1 cluster
1.1 concept of cluster
-
Today, with the development of the Internet, the magnitude of data is also growing exponentially, from GB to TB to PB. It is more and more difficult to operate the data. The traditional relational database can not meet the needs of fast query and data insertion. One database server can not meet the storage needs of massive data, so the database cluster composed of multiple databases has become an inevitable way. However, in order to ensure data consistency and query efficiency, it is also necessary to solve the problems of communication and load balancing among multiple servers.
-
MYCAT is a database clustering software. It is a well-known open source product of Alibaba Cobar. In short, MYCAT is a novel database middleware product that supports MySQL clusters and provides high availability data fragmentation clusters. You can use MYCAT like mysql. For developers, there is no sense of MYCAT. MYCAT not only supports mysql, but also common relational databases Oracle and SqlServer.
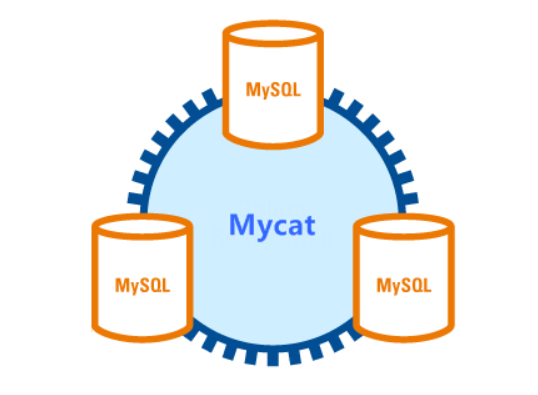
1.2 principle of cluster
- Let's take an example, looking for a needle in a haystack and looking for a needle in a water bottle. There is no doubt that the needle can be found faster in a water bottle because it needs a smaller search range. This is also the principle of database cluster. We can divide a database with a data volume of 300G into three parts on average. Only 100G data is stored in each database. At this time, the user searches through our intermediate agent layer. The intermediate agent layer sends three requests to execute the query at the same time. For example, the first platform returns 100 data, which takes 3 seconds, and the second platform returns 200 data, which takes 3 seconds, The third machine returns 500 pieces of data, which takes 3 seconds. At this time, the middleware only needs to filter 800 records to retrieve the results required by the user. At this time, the total time is only 3 seconds, because each machine performs operations at the same time. If we directly query the 300G database at this time, which takes 10 seconds, the efficiency of clustering using middleware is very obvious
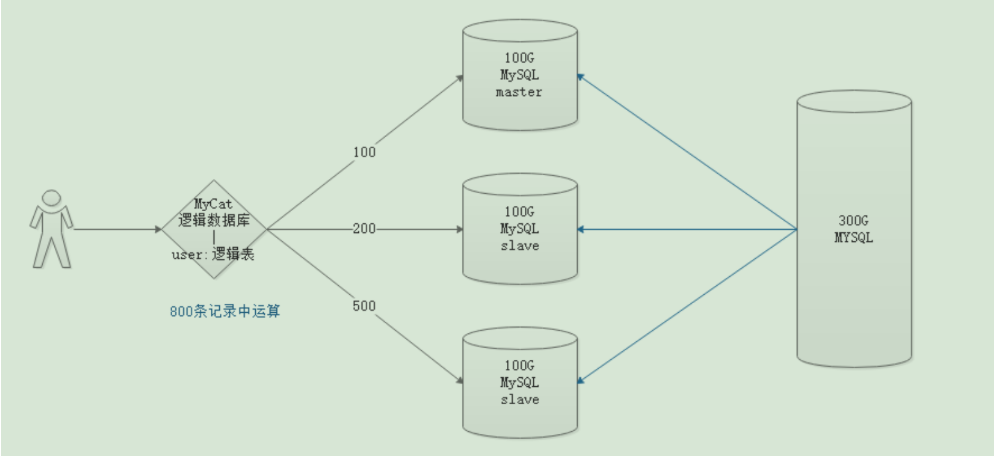
- The implementation process of MyCat is roughly similar to this process. MyCat itself does not store data, but users can directly connect to MyCat every time they link to the database Therefore, MyCat itself is actually a logical database. It also has a table structure, which is called a logical table.
