It mainly explains crawler related knowledge, such as http, web pages, crawler law, etc., so that everyone has a relatively perfect understanding of crawlers and some off topic knowledge points.
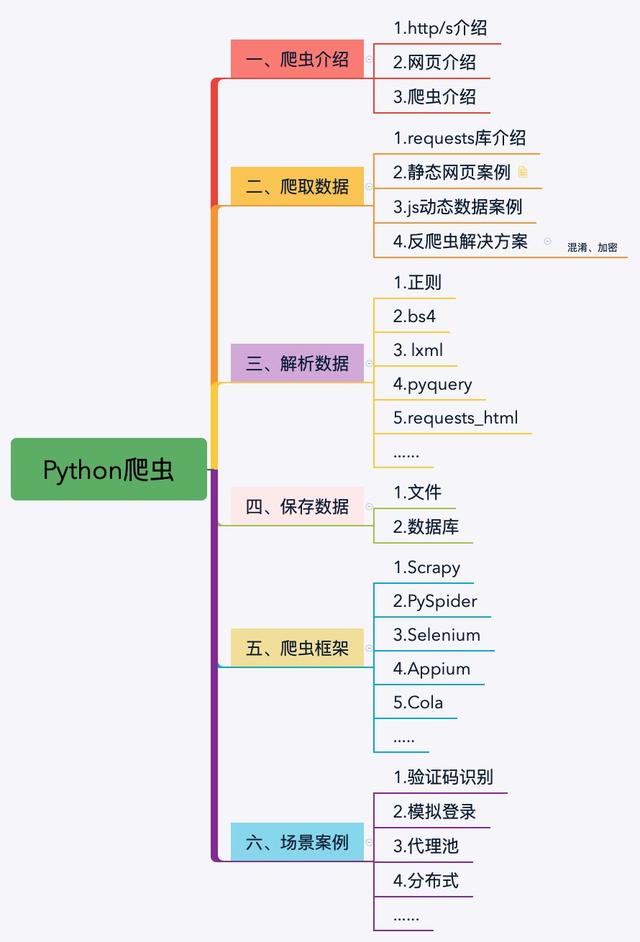
In today's article, we will officially enter the practical stage from today. There will be more practical cases later.
After explaining the principle of HTTP, many people are curious: what is the relationship between crawlers and HTTP? In fact, what we often call a crawler (also known as a web crawler) is a network request initiated by using some network protocols, and the most used network protocol is the HTTP/S network protocol cluster.
1, What network libraries does Python have
In real web browsing, we click the web page with the mouse, and then the browser helps us initiate a network request. How do we initiate a network request in Python? Of course, the answer is the library. Which library? Brother pig, give us a list:
- Python2: httplib,httplib2,urllib,urllib2,urllib3,requests
- Python3: httplib2,urllib,urllib3,requests
Python has a lot of network request libraries, and I've seen them used on the Internet. What's the relationship between them? How to choose?
- httplib/2: This is a Python built-in http library, but it is partial to the underlying library and is generally not used directly. httplib2 is a third-party library based on httplib, which is more complete than httplib, and supports functions such as caching and compression. Generally, these two libraries are not used. If you need to encapsulate the network request yourself, you may need to use them.
- Urllib / urllib 2 / urllib 3: urllib is an upper level library based on httplib, and urllib 2 and urllib 3 are third-party libraries. Urllib 2 adds some advanced functions to urllib, such as HTTP authentication or cookies. Urllib 2 is incorporated into urllib in Python 3. Urllib 3 provides thread safe connection pool and file post support, which has little to do with urllib and urllib 2.
- Requests: requests library is a third-party network library based on urllib/3. It is characterized by powerful functions and elegant API. As can be seen from the above figure, the requests library is also recommended in the official python documents for http clients. In practice, the requests library is also used more often. Finally, if your time is not very tight and you want to improve python quickly, the most important thing is not afraid of hardship. I suggest you can fight ♥ Xin (homonym): 2763177065, that's really good. Many people have made rapid progress. You need to be not afraid of hardship! You can add it and have a look~
To sum up, we choose the requests library as the starting point for our introduction to crawlers. In addition, the above libraries are synchronous network libraries. If you need high concurrent requests, you can use the asynchronous network library: aiohttp. Brother pig will also explain this later.
2, requests introduction
**I hope you will always remember: when learning any language, don't forget to look at the official documents** Perhaps the official document is not the best introductory tutorial, but it is definitely the latest and most complete teaching document!
1. Home page
Official document of requests (currently supports Chinese)

From the words "let HTTP serve human beings" in the home page, we can see that the core purpose of requests is to make users easy to use and indirectly express their concept of elegant design.

