I saw some students ask before. I hope to see some partial practice, especially the arrangement with source code! Today, I will take you to complete a small semantic retrieval system based on domain pre training and comparative learning SimCSE.
The so-called semantic retrieval (also known as vector based retrieval) means that the retrieval system is no longer confined to the user Query literal itself (such as BM25 retrieval), but can accurately capture the real intention behind the user Query and use it to search, so as to more accurately return the most consistent results to the user.
The final visual demo is as follows. On the one hand, you can obtain the vector representation of the text; On the other hand, you can do text retrieval, that is, you can get the top-K related documents entered into Query!
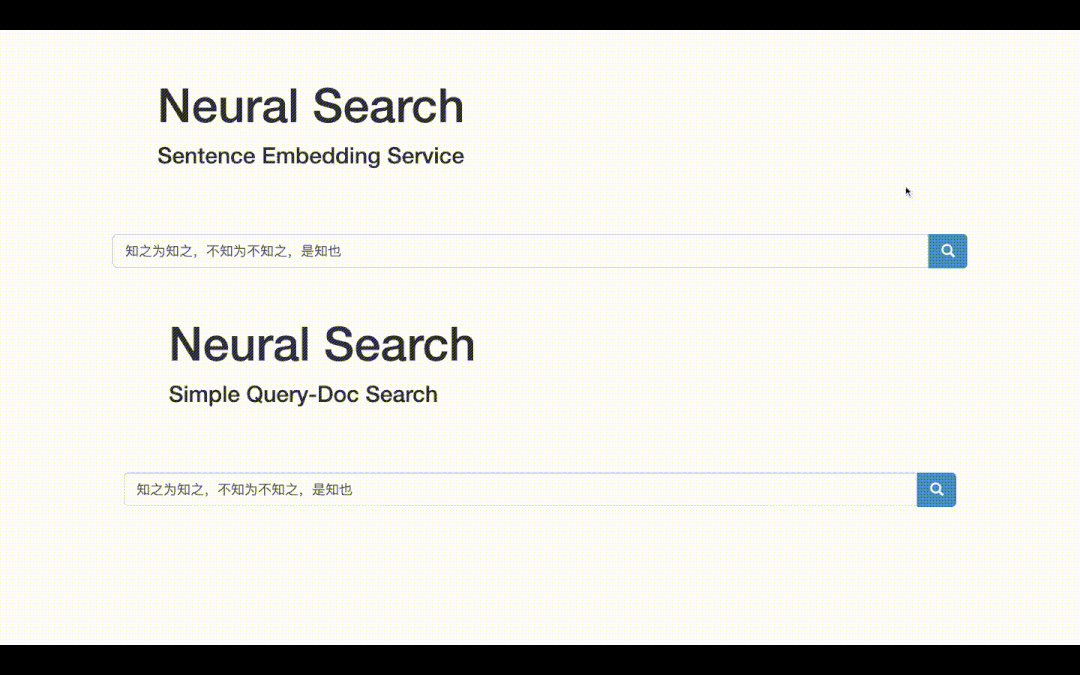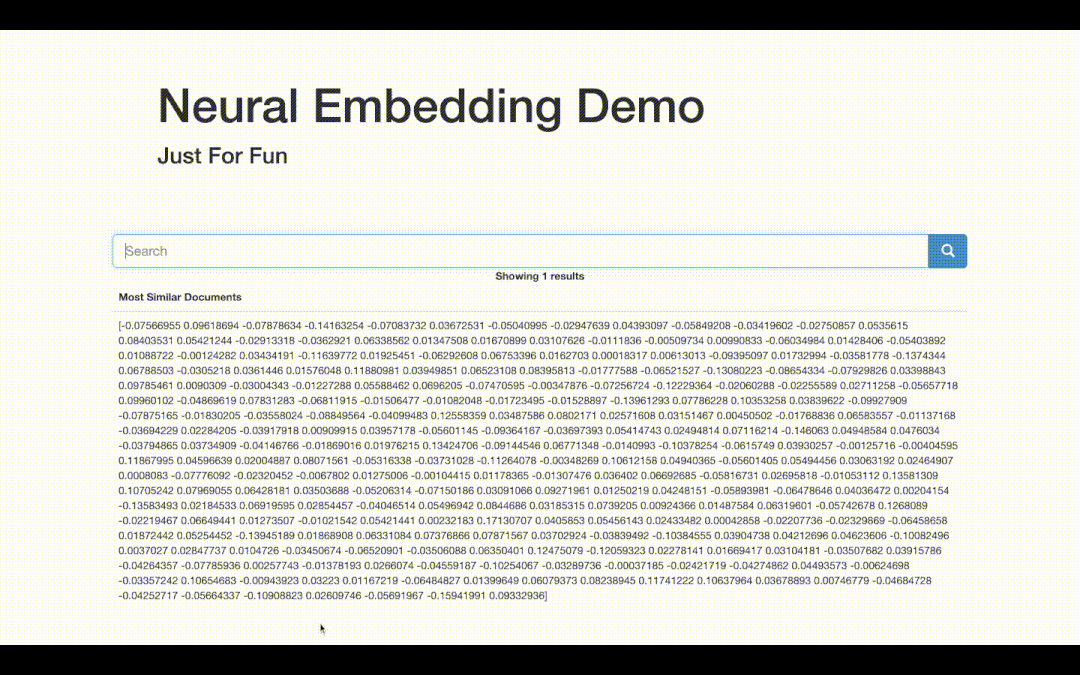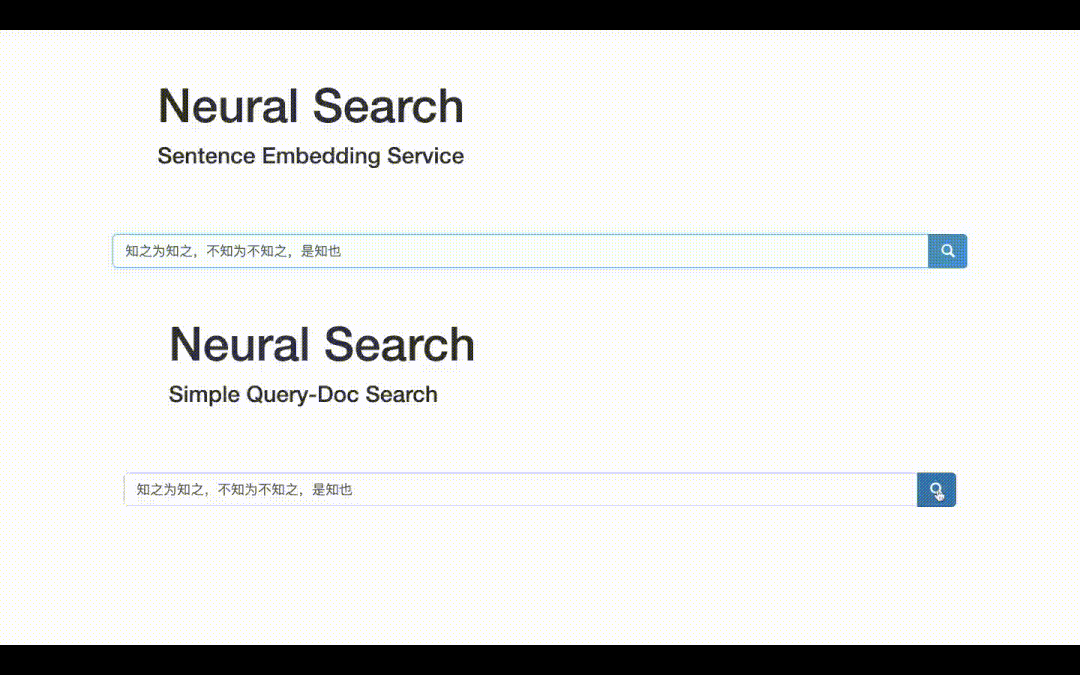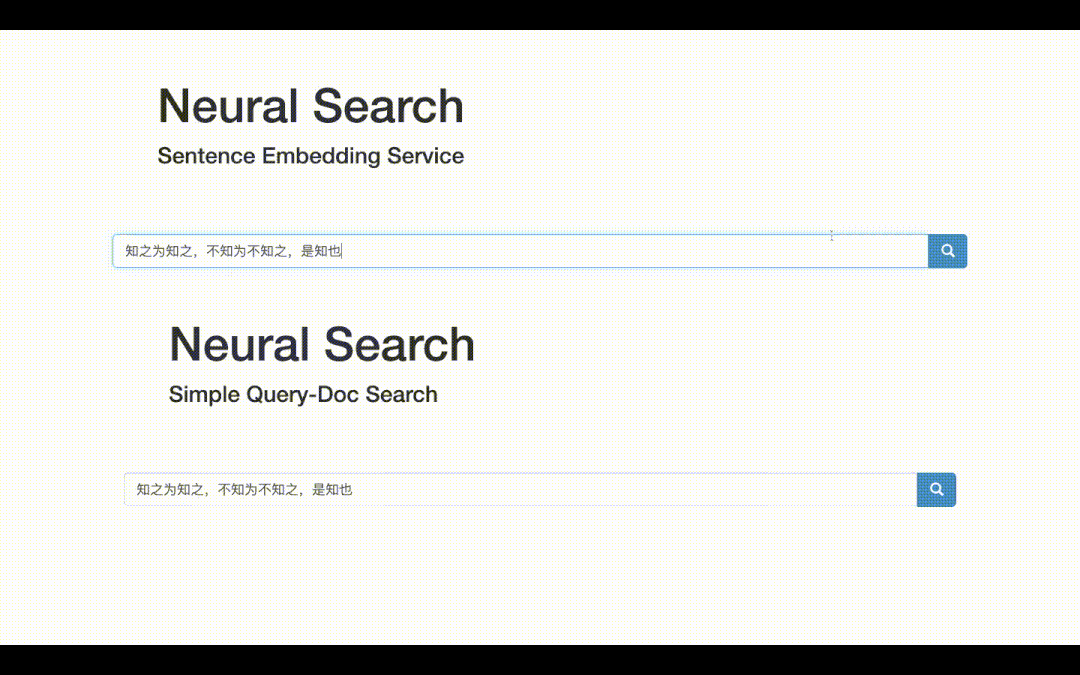
Semantic retrieval, whose underlying technology is semantic matching, is one of the most basic and common tasks of NLP. From the perspective of breadth, semantic matching can be applied to QA, search, recommendation, advertising and other major directions; From the perspective of technical depth, semantic matching needs to integrate various SOTA models, magic changes of two common frameworks, two towers and interaction, as well as the art of sample processing and various engineering tricks.
Interestingly, when I was looking for relevant information, I found that Baidu PaddlePaddle PaddleNLP has just opened up a similar function recently, and the light of domestic products can be seen. Paddlenlp has been used before, which basically covers various NLP applications and SOTA models. It is also very convenient to call. It is strongly recommended that you try!
Next, we take the search scenario as an example, that is, enter Query to return the Document collection, and build a semantic retrieval system step by step based on the wheel provided by paddelnlp. The overall framework is as follows. Due to the limitation of computation and resources, the general industrial search system will be designed into a multi-stage cascade structure, mainly including recall, sorting (Rough sorting, fine sorting, rearrangement) and other modules.
- step-1: offline construction of candidate corpus using pre training model
- step-2: recall module. For online Query, use Milvus to quickly retrieve the top1000 candidate set
- step-3: sorting module. For the recalled top1000, more refined sorting is performed to get the Top100 result and return it to the user.