2. MYCAT environment construction
2.1 Mycat download and installation
- Official website: http://www.mycat.io/
- Download address: http://dl.mycat.io/
- Select version 1.6.7.1, download it to disk D, and install the package as shown below:

- Upload: use SFTP command of SecureCRT to send files to root directory of Linux virtual machine:
sftp> put D:\Mycat-server-1.6.7.1-release-20190627191042-linux.tar.gz
- Unzip: unzip MYCAT tar. GZ and view
tar -zxvf mycat.tar.gz cd mycat ll
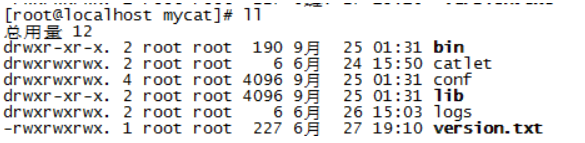
- Authorization: set mycat permissions
chmod -R 777 mycat
- Environment variables: configuring environment variables
vi /etc/profile // add to export MYCAT_HOME=/root/mycat // Make environment variables effective source /etc/profile
- Start mycat
// Enter the bin directory [root@localhost]# cd /root/mycat/bin // Execute start command [root@localhost bin]# ./mycat start
-
View: check the port listening status. The port number of Mycat is 8066
[root@localhost bin]# netstat -ant|grep 8066

- Connect: use SQLYog to connect Mycat
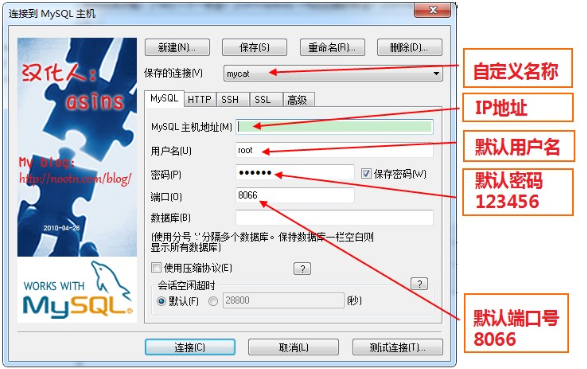
- Display after connection:
2.2 environmental preparation
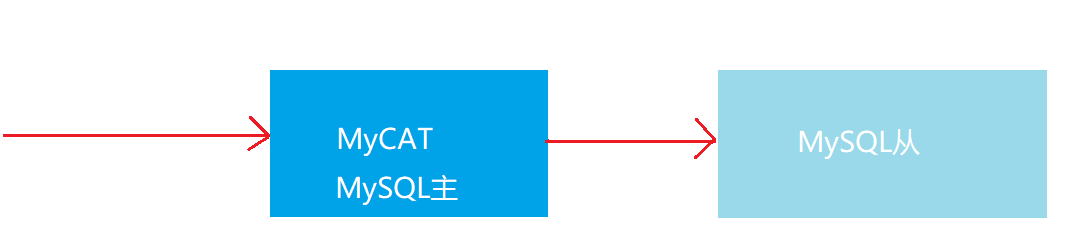
- Configuration model
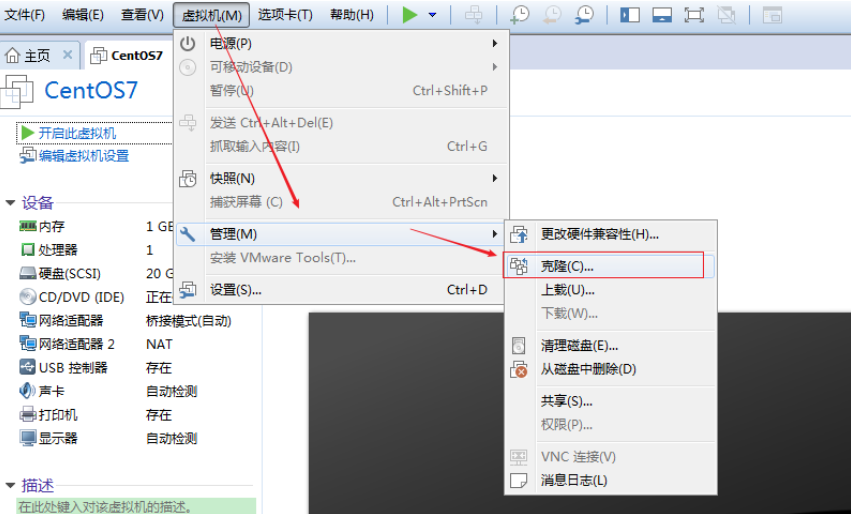
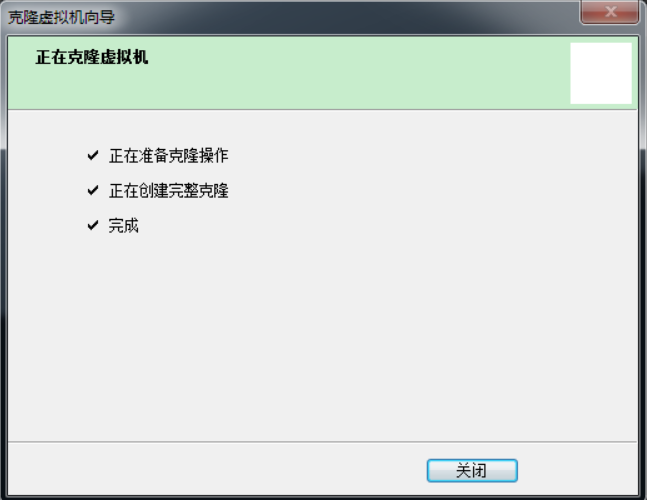
- Clone virtual machine
-
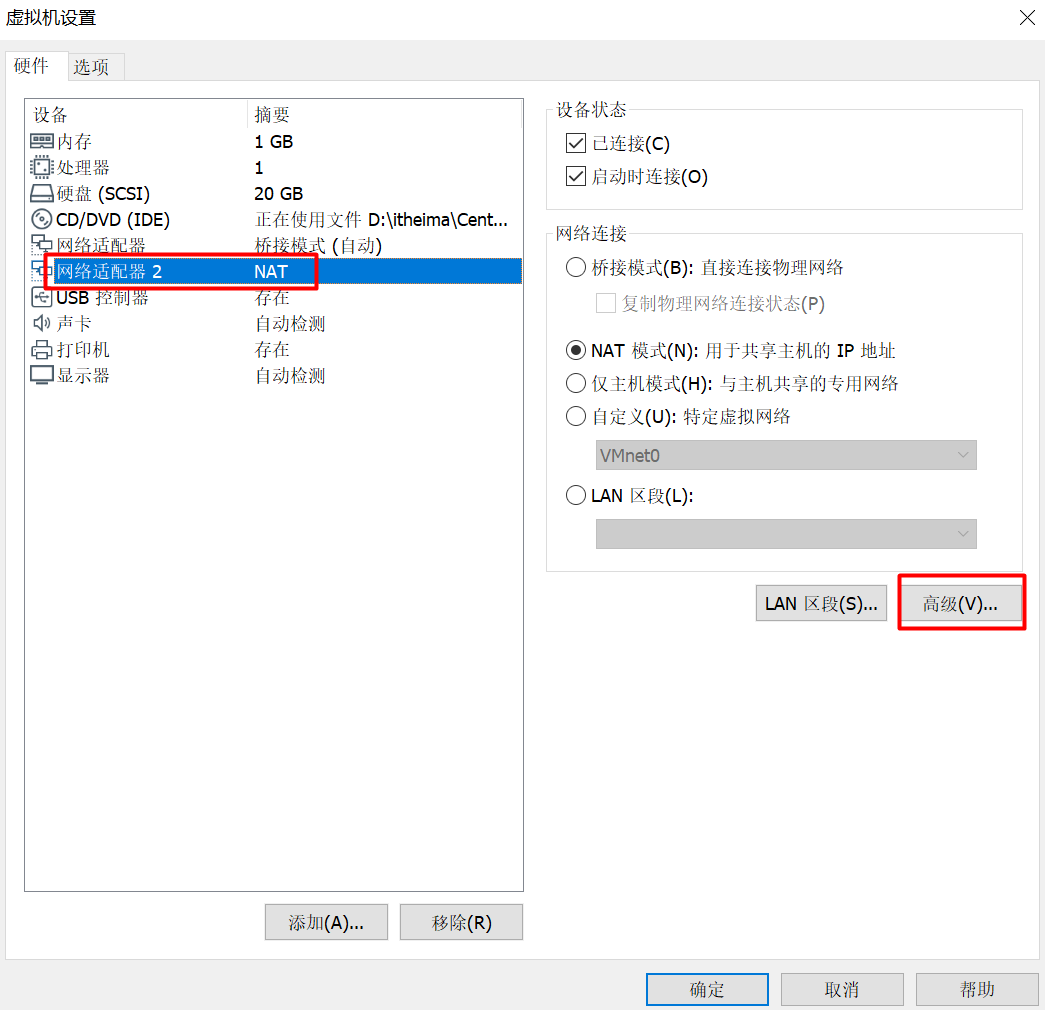
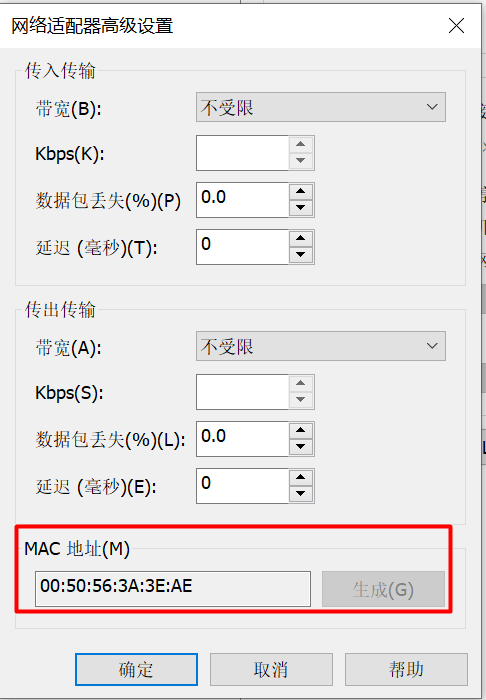
Modify configuration network card
- In the second virtual machine, a new mac address is generated
- Restart the network
// Restart the network service network restart //View ip address ip addr
-
Modify the mysql configuration file and change the uuid
- On the second server, modify the uuid of mysql
// Edit profile vi /var/lib/mysql/auto.cnf // Change server UUID to
-
Start MySQL and view
//Turn off the firewall of both servers systemctl stop firewalld //Start mysql on both servers service mysqld restart //Start mycat for both servers cd /root/mycat/bin ./mycat restart //View listening port netstat -ant|grep 3306 netstat -ant|grep 8066 //Test connections using sqlyog
3 master slave replication
-
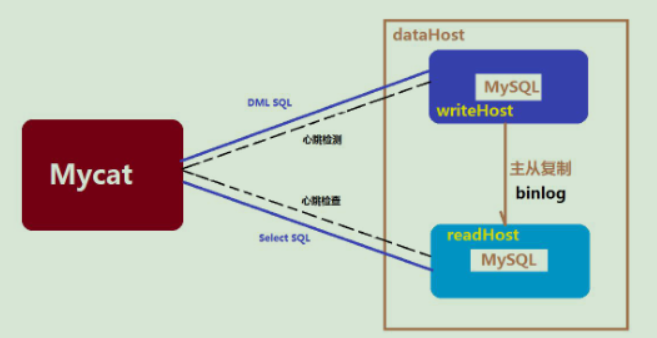
The concept of master-slave replication
- In order to use Mycat for read-write separation, we must first configure the master-slave replication of MySQL database.
- The slave server automatically synchronizes the data of the master server to achieve data consistency.
- Furthermore, we can only operate the master server when writing, and the slave server when reading.
- Principle: when processing data, the master server generates binlog log, and realizes data synchronization from the slave server through log backup.
