This column will explain the open source code of GitHub YOLOv5 with a comprehensive series from installation to examples. Column address: GitHub YOLOv5 open source project series explanation

catalogue
2. Detailed explanation of parameters
1 General
Using yolov5 to train the neural network, the train in the open source project source code is used py.
We can adjust the parameters of the red box part of its main function.
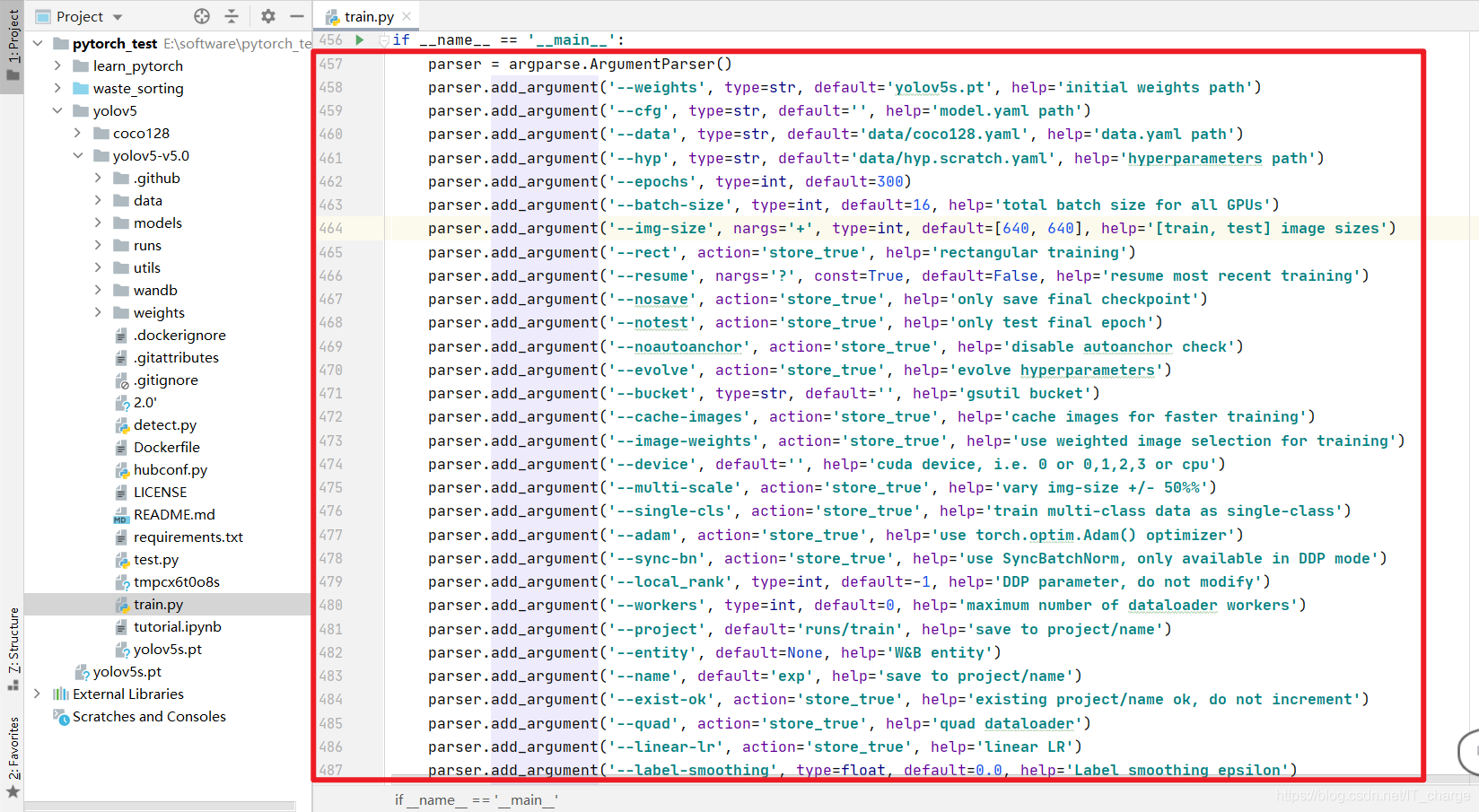
2. Detailed explanation of parameters
2.1 --weights
parser.add_argument('--weights', type=str, default='', help='initial weights path')It can be used to specify a trained model path and initialize some parameters in the model with this model (first, it needs to be downloaded in advance or it will be downloaded automatically when running the program)
Default is empty by default. The meaning is to initialize with the parameter weight of the program instead of the trained model.