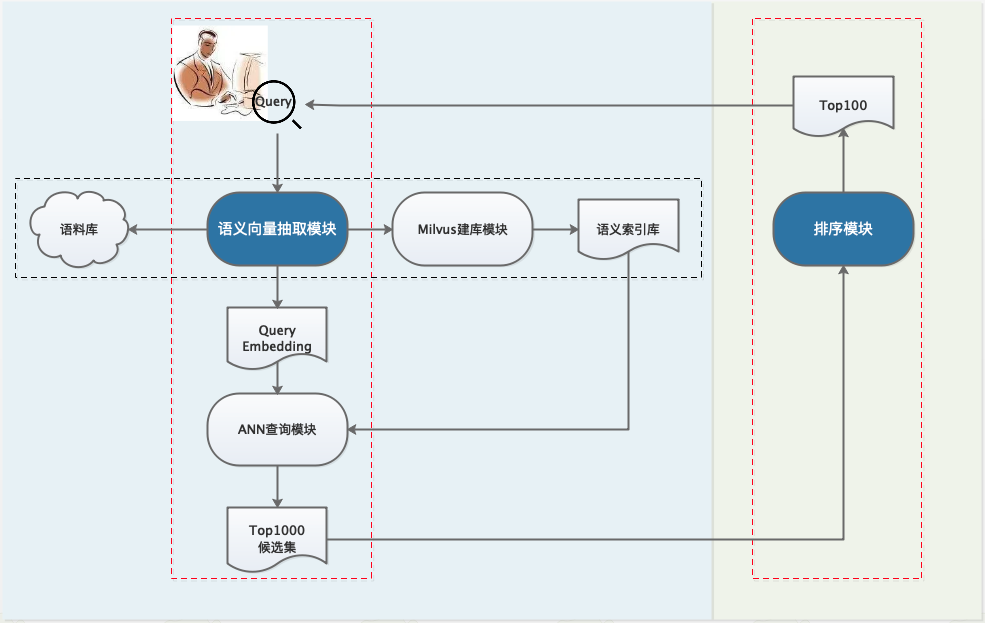
Semantic retrieval technology framework
1. Overall overview
1.1 data
The data comes from a literature retrieval system, which is divided into supervised (small amount) and unsupervised (large amount). Specific examples are introduced below
- Data download address: https://bj.bcebos.com/v1/paddlenlp/data/literature_search_data.zip
1.2 code
First, clone Code:
git clone git@github.com:PaddlePaddle/PaddleNLP.git cd applications/neural_search
The operating environment is
- python3
- paddlepaddle==2.2.1
- paddlenlp==2.2.1
For other dependent packages, refer to requirements txt
2. Offline database building
As can be seen from the above semantic retrieval technology framework diagram, firstly, we need a semantic model to extract vectors from the input Query/Doc text. Here, SimCSE based on comparative learning is selected. The core idea is to make sentences with similar semantics close to each other in the vector space and sentences with different semantics far away from each other. For a more specific introduction to SimCSE, read our previous article:
So, how can training make full use of the model to achieve higher accuracy? For the pre training model, the commonly used training paradigm has changed from the two-stage paradigm of "general pre training - > domain fine tuning" to the three-stage paradigm of "general pre training - > domain pre training - > domain fine tuning". See our previous for more information
Specifically, here, our model training is divided into several steps (the code and corresponding data are introduced in the next section):
- The general ERNIE 1.0 is further pre trained on the unsupervised domain data set to obtain the domain ERNIE
- Taking the domain ERNIE as the hot start, SimCSE is pre trained on the unsupervised literature data set
- On the supervised literature data set, combined with the in batch negative strategy, fine tune the step 2 model to obtain the final model, which is used to extract the text vector representation, that is, the semantic model we need, for database building and recall.
Because the recall module needs to quickly recall candidate sets from tens of millions of data, the general approach is to realize efficient ANN with the help of vector search engine, so as to realize candidate set recall. Milvus open source tools are used here. For the building tutorial of Milvus, please refer to the official tutorial
- https://milvus.io/cn/docs/v1.1.1/
Milvus is a domestic high-performance retrieval library, which is similar to Facebook's open source Faiss function. Unfamiliar students can read it first 100 million vector similarity retrieval library Faiss principle + application Understand.
