Amazon's page of a classified product
- At the beginning, I must just try this page to see if I can request it
- At the beginning, I didn't know whether the anti crawling was good or not, so I simply added a user agent. Sure enough, it didn't work. The web page I climbed to was the web page for me to enter the verification code.
- Then use session and cookie s, eh! I managed to climb to the.
- Then analyze the page link, page, and find that only change the url

i is the number of the for loop
"https://www.amazon.com/s?k=anime+figure+one+piece&page=" + i
- Start paging and crawling after modification. Eh! I found that the cookie did not change at all when I clicked the next page. So I got the url of all the goods
code
import requests
import json
from lxml import etree
def load_cookies():
cookie_json = {}
try:
with open('export.json', 'r') as cookies_file:
cookie_json = json.load(cookies_file)
except:
print("Json load failed")
finally:
return cookie_json
def main():
page_list = []
for i in range(1, 8):
agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
headers = {
"HOST": "www.amazon.com/s?k=anime+figure+one+piece",
"Referer": "https://www.amazon.com/s?k=anime+figure+one+piece",
"User-Agent": agent
}
session = requests.session()
session.headers = headers
requests.utils.add_dict_to_cookiejar(session.cookies, load_cookies())
url = "https://www.amazon.com/s?k=anime+figure+one+piece&page=%d" % i
response = session.get(url)
print(response.text[:300])
# with open("test.html", "wb") as f:
# f.write(response.text.encode('utf-8'))
page_text = response.text
tree = etree.HTML(page_text)
a_list = tree.xpath('//a[@class="a-link-normal a-text-normal"]/@href')
# print(a_list)
#
for j in a_list:
page_url = "https://www.amazon.com" + j
page_list.append(page_url)
print("Done")
print(page_list)
for k in page_list:
with open("page02.txt", "a+") as f:
f.write(k + "\r")
if __name__ == '__main__':
main()
In addition, coookie is encapsulated in a cookie Py file, the following cookies have been deleted
import json
def save_cookies(cookies):
cookies_file = 'export.json'
with open(cookies_file, 'w') as f:
json.dump(cookies, f)
def main():
cookies = {
"ad-privacy": "0",
"ad-id": "A5d94GSIhp6aw774YK1k",
"i18n-prefs": "USD",
"ubid-main": "138-2864646",
"session-id-time": "20887201l",
"sst-main": "Sst1|PQHBhLoYbd9ZEWfvYwULGppMCd6ESJYxmWAC3tFvsK_7-FgrCJtViwGLNnJcPk6NS08WtWl7f_Ng7tElRchY70dGzOfHe6LfeLVA2EvS_KTJUFbqiKQUt4xJcjOsog_081jnWYQRp5lAFHerRS0K30zO4KWlaGuxYf-GlWHrIlX0DCB0hiuS4F69FaHInbcKlPZphULojbSs4y3YC_Z2098BiZK5mzna84daFvmQk7GS1uIEV9BJ-7zXSaIE1i0RnRBqEDqCw",
"sess-at-main": "7B9/7TbljVmxe9FQP8pj4/TirM4hXdoh0io=",
"at-main": "Atza|IwEBICsAvrvpljvBn6U0aVHZtVAdHNTj8I9XMXpj0_akGclan8n4it62oe4MadfnSheGBfJeVJwRmrV41ZbllH48hNM32FGo4DJGoeXE01gDei-_2PGNH3jKU79B8rzg8MaHRootDMSwFmj4vNmPtnvl6qrbfZoPSmey12IuWq9ijSx3MuCbpJ2wt4Sp7ixf7jWHW6VfaZ849AJkOBDonSHp9o",
"sp-cdn": "L5Z:CN",
"session-id": "141-56579-5761416",
"x-main": "2XkJe2ehs13TDTsRlELJt12FINPkJSfDKLuc5XjGgy2akeyGa45?wYKN4wcIC",
"session-token": "HfpLyDT70a2q+Ktd9sYUopKOKUeQndXMlbDcwP8sQNGA/ZeUA9ZNGNXOPRvXV8E6pUjeI7j/RR9iDCr5S7W0sRLmHT27PAvbN3TXsyaLvvPhsn4e3hUvhgdJn/xK/BfioKniukounAKZnYZLNcGf44ZiX8sRfdIjOiOx9GvAvl+hnPfJmWi/l73tqO6/G+PPf8uc0vq7Xubsgw2SuSXzqwq0gHEtE6HcbA6AeyyE59DCuH+CdV3p2mVSxUcvmF+ToO6vewLuMl1Omfc+tQ==",
"lc-main": "en_US",
# "csm-hit": "tb:s-YM0DR0KTNG964PT0RMS0|1627973759639&t:1627973760082&adb:adblk_no"
# "csm-hit": "tb:s-K3VN7V41Z5H7N250A9NE|1627974200332&t:1627974200622&adb:adblk_no"
"csm-hit": "tb:6CJBWDDJGRZPB09G+b-K3VN7V41Z5H7N250A9NE|1627974443&t:1627974446683&adb:adblk_no"
}
save_cookies(cookies)
if __name__ == '__main__':
main()
- It's very late to climb to the url. I thought it was as simple as before. Then add a cookie to each url and climb to the page. As soon as xpath is parsed, it's over. Go to bed first.
