.registry as rdzv_registry
@record
def launch_agent(
config: LaunchConfig,
entrypoint: Union[Callable, str, None],
args: List[Any],
) -> Dict[int, Any]:
rdzv_parameters = RendezvousParameters(
backend=config.rdzv_backend,
endpoint=config.rdzv_endpoint,
run_id=config.run_id,
min_nodes=config.min_nodes,
max_nodes=config.max_nodes,
**config.rdzv_configs,
)
# Built rdzv_handler
rdzv_handler = rdzv_registry.get_rendezvous_handler(rdzv_parameters)
try:
spec = WorkerSpec(
role=config.role,
local_world_size=config.nproc_per_node,
entrypoint=entrypoint,
args=tuple(args),
rdzv_handler=rdzv_handler, # Rdzv is set here_ handler
max_restarts=config.max_restarts,
monitor_interval=config.monitor_interval,
redirects=config.redirects,
tee=config.tee,
master_addr=master_addr,
master_port=master_port,
)
agent = LocalElasticAgent( # structure
spec=spec, start_method=config.start_method, log_dir=config.log_dir
)
result = agent.run() # Start agent
except ChildFailedError:
In the run function, it will eventually call self_ rendezvous(worker_group),_ The rendezvous method calls next_rendezvous() to handle membership changes.
@prof
def _rendezvous(self, worker_group: WorkerGroup) -> None:
r"""
Runs rendezvous for the workers specified by worker spec.
Assigns workers a new global rank and world size.
Updates the rendezvous store for the worker group.
"""
spec = worker_group.spec
store, group_rank, group_world_size = spec.rdzv_handler.next_rendezvous()
# Omit subsequent codes
In this process, rdzv_registry.get_rendezvous_handler(rdzv_parameters) is the original source, so let's look at get_rendezvous_handler. And get_rendezvous_handler will return RendezvousHandler, so RendezvousHandler and rendezvous_handler_registry is fundamental.
from .api import rendezvous_handler_registry as handler_registry
def get_rendezvous_handler(params: RendezvousParameters) -> RendezvousHandler:
"""
This method is used to obtain a reference to a :py:class`RendezvousHandler`.
Custom rendezvous handlers can be registered by
::
from torch.distributed.elastid.rendezvous import rendezvous_handler_registry
from torch.distributed.elastic.rendezvous.registry import get_rendezvous_handler
def create_my_rdzv(params: RendezvousParameters):
return MyCustomRdzv(params)
rendezvous_handler_registry.register("my_rdzv_backend_name", create_my_rdzv)
my_rdzv_handler = get_rendezvous_handler("my_rdzv_backend_name", RendezvousParameters)
"""
return handler_registry.create_handler(params)
Let's take a look at rendezvous handler and rendezvous respectively_ handler_ registry.
4.2 base class RendezvousHandler
RendezvousHandler is used to execute business logic. Several virtual functions are:
- next_rendezvous: the main entrance of the rendezvous barrier. Newly added nodes will wait here until the current rendezvous ends, or times out, or the current rendezvous is marked as closed.
- is_closed: whether it has ended. If rendezvous ends, it means that all attempts to re rendezvous will fail.
- num_nodes_waiting: returns the number of current stages waiting in the rendezvous barrier. These nodes do not belong to the current workgroup. The user should call this method periodically to check whether there are new nodes waiting to join the workgroup. If so, call next_rendezvous() (re-rendezvous. ) Proceed to the next re rendezvous.
The specific codes are as follows:
class RendezvousHandler(ABC):
"""Main rendezvous interface.
Note:
Distributed Torch users normally **do not** need to implement their own
``RendezvousHandler``. An implementation based on C10d Store is already
provided, and is recommended for most users.
"""
# Get rendezvous backend name
@abstractmethod
def get_backend(self) -> str:
"""Returns the name of the rendezvous backend."""
# The main entrance of the rendezvous barrier. Newly added nodes will wait here until the current rendezvous ends, or times out, or the current rendezvous is marked as closed.
@abstractmethod
def next_rendezvous(
self,
) -> Tuple[Store, int, int]:
"""Main entry-point into the rendezvous barrier.
Blocks until the rendezvous is complete and the current process is
included in the formed worker group, or a timeout occurs, or the
rendezvous was marked closed.
