Shared before I heard that the official account of Shenzhen Health Protection Committee is being complained by netizens. I have taken all the titles and reading numbers of the articles under analysis. Later, it was found that the cover map of the number was interesting, so the bulk cover was downloaded. If necessary, reply to the cover of the official account dialog box to get the SkyDrive address of all the cover maps.
The file name of all cover charts is the release date of the article plus the title for easy search.

So I studied the contents, pictures, videos and audio of the official account in batches. The contents of the article support the export of HTML and pdf format. Take my official account as an example, more than 300 original articles were downloaded soon, and the details of the download were read before. One button downloads all the official account numbers, and export files to support PDF, HTML, Markdown, Excel, chm and so on. If you need to grab the downloaded official account, contact me at the background WeChat.
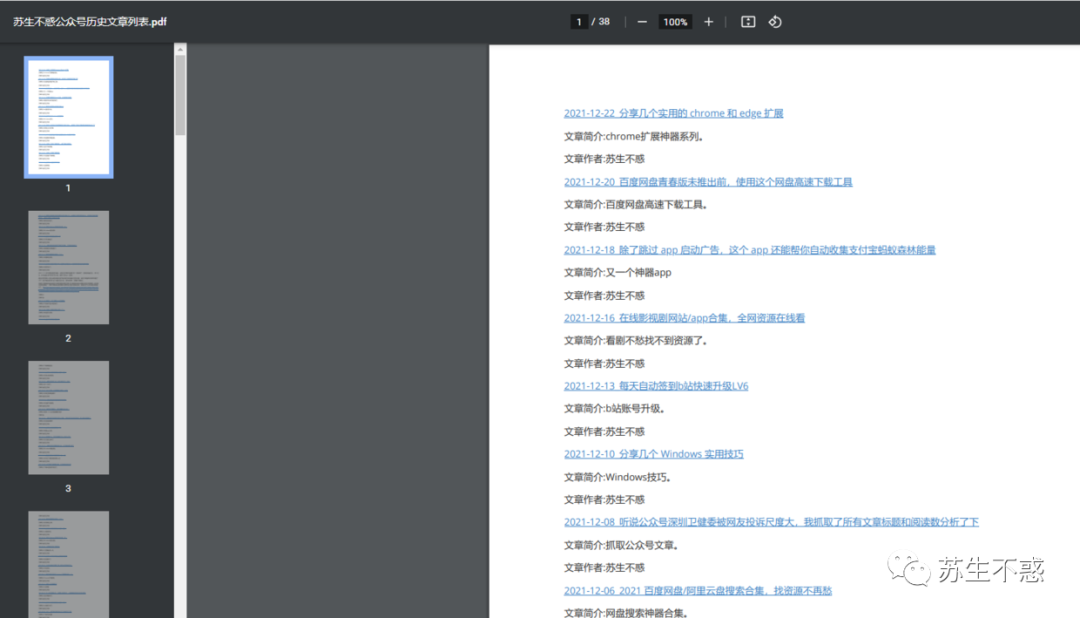
pdf files of all historical article lists generated, including article release time, article author, article introduction and article link. Which article you need to find can be opened after ctrl+f search, which is much more convenient than searching in wechat.
There are also markdown format files.