- The next morning, I continued to do it and found that things were not so simple. When crawling each commodity, the cookie will change accordingly. Each request will find that the value of CSM hit field in the cookie will change. And I don't know why I couldn't climb the code last night. It collapsed. But there must be a way.
- Yes, it's selenium. Automatic operation, requesting page URLs one by one, and obtaining page details are also very delicious. You don't have to enter cookie s.
- Retrieve yesterday's url first. (it is found that the url is not fully obtained by headless, so it is commented out)
from selenium import webdriver
from time import sleep
from lxml import etree
# # Realize no visual interface
# from selenium.webdriver.chrome.options import Options
# # Implementation of circumvention detection
# from selenium.webdriver import ChromeOptions
# # Realize the operation without visual interface
# chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# # Implementation of circumvention detection
# option = ChromeOptions()
# option.add_experimental_option('excludeSwitches', ['enable-automation'])
# , chrome_options=chrome_options, options=option
driver = webdriver.Chrome(r'C:\Program Files\Google\Chrome\Application\chromedriver.exe')
sleep(2)
for i in range(1, 8):
url = "https://www.amazon.com/s?k=anime+figure+one+piece&page=" + str(i)
try:
driver.get(url)
page_list = []
page_text = driver.page_source
tree = etree.HTML(page_text)
a_list = tree.xpath('//a[@class="a-link-normal a-text-normal"]/@href')
for j in a_list:
page_url = "https://www.amazon.com" + j
page_list.append(page_url)
for k in page_list:
with open("page02.txt", "a") as f:
f.write(k + "\r")
sleep(2)
print(str(i) + " ok")
except:
print(str(i) + " eroor")
continue
- Because you need the title and introduction of the goods in English, you should input the zip code of the United States before crawling the details of the goods, and it will be automatically changed to English. Of course, automation is coming. click and then input.
- The problem comes again. How can I get this picture? All the pictures I get are 40 * 40. I can't see them clearly at all. But problems can always be solved.
- Analyze the html page. The high-definition picture is in the highlighted li tag, but only this high-definition picture.
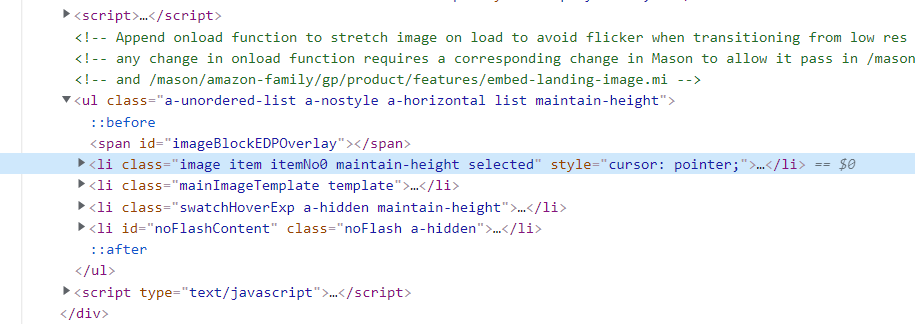
- But after careful study, I found that when I mouse over this picture

- The following li tags immediately increased. When they were opened one by one, they found that they were really high-definition pictures
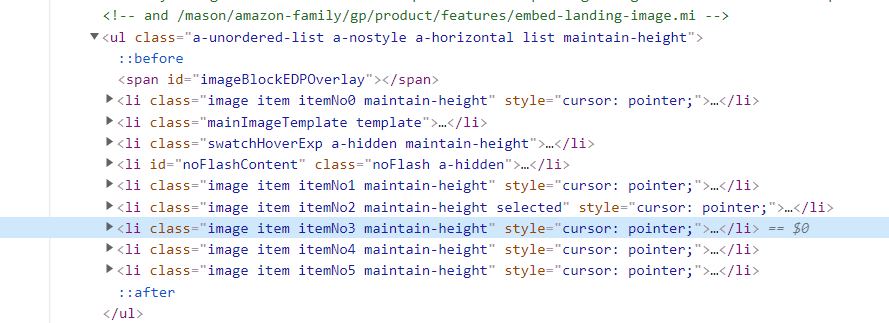
- So there's a way. I can click on the picture before getting the html details of the page every time, then get the html information of the page, then parse it by xpath, and then write the obtained title, introduction and price into the file, so it's OK.