Returns:
A tuple of :py:class:`torch.distributed.Store`, ``rank``, and
``world size``.
"""
# Is it over? If rendezvous is over, it means that all attempts to re rendezvous will fail
@abstractmethod
def is_closed(self) -> bool:
"""Checks whether the rendezvous has been closed.
A closed rendezvous means all future attempts to re-rendezvous within
same job will fail.
"""
@abstractmethod
def set_closed(self):
"""Marks the rendezvous as closed."""
# Returns the number of current stages waiting in the rendezvous barrier. These nodes do not belong to the current workgroup. Users should call this method periodically to check whether there are new nodes waiting to join the workgroup. If so, call ` next_rendezvous()` (re-rendezvous. ) Proceed to the next re rendezvous.
@abstractmethod
def num_nodes_waiting(self) -> int:
"""Returns the number of nodes who arrived late at the rendezvous
barrier, hence were not included in the current worker group.
Callers should periodically call this method to check whether new
nodes are waiting to join the job and if so admit them by calling
:py:meth:`next_rendezvous()` (re-rendezvous).
"""
@abstractmethod
def get_run_id(self) -> str:
"""Returns the run id of the rendezvous.
The run id is a user-defined id that uniquely identifies an instance of
a distributed application. It typically maps to a job id and is used to
allow nodes to join the correct distributed application.
"""
def shutdown(self) -> bool:
"""Closes all resources that were open for the rendezvous.
"""
4.3 registration
Let's look at rendezvous_handler_registry.
In torch / distributed / elastic / rendezvous / API Py has the following code.
# The default global registry instance used by launcher scripts to instantiate # rendezvous handlers. rendezvous_handler_registry = RendezvousHandlerRegistry()
So we came to rendezvous handler registry.
4.3.1 RendezvousHandlerRegistry
RendezvousHandlerRegistry is a factory class responsible for creating RendezvousHandler.
- register is to add the corresponding builder to the internal dictionary.
- create_handler takes out the corresponding builder according to the key.
- rendezvous_handler_registry is the global registry.
class RendezvousHandlerRegistry:
"""Represents a registry of :py:class:`RendezvousHandler` backends."""
_registry: Dict[str, RendezvousHandlerCreator]
def __init__(self) -> None:
self._registry = {}
def register(self, backend: str, creator: RendezvousHandlerCreator) -> None:
"""Registers a new rendezvous backend.
Args:
backend:
The name of the backend.
creater:
The callback to invoke to construct the
:py:class:`RendezvousHandler`.
"""
current_creator: Optional[RendezvousHandlerCreator]
current_creator = self._registry[backend]
self._registry[backend] = creator
def create_handler(self, params: RendezvousParameters) -> RendezvousHandler:
"""Creates a new :py:class:`RendezvousHandler`."""
creator = self._registry[params.backend]
handler = creator(params)
return handler
4.3. 2 Global registry
The system will create a global registry, which is rendezvous as seen earlier_ handler_ registry.
# The default global registry instance used by launcher scripts to instantiate # rendezvous handlers. rendezvous_handler_registry = RendezvousHandlerRegistry()
Several handler s are registered here to provide the creator. rendezvous provides the following implementations: etcd, etcd-v2, c10d, and static.
from .api import rendezvous_handler_registry as handler_registry
def _register_default_handlers() -> None:
handler_registry.register("etcd", _create_etcd_handler)
handler_registry.register("etcd-v2", _create_etcd_v2_handler)
handler_registry.register("c10d", _create_c10d_handler)
handler_registry.register("static", _create_static_handler)
The runtime is:
rendezvous_handler_registry =
_registry = {dict: 4}
'etcd' = {function} <function _create_etcd_handler at 0x7ff657e12d08>
'etcd-v2' = {function} <function _create_etcd_v2_handler at 0x7ff657e12d90>
'c10d' = {function} <function _create_c10d_handler at 0x7ff657e12e18>
'static' = {function} <function _create_static_handler at 0x7ff657b9d2f0>
__len__ = {int} 4
It means:_ create_etcd_handler can create a handler of etcd type, and so on.
4.4 creating
Now that we have a way to create, let's take a look at how to create. rendezvous provides the following implementations: etcd, etcd-v2, c10d and static. Here, we take static and c10d as examples.
