Link: https://www.zhihu.com/question/23148377/answer/718815659
Source: Zhihu
The copyright belongs to the author. For commercial reprint, please contact the author for authorization, and for non-commercial reprint, please indicate the source.
Summary of the top ten classic sorting algorithms (including Java code implementation)
0. Description of sorting algorithm
0.1 definition of sorting
Sort a sequence of objects according to a keyword.
0.2 description of terms
- Stable: if a is in front of b and a=b, a is still in front of b after sorting;
- Unstable: if a was originally in front of b and a=b, a may appear after b after sorting;
- Internal sorting: all sorting operations are completed in memory;
- External sorting: because the data is too large, the data is placed on the disk, and the sorting can only be carried out through the data transmission of disk and memory;
- Time complexity: the time spent in the execution of an algorithm.
- Space complexity: the amount of memory required to run a program.
0.3 algorithm summary
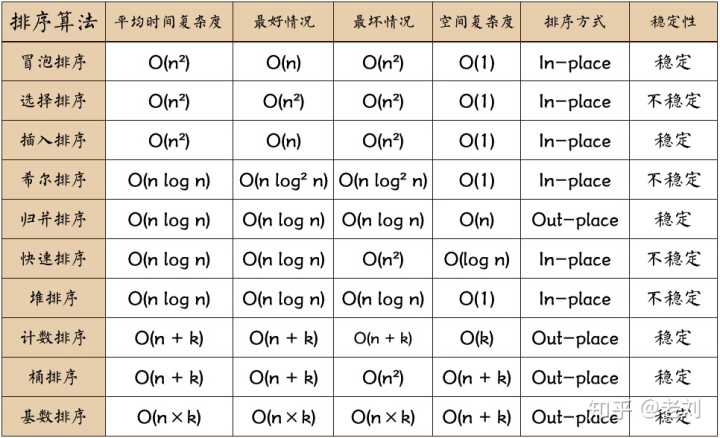
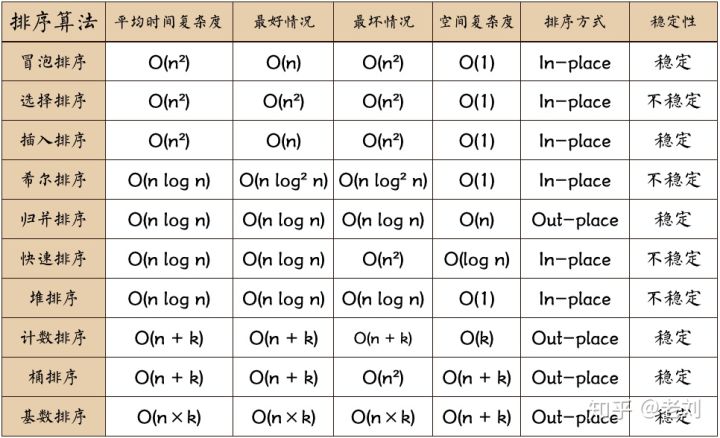
Explanation of picture terms:
- n: Data scale
- k: Number of "barrels"
- In place: constant memory, no additional memory
- Out place: taking up extra memory
0.4 algorithm classification
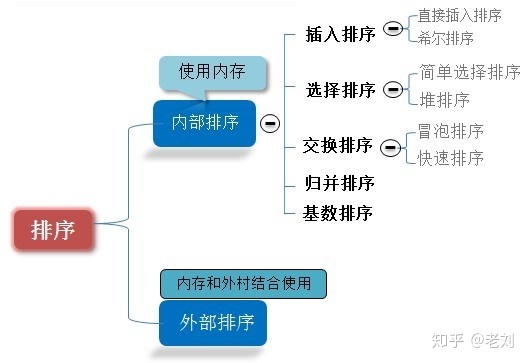
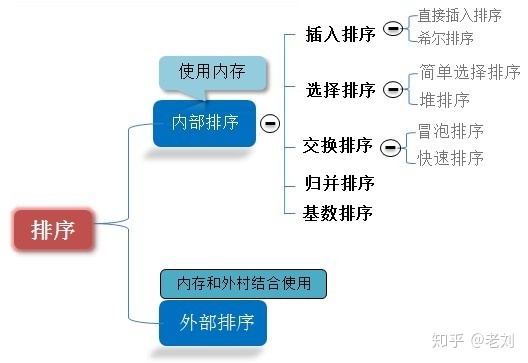
0.5 difference between comparison and non comparison
Common quick sort, merge sort, heap sort and bubble sort belong to comparative sort. In the final result of sorting, the order between elements depends on the comparison between them. Each number must be compared with other numbers to determine its position.
