Hello, I'm Xiao Huang, a Java development engineer in Unicorn enterprise. Thank you for meeting us in the vast sea of people. As the saying goes: when your talent and ability are not enough to support your dream, please calm down and learn. I hope you can learn and work together with me to realize your dream.

1, Introduction
For Java developers, we generally use the underlying knowledge as a black box without opening it.
However, with the development of the programmer industry, it is necessary to open this black box to explore the mystery.
This series of articles will take you to explore the mystery of the underlying black box.
Before reading this article, it is recommended to download openJDK for better results
openJDK download address: openJDK
If you feel slower, suggest paying attention to the official account: love knocking the code of Xiao Huang, sending: openJDK can get Baidu SkyDrive link.
Can you give me some attention~
2, Operating system
1. Out of order execution of CPU
The CPU executes instructions while reading and waiting, which is the root of CPU disorder. Instead of disorder, it improves efficiency
Let's look at the following program:
x = 0;
y = 0;
a = 0;
b = 0;
Thread one = new Thread(new Runnable() {
public void run() {
//Since thread one starts first, let it wait for thread two The waiting time can be adjusted according to the actual performance of your computer
//shortWait(100000);
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();
other.start();
one.join();
other.join();
String result = "The first" + i + "second (" + x + "," + y + ")";
if (x == 0 && y == 0) {
System.err.println(result);
break;
}
We can see that if our CPU does not execute out of order, then a = 1 must be in front of x = b, and b = 1 must be in front of y = a
What conclusion can we draw, that is, x and y must not be 0 at the same time (here readers can think about why they can't be 0 at the same time)
We run the following program and get the following results:

We got the result when running 2728842 times, which verified our conclusion.
2.1 possible problems caused by disorder
Common example: why should volatile be added to DCL?
Let's take the following example:
class T{
int m = 8;
}
T t = new T();
Decompile foreign exchange code:
0 new #2 <T> 3 dup 4 invokespeecial # 3 <T.<init>> 7 astore_1 8 return
We analyze the assembly code step by step:
- New #2 < T >: create an object with m = 0, and there is a reference to the object in the stack frame
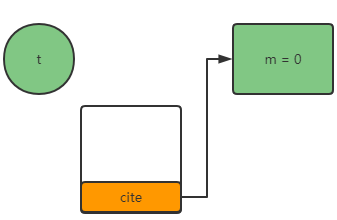
- dup: copy a reference in our stack frame
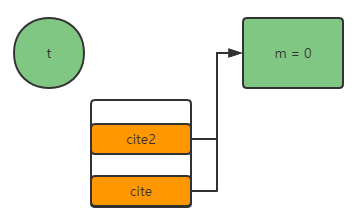
- Invokespecial #3 < T. < init > >: pop up a value in the stack frame and instantiate its construction method
- astore_1: Assign the reference of our stack frame to t, where 1 refers to the first bit in our local variable table
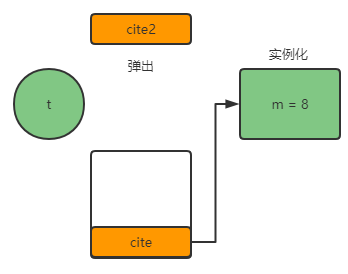
So, let's think about one thing. We have proved that the CPU is out of order, so what harm will it do to our above operations?
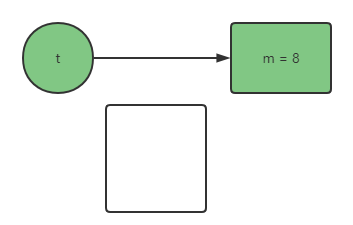
When our astore_1. Before our invokespecial # 3 < T. < init > > is executed, it will cause us to assign t to the object we have not instantiated, as shown below:
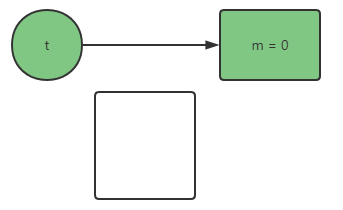
Therefore, in order to avoid this phenomenon, we should add volatile to DCL
The question is, how do we ensure the order of volatile?
