E-book analysis
Idea: when uploading e-books, multer middleware is used to complete the uploading process. After uploading, a file object will be generated in req. This file object represents an array to represent the sequence of files. The file object contains the file object, which contains the file name, file path, file resource type, etc, After receiving this information, you can generate a Book object through this information. The book object here is the so-called e-book object, and then complete the parsing process through the book object
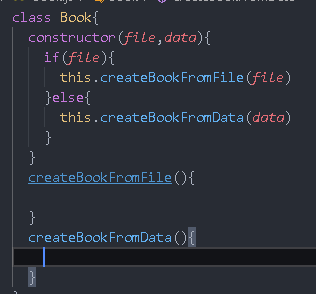
models/Book.js
The book here represents an e-book. It must provide us with some capabilities, including creating objects from files. Another is that when editing, it needs to be able to turn it into a Book object according to the data of the form
What are the benefits of becoming a Book object? After parsing the book object, you can write some methods, such as parse method, to parse the book object, and you can parse some of the details, such as language, title, creator, etc,
It can parse the e-book directory, convert the book object into json format (which can be directly used by the front end), convert it into the database field name, and quickly generate some sql statements. Therefore, it is very important that the book object corresponds to us to develop the whole e-book parsing part. Therefore, a large part of e-book parsing is writing book objects.
E-book object development
Incoming file means that an e-book file has just been uploaded. If you pass in a data, it means updating or inserting e-book data. Data means inserting data into the database. File is mainly used to parse e-book data

router/book.js call

After you know the contents of the file object, you can parse it
mimetype can give him a default type
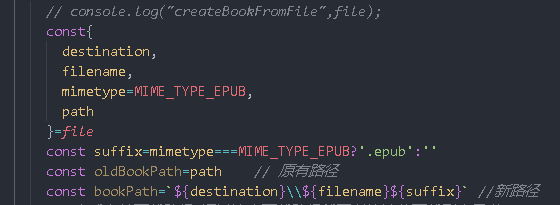
We need to change the name of the file because we found the returned file The path path has no suffix, so it will be troublesome to identify this file
The download path definition URL of the generated file is constant js
Upload has been changed here_ Path does not need two backslashes, and a '/' is OK
An ancient bug upload is found here_ There should not be \ book after path

// Generate a file download path through which you can quickly download to the e-book
const url=`${UPLOAD_URL}/book/${filename}${suffix}`
The same applies to the unzipped folder
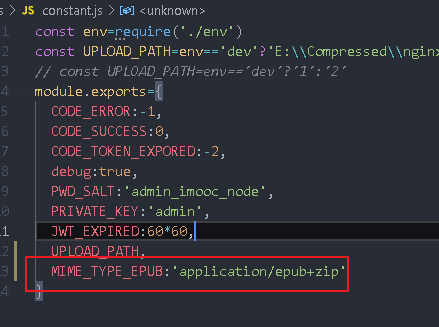
const {MIME_TYPE_EPUB,UPLOAD_URL,UPLOAD_PATH}=require('../utils/constant')
class Book{
constructor(file,data){
if(file){
this.createBookFromFile(file)
}else{
this.createBookFromData(data)
}
}
createBookFromFile(file){
// console.log("createBookFromFile",file);
const{
destination,
filename,
mimetype=MIME_TYPE_EPUB,
path
}=file
// E-book file suffix
const suffix=mimetype===MIME_TYPE_EPUB?'.epub':''
// Original path of e-book
const oldBookPath=path // Original path
// E-book new path
const bookPath=`${destination}\\${filename}${suffix}` //New path
// Generate a file download path through which you can quickly download to the e-book
// Download URL of e-book
const url=`${UPLOAD_URL}/book/${filename}${suffix}`
// Generate an e-book decompression folder named after the file name
// Folder path after e-book decompression
const unzipPath=`${UPLOAD_PATH}\\unzip\\${filename}`
// This url path will be used when reading the e-book
// Folder URL after e-book decompression
const unzipUrl=`${UPLOAD_URL}/unzip/${filename}`
}
createBookFromData(){
}
}
module.exports=Book
Next, you can create the decompression folder of the e-book
if(!fs.existsSync(unzipPath)){
// Iterate to create a folder if it does not exist
fs.mkdirSync(unzipPath,{recursive:true})
}
Next, the extracted files will be thrown under this path
Rename file
// Judge whether the current e-book exists. If it exists and the new e-book does not exist
// Call rename to rename the folder, and pass oldBookPath and bookPath to rename
if(fs.existsSync(oldBookPath)){
fs.renameSync(oldBookPath,bookPath)
}
Next, define some properties of the book object according to some fields required by the front end
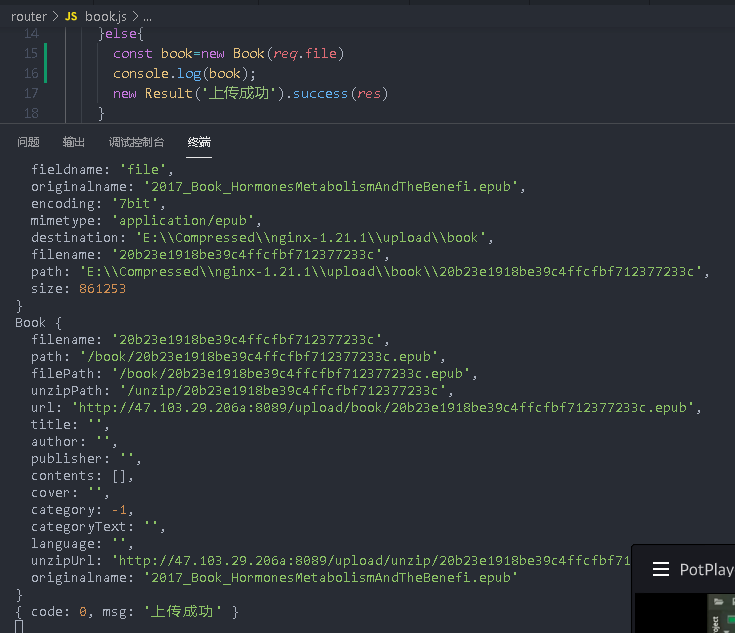
this.filename=filename // File name without suffix
// Write relative paths to be compatible with different scenarios, because the absolute paths of the server and the client are different
this.path=`/book/${filename}${suffix}` // epub file relative path
this.filePath=this.path // Create an alias
this.unzipPath=`/unzip/${filename}` // Relative path after decompression
this.url=url // epub file download link
this.title='' // Title or book title, generated after parsing
this.author=''
this.publisher='' // press
this.contents=[] // catalogue
this.cover='' // Cover image url
this.category=-1 // Classification id
this.categoryText='' // Classification name
this.language='' // languages
this.unzipUrl=unzipUrl // Unzipped folder link
this.originalname=originalname // Original name
Take a look at the result (here both backslashes should be changed to /)
E-book parsing library epub Library
epubjs library is used for browser scenes. It cannot work without the browser, because it mainly renders the browser in the browser scene
The epub library here is used in the node environment
https://github.com/julien-c/epub/blob/master/epub.js
Because his code needs to be modified, it is copied and integrated into the project, not installed through npm package
utils/epub.js
Install ADM zip xml2js
Epub class provides a parse method
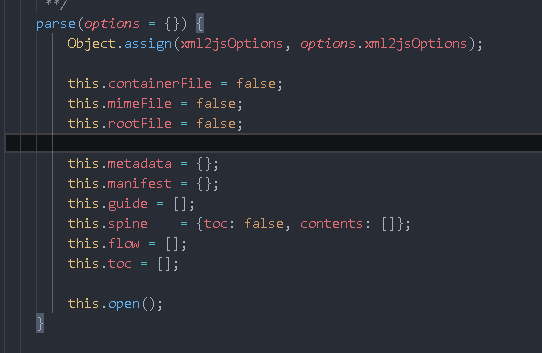
The parse method is used in actual parsing
Let's see. The usage method is implemented using event
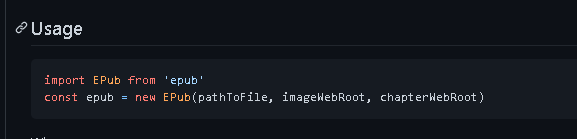
After passing in, a callback method is used
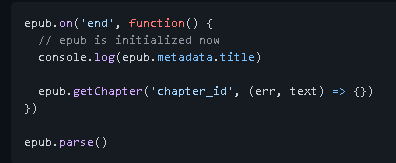
The following function is the callback after successful parsing
When to start manual parsing? You need to call ePub parse()
Call the getChapter method through the epub instance, and then call a callback
Author, this information can be obtained from metadata
After successful parsing, you can use ePub Metadata get

flow is the order in which the entire e-book is rendered
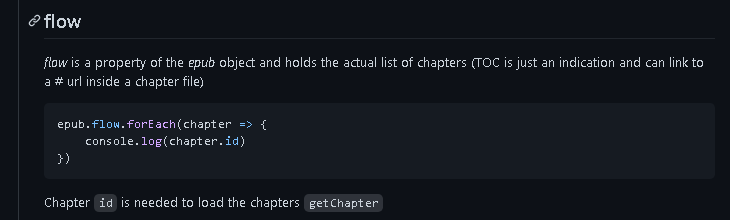
getChapter get chapter (pass in Chapter id) get the text corresponding to the chapter
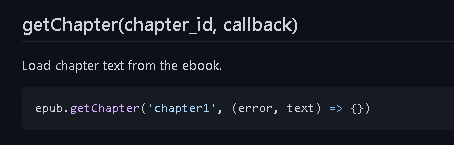
getChapterRaw represents the original text obtained, that is, a file in html format
getImage passes in the picture id to get the actual content of the picture
getFile passes in the css id and gets the css file
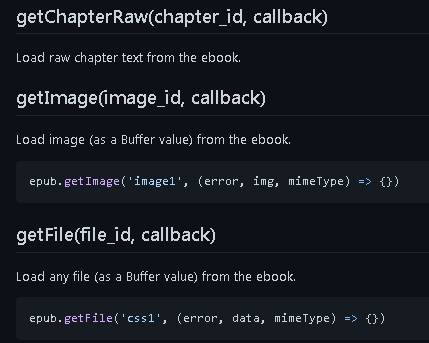
Because there are a lot of callbacks, it will be reformed later
E-book analysis method
model/Book.js into epub Library
Add a parse method. We have added many attributes to Book, but many of them are default values. They are parsed in parse and then filled in
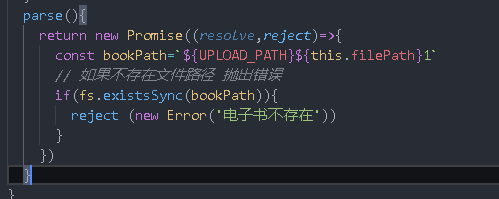
parse(){
return new Promise((resolve,reject)=>{
const bookPath=`${UPLOAD_PATH}${this.filePath}1`
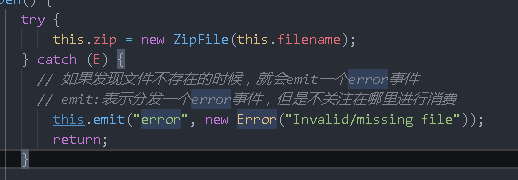
// If there is no file path, an error is thrown
if(!fs.existsSync(bookPath)){
reject (new Error('E-book does not exist'))
}
})
}
Test it
router/book.js
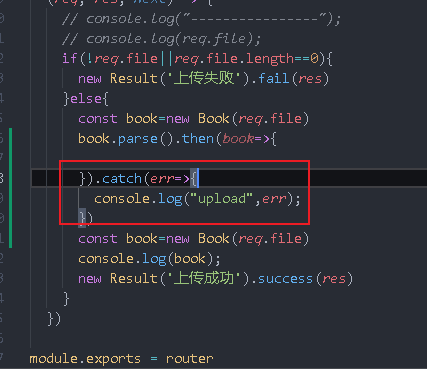
For verification, change the path casually
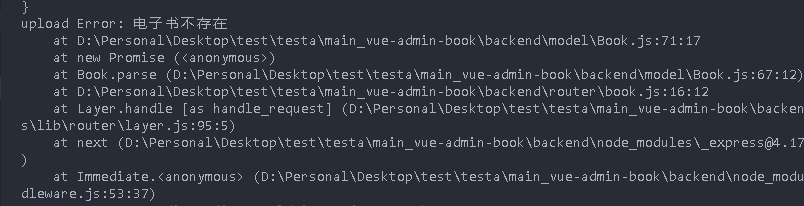
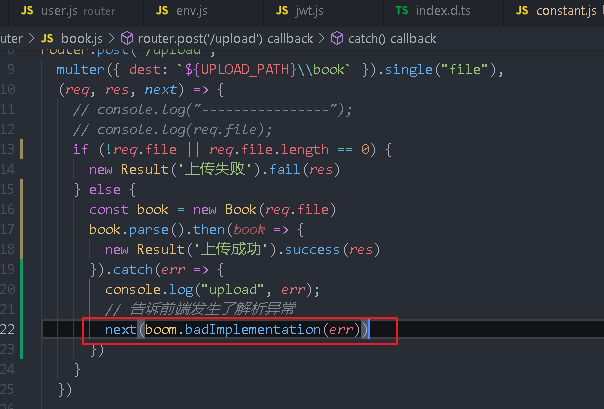
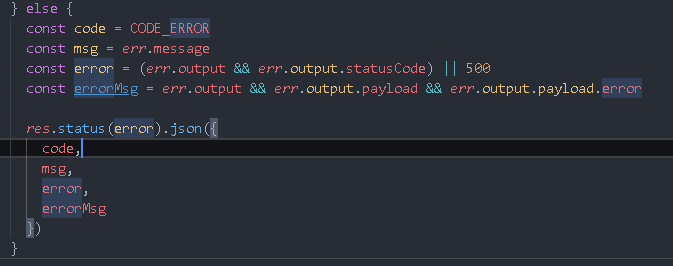
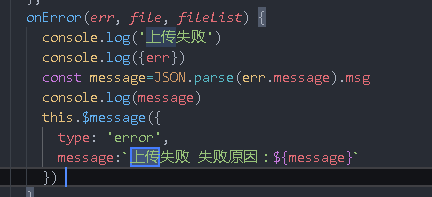
The front end is stuck here because there is no returned content. You can use boom to quickly generate exception objects
.catch(err => {
console.log("upload", err);
// Tell the front end that a parsing exception has occurred
next(boom.badImplementation(err))
})
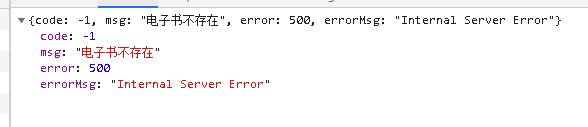
That is, the error wrapped with reject in the Book object will be returned to the next through the route, and then captured by the custom exception and returned to the front end. The front end will handle it accordingly, so that the exception thrown by the server can be caught by the front end

E-book analysis method
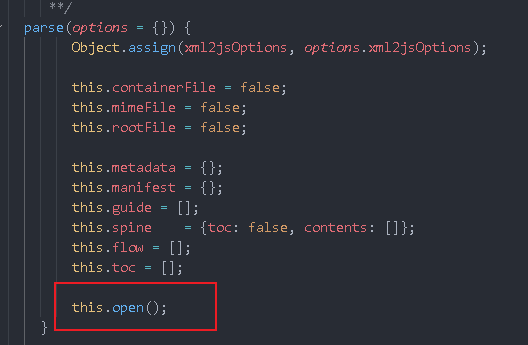
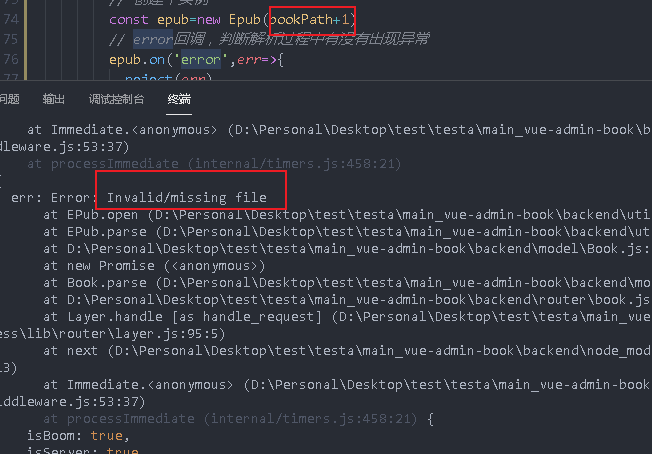
After seeing that the parse method is called, he will call an open method
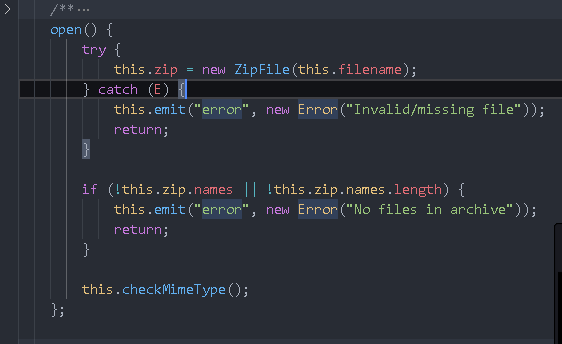
In model / book js:
consumption

