one of the main reasons for using shared memory is to cache the data on the chip, so as to reduce the number of global memory accesses in the kernel function. Next, the parallel reduction kernel function will be reused, and the shared memory will be used as the programmable management cache to reduce global memory accesses.
Reduction using shared memory
the following reduceGmem kernel function will be used as the starting point of benchmark performance. The implementation of parallel reduction only uses global memory, and the inner loop of input elements is fully expanded. The kernel functions are as follows:
__global__ void reduceGmem(int *g_idata,int *g_odata,unsigned int n)
{
unsigned int tid = threadIdx.x;
//Calculate the offset of the data block
int *idata = g_idata + blokcIdx.x * blockDim.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
if(idx >= n)
return;
//The kernel function performs an in place reduction using global memory. And reduce it to 32 elements
if(blockDim.x >= 1024 && tid < 512)
idata[tid] += idata[tid + 512];
__synthreads();
if(blockDim.x > 512 && tid < 256)
idata[tid] += idata[tid + 256];
__synthreads();
if(blockDim.x > 256 && tid < 128)
idata[tid] += idata[tid + 128];
__synthreads();
if(blockDim.x > 128 && tid < 64)
idata[tid] += idata[tid + 64];
__synthreads();
//The kernel function performs in place reduction, which uses only the first thread bundle of each thread block
//In the expanded part of the loop, the volatile modifier is used to ensure that only the latest value can be read when the thread bundle is executed in the lock step
if(tid < 32)
{
volatile int *vsmem = idata;
vsmem[tid] += vsmem[tid + 32];
vsmem[tid] += vsmem[tid + 16];
vsmem[tid] += vsmem[tid + 8];
vsmem[tid] += vsmem[tid + 4];
vsmem[tid] += vsmem[tid + 2];
vsmem[tid] += vsmem[tid + 1];
}
//Finally, the total number of input data blocks allocated to the thread block is written back to global memory
if(tid == 0)
g_odata[blockIdx.x] = idata[0];
}
next, test the following in-situ reduction kernel function reduceSmem, which adds global memory operations with shared memory. This kernel function is almost the same as the original reduceGmem kernel function. However, the reduceSmem function does not use the subset of input arrays in global memory to perform in-situ reduction, but uses the shared array smem.
//Using the following macro, set the block size to a constant 128 threads
#define DIM 128
__global__ void reduceSmem(int *g_idata,int *g_odata,unsigned int n)
{
//smem is declared to have the same dimension as each thread block.
__shared__ int smem[DIM];
unsigned int tid = threadIdx.x;
//Calculate the offset of the data block
int *idata = g_idata + blokcIdx.x * blockDim.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
if(idx >= n)
return;
smem[tid] = idata[tid];
__synthreads();
//The kernel function performs an in place reduction using global memory. And reduce it to 32 elements
if(blockDim.x >= 1024 && tid < 512)
smem[tid] += idata[tid + 512];
__synthreads();
if(blockDim.x > 512 && tid < 256)
smem[tid] += idata[tid + 256];
__synthreads();
if(blockDim.x > 256 && tid < 128)
smem[tid] += idata[tid + 128];
__synthreads();
if(blockDim.x > 128 && tid < 64)
smem[tid] += idata[tid + 64];
__synthreads();
//The kernel function performs in place reduction, which uses only the first thread bundle of each thread block
//In the expanded part of the loop, the volatile modifier is used to ensure that only the latest value can be read when the thread bundle is executed in the lock step
if(tid < 32)
{
volatile int *vsmem = smem;
vsmem[tid] += vsmem[tid + 32];
vsmem[tid] += vsmem[tid + 16];
vsmem[tid] += vsmem[tid + 8];
vsmem[tid] += vsmem[tid + 4];
vsmem[tid] += vsmem[tid + 2];
vsmem[tid] += vsmem[tid + 1];
}
//Finally, the total number of input data blocks allocated to the thread block is written back to global memory
if(tid == 0)
g_odata[blockIdx.x] = idata[0];
}
after testing, it can be found that using shared memory significantly reduces global memory access.
Parallel reduction using expansion
in the previous kernel function, each thread block processes a data block. Next, expand the thread block to improve the kernel performance. The following kernel expands four thread blocks, that is, each thread processes data elements from four data blocks. Through expansion, the following advantages can be obtained: 1 By providing more parallel I/O in each thread, the throughput of global memory is increased; 2. Global memory storage transactions are reduced by 1 / 4; 3. Improve the overall kernel performance. The specific kernel functions are as follows:
#define DIM 128
__global__ void reduceSmemUnroll(int *g_idata,int *g_odata,unsigned int n)
{
//smem is declared to have the same dimension as each thread block.
__shared__ int smem[DIM];
unsigned int tid = threadIdx.x;
//Calculate the offset of the data block
int *idata = g_idata + blokcIdx.x * blockDim.x;
unsigned int idx = blockIdx.x * blockDim.x * 4 + threadIdx.x;
int tmpSum = 0;
if(idx + 3 * blokcDim.x <= n)
{
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + blockDim.x * 2];
int a4 = g_idata[idx + blockDim.x * 3];
tmpSum = a1 + a2 + a3 + a4;
}
smem[tid] = tmpSum;
__synthreads();
//The kernel function performs an in place reduction using global memory. And reduce it to 32 elements
if(blockDim.x >= 1024 && tid < 512)
smem[tid] += idata[tid + 512];
__synthreads();
if(blockDim.x > 512 && tid < 256)
smem[tid] += idata[tid + 256];
__synthreads();
if(blockDim.x > 256 && tid < 128)
smem[tid] += idata[tid + 128];
__synthreads();
if(blockDim.x > 128 && tid < 64)
smem[tid] += idata[tid + 64];
__synthreads();
//The kernel function performs in place reduction, which uses only the first thread bundle of each thread block
//In the expanded part of the loop, the volatile modifier is used to ensure that only the latest value can be read when the thread bundle is executed in the lock step
if(tid < 32)
{
volatile int *vsmem = smem;
vsmem[tid] += vsmem[tid + 32];
vsmem[tid] += vsmem[tid + 16];
vsmem[tid] += vsmem[tid + 8];
vsmem[tid] += vsmem[tid + 4];
vsmem[tid] += vsmem[tid + 2];
vsmem[tid] += vsmem[tid + 1];
}
//Finally, the total number of input data blocks allocated to the thread block is written back to global memory
if(tid == 0)
g_odata[blockIdx.x] = idata[0];
}
Parallel reduction using dynamic shared memory
parallel reduction kernel functions can also be executed using dynamic shared memory. Through the following declaration, dynamic memory is used to replace static shared memory in reducesmemonroll: extern__ shared__ int smem[];
Effective bandwidth
since the reduced kernel functions are constrained by memory bandwidth, the appropriate performance index used in evaluating them is effective bandwidth. The effective bandwidth is the number of I / OS (in bytes) during the full execution time of the kernel function. For memory constrained applications, effective bandwidth is a good indicator of actual bandwidth utilization. It can be expressed as:
effective bandwidth = (read bytes + Write Bytes) ÷ (running time) × 109) GB/s
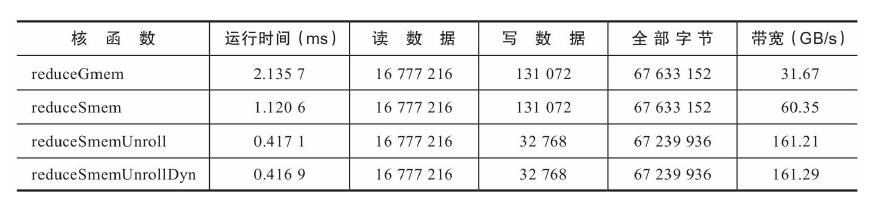
the following table summarizes the effective bandwidth achieved by each kernel function. Obviously, significant improvements in effective bandwidth can be obtained by expanding blocks. Doing so causes each thread to have multiple requests at run time, which results in high memory bus saturation.