background
There are many kinds of logs accessed by the log system with complex and diverse formats. The mainstream logs are as follows:
- The text log collected by filebeat has various formats
- Operating system logs collected by winbeat
- syslog log of logstash reported on the device
- Access to kafka service log
The above logs accessed through various channels have two main problems:
- The format is not unified, standardized and standardized enough
- How to extract indicators concerned by users from various logs and mine more business value
In order to solve the above two problems, we do a real-time log processing service based on flink and drools rule engine.
system architecture
The architecture is relatively simple. The architecture diagram is as follows: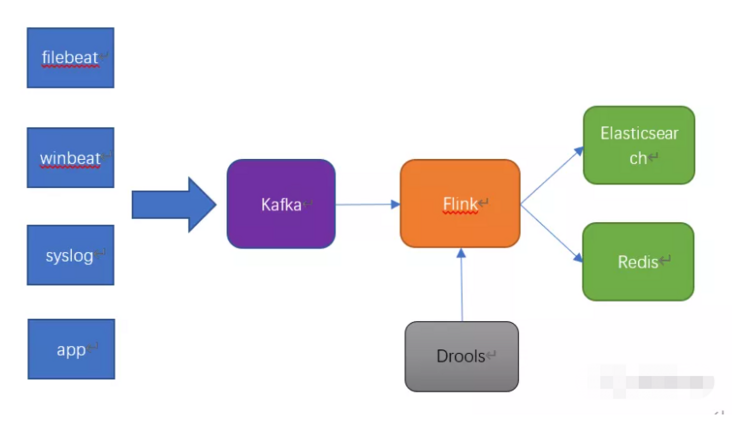
All kinds of logs are summarized through kafka for log transfer.
Flick consumes kafka's data and pulls the drools rule engine through API call. After parsing the log, the parsed data is stored in Elasticsearch for log search and analysis.
In order to monitor the real-time status of log parsing, flink will write the statistics of log processing, such as the number of logs processed per minute and the number of logs from each machine IP to Redis for monitoring statistics.
Module introduction
The system project is named eagle.
Eagle API: Based on spring boot, it serves as a write and read API service for the drools rule engine.
Eagle common: generic class module.
Eagle log: a flink based log processing service.
Focus on Eagle log:
Docking kafka, ES and Redis
The connection between Kafka and ES is relatively simple. The official connectors (flip-connector-kafka-0.10 and flip-connector-elasticsearch6) are used. See the code for details.
To connect with Redis, we first used org.com apache. The redis connector provided by Bahir was not flexible enough, so Jedis was used.
When writing statistics to redis, Big data training After the initial keyby grouping, the grouping data is cached and written after statistical processing in sink. The reference code is as follows:
String name = "redis-agg-log";
DataStream<Tuple2<String, List<LogEntry>>> keyedStream = dataSource.keyBy((KeySelector<LogEntry, String>) log -> log.getIndex())
.timeWindow(Time.seconds(windowTime)).trigger(new CountTriggerWithTimeout<>(windowCount, TimeCharacteristic.ProcessingTime))
.process(new ProcessWindowFunction<LogEntry, Tuple2<String, List<LogEntry>>, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<LogEntry> iterable, Collector<Tuple2<String, List<LogEntry>>> collector) {
ArrayList<LogEntry> logs = Lists.newArrayList(iterable);
if (logs.size() > 0) {
collector.collect(new Tuple2(s, logs));
}
}
}).setParallelism(redisSinkParallelism).name(name).uid(name);Later, it was found that this would consume a lot of memory. In fact, there is no need to cache the original data of the whole packet. Just one statistical data is OK. After optimization:
String name = "redis-agg-log";
DataStream<LogStatWindowResult> keyedStream = dataSource.keyBy((KeySelector<LogEntry, String>) log -> log.getIndex())
.timeWindow(Time.seconds(windowTime))
.trigger(new CountTriggerWithTimeout<>(windowCount, TimeCharacteristic.ProcessingTime))
.aggregate(new LogStatAggregateFunction(), new LogStatWindowFunction())
.setParallelism(redisSinkParallelism).name(name).uid(name);Here, the aggregate function and Accumulator of flex are used to make statistics through the agg operation of flex, which reduces the pressure of memory consumption.
Broadcast drools rule engine using broadcast
1. The drools rule flow is broadcast through broadcast map state.
2. kafka's data stream connect rule stream processing log.
//Broadcast rule flow
env.addSource(new RuleSourceFunction(ruleUrl)).name(ruleName).uid(ruleName).setParallelism(1)
.broadcast(ruleStateDescriptor);
//kafka data stream
FlinkKafkaConsumer010<LogEntry> source = new FlinkKafkaConsumer010<>(kafkaTopic, new LogSchema(), properties);env.addSource(source).name(kafkaTopic).uid(kafkaTopic).setParallelism(kafkaParallelism);
//Data flow connect rule flow processing log
BroadcastConnectedStream<LogEntry, RuleBase> connectedStreams = dataSource.connect(ruleSource);
connectedStreams.process(new LogProcessFunction(ruleStateDescriptor, ruleBase)).setParallelism(processParallelism).name(name).uid(name);Refer to the open source code for details.
Summary
The system provides a real-time data processing reference based on flick, connects kafka, redis and elastic search, and configures and dynamically the data processing logic through the configurable drools rule engine.
The processed data can also be connected to other finks to provide data analysis, cleaning and standardization services for other business platforms.