Author: Leo Bert LAN
background
If I remember correctly, the Android project will gradually turn to Gradle construction in 15 years. Up to now, componentization is no longer a novel topic.
Although I put this article in the gradle category, we know that the focus of the backend project built with gradle is to realize microservicing. The project is disassembled, which determines that the dependency library is already a static jar package, which is inconsistent with the scenario we want to discuss. So we still discuss this issue in the Android field.
In the component implementation of various schemes, some functional modules will be split for library sinking. Thus, there is a scenario to deal with dependencies. I believe you have thought about such a problem: if the sinking library also compiles the static aar package in advance, the compilation time of our project will be shortened.
There is no doubt that this will directly solve the problem of long compilation time from the source, that is, reduce the compilation content. However, when the projects are merged, it is inevitable to use the upper business integration to smoke when developing the lower library. ps: This is not a good practice. The smoking test environment should be configured for the library, although it will take some time.
If the ideal returns to the ideal, it will eventually lose to the reality. This problem has become a problem that fish and bear's paw want to have both.
In order to make the goal of reading more clear, let's first think about a question:
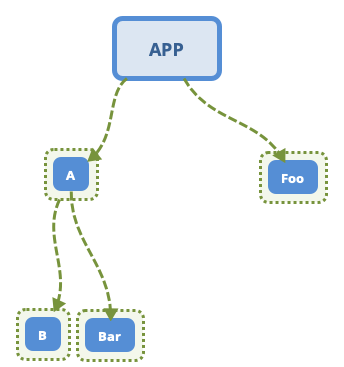
For such A project dependency, if you change the content of B, you do not need to recompile A, run APP and verify the modification of B. We will expand it to understand this problem.
Why is it easier to use dependent packages in remote warehouses than local static AARS
We know that for a module, we compile it to generate a static aar package and only process its own content. So how is his dependence transmitted?
Through pom file
for instance:
Let's create a new module and take a look at the dependencies:
dependencies {
implementation "org.jetbrains.kotlin:kotlin-stdlib:$kotlin_version"
implementation 'androidx.core:core-ktx:1.3.2'
implementation 'androidx.appcompat:appcompat:1.2.0'
implementation 'com.google.android.material:material:1.2.1'
testImplementation 'junit:junit:4.+'
androidTestImplementation 'androidx.test.ext:junit:1.1.2'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.3.0'
}
When publishing with maven plugin, there will be a task to generate pom files, as follows:
<?xml version="1.0" encoding="UTF-8"?>
<project xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>leobert</groupId>
<artifactId>B</artifactId>
<version>1.0.0</version>
<packaging>aar</packaging>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-stdlib</artifactId>
<version>1.4.21</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>androidx.core</groupId>
<artifactId>core-ktx</artifactId>
<version>1.3.2</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>androidx.appcompat</groupId>
<artifactId>appcompat</artifactId>
<version>1.2.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.google.android.material</groupId>
<artifactId>material</artifactId>
<version>1.2.1</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>
We found that the dependencies related to testing were not included in the pom file. This is reasonable. The test code is specific to the module and does not need to be provided to the user. Naturally, its dependencies do not need to be passed. As we know, there are four ways to declare dependencies in AGP (except for the variant of testXXX)
- api
- implementation
- compileOnly
- runtimeOnly
runtimeOnly corresponds to the previous apk declaration dependency. We will ignore it and test the generated pom file.
dependencies {
api "org.jetbrains.kotlin:kotlin-stdlib:$kotlin_version"
implementation 'androidx.core:core-ktx:1.3.2'
compileOnly 'androidx.appcompat:appcompat:1.2.0'
compileOnly 'com.google.android.material:material:1.2.1'
testImplementation 'junit:junit:4.+'
androidTestImplementation 'androidx.test.ext:junit:1.1.2'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.3.0'
}
<?xml version="1.0" encoding="UTF-8"?>
<project xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>leobert</groupId>
<artifactId>B</artifactId>
<version>1.0.0</version>
<packaging>aar</packaging>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-stdlib</artifactId>
<version>1.4.21</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>androidx.core</groupId>
<artifactId>core-ktx</artifactId>
<version>1.3.2</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>
Those using compileOnly are not included in the pom file, while the api and implementation methods, in the pom file, are shown as application dependencies using compile.
PS: the difference between API and implementation in the coding period is not the focus of our discussion.
Back to the question we started, when publishing the library, according to the Convention, the dependencies of the library itself will be included in the pom file. Accordingly, when the user uses the dependency in the warehouse, gradle will pull its corresponding pom file and add the dependency.
Therefore, if we directly use a compiled static package and discard its corresponding pom file, we may lose dependencies, package failure or run exceptions. This means that we need to maintain dependency passing artificially
Let's remember this and put it aside.