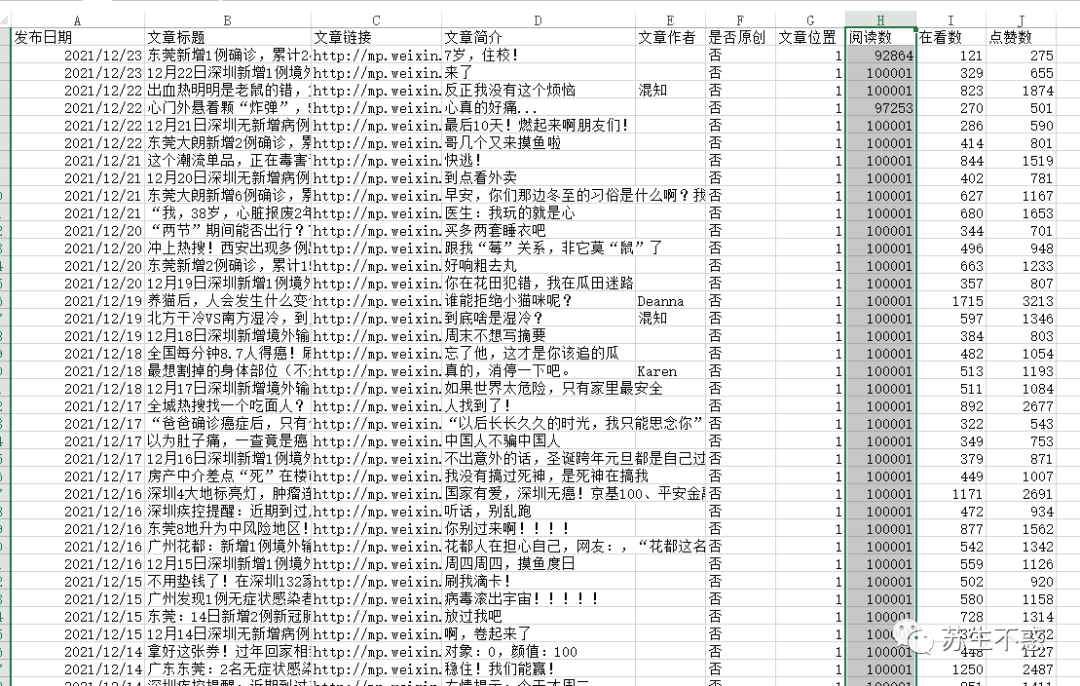
And excel data files (which are used by the official account of Shenzhen Health Committee), including the date of issue, article title, article link, article introduction, article author, reading number, number of reading and number of points, sorting according to the number of articles, it is easy to know which chapters are popular.
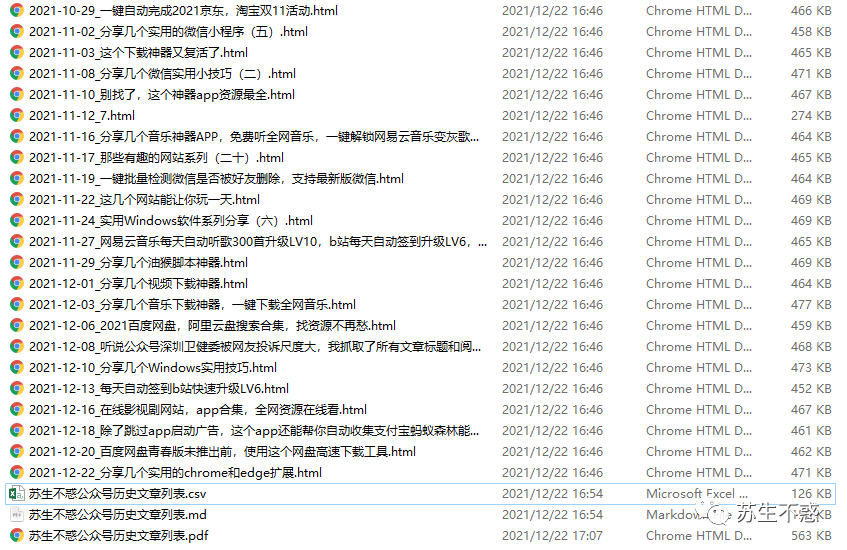
The downloaded html file can be opened with Google browser. Even if the article is deleted, you can continue to read it locally.