4.4. 1 static RendezvousHandler
We use_ create_static_handler example to see how to create a static handler.
First from_ create_static_handler.
4.4.1.1 _create_static_handler
def _create_static_handler(params: RendezvousParameters) -> RendezvousHandler:
from . import static_tcp_rendezvous
return static_tcp_rendezvous.create_rdzv_handler(params)
So we came to torch/distributed/elastic/rendezvous/static_tcp_rendezvous.py. There is create in it_ rdzv_ Handler establishes StaticTCPRendezvous.
def create_rdzv_handler(params: RendezvousParameters) -> RendezvousHandler:
endpoint = params.endpoint.strip()
master_addr, master_port = parse_rendezvous_endpoint(endpoint, -1)
world_size = params.max_nodes
rank = cast(int, params.config.get("rank"))
run_id = params.run_id
if "timeout" in params.config:
timeout = int(params.config["timeout"])
else:
timeout = _default_timeout_seconds
return StaticTCPRendezvous(
master_addr, master_port, rank, world_size, run_id, timeout
)
4.4.1.2 StaticTCPRendezvous subclass
StaticTCPRendezvous extends RendezvousHandler, which is defined as follows. Its main logic is: in group_ Create a TCPStore on rank = 0, and then package it into a PrefixStore.
class StaticTCPRendezvous(RendezvousHandler):
"""
Static rendezvous that is a wrapper around the TCPStore.
Creates TCPStore based on the input parameters with the
listener on the agent with group_rank=0
"""
def __init__(
self,
master_addr: str,
master_port: int,
rank: int,
world_size: int,
run_id: str,
timeout: int,
):
self.master_addr = master_addr
self.master_port = master_port
self.rank = rank
self.world_size = world_size
self.run_id = run_id
self.timeout = datetime.timedelta(seconds=timeout)
self._store: Optional[Store] = None
def get_backend(self) -> str:
return "static"
def next_rendezvous(self) -> Tuple[Store, int, int]:
if not self._store:
is_master = self.rank == 0
self._store = TCPStore(
self.master_addr,
self.master_port,
self.world_size,
is_master,
self.timeout,
)
store = PrefixStore(self.run_id, self._store)
return store, self.rank, self.world_size
Key function
def next_rendezvous(self) -> Tuple[Store, int, int]:
log.info("Creating TCPStore as the c10d::Store implementation")
if not self._store:
is_master = self.rank == 0
self._store = TCPStore(
self.master_addr,
self.master_port,
self.world_size,
is_master,
self.timeout,
)
store = PrefixStore(self.run_id, self._store)
return store, self.rank, self.world_size
4.4. 2 dynamic RendezvousHandler
Let's take a look at how to build a dynamic rendezvoushandler.
4.4.2.1 _create_c10d_handler
Here_ create_ c10d_ The handler returns a DynamicRendezvousHandler.
def _create_c10d_handler(params: RendezvousParameters) -> RendezvousHandler:
from .c10d_rendezvous_backend import create_backend
backend, store = create_backend(params)
return create_handler(store, backend, params)
The DynamicRendezvousHandler is returned here.
def create_handler(
store: Store, backend: RendezvousBackend, params: RendezvousParameters
) -> DynamicRendezvousHandler:
"""Creates a new :py:class:`DynamicRendezvousHandler` from the specified
parameters.
Args:
store:
The C10d store to return as part of the rendezvous.
backend:
The backend to use to hold the rendezvous state.
+-------------------+------------------------------------------------------+
| Parameter | Description |
+===================+======================================================+
| join_timeout | The total time, in seconds, within which the |
| | rendezvous is expected to complete. Defaults to 600 |
| | seconds. |
+-------------------+------------------------------------------------------+
| last_call_timeout | An additional wait amount, in seconds, before |
| | completing the rendezvous once the minimum number of |
| | nodes has been reached. Defaults to 30 seconds. |
+-------------------+------------------------------------------------------+
| close_timeout | The time, in seconds, within which the rendezvous is |
| | expected to close after a call to |
| | :py:meth:`RendezvousHandler.set_closed` or |
| | :py:meth:`RendezvousHandler.shutdown`. Defaults to |
| | 30 seconds. |
+-------------------+------------------------------------------------------+
"""
timeout = RendezvousTimeout(
_get_timeout(params, "join"),
_get_timeout(params, "last_call"),
_get_timeout(params, "close"),
)
return DynamicRendezvousHandler.from_backend(
params.run_id,
store,
backend,
params.min_nodes,
params.max_nodes,
timeout,
)
4.4.2.2 from_backend
from_backend is a method for generating DynamicRendezvousHandler, which is equivalent to a generator.