2.2 how to prohibit instruction reordering
We discuss the prohibition of instruction reordering from the following three aspects:
- Code level
- Bytecode level
- JVM level
- CPU level
2.2.1 Java code level
- Add a volatile keyword directly
public class TestVolatile {
public static volatile int counter = 1;
public static void main(String[] args) {
counter = 2;
System.out.println(counter);
}
}
2.2. 1 byte code level
At the bytecode level, after decompiling volatile, we can see VCC_volatile
We decompile the above code to get its bytecode
Through javac testvolatile Java compiles the class into a class file, and then passes javap - V testvolatile Class Command decompile view bytecode file
Here we only show the bytecode of this Code: public static volatile int counter = 1;
public static volatile int counter;
descriptor: I
flags: ACC_PUBLIC, ACC_STATIC, ACC_VOLATILE
// The following is the bytecode when initializing the counter
0: iconst_2
1: putstatic #2 // Field counter:I
4: getstatic #3 // Field
- descriptor: represents method parameters and return values
- flags: ACC_PUBLIC, ACC_STATIC, ACC_VOLATILE: Flag
- putstatic: operate on static attributes
Our subsequent operations can be through ACC_VOLATILE this flag to know that the variable has been modified by volatile
2.2. 3. Hotspot source code level
How does our JVM implement variables decorated with volatile?
We usually see these four words on my website: StoreStore, StoreLoad, LoadStore, LoadLoad

Our JVM is implemented in this way. Let's take a look at the specific implementation.
In Java, static attributes belong to classes. The static attribute is operated, and the corresponding instruction is putstatic
We use the bytecodeinterpreter. Under the root path jdk\src\hotspot\share\interpreter\zero of openjdk8 Code for processing putstatic instruction in cpp file:
CASE(_putstatic):
{
// .... Omit several lines
// Now store the result
// ConstantPoolCacheEntry* cache; -- cache is a constant pool cache instance
// cache->is_ Volatile () -- determines whether there is a volatile access flag modifier
int field_offset = cache->f2_as_index();
// ****Key judgment logic****
if (cache->is_volatile()) {
// Assignment logic of volatile variable
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {// Object type assignment
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
OrderAccess::release_store(&BYTE_MAP_BASE[(uintptr_t)obj >> CardTableModRefBS::card_shift], 0);
} else if (tos_type == btos) {// byte type assignment
obj->release_byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ltos) {// long type assignment
obj->release_long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {// char type assignment
obj->release_char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {// short type assignment
obj->release_short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {// float type assignment
obj->release_float_field_put(field_offset, STACK_FLOAT(-1));
} else {// double type assignment
obj->release_double_field_put(field_offset, STACK_DOUBLE(-1));
}
// ***storeload barrier after writing value***
OrderAccess::storeload();
} else {
// Assignment logic of non volatile variables
}
}
Paste cache - > is here_ Source code of volatile(), path: JDK \ SRC \ hotspot \ share \ utilities \ accessflags hpp
// Java access flags
bool is_public () const { return (_flags & JVM_ACC_PUBLIC ) != 0; }
bool is_private () const { return (_flags & JVM_ACC_PRIVATE ) != 0; }
bool is_protected () const { return (_flags & JVM_ACC_PROTECTED ) != 0; }
bool is_static () const { return (_flags & JVM_ACC_STATIC ) != 0; }
bool is_final () const { return (_flags & JVM_ACC_FINAL ) != 0; }
bool is_synchronized() const { return (_flags & JVM_ACC_SYNCHRONIZED) != 0; }
bool is_super () const { return (_flags & JVM_ACC_SUPER ) != 0; }
bool is_volatile () const { return (_flags & JVM_ACC_VOLATILE ) != 0; }
bool is_transient () const { return (_flags & JVM_ACC_TRANSIENT ) != 0; }
bool is_native () const { return (_flags & JVM_ACC_NATIVE ) != 0; }
bool is_interface () const { return (_flags & JVM_ACC_INTERFACE ) != 0; }
bool is_abstract () const { return (_flags & JVM_ACC_ABSTRACT ) != 0; }
Let's take a look at the assignment obj - > release_ long_ field_ Source code of put (field_offset, stack_long (- 1)): JDK \ SRC \ hotspot \ share \ OOP \ OOP inline. hpp
jlong oopDesc::long_field_acquire(int offset) const { return Atomic::load_acquire(field_addr<jlong>(offset)); }
void oopDesc::release_long_field_put(int offset, jlong value) { Atomic::release_store(field_addr<jlong>(offset), value); }