The default value can be set to:
- Yolov5s.pt
- Yolov5m.pt
- Yolov5l.pt
- Yolov5x.pt
2.2 --cfg
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')cfg is the abbreviation of configuration, which is used to configure the model.
default is used to select the model file.
Its setting values can be found in this folder:
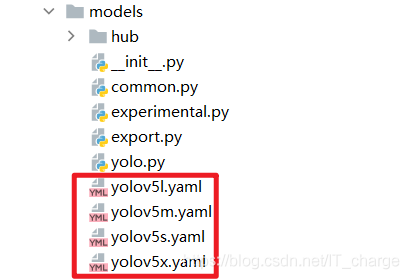
2.3 --data
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')Used to specify the training dataset.
Its setting values can be found in this folder:
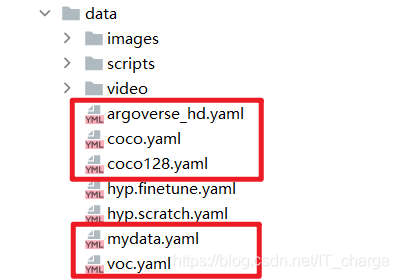
2.4 --hyp
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')Used to set super parameters (generally not used).
Its setting value can be found in this folder. Two files are provided in the source code:
- hyp.finetune.yaml: some super parameters used in training VOC data sets are set
- hyp.scratch.yaml: some super parameters used in training COCO data sets are set
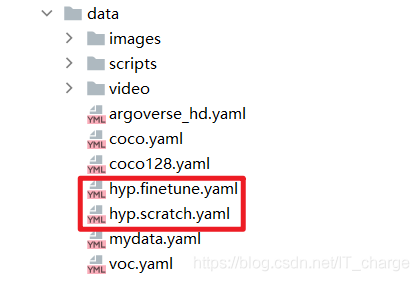
2.5 --epochs
parser.add_argument('--epochs', type=int, default=300)Used to set the number of rounds of training.
The default value in the source code is 300, and the training rounds are displayed as 0 ~ 299.
2.6 --batch-size
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')It is used to set the number of runs at a time and input the data into the network. If not set, the default value is 16.
2.7 --img-size
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')Used to set the size of training set and test set respectively.
The former is the size of the training set and the latter is the size of the test set.
2.8 --rect
parser.add_argument('--rect', action='store_true', help='rectangular training')Used to set the training method of the matrix.
The function is to subtract some unnecessary information and accelerate the model reasoning process.
2.9 --resume
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')Used to set whether to continue training based on a model of recent training.
The default value is false by default. When you want the default to be true, you must specify which model to continue training on. The specified model path is assigned to default as a string.
2.10 --nosave
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')Only the last pt file is saved after it takes effect.