It generates RendezvousSettings_ BackendRendezvousStateHolder and node, and then the dynamic rendezvoushandler is established.
@classmethod
def from_backend(
cls,
run_id: str,
store: Store,
backend: RendezvousBackend,
min_nodes: int,
max_nodes: int,
timeout: Optional[RendezvousTimeout] = None,
):
"""Creates a new :py:class:`DynamicRendezvousHandler`.
Args:
run_id:
The run id of the rendezvous.
store:
The C10d store to return as part of the rendezvous.
backend:
The backend to use to hold the rendezvous state.
min_nodes:
The minimum number of nodes to admit to the rendezvous.
max_nodes:
The maximum number of nodes to admit to the rendezvous.
timeout:
The timeout configuration of the rendezvous.
"""
# We associate each handler instance with a unique node descriptor.
node = cls._node_desc_generator.generate()
settings = RendezvousSettings(
run_id,
min_nodes,
max_nodes,
timeout or RendezvousTimeout(),
keep_alive_interval=timedelta(seconds=5),
keep_alive_max_attempt=3,
)
state_holder = _BackendRendezvousStateHolder(backend, settings)
return cls(node, settings, backend.name, store, state_holder)
4.4.2.3 DynamicRendezvousHandler
Torch Distributed Elastic comes with the :py:class:`.DynamicRendezvousHandler` class that implements the rendezvous mechanism described above. It is a backend- agnostic type that expects a particular :py:class:`.RendezvousBackend` instance to be specified during construction. Torch distributed users can either implement their own backend type or use one of the following implementations that come with PyTorch:
Dynamic RendezvousHandler extends RendezvousHandler, which is defined as follows. Its main logic is: in group_ Create a TCPStore on rank = 0, and then package it into a PrefixStore.
The most important are the following member variables:
- _ Backendrendezvous stateholder is responsible for coordinating information between Rendezvous.
- _ The distributedrendezvousopexecution is responsible for the specific execution of the business.
- _ store is responsible for saving information (distributed).
class DynamicRendezvousHandler(RendezvousHandler):
"""Represents a handler that sets up a rendezvous among a set of nodes."""
# Static
_node_desc_generator = _NodeDescGenerator()
_this_node: _NodeDesc
_settings: RendezvousSettings
_backend_name: str
_store: Store
_state_holder: _RendezvousStateHolder
_op_executor: _RendezvousOpExecutor
_heartbeat_lock: threading.Lock
_keep_alive_timer: Optional[_PeriodicTimer]
@classmethod
def from_backend(
cls,
run_id: str,
store: Store,
backend: RendezvousBackend,
min_nodes: int,
max_nodes: int,
timeout: Optional[RendezvousTimeout] = None,
):
"""Creates a new :py:class:`DynamicRendezvousHandler`.
Args:
run_id:
The run id of the rendezvous.
store:
The C10d store to return as part of the rendezvous.
backend:
The backend to use to hold the rendezvous state.
min_nodes:
The minimum number of nodes to admit to the rendezvous.
max_nodes:
The maximum number of nodes to admit to the rendezvous.
timeout:
The timeout configuration of the rendezvous.
"""
# We associate each handler instance with a unique node descriptor.
node = cls._node_desc_generator.generate()
settings = RendezvousSettings(
run_id,
min_nodes,
max_nodes,
timeout or RendezvousTimeout(),
keep_alive_interval=timedelta(seconds=5),
keep_alive_max_attempt=3,
)
state_holder = _BackendRendezvousStateHolder(backend, settings)
return cls(node, settings, backend.name, store, state_holder)
def __init__(
self,
node: _NodeDesc,
settings: RendezvousSettings,
backend_name: str,
store: Store,
state_holder: _RendezvousStateHolder,
) -> None:
self._this_node = node
self._settings = settings
self._backend_name = backend_name
self._store = store
self._state_holder = state_holder
self._op_executor = _DistributedRendezvousOpExecutor(
self._this_node, self._state_holder, self._settings
)
self._heartbeat_lock = threading.Lock()
self._keep_alive_timer = None
We can also directly generate DynamicRendezvousHandler in the following way.