In bubble sort, the problem scale is n, and because it needs to be compared n times, the average time complexity is O(n) ²). In sorting such as merge sort and quick sort, the problem scale is reduced to logN times by divide and conquer, so the time complexity is O(nlogn) on average.
The advantage of comparative sorting is that it is suitable for data of all sizes and does not care about the distribution of data. It can be said that comparative sorting is applicable to all situations that need sorting.
Count sort, cardinality sort and bucket sort belong to non comparison sort. Non comparative sorting is to sort by determining how many elements should be before each element. For array arr, calculate the number of elements before arr[i], and uniquely determine the position of arr[i] in the sorted array.
Non comparative sorting can be solved by determining the number of existing elements before each element, and all traversals can be solved at one time. Algorithm time complexity O(n).
The time complexity of non comparative sorting is low, but it takes up space to determine the unique location. Therefore, there are certain requirements for data scale and data distribution.
1. Bubble Sort
Bubble sorting is a simple sorting algorithm. It repeatedly visits the sequence to be sorted, compares two elements at a time, and exchanges them if they are in the wrong order. The work of visiting the sequence is repeated until there is no need to exchange, that is, the sequence has been sorted. The name of this algorithm comes from the fact that smaller elements will slowly "float" to the top of the sequence through exchange.
1.1 algorithm description
- Compare adjacent elements. If the first is bigger than the second, exchange them two;
- Do the same for each pair of adjacent elements, from the first pair at the beginning to the last pair at the end, so that the last element should be the largest number;
- Repeat the above steps for all elements except the last one;
- Repeat steps 1 to 3 until the sorting is completed.
1.2 dynamic diagram demonstration
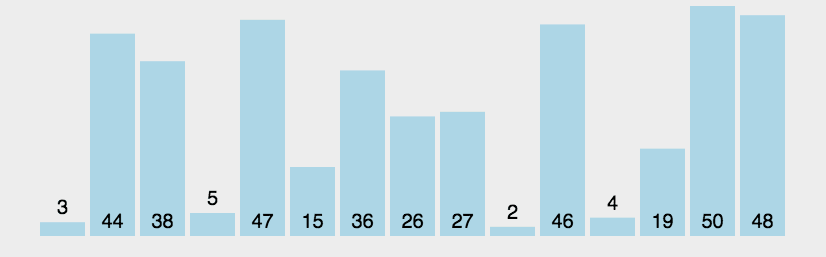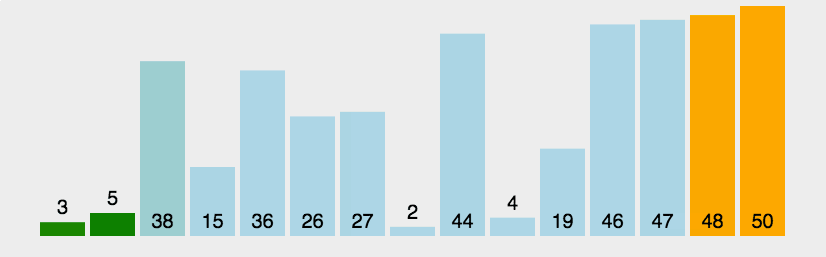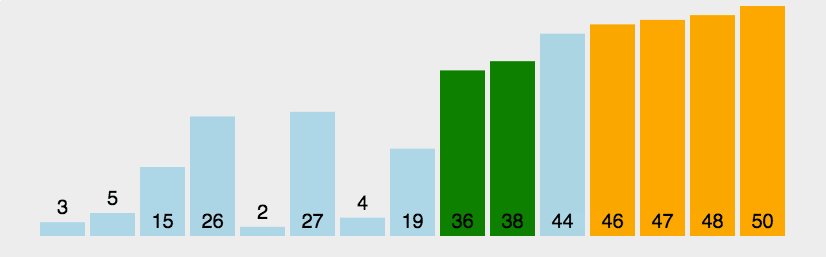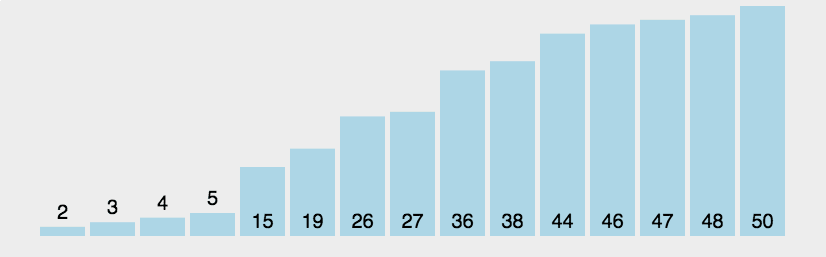
1.3 code implementation
/**
* Bubble sorting
*
* @param array
* @return
*/
public static int[] bubbleSort(int[] array) {
if (array.length == 0)
return array;
for (int i = 0; i < array.length; i++)
for (int j = 0; j < array.length - 1 - i; j++)
if (array[j + 1] < array[j]) {
int temp = array[j + 1];
array[j + 1] = array[j];
array[j] = temp;
}
return array;
}1.4 algorithm analysis
Best case: T(n) = O(n) worst case: T(n) = O(n2) average case: T(n) = O(n2)
2. Selection Sort