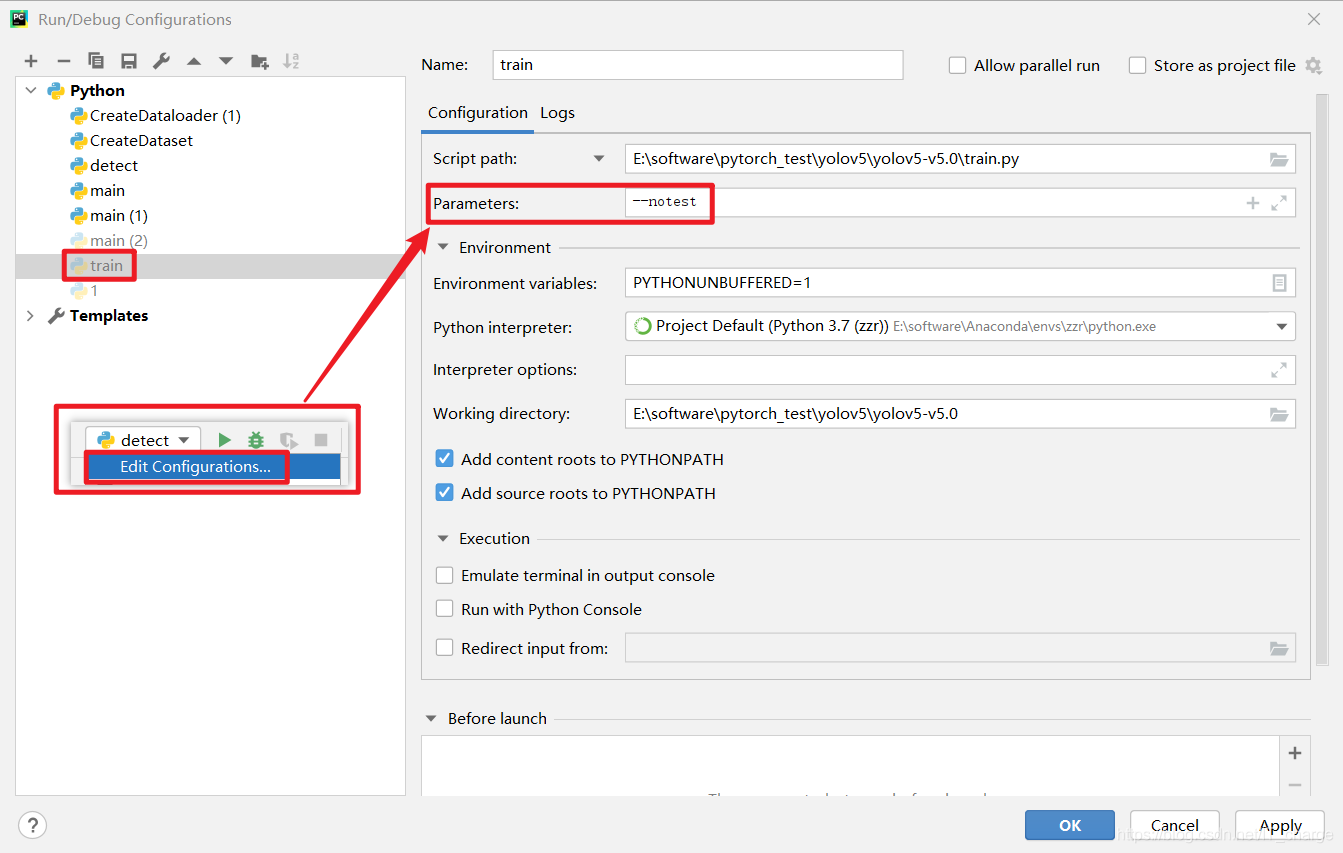
2.11 --notest
parser.add_argument('--notest', action='store_true', help='only test final epoch')Only the last test shall be carried out after taking effect.
The condition for activating such parameters is to fill in edit configuration -- > parameters. If there are multiple activated parameters, they can be separated by spaces.
2.12 --noautoanchor
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')Used to set whether to use anchor point / anchor box in target detection task.
Traverse all possible pixel boxes on the input image, then select the correct target box, and adjust the position and size to complete the target detection task.
It is enabled by default. This method is used to simplify the model training process.
2.13 --evolve
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')After taking effect, the super parameters are purified.
The method is to use genetic algorithm to automatically search the super parameters.
Silent people don't open it.
2.14 --bucket
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')This parameter is yolov5. The author puts some things on Google cloud disk and can download them.
2.15 --cache-images
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')After taking effect, the pictures will be cached for better training.
2.16 --image-weights
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')After taking effect, some weights will be added to the pictures with poor training in the next round.
2.17 --device
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')It is used to set whether the device running the pytorch framework uses GPU cuda or cpu. It is suitable for setting these contents.
2.18 --multi-scale
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')Used to transform the picture scale.
2.19 --single-cls
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')Used to set whether the training dataset is single category or multi category.
The default is false, which means multiple categories.
2.20 --adam
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')Used as an optimizer after it takes effect.