After sinking, the library will have multiple levels
For example, in the figure: app = > A = > b, that is, APP depends on a, a depends on B, and both a and B are libraries
We know that there will be no statement about B, which will only appear in A and APP
If you do not use static packages, A declares:
api project(':B')
//perhaps
implementation project(':B')
Let's take a look at the pom file of library-A generated in this way
<?xml version="1.0" encoding="UTF-8"?>
<project xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>leobert</groupId>
<artifactId>A</artifactId>
<version>1.0.0</version>
<packaging>aar</packaging>
<dependencies>
<dependency>
<groupId>Demo</groupId>
<artifactId>B</artifactId>
<version>unspecified</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>
You will get that groupID is the project name, artifactId is the module name, and version is an unknown dependency. If I compile A into A static package and publish it to the warehouse, and use the dependency description in pom, I will be unable to find it: demo-b-unspecified pom problem.
Of course, this problem can be solved by redefining the dependency of B in the APP.
This means that we need to be vigilant and maintain the dependencies of each module. Otherwise, we can't enjoy it at the same time: static packages reduce Compilation & arbitrary modification of parts and integration testing
This is obviously an inhumane thing.
In retrospect, for A, it needs B, but only at two times:
- Compile time checked, complete compilation
- Runtime
As A library, it itself does not correspond to the runtime, so compileOnly is the best way to declare its dependence on B. This means that the final content corresponding to the runtime, that is, APP, needs to add A dependency on B during compilation. When A used Api to declare its dependency on B, it was added by gradle analyzing pom files. Now, it needs human maintenance. As long as humanitarianism is realized, we can have both fish and bear's paws.
Reflection on the essence of dependency transmission
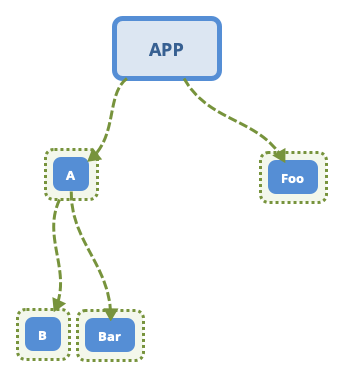
In general, we will declare dependencies like the following demonstration code:
//APP:
implementation project('A')
implementation project('Foo')
//A:
implementation project('B')
implementation project('Bar')
Because of dependency transitivity, APP actually relies on A, Foo, B and Bar. In fact, it is A collection of nodes in A tree with the root node removed. For A non root node, there are only two forms of dependency:
- Static package, no need to recompile, saving compilation time
- module, which needs to be compiled again. You can use the latest changes
We can define such a key value pair information:
project.ext.depRules = [
"B": "p",
"A": "a"
]
"p" stands for project and "a" stands for static package.
And express the content of this tree: let's ignore Foo and Bar first
project.ext.deps = [
"A" : [
"B": [
"p": project(':B'),
"a": 'leobert:B:1.0.0'
]
],
"APP": [
"A": [
"p": project(':A'),
"a": 'leobert:A:1.0.0'
]
]
].with(true) {
A.each { e ->
APP.put(e.key, e.value)
}
}
Taking A as an example, we can dynamically add dependencies through code:
project.afterEvaluate { p ->
println("handle deps for:" + p)
deps.A.each { e ->
def rule = depRules.get(e.key)
println("find deps of A: rule is" + rule + " ,dep is:" + e.value.get(rule).toString())
project.dependencies.add("compileOnly", e.value.get(rule))
}
}
Similarly, for APP:
project.afterEvaluate { p->
println("handle deps for:" + p)
deps.APP.each { e ->
def rule = depRules.get(e.key)
println("find deps of App:rule is" + rule + " ,dep is:" + e.value.get(rule).toString())
project.dependencies.add("implementation", e.value.get(rule))
}
}
View output:
Configure project :A handle deps for:project ':A' find deps of A: rule isp ,dep is:project ':B'
Configure project :app handle deps for:project ':app' find deps of App:rule isa ,dep is:leobert:A:1.0.0 find deps of App:rule isp ,dep is:project ':B'
In this way, we can achieve both fish and bear's paw by modifying the dependency configuration of the corresponding node. No longer constrained by pom files. At that time, we went back to the inhumanity mentioned above. We injected A's own dependency information into the APP through the with function.
However, when the size of the tree becomes larger, human maintenance is very tired. This must be solved. Of course, it is easy to solve. We can use recursive processing directly
Only the intuitive feeling close to people can be elegant and gradually realize humanitarianism. We add a global closure:
ext.utils = [
applyDependency: { project, e ->
def rule = depRules.get(e.key)
println("find deps of App:rule is " + rule + " ,dep is:" + e.value.get(rule).toString())
project.dependencies.add("implementation", e.value.get(rule))
try {
println("try to add sub deps of:" + e.key)
def sub = deps.get(e.key)
if (sub != null && sub.get("isEnd") != true) {
sub.each { se ->
ext.utils.applyDependency(project, se)
}
}
} catch (Exception ignore) {
}
}
]
Note that the dependency information we define is: modulename - > (modulename - > (scopename - > depinfo)).
