Original title: Spring certified China Education Management Center - spring data tutorial II of Apache Solr (spring China Education Management Center)

3.6. file map
Although entity mapping is already supported in SolrJ, Spring Data Solr comes with its own mapping mechanism (described in the next section).
DocumentObjectBinder has superior performance. Therefore, if you do not need a customer mapping, we recommend that you use it. You can switch from DocumentObjectBinder to SolrTemplate by registering with SolrJConverter.
3.6.1. Object mapping Basics
This section covers the basics of Spring Data object mapping, object creation, field and property access, variability, and invariance. Note that this section applies only to Spring Data modules that do not use object mapping of the underlying data store, such as JPA. In addition, be sure to consult the storage specific section for storage specific object mappings, such as indexes, custom column or field names.
The core responsibility of Spring Data object mapping is to create instances of domain objects and map the stored native data structures to these instances. This means that we need two basic steps:
- Create an instance using one of the exposed constructors.
- Instance population to implement all exposed properties.
objects creating
Spring Data automatically attempts to detect the constructor to be used to materialize the persistent entity of the object of this type. The working principle of the analytical algorithm is as follows:
- If there is only one constructor, use it.
- If there are multiple constructors and only one annotates @ PersistenceConstructor, use it.
- If a parameterless constructor exists, it is used. Other constructors will be ignored.
Value resolution assumes that the constructor parameter name matches the attribute name of the entity, that is, the resolution will be performed as if the attribute is to be filled, including all customizations in the mapping (different data storage column or field names, etc.). This also requires parameter name information available in the class file or comments that exist in the @ ConstructorProperties constructor.
You can customize Value resolution using Spring Framework Value annotations by using @ Value store specific spiel expressions. For more details, see the section on store specific mappings.
Object create internal
In order to avoid the overhead of reflection, the Spring Data object creates a factory class generated by runtime by default, which will directly call the domain class constructor. That is, for this sample type:
class Person {
Person(String firstname, String lastname) { ... }
}We will create a factory class semantically equivalent to this at runtime:
class PersonObjectInstantiator implements ObjectInstantiator {
Object newInstance(Object... args) {
return new Person((String) args[0], (String) args[1]);
}
}This gives us about 10% better performance than reflection. To qualify a domain class for such optimization, it needs to comply with a set of constraints:
- It cannot be a private course
- It cannot be a non static inner class
- It cannot be a CGLib proxy class
- The constructor used by Spring Data cannot be private
If any of these conditions match, Spring Data will fall back to entity instantiation through reflection.
Property population
Once an instance of the entity is created, Spring Data populates all the remaining persistent properties of the class. Unless the entity's constructor has been populated (i.e., consumed through its constructor parameter list), the identifier attribute will be populated first to allow resolution of the circular object reference. After that, all non transient properties that have not been populated by the constructor are set on the entity instance. To do this, we use the following algorithm:
- If the attribute is immutable but exposes a with... Method (see below), we use the with... Method to create a new entity instance with a new attribute value.
- If property access is defined (that is, through getter s and setters), we will call the setter method.
- If the attribute is variable, we set the field directly.
- If the property is immutable, we will use the constructor used by the persistence operation (see object creation) to create a copy of the instance.
- By default, we set the field value directly.
Internal structure of property population
Similar to our optimization in object construction, we also use the accessor class generated by the Spring Data runtime to interact with the entity instance.
class Person {
private final Long id;
private String firstname;
private @AccessType(Type.PROPERTY) String lastname;
Person() {
this.id = null;
}
Person(Long id, String firstname, String lastname) {
// Field assignments
}
Person withId(Long id) {
return new Person(id, this.firstname, this.lastame);
}
void setLastname(String lastname) {
this.lastname = lastname;
}
}Example 61 Generated property accessors
class PersonPropertyAccessor implements PersistentPropertyAccessor {
private static final MethodHandle firstname;
private Person person;
public void setProperty(PersistentProperty property, Object value) {
String name = property.getName();
if ("firstname".equals(name)) {
firstname.invoke(person, (String) value);
} else if ("id".equals(name)) {
this.person = person.withId((Long) value);
} else if ("lastname".equals(name)) {
this.person.setLastname((String) value);
}
}
}PropertyAccessor holds a variable instance of the underlying object. This is to enable mutations in other immutable attributes.