from selenium import webdriver
from time import sleep
from lxml import etree
import os
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
}
driver = webdriver.Chrome(r'C:\Program Files\Google\Chrome\Application\chromedriver.exe')
driver.get("https://www.amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_atf_aps_sr_pg1_1?ie=UTF8&adId=A08238052EFHH6KXIQA1O&url=%2FAnime-Cartoon-Figure-Character-Model-Toy%2Fdp%2FB094QMYVNV%2Fref%3Dsr_1_1_sspa%3Fdchild%3D1%26keywords%3Danime%2Bfigure%2Bone%2Bpiece%26qid%3D1627911157%26sr%3D8-1-spons%26psc%3D1&qualifier=1627911157&id=1439730895405084&widgetName=sp_atf")
button = driver.find_element_by_xpath(
'//a[@class="nav-a nav-a-2 a-popover-trigger a-declarative nav-progressive-attribute"]')
button.click()
sleep(2)
input = driver.find_element_by_id('GLUXZipUpdateInput')
input.send_keys("75159")
sleep(1)
button_set = driver.find_element_by_id('GLUXZipUpdate')
button_set.click()
sleep(2)
# button_close = driver.find_element_by_id('GLUXConfirmClose-announce')
# sleep(2)
page_list = []
with open("page02.txt", "r") as f:
for i in range(0, 368):
t = f.readline()
page_list.append(t[0:-1])
i = 1
for url in page_list:
try:
# ls = []
sleep(2)
driver.get(url)
# page_text = driver.page_source
# # print(page_text)
# tree = etree.HTML(page_text)
sleep(2)
# img
for p in range(4, 13):
try:
xpath_1 = format('//li[@class="a-spacing-small item imageThumbnail a-declarative"]/span/span[@id="a-autoid-%d"]' % p)
min_img = driver.find_element_by_xpath(xpath_1)
min_img.click()
except:
continue
page_text = driver.page_source
tree = etree.HTML(page_text)
max_img_list = tree.xpath('//ul[@class="a-unordered-list a-nostyle a-horizontal list maintain-height"]//div[@class="imgTagWrapper"]/img/@src')
# print(max_img_list)
# title
title_list = tree.xpath('//span[@class="a-size-large product-title-word-break"]/text()')[0]
# print(title_list[8:-7])
title = title_list[8: -7]
# price
price_list = tree.xpath('//span[@class="a-size-medium a-color-price priceBlockBuyingPriceString"]/text()')
# print(price_list[0])
price = price_list[0]
# item
item_title = tree.xpath('//table[@class="a-normal a-spacing-micro"]/tbody/tr/td[@class="a-span3"]/span/text()')
item_con = tree.xpath('//table[@class="a-normal a-spacing-micro"]/tbody/tr/td[@class="a-span9"]/span/text()')
# print(item_title)
# print(item_con)
item_list = []
for k in range(len(item_title)):
item_list.append(item_title[k] + " -:- " + item_con[k])
# print(item_list)
# about
# about_title = tree.xpath('//div[@class="a-section a-spacing-medium a-spacing-top-small"]/h1[@class="a-size-base-plus a-text-bold"]/text()')
about_li = tree.xpath('//div[@class="a-section a-spacing-medium a-spacing-top-small"]/ul/li/span[@class="a-list-item"]/text()')
# about_title_str = about_title[0][2:-2]
# print(about_li[2:])
# Folder path
path = "./data4/" + str(i)
if not os.path.exists(path):
os.mkdir(path)
# print(path)
# txt file path
path_txt = path + "/" + str(i) + ".txt"
with open(path_txt, "a") as f:
f.write(title + "\r")
f.write(price + "\r")
for p in item_list:
with open(path_txt, "a+") as f:
# f.write("\r")
f.write(p + "\r")
for o in about_li:
with open(path_txt, "a+", encoding="utf8") as f:
f.write(o)
for d in max_img_list:
img_data = requests.get(url=d, headers=headers).content
img_path = path + "/" + str(i) + d.split("/")[-1]
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(str(i) + " OK")
i = i + 1
except:
sleep(2)
i = i + 1
print(str(i) + "error")
continue
sleep(10)
driver.quit()
Note: you must click on the pictures first, and then obtain the html page source code, otherwise you can't parse the high-definition pictures.