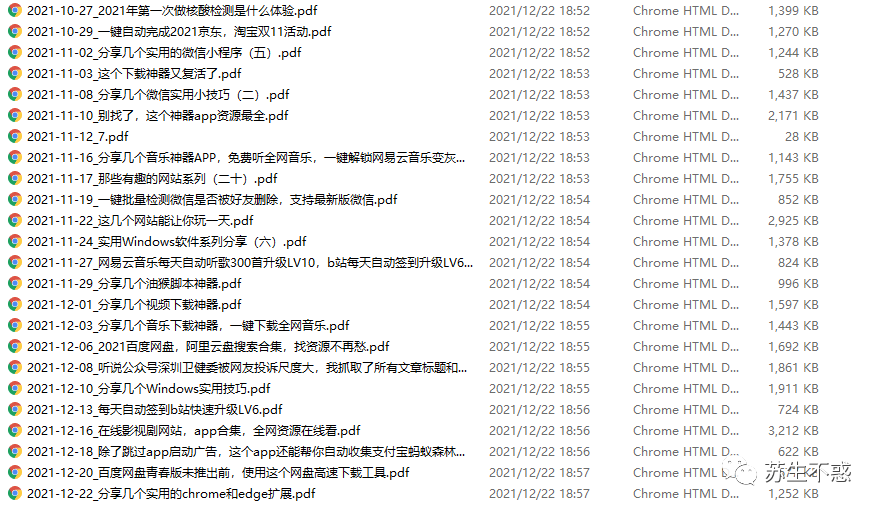
Then use python script to convert html into pdf files in batches.
def export_pdf():
import pdfkit,os
print('export PDF...')
htmls = []
for root, dirs, files in os.walk('.'):
for name in files:
if name.endswith(".html"):
print(name)
try:
pdfkit.from_file(name, 'pdf/'+name.replace('.html', '')+'.pdf')
except Exception as e:
print(e)
export_pdf()
The converted pdf file is larger than html file.
Because my article doesn't send audio, here take this number silently as an example, a single article Light in the tunnel The audio can be downloaded directly with idm.
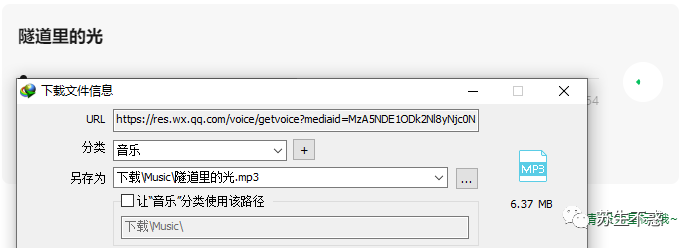
The audio link file format is https://res.wx.qq.com/voice/getvoice?mediaid=xxx So you can download audio in batches with regular matching.
def audio(res,headers,date,title):
aids = re.findall(r'"voice_id":"(.*?)"',res.text)
time.sleep(2)
tmp = 0
for id in aids:
tmp +=1
url = f'https://res.wx.qq.com/voice/getvoice?mediaid={id}'
audio_data = requests.get(url,headers=headers)
print('Downloading audio:'+title+'.mp3')
with open(date+'___'+title+'___'+str(tmp)+'.mp3','wb') as f:
f.write(audio_data.content)
Batch download audio effect:
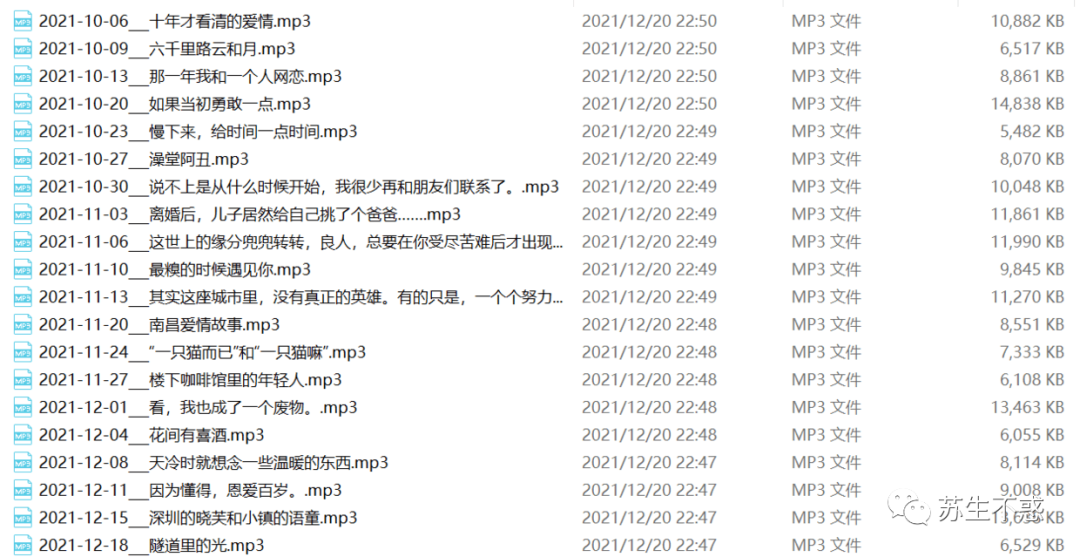
The downloaded audio file name is article release time + article title mp3 is also convenient for searching.