By default, Spring Data uses field access to read and write property values. MethodHandles are used to interact with private fields according to the visibility rules of private fields.
This class discloses a withId(...) method for setting an identifier, for example, when an instance is inserted into the data store and generates an identifier. Call withId(...) to create a new Person object. All subsequent mutations will occur in the new instance, while the previous one remains unchanged.
Using property access allows direct method calls without using MethodHandles
This gives us a performance improvement of about 25% over reflection. To qualify a domain class for such optimization, it needs to comply with a set of constraints:
- Types must not be under default values or java packages.
- Type and its constructor must be public
- The type belonging to the inner class must be static
- The Java runtime used must be allowed in the original classloader Java 9 and later impose certain restrictions.
By default, Spring Data attempts to use the generated property accessor, and if a restriction is detected, fallback to the reflection based accessor.
Let's look at the following entities:
Example 62 Example entity
class Person {
private final @Id Long id;
private final String firstname, lastname;
private final LocalDate birthday;
private final int age;
private String comment;
private @AccessType(Type.PROPERTY) String remarks;
static Person of(String firstname, String lastname, LocalDate birthday) {
return new Person(null, firstname, lastname, birthday,
Period.between(birthday, LocalDate.now()).getYears());
}
Person(Long id, String firstname, String lastname, LocalDate birthday, int age) {
this.id = id;
this.firstname = firstname;
this.lastname = lastname;
this.birthday = birthday;
this.age = age;
}
Person withId(Long id) {
return new Person(id, this.firstname, this.lastname, this.birthday, this.age);
}
void setRemarks(String remarks) {
this.remarks = remarks;
}
}| The identifier property is final, but is set to null in the constructor. This class discloses a withId(...) method for setting an identifier, for example, when an instance is inserted into the data store and generates an identifier. When Person creates a new instance, the original instance remains unchanged. The same pattern typically applies to other properties that are managed by storage but may have to be changed for persistent operations. The with method is optional because the persistence constructor (see 6) is actually a copy constructor, and setting this property will be converted to creating a new instance to apply the new identifier value. | |
| The firstname and lastname properties are common immutable properties that may be exposed through getters. | |
| The age attribute is immutable, but originates from the birthday attribute. Using the design shown, the database value will outperform the default value because Spring Data uses a uniquely declared constructor. Even if the intention is that calculation should be preferred, it is important that this constructor takes age as a parameter (it may be ignored), otherwise the attribute filling step will try to set the age field and fail because it is immutable and there is no with... Method. | |
| The comment attribute is variable and is populated by directly setting its field. | |
| The remarks feature of is mutable and populates the comment field directly by setting or by calling the setter method | |
| This class exposes a factory method and a constructor for creating objects. The core idea here is to use factory methods instead of additional constructors to avoid the need to pass @ PersistenceConstructor Instead, the default settings for properties are handled in the factory method. |
General recommendations
- Try to stick to immutable objects -- immutable objects are easy to create because materializing an object is just a problem of calling its constructor. In addition, this avoids flooding your domain objects with setter methods that allow client code to manipulate the object state. If you need these, it's best to package and protect them so that they can only be called by a limited number of collocated types. Constructor only implementation is 30% faster than property padding.
- Provide a full parameter constructor - even if you can't or don't want to model your entity as immutable, providing a constructor that takes all the attributes of the entity as parameters is still valuable, including variable, because it allows object mapping to skip attribute filling for best performance.
- Use factory methods instead of overloading constructors to avoid @ PersistenceConstructor - in order to obtain the best performance, we need a full parameter constructor. We usually want to expose more application use case specific constructors, which omit automatically generated identifiers, etc. This is an established pattern, rather than using static factory methods to expose these variants of the all args constructor.
- Ensure compliance with the constraints that allow the use of generated instantiator and property accessor classes --
- For the identifier to be generated, the final field is still used in combination with the all parameter persistence constructor (preferred) or with... Method --
- Use Lombok to avoid template code - since persistence operations usually require a constructor that accepts all parameters, their declaration becomes a tedious repetition of template parameters assigned to fields, and use Lombok's @ AllArgsConstructor
Kotlin support
Spring Data tweaks the details of Kotlin to allow objects to be created and changed.