Let's go to JDK \ SRC \ hotspot \ share \ runtime \ atomic HPP take a look at Atomic::release_store method
inline T Atomic::load_acquire(const volatile T* p) {
return LoadImpl<T, PlatformOrderedLoad<sizeof(T), X_ACQUIRE> >()(p);
}
template <typename D, typename T>
inline void Atomic::release_store(volatile D* p, T v) {
StoreImpl<D, T, PlatformOrderedStore<sizeof(D), RELEASE_X> >()(p, v);
}
We can clearly see that const volatile T* p and volatile D* p directly use the volatile keyword of C/C + + when calling
Let's continue to look. After we finish assigning parameters, we will have this operation: OrderAccess::storeload();
Let's look at orderaccess.jdk\src\hotspot\share\runtime HPP file, found such a piece of code
// barriers static void loadload(); static void storestore(); static void loadstore(); static void storeload(); static void acquire(); static void release(); static void fence();
We can clearly see that this is the read-write barrier of the JVM we see on major websites
Of course, we have to look at its application in linux_x86 implementation mode, in JDK \ SRC \ hotspot \ OS_ cpu\linux_ Orderaccess for x86_ linux_x86. Under HPP
// A compiler barrier, forcing the C++ compiler to invalidate all memory assumptions
static inline void compiler_barrier() {
__asm__ volatile ("" : : : "memory");
}
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() { compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() { compiler_barrier(); }
inline void OrderAccess::release() { compiler_barrier(); }
2.2.4 CPU level
- Intel primitive instructions: mfence memory barrier, ifence read barrier, sfence write barrier
We can see that the key is this line of code:__ asm__ volatile ("" : : : "memory");
- __ asm__ : Used to instruct the compiler to insert assembly statements here
- volatile: tell the compiler that it is strictly forbidden to recombine and optimize the assembly statements here with other statements. That is: the compilation here is processed as it is.
- ("":: "memory"): memory forces the gcc compiler to assume that all RAM memory units are modified by the assembly instruction, so that the data in registers in cpu and cached memory units in cache will be invalidated. The cpu will have to re read the data in memory when needed. This prevents the cpu from using the data in registers and cache to optimize instructions and avoid accessing memory.
Simple summary: tell our CPU not to optimize it for me blindly, and I will execute it serially.
In this way, we can see that these instructions maintain order by changing the CPU registers and cache
The basic interview is almost here. We can beat 80% of the interviewers and interviewers, but our article is not enough!
When we observe these methods, we will find a method called fence(). Let's observe this method:
inline void OrderAccess::fence() {
// always use locked addl since mfence is sometimes expensive
//
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
compiler_barrier();
}
We can see that our method does not recommend that we use our primitive instruction mfence (memory barrier), because mfence consumes more resources than locked
Directly determine whether AMD64 processes its different registers rsp\esp
"lock; addl "Lock; ADDL $0,0 (%% rsp)",0(%%rsp)": adding a 0 to the rsp register is a Full Barrier. During execution, the memory subsystem will be locked to ensure the execution order, even across multiple CPU s
Here, our volatile is almost the same. We should be able to beat 90% of the interviewers
2.3 hamppens before principle
In short, the JVM specifies the rules that reordering must follow (just know)
- Program Order Rule
- Tube side locking rules
- volatile
- Thread start rule
- Thread termination rule
- Thread interrupt rule
- Object termination rule
- Transitivity
2.4 as if serial
No matter how reordered, the result of single thread execution will not change
3, Summary
This article has been written for about a week. The most difficult thing is that I can't find a process from shallow to deep, so I don't know how to write it
Finally, it was successfully completed, which further improved my understanding of volatile
At least after reading this article, I'm not afraid of any interviewer on volatile questions
The next step is to talk about merge writing, process, thread, fiber or algorithm
I am a Java development engineer of Unicorn enterprise. I hope you can pay attention to the smart, lovely and kind-hearted. If you have any questions, you can leave a message or private letter. See you next time!