-
Configuration of master server
- On the first server, edit the mysql configuration file
// Edit mysql configuration file vi /etc/my.cnf //Under [mysqld], add: log-bin=mysql-bin # Start copy operation server-id=1 # master is 1 innodb_flush_log_at_trx_commit=1 sync_binlog=1
- Log in to mysql, create a user and authorize it
// Login to mysql mysql -u root -p // Remove password permissions SET GLOBAL validate_password_policy=0; SET GLOBAL validate_password_length=1; // Create user CREATE USER 'hm'@'%' IDENTIFIED BY 'itheima'; // to grant authorization GRANT ALL ON *.* TO 'hm'@'%';
- Restart the mysql service and log in to the mysql service
// Restart mysql service mysqld restart // Login to mysql mysql -u root -p
- View the configuration of the primary server
// View master server configuration show master status;

-
Configuration of slave server
- On the second server, edit the mysql configuration file
// Edit mysql configuration file vi /etc/my.cnf // Under [mysqld], add: server-id=2
- Login to mysql
// Login to mysql mysql -u root -p // implement use mysql; drop table slave_master_info; drop table slave_relay_log_info; drop table slave_worker_info; drop table innodb_index_stats; drop table innodb_table_stats; source /usr/share/mysql/mysql_system_tables.sql;
- Restart mysql, log in again, and configure the slave node
// Restart mysql service mysqld restart // Login mysql again mysql -u root -p // implement change master to master_host='master server ip address',master_port=3306,master_user='hm',master_password='itheima',master_log_file='mysql-bin.000001',master_log_pos=4642;
- Restart mysql, log in again, and start the slave node
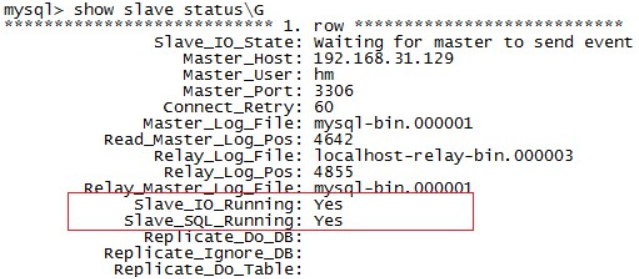
// Restart mysql service mysqld restart // Login mysql again mysql -u root -p // Turn on slave node start slave; // Query results show slave status\G; //Slave_IO_Running and slave_ SQL_ If running is yes, the synchronization is successful.
-
test
- sqlyog connect to master server
-- Master server creation db1 database,The slave server automatically synchronizes CREATE DATABASE db1;
- sqlyog connection slave server
-- Create from server db2 database,The primary server does not automatically synchronize CREATE DATABASE db2;
-
Solutions that failed to start
Startup failed: Slave_IO_Running by NO Method 1:Reset slave slave stop; reset slave; start slave ; Method 2:Reset synchronization log file and read location slave stop; change master to master_log_file='mysql-bin.000001', master_log_pos=1; start slave ;
4. Read write separation
-
The concept of read-write separation
- The write operation only writes to the master server, and the read operation reads from the slave server.
-
Modify the server on the primary server xml
- The user tag is mainly used to define the user and permission to log in to mycat. As defined above, the user name mycat and password 123456 can access the HEIMADB logical library of the schema.
<user name="root" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">HEIMADB</property> <!-- Table level DML Permission setting --> <!-- <privileges check="false"> <schema name="TESTDB" dml="0110" > <table name="tb01" dml="0000"></table> <table name="tb02" dml="1111"></table> </schema> </privileges> --> </user>
- Modify the schema on the master server xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="HEIMADB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema> <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- Write to primary server --> <writeHost host="hostM1" url="localhost:3306" user="root" password="itheima"> <!-- The slave server is responsible for reading operations --> <readHost host="hostS1" url="192.168.203.135:3306" user="root" password="itheima" /> </writeHost> </dataHost> </mycat:schema>
-
Configuration details
-
The concept of schema tag logical database is the same as that of Datebase in mysql database. When querying the tables in the two logical databases, we need to switch to the logical database to find the required tables.
-
dataNode attribute: this attribute is used to bind the logical library to a specific database.
-
dataNode tag: the dataNode tag defines the data nodes in mycat, that is, data fragmentation. A dataNode tag is an independent data fragment.
-
Name attribute: defines the name of the data node. This name must be unique. We need to apply this name on the table tag to establish the corresponding relationship between the table and the partition.
-
Datahost attribute: this attribute is used to define the database instance to which the partition belongs. The attribute value refers to the name attribute defined by the datahost tag.
-
Database attribute: this attribute is used to define the specific database on which the partition belongs, because two dimensions are used to define the partition: instance + specific database. Because the table and table structure established on each library are the same. So it's easy to split the table horizontally.
-
dataHost tag: this tag also exists as the lowest tag in the mycat logic library. It directly defines specific database instances, read-write separation configuration and heartbeat statements.
-
balance attribute: load balancing type
balance=0: do not enable read / write separation. All read operations are sent to the currently available writeHost.
balance=1: all readhosts and Stand by writeHost participate in the load balancing of the select statement
balance=2: all read operations are randomly distributed on writeHost and readHost.
balance=3: all read requests are randomly assigned to the readHost corresponding to writeHost for execution. writeHost does not bear the read pressure. -
switchType property:
- 1: indicates no automatic switching.