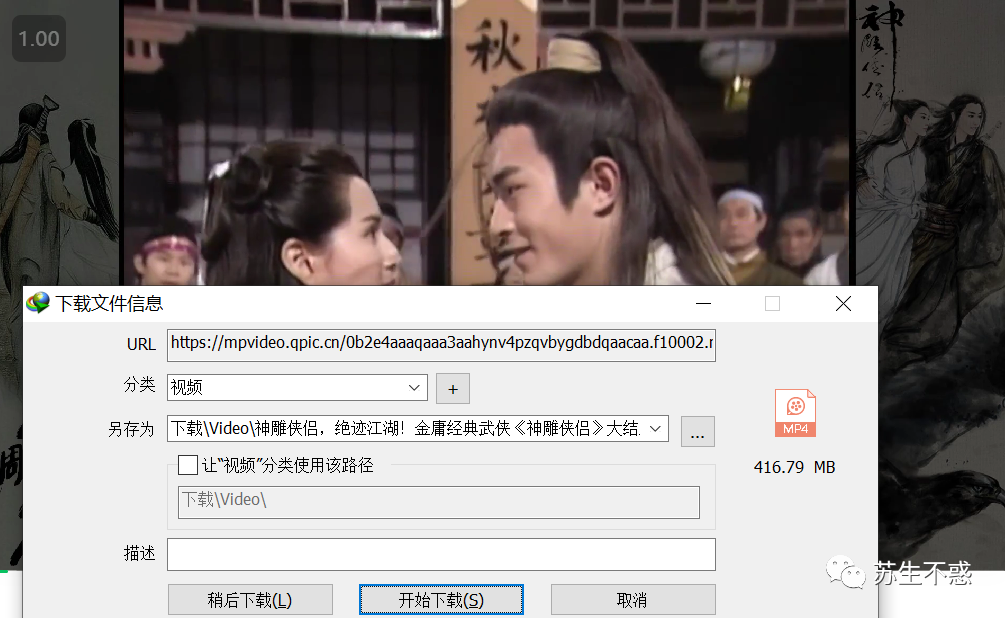
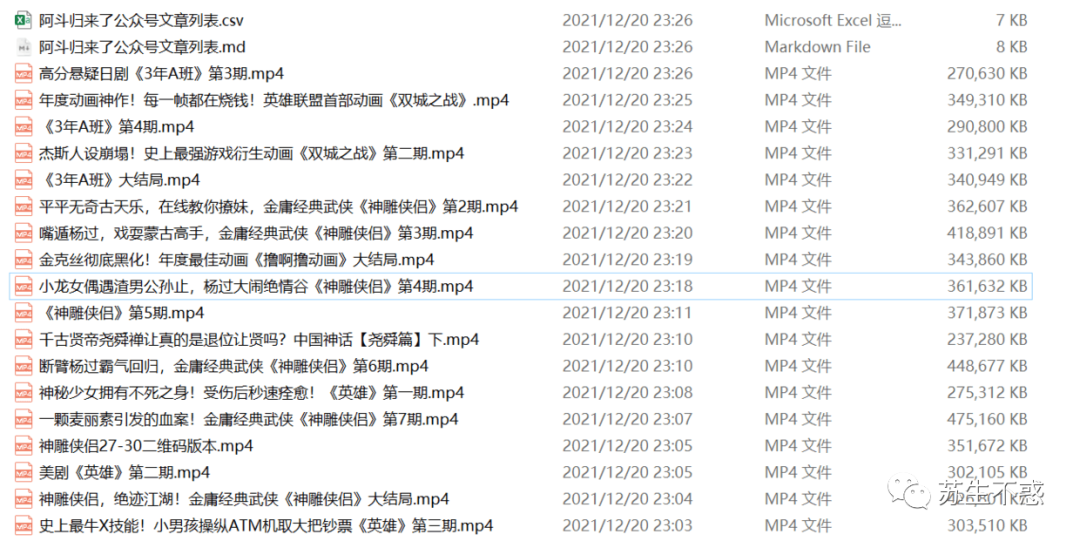
Similarly, my official account does not send videos. Here is the return of the fight. Immortal Eagle Xia, extinct in the Jianghu! The grand finale of Jin Yong's classic martial arts "divine carving heroes" The video can also be downloaded with idm.
Video links are also regular, and videos are downloaded in batches through regular matching:
def video(res, headers):
vid = re.search(r'wxv_.{19}',res.text).group(0)
time.sleep(2)
if vid:
url = f'https://mp.weixin.qq.com/mp/videoplayer?action=get_mp_video_play_url&preview=0&vid={vid}'
data = requests.get(url,headers=headers).json()
