demand
One came from the front docx document, the back-end parses the tables in the document and processes the data in it.
(I don't know why I have to parse the tables in word documents instead of directly transferring them to excel.)
realization
1. Front end elementui-upload , take the whole The docx file is passed to the backend.
2. The back-end controller receives this document. Note that the received format is MultipartFile, not file, otherwise it will report 500.
3. The backend service parses this document:
public Map < String, Object > dealWord(MultipartFile file) throws IOException {
// 3.1 parsing the entire document
XWPFDocument xwpf = new XWPFDocument(file.getInputStream());
// 3.2 iterators for getting tables from documents
Iterator < XWPFTable > it = xwpf.getTablesIterator();
// 3.3 traverse all tables and parse them one by one
while (it.hasNext()) {
// 3.3.1 get the current table
XWPFTable table = it.next();
// 3.3.2 get row data
List < XWPFTableRow > rows = table.getRows();
// 3.3.3 traverse each row and get each cell
for (int i = 1; i < rows.size(); i++) {
XWPFTableRow row = rows.get(i);
List<XWPFTableCell> cells = row.getTableCells();
// 3.3.4 get the text in each cell
for(int j = 0;j<cells.size();j++){
String text = cells.get(j).getText()
}
}
}
If you only need to get the text content in each cell without considering line wrapping, then this is the end.
If you need to parse line breaks in cells, please continue to look down.
Next, let's introduce the big pit.
pit
At first, I thought XWPFTable could not parse line breaks. Later, I thought it was impossible. I looked at the data structure in XWPFTable.
But I have read and written in wps and office docx document, the parsed paragraph structure is different!
But it's good to be compatible.
Here by the way, let's introduce the parsed structure!
Take the following table as an example (WPS read-write version):

The data parsed from this table is similar to this:
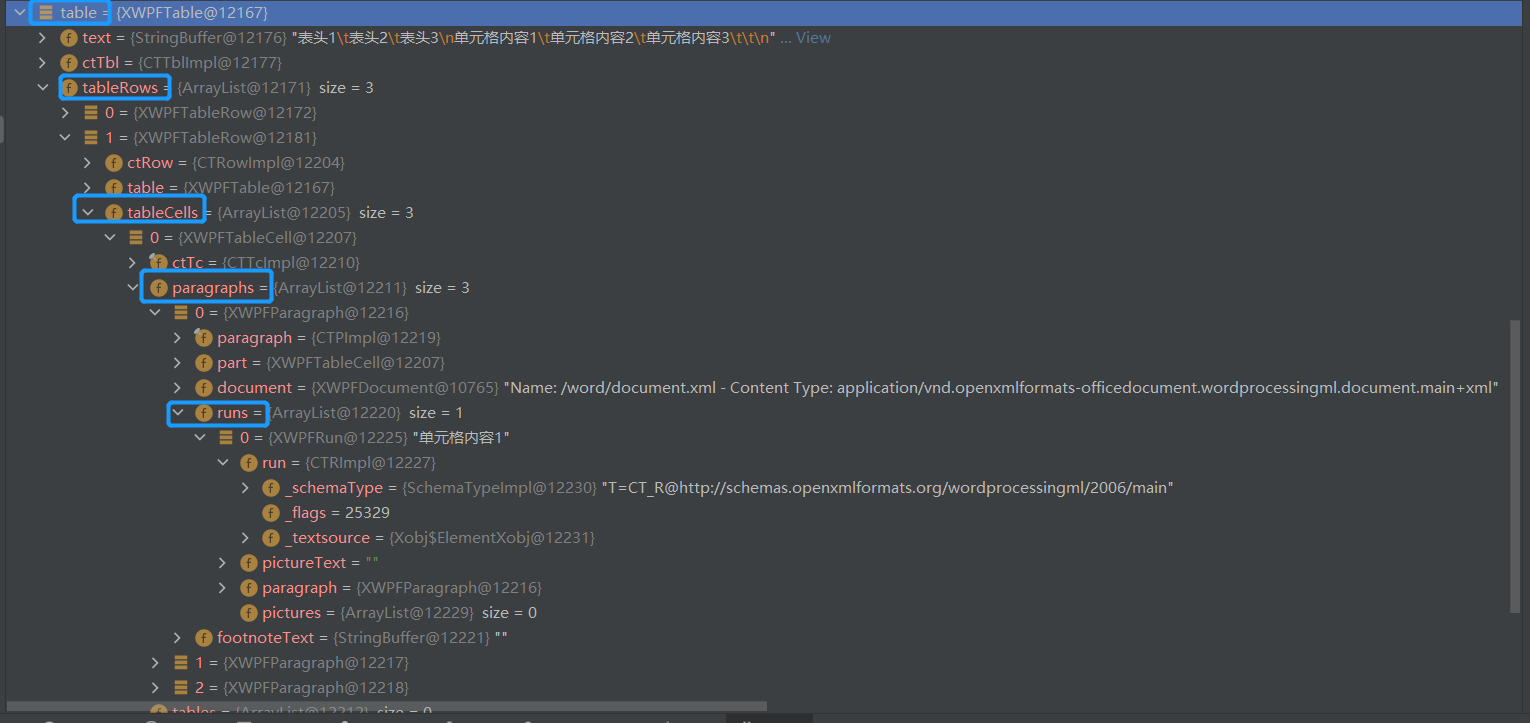
Field interpretation:

I don't know how to explain the runs here I don't quite understand the official documents. I hope friends who know something can add.
The difference between wps and word is in runs.
As you can see in the figure, there is a run object in paragrah, which is cell 1
Each of the three paragraphs has a run object.
However, in the table read and written by office, there may be multiple run objects, that is, cell 1 may be split into multiple run objects.
You can compare:
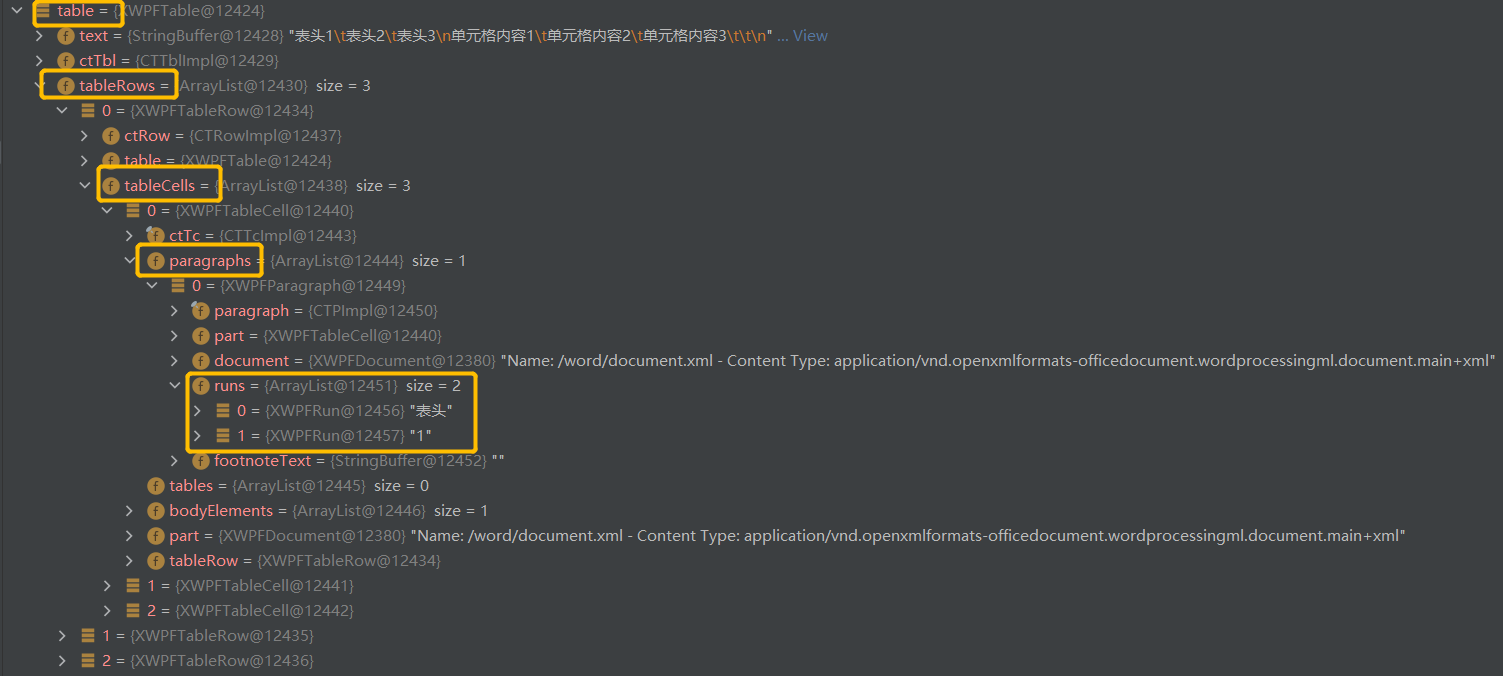
Here, cell 1 is disassembled into cell 1 and two run objects.