store = TCPStore("localhost")
backend = C10dRendezvousBackend(store, "my_run_id")
rdzv_handler = DynamicRendezvousHandler.from_backend(
run_id="my_run_id",
store=store,
backend=backend,
min_nodes=2,
max_nodes=4
)
4.4.2.4 next_rendezvous
This function call will be blocked until the number of workers meets the requirements. This function will be called when the worker is initialized or restarted. When the function returns, different worker group s will get a rank as the unique identifier. Its internal logic is:
- First use_ RendezvousExitOp causes the node to exit.
- Then use it_ RendezvousJoinOp rejoins the node.
- Finally, start the heartbeat and return to world size, store, etc. at this time, all participating nodes are in participants.
def next_rendezvous(self) -> Tuple[Store, int, int]:
"""See base class."""
self._stop_heartbeats()
# Delay the execution for a small random amount of time if this is our
# first run. This will slightly skew the rendezvous attempts across the
# nodes and reduce the load on the backend.
if self._state_holder.state.round == 0:
_delay(seconds=(0, 0.3))
exit_op = _RendezvousExitOp()
join_op = _RendezvousJoinOp()
deadline = self._get_deadline(self._settings.timeout.join)
self._op_executor.run(exit_op, deadline)
self._op_executor.run(join_op, deadline)
self._start_heartbeats()
rank, world_size = self._get_world()
store = self._get_store()
return store, rank, world_size # The rank of the worker group is returned
4.4.2.5 _get_world
In the above code, the_ get_world, let's analyze it again here. rank, world_ The size variables are generated dynamically, so they are taken from the state. Moreover, because participants are synchronized among all nodes, the participants obtained by each Node are exactly the same.
rank, world_size = self._get_world()
def _get_world(self) -> Tuple[int, int]:
state = self._state_holder.state
return state.participants[self._this_node], len(state.participants)
state. Where do participants come from? At the end of rendezvous, rank will be set. Because each Node is sorted according to the same algorithm, the rank sorting is the same on each Node. It can be ensured that the rank obtained by each Node is different from that of other nodes.
def _mark_rendezvous_complete(self) -> None:
state = self._state
state.complete = True
state.deadline = None
# Assign the ranks.
for rank, node in enumerate(sorted(state.participants)):
state.participants[node] = rank
4.5 fault tolerance
As mentioned earlier, between the start of join rendezvous and the completion of rendezvous, if there is a process crash (or network failure, etc.), a re rendezvous will be automatically triggered, and the remaining healthy nodes will be reorganized automatically.
Torch Distributed Elastic rendezvous is designed to tolerate node failures during the rendezvous process. Should a process crash (or lose network connectivity, etc), between joining the rendezvous and it being completed, then a re-rendezvous with remaining healthy nodes will happen automatically.
4.5.1 ETCD
This part of fault tolerance mechanism is particularly obvious in EtcdRendezvousHandler.
next_ The rendezvous method calls rendezvous_barrier.
def next_rendezvous(self):
rdzv_version, rank, world_size = self._rdzv_impl.rendezvous_barrier()
log.info("Creating EtcdStore as the c10d::Store implementation")
store = self._rdzv_impl.setup_kv_store(rdzv_version)
return store, rank, world_size
In Rendezvous_ In barrier, if the bottom layer throws various exceptions, it will catch and then call init_. Phase executes rendezvous again until deadline time expires.
def rendezvous_barrier(self):
"""
Main entry point for next rendezvous.
This method is blocking until rendezvous succeeds or a timeout occurs.