It is true when it is filled in edit configuration -- > parameters, which means that this optimizer is used; Otherwise, it is false. When it is false, the random gradient descent (SGD) optimization algorithm is used.
2.21 --sync-bn
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')After taking effect, conduct distributed training with multiple GPU s.
2.22 --local_rank
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')DistributedDataParallel single machine multi card training, generally unchanged.
2.23 --workers
parser.add_argument('--workers', type=int, default=0, help='maximum number of dataloader workers')It is strongly recommended that default be set to 0.
2.24 --project
parser.add_argument('--project', default='runs/train', help='save to project/name')Used to specify the save path of the trained model.
2.25 --entity
parser.add_argument('--entity', default=None, help='W&B entity')The corresponding thing of wandb library has little effect and does not need to be considered.
Here is a supplementary point: The way to close wandb is to find util -- > wandb under the source tree_ logging --> wandb_ utils. Py file, after the position of about 18 lines, add a sentence "wandb = None" to close it. (because the wandb library needs to be installed separately, and its effect is not significant, a method of ignoring is provided here.)

2.26 --name
parser.add_argument('--name', default='exp', help='save to project/name')Used to set the saved model file name.
2.27 --exist-ok
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')Used to set the storage location of prediction results.
false when not activated, and saved in a newly named folder.
When activated, it is true, saved in the folder specified by name, and saved in the exp folder in the source code
The corresponding sample picture is in< Explanation of GitHub YOLOv5 open source code project series (III) -- Explanation of prediction related parameters >Part 2.17 of the blog can be found.
2.28 --quad
parser.add_argument('--quad', action='store_true', help='quad dataloader')Explain the relevant settings for quad data loading.
Simply understand that after it takes effect, you can train on a larger data set than the training test data set set set in the "- img size" section above.
- The advantage is that the training effect is better on a dataset larger than the default 640
- The side effect is that the training effect may be worse on the 640 size data set
2.29 --linear-lr
parser.add_argument('--linear-lr', action='store_true', help='linear LR')Used to adjust the learning rate
The default is false, which means that the learning rate is reduced by cosine function.
Note: when we use the gradient descent algorithm to optimize the objective function, when it is getting closer to the global minimum of the Loss value, the learning rate should become smaller to make the model as close as possible, and Cosine annealing can reduce the learning rate through the cosine function.
After it takes effect, it changes to reduce the learning rate through linear processing.
2.30 --label-smoothing
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')Used to smooth labels.
The function is to prevent over fitting in the classification algorithm.
2.31 --upload_dataset
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')The corresponding thing of wandb library has little effect and does not need to be considered.
2.32 --bbox_interval
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')This is another parameter setting related to wandb library. It has little effect and is ignored.
2.33 --save_period
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')It is used to record training log information. It is of type int, and the default is - 1.
2.34 --artifact_alias
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')This line of parameters represents a content that you want to implement but have not yet implemented. You can ignore it. The whole program can also be run after being commented out.
3 display of training results
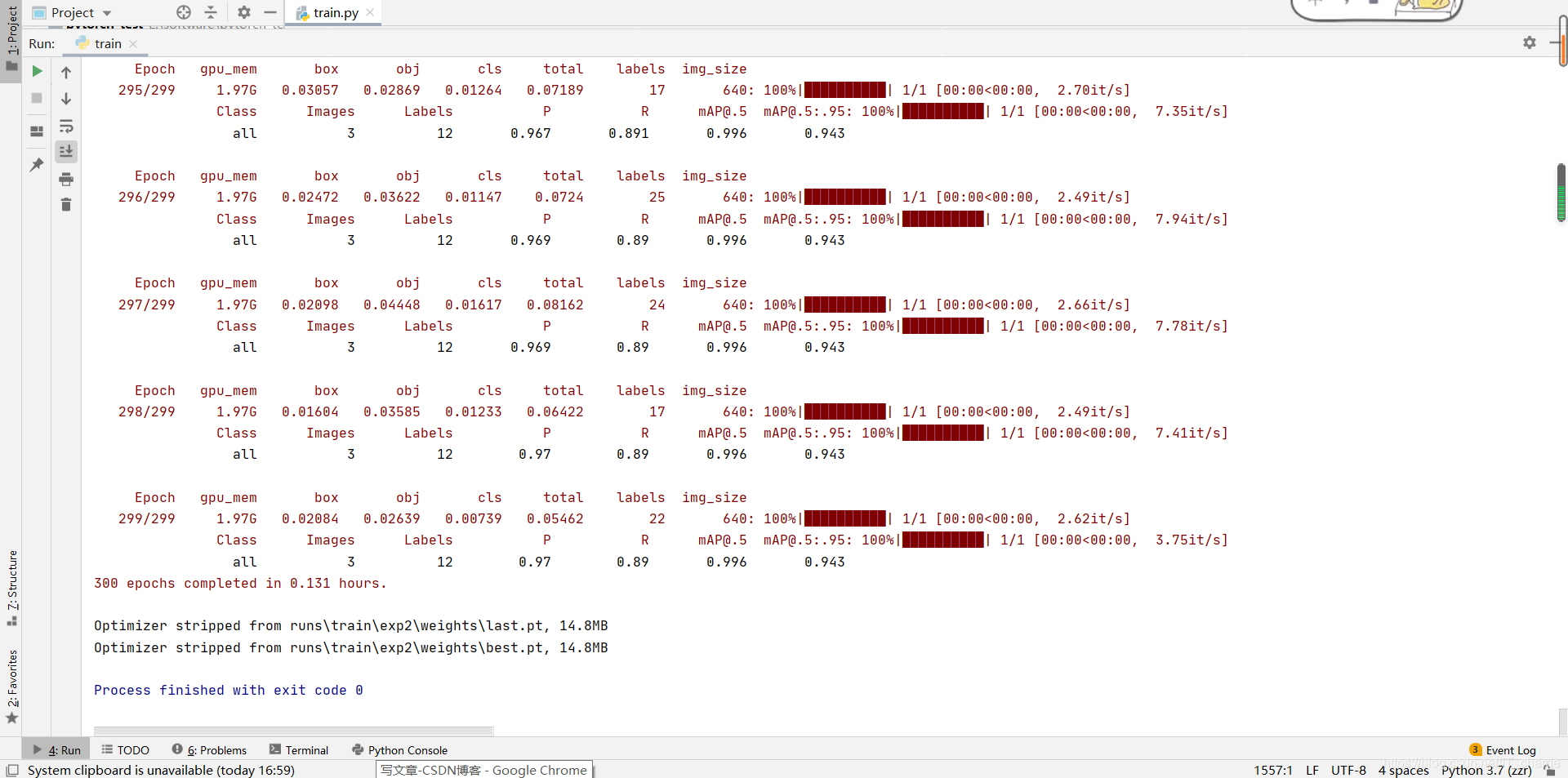
Save location
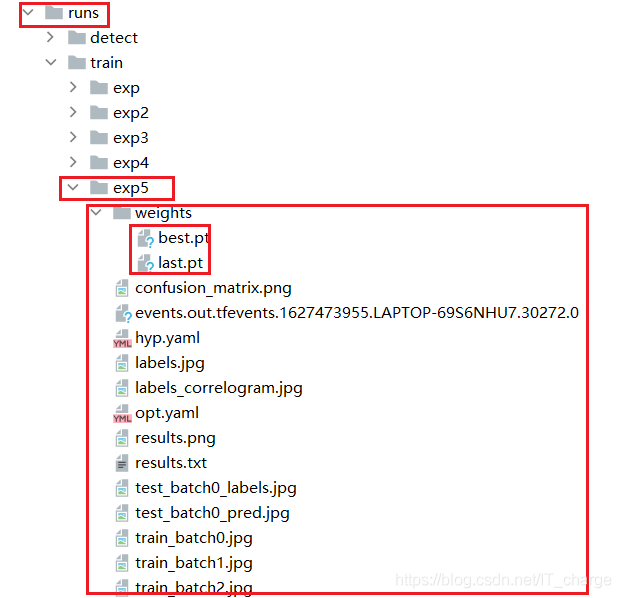
The above is all about the explanation of training related parameters. Thank you for reading!