1: default value, indicating automatic switching
2: indicates whether to switch based on MySQL master-slave synchronization status. Heartbeat statement: show slave status
3: indicates the switching mechanism based on MySQL galaxy cluster, which is suitable for mycat1 For versions above 4, the heartbeat statement show status like "% esrep%"; -
writeHost tag and readHost tag: these two tags specify the relevant configuration of the back-end database to mycat for instantiating the back-end connection pool. The only difference is that writeHost specifies the write instance and readHost specifies the read instance. These read and write instances are combined to meet the requirements of the system.
- host attribute: used to identify different instances. For writehost, M1 is generally used; For readhost, generally use S1
- url attribute: the connection address of the backend instance. If a native dbDriver is used, it is usually in the form of address:port. If JDBC or other dbdrivers are used, it needs to be specified. When using JDBC, it can be written as follows: jdbc:mysql://localhost:3306/ .
- User attribute: the user name of the backend storage instance.
- Password attribute: the password of the backend storage instance
-
-
test
- Restart mycat on the primary server
// Restart mycat cd /root/mycat/bin ./mycat restart // View port listening netstat -ant|grep 8066
- sqlyog connecting mycat
-- Create student table CREATE TABLE student( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10) ); -- Query student table SELECT * FROM student; -- Add two records INSERT INTO student VALUES (NULL,'Zhang San'),(NULL,'Li Si'); -- After master-slave replication is stopped, the added data will only be saved to the master server. INSERT INTO student VALUES (NULL,'Wang Wu');
- sqlyog connect to master server
-- Main server: query the student table and you can see the data SELECT * FROM student;
- sqlyog connection slave server
-- From the server: query the student table to see the data(Because there is master-slave replication) SELECT * FROM student; -- From server: delete a record.(The primary server was not deleted, mycat The result of middleware query is the data from the server) DELETE FROM student WHERE id=2;
5. Sub warehouse and sub table
-
Concept of sub database and sub table
- Split huge amounts of data
- Horizontal split: split the data in the same table to multiple database servers according to certain conditions according to the data logical relationship of the table, which is also called horizontal split. For example, as like as two peas, a large table of 10 million is split into 4 4 small tables according to the same structure, and stored in 4 databases.
- Vertical splitting: splitting different tables into different databases according to business dimensions, also known as vertical splitting. For example, all orders are saved in the order library, all users are saved in the user library, tables of the same type are saved in the same library, and different tables are scattered in different libraries.
-
Mycat horizontal split
-
Modify the server of the master server xml
-
0: local file mode
In MYCAT / conf / sequence_ In the conf.properties file:
GLOBAL.MINDI=10000 min
GLOBAL. Maximum = 20000 maximum value, it is recommended to modify it to 99999999 -
1: Database mode
The global primary key is guaranteed to be self incremented and unique in the sub database and sub table, but the mycat function needs to be executed and the sequence needs to be configured_ db_ conf.properties
-
2: Timestamp mode
For the timestamp implemented by mycat, the varchar type is recommended. Pay attention to the length of the id
-
<!-- How to modify the primary key --> <property name="sequnceHandlerType">0</property>
- Modify the sequence of the master server_ conf.properties
#default global sequence GLOBAL.HISIDS= # You can customize keywords GLOBAL.MINID=10001 # minimum value GLOBAL.MAXID=20000 # Maximum GLOBAL.CURID=10000
- Modify the schema of the master server xml
- The table tag defines a logical table. All tables that need to be split need to be defined in this tag.
- Rule attribute: split rule. Mod long is one of the splitting rules. The primary key is modeled according to the number of servers. In rule Specified in XML. If there are three databases, the data will be evenly distributed to the three databases after taking the module.
- Name attribute: defines the table name of the logical table. This name is the same as the name specified by executing the create table command in the database. The table name defined in the same schema tag must be unique.
- dataNode attribute: define the dataNode to which this logical table belongs. The value of this attribute must correspond to the value of the name attribute in the dataNode tag.