The code for offline library building is located in PaddleNLP/applications/neural_search/recall/milvus
|- scripts
|- feature_extract.sh #bash script for extracting feature vectors
├── base_model.py # Semantic index model base class
├── config.py # milvus profile
├── data.py # Data processing function
├── embedding_insert.py # Insert vector
├── embedding_recall.py # Retrieve topK similar results / ANN
├── inference.py # Dynamic graph model vector extraction script
├── feature_extract.py # Batch extraction vector script
├── milvus_insert.py # Insert vector tool class
├── milvus_recall.py # Vector recall tool class
├── README.md
└── server_config.yml # The config file of milvus is the configuration used in this project
2.1 extraction vector
After building the vector engine according to the Milvus tutorial, you can extract text vectors using the pre training semantic model. Run feature_extract.py, and pay attention to modifying the data source path to build the database.
After running, 10 million text data will be generated and saved as corpus_embedding.npy.
2.2 insertion vector
Next, modify config Py, and import the vector generated in the previous step into the Milvus library.
embeddings=np.load('corpus_embedding.npy')
embedding_ids = [i for i in range(embeddings.shape[0])]
client = VecToMilvus()
collection_name = 'literature_search'
partition_tag = 'partition_2'
data_size=len(embedding_ids)
batch_size=100000
for i in tqdm(range(0,data_size,batch_size)):
cur_end=i+batch_size
if(cur_end>data_size):
cur_end=data_size
batch_emb=embeddings[np.arange(i,cur_end)]
status, ids = client.insert(collection_name=collection_name, vectors=batch_emb.tolist(), ids=embedding_ids[i:i+batch_size],partition_tag=partition_tag)
Extracting and inserting vectors may take a long time if the machine resources are not very "rich". It is suggested that a small part of data can be used to test functions, quickly perceive, and then operate the whole database in the real deployment stage.
After the insertion, we can view the vector data through the visualization tool [1] provided by Milvus, which is the ID and vector corresponding to the document.
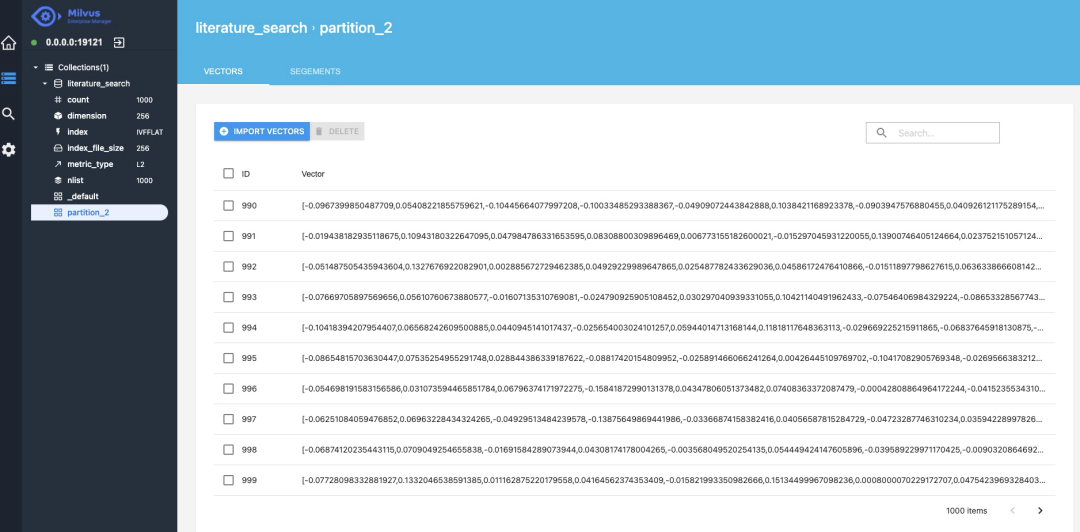
3. Document recall
The purpose of the recall phase is to quickly retrieve the relevant Doc documents that meet the Query requirements from the massive resource database. Due to the amount of computation and the requirements for online delay, the general recall model will be designed in the form of two towers. The Doc tower will build a database offline, and the Query tower will process online requests in real time.
The recall model adopts domain adaptive training + simcse + in batch negatives.
In addition, if you just want to test or deploy quickly, it is found that paddelnlp has also opened the trained model file, which can be downloaded immediately. The model link is directly posted here:
- Domain pre training ERNIE: https://bj.bcebos.com/v1/paddlenlp/models/ernie_pretrain.zip
- Unsupervised SimCSE: https://bj.bcebos.com/v1/paddlenlp/models/simcse_model.zip
- Supervised in batch negatives: https://bj.bcebos.com/v1/paddlenlp/models/inbatch_model.zip
3.1 field pre training
The advantages of domain adaptive training have been described in detail in the previous article and will not be repeated. Directly to the code, and the specific functions are marked later.
domain_adaptive_pretraining/
|- scripts
|- run_pretrain_static.sh # Static graph and bash script for training
├── ernie_static_to_dynamic.py # Static graph to dynamic graph
├── run_pretrain_static.py # ernie1.0 static graph pre training
├── args.py # Parameter profile for pre training
└── data_tools # Pre training data processing file directory3.2 SimCSE unsupervised pre training
The double tower model adopts ERNIE 1.0 hot start and introduces SimCSE strategy. Examples of training data are as follows

The code structure is as follows. The functions of each file are clearly noted later.
simcse/
├── model.py # SimCSE model networking code
|- deploy
|- python
|- predict.py # PaddleInference
├── deploy.sh # bash script for Paddle Inference
|- scripts
├── export_model.sh # bash script for converting dynamic graph to static graph
├── predict.sh # Predicted bash script
├── evaluate.sh # Recall evaluation bash script
├── run_build_index.sh # Build script for index
├── train.sh # bash script for training
|- ann_util.py # Ann build index library related functions
├── data.py # Reading logic of unsupervised semantic matching training data and test data
├── export_model.py # Dynamic graph to static graph
├── predict.py # Calculating text Pair similarity based on trained unsupervised semantic matching model
├── evaluate.py # Calculate the evaluation index according to the recall results and evaluation set
|- inference.py # Dynamic Graph Extraction vector
|- recall.py # Based on the trained semantic index model, the similar text of a given text is recalled from the recall database
└── train.py # SimCSE model training and evaluation logic
For training, evaluation and prediction, run the corresponding scripts in the scripts directory respectively. The trained model can be used to extract the semantic vector representation of text on the one hand, and calculate the semantic similarity of text pairs on the other hand. We only need to adjust the data input format.
3.3 supervised fine adjustment
Fine tune the supervised data of the model in the previous step. The training data example is as follows. Each line is composed of a pair of text pairs with similar semantics. tab segmentation, and negative samples are derived from the introduction of in batch negatives sampling strategy.

For details on in batch negatives, please refer to the previous article:
The overall code structure is as follows
|- data.py # Preprocessing logic such as data reading and data conversion
|- base_model.py # Semantic index model base class
|- train_batch_neg.py # Main training script for in batch negatives policy
|- batch_negative
|- model.py # In batch negatives policy core network structure
|- ann_util.py # Ann build index library related functions
|- recall.py # Based on the trained semantic index model, the similar text of a given text is recalled from the recall database
|- evaluate.py # Calculate the evaluation index according to the recall results and evaluation set
|- predict.py # Given the input file, calculate the similarity of text pair
|- export_model.py # Convert dynamic graph to static graph
|- scripts
|- export_model.sh # Script for converting dynamic graph to static graph
|- predict.sh # Forecast bash version
|- evaluate.sh # Evaluate bash version
|- run_build_index.sh # Build index bash version
|- train_batch_neg.sh # Training bash version
|- deploy
|- python
|- predict.py # PaddleInference
|- deploy.sh # Paddy inference deployment script
|- inference.py # Dynamic Graph Extraction vector
The steps of training, evaluation and prediction are similar to the unsupervised steps in the previous step. You must understand it at a glance!