Note: PEP 20 is the famous Zen of Python.
Warning: non professional use of other HTTP libraries can lead to dangerous side effects, including security defects, redundant code, reinvention of the wheel, document gnawing, depression, headache and even death.
2. Functional characteristics
It is said that requests are powerful. Let's take a look at the features of requests:
- Keep alive & connection pool
- Internationalized domain names and URL s
- Session with persistent Cookie
- Browser based SSL authentication
- Automatic content decoding
- Basic / digest authentication
- Elegant key/value Cookie
- Automatic decompression
- Unicode response body
- HTTP(S) proxy support
- File block upload
- Stream Download
- connection timed out
- Block request
- support. netrc
Requests fully meet the needs of today's web. Requests supports Python 2.6-2.7 and 3.3-3.7, and can run perfectly under PyPy
3, Install requests
pip install requests
If pip3, use
pip3 install requests
If you use anaconda, you can
conda install requests
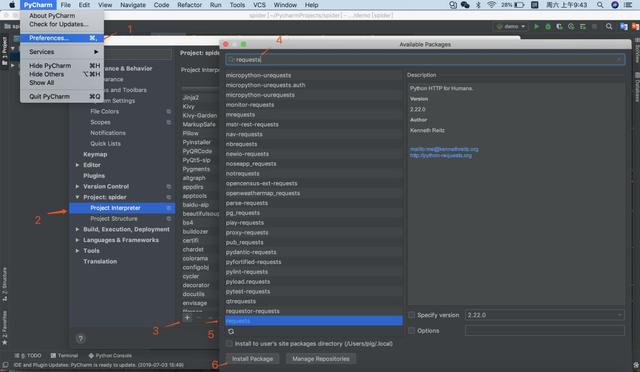
If you don't want to use the command line, you can download the library in pycharm
4, Crawler process
The following figure is a project development process summarized by brother Zhu's previous work, which is relatively detailed. It really needs to be so detailed when developing a large project, otherwise the project cannot be redone when the project goes online fails or needs to be modified. At that time, the programmer may sacrifice the day...
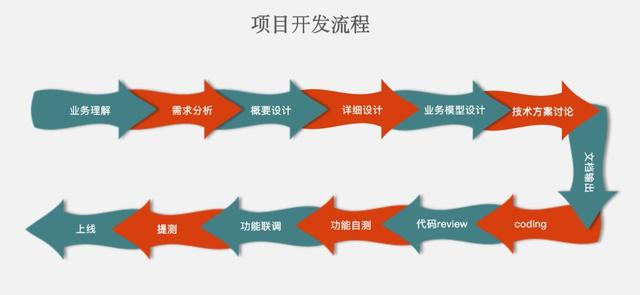
To get back to business, let's show you the development process of the project to lead to the process of crawler crawling data:
- Determine the page to crawl
- Browser check data source (static web page or dynamic load)
- Find the parameter rule of loading data url (such as paging)
- Code simulation request crawling data
Founded in May 2002, starting point Chinese network is one of the largest literature reading and writing platforms in China. It is a leading original literature portal in China and is subordinate to reading group, the largest comprehensive digital content platform in China. Finally, if your time is not very tight and you want to improve python quickly, the most important thing is not afraid of hardship. I suggest you can fight ♥ Xin (homonym): 2763177065, that's really good. Many people have made rapid progress. You need to be not afraid of hardship! You can add it and have a look~
The general idea is divided into three steps:
1. Analyze the web page structure, use xpath expression to crawl to all article names and links, and generate folders according to article names.
import requestsfrom urllib import requestfrom lxml import etreeimport osheader = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}class Spider(object):
def start_request(self):
url = 'https://www.qidian.com/all'
req = request.Request(url,headers=header)
html= request.urlopen(req).read().decode('utf-8')
html=etree.HTML(html)
bigtit_list=html.xpath('//div[@class="book-mid-info"]/h4/a/text()')
##Crawl all the article names
bigsrc_list = html.xpath('//div[@class="book-mid-info"]/h4/a/@href')
print(bigtit_list)
print(bigsrc_list)
for bigtit,bigsrc in zip(bigtit_list,bigsrc_list):
if os.path.exists(bigtit)==False:
os.mkdir(bigtit)
self.file_data(bigsrc,bigtit)
2. Use the article link to crawl the name and link of each chapter
def file_data(self,bigsrc,bigtit):
#Detail page
url="http:"+bigsrc
req = request.Request(url, headers=header)
html = request.urlopen(req).read().decode('utf-8')
html = etree.HTML(html)
print(html)
Lit_tit_list = html.xpath('//ul[@class="cf"]/li/a/text()')
#Climb the name of each chapter
Lit_href_list = html.xpath('//ul[@class="cf"]/li/a/@href')
#Link to each chapter
for tit,src in zip(Lit_tit_list,Lit_href_list):
self.finally_file(tit,src,bigtit)
3. Use the link of each chapter to generate a txt file with chapter name and save it to each article folder.
def finally_file(self,tit,src,bigtit):
url = "http:" + src
req = request.Request(url, headers=header)
html = request.urlopen(req).read().decode('utf-8')
html = etree.HTML(html)
text_list = html.xpath('//div[@class="read-content j_readContent"]/p/text()')
text = "\n".join(text_list)
file_name = bigtit + "\\" + tit + ".txt"
print("Crawling articles:" + file_name)
with open(file_name, 'a', encoding="utf-8") as f:
f.write(text)spider=Spider()spider.start_request()
success!

The generated folder is as follows: