preface
The previous project was based on springboot and integrated spark, running on standalone. I once wrote a blog, link:
https://blog.csdn.net/qq_41587243/article/details/112918052?spm=1001.2014.3001.5501
The same scheme is used now, but spark is submitted on the production environment yarn cluster, and kerbores verification is required, as shown below.
background
According to the company's project requirements, an analytical platform is made through mobile phone signaling location data. Analyze based on the current online environment spark+hadoop+yarn. Data volume: 1 billion users.
spark on yarn problem summary
First of all, in the development process, the premise is to ensure the consistency of the version, otherwise there will be more problems!!
1, What's the difference between standalone and yarn
- To run in standalone mode, you only need to specify the url of setMaster as spark://172.31.13.100:7077 , there are various startup methods. java -jar, tomcat and spark submit can all be started.
- On the Yarn cluster, so you can only use spark submit to start. Spark Yarn client hosts the application jar. Otherwise, the application jar lacks a module to apply for resources from the Yarn resource manager and cannot be started normally.
As follows:
./spark-submit --conf spark.yarn.jars="/xxxx/spark/jars/*,hdfs://ns1:8020/xxxxx/lib/*" --driver-java-options "-Dorg.springframework.boot.logging.LoggingSystem=none -Dspring.profiles.active=test -Dspark.yarn.dist.files=/yarn-site.xml" -- master yarn --deploy-mode client --executor-cores 3 --num-executors 80 --executor-memory 12g --driver-memory 12g --name xxxxx_analysis --queue xxxxxxx --class org.springframework.boot.loader.JarLauncher ./com.xxx-1.0-SNAPSHOT.jar --principal xxxx --keytab xxx.keytab >> xxx.log 2>&1 &
Parameter interpretation:
--conf spark.yarn.jars Specifies some of the information needed to run the project jar Packet, first to hdfs Corresponding directory;
Spark Some required on the client jar Package, springboot Dependent jar package
--driver-java-options Specify the running environment parameters of the application.
--class Must specify springboot of main Where class
--master --deploy-mode appoint yarn of client end
--queue appoint hdaoop in yarn queue
--principal appoint kerberos User
--keytab appoint kerberos Bill
2, Log conflict
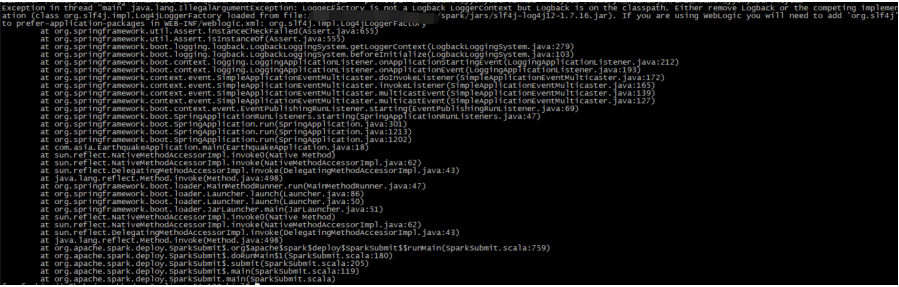
solve:
For log conflicts, spark submit internally uses log4j as the log module, and springboot uses logbak as the log module. There are two solutions: one is to delete the logback classic jar package in the exclusion of springbooe, and the other is to add - dorg. DLL directly when starting the running environment springframework. boot. logging. LoggingSystem=none.
3, GSON version conflict
The GSON version of Spark may conflict with the version that SpringBoot depends on, causing the following exceptions:
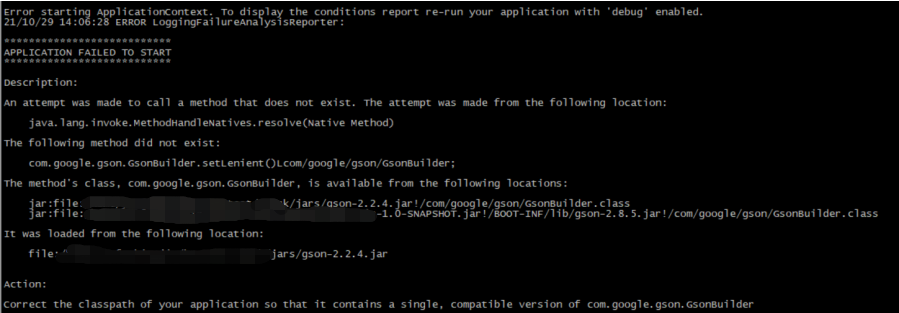
The obvious problem is that the jar packages conflict. The versions of the gson packages are different in the two locations. Just remove the gson version from the jars of spark.
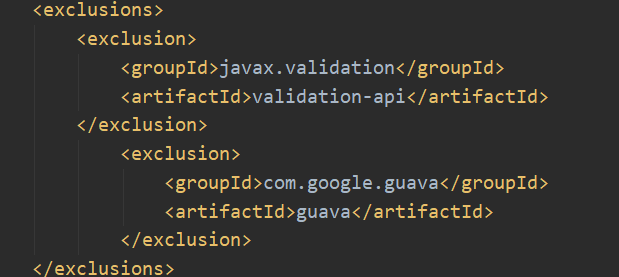
4, guava and validation API packages conflict
You can directly exclude everything involved in spring boot, including spark and Java EE API.
5, Serialization and deserialization problems
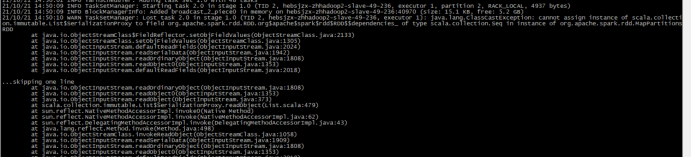
Just see the mistake and react, oh! Serialization, java uses javaserializer serialization, spark uses kyro serialization, and then modifies spark code to extend to inherit javaserializer, but it doesn't work. Baidu can't find it. It's bothered for several days. Finally, it's solved. Com.com under the target folder after packaging springboot asia-1.0-SNAPSHOT. jar. The original file is renamed com asia-api. Jar, this is the jar package of our own development program. Upload this jar to the path we specified in advance for hdfs project dependency. Solve it!!
6, The runtime cannot find a class in the app
1) Unzip the application jars and upload all jars in the Lib directory to the HDFS directory“ hdfs://xxx:8020/lib "
2)" hdfs://xxx:8020//lib "Append to the" spark.yarn.jars "parameter on the command line
3) Delete packages that may conflict with the cluster environment
The "spark.yarn.jars" parameter is not specified, resulting in the lack of dependent libraries in the executor node. The command line specifies the "spark.yarn.jars" parameter, adds all necessary library directories, and excludes hadoop *, spark *, scala * packages from the dependent packages on the springboot. This is also to prevent conflicts and add - calss
7, Conflict
This problem occurred in the local test. The package is missing, so it is added in the sub pom
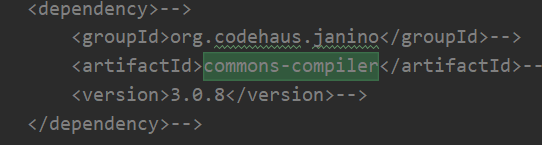
Now it is submitted to the cluster and conflicts with those in spark, so you can directly exclude them from your own project and remove them from the dependent jar s on the corresponding hdfs.
yarn resource release
In order to save yarn's resources, it is planned to automatically release resources after each application runs. There are two options:
First:
After each program is run, directly release sparkSession Close(), in the process of releasing, it also closes the sparkContext, so it no longer occupies yarn resources. After the next task is started, it will automatically start the spark task to apply for resources. sparkSession is not directly added to the springboot boot boot item, and the initial sparkSession is loaded before each task is run.
Second:
The sparkSession is not released directly, and dynamic resources are set. The maximum executors and minimum executors are used.
1.take spark.dynamicAllocation.enabled Set to true. It means to start the dynamic resource function; 2.In addition, there are the following parameters related to dynamic resource allocation 3.spark.dynamicAllocation.initialExecutors: initial executor Quantity, if--num-executors If the value set is greater than this value, the--num-executors Set the value as the initial value executor quantity 4.spark.dynamicAllocation.maxExecutors: executor The upper limit of quantity is unlimited by default. 5.spark.dynamicAllocation.minExecutors: executor The lower limit of quantity is 0 by default 6.spark.dynamicAllocation.cachedExecutorIdleTimeout: If executor Cache data in(cache data),And free N Seconds. be remove Should executor. The default value is unlimited. That is, if there is cached data, it will not remove Should executor Why? Like writing shuffle When the data, executor It may be written to disk or saved in memory. If saved in memory, the executor also remove If it is lost, the data will be lost.