One of the most stable sorting algorithms, because no matter what data goes in, it is O(n2) time complexity, so when it is used, the smaller the data size, the better. The only advantage may be that it doesn't take up additional memory space. In theory, selective sorting may also be the most common sorting method that most people think of.
Selection sort is a simple and intuitive sorting algorithm. Its working principle: first, find the smallest (large) element in the unordered sequence and store it at the beginning of the sorted sequence, then continue to find the smallest (large) element from the remaining unordered elements, and then put it at the end of the sorted sequence. And so on until all elements are sorted.
2.1 algorithm description
For the direct selection sorting of n records, the ordered results can be obtained through n-1 times of direct selection sorting. The specific algorithm is described as follows:
- Initial state: the disordered area is R[1..n], and the ordered area is empty;
- At the beginning of the ith sort (i=1,2,3... n-1), the current ordered area and disordered area are R[1..i-1] and R(i..n) respectively. The sequence selects the record R[k] with the smallest keyword from the current unordered area and exchanges it with the first record r in the unordered area, so that R[1..i] and R[i+1..n) become a new ordered area with an increase in the number of records and a new unordered area with a decrease in the number of records respectively;
- At the end of n-1 trip, the array is ordered.
2.2 dynamic diagram demonstration
2.3 code implementation
/**
* Select sort
* @param array
* @return
*/
public static int[] selectionSort(int[] array) {
if (array.length == 0)
return array;
for (int i = 0; i < array.length; i++) {
int minIndex = i;
for (int j = i; j < array.length; j++) {
if (array[j] < array[minIndex]) //Minimum number found
minIndex = j; //Save the index of the smallest number
}
int temp = array[minIndex];
array[minIndex] = array[i];
array[i] = temp;
}
return array;
}2.4 algorithm analysis
Best case: T(n) = O(n2) worst case: T(n) = O(n2) average case: T(n) = O(n2)
3. Insertion Sort
The algorithm description of insertion sort is a simple and intuitive sorting algorithm. Its working principle is to build an ordered sequence, scan the unordered data from back to front in the sorted sequence, find the corresponding position and insert it. In the implementation of insertion sort, in place sort is usually adopted (i.e. the sort that only needs the additional space of O(1)). Therefore, in the process of scanning from back to front, the sorted elements need to be moved back step by step to provide insertion space for the latest elements.