After reject
Then you will go to custom exception handling
test

Change the bookPath back
Print it out ePub metadata

The information in the metadata needs to be parsed
Print book
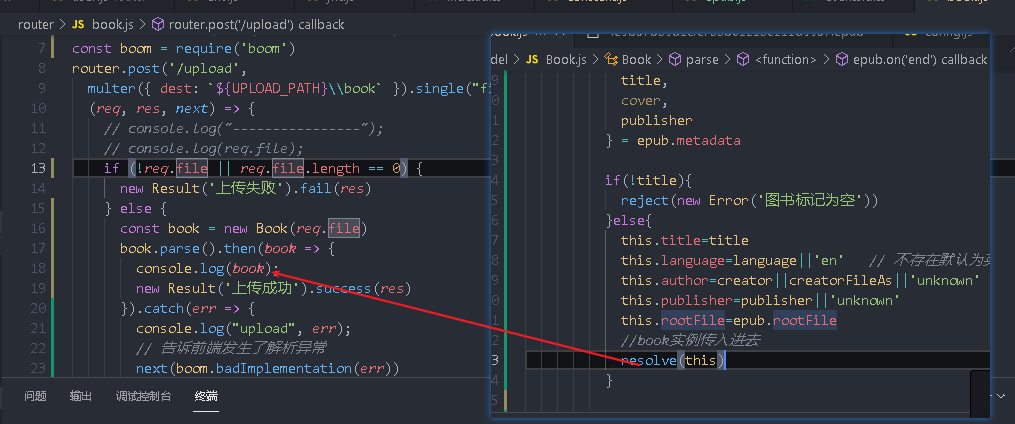
epub object:
containerFile: the first file parsed by epub. Find content based on this file opf
rootFile: content The location of OPF, because when reading e-books, you actually need to parse content opf
As long as you can find content OPF, then the later process will be easy
manifest: resource file you can find the cover image through the resource file
toc: Directory
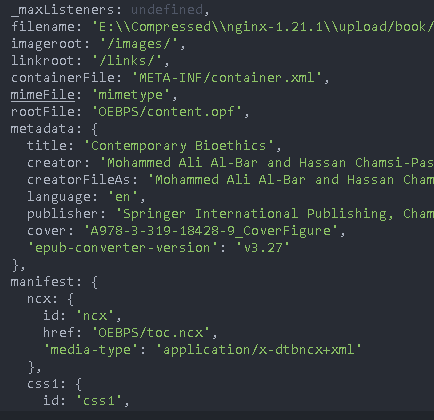
book object printing
Get cover page: getImage method provided by epub Library
This method needs to pass in two parameters, one is id and the other is callback
id is the id corresponding to the cover image
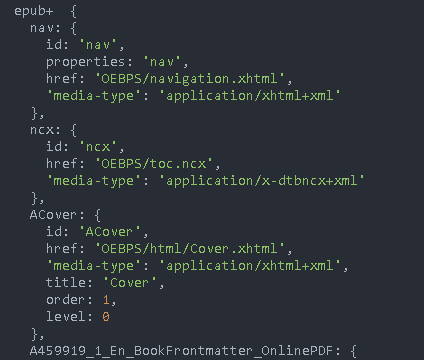
We just want to copy the pictures in the href to the img folder under the nginx directory. In this way, we can get the url link, which can be used as a link to the cover picture
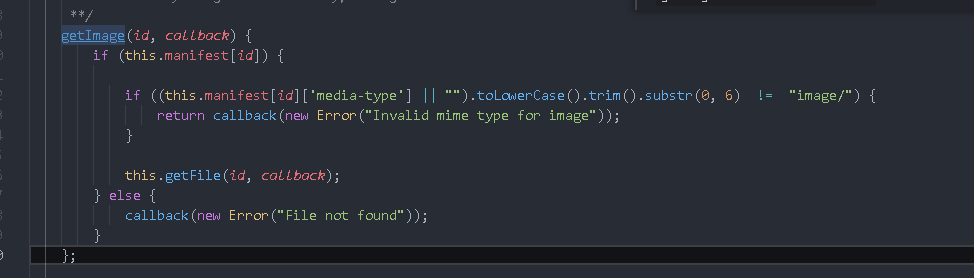
Analyze the source code of getImage method
getImage(id, callback) {
// Find link to manifest
if (this.manifest[id]) {
// If the media type exists, the first six characters will be intercepted and compared with image /. If they are not equal, an exception will be thrown and an error object will be passed in the callback
if ((this.manifest[id]['media-type'] || "").toLowerCase().trim().substr(0, 6) != "image/") {
return callback(new Error("Invalid mime type for image"));
}
// If it is an image, call getFile to pass in the id and callback
this.getFile(id, callback);
} else {
callback(new Error("File not found"));
}
};
Take a look at how getFile is implemented
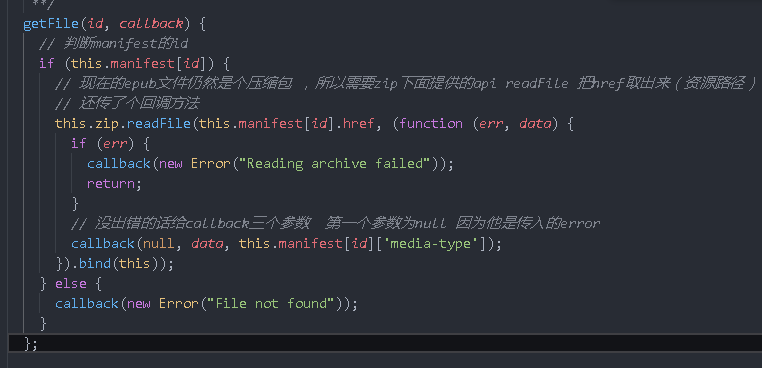
Let's use the getImage method to renovate the library then or async await is better. Here, use callback first
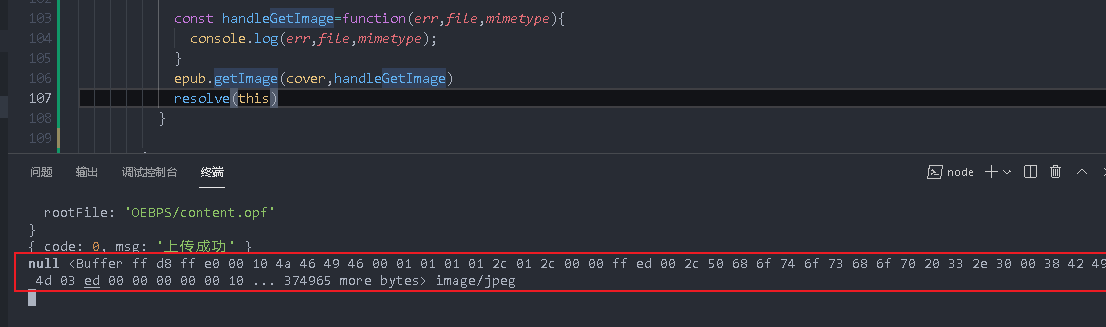
In this way, the data has been obtained (it has been read into the memory but not in the disk)
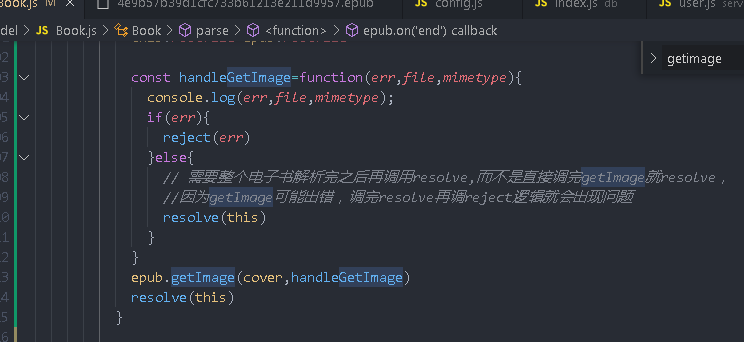
suffix is obtained according to mimetype
write file
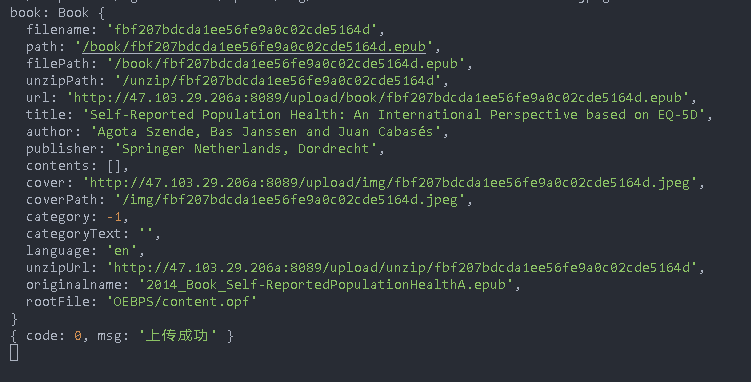
Punch in book JS code
const { MIME_TYPE_EPUB, UPLOAD_URL, UPLOAD_PATH } = require('../utils/constant')
const fs = require('fs')
const Epub = require('../utils/epub')
class Book {
constructor(file, data) {
if (file) {
this.createBookFromFile(file)
} else {
this.createBookFromData(data)
}
}
createBookFromFile(file) {
console.log("createBookFromFile", file);
const {
destination,
filename,
mimetype = MIME_TYPE_EPUB,
path,
originalname
} = file
// E-book file suffix
const suffix = mimetype === MIME_TYPE_EPUB ? '.epub' : ''
// Original path of e-book
const oldBookPath = path // Original path
// E-book new path
const bookPath = `${destination}/${filename}${suffix}` //New path
// Generate a file download path through which you can quickly download to the e-book
// Download URL of e-book
const url = `${UPLOAD_URL}/book/${filename}${suffix}`
// Generate an e-book decompression folder named after the file name
// Folder path after e-book decompression
const unzipPath = `${UPLOAD_PATH}/unzip/${filename}`
// This url path will be used when reading the e-book
// Folder URL after e-book decompression
const unzipUrl = `${UPLOAD_URL}/unzip/${filename}`
// If unzipPath does not exist, create it
if (!fs.existsSync(unzipPath)) {
// Iterate to create a folder if it does not exist
fs.mkdirSync(unzipPath, { recursive: true })
}
// Judge whether the current e-book exists. If it exists and the new e-book does not exist
// Call rename to rename the folder, and pass oldBookPath and bookPath to rename
if (fs.existsSync(oldBookPath)) {
fs.renameSync(oldBookPath, bookPath)
}
this.filename = filename // File name without suffix
// Write relative paths to be compatible with different scenarios, because the absolute paths of the server and the client are different
this.path = `/book/${filename}${suffix}` // epub file relative path
this.filePath = this.path // Create a relative path
this.unzipPath = `/unzip/${filename}` // Relative path after decompression
this.url = url // epub file download link
this.title = '' // Title or book title, generated after parsing
this.author = ''
this.publisher = '' // press
this.contents = [] // catalogue
this.cover = '' // Cover image url
this.coverPath=''
this.category = -1 // Classification id
this.categoryText = '' // Classification name
this.language = '' // languages
this.unzipUrl = unzipUrl // Unzipped folder link
this.originalname = originalname // Original name
}
createBookFromData() {
}
parse() {
return new Promise((resolve, reject) => {