--executor-memory 20g --executor-cores 5 --driver-memory 10g --driver-cores 5 \ --conf spark.dynamicAllocation.enabled=true \ --conf spark.shuffle.service.enabled=true \ --conf spark.dynamicAllocation.initialExecutors=20 \ --conf spark.dynamicAllocation.minExecutors=20 \ --conf spark.dynamicAllocation.maxExecutors=400 \ --conf spark.dynamicAllocation.executorIdleTimeout=300s \ --conf spark.dynamicAllocation.schedulerBacklogTimeout=10s \
hadoop token timeout problem
HDFS_DELEGATION_TOKEN token 13619910 for zh2_xxxx) can't be found in cache

First of all, the problem is that the keytab has an expiration time of 24 hours, so you can't directly introduce it into springboot to refresh the ticket regularly or refresh the ticket before use;
Secondly, this problem is the problem of connecting hadoop to judge whether the file exists, because the code loads hadoop tickets and establishes the connection when starting hadoop. This is obviously a timeout problem;
Solution: do not refresh the ticket regularly, because the sparkSession will be closed every time, so refresh the ticket every time before the program starts.
delegation token is actually a lightweight authentication method in hadoop as a supplement to kerberos authentication.
Detailed explanation: https://blog.csdn.net/qq_41587243/article/details/122255689
POM file dependency
<properties>
<java.version>1.8</java.version>
<druid.version>1.1.9</druid.version>
<mybatis.version>1.2.0</mybatis.version>
<spark.version>2.2.0</spark.version>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.8.2</hadoop.version>
<spring.boot.version>2.1.6.RELEASE</spring.boot.version>
<swagger.version>2.9.2</swagger.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<!-- Remove dependency on default logs -->
<!-- <exclusions>-->
<!-- <exclusion>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-logging</artifactId>-->
<!-- </exclusion>-->
<!-- </exclusions>-->
<exclusions>
<exclusion>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- introduce Druid Rely on the data source provided by Alibaba -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.version}</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.version}</version>
</dependency>
<!-- Use external tomcat -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
<version>${spring.boot.version}</version>
<!-- provided It indicates that the package is only used during compilation and testing, and the default is removed tomcat -->
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
<!-- <exclusions>-->
<!-- <exclusion>-->
<!-- <groupId>io.netty</groupId>-->
<!-- <artifactId>netty-all</artifactId>-->
<!-- </exclusion>-->
<!-- </exclusions>-->
<exclusions>
<exclusion>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
</exclusion>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.0.43.Final</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql_2.10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
<exclusion>
<groupId>org.codehaus.janino</groupId>
<artifactId>janino</artifactId>
</exclusion>
<exclusion>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.11</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Because we need to use Scala Code, so we need to add scala-library rely on -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
<version>${spring.boot.version}</version>
</dependency>
<!-- swagger -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>${swagger.version}</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>${swagger.version}</version>
</dependency>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-api</artifactId>
<version>8.0</version>
<exclusions>
<exclusion>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>commons-net</groupId>
<artifactId>commons-net</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
<!--Data Annotation dependency-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.10</version>
<scope>provided</scope>
</dependency>
<!-- postgresql -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.18</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<recompileMode>incremental</recompileMode>
<scalaVersion>${scala.version}</scalaVersion>
<launchers>
<launcher>
<id>app</id>
<mainClass>com.asia.xxxApplication</mainClass>
<args>
<arg>-deprecation</arg>
</args>
<jvmArgs>
<jvmArg>-Xms2056m</jvmArg>
<jvmArg>-Xmx4096m</jvmArg>
</jvmArgs>
</launcher>
</launchers>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<!--The following is packaging without dependency and only contains code-->
<configuration>
<includes>
<include>
<groupId>com.asia</groupId>
<artifactId>business</artifactId>
</include>
</includes>
</configuration>
</plugin>
</plugins>
</build>
These are some pits in the integration of springboot and spark in the project. Some small problems may be skipped. If there are problems, you can communicate! Welcome to leave a message
Later, I also tried to use the multi-threaded thread pool to submit cases of multiple job s, which can also shorten the analysis time and make full use of resources. I can share it when I have time!!