3.4 semantic model effect
Having said so much, let's see how the effects of several models are? For the matching or retrieval model, the commonly used evaluation index is Recall@K , that is, the ratio of the number of correct results retrieved from the TOP-K results to the number of all correct results in the whole database.
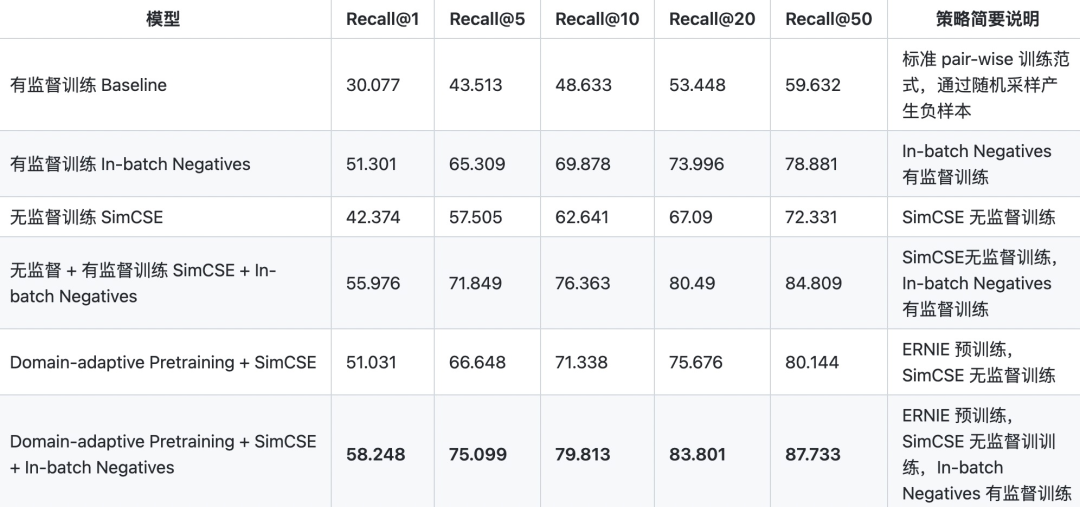
Through comparison, it can be found that the best performance can be obtained by first using ERNIE 1.0 for domain adaptive training, then loading the trained model into SimCSE for unsupervised training, and finally using in batch negatives for training on supervised data.
3.5 vector recall
Finally, it's time to recall. In retrospect, we have trained the semantic model and built the recall library. Next, we just need to search in the library. The code is located in PaddleNLP/applications/neural_search/recall/milvus/inference.py
def search_in_milvus(text_embedding):
collection_name = 'literature_search' # Milvus library built before
partition_tag = 'partition_2'
client = RecallByMilvus()
status, results = client.search(collection_name=collection_name, vectors=text_embedding.tolist(),
partition_tag=partition_tag)
corpus_file = "../../data/milvus/milvus_data.csv"
id2corpus = gen_id2corpus(corpus_file)
for line in results:
for item in line:
idx = item.id
distance = item.distance
text = id2corpus[idx]
print(idx, text, distance)
Taking the impact of importing non-state-owned capital into state-owned enterprises on Innovation Performance -- Based on the empirical evidence of state-owned listed companies in manufacturing industry as an example, the retrieval return effect is as follows

The last column of the returned result is the similarity. Milvus uses the European distance by default. If you want to change it to cosine similarity, you can modify it in Milvus's configuration file.
4. Document sorting
Unlike recall, in the sorting stage, because the scoring set oriented is relatively small, generally only a few thousand levels, more complex models can be used. Ernie gram pre training model is used here, and margin is used for loss_ ranking_ loss.