Kotlin object creation
Kotlin classes support instantiation. By default, all classes are immutable, and explicit attribute declarations are required to define variable attributes. Consider the following data class Person:
data class Person(val id: String, val name: String)
The above class is compiled into a typical class with an explicit constructor. We can customize this class by adding another constructor and use the annotation @ PersistenceConstructor to indicate constructor preferences:
data class Person(var id: String, val name: String) {
@PersistenceConstructor
constructor(id: String) : this(id, "unknown")
}Kotlin supports parameter selectability by allowing default values to be used when no parameters are provided. When Spring Data detects a constructor with parameter default values, if the data store does not provide values (or simply returns null), it will make these parameters nonexistent, so kotlin can apply parameter default values. Consider the following class name that applies the default value of the parameter
data class Person(var id: String, val name: String = "unknown")
Each time the name parameter is not part of the result or its value is null, the name defaults to unknown.
Property filling of Kotlin data class
In Kotlin, all classes are immutable by default, and explicit attribute declarations are required to define variable attributes. Consider the following data class Person:
data class Person(val id: String, val name: String)
This class is actually immutable. It allows the creation of new instances because Kotlin generates a copy(...) method for creating new object instances, which copies all attribute values from existing objects and applies the attribute values provided as parameters to the method.
3.6.2.MappingSolrConverter
The mapping solrconverter allows you to register custom converters for your SolrDocument and other types of SolrInputDocument nested in your bean. The converter is not 100% compatible with DocumentObjectBinder, @ Indexed must add readonly=true to ignore the fields written to Solr. The following example maps multiple fields in a document:
Example 63 Sample document mapping
public class Product {
@Field
private String simpleProperty;
@Field("somePropertyName")
private String namedPropery;
@Field
private List<String> listOfValues;
@Indexed(readonly = true)
@Field("property_*")
private List<String> ignoredFromWriting;
@Field("mappedField_*")
private Map<String, List<String>> mappedFieldValues;
@Dynamic
@Field("dynamicMappedField_*")
private Map<String, String> dynamicMappedFieldValues;
@Field
private GeoLocation location;
}The following table describes the properties that you can map MappingSolrConverter:
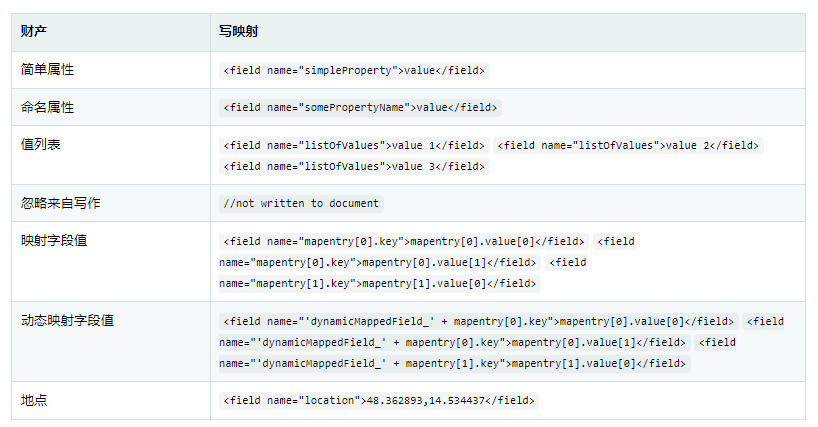
You can register a custom Converter CustomConversions to implement the SolrTemplate and its own initialization Converter, as shown in the following example:
<bean id="solrConverter" class="org.springframework.data.solr.core.convert.MappingSolrConverter"> <constructor-arg> <bean class="org.springframework.data.solr.core.mapping.SimpleSolrMappingContext" /> </constructor-arg> <property name="customConversions" ref="customConversions" /> </bean> <bean id="customConversions" class="org.springframework.data.solr.core.convert.SolrCustomConversions"> <constructor-arg> <list> <bean class="com.acme.MyBeanToSolrInputDocumentConverter" /> </list> </constructor-arg> </bean> <bean id="solrTemplate" class="org.springframework.data.solr.core.SolrTemplate"> <constructor-arg ref="solrClient" /> <property name="solrConverter" ref="solrConverter" /> </bean>