Dictionaries and collections
It is a coincidence that dictionaries and collections are always put together because they are wrapped in braces {}.
What are the basic operations of dictionaries and collections
Let's start with the dictionary
The dictionary is composed of Key Value pairs. The Key is Key and the Value is Value. Mark it in Python 3 Before 6, the dictionary was unnecessary, the length and size were variable, and the elements could be deleted and changed arbitrarily. After Python 3.7, the dictionary was ordered.
In order to test the disorder of the dictionary, I specifically tested it in the Python online environment. The code is as follows:
my_dict = {}
my_dict["A"] = "A"
my_dict["B"] = "B"
my_dict["C"] = "C"
my_dict["D"] = "D"
for key in my_dict:
print(key)The running results also prove the disorder. 
In the local Python version 3.8 test, there is no disorder.
So if someone asks if the dictionaries in Python are in order, don't directly answer out of order. This thing now has order.
Dictionary, a key value pair structure, is more suitable for adding elements, deleting elements, finding elements and so on than lists and tuples.
The creation of the dictionary is not detailed. It has been involved in the snowball's first learning. It should be noted that when the index key does not exist, a KeyError error error will appear, which is an extremely common error.
my_dict = {}
my_dict["A"] = "A"
my_dict["B"] = "B"
my_dict["C"] = "C"
my_dict["D"] = "D"
print(my_dict["F"])The error prompt is as follows:
Traceback (most recent call last):
File ".\demo.py", line 7, in <module>
print(my_dict["F"])
KeyError: 'F'If you don't want this exception to occur, you can use the get(key,default) function when indexing keys.
print(my_dict.get("F","None"))Talk about the collection again
The basic structure of a set is the same as that of a dictionary. The biggest difference is that a set has no key value pairs. It is an unordered and unique combination of elements.
The collection does not support index operation, which means that the following code will report an error.
my_set = {"A","B","C"}
print(my_set[0])The exception prompt is type error: typeerror: 'set' object is not subscribable.
The rest of the key memory is the collection, which is often used in the de duplication operation, which can be mastered.
Dictionary and collection sorting
The basic operations are still not explained too much. If necessary, you can go to the snowball for the first time. Here we emphasize the sorting function, because it involves some extended knowledge points, you can contact it first, and some contents will be discussed in detail later.
Before learning, you should remember that the elements obtained by pop operation on the collection are uncertain because the collection is disordered. For details, you can test the following code:
my_set = {"A","B","C"}
print(my_set.pop())If you want to sort dictionaries, you can do so according to our known technology.
The following is Python 3 Running results under version 6. 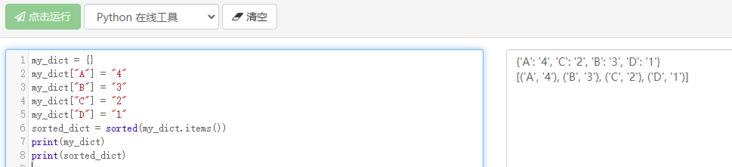
The sorted function can be used directly to sort dictionaries. When sorting, you can also specify to sort by key or value, such as ascending sorting by dictionary value.
my_dict = {}
my_dict["A"] = "4"
my_dict["B"] = "3"
my_dict["C"] = "2"
my_dict["D"] = "1"
sorted_dict = sorted(my_dict.items(),key=lambda x:x[1])
print(sorted_dict)The output results are as follows. The results are sorted according to the values of the dictionary. It should be noted that the lambda anonymous function will be expanded step by step in subsequent courses
[('D', '1'), ('C', '2'), ('B', '3'), ('A', '4')]There are no special instructions for sorting collections. You can directly use the sorted function.
Dictionary and set efficiency
For the efficiency of dictionaries and collections, the main object of comparison is lists. Assuming there is a pile of student number and weight data, we need to judge the number of students with different weights.
Requirements are described as follows:
There are 4 students. The tuples formed by sorting according to the student number are (1,90), (2,90), (3,60), (4100), and the final result output 3 (there are three different weights)
Write the following code according to the requirements:
List writing
def find_unique_weight(students):
# Declare a statistical list
unique_list = []
# Cycle all student data
for id, weight in students:
# If the weight is not in the statistical list
if weight not in unique_list:
# New weight data
unique_list.append(weight)
# Calculate list length
ret = len(unique_list)
return ret
students = [
(1, 90),
(2, 90),
(3, 60),
(4, 100)
]
print(find_unique_weight(students))Next, the above code is modified to set writing
def find_unique_weight(students):
# Declare a collection of Statistics
unique_set = set()
# Cycle all student data
for id, weight in students:
# The collection automatically filters duplicate data
unique_set.add(weight)
# Calculate set length
ret = len(unique_set)
return retAfter the code is written, it is not found that there is much difference, but if the data is expanded to two larger sets, such as tens of thousands of data.
The following code time calculation function applies time perf_ Counter() when this function is called for the first time, randomly select A time point A from the computer system and calculate how many seconds it is from the current time point B1. When the function is called for the second time, it defaults to the number of seconds from the current time point B2 calculated from the time point A of the first call. Take the difference between the two functions, that is, realize the timing function from time point B1 to B2. First, run the following code in combination with the function calculated in the list
import time
id = [x for x in range(1, 10000)]
# The weight data can only be from 1 to 10000 for calculation
weight = [x for x in range(1, 10000)]
students = list(zip(id, weight))
start_time = time.perf_counter()
# Call list calculation function
find_unique_weight(students)
end_time = time.perf_counter()
print("The operation time is:{}".format(end_time - start_time))The running time is 1.7326523, and the running speed of each computer is inconsistent, depending on the difference.
Modify the above code and run it on the function written by the collection. The final result is 0.0030606. You can see that such a big difference has occurred in the order of 10000 data. If the order of magnitude is rising, the difference will increase again, so do you know what to use?
Summary of this blog
In this blog, we have supplemented the knowledge related to dictionaries and sets. One knowledge eraser is still omitted, that is, the storage principle of dictionaries and sets, which will specifically involve the knowledge related to hash table structure. This part has little impact on primary applications, so it will be omitted for the time being. For dictionaries and sets, if you need to find data efficiently in writing programs To remove the duplicate data, it is recommended to apply the two in time.