const bookPath = `${UPLOAD_PATH}${this.filePath}`
// If there is no file path, an error is thrown
if (!fs.existsSync(bookPath)) {
reject(new Error('E-book does not exist'))
}
// Create an instance
const epub = new Epub(bookPath)
// error callback to judge whether there is any exception during parsing
epub.on('error', err => {
reject(err)
})
// The end event indicates that the e-book was successfully parsed
epub.on('end', err => {
if (err) {
reject(err)
} else {
// console.log("epub+ ", epub.manifest);
const {
language,
creator,
creatorFileAs,
title,
cover,
publisher
} = epub.metadata
if (!title) {
reject(new Error('Book tag is empty'))
} else {
this.title = title
this.language = language || 'en' // Does not exist. The default is English
this.author = creator || creatorFileAs || 'unknown'
this.publisher = publisher || 'unknown'
this.rootFile = epub.rootFile
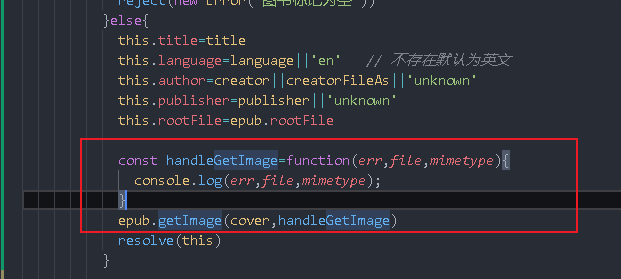
const handleGetImage = (err, file, mimetype) =>{
console.log(err, file, mimetype);
if (err) {
reject(err)
} else {
// You need to call resolve after the whole e-book is parsed, instead of directly calling getImage to resolve,
//Because getImage may have errors, there will be problems when you call the reject logic after you call resolve
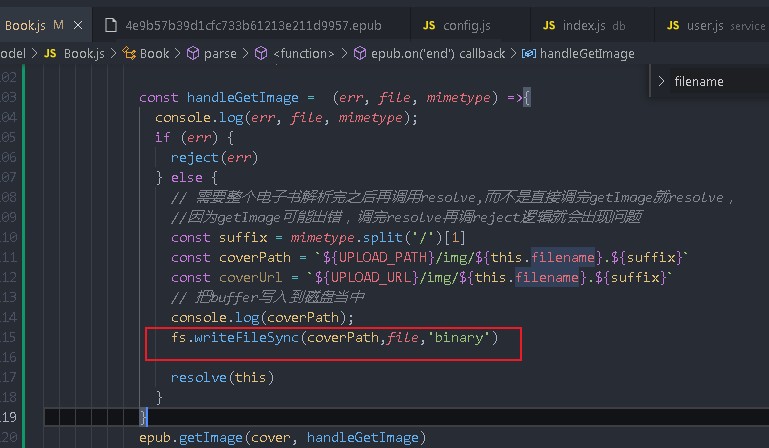
const suffix = mimetype.split('/')[1]
const coverPath = `${UPLOAD_PATH}/img/${this.filename}.${suffix}`
const coverUrl = `${UPLOAD_URL}/img/${this.filename}.${suffix}`
// Write buffer to disk
console.log(coverPath);
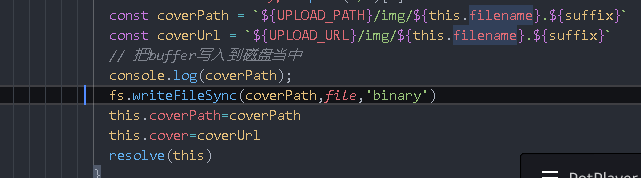
fs.writeFileSync(coverPath,file,'binary')
this.coverPath=`/img/${this.filename}.${suffix}`
this.cover=coverUrl
resolve(this)
}
}
epub.getImage(cover, handleGetImage)
// resolve(this) don't write here
}
}
})
epub.parse()
})
}
}
module.exports = Book
Analysis and optimization of cover image
Some e-books can't get the cover picture in this way
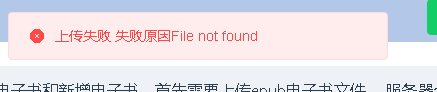
See where this error occurs
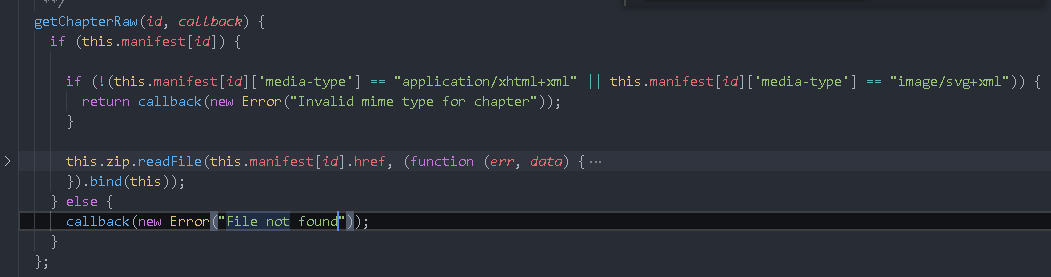
Print cover
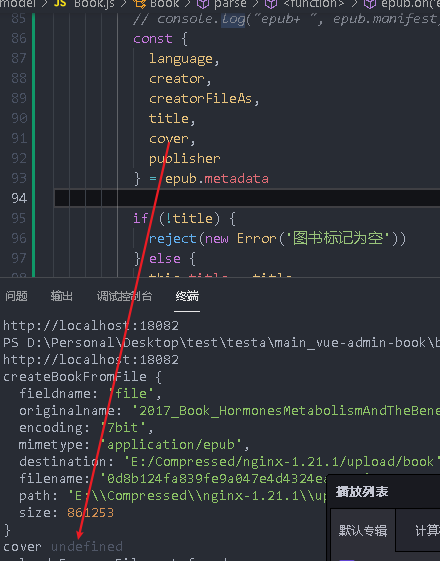
Extract it and analyze it
Open package opf
There is no label in the metadata. It is a description of cover. There is no way to obtain the resource id of the cover image
Look in the manifest
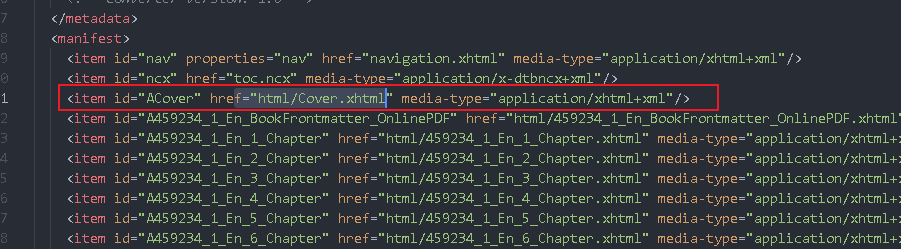
You can see the resource file of the cover, but it is of xhtml type, which indicates that it is the content of the chapter, not the picture. The picture should start with image
This is the cover picture
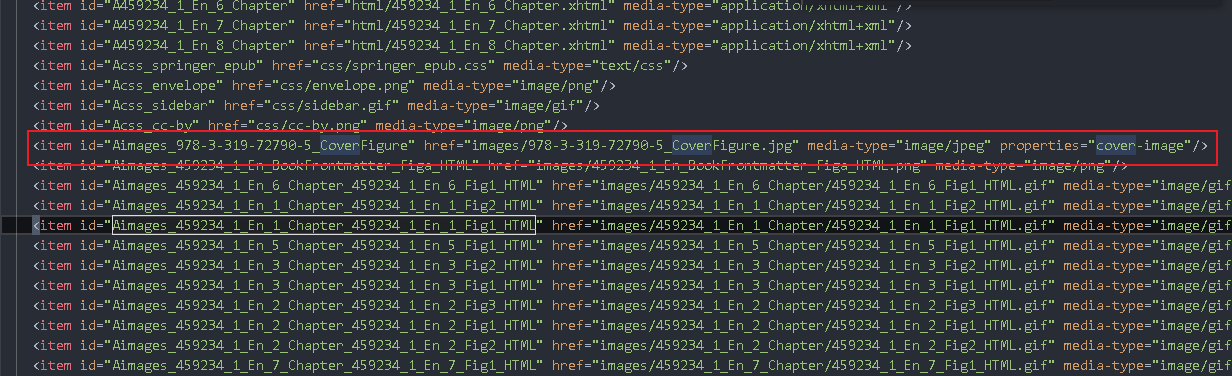
It is the file beginning with 978 in the image path
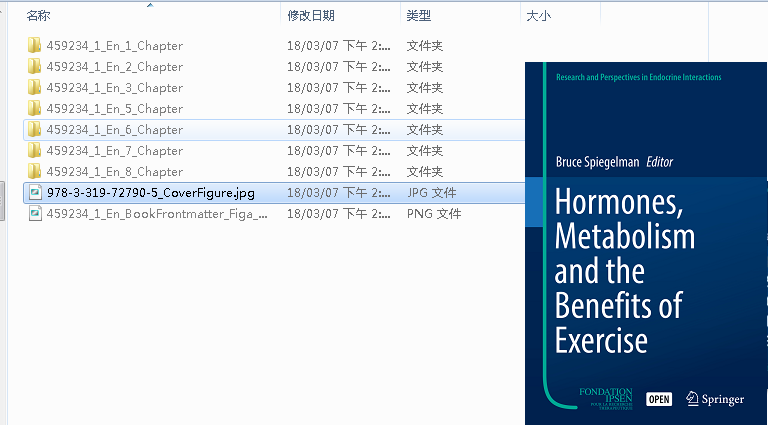
Therefore, another way to query the cover page is to read the properties under item. If cover image means the cover page image, you can get the href of the image, then find its resource file, extract it from epub and save it locally
EPub Transformation of getImage method of JS
If the manifest cannot be obtained from the cover, the logic here needs to be improved
Rough frame
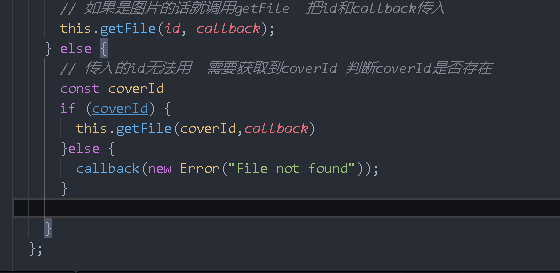
How to get coverId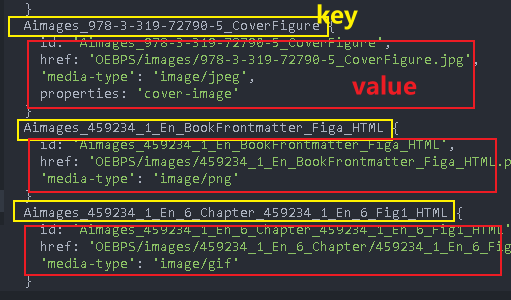
const coverId=Object.keys(this.manifest).find(key=>{ //Note that these are not curly braces
// console.log(key,this.manifest[key]);
this.manifest[key].properties==='cover-image'
})
getImage(id, callback) {
// Find link to manifest
if (this.manifest[id]) {
// If the media type exists, the first six characters will be intercepted and compared with image /. If they are not equal, an exception will be thrown and an error object will be passed in the callback
if ((this.manifest[id]['media-type'] || "").toLowerCase().trim().substr(0, 6) != "image/") {
return callback(new Error("Invalid mime type for image"));
}
// If it is an image, call getFile to pass in the id and callback
this.getFile(id, callback);
} else {
// The passed in id cannot be used to determine whether the coverId exists by obtaining the coverId
// This returns the qualified key
const coverId = Object.keys(this.manifest).find(key => (
// console.log(key,this.manifest[key]);
this.manifest[key].properties === 'cover-image'
))
console.log("coverId", coverId);
if (coverId) {
this.getFile(coverId, callback)
} else {
callback(new Error("File not found"));
}
}
};
Next, develop a more difficult point - parsing the e-book directory
The epub library does not provide a solution. Although the manifest directory has many resource files, it does not form an order. We need to determine the hierarchical relationship of the directory
Directory analysis principle and e-book decompression
Directory parsing principle
First, get the toc attribute (the resource id of the directory) from under the spin tag