Returns:
``(rdzv_version, rank, world_size)``
Raises:
RendezvousTimeoutError - timeout waiting for rendezvous
RendezvousClosedError - rendezvous is or was closed while waiting
RendezvousError - other persistent errors that
render the rendezvous non-retryable
"""
self._rendezvous_deadline = time.time() + self._timeout
while True:
if time.time() > self._rendezvous_deadline:
raise RendezvousTimeoutError()
log.info("Attempting to join next rendezvous")
try:
# Dis-own our lease in the previous rendezvous, if exists
if self._lease_this_rank_stop is not None:
self._lease_this_rank_stop.set()
return self.init_phase()
except EtcdRendezvousRetryImmediately:
# The type of failure suggests we can retry without delay
pass
except EtcdRendezvousRetryableFailure:
# In case of retryable failure, wait a small delay
# to avoid spamming etcd
time.sleep(1)
except RendezvousTimeoutError:
log.info("Rendezvous timeout occured in EtcdRendezvousHandler")
raise
except RendezvousClosedError:
log.info(
f"Rendezvous for run_id={self._run_id} was observed to be closed"
)
raise
except RendezvousError:
raise
except Exception as e:
# In case of a general exception, wait a small delay
# to avoid spamming etcd
# FIXME: there are a few things that fall under this like
# etcd.EtcdKeyNotFound, etc, which could be handled more explicitly.
log.info("Rendezvous attempt failed, will retry. Reason: " + str(e))
time.sleep(1)
init_phase will launch a rendezvous round.
def init_phase(self):
"""
Initially, the rendezvous state is expected to be one of:
1. empty (non-existent) - in this case we try to create a new one.
2. joinable - we try to join it.
3. final - we announce ourselves as waiting, and go into monitoring mode
Any other state is considered transitional, and will be retried after
a short delay.
Returns:
``(rdzv_version, rank, world_size)``
Raises:
RendezvousClosedError - current rendezvous was/is closed
EtcdRendezvousRetryableFailure - observed some intermediate
state, which is best handled by retrying later
"""
try:
active_version = self.try_create_rendezvous() # Launch a round of rendezvous
state = json.loads(active_version.value)
log.info("New rendezvous state created: " + str(state))
except etcd.EtcdAlreadyExist:
active_version, state = self.get_rdzv_state()
# Note: it is possible for above query to fail (etcd.EtcdKeyNotFound),
# but this is ok for us - just means we'll restart from beginning.
log.info("Observed existing rendezvous state: " + str(state))
if state["status"] == "closed":
raise RendezvousClosedError()
if state["status"] == "joinable":
return self.join_phase(state["version"])
if state["status"] == "final":
self.handle_existing_rendezvous(state["version"])
raise EtcdRendezvousRetryImmediately()
self.try_wait_for_state_change(etcd_index=active_version.etcd_index + 1)
raise EtcdRendezvousRetryableFailure()
4.5.2 DynamicRendezvousHandler
It is not obvious in the dynamic rendezvous handler. It should be because the dynamic rendezvous handler is developed after ETCD, so many functions are imperfect and evolving.
This series is mainly analyzed based on PyTorch 1.9, so next above_ There is no error handling in the rendezvous code, and it is directly thrown to the outside. Error handling has been added to the latest code from 2021 to December, and it should continue to be improved in the future.
def next_rendezvous(self) -> Tuple[Store, int, int]:
"""See base class."""
msg = (
f"The node '{self._this_node}' attempts to join the next round of the rendezvous "
f"'{self._settings.run_id}'."
)
self._record(message=msg)
try: # Error handling added
self._stop_heartbeats()
# Delay the execution for a small random amount of time if this is our
# first run. This will slightly skew the rendezvous attempts across the
# nodes and reduce the load on the backend.
if self._state_holder.state.round == 0:
_delay(seconds=(0, 0.3))
exit_op = _RendezvousExitOp()
join_op = _RendezvousJoinOp()
deadline = self._get_deadline(self._settings.timeout.join)
self._op_executor.run(exit_op, deadline)
self._op_executor.run(join_op, deadline)
self._start_heartbeats()
rank, world_size = self._get_world()
store = self._get_store()
except Exception as e: # Error handling was added, but the next round of rendezvous was not initiated
self._record(
message=f"{type(e).__name__}: {str(e)}",
node_state=NodeState.FAILED,
)
raise
msg = (
f"The node '{self._this_node}' has joined round {self._state_holder.state.round} of "
f"the rendezvous '{self._settings.run_id}' as rank {rank} in a world of size "
f"{world_size}."