3.1 algorithm description
Generally speaking, insertion sorting is implemented on the array using in place. The specific algorithm is described as follows:
- Starting from the first element, the element can be considered to have been sorted;
- Take out the next element and scan from back to front in the sorted element sequence;
- If the element (sorted) is larger than the new element, move the element to the next position;
- Repeat step 3 until the sorted element is found to be less than or equal to the position of the new element;
- After inserting the new element into this position;
- Repeat steps 2 to 5.
3.2 dynamic diagram demonstration
3.3 code implementation
/**
* Insert sort
* @param array
* @return
*/
public static int[] insertionSort(int[] array) {
if (array.length == 0)
return array;
int current;
for (int i = 0; i < array.length - 1; i++) {
current = array[i + 1];
int preIndex = i;
while (preIndex >= 0 && current < array[preIndex]) {
array[preIndex + 1] = array[preIndex];
preIndex--;
}
array[preIndex + 1] = current;
}
return array;
}3.4 algorithm analysis
Best case: T(n) = O(n) worst case: T(n) = O(n2) average case: T(n) = O(n2)
4. Shell Sort
Hill sorting is a sort algorithm proposed by Donald Shell in 1959. Hill sort is also an insertion sort. It is a more efficient version of simple insertion sort after improvement, also known as reduced incremental sort. At the same time, this algorithm is one of the first algorithms to break through O(n2). It differs from insert sort in that it preferentially compares elements that are far away. Hill sort is also called reduced incremental sort.
Hill sorting is to group the records in certain increments in the following table, and sort each group by using the direct insertion sorting algorithm; As the increment decreases, each group contains more and more keywords. When the increment decreases to 1, the whole file is just divided into one group, and the algorithm terminates.
4.1 algorithm description
Let's look at the basic steps of hill sorting. Here, we select the increment gap=length/2, reduce the increment and continue to use gap = gap/2. This incremental selection can be expressed in a sequence, {n/2,(n/2)/2...1}, which is called Incremental sequence . The selection and proof of the incremental sequence of hill sorting is a mathematical problem. The incremental sequence we choose is commonly used and is also the increment suggested by hill, which is called Hill increment, but in fact, this incremental sequence is not optimal. Here we use it as an example Hill increment.
First, divide the whole record sequence to be sorted into several subsequences for direct insertion sorting. The specific algorithm description is as follows:
- Select an incremental sequence t1, t2,..., tk, where ti > TJ, tk=1;
- Sort the sequence k times according to the number of incremental sequences k;
- For each sorting, the sequence to be sorted is divided into several subsequences with length m according to the corresponding increment ti, and each sub table is directly inserted and sorted. only Increment factor When it is 1, the whole sequence is treated as a table, and the table length is the length of the whole sequence.
4.2 process demonstration
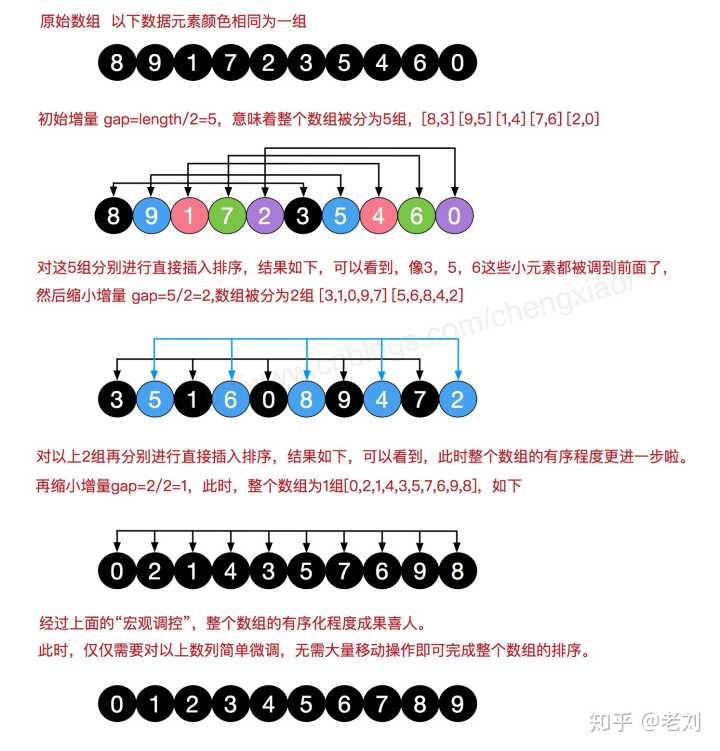
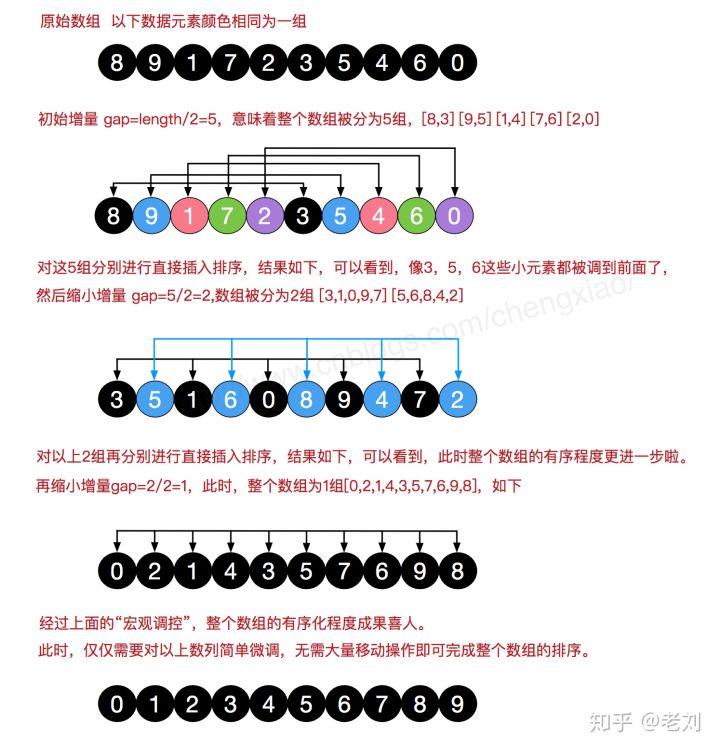
4.3 code implementation
/**
* Shell Sort
*
* @param array
* @return
*/
public static int[] ShellSort(int[] array) {
int len = array.length;
int temp, gap = len / 2;
while (gap > 0) {
for (int i = gap; i < len; i++) {
temp = array[i];
int preIndex = i - gap;
while (preIndex >= 0 && array[preIndex] > temp) {
array[preIndex + gap] = array[preIndex];
preIndex -= gap;
}
array[preIndex + gap] = temp;
}
gap /= 2;
}
return array;
}4.4 algorithm analysis
Best case: T(n) = O(nlog2 n) worst case: T(n) = O(nlog2 n) average case: T(n) =O(nlog2n)
5. Merge Sort
Like selective sorting, the performance of merge sorting is not affected by the input data, but it is much better than selective sorting, because it is always O(n log n) time complexity. The cost is the need for additional memory space.
Merge sort is an effective sort algorithm based on merge operation. The algorithm is a very typical application of Divide and Conquer. Merge sort is a stable sort method. The ordered subsequences are combined to obtain a completely ordered sequence; That is, each subsequence is ordered first, and then the subsequence segments are ordered. If two ordered tables are merged into one ordered table, it is called 2-way merging.
5.1 algorithm description
- The input sequence with length n is divided into two subsequences with length n/2;
- The two subsequences are sorted by merging;
- Merge two sorted subsequences into a final sorting sequence.