video_url = data['url_info'][0]['url']
video_data = requests.get(video_url,headers=headers)
print('Downloading video:'+trimName(data['title'])+'.mp4')
with open(trimName(data['title'])+'.mp4','wb') as f:
f.write(video_data.content)
Batch download video effects:
The downloaded video is shown in the figure below:
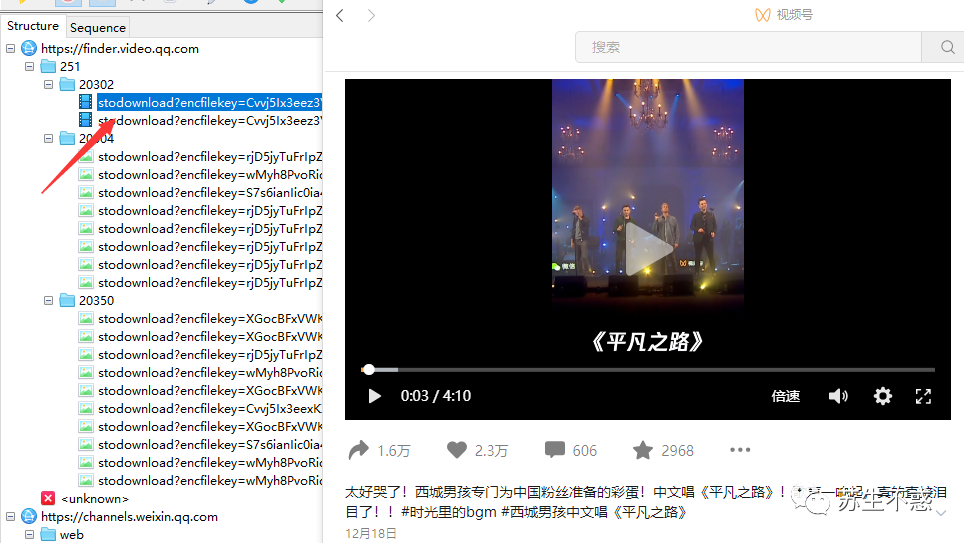
If the video in the video number is used in the article, it can only be downloaded by capturing the package. At present, how to download the video number in batch has not been studied. Here, taking the video of Xicheng boy's video number a few days ago as an example, you can obtain the video download address by capturing the package.