Then find it in the manifest
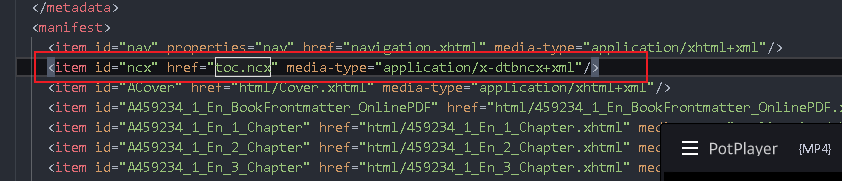
Open TOC ncx
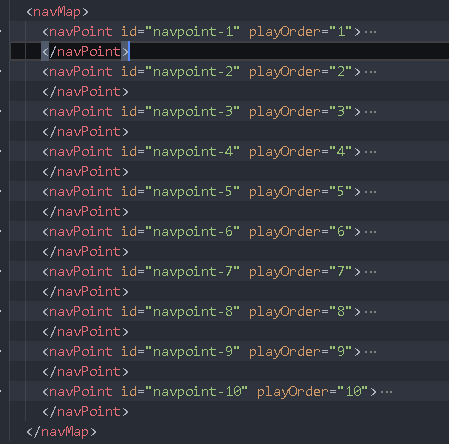
navMap: navigation
There are all directories inside. Directories may be nested
1. Extract the e-book file
Unzip it and put it in the unzip folder
Through the previous getFile method, we can directly obtain the e-book file, but we choose to decompress it first, so that the reading efficiency will be higher
Come to the Book class written by yourself,
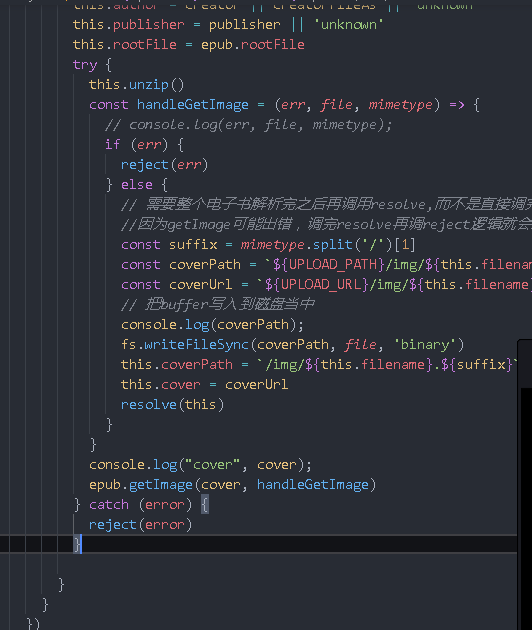
Write unzip method
unzip(){
const AdmZip=require('adm-zip')
const zip=new AdmZip(Book.genPath(this.path))
// The api extractAllTo() of the zip object means to decompress the files under the path,
// After decompression, put it under a new path. The second parameter is whether to overwrite it
zip.extractAllTo(Book.genPath(this.unzipPath),true)
}
// Generate a static method to obtain the absolute path
static genPath(path){
if(!path.startsWith('/')){
path=`/${path}`
}
return `${UPLOAD_PATH}${path}`
}
}
After extracting it, you can parse it
The unzip method is a synchronization method
After unzip, you can define a parseContents. Pass in the epub object because you need to go to the toc spin to find the toc attribute
parseContents(epub){
function getNcxFilePath(){
const spine=epub&&epub.spine
console.log("spine",spine);
}
getNcxFilePath()
}
Print out spin
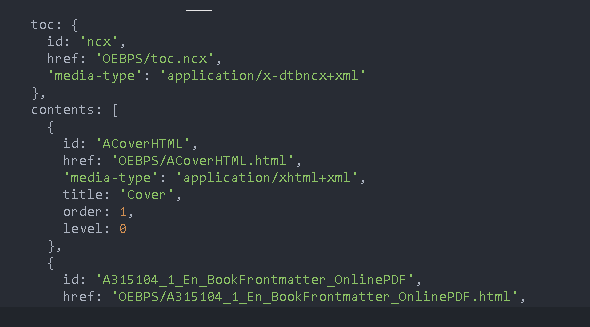
You can see that there is a toc attribute under the spine
You can find the id / corresponding to toc, or you can directly get the href
If you don't have a href, look for ID - > manifest
parseContents(epub){
function getNcxFilePath(){
const spine=epub&&epub.spine
const manifest=epub&&epub.manifest
const ncx=spine.toc&&spine.toc.href
const id=spine.toc&&spine.toc.id
console.log("spine", spine.toc,ncx,id,manifest[id].href);
if(ncx){
return ncx
}else{
// This must exist, because this is the directory of e-books
return manifest[id].href
}
}
getNcxFilePath()
}
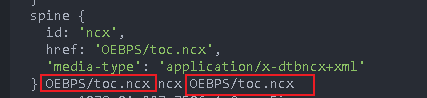
It can be found that both methods can get the directory
Then get the path
const ncxFilePath=getNcxFilePath()
This is a relative path. You need to spell it into an absolute path
const ncxFilePath=Book.genPath(getNcxFilePath())
This is still wrong. You need to add unzipPath
const ncxFilePath=Book.genPath(`${this.unzipPath}/${getNcxFilePath()}`)
console.log(ncxFilePath);
One more thing to do is to judge whether the path exists. If it does not exist, you need to throw an exception
if(fs.existsSync(ncxFilePath)){
}else{
throw new Error('The resource file corresponding to the directory does not exist')
}
catch here
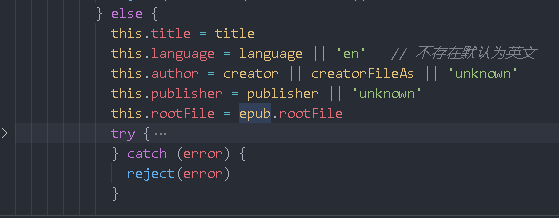
Eventually, the front end will get an error message
Try it
const ncxFilePath=Book.genPath(`${this.unzipPath}/${getNcxFilePath()+1}`)

E-book standard catalog analysis
Open TOC ncx
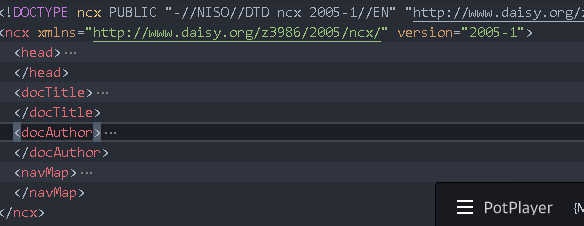
There is a navMap under the ncx object
Each navPoint under navMap is a directory option

navLabel: specific directory content
content: path of src directory, playOrder: Directory order
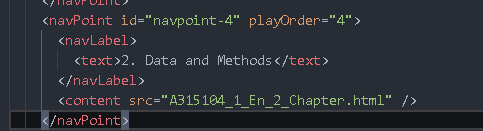
Directories may be nested, and we also need to identify secondary directories, so we need an iterative method to identify directories (difficulty)
Book.js first references the xml2js library
https://www.npmjs.com/package/xml2js
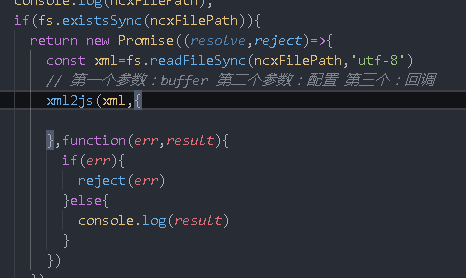
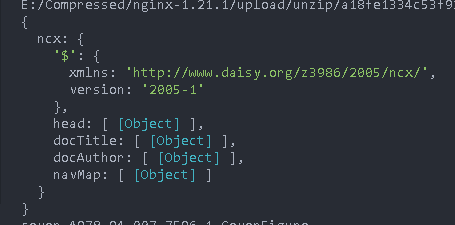
What we want to get is the navMap attribute under ncx
Print the navMap

Tip: look at the details
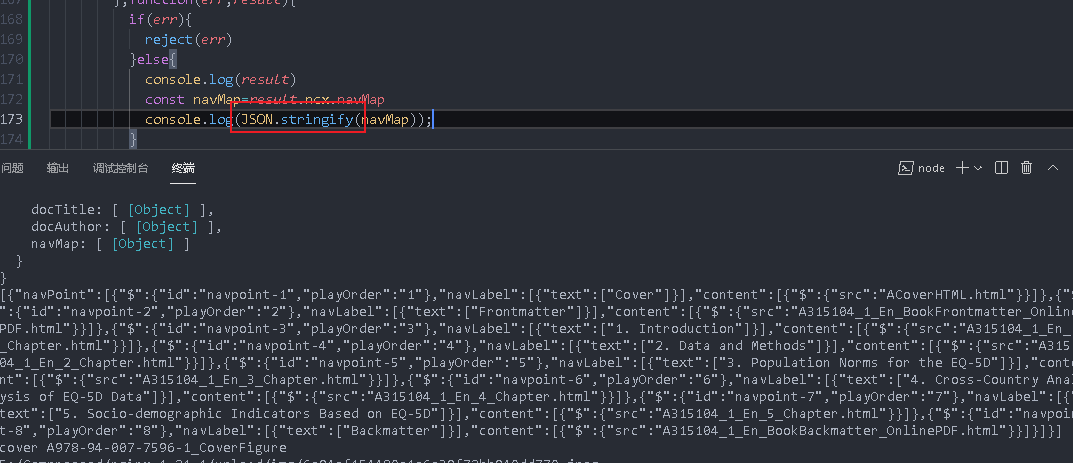
Paste string to JSON Cn inside


directory structure

The returned result is wrapped in an array. If you don't want to wrap it in the array, you can add a parameter,

xml2js(xml,{
explicitArray:false,
ignoreAttrs:false
},function(err,result){
if(err){
reject(err)
}else{
console.log(result)
const navMap=result.ncx.navMap
console.log(JSON.stringify(navMap));
}
})
Current structure