Examples of training data are as follows: three columns, namely (query, title, neg_title) and tab segmentation. For real search scenarios, training data usually comes from click logs on business lines to construct positive samples and strong negative samples.

The code structure is as follows
ernie_matching/
├── deply # deploy
└── python
├── deploy.sh # Predictive deployment bash script
└── predict.py # python predictive deployment example
|- scripts
├── export_model.sh # bash file for exporting static graph parameters from dynamic graph parameters
├── train_pairwise.sh # bash file of pair wise single tower matching model training
├── evaluate.sh # Evaluation validation file bash script
├── predict_pairwise.sh # bash file of pair wise single tower matching model prediction script
├── export_model.py # Dynamic graph parameter export static graph parameter script
├── model.py # Pair wise matching model
├── data.py # The transformation logic of pair wise training samples and the logic of pair wise generating random negative examples
├── train_pairwise.py # Pair wise single tower matching model training script
├── evaluate.py # Evaluation verification document
├── predict_pairwise.py # Pair wise single tower matching model prediction script, and the output text pair is similarity
Training run sh scripts/train_pairwise.sh is enough.
Similarly, PaddleNLP also open source the sorting model, https://bj.bcebos.com/v1/paddlenlp/models/ernie_gram_sort.zip
For prediction, the prepared data is a text pair for each line, and the final prediction returns the semantic similarity of the text pair.
{'query': 'Differences between Chinese and Western languages and cultures', 'title': 'A major obstacle to second language acquisition is cultural differences.', 'pred_prob': 0.85112214}
{'query': 'Differences between Chinese and Western languages and cultures', 'title': 'On the external communication path of Chinese culture from the perspective of cross culture,Chinese culture,spread,translate', 'pred_prob': 0.78629625}
{'query': 'Differences between Chinese and Western languages and cultures', 'title': 'On English Chinese translation from the perspective of the differences between Chinese and Western National Cultural Psychology,Culture,National Cultural Psychology,Mode of thinking,translate', 'pred_prob': 0.91767526}
{'query': 'Differences between Chinese and Western languages and cultures', 'title': 'The influence of Chinese and English cultural differences on Translation,difference,Influence of translation', 'pred_prob': 0.8601749}
{'query': 'Differences between Chinese and Western languages and cultures', 'title': 'On culture and language acquisition,language,The relationship between culture and language,Culture and language acquisition awareness,cross-cultural communication', 'pred_prob': 0.8944413}
5. Summary
In this paper, we quickly built a semantic retrieval system based on the Neural Search function provided by paddelnlp. Compared with starting from scratch, PaddleNLP provides a set of wheels very well. If you directly download the PaddleNLP open source trained model file, you can call the ready-made script for the semantic similarity task in a few minutes; For the semantic retrieval task, the full amount of data needs to be imported into Milvus to build the index. In addition to the training and database building time, the whole process is expected to be completed in 30-50 minutes.
During the interval of training, I also studied and found that the documents on Github are also very clear and detailed. For the entry-level students of Xiaobai, they have achieved one key operation, so as not to be trapped by complicated process steps and gradually lose interest; For students who want to study deeply, PaddleNLP also has open source code, which can be further studied. fabulous!
In addition, we can also carry out our own additional development based on these functions, such as the moving graph at the beginning to build a more intuitive semantic vector generation and retrieval service. Have Fun!
I also encountered some problems in running the code. Thank you very much for your patience. And I learned that they seem to hold a class on this project recently. It's free. Oh, it's so sweet! In order to thank you for your enthusiastic answers, here to help publicize their open class. Interested students are welcome to listen!
From December 28 to December 30, baidu engineers will bring live explanation. In addition to the semantic retrieval system, they will also bring the system scheme of Q & A and emotion analysis scene, as well as the sharing of landing experience. You can scan the code to enter the course group for details
Finally, the code of this practice project is attached: https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/neural_search
References for this article
[1] Visualization tools: https://zilliz.com/products/em