Finally, let's talk about batch downloading the pictures in the article, which is also batch downloading with regular matching picture links:
def imgs(content,headers,date,position,title):
imgs=re.findall('data-src="(.*?)"',content)
time.sleep(2)
num = 0
for i in imgs:
num+=1
img_data = requests.get(i,headers=headers)
print('Downloading pictures:'+i)
with open(date+'___'+title+'___'+str(position)+'___'+str(num)+'.jpg','wb') as f:
f.write(img_data.content)
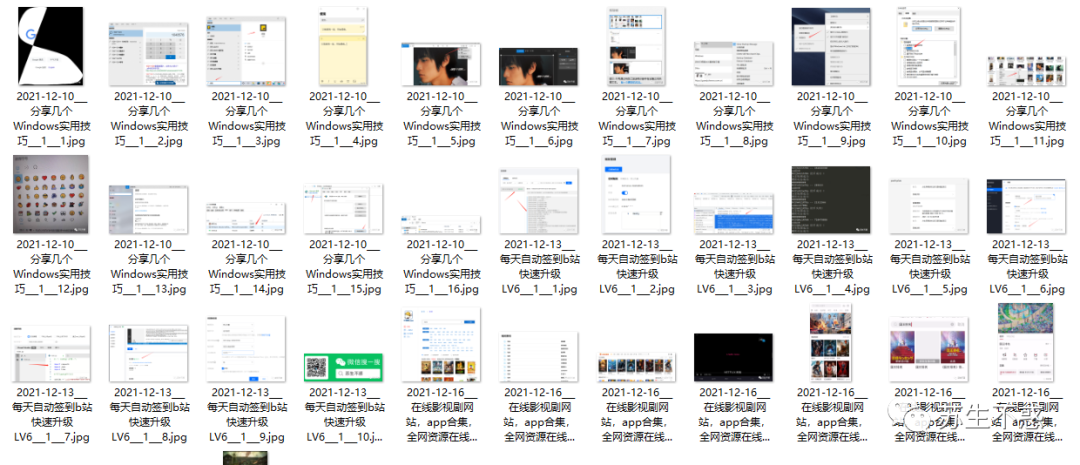
Batch download picture effect:
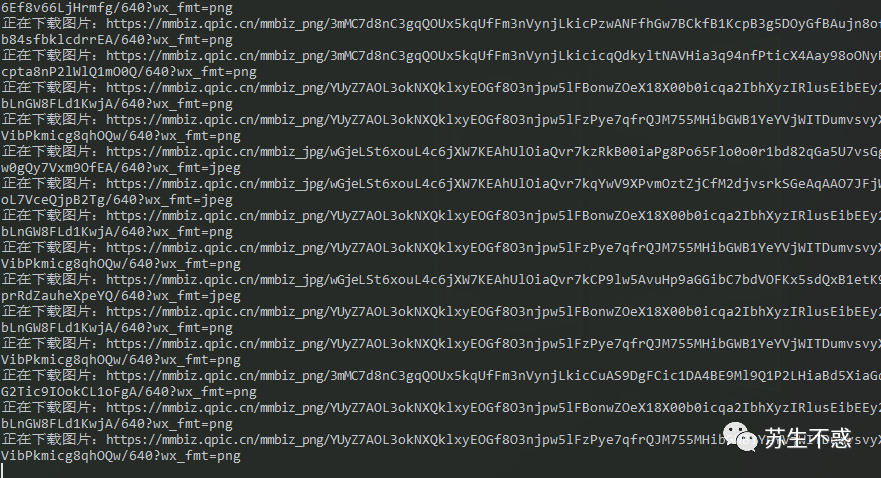
The downloaded image file name is the article release time plus the article title and number: