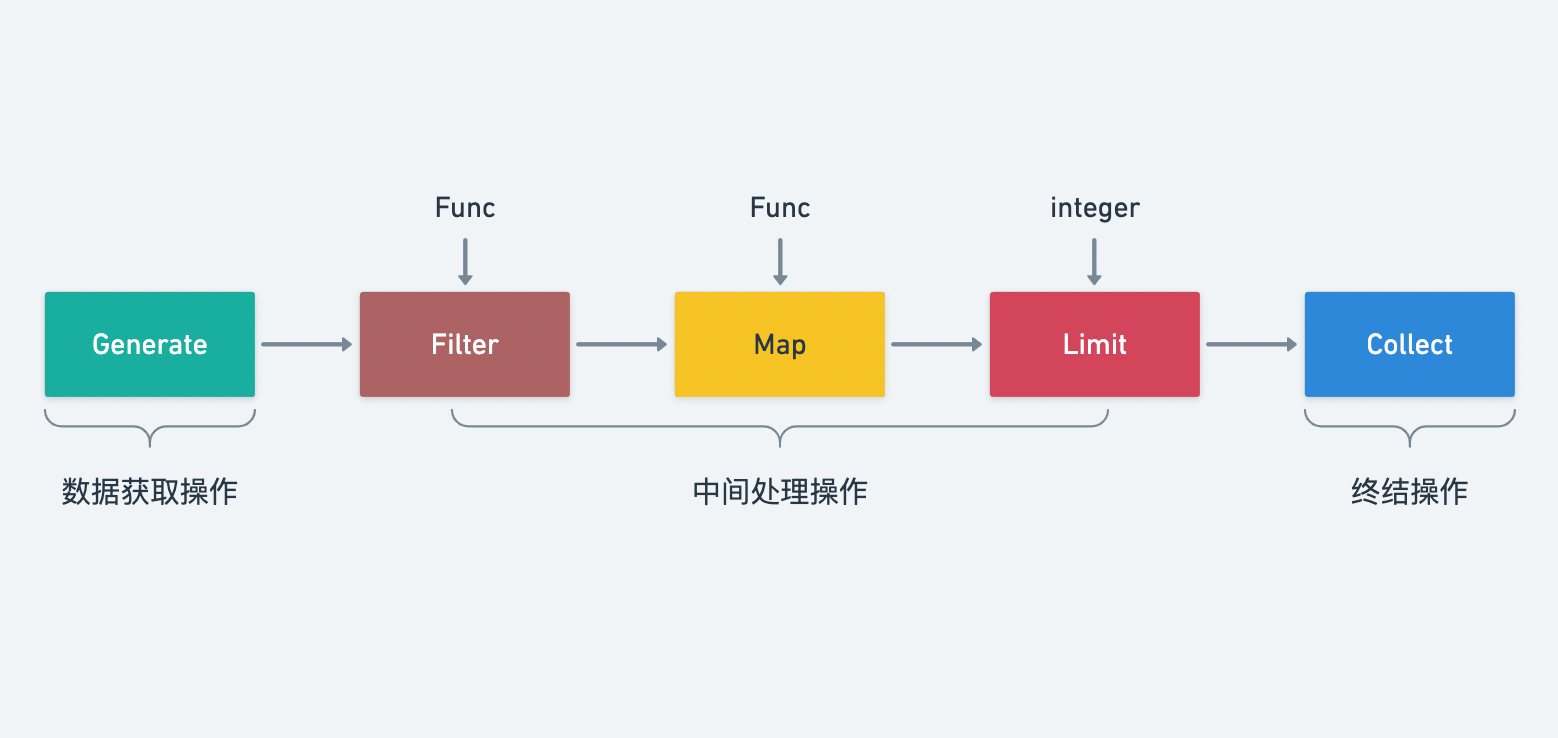
What is stream processing
If you have Java experience, you will be full of praise for java8 Stream, which greatly improves your ability to process collection type data.
int sum = widgets.stream()
.filter(w -> w.getColor() == RED)
.mapToInt(w -> w.getWeight())
.sum();Stream enables us to support the style of chain call and function programming to realize data processing. It seems that the data is continuously processed in real time like a pipeline and finally summarized. The implementation idea of stream is to abstract the data processing flow into a data flow, and return a new flow for use after each processing.
Stream function definition
Before writing code, think clearly. Clarifying the requirements is the most important step. We try to think about the implementation process of the whole component from the perspective of the author. First, put the logic of the underlying implementation, and try to define the stream function from scratch.
In fact, the workflow of Stream belongs to the production consumer model. The whole process is very similar to the production process in the factory. Try to define the life cycle of Stream first:
- Creation phase / data acquisition (raw material)
- Processing stage / intermediate processing (assembly line processing)
- Summary phase / end operation (final product)
The API is defined around the three life cycles of stream:
Creation phase
In order to create the abstract object of data stream, it can be understood as a constructor.
We support three ways to construct stream s: slice transformation, channel transformation and functional transformation.
Note that the methods at this stage are ordinary public methods and do not bind Stream objects.
// Create a stream with variable parameter mode
func Just(items ...interface{}) Stream
// Create a stream through channel
func Range(source <-chan interface{}) Stream
// Create stream through function
func From(generate GenerateFunc) Stream
// Splicing stream
func Concat(s Stream, others ...Stream) StreamProcessing stage
The operations required in the processing stage often correspond to our business logic, such as transformation, filtering, de duplication, sorting, etc.
The API at this stage belongs to method and needs to be bound to the Stream object.
The following definitions are made in combination with common business scenarios:
// Remove duplicate item s Distinct(keyFunc KeyFunc) Stream // Filter item s by criteria Filter(filterFunc FilterFunc, opts ...Option) Stream // grouping Group(fn KeyFunc) Stream // Return the first n elements Head(n int64) Stream // Return the last n elements Tail(n int64) Stream // Conversion object Map(fn MapFunc, opts ...Option) Stream // Merge item s into slice to generate a new stream Merge() Stream // reversal Reverse() Stream // sort Sort(fn LessFunc) Stream // Act on each item Walk(fn WalkFunc, opts ...Option) Stream // Aggregate other streams Concat(streams ...Stream) Stream
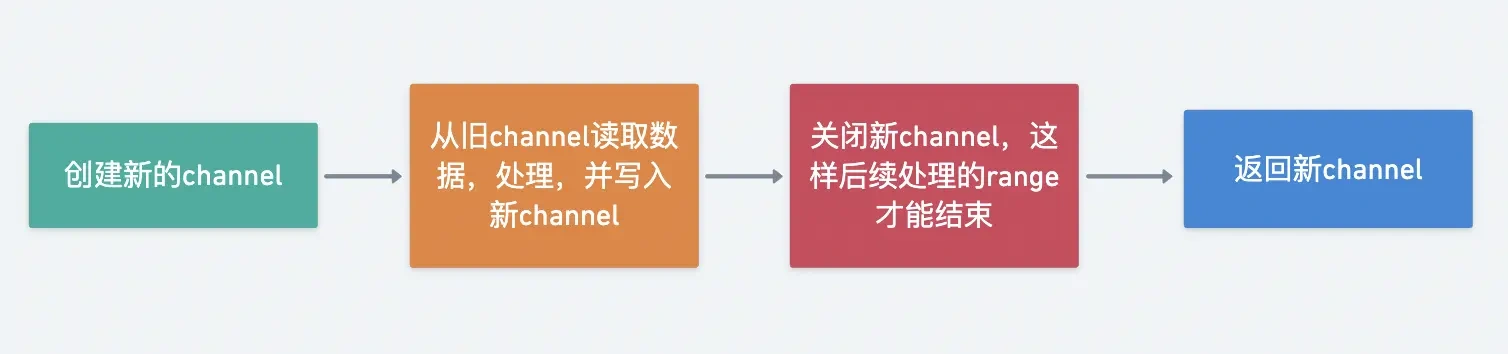
The processing logic in the processing stage will return a new Stream object. Here is a basic implementation paradigm
Summary stage
The summary stage is actually the processing result we want, such as whether it matches, counting quantity, traversal, etc.