Achievement display
Each item has a folder
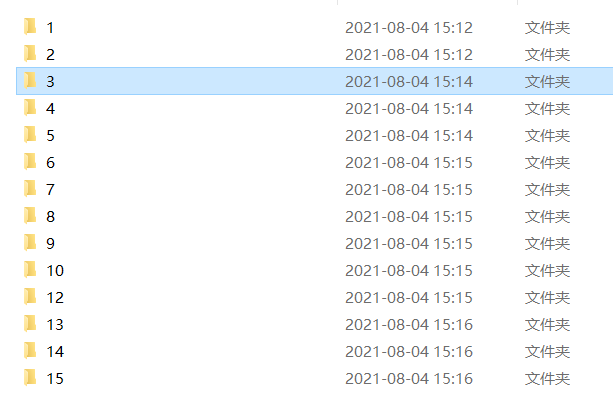
There is a txt file and all the pictures
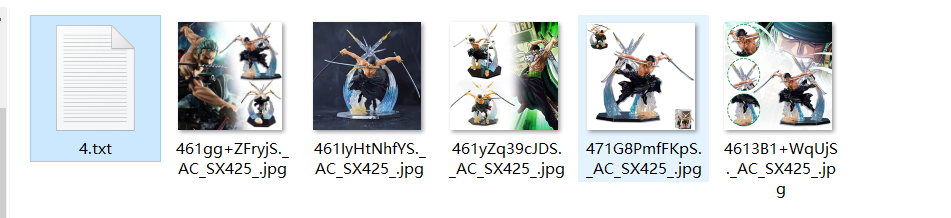
txt file is the title, price, detailed description
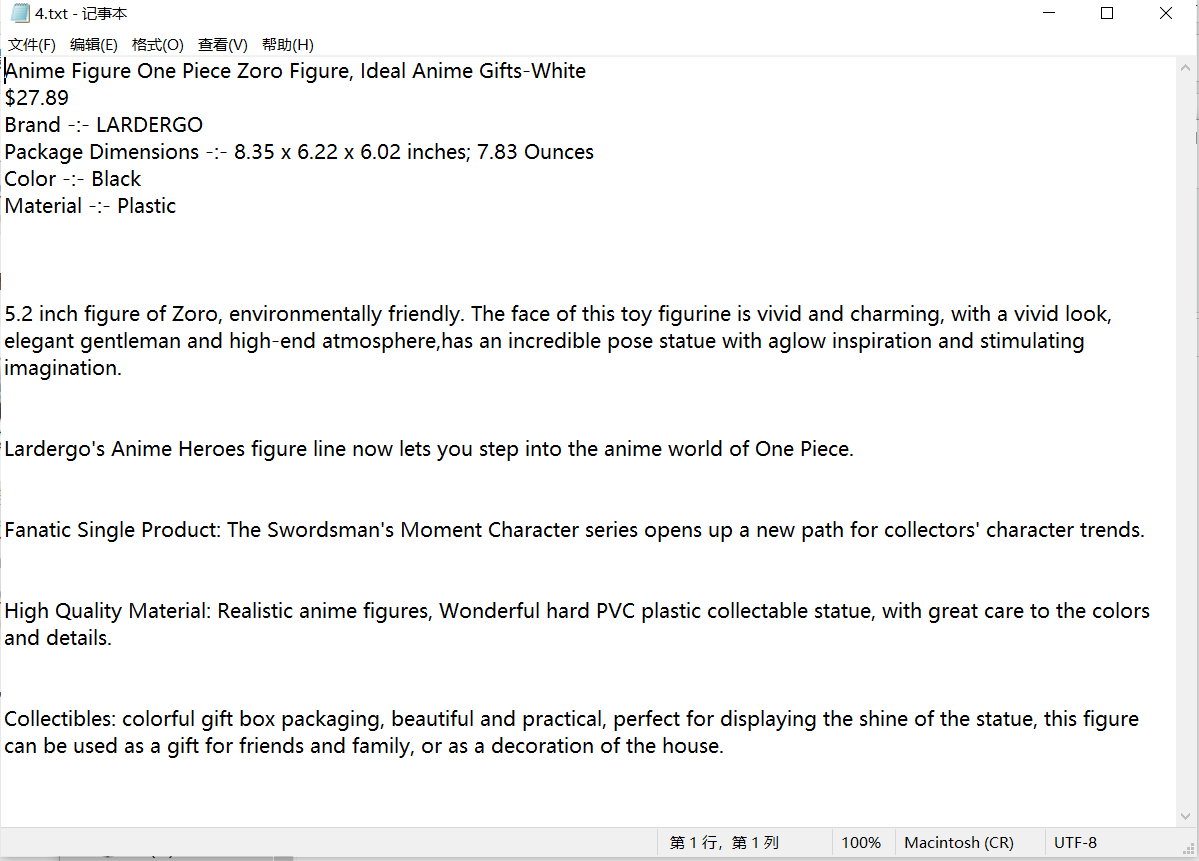
over! over!