Explore office
Idle is also idle. Explore the rules for the number of run objects in office.
Speculation: split the text of the whole paragraph by data type. The table is string text and 1 is number.
Now we want to parse the offcie read / write table:
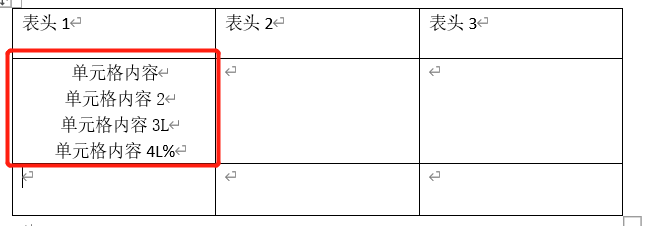
Parsed results:
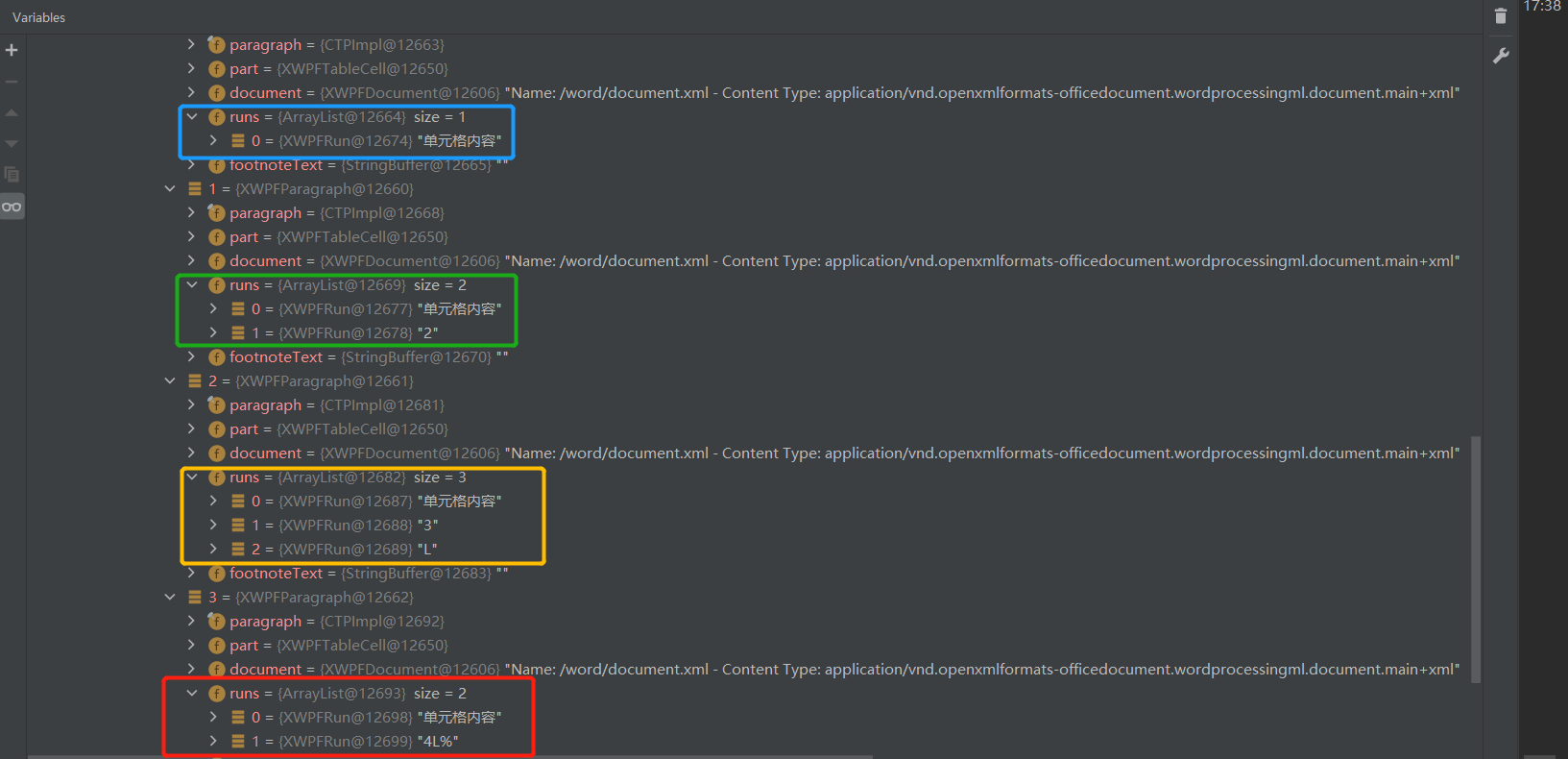
Compare:
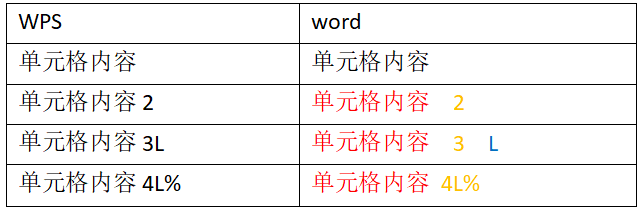
I don't understand With my limited knowledge, I don't know why I split 3 and l, but merged 4L% into a run object
terms of settlement
This problem is easy to solve:
To get the first row of content in a cell:
Get tableCell, get all paragrahs, get the first paragrah, and traverse to get all runs in this paragrah
In this way, it can adapt to wps and office at the same time.
Previous code:
public Map < String, Object > dealWord(MultipartFile file) throws IOException {
// 3.1 parsing the entire document
XWPFDocument xwpf = new XWPFDocument(file.getInputStream());
// 3.2 iterators for getting tables from documents
Iterator < XWPFTable > it = xwpf.getTablesIterator();
// 3.3 traverse all tables and parse them one by one
while (it.hasNext()) {
// 3.3.1 get the current table
XWPFTable table = it.next();
// 3.3.2 get row data
List < XWPFTableRow > rows = table.getRows();
// 3.3.3 traverse each row and get each cell
for (int i = 1; i < rows.size(); i++) {
XWPFTableRow row = rows.get(i);
List<XWPFTableCell> cells = row.getTableCells();
// 3.3.4 get the text in each cell
for(int j = 0;j<cells.size();j++){
String text = cells.get(j).getText()
}
// 3.3.5 get the first paragraph in the cell
// If you want to get the contents of all segments, use ArrayList to receive them. Ha, there is no demonstration here
for(int k = 0;k<cells.getParagraphs().size();k++){
String text = "";
// Traverse all the run s in the first paragraph. Note that only the paragraph with 0 is got here
for(int p = 0;p<cells.getParagraphs().get(0).getRuns().size();p++){
text = text + cells.getParagraphs().get(0).getRuns().get(p);
}
System.out.prrintln("The contents of the first row of cells are:"+text);
}
}
}
It's a very simple traversal. It's easy to adapt. It's written here.