This makes it difficult for us to judge the end node, that is, it is difficult to judge the recursive tail. We need to mark the end node manually. At this time, we only need to describe the tree: Foo and Bar are also ignored
project.ext.deps = [
"A" : [
"B": [
"isEnd": true,
"p" : project(':B'),
"a" : 'leobert:B:1.0.0'
]
],
"APP": [
"A": [
"p": project(':A'),
"a": 'leobert:A:1.0.0'
]
]
]
The problem has been basically solved, but it is not elegant.
Elegant, elegant, elegant
We might as well modify the description of the dependency tree to separate the node information from the tree structure and improve it again:
More humanitarian dependency description
project.ext.deps = [
"A" : ["B"],
"app": ["A"]
]
project.ext.modules = [
"A": [
"p": project(':A'),
"a": 'leobert:A:1.0.0'
],
"B": [
"p" : project(':B'),
"a" : 'leobert:B:1.0.0'
]
]
project.ext.depRules = [
"B": "p",
"A": "a"
]
Abstract the process of adding dependencies, recursively process the dependency collection of each node, and add to the host module. When a node has no dependencies in ext.deps, it is classified as:
ext.utils = [
applyDependency: { project, scope, e ->
def rule = depRules.get(e)
def eInfo = ext.modules.get(e)
println("find deps of " + project + ":rule is " + rule + " ,dep is:" + eInfo.get(rule).toString())
project.dependencies.add(scope, eInfo.get(rule))
def sub = deps.get(e) //list deps of e
println("try to add sub deps of:" + e + " ---> " + sub)
if (sub != null && !sub.isEmpty()) {
sub.each { dOfE ->
ext.utils.applyDependency(project, scope, dOfE)
}
}
}
]
Each module only needs to specify its own scope:
//:app
project.afterEvaluate { p ->
println("handle deps for:" + p)
deps.get(p.name).each { e ->
rootProject.ext.utils.applyDependency(p,"implementation",e)
}
}
//:A
project.afterEvaluate { p ->
println("handle deps for:" + p.name)
deps.get(p.name).each { e ->
rootProject.ext.utils.applyDependency(p,"compileOnly",e)
}
}
As long as it is not an independent module, it is compileOnly, otherwise it is implementation. The output is also easy to beat wrong:
> Configure project :A handle deps for:A find deps of project ':A':rule is p ,dep is:project ':B' try to add sub deps of:B ---> null > Configure project :app handle deps for:project ':app' find deps of project ':app':rule is a ,dep is:leobert:A:1.0.0 try to add sub deps of:A ---> [B] find deps of project ':app':rule is p ,dep is:project ':B' try to add sub deps of:B ---> null
Test a complex scenario, and let B and Foo rely on Base based on the figure above
project.ext.deps = [
"app": ["A", "Foo"],
"A" : ["B", "Bar"],
"Foo": ["Base"],
"B" : ["Base"],
]
project.ext.modules = [
"A": [
"p": project(':A'),
"a": 'leobert:A:1.0.0'
],
"B": [
"p": project(':B'),
"a": 'leobert:B:1.0.0'
],
"Foo": [
"p": project(':Foo'),
],
"Bar": [
"p": project(':Bar'),
],
"Base": [
"p": project(':Base'),
]
]
project.ext.depRules = [
"B" : "p",
"A" : "a",
"Foo" : "p",
"Bar" : "p",
"Base": "p"
]
> Configure project :A handle deps for:A find deps of project ':A':rule is p ,dep is:project ':B' try to add sub deps of:B ---> [Base] find deps of project ':A':rule is p ,dep is:project ':Base' try to add sub deps of:Base ---> null find deps of project ':A':rule is p ,dep is:project ':Bar' try to add sub deps of:Bar ---> null > Configure project :app handle deps for:project ':app' find deps of project ':app':rule is a ,dep is:leobert:A:1.0.0 try to add sub deps of:A ---> [B, Bar] find deps of project ':app':rule is p ,dep is:project ':B' try to add sub deps of:B ---> [Base] find deps of project ':app':rule is p ,dep is:project ':Base' try to add sub deps of:Base ---> null find deps of project ':app':rule is p ,dep is:project ':Bar' try to add sub deps of:Bar ---> null find deps of project ':app':rule is p ,dep is:project ':Foo' try to add sub deps of:Foo ---> [Base] find deps of project ':app':rule is p ,dep is:project ':Base' try to add sub deps of:Base ---> null > Configure project :Bar handle deps for:Bar > Configure project :Base handle deps for:Base > Configure project :Foo handle deps for:Foo find deps of project ':Foo':rule is p ,dep is:project ':Base' try to add sub deps of:Base ---> null
With the increase of the tree size, the reading dependency is still obvious, but the reading log is not very elegant.
Summary and Prospect
Through exploration, we found a dependency processing method that can have both fish and bear's paw, so that we can flexibly switch in the component scenario of Android field (single project, multiple module s):
- Static package dependency to shorten compilation time
- Project dependency, rapid deployment of changes for integration testing
By the way, we didn't focus on how to switch. In fact, it's very simple:
Just modify the project The corresponding configuration item in ext.deprules.
If you still have leisure, you can write another studio plug-in to obtain dependency Gradle information, output visual dependency tree; rule configuration, directly made into multiple switches, elegant and never out of date.