)
self._record(message=msg, rank=rank)
return store, rank, world_size
4.6 summary
The logical relationship between Rendezvous and Agent is summarized as follows. Each startup script has such a mechanism. Several mechanisms for starting scripts are interconnected.
+-----------------------------+ +------------------------------------------------+
| LocalElasticAgent | | WorkerSpec |
| | | |
| +------------------------+ | | rdzv_handler = {DynamicRendezvousHandler} -------+
| |WorkerGroup | | | | |
| | spec +--------------> | entry = worker_fn | |
| | workers | | | | |
| | store | | | role = {str} 'trainer' | |
| | group_rank | | | | |
| | group_world_size | | +------------------------------------------------+ |
| | | | |
| +------------------------+ | |
| | |
| rdzv_run_id | |
| store | +-----------------------------------------+ |
| | |DynamicRendezvousHandler | |
+-----------------------------+ | | |
| | |
| _settings: RendezvousSettings | <--+
| |
| _store: Store |
| |
| _state_holder: _RendezvousStateHolder |
| |
| _op_executor: _RendezvousOpExecutor |
| |
+-----------------------------------------+
Or combine it with the previous static logic.
+------------------------+ +----------------------------------------------+ + +------------------------+ +---------------------------------------------+
| LocalElasticAgent | | WorkerSpec | | | LocalElasticAgent | | WorkerSpec |
| | | | | | | | |
| +--------------------+ | | rdzv_handler = {DynamicRendezvousHandler} ----+ | | +--------------------+ | | rdzv_handler = {DynamicRendezvousHandler}-----+
| | WorkerGroup | | | | | | | | WorkerGroup | | | | |
| | spec +----------->+ entry = worker_fn | | | | | spec +----------->+ entry = worker_fn | |
| | workers | | | | | | | | workers | | | | |
| | store | | | role = {str} 'trainer' | | | | | store | | | role = {str} 'trainer' | |
| | group_rank | | | | | | | | group_rank | | | | |
| | group_world_size | | +----------------------------------------------+ | | | | group_world_size | | +---------------------------------------------+ |
| | | | +--------------------------------------------+ | | | | | | +--------------------------------------------+ |
| +--------------------+ | | DynamicRendezvousHandler | | | | +--------------------+ | | DynamicRendezvousHandler | |
| rdzv_run_id | | | | | | rdzv_run_id | | | |
| store | | | | | | store | | | |
+------------------------+ | _settings: RendezvousSettings | | | +------------------------+ | _settings: RendezvousSettings | |
| | <--+ | | +<--+
| _store: Store | | | _store: Store |
| | | | |
+----------+ _state_holder: _RendezvousStateHolder | | | _state_holder: _RendezvousStateHolder +-----+
| | | | | | |
| | _op_executor: _RendezvousOpExecutor | | | _op_executor: _RendezvousOpExecutor | |
| | | | | | |
| +--------------------------------------------+ | +--------------------------------------------+ |
v | |
+---------+---------------------+ | +-------------------------------+ |
| _BackendRendezvousStateHolder | | | _BackendRendezvousStateHolder | |
| | +-------------------+ | +--------------------+ | | |
| _settings +-----------> | RendezvousSettings| | | RendezvousSettings | <----------+ _settings | <-------+
| | +-------------------+ | +--------------------+ | |
| | +-------------------+ | +--------------------+ | |
| _state +--------------> | _RendezvousState | | | _RendezvousState | <----------+ _state |
| | | | | | | | |
| | +-------------------+ | +--------------------+ | |
| | +-----------------------+ + +----------------------+ | |
| _backend +------------> | C10dRendezvousBackend | | C10dRendezvousBackend| <-------+ _backend |
| | | | +---------+ | | | |
| | | _store +-----> |TCPStore | <-------+ _store | | |
| | +---+-------------------+ +---+-----+ +-----------+----------+ | |
| | ^ | ^ | |
| | | | | | |
| | | | | | |
| sync +----------------------+ | +---------------------+ sync |
| | set_state NODE 1 | NODE 2 set_state | |
+-------------------------------+ + +-------------------------------+
Mobile phones are as follows:
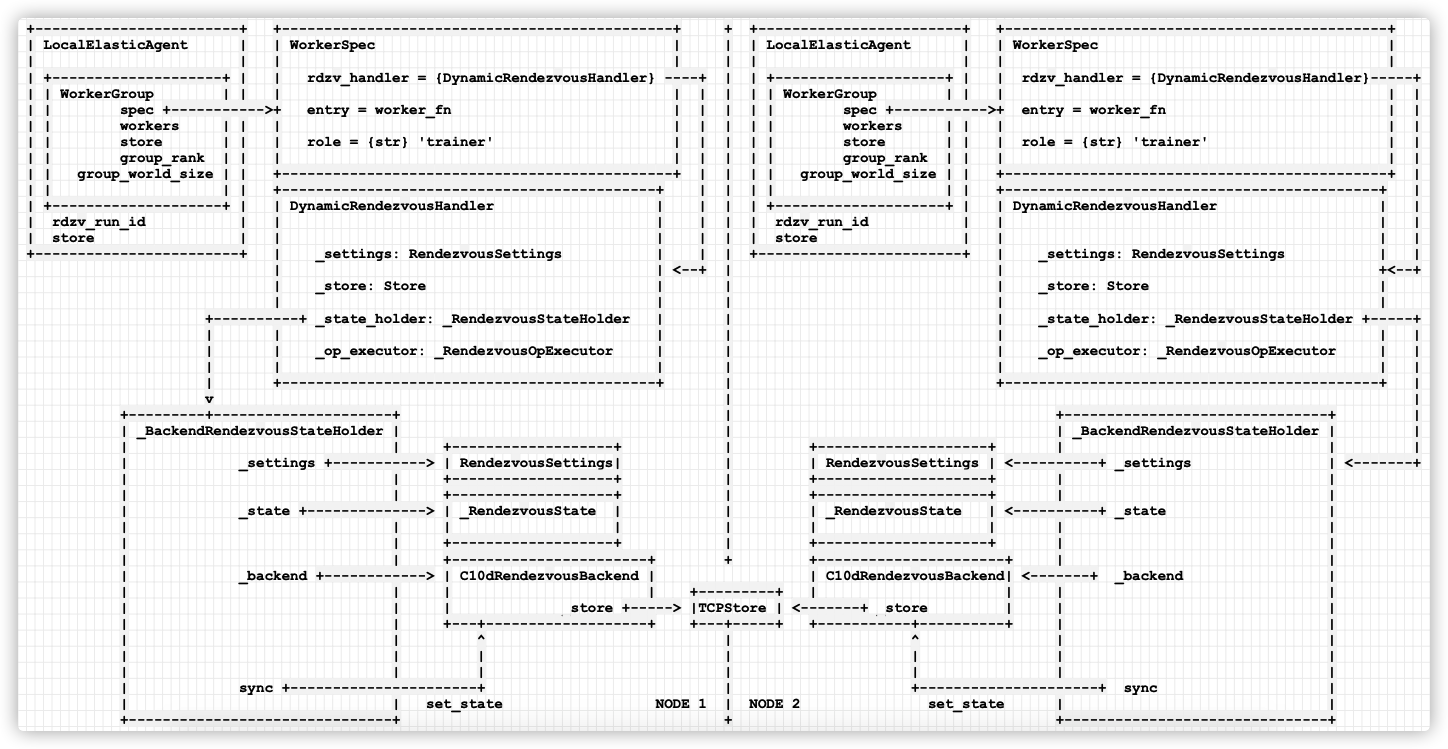
0x05 summary
At present, we have analyzed the static structure and dynamic logic of Rendezvous, and we have a basic understanding of its mechanism, such as the following concepts:
- Node concept_ NodeDesc, which can express the system.
- State concept_ Rendezvous state is the state of rendezvous. It is dynamic information. Each node maintains a local state.
- Overall static class_ BackendRendezvousStateHolder is used to uniformly maintain nodes, States, backend and other information.
- Shared key value storage, such as TCPStore, can store the above information in a centralized way, or exchange information with each other to reach a consensus.
- Dynamic server or handler, rendezvous handler provides a set of API s for external access.
In the next article, we introduce how to implement the internal business logic, that is, Rendezvous engine.
0xEE personal information
★★★★★★★ thinking about life and technology ★★★★★★
Wechat public account: Rossi's thinking
If you want to get the news push of personal articles in time, or want to see the technical materials recommended by yourself, please pay attention.