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="HEIMADB" checkSQLschema="false" sqlMaxLimit="100"> <table name="product" primaryKey="id" dataNode="dn1,dn2,dn3" rule="mod-long"/> </schema> <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataNode name="dn2" dataHost="localhost1" database="db2" /> <dataNode name="dn3" dataHost="localhost1" database="db3" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- write --> <writeHost host="hostM1" url="localhost:3306" user="root" password="itheima"> <!-- read --> <readHost host="hostS1" url="192.168.203.135:3306" user="root" password="itheima" /> </writeHost> </dataHost> </mycat:schema>
- Modify the rule of the master server xml
<function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <!-- Number of databases --> <property name="count">3</property> </function>
-
test
- mycat operation
-- establish product surface CREATE TABLE product( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20), price INT ); -- Add 6 pieces of data INSERT INTO product(id,NAME,price) VALUES (NEXT VALUE FOR MYCATSEQ_GLOBAL,'iPhone',6999); INSERT INTO product(id,NAME,price) VALUES (NEXT VALUE FOR MYCATSEQ_GLOBAL,'Huawei mobile phone',5999); INSERT INTO product(id,NAME,price) VALUES (NEXT VALUE FOR MYCATSEQ_GLOBAL,'Samsung mobile phone',4999); INSERT INTO product(id,NAME,price) VALUES (NEXT VALUE FOR MYCATSEQ_GLOBAL,'Mi phones',3999); INSERT INTO product(id,NAME,price) VALUES (NEXT VALUE FOR MYCATSEQ_GLOBAL,'ZTE Mobile',2999); INSERT INTO product(id,NAME,price) VALUES (NEXT VALUE FOR MYCATSEQ_GLOBAL,'OOPO mobile phone',1999); -- query product surface SELECT * FROM product;
- Master server operation
-- Query in different databases product surface SELECT * FROM product;
- Operation from server
-- Query in different databases product surface SELECT * FROM product;
-
-
Mycat vertical split
- Modify the schema of the master server
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="HEIMADB" checkSQLschema="false" sqlMaxLimit="100"> <table name="product" primaryKey="id" dataNode="dn1,dn2,dn3" rule="mod-long"/> <!-- Animal data sheet --> <table name="dog" primaryKey="id" autoIncrement="true" dataNode="dn4" /> <table name="cat" primaryKey="id" autoIncrement="true" dataNode="dn4" /> <!-- Fruit data sheet --> <table name="apple" primaryKey="id" autoIncrement="true" dataNode="dn5" /> <table name="banana" primaryKey="id" autoIncrement="true" dataNode="dn5" /> </schema> <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataNode name="dn2" dataHost="localhost1" database="db2" /> <dataNode name="dn3" dataHost="localhost1" database="db3" /> <dataNode name="dn4" dataHost="localhost1" database="db4" /> <dataNode name="dn5" dataHost="localhost1" database="db5" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- write --> <writeHost host="hostM1" url="localhost:3306" user="root" password="itheima"> <!-- read --> <readHost host="hostS1" url="192.168.203.135:3306" user="root" password="itheima" /> </writeHost> </dataHost> </mycat:schema>-
test
- sqlyog connecting mycat
-- establish dog surface CREATE TABLE dog( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10) ); -- Add data INSERT INTO dog(id,NAME) VALUES (NEXT VALUE FOR MYCATSEQ_GLOBAL,'Siberian Husky'); -- query dog surface SELECT * FROM dog; -- establish cat surface CREATE TABLE cat( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10) ); -- Add data INSERT INTO cat(id,NAME) VALUES (NEXT VALUE FOR MYCATSEQ_GLOBAL,'Persian cat'); -- query cat surface SELECT * FROM cat; -- establish apple surface CREATE TABLE apple( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10) ); -- Add data INSERT INTO apple(id,NAME) VALUES (NEXT VALUE FOR MYCATSEQ_GLOBAL,'Red Fuji'); -- query apple surface SELECT * FROM apple; -- establish banana surface CREATE TABLE banana( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10) ); -- Add data INSERT INTO banana(id,NAME) VALUES (NEXT VALUE FOR MYCATSEQ_GLOBAL,'Banana'); -- query banana surface SELECT * FROM banana;
- sqlyog connect to master server
-- query dog surface SELECT * FROM dog; -- query cat surface SELECT * FROM cat; -- query apple surface SELECT * FROM apple; -- query banana surface SELECT * FROM banana;
- sqlyog connection slave server
-- query dog surface SELECT * FROM dog; -- query cat surface SELECT * FROM cat; -- query apple surface SELECT * FROM apple; -- query banana surface SELECT * FROM banana;