// Check all matches AllMatch(fn PredicateFunc) bool // Check for at least one match AnyMatch(fn PredicateFunc) bool // Check for all mismatches NoneMatch(fn PredicateFunc) bool // Statistical quantity Count() int // Empty stream Done() // Perform operations on all elements ForAll(fn ForAllFunc) // Perform operations on each element ForEach(fn ForEachFunc)
After sorting out the requirements boundaries of components, we have a clearer understanding of the Stream to be implemented. In my opinion, real architects can grasp requirements and follow-up evolution with great accuracy, which is inseparable from in-depth thinking on requirements and insight into the essence behind requirements. By substituting the author's perspective to simulate the construction process of the whole project and learn the author's thinking methodology, this is the greatest value of learning open source projects.
Well, let's try to define a complete overview of the Stream interface and functions.
The function of the interface is not only a template, but also to use its abstract ability to build the overall framework of the project without falling into details at the beginning. It can quickly express our thinking process concisely through the interface, and learn to develop a top-down thinking method to observe the whole system from a macro perspective, If you get caught up in details at the beginning, it's easy to draw your sword and look around at your heart...
rxOptions struct {
unlimitedWorkers bool
workers int
}
Option func(opts *rxOptions)
// key generator
//Item - element in stream
KeyFunc func(item interface{}) interface{}
// Filter function
FilterFunc func(item interface{}) bool
// Object conversion function
MapFunc func(intem interface{}) interface{}
// Object comparison
LessFunc func(a, b interface{}) bool
// Ergodic function
WalkFunc func(item interface{}, pip chan<- interface{})
// Matching function
PredicateFunc func(item interface{}) bool
// Perform operations on all elements
ForAllFunc func(pip <-chan interface{})
// Perform an action on each item
ForEachFunc func(item interface{})
// Perform operations concurrently on each element
ParallelFunc func(item interface{})
// Aggregate all elements
ReduceFunc func(pip <-chan interface{}) (interface{}, error)
// item generating function
GenerateFunc func(source <-chan interface{})
Stream interface {
// Remove duplicate item s
Distinct(keyFunc KeyFunc) Stream
// Filter item s by criteria
Filter(filterFunc FilterFunc, opts ...Option) Stream
// grouping
Group(fn KeyFunc) Stream
// Return the first n elements
Head(n int64) Stream
// Return the last n elements
Tail(n int64) Stream
// Get the first element
First() interface{}
// Get the last element
Last() interface{}
// Conversion object
Map(fn MapFunc, opts ...Option) Stream
// Merge item s into slice to generate a new stream
Merge() Stream
// reversal
Reverse() Stream
// sort
Sort(fn LessFunc) Stream
// Act on each item
Walk(fn WalkFunc, opts ...Option) Stream
// Aggregate other streams
Concat(streams ...Stream) Stream
// Check all matches
AllMatch(fn PredicateFunc) bool
// Check for at least one match
AnyMatch(fn PredicateFunc) bool
// Check for all mismatches
NoneMatch(fn PredicateFunc) bool
// Statistical quantity
Count() int
// Empty stream
Done()
// Perform operations on all elements
ForAll(fn ForAllFunc)
// Perform operations on each element
ForEach(fn ForEachFunc)
}The channel() method is used to obtain the Stream pipeline attribute. Because we are facing the interface object in the concrete implementation, we expose a private method read.
// Get the internal data container channel and internal method
channel() chan interface{}Realization idea
After sorting out the function definition, we will consider several engineering implementation problems.
How to implement chain call
Chain call, the builder mode used to create objects can achieve the effect of chain call. In fact, the principle of Stream implementation similar to chain effect is the same. After each call, a new Stream is created and returned to the user.
// Remove duplicate item s Distinct(keyFunc KeyFunc) Stream // Filter item s by criteria Filter(filterFunc FilterFunc, opts ...Option) Stream
How to realize the processing effect of pipeline
The so-called pipeline can be understood as the storage container of data in the Stream. In go, we can use channel as the data pipeline to achieve the asynchronous and non blocking effect when the Stream chain call performs multiple operations.
How to support parallel processing
Data processing is essentially processing the data in the channel, so to realize parallel processing is nothing more than parallel consumption of the channel. Parallel processing can be realized very conveniently by using goroutine collaboration and WaitGroup mechanism.
Go zero implementation
core/fx/stream.go
The implementation of Stream in go zero does not define an interface, but it doesn't matter. The logic of the underlying implementation is the same.
In order to implement the Stream interface, we define an internal implementation class, where source is the channel type, simulating the pipeline function.
Stream struct {
source <-chan interface{}
}Create API
channel create Range
Create a stream through channel
func Range(source <-chan interface{}) Stream {
return Stream{
source: source,
}
}Variable parameter mode create Just
It is a good habit to create a stream through variable parameter mode and close the channel in time after writing.
func Just(items ...interface{}) Stream {
source := make(chan interface{}, len(items))
for _, item := range items {
source <- item
}
close(source)
return Range(source)
}Function to create From
Create a Stream through a function
func From(generate GenerateFunc) Stream {
source := make(chan interface{})
threading.GoSafe(func() {
defer close(source)
generate(source)
})
return Range(source)
}The execution process is not available because it involves the function parameter call passed in from the outside. Therefore, it is necessary to catch the runtime exception to prevent the panic error from being transmitted to the upper layer and causing the application to crash.
func Recover(cleanups ...func()) {
for _, cleanup := range cleanups {
cleanup()
}
if r := recover(); r != nil {
logx.ErrorStack(r)
}
}
func RunSafe(fn func()) {
defer rescue.Recover()
fn()
}
func GoSafe(fn func()) {
go RunSafe(fn)
}Splice Concat
Splice other streams to create a new Stream and call the internal Concat method method. The source code implementation of Concat will be analyzed later.
func Concat(s Stream, others ...Stream) Stream {
return s.Concat(others...)
}Processing API
De duplicate Distinct
Because the function parameter KeyFunc func(item interface{}) interface {} is passed in, it also supports custom de duplication according to business scenarios. In essence, it uses the results returned by KeyFunc to realize de duplication based on map.
Function parameters are very powerful and can greatly improve flexibility.
func (s Stream) Distinct(keyFunc KeyFunc) Stream {
source := make(chan interface{})
threading.GoSafe(func() {
// channel remember that closing is a good habit
defer close(source)
keys := make(map[interface{}]lang.PlaceholderType)
for item := range s.source {
// Custom de duplication logic
key := keyFunc(item)
// If the key does not exist, write the data to the new channel
if _, ok := keys[key]; !ok {
source <- item
keys[key] = lang.Placeholder
}
}
})
return Range(source)
}Use case:
// 1 2 3 4 5
Just(1, 2, 3, 3, 4, 5, 5).Distinct(func(item interface{}) interface{} {
return item
}).ForEach(func(item interface{}) {
t.Log(item)
})
// 1 2 3 4
Just(1, 2, 3, 3, 4, 5, 5).Distinct(func(item interface{}) interface{} {
uid := item.(int)
// Carry out special de duplication logic for items greater than 4, and finally only one item > 3 is retained
if uid > 3 {
return 4
}
return item
}).ForEach(func(item interface{}) {
t.Log(item)
})Filter
By abstracting the filtering logic into filterffunc, and then acting on item s respectively, it is determined whether to write back to the new channel to realize the filtering function according to the Boolean value returned by filterffunc. The actual filtering logic is entrusted to Walk method.
The Option parameter contains two options:
- Unlimited workers does not limit the number of processes
- workers limit the number of processes
FilterFunc func(item interface{}) bool
func (s Stream) Filter(filterFunc FilterFunc, opts ...Option) Stream {
return s.Walk(func(item interface{}, pip chan<- interface{}) {
if filterFunc(item) {
pip <- item
}
}, opts...)
}Use example:
func TestInternalStream_Filter(t *testing.T) {
// Keep even 2,4
channel := Just(1, 2, 3, 4, 5).Filter(func(item interface{}) bool {
return item.(int)%2 == 0
}).channel()
for item := range channel {
t.Log(item)
}
}Walk through execution
Walk means walk in English. It means to perform a WalkFunc operation on each item and write the result to a new Stream.
Note here that the data sequence in the channel in the new Stream is random because the internal co process mechanism is used to read and write data asynchronously.
// Item element in item stream
// If the pipe item meets the conditions, it is written to pipe
WalkFunc func(item interface{}, pipe chan<- interface{})
func (s Stream) Walk(fn WalkFunc, opts ...Option) Stream {
option := buildOptions(opts...)
if option.unlimitedWorkers {
return s.walkUnLimited(fn, option)
}
return s.walkLimited(fn, option)
}
func (s Stream) walkUnLimited(fn WalkFunc, option *rxOptions) Stream {
// Create a buffered channel
// The default value is 16. More than 16 elements in the channel will be blocked
pipe := make(chan interface{}, defaultWorkers)
go func() {
var wg sync.WaitGroup
for item := range s.source {
// All elements of s.source need to be read
// This also explains why the channel is finally written and remembered
// If it is not closed, the process may be blocked all the time, resulting in leakage
// Important, not assigning value to val is a typical concurrency trap, which is later used in another goroutine
val := item
wg.Add(1)
// Executing functions in safe mode
threading.GoSafe(func() {
defer wg.Done()
fn(item, pipe)
})
}
wg.Wait()
close(pipe)
}()
// Returns a new Stream
return Range(pipe)
}
func (s Stream) walkLimited(fn WalkFunc, option *rxOptions) Stream {
pipe := make(chan interface{}, option.workers)
go func() {
var wg sync.WaitGroup
// Number of control processes
pool := make(chan lang.PlaceholderType, option.workers)
for item := range s.source {
// Important, not assigning value to val is a typical concurrency trap, which is later used in another goroutine
val := item
// It will be blocked when the co process limit is exceeded
pool <- lang.Placeholder
// This also explains why the channel is finally written and remembered
// If it is not closed, the process may be blocked all the time, resulting in leakage
wg.Add(1)
// Executing functions in safe mode
threading.GoSafe(func() {
defer func() {
wg.Done()
//After the execution is completed, read the pool once and release one co process position
<-pool
}()
fn(item, pipe)
})
}
wg.Wait()
close(pipe)
}()
return Range(pipe)
}Use case:
The order of return is random.
func Test_Stream_Walk(t *testing.T) {
// Return 300100200
Just(1, 2, 3).Walk(func(item interface{}, pip chan<- interface{}) {
pip <- item.(int) * 100
}, WithWorkers(3)).ForEach(func(item interface{}) {
t.Log(item)
})
}Group group
Put the item into the map by matching it.
KeyFunc func(item interface{}) interface{}
func (s Stream) Group(fn KeyFunc) Stream {
groups := make(map[interface{}][]interface{})
for item := range s.source {
key := fn(item)
groups[key] = append(groups[key], item)
}
source := make(chan interface{})
go func() {
for _, group := range groups {
source <- group
}
close(source)
}()
return Range(source)
}Get the first n element heads
If n is greater than the actual data set length, all elements will be returned
func (s Stream) Head(n int64) Stream {
if n < 1 {
panic("n must be greather than 1")
}
source := make(chan interface{})
go func() {
for item := range s.source {
n--
// The n value may be greater than the length of s.source, so it is necessary to judge whether it is > = 0
if n >= 0 {
source <- item
}
// let successive method go ASAP even we have more items to skip
// why we don't just break the loop, because if break,
// this former goroutine will block forever, which will cause goroutine leak.
// n==0 indicates that the source is full and can be closed
// Now that the source has met the conditions, why not directly break out of the loop?
// The author mentioned the prevention of collaborative process leakage
// Because each operation will eventually produce a new Stream, and the old Stream will never be called
if n == 0 {
close(source)
break
}
}
// The above loop jumps out, indicating that n is greater than the actual length of s.source
// You still need to display and close the new source
if n > 0 {
close(source)
}
}()
return Range(source)
}Use example:
// Return 1,2
func TestInternalStream_Head(t *testing.T) {
channel := Just(1, 2, 3, 4, 5).Head(2).channel()
for item := range channel {
t.Log(item)
}
}Get the last n elements Tail
It's interesting here. In order to get the last n elements and use the Ring slice Ring data structure, let's first understand the implementation of Ring.
// Circular slice
type Ring struct {
elements []interface{}
index int
lock sync.Mutex
}
func NewRing(n int) *Ring {
if n < 1 {
panic("n should be greather than 0")
}
return &Ring{
elements: make([]interface{}, n),
}
}
// Add element
func (r *Ring) Add(v interface{}) {
r.lock.Lock()
defer r.lock.Unlock()
// Writes the element to the specified location of the slice
// The remainder here realizes the circular write effect
r.elements[r.index%len(r.elements)] = v
// Update next write location
r.index++
}
// Get all elements
// The read order is consistent with the write order
func (r *Ring) Take() []interface{} {
r.lock.Lock()
defer r.lock.Unlock()
var size int
var start int
// When circular write occurs
// The start reading position needs to be realized through residual removal, because we want the read order to be consistent with the write order
if r.index > len(r.elements) {
size = len(r.elements)
// Because of circular write, the current write position index starts to be the oldest data
start = r.index % len(r.elements)
} else {
size = r.index
}
elements := make([]interface{}, size)
for i := 0; i < size; i++ {
// The remainder is used to realize ring reading, and the reading order is consistent with the writing order
elements[i] = r.elements[(start+i)%len(r.elements)]
}
return elements
}Summarize the advantages of circular slicing:
- Support automatic rolling update
- Save memory
Ring slicing can realize that when the fixed capacity is full, the old data is constantly covered by new data. Because of this feature, it can be used to read the last n elements of the channel.
func (s Stream) Tail(n int64) Stream {
if n < 1 {
panic("n must be greather than 1")
}
source := make(chan interface{})
go func() {
ring := collection.NewRing(int(n))
// Read all elements. If the number is > N, the ring slice can realize the new data to overwrite the old data
// Ensure the last n elements obtained
for item := range s.source {
ring.Add(item)
}
for _, item := range ring.Take() {
source <- item
}
close(source)
}()
return Range(source)
}So why not use len(source) length slices directly?
The answer is to save memory. When it comes to ring type data structures, it has an advantage that it saves memory and can allocate resources on demand.
Use example:
func TestInternalStream_Tail(t *testing.T) {
// 4,5
channel := Just(1, 2, 3, 4, 5).Tail(2).channel()
for item := range channel {
t.Log(item)
}
// 1,2,3,4,5
channel2 := Just(1, 2, 3, 4, 5).Tail(6).channel()
for item := range channel2 {
t.Log(item)
}
}Element conversion Map
For element conversion, the internal coprocessor completes the conversion operation. Note that the output channel does not guarantee the output in the original order.
MapFunc func(intem interface{}) interface{}
func (s Stream) Map(fn MapFunc, opts ...Option) Stream {
return s.Walk(func(item interface{}, pip chan<- interface{}) {
pip <- fn(item)
}, opts...)
}Use example:
func TestInternalStream_Map(t *testing.T) {
channel := Just(1, 2, 3, 4, 5, 2, 2, 2, 2, 2, 2).Map(func(item interface{}) interface{} {
return item.(int) * 10
}).channel()
for item := range channel {
t.Log(item)
}
}Merge
The implementation is relatively simple. I've thought about it for a long time. I didn't expect any scenario suitable for this method.
func (s Stream) Merge() Stream {
var items []interface{}
for item := range s.source {
items = append(items, item)
}
source := make(chan interface{}, 1)
source <- items
return Range(source)
}Reverse
Inverts the elements in the channel. The inversion algorithm flow is:
Find intermediate node
The two sides of the node start switching
Note why the slice is used to receive s.source? The slice will expand automatically. Isn't it better to use an array?
In fact, you can't use arrays here, because you don't know that the operation of writing from Stream to source is often written asynchronously in the process, and the channel s in each Stream may change dynamically. It's very vivid to use pipeline to compare the workflow of Stream.
func (s Stream) Reverse() Stream {
var items []interface{}
for item := range s.source {
items = append(items, item)
}
for i := len(items)/2 - 1; i >= 0; i-- {
opp := len(items) - 1 - i
items[i], items[opp] = items[opp], items[i]
}
return Just(items...)
}Use example:
func TestInternalStream_Reverse(t *testing.T) {
channel := Just(1, 2, 3, 4, 5).Reverse().channel()
for item := range channel {
t.Log(item)
}
}Sort sort
The Intranet can call the sorting scheme of slice official package and pass in the comparison function to realize the comparison logic.
func (s Stream) Sort(fn LessFunc) Stream {
var items []interface{}
for item := range s.source {
items = append(items, item)
}
sort.Slice(items, func(i, j int) bool {
return fn(i, j)
})
return Just(items...)
}Use example:
// 5,4,3,2,1
func TestInternalStream_Sort(t *testing.T) {
channel := Just(1, 2, 3, 4, 5).Sort(func(a, b interface{}) bool {
return a.(int) > b.(int)
}).channel()
for item := range channel {
t.Log(item)
}
}Splice Concat
func (s Stream) Concat(steams ...Stream) Stream {
// Create a new unbuffered channel
source := make(chan interface{})
go func() {
// Create a waiGroup object
group := threading.NewRoutineGroup()
// Read data from the original channel asynchronously
group.Run(func() {
for item := range s.source {
source <- item
}
})
// Asynchronously read the channel data of the Stream to be spliced
for _, stream := range steams {
// Each Stream starts a collaboration
group.Run(func() {
for item := range stream.channel() {
source <- item
}
})
}
// Blocking waiting for read to complete
group.Wait()
close(source)
}()
// Returns a new Stream
return Range(source)
}Summary API
Match all AllMatch
func (s Stream) AllMatch(fn PredicateFunc) bool {
for item := range s.source {
if !fn(item) {
// The s.source needs to be emptied, otherwise the goroutine in front may be blocked
go drain(s.source)
return false
}
}
return true
}Any match AnyMatch
func (s Stream) AnyMatch(fn PredicateFunc) bool {
for item := range s.source {
if fn(item) {
// The s.source needs to be emptied, otherwise the goroutine in front may be blocked
go drain(s.source)
return true
}
}
return false
}None of them match NoneMatch
func (s Stream) NoneMatch(fn func(item interface{}) bool) bool {
for item := range s.source {
if fn(item) {
// The s.source needs to be emptied, otherwise the goroutine in front may be blocked
go drain(s.source)
return false
}
}
return true
}Quantity statistics Count
func (s Stream) Count() int {
var count int
for range s.source {
count++
}
return count
}Empty Done
func (s Stream) Done() {
// Drain the channel to prevent goroutine blocking and leakage
drain(s.source)
}Iterate all elements ForAll
func (s Stream) ForAll(fn ForAllFunc) {
fn(s.source)
}Iterate each element ForEach
func (s Stream) ForAll(fn ForAllFunc) {
fn(s.source)
}Summary
So far, all the Stream components have been implemented. The core logic is to use the channel as the pipeline and the data as the water flow, and constantly receive / write data to the channel with the collaborative process to achieve the effect of asynchronous and non blocking.
Back to the problem mentioned at the beginning, it seems very difficult to implement a stream before you start. It's hard to imagine that such a powerful component can be implemented in more than 300 lines of code in go.
Three language features are the basic sources for achieving efficiency:
- channel
- Synergetic process
- Functional programming
reference material
Project address
Welcome to go zero and star support us!
Wechat communication group
Focus on the "micro service practice" official account and click on the exchange group to get the community community's two-dimensional code.