The findParent method is added because it is a single-level directory, so it returns the same array, which will be improved in the future
function findParent(array){
return array.map(item=>{
return item
})
}
If there are subdirectories, it is a tree structure, which is not conducive to the front-end display
Therefore, we need to change the tree structure into a one-dimensional structure. There is no such scenario yet, but we still need to build the method first
navMap.navPoint=findParent(avMap.navPoint) const newNavMap=flatten(navMap.navPoint)
newNavMap is a shallow copy of navMap
function findParent(array){
return array.map(item=>{
return item
})
}
function flatten(array){
return [].concat(...array.map(item=>{
return item
}))
}
newNavMap is an array copied
epub.flow: display order
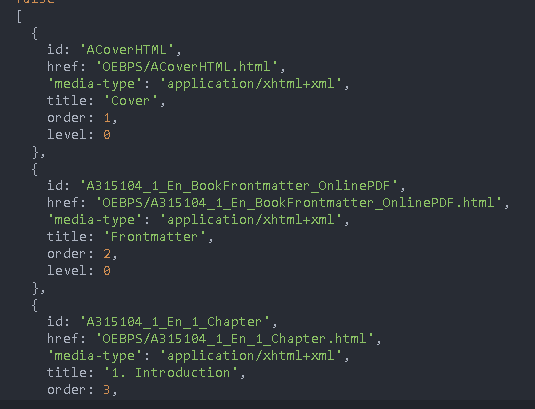
epub.flow.forEach((chapter,index)=>{
if(index+1>newNavMap.length){
// If the information in flow exceeds the directory information, return
return
}else{
// No more than
// Get directory information
const nav=newNavMap[index]
// Add an attribute (Chapter url)
chapter.text=`${UPLOAD_URL}/unzip/${fileName}/${chapter.href}`
console.log(chapter.text);
}
})
console.log(epub.flow);
}else{
reject('Directory resolution failed, directory tree is 0')
}


There's a problem. Just use ePub Can't flow
In fact, ePub Flow has some hidden pits
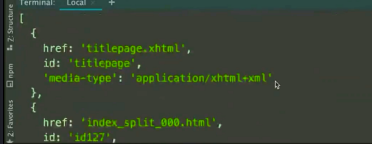
Some e-books do not have order and level, which is inaccurate
Therefore, get more authentic directory information from navMap
Continue adding attributes to the chapter
if (nav && nav.navLabel) {
chapter.label = nav.navLabel.text || ''
} else {
chapter.label = ''
}
chapter.navId=nav['$'].id
chapter.fileName=fileName
chapter.order=index+1
chapters.push(chapter)
console.log(chapter.text);
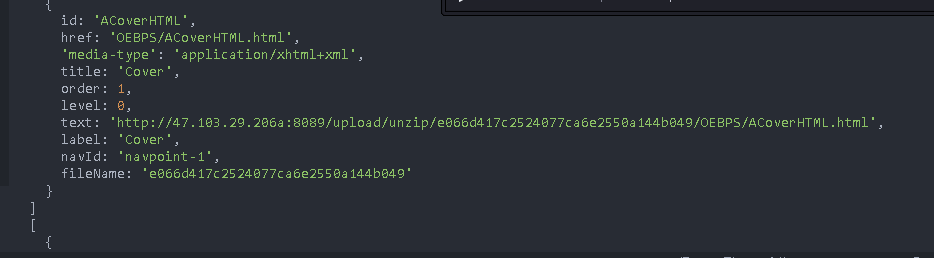
Nested directory resolution
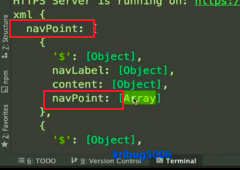
Do some articles in findParent
The default level is 0 and the next level is 1, so you can indent according to the level when returning to the front end
Pass in three parameters: array,level=0,pid=0
There is no level field in navPoint. You can add a level field to it
function findParent(array, level = 0, pid = '') {
// There are three scenarios: 1. navPoint is not included: direct complex value, level,pid
// 2: There is a navPoint, and the navPoint is an array. The description contains subdirectories for iteration
// 3: When navPoint is not an array but an object (only one directory), it is directly assigned
return array.map(item => {
item.level = level
item.pid = pid
// Indicates that a subdirectory exists
if (item.navPoint && item.navPoint.length) {
item.navPoint = findParent(item.navPoint, level + 1, item['$'].id)
} else if (item.navPoint) {
item.navPoint.level = level + 1
item.navPoint.pid = item['$'].id
}
return item
})
}
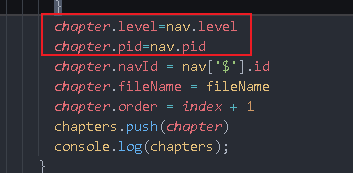
flatten method: change the navPoint array into a flat state
Cooperate here
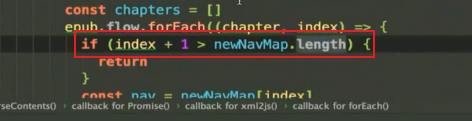
If it remains flat, the length of newNavMap must be less than index+1(flow)
flatten method
function flatten(array) {
return [].concat(...array.map(item => {
// If it contains an array
if(item.navPoint&&item.navPoint.length>0){
// merge
return [].concat(item,...flatten(item.navPoint))
}else if(item.navPoint){
// If it's an object
return [].concat(item,item.navPoint)
}
return item
}))
}
resolve reject
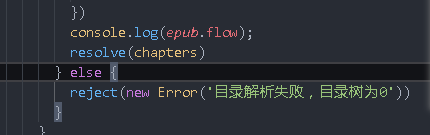
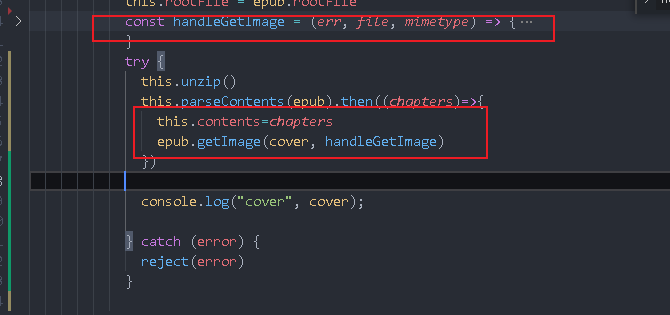
You can return the book to the front end
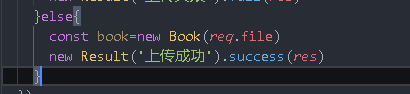
new Result(book 'upload succeeded') success(res)