5.2 dynamic diagram demonstration
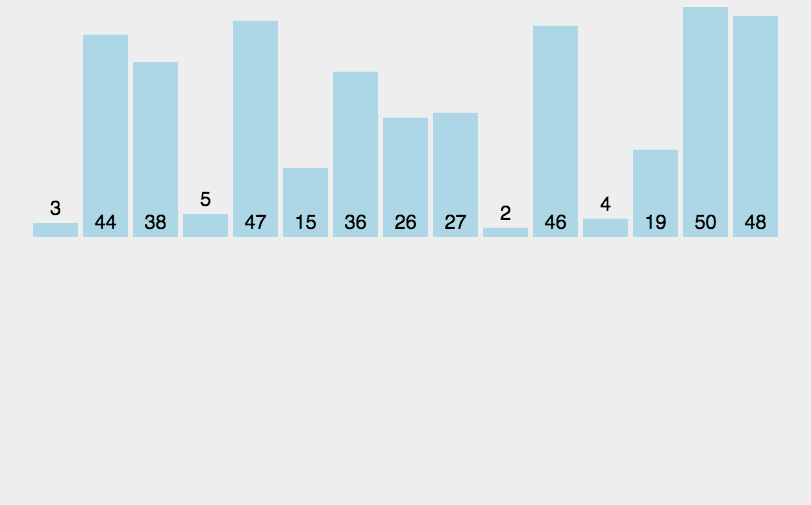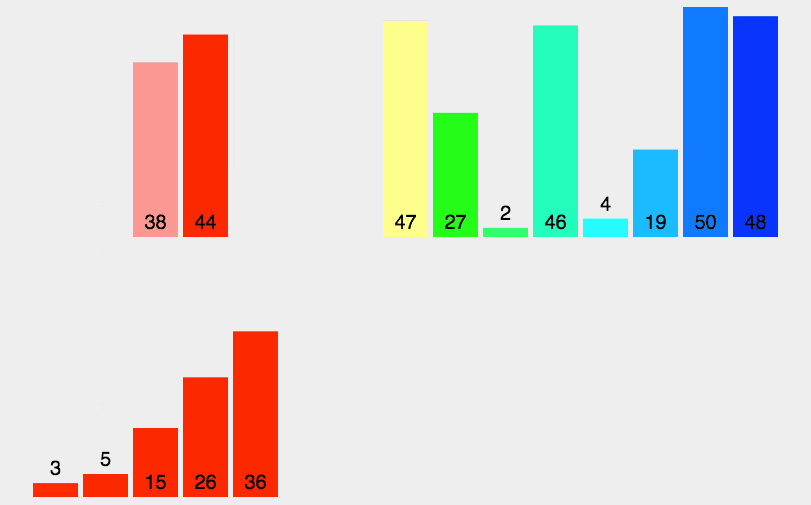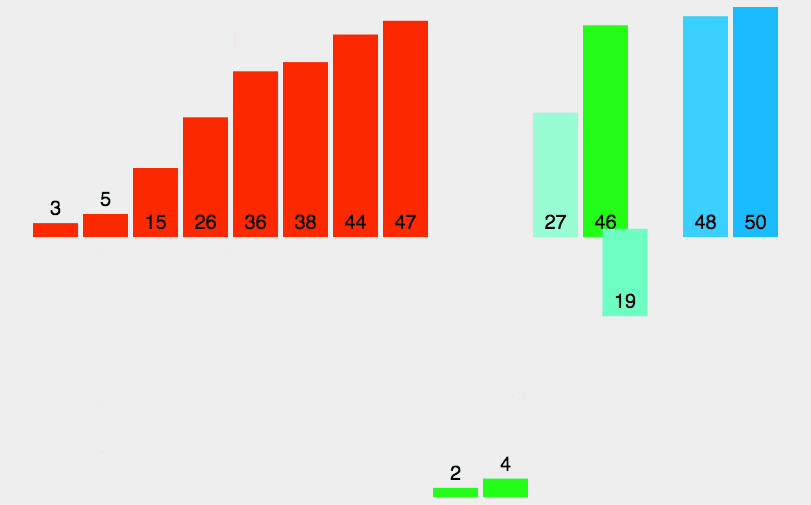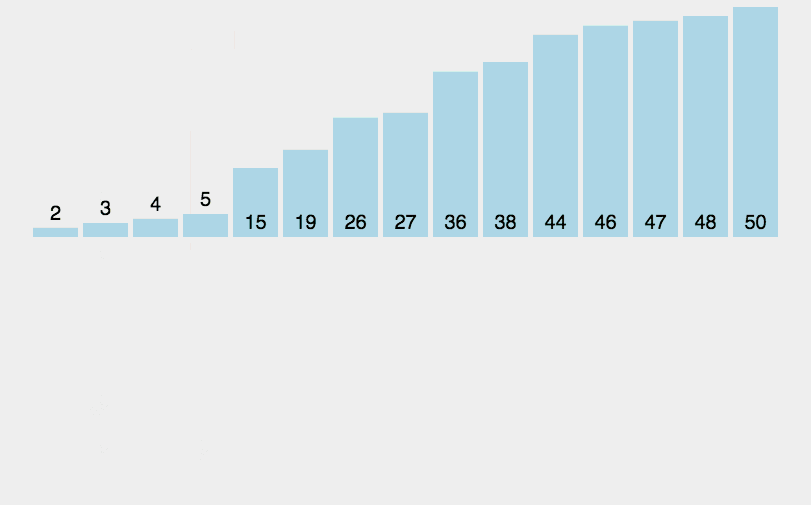
5.3 code implementation
/**
* Merge sort
*
* @param array
* @return
*/
public static int[] MergeSort(int[] array) {
if (array.length < 2) return array;
int mid = array.length / 2;
int[] left = Arrays.copyOfRange(array, 0, mid);
int[] right = Arrays.copyOfRange(array, mid, array.length);
return merge(MergeSort(left), MergeSort(right));
}
/**
* Merge sort - combines two sorted arrays into a sorted array
*
* @param left
* @param right
* @return
*/
public static int[] merge(int[] left, int[] right) {
int[] result = new int[left.length + right.length];
for (int index = 0, i = 0, j = 0; index < result.length; index++) {
if (i >= left.length)
result[index] = right[j++];
else if (j >= right.length)
result[index] = left[i++];
else if (left[i] > right[j])
result[index] = right[j++];
else
result[index] = left[i++];
}
return result;
}5.4 algorithm analysis
Best case: T(n) = O(n) worst case: T(n) = O(nlogn) average case: T(n) = O(nlogn)
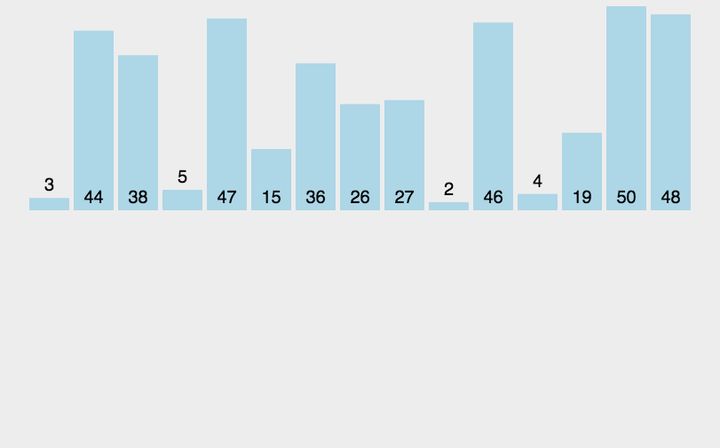
6. Quick Sort
Basic idea of quick sort: divide the records to be arranged into two independent parts through one-time sorting. If the keywords of one part of the records are smaller than those of the other part, the records of the two parts can be sorted separately to achieve the order of the whole sequence.
6.1 algorithm description
Quick sort uses divide and conquer to divide a list into two sub lists. The specific algorithm is described as follows:
- Pick out an element from the sequence, which is called "pivot";
- Reorder the sequence, all elements are smaller than Reference value The small ones are placed in front of the datum, and all elements larger than the datum value are placed behind the datum (the same number can be on either side). After the partition exits, the benchmark is in the middle of the sequence. This is called a partition operation;
- Recursively sorts subsequences that are smaller than the reference value element and subsequences that are larger than the reference value element.
6.2 dynamic diagram demonstration
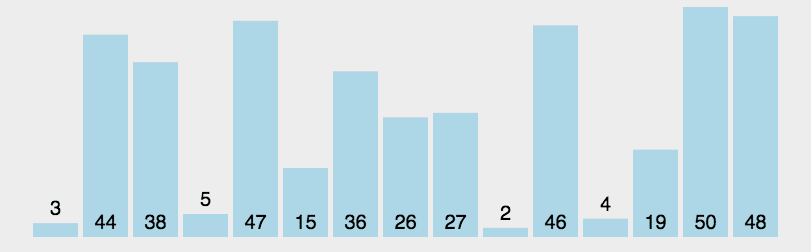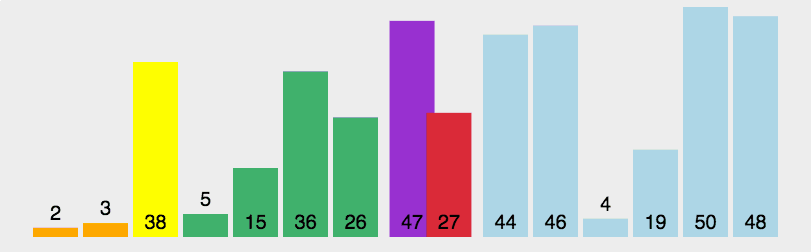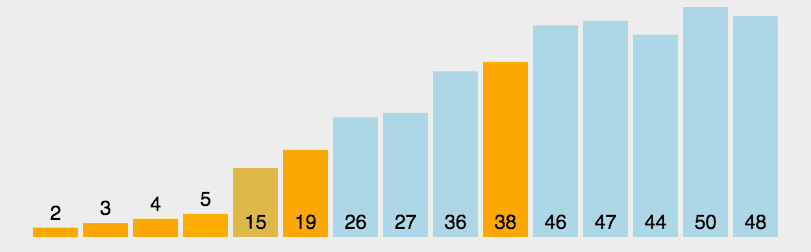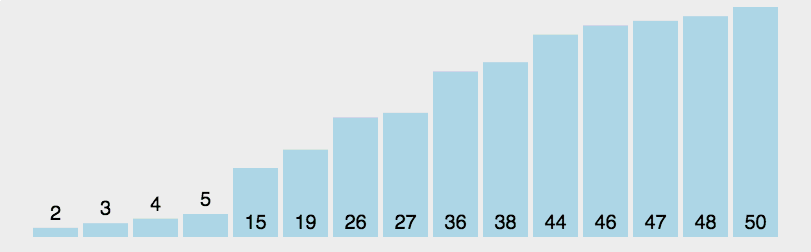
6.3 code implementation
/**
* Quick sort method
* @param array
* @param start
* @param end
* @return
*/
public static int[] QuickSort(int[] array, int start, int end) {
if (array.length < 1 || start < 0 || end >= array.length || start > end) return null;
int smallIndex = partition(array, start, end);
if (smallIndex > start)
QuickSort(array, start, smallIndex - 1);
if (smallIndex < end)
QuickSort(array, smallIndex + 1, end);
return array;
}
/**
* Fast sorting algorithm -- partition
* @param array
* @param start
* @param end
* @return
*/
public static int partition(int[] array, int start, int end) {
int pivot = (int) (start + Math.random() * (end - start + 1));
int smallIndex = start - 1;
swap(array, pivot, end);
for (int i = start; i <= end; i++)
if (array[i] <= array[end]) {
smallIndex++;
if (i > smallIndex)
swap(array, i, smallIndex);
}
return smallIndex;
}
/**
* Swap two elements in an array
* @param array
* @param i
* @param j
*/
public static void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[